前言
2023 年底,公司正式决策启动货运离线大数据迁移项目。历经五个月协同推进,项目于 2024 年 5 月顺利完成离线链路全量(覆盖任务、数据、服务及基础设施)跨云迁移切换,期间共有十余个部门深度参与。如今距离迁移完成已逾一年,回望整个过程仍历历在目 ------ 项目推进中曾面临诸多难点与挑战,最终均通过多方协作逐一攻克,为后续链路稳定运行奠定了坚实基础。
业界迁移上云或跨云迁移的案例虽多,但鲜有聚焦大数据场景的实施细节分享。为此,我们决定将本次离线大数据迁移的完整实施过程梳理成文,希望能为行业内同类大数据迁移实践提供可借鉴的经验与思路。本文先从整体视角介绍迁移方案设计与实施全流程,后续将通过系列公众号文章,对数据迁移技术细节、数据验证方法体系等核心内容展开深度拆解与分享,诚邀大家关注并提出宝贵指导意见。
背景介绍
1. 大数据跨云架构
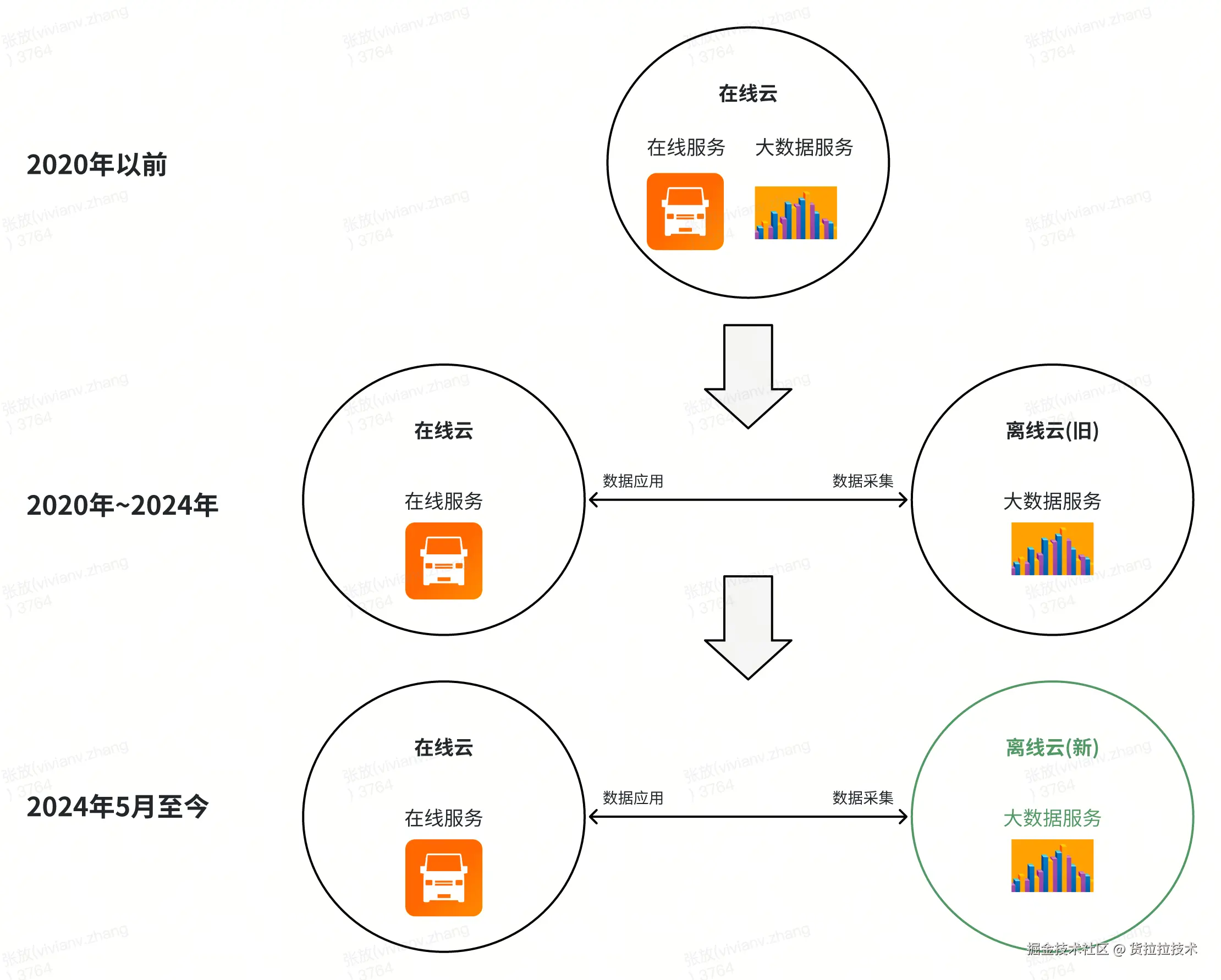
货拉拉大数据 IT 架构是"多云 + 云上自建"形式。大数据核心服务能力从一开始,只依赖云商的基础设施(IaaS)层,开始研发时投入较大,但从长期看有可控性强、能做深度研发优化、容易迁移和复制等优势。
- 2020 年前:在线服务和大数据服务都部署在同一个云上。
