大家好,我是二哥呀。
上次发小米的帖子里,有同学留言说:"武汉金山本科都能开到20k以上,谁是雷总亲儿子不用我多说了吧?"
你别说,真别说,金山如果真能开到 20k 以上,还是本科,那绝逼是比小米亲儿子的。
但是金山招人太少了,并且主要是 Go 岗居多。想冲 Go 的同学可以参考一下我这个学习路线,很顶的,Google 搜 Go 学习路线排名第一。
等后续校招派、简历派这两个项目做完后,我也打算做一些 Go 的实战项目,计划先把派聪明开个 Go 的分支,再做几个轮子,有需要的同学可以 push 一下我。
就目前来说,仍然推荐大家多冲冲小米,是不是亲儿子不知道,反正岗位是比金山要多不少。
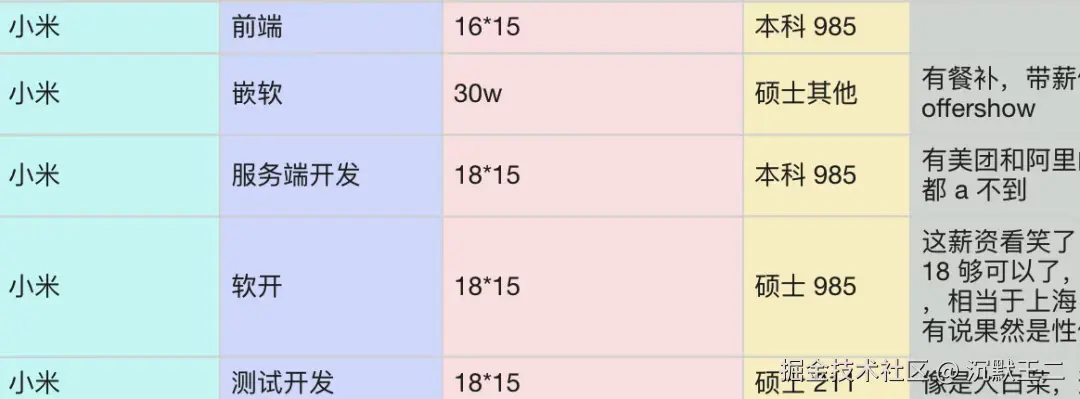
刚好最近也有球友参加了小米的线下面试,还分享了面经,就借这个机会,给大家复盘下这些面试题,方便后续参加面试的同学做个参考,原题出现的概率很大。
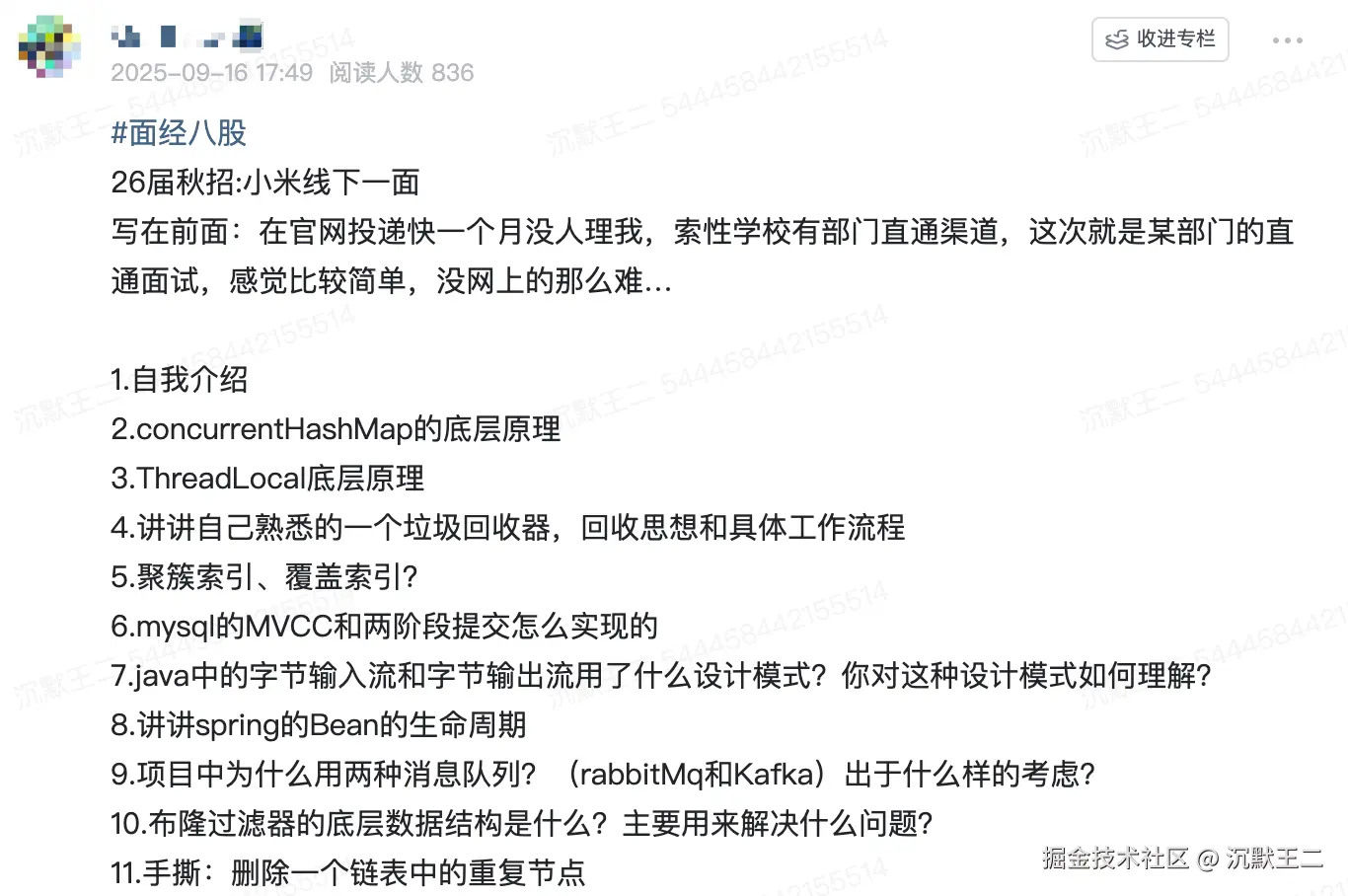
因为这些题目都很高频,主要集中在 Java 基础、MySQL、Spring、Redis、消息队列上面,大家在面试的时候也一定要注意每家公司的特点,好针对性地去复习准备。
同学 P小米线下面试
自我介绍
我是来自家里蹲大学的小王,之前参加过小米的训练营。项目目前做一个基于 RAG 架构的企业级私有知识库派聪明,其核心意义在于解决现代企业知识管理的痛点,推动组织智能化转型。
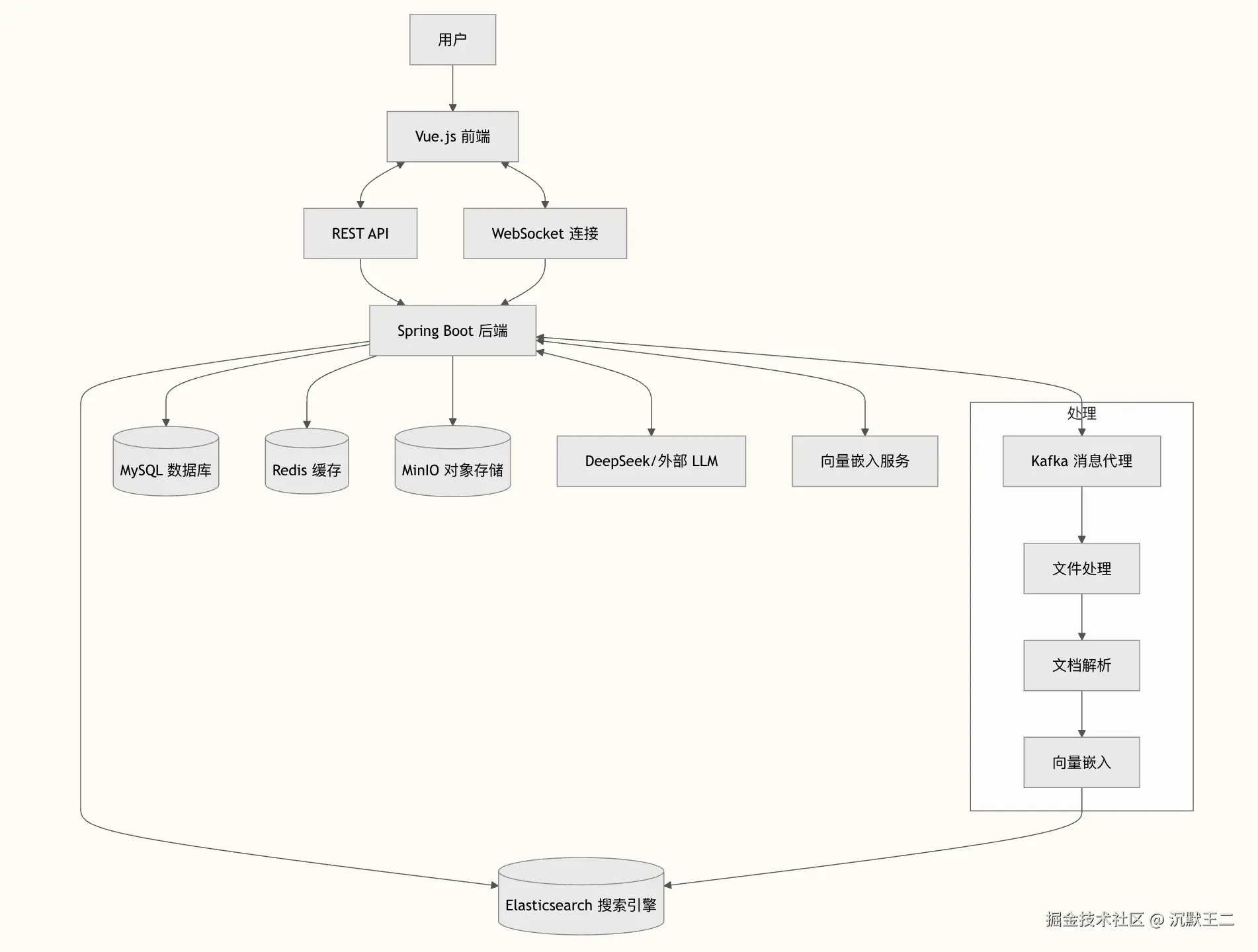
派聪明通过集成 Apache Tika 文档解析、DeepSeek 大模型向量化和 Elasticsearch 混合检索技术,构建了一套完整的智能知识处理流水线。系统能够自动解析 Word、PDF、Excel 等多种格式文档,将非结构化信息转化为可检索的知识资产。更重要的是,基于语义理解的向量检索技术突破了传统关键词匹配的局限,用户可以用自然语言描述需求,系统能够理解意图并返回相关内容。
