面壁「小钢炮」又有新成员啦。
清华大学联合面壁智能推出了一款新的语音生成模型:VoxCPM,目前已经在 GitHub 和 Hugging Face 上开源了。
VoxCPM 模型参数尺寸仅有 0.5 B,非常轻量,但语音合成的效果一点儿不逊。
在自然度、音色复刻程度、韵律等方面都达到了最优的水平,极其高效、实用。
而且RTF只有0.17左右 ,支持流式输出。这个新的小钢炮不仅能快速合成语音 ,还能适应各种实时交互场景哦。
01、先来看看效果
面壁小钢炮 VoxCPM 不仅拥有高质量和丰富表现力的声线,而且只需上传几秒的参考声音,就能实现克隆。
可以看这个demo 样例,openbmb.github.io/VoxCPM-demo...
比如上传一段咖喱味的英语作为参考音色,使用 VoxCPM 参考合成一段新的音频。
方言场景,上传比较有特色的四川话和河南话,看看 VoxCPM 怎么个情况。
不同情绪的合成效果,看看小钢炮在伤心、开心、愤怒上情绪表达的效果。
实际听感上,VoxCPM 生成的语音在情绪、音色、口音、停顿、韵律等方面表现与真人无异。
02、性能表现
下面这个表梳理了目前主流的语音合成模型的表现,开源的和不开源的都列进去了。
基于 Seed-TTS-EVAL 权威评测榜单,可以看到面壁小钢炮 VoxCPM 在 WER% (词错误率) 、 CER% (字错误率)、SIM% (相似度) 等维度上,不管是英文还是中文都达到了最优。
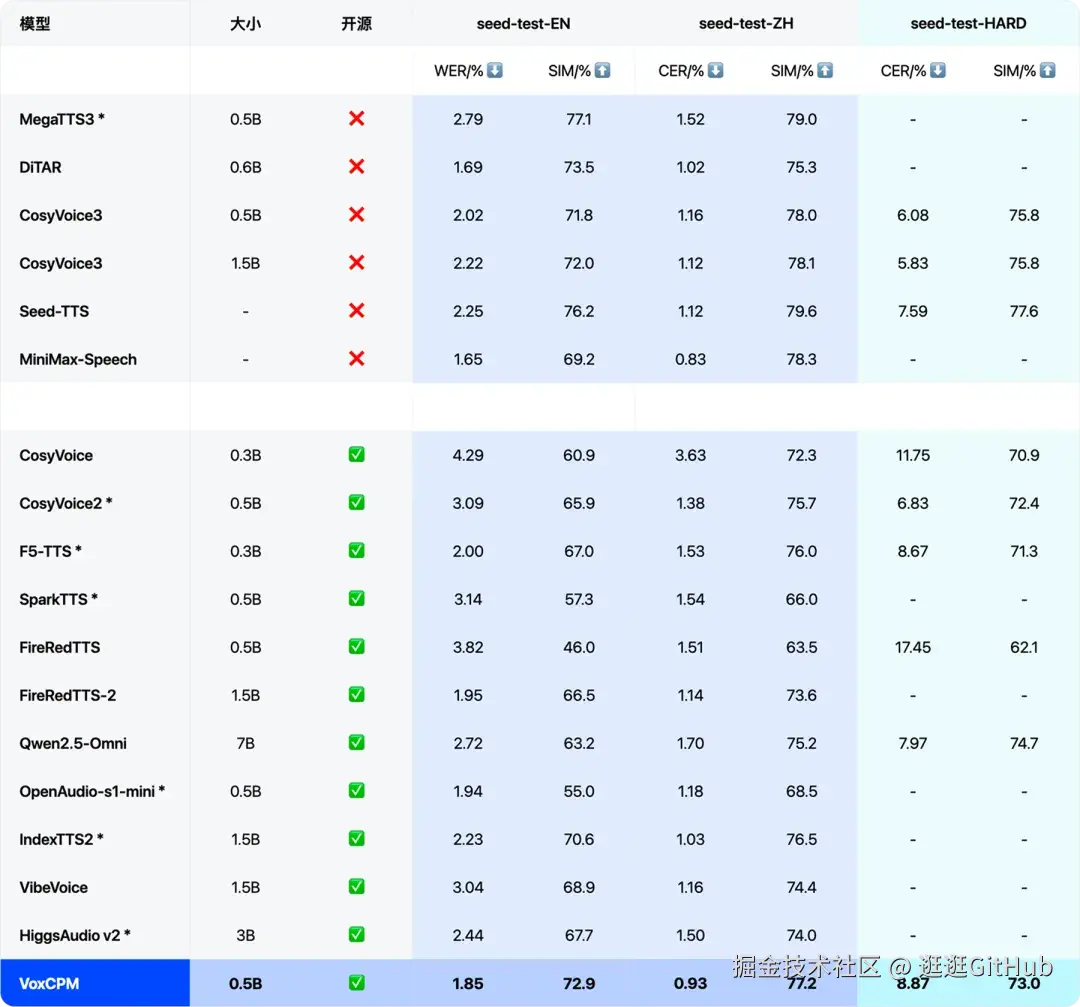
也就是说这个 0.5B 的小家伙,合成语音的准确性 、克隆音色的相似程度、效率三个方面取得了惊人平衡的模型。
尤其在中文场景下表现堪称完美。
03、模型原理
下面是 VoxCPM 模型的架构图。
它利用一个 MiniCPM-4 作为大脑来理解文本上下文,摒弃传统的语音离散化步骤,直接在连续空间中,采用扩散自回归的生成方式。
并辅以 FSQ 等约束来实现特征解耦,从而同时实现高度表现力的语音合成和极其逼真的零样本语音克隆。
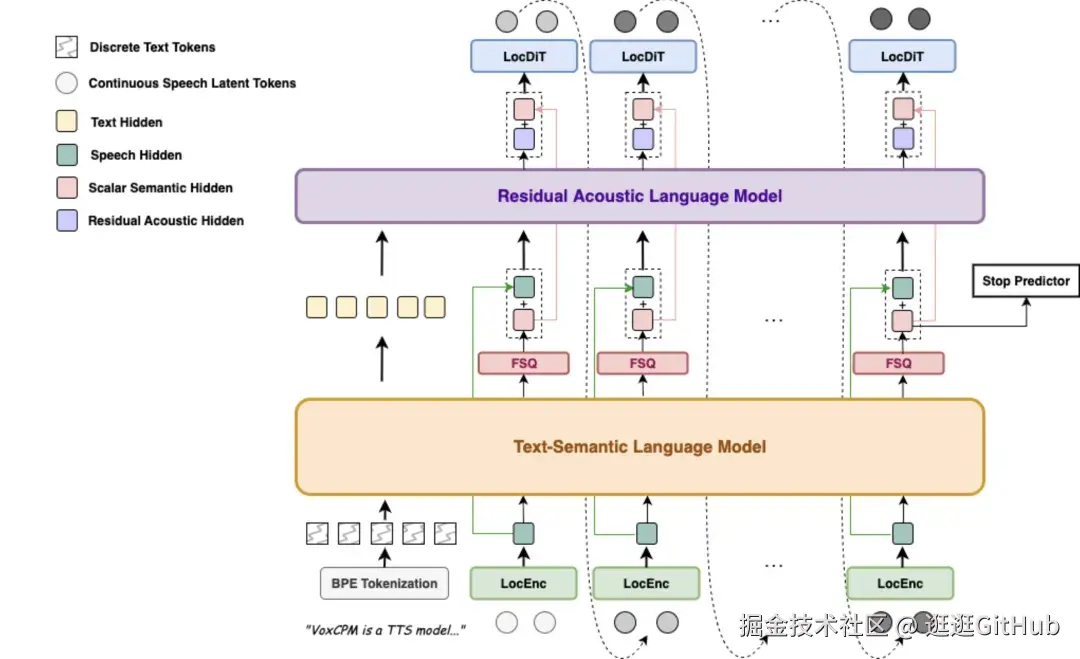
这种方法的优势在于生成的语音细节更丰富、更自然,并且对参考音色的还原度非常高,不仅模仿音色,还能模仿说话风格。
而且 VoxCPM 的推理效率特别高,在一张 RTX 4090 显卡上,RTF 只有 0.17 左右,还支持流式输出。
这意味着它不仅能快速合成语音,还能适应各种实时交互场景。
补充说明:RTF 指的是 生成音频所需时间 / 音频本身的时长,这个值越小,速度越快。一般来说,RTF 低于 0.2 就已经是非常好的水平了。
04、如何使用
面壁小钢炮提供了一个地址,你不需要自己部署就能在下面这个链接体验到。
ruby
Demo体验:https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo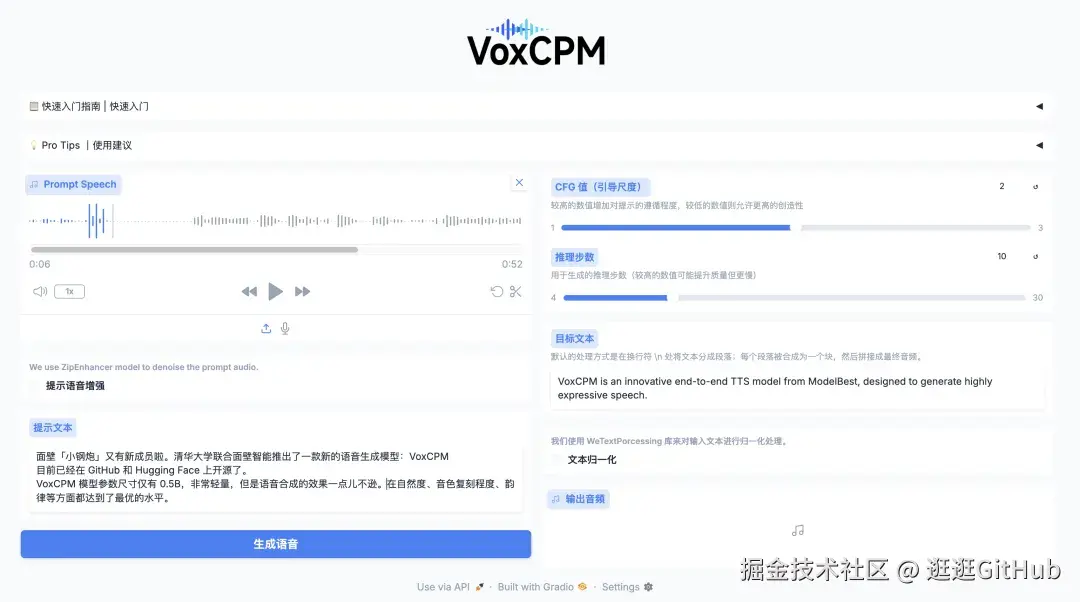
下面是 VoxCPM 模型在 GitHub 等社区的开源链接,你可以前往开源项目主页查看部署教程。
ruby
Github: https://github.com/OpenBMB/VoxCPM/Hugging Face: https://huggingface.co/openbmb/VoxCPM-0.5BPlayGround体验: https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo音频样例页面地址:https://openbmb.github.io/VoxCPM-demopage部署很简单,安装后下载模型权重,然后调用使用就行了。
① 安装模型
pip install voxcpm② 下载模型
其实在首次运行的时候模型会自动下载,如果不放心可以通过下面的命令自己先下载着。
java
# 下载 VoxCPM-0.5Bfrom huggingface_hub import snapshot_downloadsnapshot_download("openbmb/VoxCPM-0.5B",local_files_only=local_files_only)
# 下载 ZipEnhancer 和 SenseVoice-Small。from modelscope import snapshot_downloadsnapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')snapshot_download('iic/SenseVoiceSmall')ZipEnhancer 可以增强语音提示,使用 SenseVoice-Small 进行语音提示的 ASR。
③ 代码调用
python
import soundfile as sffrom voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
wav = model.generate( text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.", prompt_wav_path=None, # optional: path to a prompt speech for voice cloning prompt_text=None, # optional: reference text cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed normalize=True, # enable external TN tool denoise=True, # enable external Denoise tool retry_badcase=True, # enable retrying mode for some bad cases (unstoppable) retry_badcase_max_times=3, # maximum retrying times retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech)
sf.write("output.wav", wav, 16000)print("saved: output.wav")如果想部署一个 UI 界面鼠标操作,直接。运行 python app.py 就行了。