在实时竞价(RTB)广告系统中,广告出价模块作为连接广告主需求与流量匹配的核心枢纽,需要将广告主的营销目标(如转化率、ROI)转化为动态竞价决策。作为竞价机制的中枢神经,广告出价不仅直接影响广告主的投放效果,也是广告排序分的关键组成模块,进而影响平台侧的流量分配效率。
广告出价的面临的核心挑战可以概括为以下三点:
-
既要花钱,又要省着花:广告主既需控制单日花费不超预算,又需尽可能降低每次转化(如购买、下载等)的成本。
-
未来难以预测:系统无法预知即将到来的流量状况和竞争对手行为,必须依据实时花费与成本等数据动态调整出价。
-
牵一发而动全身:每次出价会影响广告展示与消耗,改变账户状态(如剩余预算),进而影响后续出价,构成连续而复杂的序列决策问题。
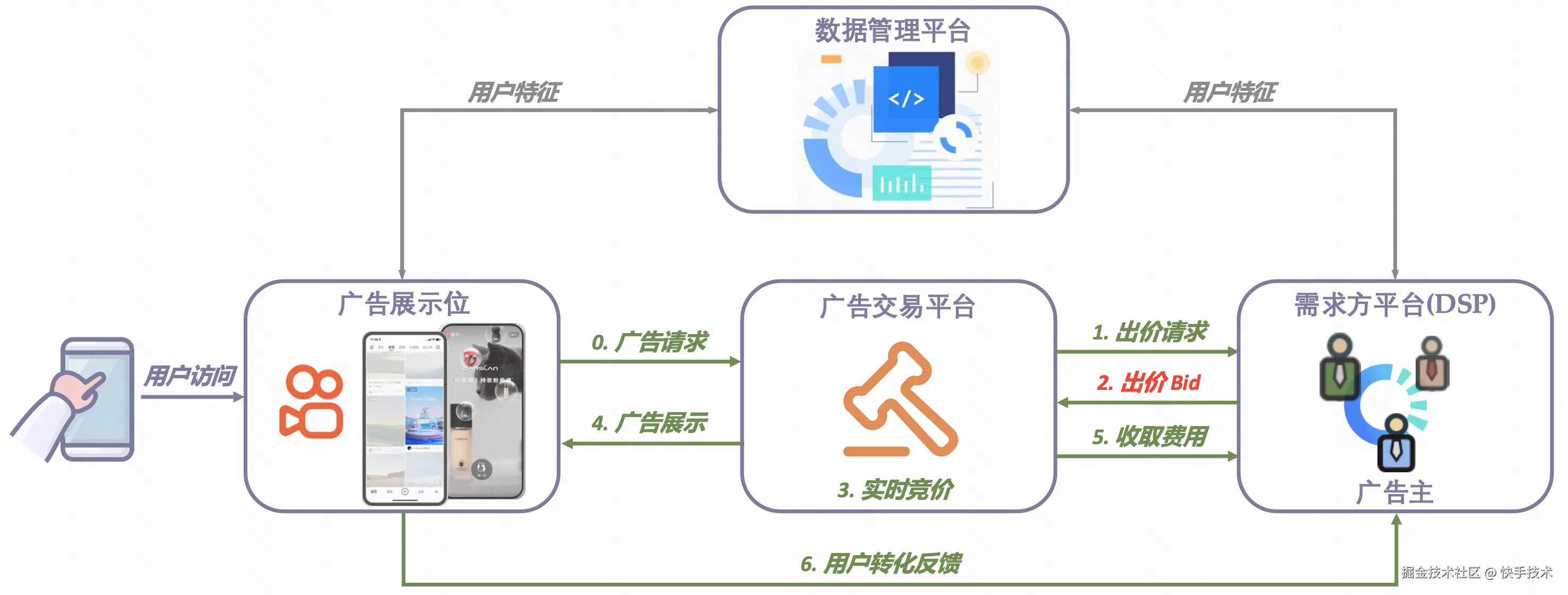
图 1:实时出价系统示意图
快手的出价算法经历了从 PID、MPC 到强化学习(RL)的三代演进。若将这一过程比喻为汽车工业的发展:
- 第一代(PID):类似于定速巡航。它只能根据当前速度和设定速度的差异来调整油门,反应直接但比较"笨",难以应对复杂多变的竞价环境。
- 第二代(MPC):类似于更高级的适应巡航。 通过预测未来短时间内的路况以调整车速,但其建模相对简单,易陷入局部最优,本质上难以实现效果的根本性突破。
- 第三代(强化学习):如同根据专家驾驶数据学习的 AI 驾驶员。通过分析海量历史驾驶数据(离线数据集),学习在特定状态下的最佳动作(出价),以最大化全程奖励(广告效果)。该方法安全性高(不直接影响线上业务),且能够挖掘数据中蕴藏的更优策略。
2025 年至今,快手将生成式强化学习出价技术全面落地在广告系统,为平台实现了超过 3% 的广告收入提升。
一、新一代出价技术:生成式强化学习出价
既然强化学习已奠定了良好基础,为何还需引入"生成式"方法?