另外一个项目是 xxxx。
我个人也是小米的忠实用户,家里的智能设备都买的清一色小米,手机也一直用的小米,也非常期待能加入到小米这个大家庭。
concurrentHashMap的底层原理
ConcurrentHashMap 是 HashMap 的线程安全版本。
JDK 7 采用的是分段锁,整个 Map 会被分为若干段,每个段都可以独立加锁。不同的线程可以同时操作不同的段,从而实现并发。
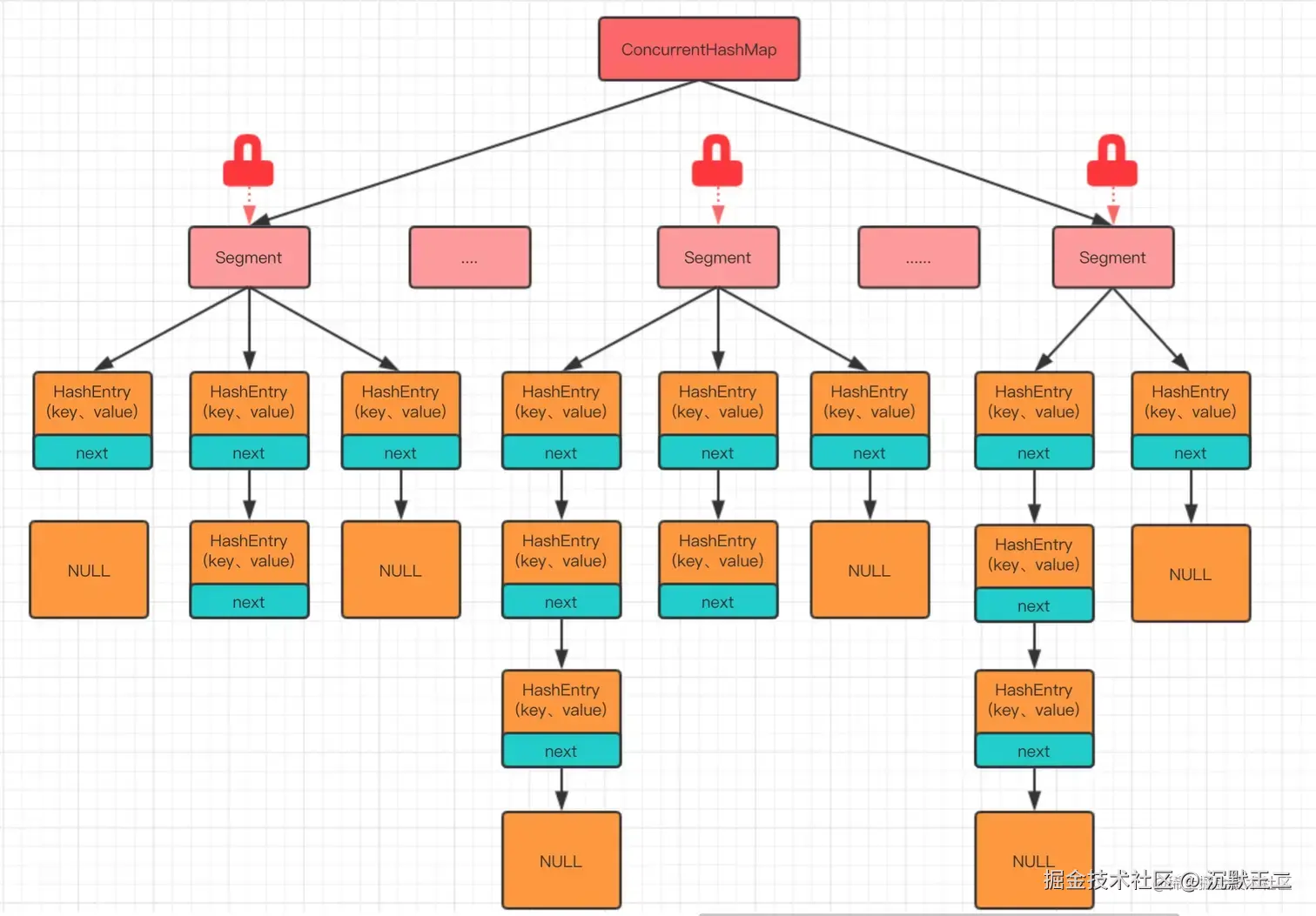
JDK 8 使用了一种更加细粒度的锁------桶锁,再配合 CAS + synchronized 代码块控制并发写入,以最大程度减少锁的竞争。
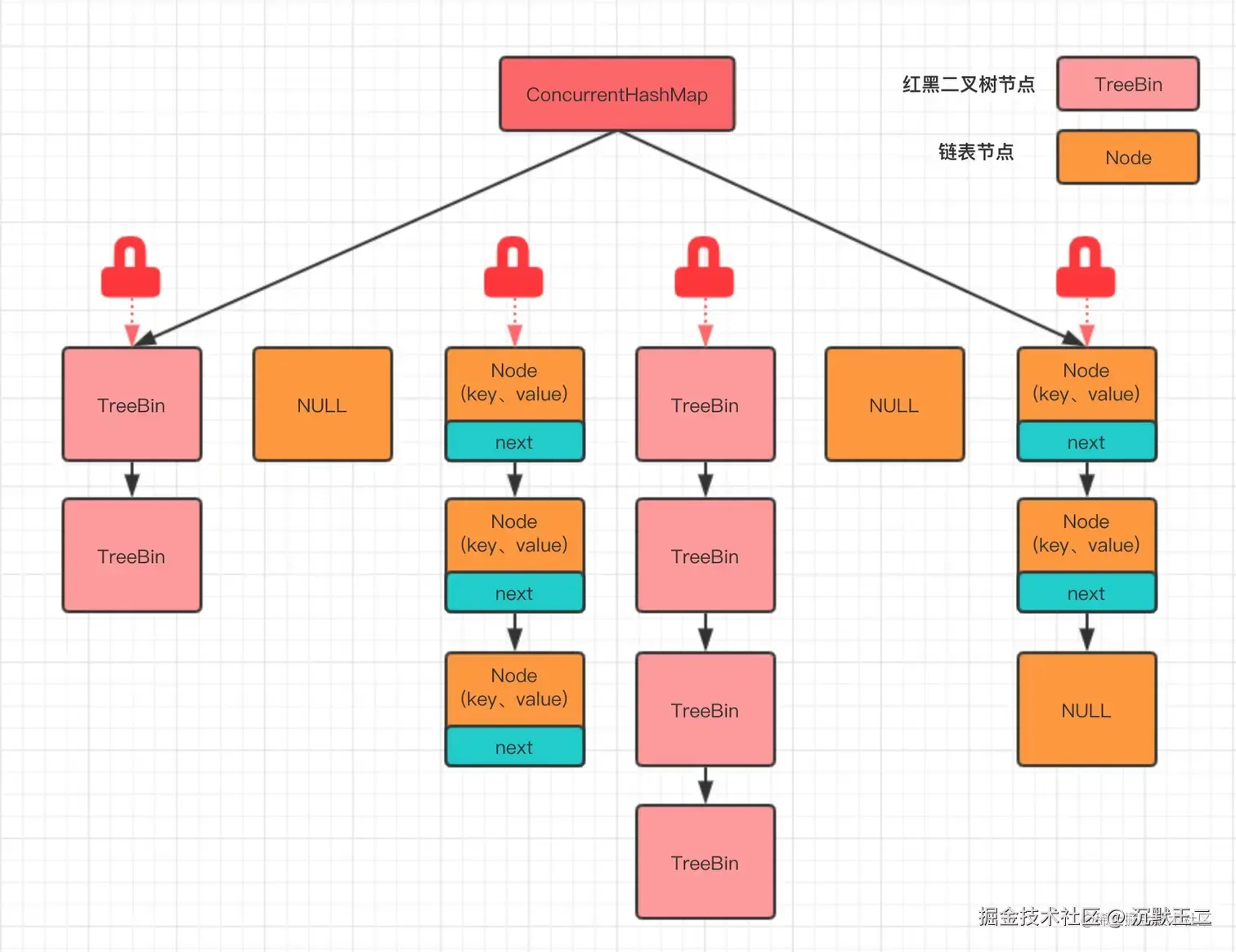
对于读操作,ConcurrentHashMap 使用了 volatile 变量来保证内存可见性。
对于写操作,ConcurrentHashMap 优先使用 CAS 尝试插入,如果成功就直接返回;否则使用 synchronized 代码块进行加锁处理。
ThreadLocal底层原理
当我们创建一个 ThreadLocal 对象并调用 set 方法时,其实是在当前线程中初始化了一个 ThreadLocalMap。
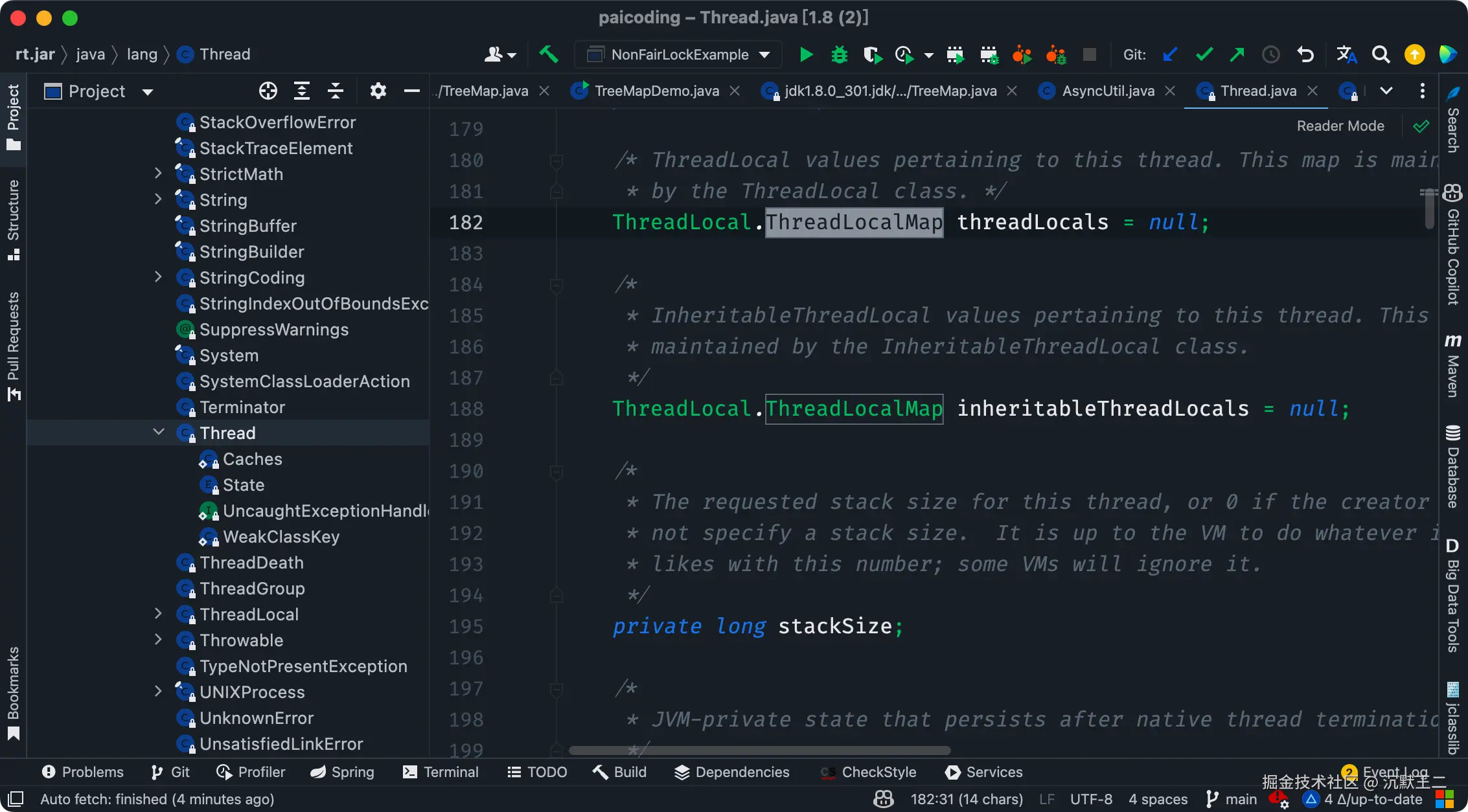
ThreadLocalMap 是 ThreadLocal 的一个静态内部类,它内部维护了一个 Entry 数组,key 是 ThreadLocal 对象,value 是线程的局部变量,这样就相当于为每个线程维护了一个变量副本。