- 2020 年后:将离线大数据服务迁移到离线云,进入多云阶段。多云架构是业界中大型互联网公司常见的 IT 架构,具有和云商议价空间大、能互补云商技术优势等优点。
- 2024 年 5 月后:将大数据离线服务原有离线云迁移到新的云上。
2. 离线大数据规模
2.1 离线存储
这次迁移包含公司货运 10 年积累的约 40PB 数据存储和 4 万多个数据计算任务,在货运行业属于前列体量。
| 业务线 | 数据量 | 文件数量 | 任务量 | 涉及部门数 |
|---|---|---|---|---|
| HLL | 40PB | 10亿+ | 40000+ | 17个 |
2.2 离线计算
货拉拉离线大数据集群规模近千节点,同时还有 Presto 混合引擎集群、业务专用计算集群、分布式调度服务节点以及 GPU/CPU 异构计算资源池,整体架构呈现多层级、组件异构的特征。在迁移过程中,需要控制与在线服务集群(低延迟交互)、实时计算集群(流式数据依赖)的跨网络域数据交换策略,跨集群的数据传输和网络权限设计面临严峻挑战。
迁移方案设计
设计云迁移方案时,对技术保障要求很高,要保证"迁移前后数据准确、准时,停机时间少且不影响业务"。因此,我们根据以前的数据迁移经验,结合这次迁移的复杂程度,重新设计了"可验证、可回滚"的数据迁移方案。