现有的强化学习技术有点像 "一维思考",只根据单步状态信息进行决策,对于出价状态序列信息利用不够充分。而生成模型(如 Transformer, Diffusion)特别擅长理解和生成有复杂模式的序列数据。然而,生成模型本质是模仿数据集的动作,高度依赖数据集质量,难以优化序列整体价值;而强化学习能够学到超出数据集效果的策略,直接优化序列整体价值,在原理上相比生成模型具有更高的收益空间。
快手将这两种技术融合,创新性提出了"生成式强化学习",让出价模型能 "多维思考" 。更充分地利用历史出价序列信息,从而做出更精准的决策。生成式强化学习有两个大方向:
- Generative Model as a world model: 建立一个可以模拟不同出价策略下广告投放结果的"数字沙盒",生成大量训练数据来增强模型学习。
- Generative Models as policies: 用生成模型直接建模强化出价策略,提升对于出价状态序列信息的利用能力。
Generative Models as policies 主要包括两类方法:Decision Transformer(DT)与 Diffusion Model。
-
DT 应用于出价策略(如图 1):其机制类似于大语言模型中的"下一词预测"(Next Token Prediction)。模型依据历史状态、调价动作与奖励序列,预测能够最大化序列整体价值的最佳出价动作。可类比为让模型学习大量优质出价案例,进而根据当前上下文推断出最合理的后续动作。
-
Diffusion Model 的应用机制:在推理阶段,模型以状态-动作-奖励为条件进行去噪,通过扩散过程生成未来状态序列(Next Trajectory Prediction),再结合历史状态反推当前最优出价(Next Bid Prediction)。这一过程犹如一位"AI 画家"------基于已有状态从噪声中勾勒出理想的未来轨迹(如预期消耗、成本曲线),再逆向推导当前应当执行的出价。
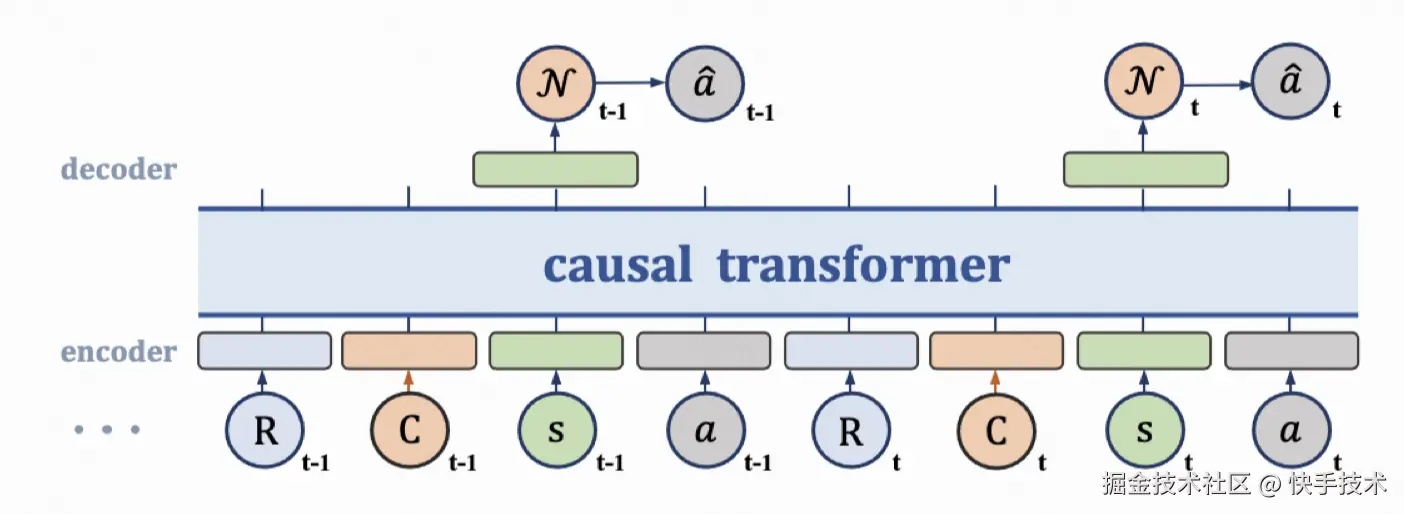