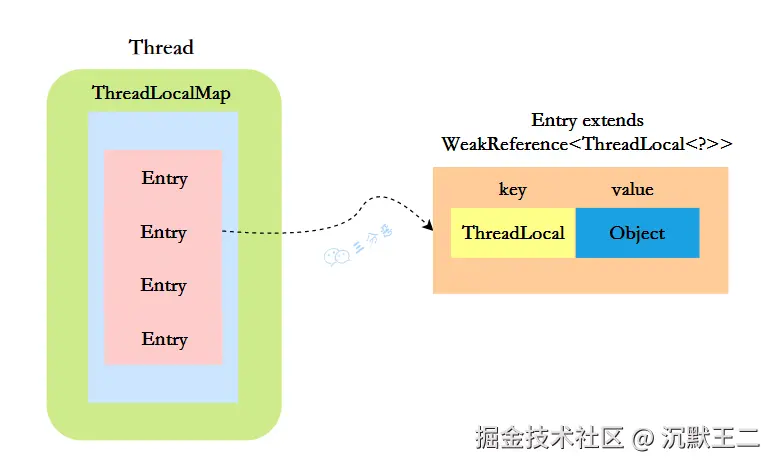
Entry 继承了 WeakReference,它限定了 key 是一个弱引用,弱引用的好处是当内存不足时,JVM 会回收 ThreadLocal 对象,并且将其对应的 Entry.value 设置为 null,这样可以在很大程度上避免内存泄漏。
简版回答:
ThreadLocal 的实现原理是,每个线程维护一个 Map,key 为 ThreadLocal 对象,value 为想要实现线程隔离的对象。
1、通过 ThreadLocal 的 set 方法将对象存入 Map 中。
2、通过 ThreadLocal 的 get 方法从 Map 中取出对象。
3、Map 的大小由 ThreadLocal 对象的多少决定。
讲讲自己熟悉的一个垃圾回收器,回收思想和具体工作流程
我比较熟悉的是 G1,它在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为默认的垃圾收集器。
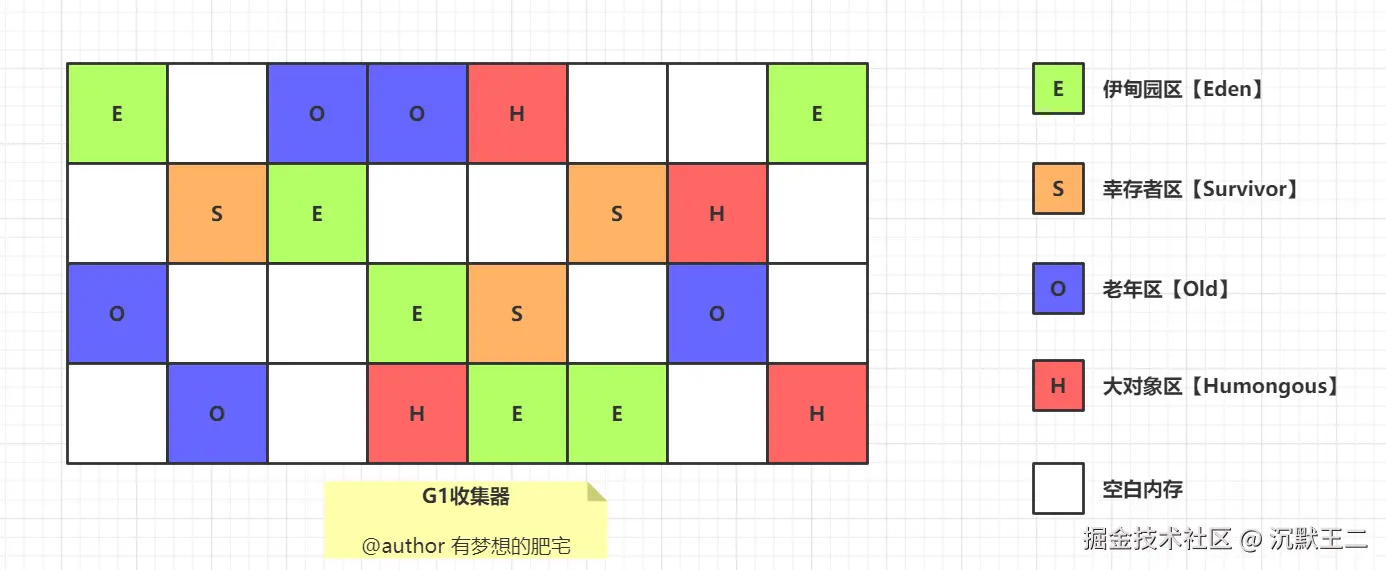
G1 把 Java 堆划分为多个大小相等的独立区域 Region,每个区域都可以扮演新生代或老年代的角色。
同时,G1 还有一个专门为大对象设计的 Region,叫 Humongous 区。
大对象的判定规则是,如果一个大对象超过了一个 Region 大小的 50%,比如每个 Region 是 2M,只要一个对象超过了 1M,就会被放入 Humongous 中。
这种区域化管理使得 G1 可以更灵活地进行垃圾收集,只回收部分区域而不是整个新生代或老年代。
G1 收集器的运行过程大致可划分为这几个步骤:
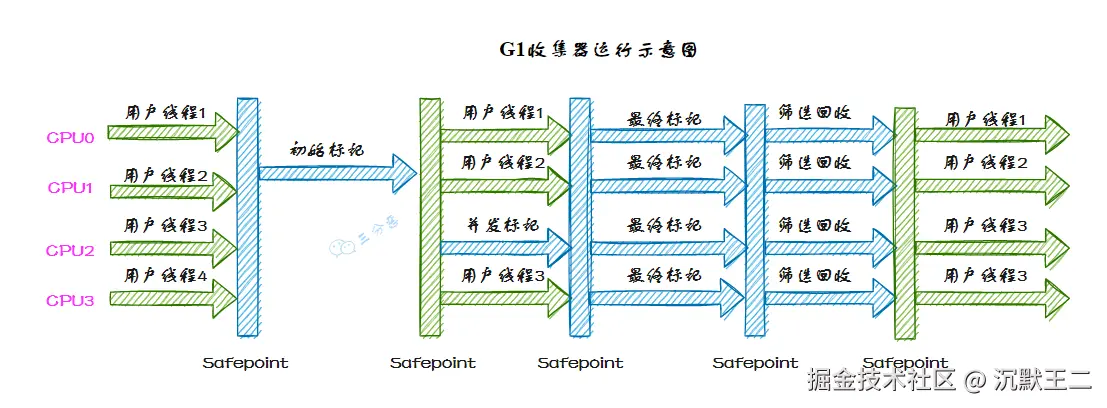
①、并发标记,G1 通过并发标记的方式找出堆中的垃圾对象。并发标记阶段与应用线程同时执行,不会导致应用线程暂停。
②、混合收集,在并发标记完成后,G1 会计算出哪些区域的回收价值最高(也就是包含最多垃圾的区域),然后优先回收这些区域。这种回收方式包括了部分新生代区域和老年代区域。
选择回收成本低而收益高的区域进行回收,可以提高回收效率和减少停顿时间。
③、可预测的停顿,G1 在垃圾回收期间仍然需要「Stop the World」。不过,G1 在停顿时间上添加了预测机制,用户可以 JVM 启动时指定期望停顿时间,G1 会尽可能地在这个时间内完成垃圾回收。
聚簇索引、覆盖索引?
聚簇索引的叶子节点存储了完整的数据行,数据和索引是在一起的。InnoDB 的主键索引就是聚簇索引,叶子节点不仅存储了主键值,还存储了其他列的值,因此按照主键进行查询的速度会非常快。
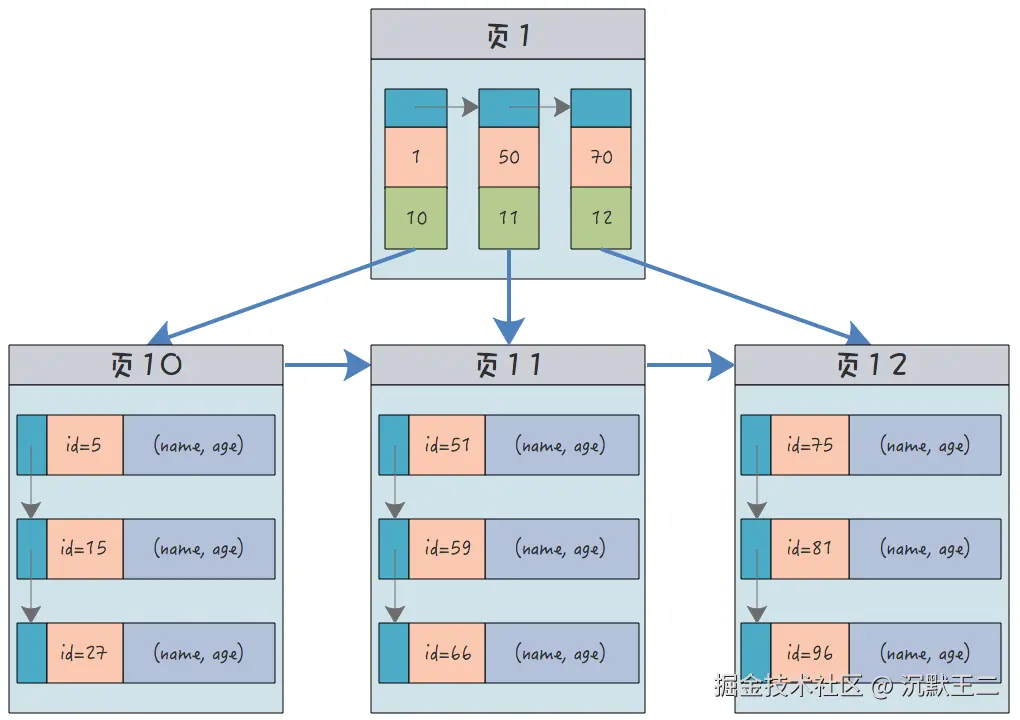
每个表只能有一个聚簇索引,通常由主键定义。如果没有显式指定主键,InnoDB 会隐式创建一个隐藏的主键索引 row_id。
覆盖索引指的是:查询所需的字段全部都在索引中,不需要回表,从索引页就能直接返回结果。
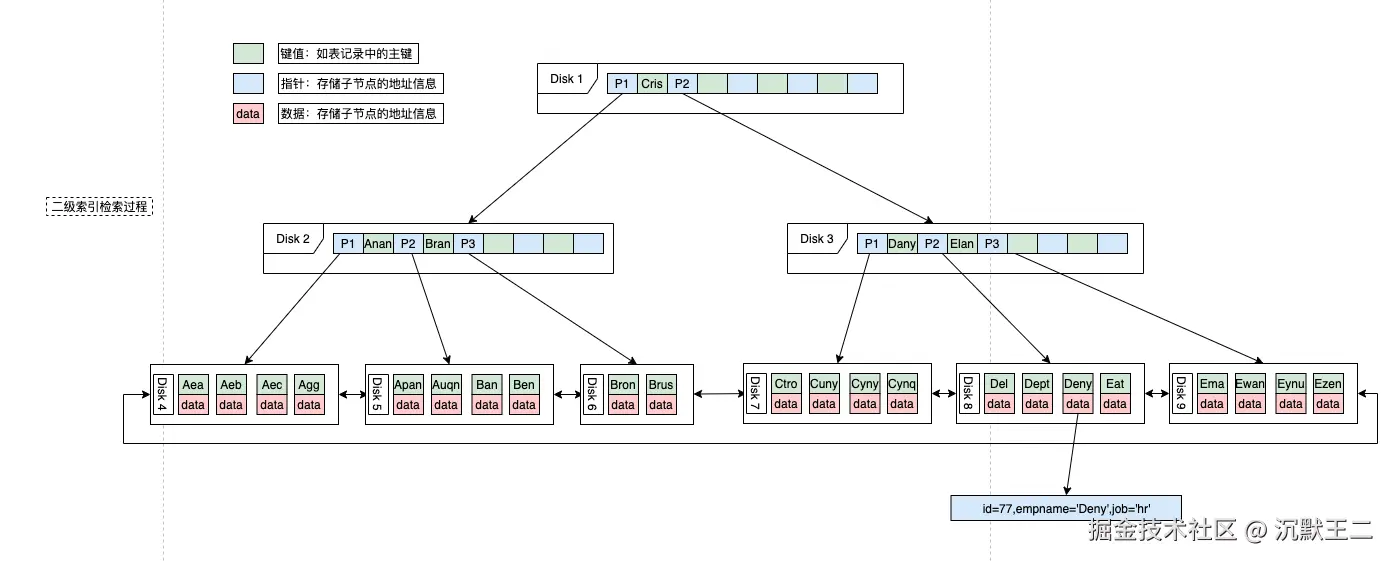
empname 和 job 两个字段是一个联合索引,而查询也恰好是这两个字段,这时候单次查询就可以达到目的,不需要回表。
可以将高频查询的字段(如 WHERE 条件和 SELECT 列)组合为联合索引,实现覆盖索引。
例如:
sql
CREATE INDEX idx_empname_job ON employee(empname, job);这样查询的时候就可以走索引:
sql
SELECT empname, job FROM employee WHERE empname = '王二' AND job = '程序员';普通索引只用于加速查询条件的匹配,而覆盖索引还能直接提供查询结果。
mysql的MVCC和两阶段提交怎么实现的
MVCC 指的是多版本并发控制,每次修改数据时,都会生成一个新的版本,而不是直接在原有数据上进行修改。并且每个事务只能看到在它开始之前已经提交的数据版本。
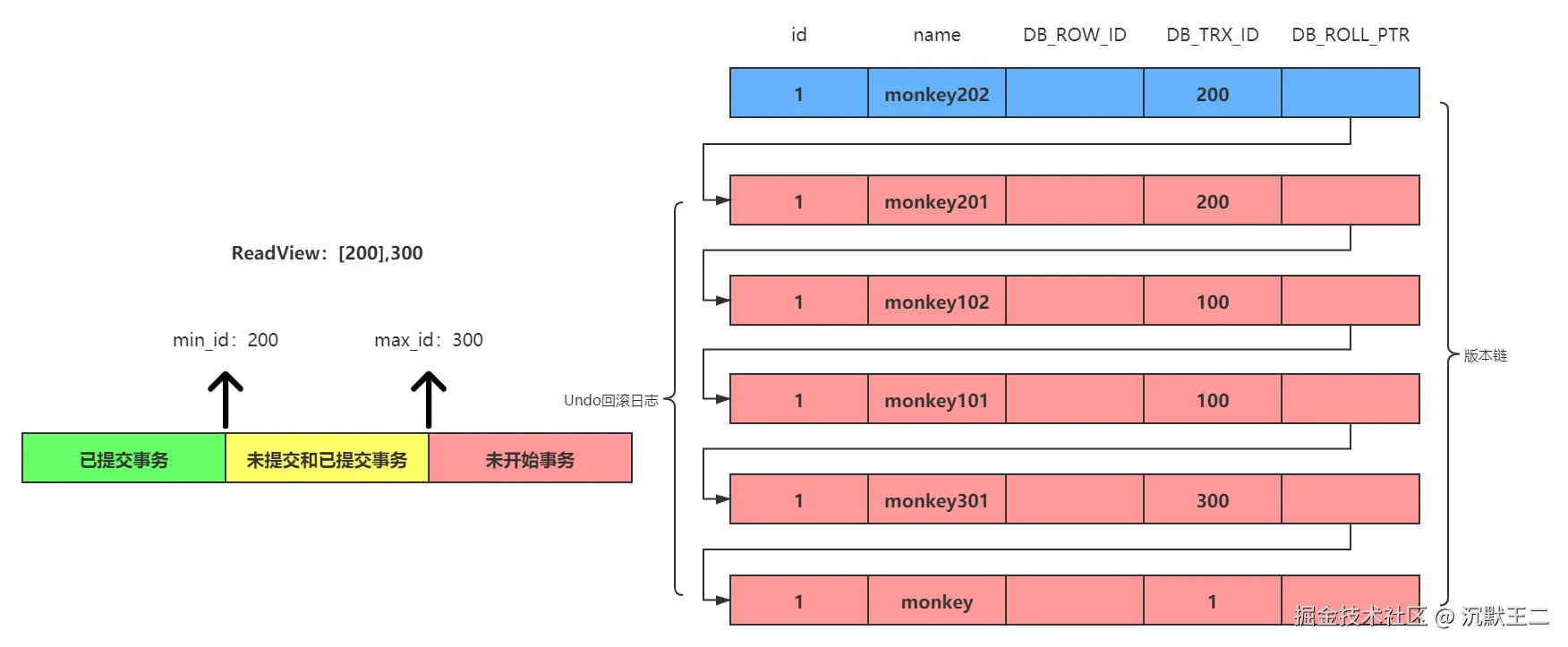
这样的话,读操作就不会阻塞写操作,写操作也不会阻塞读操作,从而避免加锁带来的性能损耗。
其底层实现主要依赖于 Undo Log 和 Read View。
每次修改数据前,先将记录拷贝到Undo Log,并且每条记录会包含三个隐藏列,DB_TRX_ID 用来记录修改该行的事务 ID,DB_ROLL_PTR 用来指向 Undo Log 中的前一个版本,DB_ROW_ID 用来唯一标识该行数据(仅无主键时生成)。
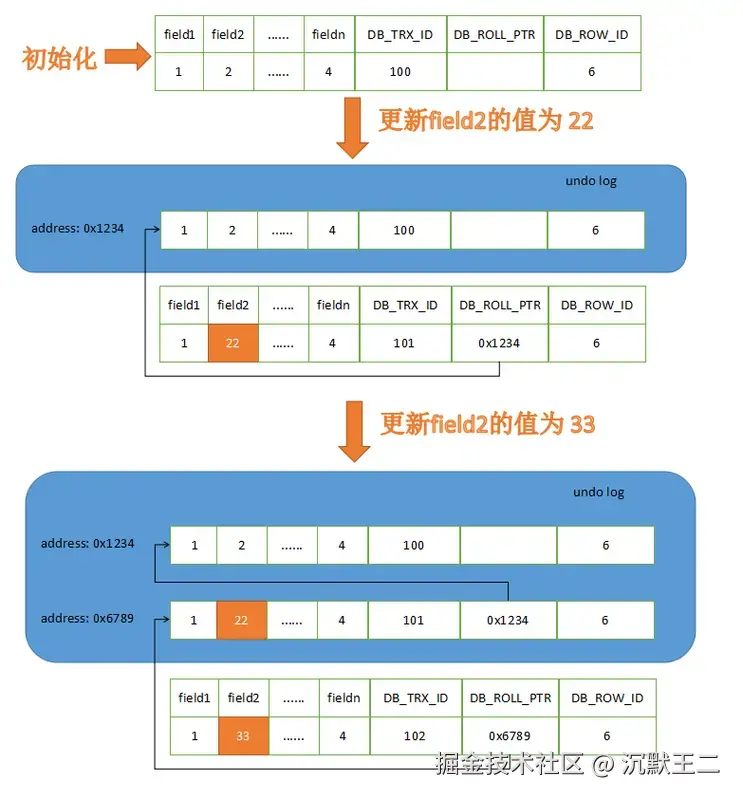
每次读取数据时,都会生成一个 ReadView,其中记录了当前活跃事务的 ID 集合、最小事务 ID、最大事务 ID 等信息,通过与 DB_TRX_ID 进行对比,判断当前事务是否可以看到该数据版本。
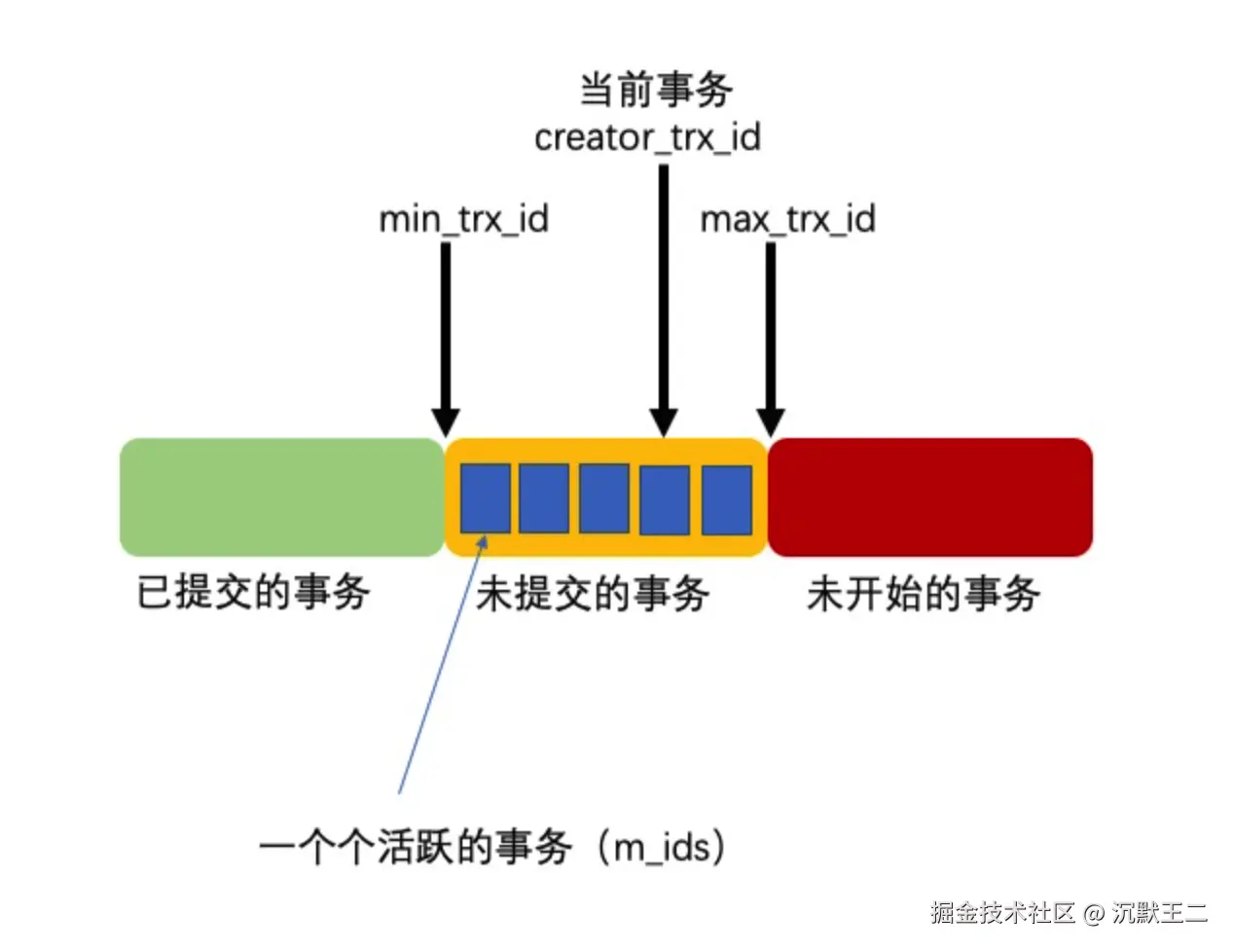
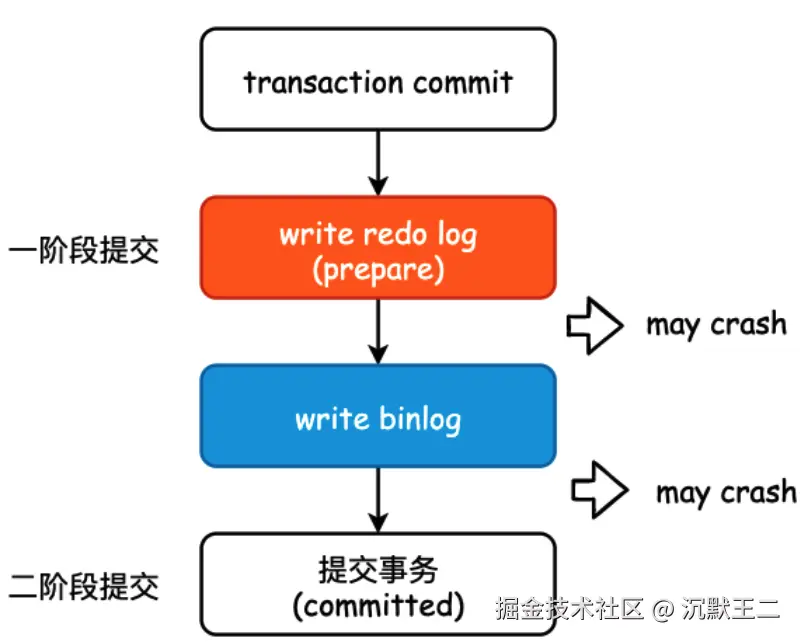
为保证两种日志的一致性,innodb 采用了两阶段提交策略,redo log 在事务执行过程中持续写入,并在事务提交前进入 prepare 状态;binlog 在事务提交的最后阶段写入,之后 redo log 会被标记为 commit 状态。
可以通过回放 binlog 实现数据同步或者恢复到指定时间点;redo log 用来确保事务提交后即使系统宕机,数据仍然可以通过重放 redo log 恢复。
java中的字节输入流和字节输出流用了什么设计模式?你对这种设计模式如何理解?
用到了------装饰器模式,装饰器模式的核心思想是在不改变原有对象结构的前提下,动态地给对象添加新的功能。
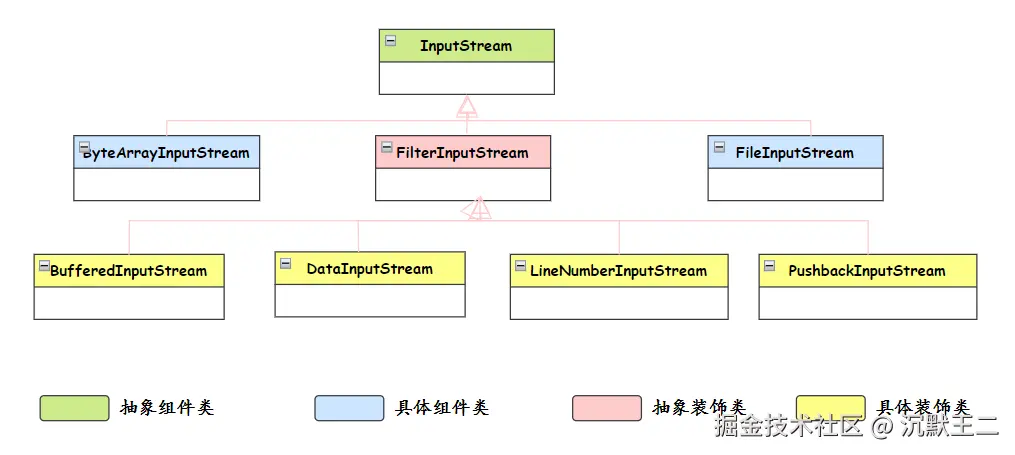
具体到 Java IO 中,InputStream 和 OutputStream 这些抽象类定义了基本的读写操作,然后通过各种装饰器类来增强功能。比如 BufferedInputStream 给基础的输入流增加了缓冲功能,DataInputStream 增加了读取基本数据类型的能力,它们都是对基础流的装饰和增强。
java
InputStream input = new BufferedInputStream(
new DataInputStream(
new FileInputStream("data.txt")
)
);这里 FileInputStream 提供基本的文件读取能力,DataInputStream 装饰它增加了数据类型转换功能,BufferedInputStream 再装饰它增加了缓冲功能。每一层装饰都在原有功能基础上增加新特性,而且可以灵活组合。
我对装饰器模式的理解是它很好地体现了"组合优于继承"的设计原则。优势在于运行时动态组合功能,而且遵循开闭原则,可以在不修改现有代码的情况下增加新功能。
讲讲spring的Bean的生命周期
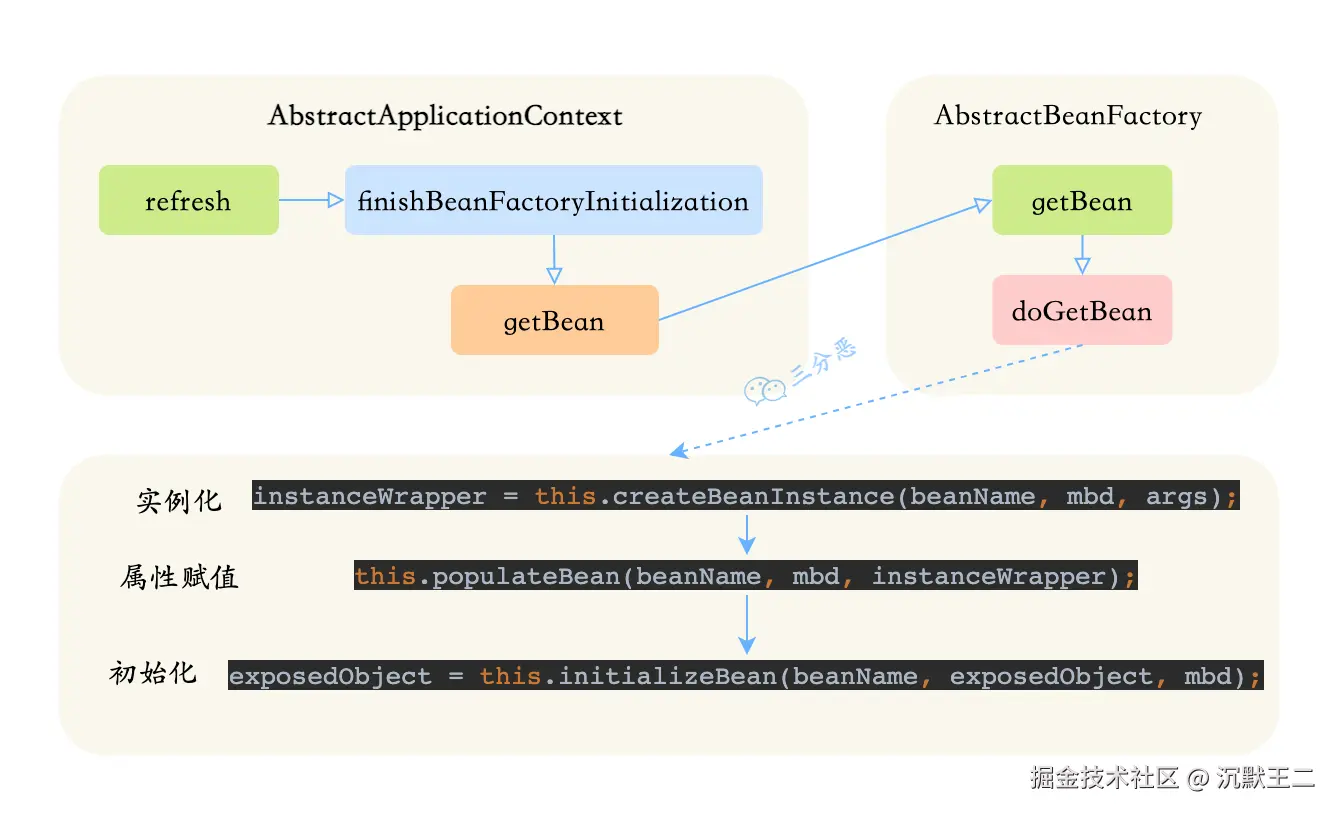
Bean 的生命周期可以分为 5 个主要阶段,我按照实际的执行顺序来说一下。
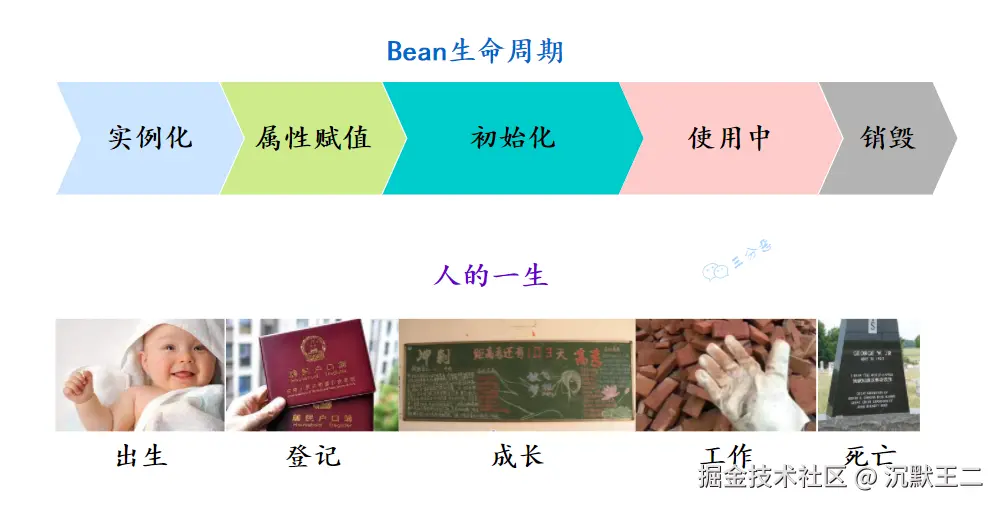
第一个阶段是实例化。Spring 容器会根据 BeanDefinition,通过反射调用 Bean 的构造方法创建对象实例。如果有多个构造方法,Spring 会根据依赖注入的规则选择合适的构造方法。
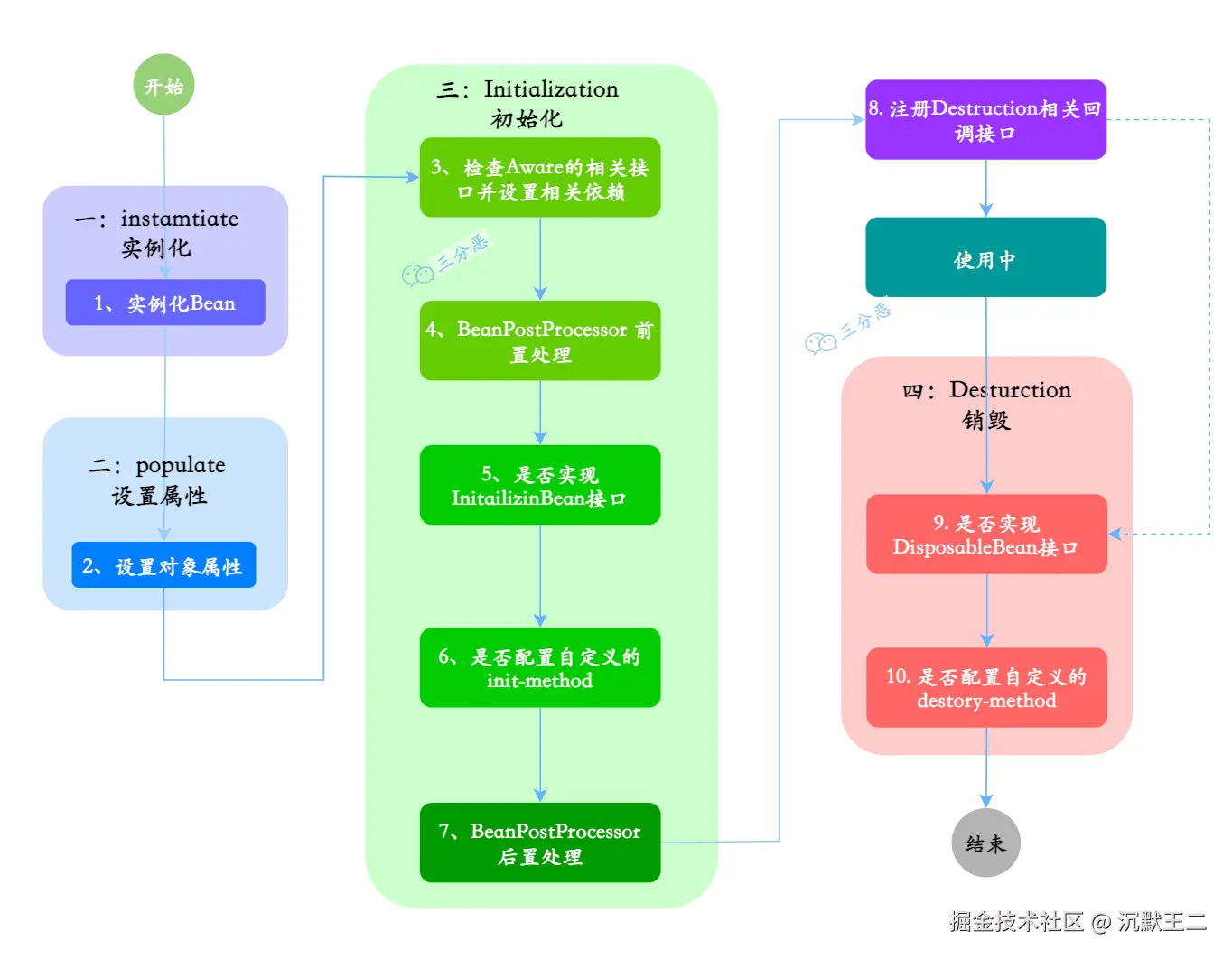
第二阶段是属性赋值。这个阶段 Spring 会给 Bean 的属性赋值,包括通过 @Autowired、@Resource 这些注解注入的依赖对象,以及通过 @Value 注入的配置值。
第三阶段是初始化。这个阶段会依次执行:
@PostConstruct标注的方法- InitializingBean 接口的 afterPropertiesSet 方法
- 通过
@Bean的 initMethod 指定的初始化方法
我在项目中经常用 @PostConstruct 来做一些初始化工作,比如缓存预加载、DB 配置等等。
java
// CategoryServiceImpl中的缓存初始化
@PostConstruct
public void init() {
categoryCaches = CacheBuilder.newBuilder().maximumSize(300).build(new CacheLoader<Long, CategoryDTO>() {
@Override
public CategoryDTO load(@NotNull Long categoryId) throws Exception {
CategoryDO category = categoryDao.getById(categoryId);
// ...
}
});
}
// DynamicConfigContainer中的配置初始化
@PostConstruct
public void init() {
cache = Maps.newHashMap();
bindBeansFromLocalCache("dbConfig", cache);
}初始化后,Spring 还会调用所有注册的 BeanPostProcessor 后置处理方法。这个阶段经常用来创建代理对象,比如 AOP 代理。
第五阶段是使用 Bean。比如我们的 Controller 调用 Service,Service 调用 DAO。
java
// UserController中的使用示例
@Autowired
private UserService userService;
@GetMapping("/users/{id}")
public UserDTO getUser(@PathVariable Long id) {
return userService.getUserById(id);
}
// UserService中的使用示例
@Autowired
private UserDao userDao;
public UserDTO getUserById(Long id) {
return userDao.getById(id);
}
// UserDao中的使用示例
@Autowired
private JdbcTemplate jdbcTemplate;
public UserDTO getById(Long id) {
String sql = "SELECT * FROM users WHERE id = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{id}, new UserRowMapper());
}最后是销毁阶段。当容器关闭或者 Bean 被移除的时候,会依次执行:
@PreDestroy标注的方法- DisposableBean 接口的 destroy 方法
- 通过
@Bean的 destroyMethod 指定的销毁方法
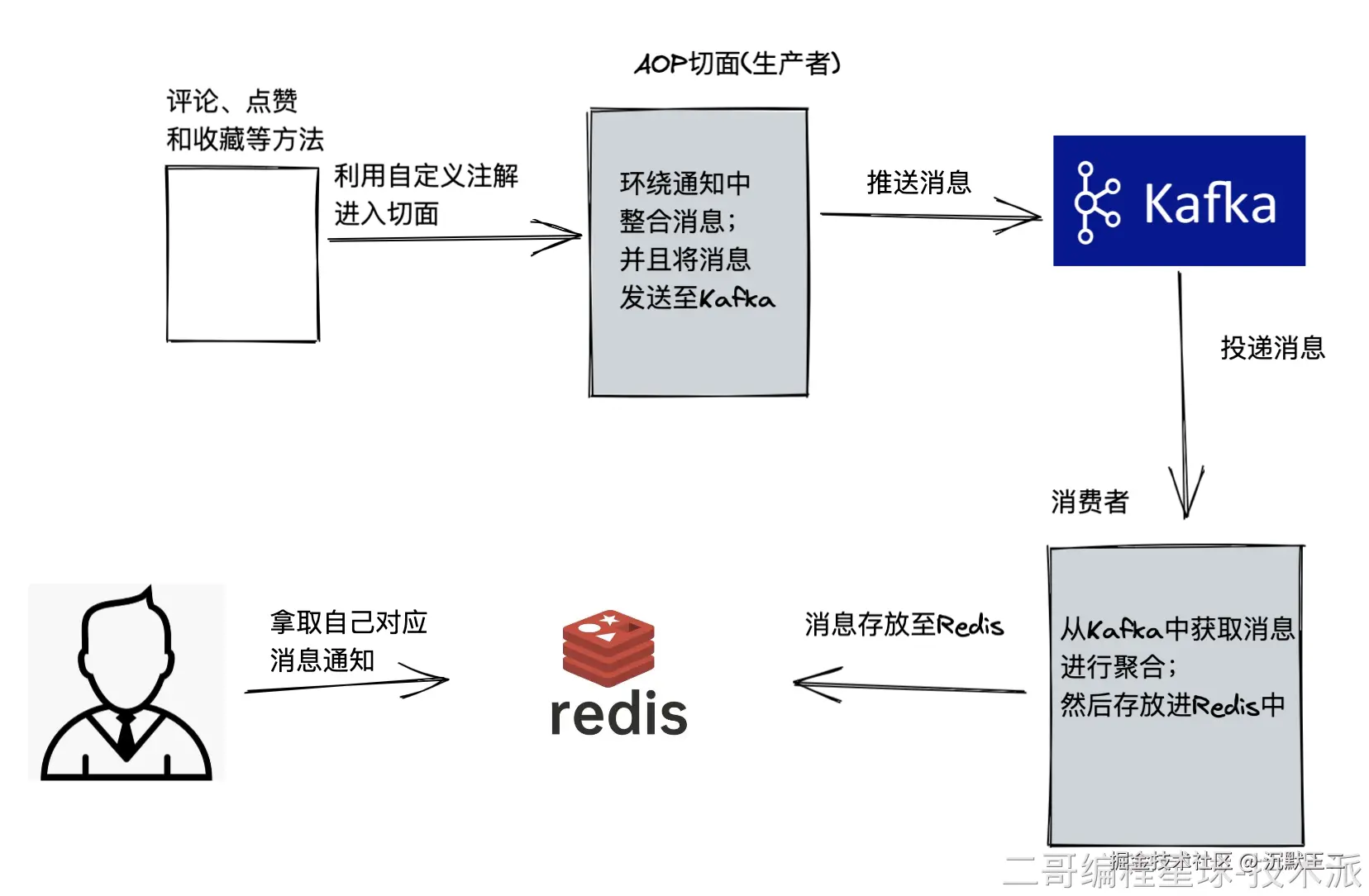
项目中为什么用两种消息队列?(rabbitMq和Kafka)出于什么样的考虑?
在技术派项目中,我们根据业务特点选择了不同的消息队列。RabbitMQ 主要用于处理用户互动相关的实时消息,比如点赞、评论、收藏等操作;用 Kafka 主要是因为很多企业级的项目会用到,所以我就想提前了解和使用,和企业的真实开发接轨。
布隆过滤器的底层数据结构是什么?主要用来解决什么问题?
布隆过滤器是一种空间效率极高的概率性数据结构,用于快速判断一个元素是否在一个集合中。它的特点是能够以极小的内存消耗,判断一个元素"一定不在集合中"或"可能在集合中",常用来解决 Redis 缓存穿透的问题。
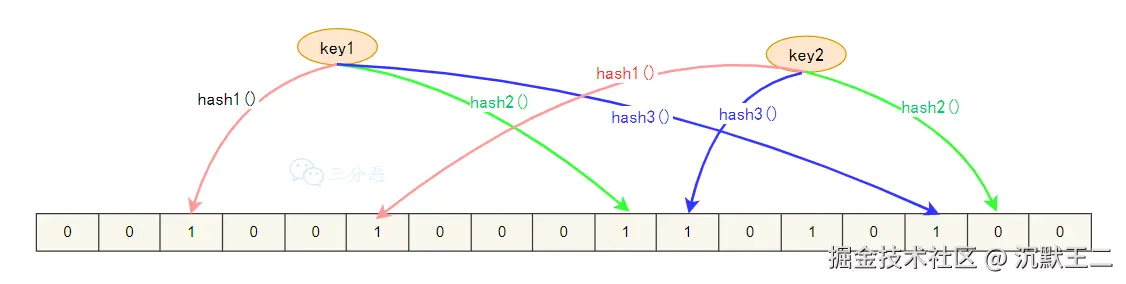
布隆过滤器的核心由一个很长的二进制向量和一系列哈希函数组成。
- 初始化的时候,创建一个长度为 m 的位数组,初始值全为 0,同时选择 k 个不同的哈希函数
- 当添加一个元素时,用 k 个哈希函数计算出 k 个哈希值,然后对 m 取模,得到 k 个位置,将这些位置的二进制位都设为 1
- 当需要判断一个元素是否在集合中时,同样用 k 个哈希函数计算出 k 个位置,如果这些位置的二进制位有任何一个为 0,该元素一定不在集合中;如果全部为 1,则该元素可能在集合中