- 可验证 :
- 性能验证:
- 前期 POC 阶段对新环境的存储和计算性能进行充分测试;
- 链路双跑阶段,在新云环境里尽可能多的将所有可被双跑的任务运行起来,跟踪新链路性能指标。
- 数据验证:新旧环境大数据库表、文件能进行比对,验证数据质量。
- 性能验证:
- 可回滚:采用主备链路双跑方案,主备切换时一旦切换实施有问题,还能再切回主链路。
整体方案可以简化为下图:
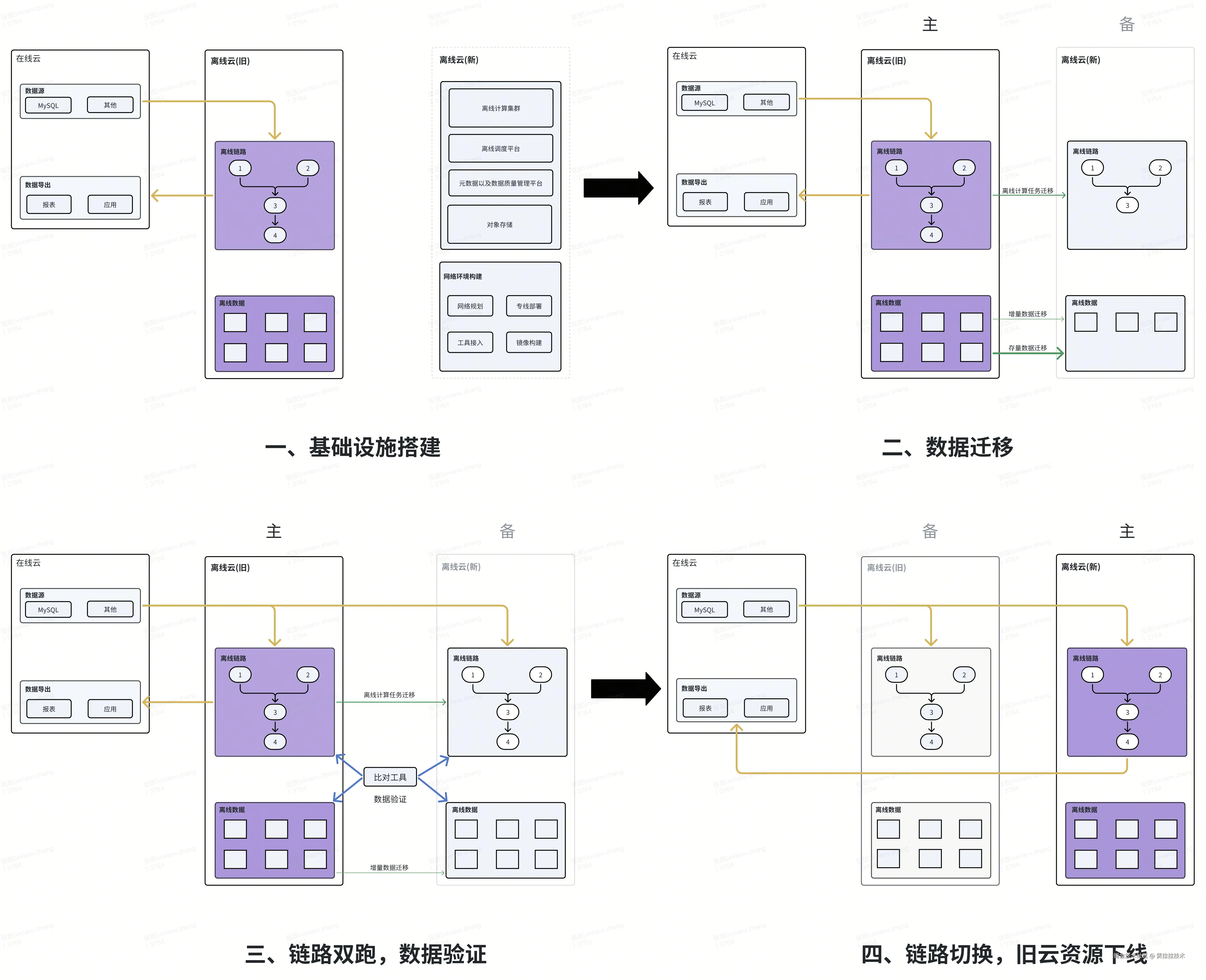
- 基础设施搭建:完成新云环境网络规划、基础组件适配、大数据集群交付等工作;
- 数据迁移:开始进行存量数据迁移、元数据迁移、离线链路任务迁移等事项;
- 链路双跑、数据验证:新云链路开启离线计算链路抽数(Mysql/其他 to Hive)任务,每天验证数据链路结果;
- 链路切换、资源下线:数据质量验收通过之后,新云链路切主,旧云链路变为备链路(具备可回滚条件)。新云环境运行稳定、历史数据无质量问题之后,下线旧云链路以及资源。
迁移方案实施