图 2:Decision Transformer 架构
然而,利用生成模型直接建模出价策略仍面临两大挑战:
1)依赖高质量数据集:简单探索会遇到 OOD(Out of Distribution)问题,需设计高效的离线探索机制。
2)和优化目标难以对齐:生成模型原理上难以最大化序列整体收益(优化目标),因而存在和优化目标难以对齐的问题。
针对挑战一,快手提出 GAVE 算法,结合强化学习中的价值函数引导模型在离线训练时更有效地探索。该方案也是 NeurIPS 2024 Competition: Auto-Bidding in Large-Scale Auctions 比赛的冠军方案。针对挑战二,快手提出 CBD 算法,首先预估一个 trajectory-level 奖励模型作为 aligner,然后在推理阶段利用 aligner 修改生成的轨迹,从而实现和优化目标对齐。
下文将围绕生成模型在出价任务中面临的上述两个核心挑战,详细介绍 GAVE 与 CBD 算法的技术细节.
二、依赖高质量数据集挑战:GAVE 出价算法
如前文所述,DT 能够有效建模序列信息,弥补了离线强化学习在序列信息利用方面的不足。然而,将其直接应用于广告出价仍存在两个关键挑战:
- 其一:出价存在转化、成本多个目标,如何能让 DT 架构更好地适配广告多个投放目标;
- 其二:DT 的学习原理是模仿数据集的出价动作,其效果受限于数据集质量。
为解决上述问题,需引入高效且稳定的探索机制以增强模型探索能力。针对第一个挑战,快手商业化算法团队提出 Score-based RTG(Return to Go)模块,以灵活适配多种广告投放目标;针对第二个挑战,我们提出基于价值函数的动作探索机制,通过学习最优价值函数,引导模型探索出最优 action,避免 OOD(Out of Distribution)问题,有效提升模型学习效果。
GAVE 算法创新性融合了 Score-based RTG 与基于价值函数的动作探索机制,其整体结构如图 3 所示。
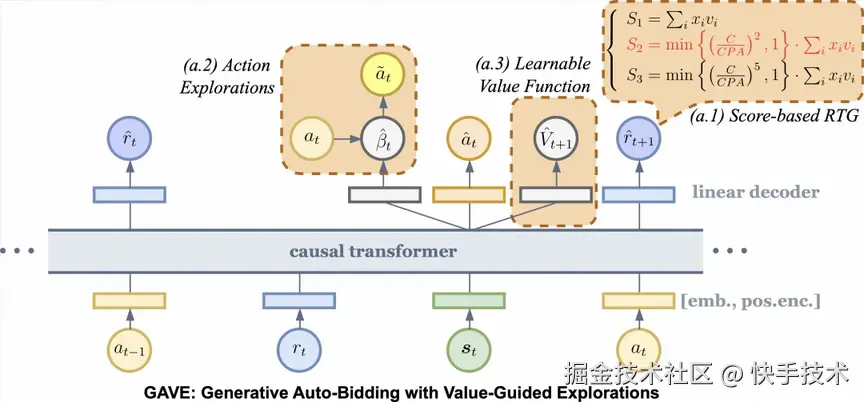
图 3: GAVE 算法架构图
2.1 Score-based RTG
DT 直接用于出价通常只能适配转化目标,而无法考虑成本率的约束。快手商业化算法团队提出 Score-based RTG,把当前时刻到序列结尾的成本率约束加到每个时刻 t,使得 RTG 对齐最终评估指标(带惩罚的总转化)。通过灵活调整得分函数参数,框架可适配 CPA、ROI 等不同广告场景需求,以实现目标导向的出价生成决策。
2.2 基于价值函数的动作探索机制
为了解决生成模型依赖高质量数据集的挑战。快手提出一种基于价值函数的动作探索机制,包含括动作探索模块(Action Explorations)以及可学习价值函数模块(Learnable Value Function)。
- 动作探索模块: 首先生成探索动作,然后预估原动作和探索动作的长期价值,最后让模型的预测动作更多地向原始动作和探索动作中价值最大的那个动作进行更新。
- 可学习价值函数模块:首先借鉴 IQL 算法的期望回归损失,预估当前序列下未来回报(RTG)的上界,形成探索动作的价值参考锚点;然后使扰动动作的 RTG 向预测的最优价值更新,这有效地避免无效或者危险的探索。
2.3 实验效果
离线实验
我们在 AuctionNet 公开出价数据集上测试 GAVE 以及基线算法性能。如表 1 显示,GAVE 在不同预算设置与数据条件下均取得最优效果,其相对于 DT 的显著提升验证了基于价值函数的动作探索机制的有效性。消融实验(图 3)进一步证明了 Score-based RTG 模块与动作探索机制的必要性。
表 1: 离线对比
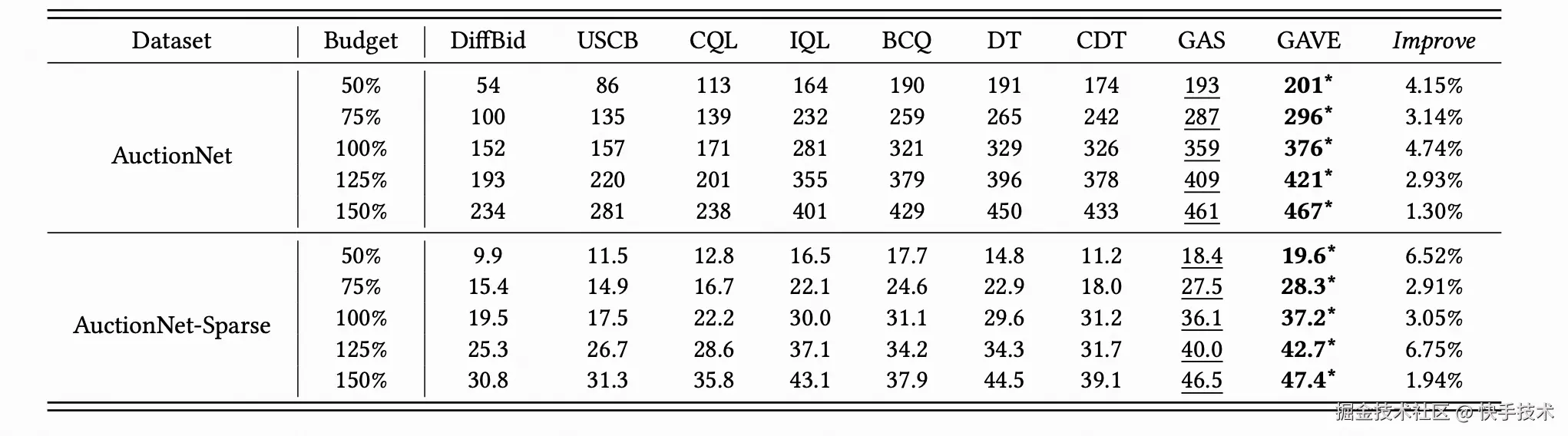
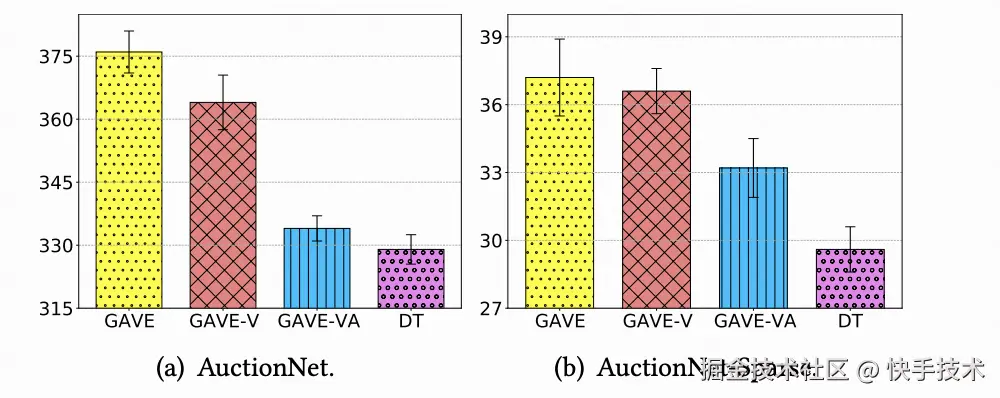
图 3: 消融实验
在线实验
为验证实际效果,我们在大型广告系统中进行了线上 A/B 测试。实验表明,在 Nobid(预算约束下最大化转化)和 Costcap(CPA 约束下优化转化)两种场景中,GAVE 均显著优于基线:Costcap 场景:消耗提升 2.0%,预期消耗提升 2.2%,CPA 达标率提升 1.9%;Nobid 场景:消耗提升 0.8%,预期消耗提升 3.2%。结果验证了 GAVE 在真实广告竞价环境中的有效性与实用性。