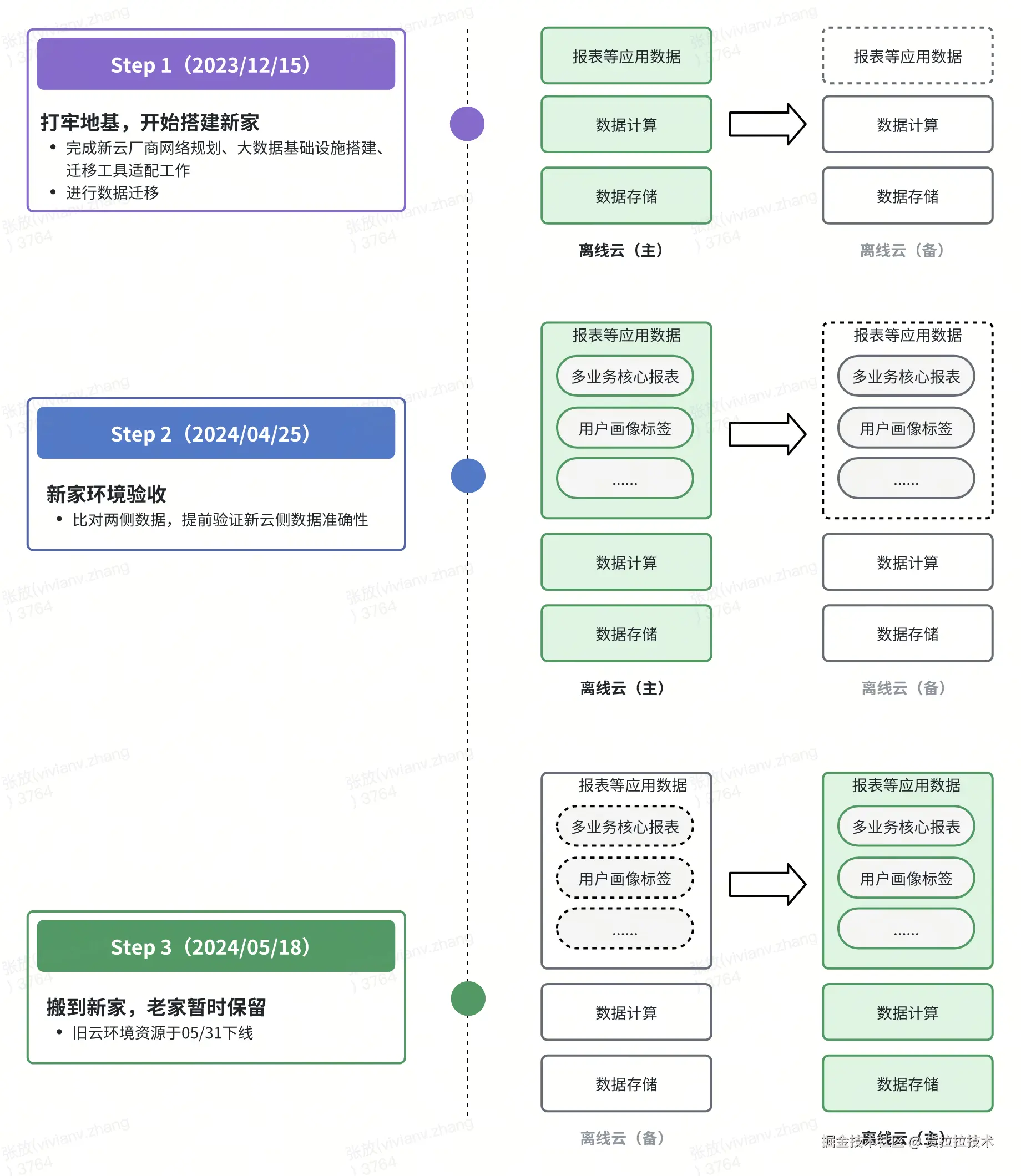 迁移方案设计完成之后,我们于 2023 年 12 月开始"搬家",整个迁移困难重重但是有惊无险。因为篇幅有限,本文列举部分难点问题及解决方案:
迁移方案设计完成之后,我们于 2023 年 12 月开始"搬家",整个迁移困难重重但是有惊无险。因为篇幅有限,本文列举部分难点问题及解决方案:
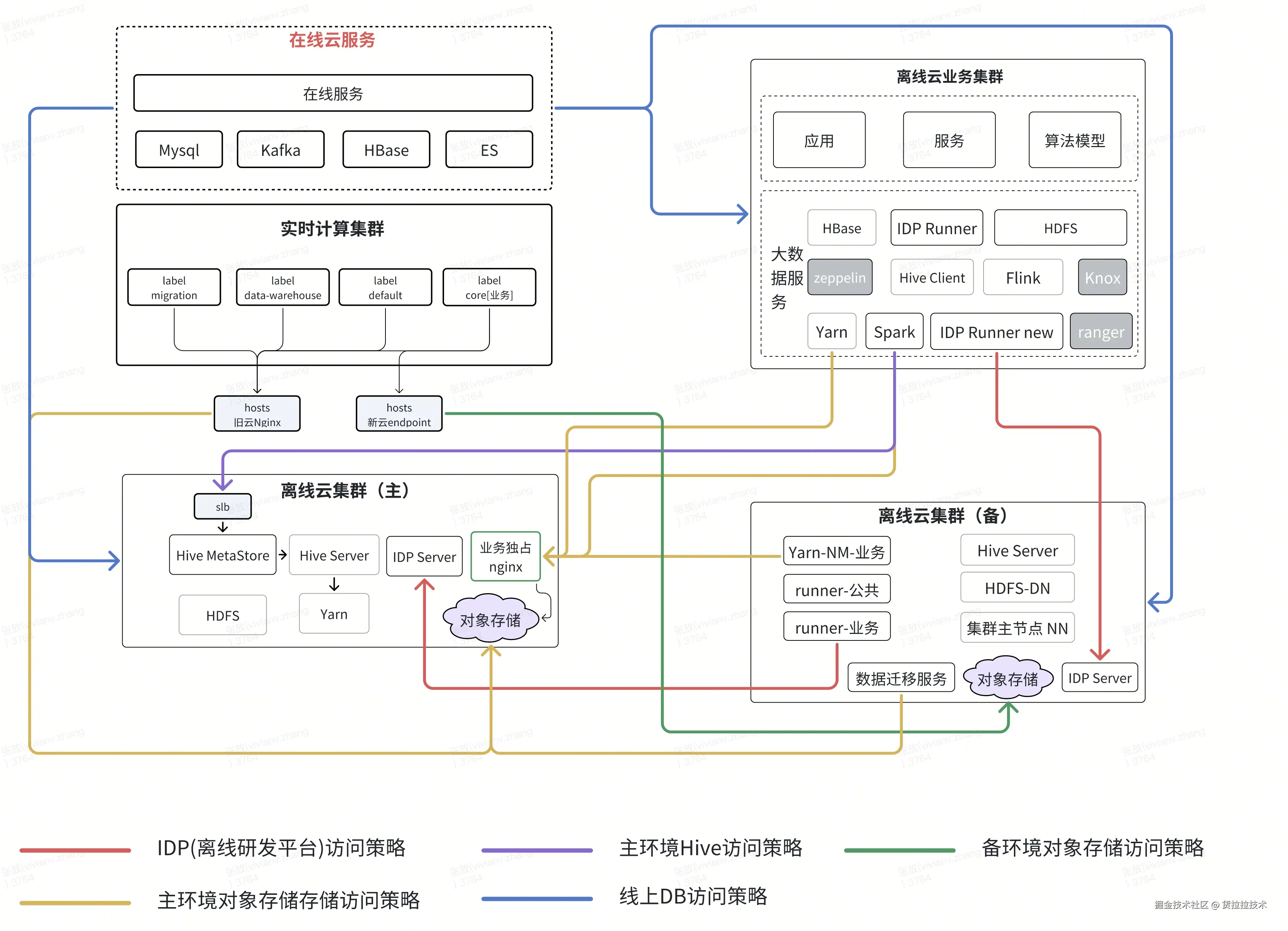
1. 网络怎么隔离
大数据网络架构是"离线云(旧)-- 离线云(新)-- 在线云"三朵云跨云数据交互,不同云集群按"组件端口粒度"进行网络隔离,同时需确保隔离策略不会对现有业务网络产生影响。首次在大数据场景实施此隔离策略,技术挑战大:
1. 拓扑梳理与粒度细化:梳理四套集群、30 余个组件、IDP 大数据离线调度平台及线上服务的调用关系,形成完整调用拓扑图,并将链路信息细化至端口级别,为后续网络配置与迁移规划提供精准依据;
2. 主备链路网络隔离:采用网络白名单机制实现主备双跑链路的隔离管控,只允许主环境数据同步到备环境;
3. 备链路与在线云隔离策略:采用网络黑名单机制构建新云与在线云的隔离,防止链路双跑过程中新链路数据推送到在线业务;
4. 切换前网络验证:链路切换前临时开启新云和在线云的隔离策略,验证双跑期间无法双跑的任务(Hive to HBase、Hive to Mysql 等场景);
5. 切换后网路配置:链路切换后停用新云和在线云的网络隔离策略,保留新云和旧云的策略;同时新增旧云和在线云的网络隔离策略,防止备链路数据污染主链路和线上。
2. 海量数据怎么迁移
40PB 的海量数据,而且每天都在变,怎么快速搬到新云环境并保证数据准确?大数据迁移不是简单的"文件复制粘贴",而是一场系统工程:迁移过程中的数据质量是重中之重,只有当两侧链路的元数据、Hive表数据、任务代码一致之后,才能开始双跑和验数工作。因此针对数据迁移和数据一致性保障我们做了如下工作:
-
打造高吞吐、可扩展数据迁移工具:经过前期调研发现,Hadoop DistCP等工具只能进行简单的数据搬迁,无法校验大数据库表结果一致性。大数据场景还有十亿级别的小文件,怎样在并行迁移的同时还能持续打满跨云专线,提升迁移效率也是一大难题。因此我们自研了高吞吐、高性能、可扩展的数据迁移工具,用千台机器规模的大数据集群一起进行数据搬迁和比对。同时支持Hive表级别、分区级别、文件级别数据比对,以及Hive元数据比对、同步,解决了海量数据迁移时的元数据、表、文件一致性问题。
- 高吞吐:无法打满跨云带宽 -> 持续打满100Gb带宽
- 高性能 :每日多轮的全量文件元数据比对,2日一轮的数据行数比对。
- 2500万+全量分区数据行数比对耗时:18日 -> 2日
- 14亿全量文件元数据比对耗时:5小时 -> 1.5小时
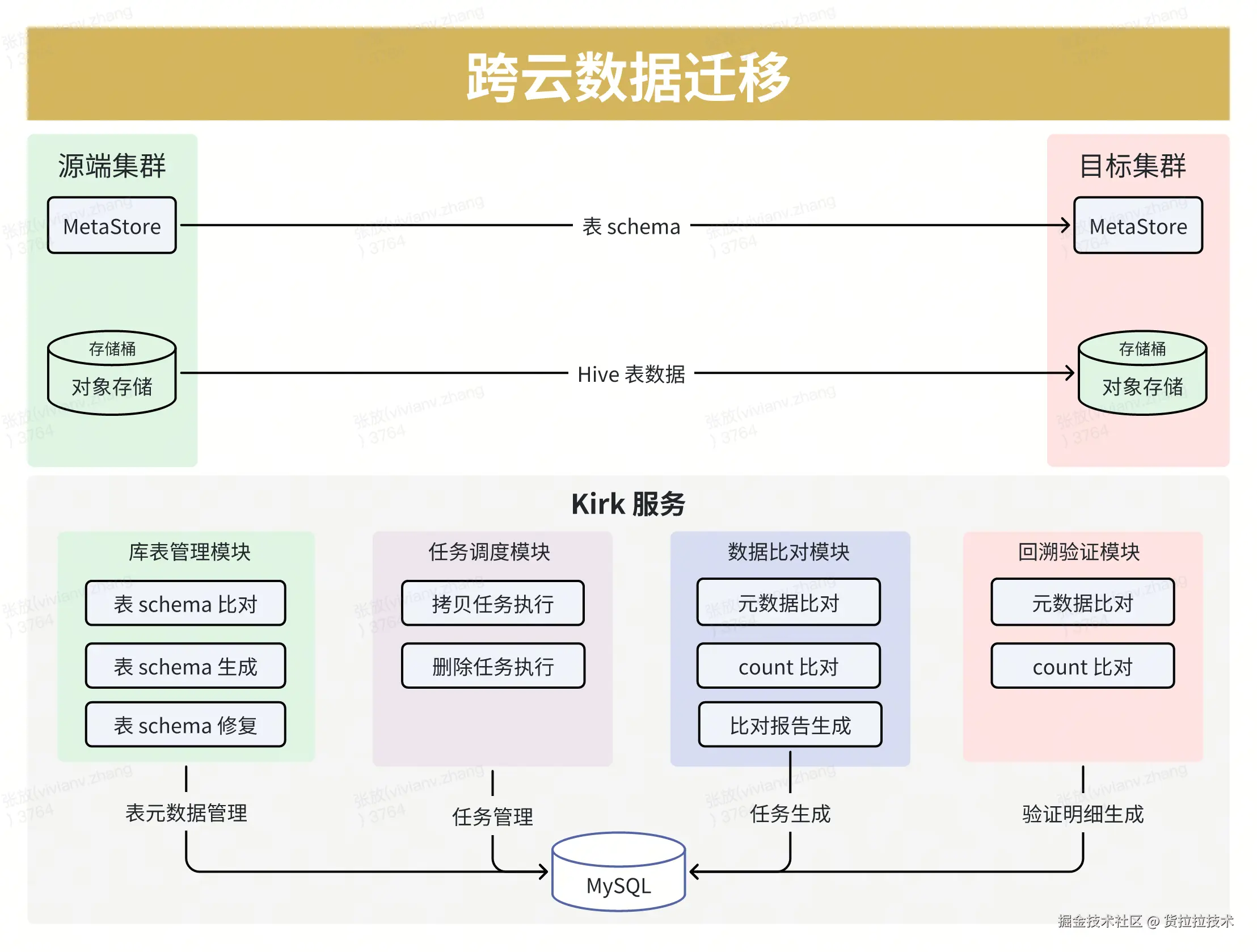
- 数据一致性保障:
- 数据一致性:实现每日500TB以上数据(未拷贝分区和不一致分区)及时拷贝;通过比对报告(库级、表级)准确掌握同步结果。
- 表元数据一致性:通过表 schema 自动化差异比对,针对表末尾加字段、表字段乱序等场景自动生成 DDL 语句,结合是否核心链路表、表大小等信息判断后自动同步。
- 代码一致性:为保证计算任务代码、数据、元数据一致,数据平台研发了自动同步功能,用户在主环境修改的数据和计算任务,能自动同步到备环境,减少了双跑期间用户维护代码的复杂度,保证了主备环境代码的一致性。
3. 数据如何验证
存量数据迁移完成(每日仍在迁移增量数据)、抽数任务全量打开后,新环境开始"蓄水"了。此时开始进入链路双跑期,新链路的数据每天会调度产出,数据验证的考验接踵而至:怎么验证涉及公司近 20 个部门、数万张Hive表的数据和主环境是否一致?
- 自研自动化数据比对能力 :研发上线平台化数据校验工具,支持定时任务 + 批量比对等核心功能,将用户验数时间缩短 90% 以上 ------ 例如某部门仅需 1 人耗时数天,便完成了近 1500 张重点数仓表的精准验证。另外,数据验证时我们总结了"先粗验、再精验"的验收方案:
- 粗验:仅对比迁移前后两侧数据表及分区的行数,待行数一致后,判定为满足精准验数的基础条件;
- 精验:精确比对表字段,可以按指定字段联合比对,针对订单金额等数据场景可以支持设置"数据误差比对"。 因数据应用层存在大量报表类库表,其单量、金额等指标易因上游抽数的微小时间差导致join不上,通过设置合理误差容忍区间,可实现对结果准确性的科学评估。
- 数据比对分优先级层层推进:按数据基建层、数据应用层顺序验数,每天定时产出库表验数报告,验数小组负责定位、解决、跟踪数据不一致问题,直到所有问题全部闭环。

4. 主备链路怎么切换
万事俱备,只欠东风。在顺利完成链路双跑和数据验证之后,即将进入最关键的环节 ------ 主备链路切换。尽管当前的双跑机制支持快速回滚,但我们依然希望力争一次切换成功。一旦切换失败,不仅可能导致项目延期,更会带来数据延迟、线上数据异常等难以承受的严重后果。
为了确保切换过程万无一失,我们详细制定了链路切换SOP,并成立了专门的 "链路切换重点保障小组",为整个主备切换流程保驾护航。以下是切换SOP的简略大纲:

思考与总结
经过全体项目组成员的努力,我们最终顺利完成了切换动作,新环境链路数据正常准确产出,打赢了这场旷日持久的攻坚战。项目结束后,我们也在思考如果再做一次,哪些事能做得更好,哪些经验能用到后续类似项目中:
- 持续迭代优化迁移方案:方案的完整性与适配性是迁移成功的核心前提。鉴于需迁移的大数据链路及基础设施已积累近十年,难免会有线上调用、非常规依赖及无归属代码/任务等意外case,因此需全面覆盖各类潜在风险点,通过多轮方案打磨将风险降到最低。
- 自动化能力至关重要 :
- 数据迁移工具:极大的提升了我们的数据迁移效率,后续可应用于大数据灾备时可扩大灾备场景范围(增加元数据灾备能力);
- 资源交付自动化:云上基础设施和大数据集群能自动搭建交付,缩短了基础设施搭建时间;
- 数据自动比对工具:比手动验数节省人力约20+人月,用少量资源完成了全公司重点表数据及任务代码验证。
- 云上技术选型经验:大数据积累了成熟的成本测算、云产品性能测试、云产品稳定性保障能力对比等流程,面对新云环境能快速完成性能 POC。
致谢
本次离线大数据云迁移项目由货拉拉技术中心多个部门和 10 多个业务部门重点参与,项目的圆满完成离不开全体项目组成员近半年夜以继日的付出,以及云商专家团队的支持配合,在此一并表示感谢!
笔者介绍:张伟伟|大数据专家,目前负责货拉拉大数据SRE方向,以及实时稳定性保障、大数据成本管控体系