三、和优化目标难以对齐挑战:CBD 出价算法
基于的 DT 出价技术采用动态规划的方式逐步输出单个动作,以间接实现 trajectory stitching 这一目标。然而,这种方式可能导致误差的累积,缺乏长程规划能力,且可解释性较差。相比之下,Diffuser 方法采用扩散模型生成未来轨迹,再通过逆动力模型推理决策动作,不仅长程规划能力更强,还能清晰地理解"模型的决策意图"。此外,广告的转化往往稀疏的,因此基于此设置的单步奖励信号也非常稀疏,限制了 DT 在广告场景中的应用。Diffuser 通过将多步累积奖励作为条件输入,建立其与生成轨迹之间的映射关系,有效缓解了奖励稀疏性问题,从而有望突破 DT 的性能瓶颈。
若直接将 Diffuser 应用于广告出价,在推理时需在每个调价步 t 生成整条状态轨迹{s_0,...,s_t,...,s_T},然后根据生成的未来状态序列{s_{t+1},...,s_T}和真实观测的状态序列 jishu 推演出此时的出价。但由于竞价环境的动态性,真实观测状态序列和生成的未来状态序列往往存在不一致,导致两个突出问题(如图 4 所示):
-
一是生成状态序列合法性问题:例如生成的剩余预算可能违反物理规律(如不降反增)
-
二是难以和偏好对齐的问题:即生成出价状态序列偏离优化目标

图 4: 生成状态序列一致性问题和偏好不对齐问题
3.1 CBD 出价算法详解
为促使基于扩散模型的生成式强化学习出价模型与优化目标更好对齐,CBD (C ausal Auto-B idding via Diffusion Completer-Aligner) 算法创新性地引入了 Completer 和 Aligner 两个模块(结构如图 5 所示)。Completer 基于历史观测序列扩散补全未来序列,Aligner 则对生成序列进行偏好对齐,从而实现离在线环境下的性能提升与稳定部署。
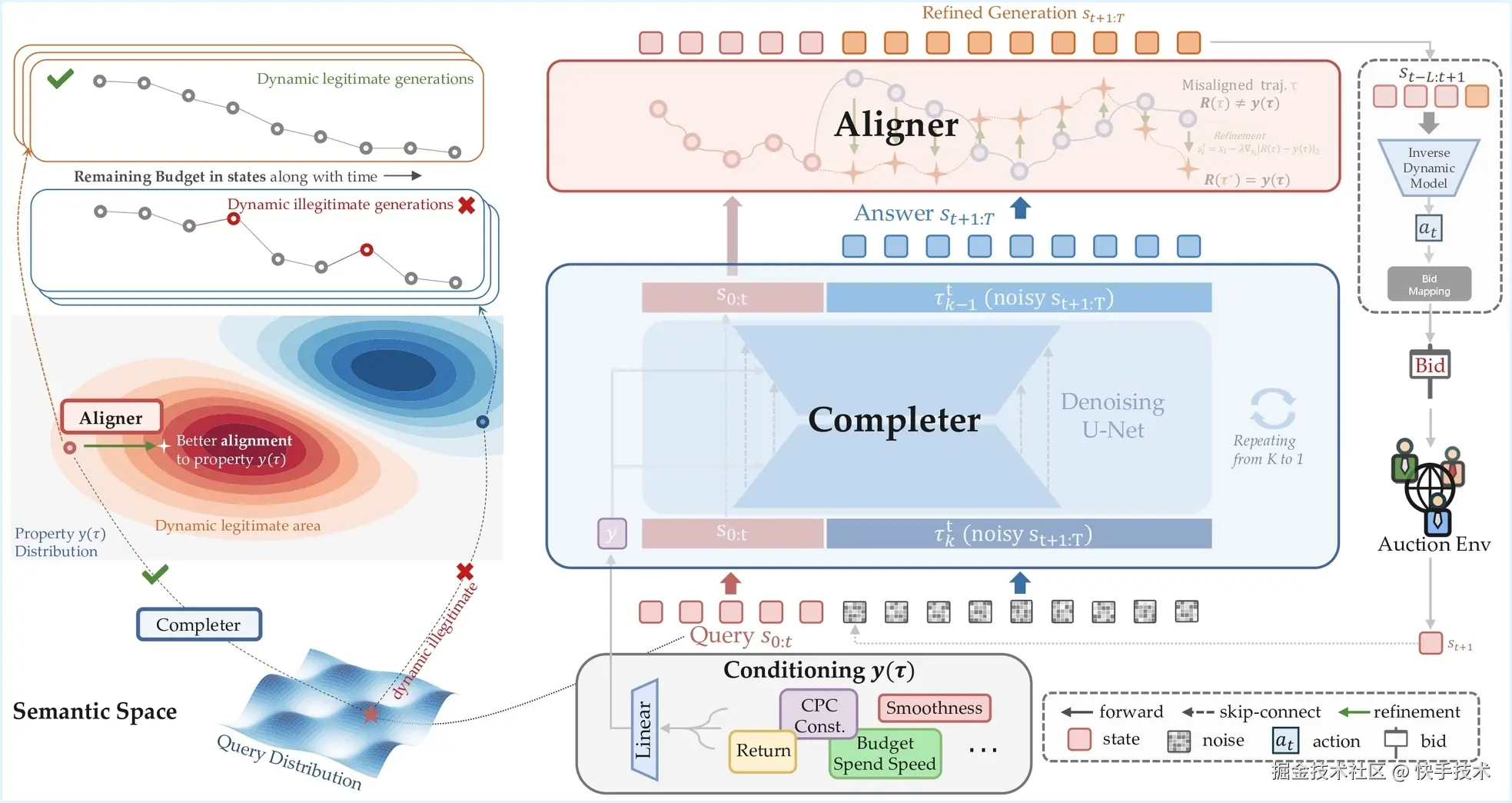
图 5: CBD 算法架构图
1)扩散补全 Completer:训练中的补全学习
我们引入新的随机变量决策步 t 对训练过程进行增强,训练目标定义为:
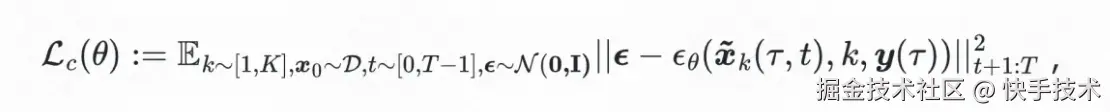
此时,扩散模型的输入与决策步 t 相关,与推理设定保持完全一致。具体操作中,我们随机采样一个时间步 t,将真实历史出价状态序列 s_{t-H:t}与剩余位置上填充的 padding noise 拼接,作为 Completer 的输入以生成未来状态。损失函数仅针对生成轨迹中 𝑡+1:𝑇 的部分进行计算。因此,Completer 能够基于随机长度的观测序列,补全生成未来未观测段,是一个具备"补全"能力的扩散模型。
2)偏好对齐 Aligner: 推理中的生成优化
我们引入基于轨迹奖励模型 R(x) 的 aligner 模块用于偏好对齐。 该奖励模型能够预估完整生成轨迹的累积奖励,在此基础上我们可以对生成的序列做修改,使得更新之后的轨迹更接近期待的优化目标 y, 其修改方式可基于梯度更新,操作如下
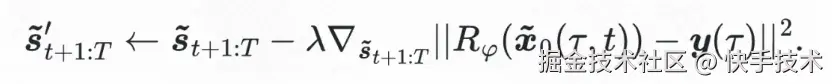
经由 Aligner 对齐得到最终的未来轨迹,与历史序列一并输入至逆动力模型,反推得到待执行的出价动作。
3.2 实验效果
离线实验
我们在 AuctionNet 公开出价数据集上测试 CBD 以及基线算法性能(包括离线强化学习和 DT 等生成模型方法)。表 2 展示了不同预算及奖励稀疏程度下,各算法所竞得的总转化价值(Value)。实验结果表明,CBD 算法显著优于其他方法。同时,生成轨迹的可视化结果(图 4)显示,CBD 能有效缓解 Diffuser 直接应用时出现的问题。表 3 中的消融实验进一步验证了扩散模型结构的有效性以及 Completer--Aligner 框架的必要性。
表 2:离线对比不同方法竞得的总转化 Value
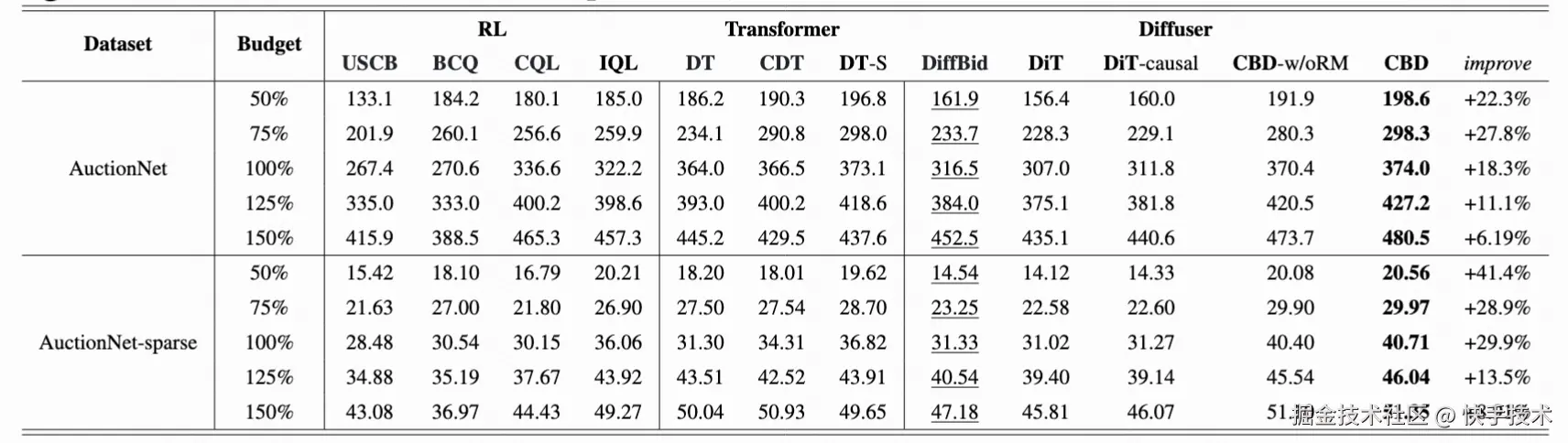
表 3: 消融实验

在线实验
我们在大型广告系统中进行了线上 A/B 测试,对比了 CBD 与 GAVE 在计算效率和性能方面的表现。实验表明,在相同计算资源下,CBD 仅增加 6 毫秒推理耗时,但在效果上显著优于 GAVE:在消耗持平的情况下,实现了 2.0%的预期消耗提升。该结果验证了 CBD 在严格业务约束下的有效性,为动态竞价环境提供了一种性能更强的生成式出价方法。
四、成果多次亮相顶会
作为快手核心算法部门,商业化算法团队支持快手国内与海外多场景的广告变现算法研发,持续构建业界领先的智能广告系统,以算法驱动商业增长,并不断优化用户体验和客户效果。团队深耕实际业务需求,多项研究成果已在 KDD、ICLR、ICML、NeurIPS 等国际顶级会议上发表,并先后斩获 CIKM Best Paper、SIGIR Best Paper 提名奖、钱伟长中文信息处理科学技术奖一等奖等荣誉。
2024 年,团队在 NeurIPS 大规模广告自动出价竞赛中斩获双赛道冠军,充分体现了其在人工智能领域的核心实力。2025 年,团队首次提出并全面落地生成式强化学习出价技术,通过有机融合生成模型与强化学习,显著提升快手广告收入。其所研发的 GAVE、CBD 等出价算法已成为该领域的 SOTA 算法,受到业界的广泛关注与应用参考。

五、未来展望
展望未来,出价技术仍存在两大重要演进方向:一是出价基座大模型,依托多场景、多目标的出价历史序列数据,基于 DT 或 Diffusion 架构训练通用基础出价模型,充分发挥数据与算力的规模效应;二是出价推理大模型,引入大语言模型的复杂推理机制,增强出价模型的可解释性与决策思维能力,推动自动出价向更高智能层次迈进。
更多信息可查看论文:
论文名称:Generative Auto-Bidding with Value-Guided Explorations
论文名称:Generative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner