一、背景
评价作为商品中几乎最为重要的一环,很多时候商品的评价在很大程度上决定了用户是否会下单这个商品。
但是用户决策时通常不会浏览全量评论(单商品评论量可能达数千甚至数万条),评论排序直接决定用户可见内容,而我们要做的就是需要给用户呈现最能促成下单的评价。
我们业务目前处于策略探索期:为了提升用户下单率,评论排序规则需频繁迭代(已迭代只第五个版本)。但现有技术实现排序策略使用硬编码方式,将排序策略写死在应用系统中,导致策略变更效率极低,无法适配业务快速试错需求。
二、现状及思考
2.1 现状
当前历史版本以及新版本下每次评论排序策略的主要排序因子和排序顺序:
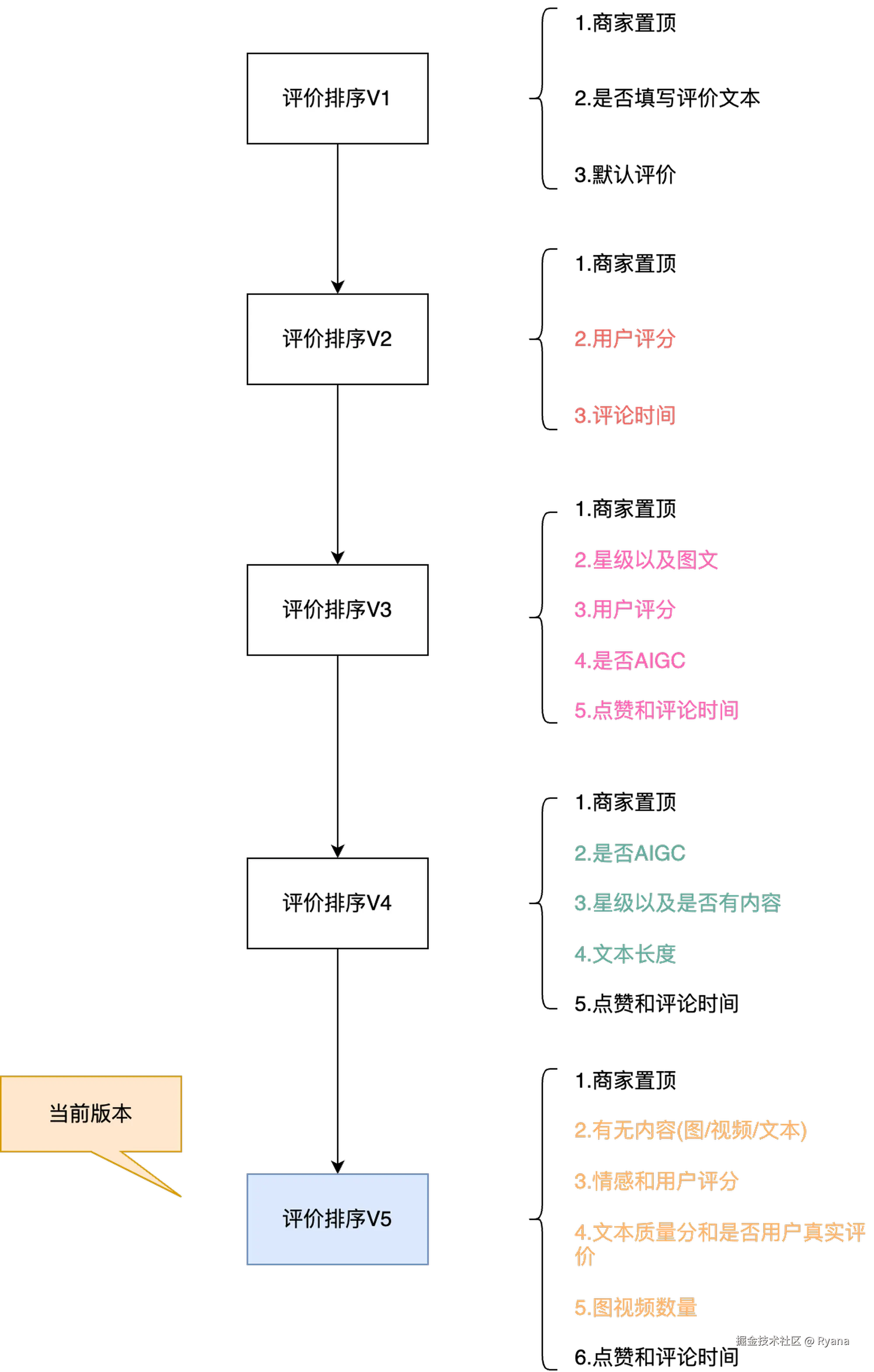
目前评价透出的排序已经做到了第5个版本,而且后续还有很大的概率会去进行迭代,并且每一版的逻辑都比较复杂,每一个版本的排序规则都会有很大变动,每个排序规则都是通过硬编码的方式实现。此外,用户查看评论的时候还有可能是实时计算评论的排序,QPS过高系统可能会对系统压力很大。
其中某一个版本的规则示例如下:

因此目前来看,如果再按照之前的方式迭代下去会存在几个问题:
- 排序的规则极为复杂且拓展性差。每次评价对于配置规则都需要硬编码,需要从一个较为抽象的逻辑,转化为一个较为具体的编码。若未来需加入新的排序因子(如 "用户购买品类相关性"),硬编码需大幅修改核心逻辑,甚至重构排序模块。
- 维护成本高,策略逻辑与业务代码耦合,任何改动都需要重新上线。 排序策略嵌入系统核心代码,维护成本高。如果在上线后需要对其中一条规则进行调整,都需要进行修改代码、测试、部署上线不足,时间陈宝国和人力成本高。
- 性能较差。 每次用户查询评论时都需要先查出缓存中全量的评论,然后再通过编码计算分数,再进行排序过滤等等。
2.2 调研
那么我们通过两个方向调研业界上现有的排序规则方案:
- 一是调研业界现有的评价排序策略都有哪些策略因子。最好能够做到第一次上线就将后续可能会用到的排序因子全部纳入到排序系统中,防止后续还需要改代码从评论实体中获取对应的排序因子。
- 二是调研业界现有的评价排序策略在频繁迭代的场景下,如何实现不频繁变更代码上线的技术方案。
调研结论:
- 首先是排序因子调研
我们调研后发现无论是淘宝、拼多多还是京东,常用的排序因子大概有以下几种:
- 是否置顶
- 文本长度
- 是否有图或者视频
- 用户评分
- 是否有追评
- 用户信用等级
- 其他用户给该条评论点赞数量
- 创建时间
- 其次是技术方案调研
我们调研了业界现有的几种实现
- 通过抽象接口+实现类的方式,定义SortStrategy接口,每个版本的策略通过实现接口的方式实现策略。在使用时传入不同的版本号获取不同的策略服务。
该方法只能解决计算逻辑与业务代码耦合的问题,适合明确只有两三个版本后续不会再迭代的场景,但是对于频繁变更排序策略的场景仍不能解决。
- 搭建规则中心,支持运营同学在后台拖过拖拽的方式实现排序策略,并将该策略转义为一个表达式,每条评论实体经过该策略都会返回一个分数。
该方案可以解决我们的问题,即实现了解耦又可以解决频繁变更的问题,但是这个方案相对来说比较重量级,搭建一个规则中心的成本还是比较高的,我们的排序规则虽然会经常变化但是也不至于每天都会发生变化,因此也暂不考虑。
- 通过规则引擎实现排序规则,通过配置中心实现动态加载规则配置。
该方案可以解决我们的问题,即实现了解耦又可以解决频繁变更的问题,同时也较为轻量化。
因此通过我们最终决定选用方案3来实现我们的需求。
2.2 思考
那么通过以上的调研我们应该实现我们的技术方案呢?
"
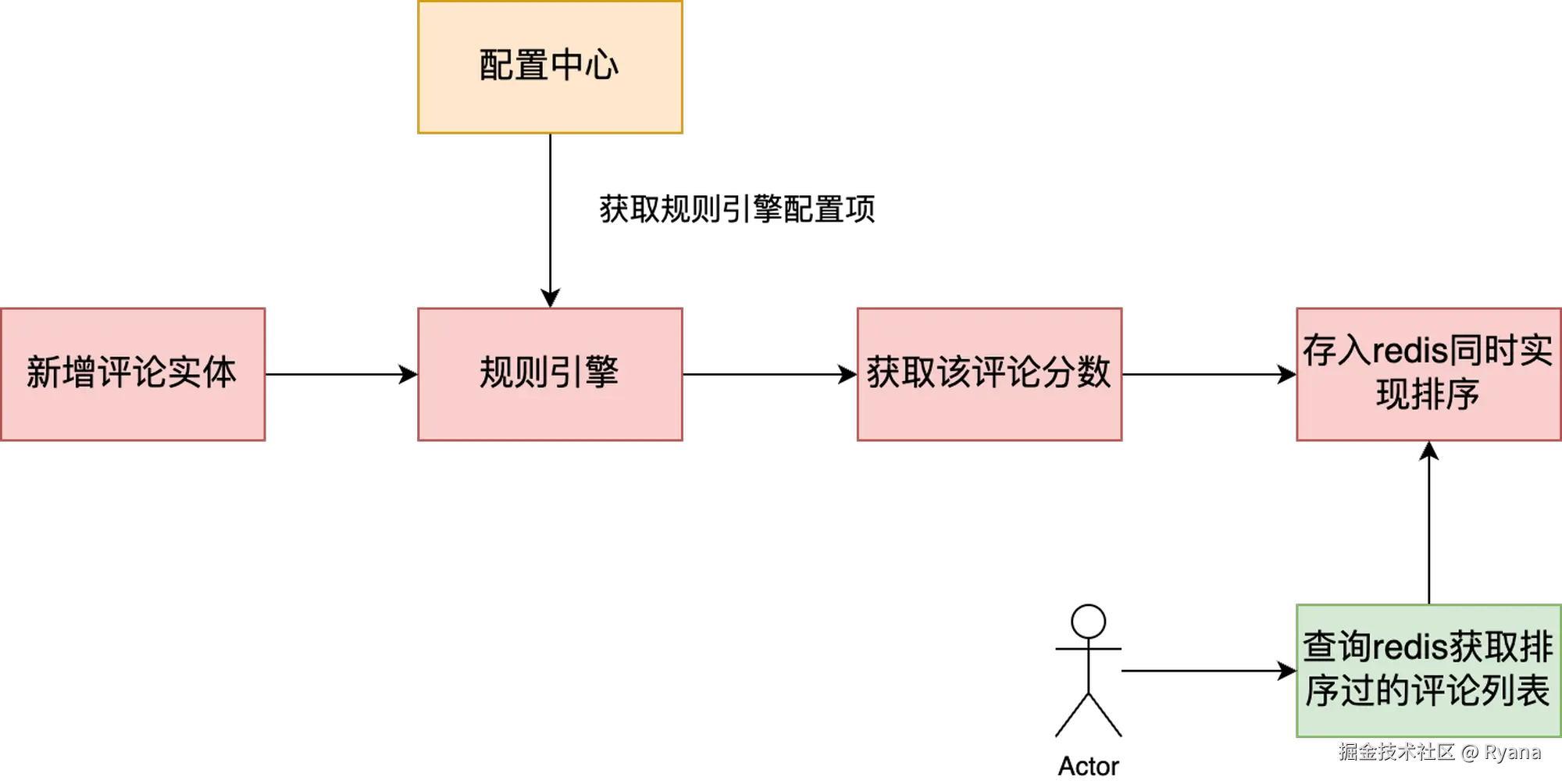
① 我们需要实现评论的排序,那么排序如何实现呢?,我们可以将每条评论实体转换为一个分数,然后存入redis的zset(有序集合)中 ,每次获取时按照分数排名获取结果即可,同时预先生成分数也可以避免每次查询时对全量缓存进行排序,性能也会更好。
② 我们如何将一个评论实体转换为一个分数呢?可以通过规则引擎,评论实体中的每个排序因子都是都对应一个,每个规则对应一个或多个公式,经过公式计算后得到一个分值。最后将所有的分值相加即可计算出总分值。 总分值越高,代表该评论越应该排在前面
③ 如何避免每次变动都需要重新上线呢?我们可以将规则引擎中的规则公式维护在配置中心,这样每次有变动都可以通过配置中心修改,避免每次需要修改代码重走上线流程。
"
通过上述思路,那我们来看一下这个方案是否能解决上述的问题呢。
- 通过配置化,后续每次新版本的迭代都不需要关注代码的开发 ✅
- 通过配置化,对于每次规则的微调改动都不需要修改代码,只需要修改相对应的配置即可 ✅
- 通过配置化,实现排序逻辑与业务代码的解耦,对于其他同学而言,理解成本极低 ✅
- 通过配置化,如果未来有新的排序因子,代码只需要从一条评论实体解析出对应的排序因子即可,无需关心排序逻辑 ✅
- 通过规则计算分,然后再存储redis的zset,实现查询接口的高性能✅
以上,就是我们的整体思路了,但是我们在实际写技术文档的时候发现只是规则引擎或许不够用,那么我们最终的技术方案是什么样呢?
三、实现方案
3.1 排序策略配置化
3.1.1 实现方案
首先来看最重要的点,如何将排序策略做到配置化。上面我们已经知道了可以通过规则引擎来实现,那么确实是可以的吗?我们先来看看规则引擎的定义:

好像跟我们的需求很像但是又不完全一样,规则引擎主要是对流程的编排 ,而流程的编排只是我们需求中的一部分,我们一个版本的排序规则可能有多个模块(例如置顶模块、图片和视频模块、情感和星级模块等等),规则引擎可以支持这几个模块之间的流程编排。例如如果满足A就B,否则C。
但是每个模块内部还会有一定的计算规则,那么这个计算规则如何实现呢?
通过表达式引擎。
我们看一下表达式引擎的规则引擎的区别:

那么其实到这里就比较清晰了,规则引擎专注于各个模块之间的流程编排,表达式引擎专注于一个模块内部的表达式规则解析为一个分数(即将一个表达式转换为一个分数)。
我们举个例子看一下:
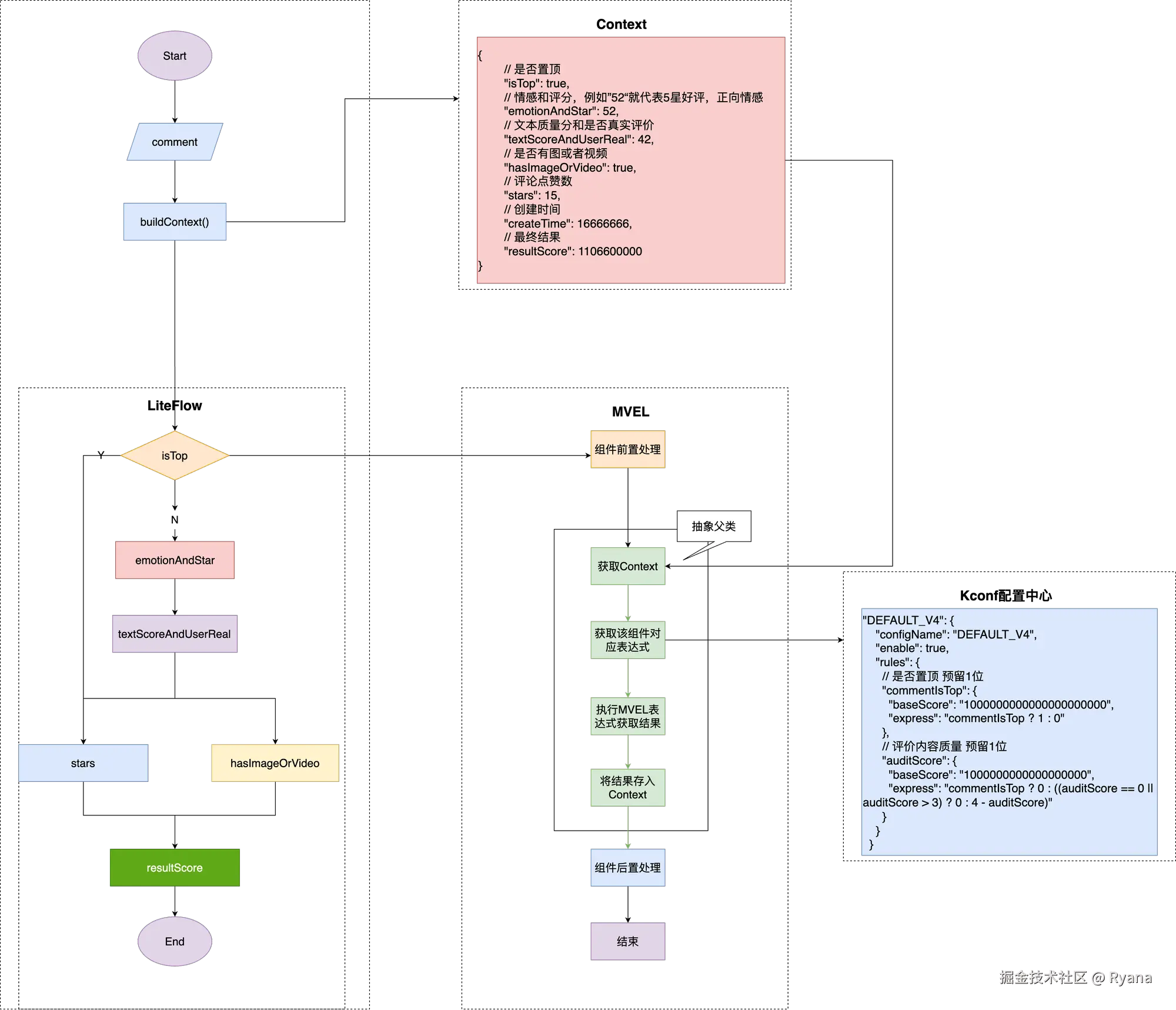
还是刚刚那个场景,规则引擎负责编排模块之间的流程,例如该条评论是否被置顶,如果是的话则直接结束即可,否则继续向下走图片和视频模块。在图片和视频模块中,表达式引擎负责计算如果有图的话会给该评论加多少分,如果有视频的话会加多少分,如果都没有的话是多少分。
3.1.2 框架选择
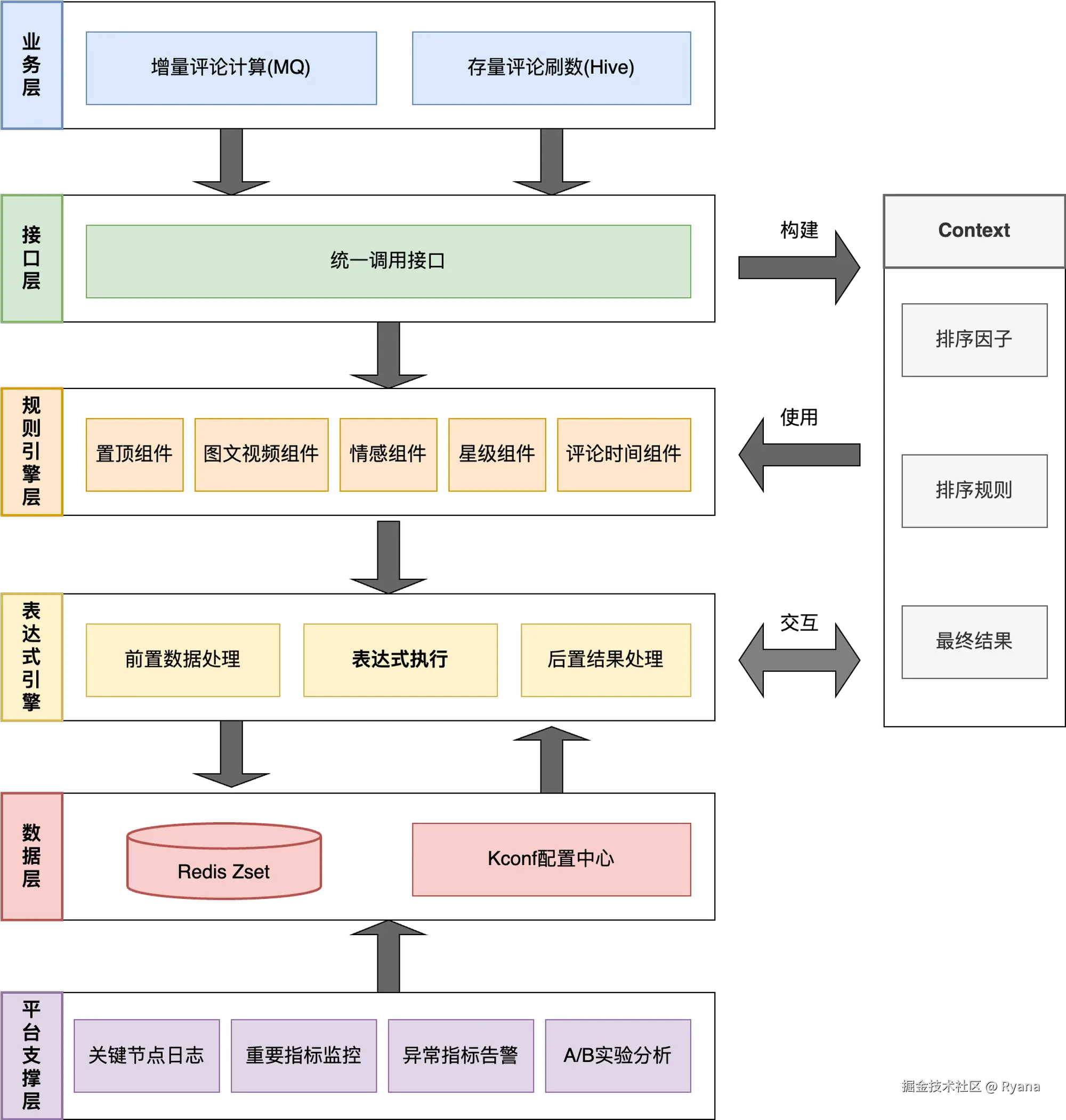
我们对比了现有的几款开源框架,包括规则引擎和表达式引擎,最终选择了「LiteFlow(规则引擎)」+「MVEL(表达式引擎)」 的框架来实现我们的方案,核心优势如下:
LiteFlow与其他规则引擎的对比:
| 维度 | LiteFlow | Spring StateMachine | Drools |
|---|---|---|---|
| 开发效率 | 基于链式/脚本式规则,配置化,迭代快 | 需手动建模状态,配置复杂 | 规则语言 DRL 学习成本高 |
| 灵活性 | 支持流程编排、规则动态变更、异步并行 | 状态转换灵活,但偏有限场景 | 功能强大,但过于重量级 |
| 学习成本 | Java 风格 DSL,学习曲线平缓 | 需要理解状态机模型 | 需掌握 DRL 语法和推理机制 |
| 可维护性 | 高度抽象,逻辑与代码解耦,易扩展 | 中等,适合状态驱动场景 | 可维护性强,但配置/调试复杂 |
| 适用场景 | 复杂业务编排、动态规则、配置化逻辑 | 状态驱动流程(订单、审批) | 金融、电信等对规则精度要求极高的场景 |
MVEL与其他表达式引擎的对比:
| 维度 | MVEL | SpEL | OGNL | Aviator |
|---|---|---|---|---|
| 性能 | 执行快,JIT 编译优化,适合高频场景 | 性能中等,适合 Spring 应用内使用 | 性能较差,表达式复杂时开销大 | 性能较好,强调高效计算 |
| 语法灵活性 | 语法接近 Java,简洁,支持集合、函数、lambda | 语法较完整,但偏重 Spring Bean 访问 | 功能强大但语法复杂,学习曲线陡峭 | 语法简洁,函数式支持好,但灵活性略逊 MVEL |
| 独立性 | 独立使用轻量化,无框架强依赖,适合通用场景 | 与 Spring 深度耦合,离开 Spring 用处有限 | 多用于 Struts2,对框架依赖强 | 独立性好,易于集成 |
| 功能扩展性 | 支持自定义解析器、动态类型、内联函数,规则场景友好 | 偏向于 Spring Bean 操作,扩展性有限 | 对象图导航强大,但扩展复杂 | 部分功能需付费或受限,高级特性依赖商业版 |
| 适用场景 | 规则引擎、动态逻辑、配置化计算,通用性强 | Spring 项目内部的配置和 Bean 访问 | 主要用于对象导航、老旧框架 | 高性能计算、部分企业应用 |
因此,综合以上考虑,我们决定使用了「LiteFlow」+「MVEL」。
3.1.3 架构图和流程图
综上,整个方案架构图图如下:
系统运转流程图如下:
3.1.4 示例
例如我们现在有一个评论实体,要通过一定的规则转换为一个分数,分数越大在展示时越应该排在前面。
假如说现在有个规则是,第1位表示置顶,第2-4位表示点赞数量,后面10为表示创建时间,那么一个评论就可以转换为:
10251757417797 表示为该条评论已经置顶,点赞数量为25个,创建时间为1757417797
01021757417798 表示为该条评论未置顶,点赞数量102个,创建时间为1757417798
然后再将其存入redis的zset中,查询评论时按照分值查询,分数越高的评论会越往前,这样就实现了评论的排序功能。
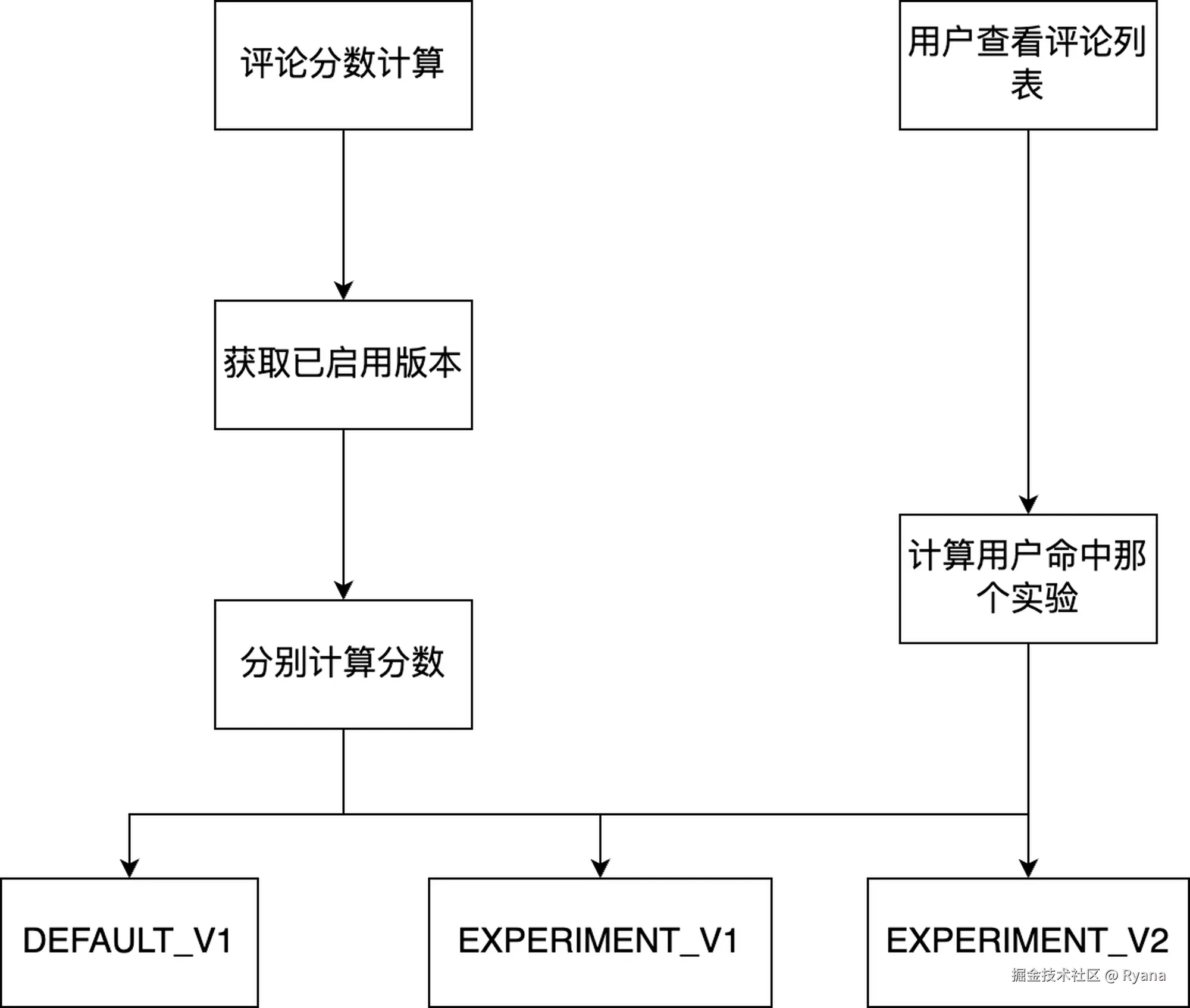
3.2 版本化
前文提到我们目前还在频繁的调整排序策略,那么我们应该观测每次调整后的策略版本是否有更好的效果呢?
我们借用了Git的版本思路,规则配置分为两种类型,默认版本和实验版本。
在计算评论分数时,会根据现有启用的版本各自算出来一套分数。用户在读取评论时,会判断该用户可以读取那个版本的数据,然后返回不同的排序方式。 然后再观察用户在不同的版本中是否对下单率有所不同,从而选择更优的版本。
3.3 如何保证排序策略的准确性
在我们验证排序策略是否准确的时候,确实发现了一个问题。我们发现加入有A和B两条评论,这两条评论除了评论时间有一些差异之外(例如A比B的评论时间晚),其他的排序因子一模一样,理论上来说,A的排序肯定会在B的前面(因为A的评论时间的时间戳比较大) ,但是实际在查看评论中发现并不是这样,有的时候发现B会排在A的前面。
排查后发现,在这个场景下,A和B两个不同的评论应该会产生不同的分数(因为评论时间戳不一样),但是在redis中这两个评论的分值竟然一样,但是有些诡异的点是这两个评论的最后几位都变成了0.
css
A评论:
123456781757417799
B评论:
123456781757417753
两者之间只差了最后两位
但是在存入redis之后却变成了
123456789123400000
后面的几位全被舍弃成0了排查后发现,我们计算分数时用的是bigDecimal,存入redis的时候会转换为double,就是在这个时候丢失了精度。
查询资料后发现,double类型的数字,最大可以存储大概E300级别的数字,也就是10的300次方,但是其精度一般只有E15-E17左右。也就是说,虽然他可以存储很大的数字,但是当数字达到一定位数之后,后面的精度会丢失。
那么为什么我们的分数位数会比较长呢?
上文提到,我们是将每一条评论通过规则计算出一个分数,仅创建时间一项就占用了10位数字,再加上其他的纬度 ,总的分数长度可能会达到20位数字。而double在不丢失精度的情况下,最多只能保留15-17位数字,因此当我们的纬度变多,就会出现丢失精度的情况。
那么我们应该怎么解决这个问题呢?
3.3.1 压缩长度(局限性太多)
我们首先想到的就是压缩长度。
我们有一个时间戳变量,他的位数就有10位左右,但是通常情况下他的前两位是不变的:
例如:对于1756204197我们是不是可以只记录后面的数字56204197,而舍弃掉前面两位。
或者是说我们有很多布尔变量,如果连续的一串布尔变量例如0110可以将其视为二进制转换为一个数字6,从4为转换为了1位。
但是以上这两种方案局限性太多,并且效果不好只能节省几位的数字,另外尤其是第二种比较复杂,实现起来很困难。
综合来看这个方法不是很行。
3.3.2 通过函数转换(治标不治本)
这个时候我们又考虑到,我们其实并不太关心数字本身,我们更关心的是两个数字之间的相对关系。例如我们只需要知道数字A是否比数字B大就可以,而不需要关系具体的A或者B是多少。那么我们是不是可以通过数学函数进行转换呢?
例如我们现在有两个数字110999999999999999和110999999999989999,假如说这个时候直接存储这个数字会丢失精度,例如都会变成11099999999900000,此时会出现丢失精度。但是如果我们对这两个数字求「ln(x)」呢
ln(x)的曲线如下: 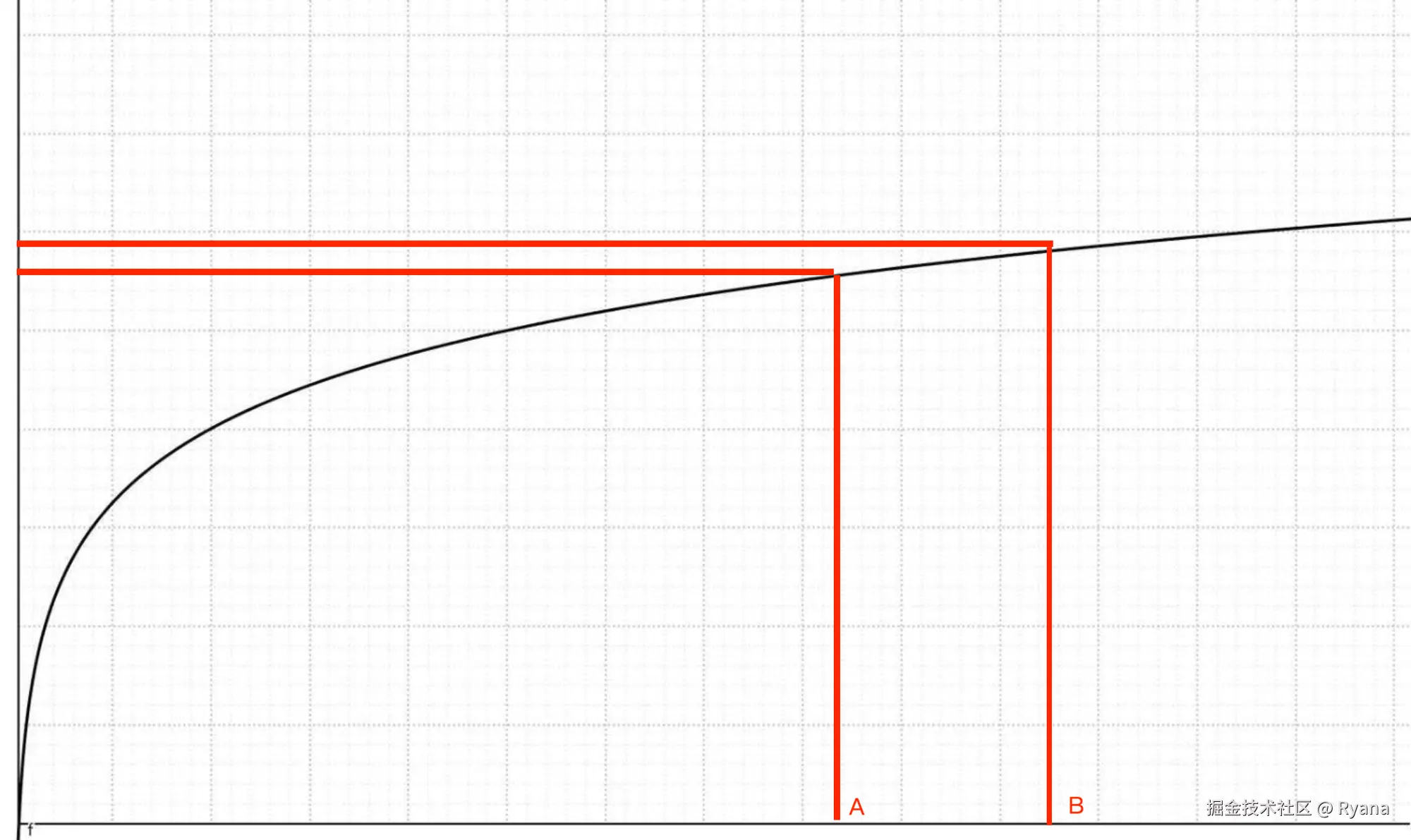
在上面的示例中求值如下:
ln(110999999999999999)≈38.54748436554357
ln(110999999999989999)≈38.54748436554348
可以看到,计算完成之后的结果是能区分出相对大小的。因为ln是单调的,因此只要一个分数比另一个分数大,得到的结果肯定是相对也大的。我们只需要限制ln的结果的位数,是不是就能保证不丢失精度呢?
我们再看一组数字,他们的数字差异比较小,
1.23456789123456789123456789E30
1.23456789123456789123456790E30
这个时候就会发现这两个数字的结果都是一样的(保留14位小数):
30.09151557188368
相当于还是会舍弃掉一部分精度。
综上所述,前面两种方案都是治标不治本,未来排序因子多了之后仍然可能丢失精度。
3.3.3 使用key排序(最终方案)
根据上面的描述,我思考了一下,因为double只能描述17位的精度,那么无论我们怎么处理得分,他都是有可能会超出最大精度导致精度丢失的问题。这个时候我感觉不能再陷入死胡同里了,我们退一步来向。
我们再重新思考一下,为什么要使用double?因为要使用redis的zadd排序, 这样当我们查询一个商品下的评论是,顺序就已经是排好了的,而zadd中score只能是double。那么我们一定要用zset排序吗?如果要用的话一定是要按照score排序吗?
退一步海阔天空,那么此时我们现在有两种解决方案。
- 不使用zadd有序集合,使用普通的集合sadd,这个时候在每一个member中拼接对应的分数,使用时,查询全量的集合,然后获取对应的分数,在jvm的内存中按照分数排序。
bash
SADD perfix_${item_id} ${comment_id}_${score}这个方式有两个问题,一是在jvm中内存排序会加重系统负担,二是普通集合并没有有序集合的需要保留多少个元素的功能,例如zremrangebyrank。
- 如果要用zset的话一定是要按照score排序吗? 其实并不是,redis除了提供按照double类型分数获取数据的方式,还提供了一种按照member的字典序的方式获取数据:ZRANGEBYLEX
bash
// score默认设置为0,然后将计算好的评论分数放在前面,
ZADD perfix_${item_id} 0 ${comment_score1}_${comment_id1}
# 存储:score固定为0,member=补位分数_评论ID
ZADD comment_rank_1001 0 00000000123_10086
ZADD comment_rank_1001 0 00000000098_10087
# 查询:按字典序获取前10条评论
ZRANGEBYLEX comment_rank_1001 - + LIMIT 0 10当获取数据时,会先按照score排序,此时我们的score默认都为0,然后就位按照member的字典序排序,而此时member的前半部分就是计算好的分数,因此只需要补齐位数,就可以实现多少位的分数都可以排序。
那我们从空间和效率上考虑一下,这里直接贴出AI的回复:
空间差异:
ZRANGEBYLEX 的排序依赖字符串,字符串长会稍微增加内存,但仍远小于存储 BigDecimal 全量精度的成本。
性能差异:
score 排序 (ZRANGEBYSCORE):
通过 skiplist 的 score 直接定位,范围查询是 O(logN + M)(N=总元素,M=返回数量)。
member 排序 (ZRANGEBYLEX):
要求所有元素 score 相同,才能按字典序。
也是基于 skiplist,但跳表排序依据是 member 而非 score,复杂度同样是 O(logN + M)。
综上所述:
通过ZREMRANGEBYLEX这种方案,就可以实现无论未来哟多少种排序因子,我们都可以实现不丢失精度!
四、结论和拓展
4.1 方案效果
那么我们如何评估我们这次方案带来的效果呢?我觉得可以从两个层面分析,一个是人效方面,另一个是系统性能方面。
4.1.1 人效提升
我们来预估一下假如下次有排序策略变更时,新方案需要耗时多久。
- 研发同学需要将产品给的PRD中的排序策略转换为策略配置,预计耗时为0.4pd。
- 测试同学需要将根据新的排序策略整理一定的测试样本和测试结果验证上一步的排序策略是否准确。预计最大耗时为1pd。
- 生效新策略配置、启动相关刷数任务等,预计耗时为0.2pd。
预计总计耗时为0.4+1+0.2=1.6pd
那么之前的方案需要的总pd数是多少呢?我们来看一下之前某一个版本的排期:
开发:5.28-5.31
提测:5.31
测试:6.3-6.4
PRT:6.4
上线:6.5
总计耗时为6pd。
那么我们所提升的人效就为:
(6-1.6)/6*100%≈73.33%
4.1.2 性能提升
之前的方案是每次先查询出一批评价实体,然后再在jvm内存中按照固定的逻辑编码进行排序。而新方案从缓存中获取好的就是排序好的顺序,可以直接使用。因此理论上新方案的性能会有一些提升。
但是我们观察了上线前后的cpu和jvm的情况,发现区别不大,思考后认为应该是查询评论的qps相对来说不是很高,目前的集群机器性能是能cover住的,并且尚未达到瓶颈,因此目前来看性能提升不是很明显。
4.2 拓展:是否还能继续提效?
根据我们前面的预估,发现其实现在的方案最耗时的时间花费在将PRD的逻辑转换为对应的规则表达式,其次是测试同学需要整理新策略的用例以及执行。
思考一下其实这两步都是可以通过AI来完成的,最理想的情况下,我们可以做一个智能体Agent,我们只需要把我们现在有的规则以及要修改的规则告诉AI,期望AI能够帮我们生成对应的排序规则配置,然后根据配置生成对应的测试集,然后再通过MCP自动化执行测试集,如果全部验证通过,人工只需要check结果即可上线。
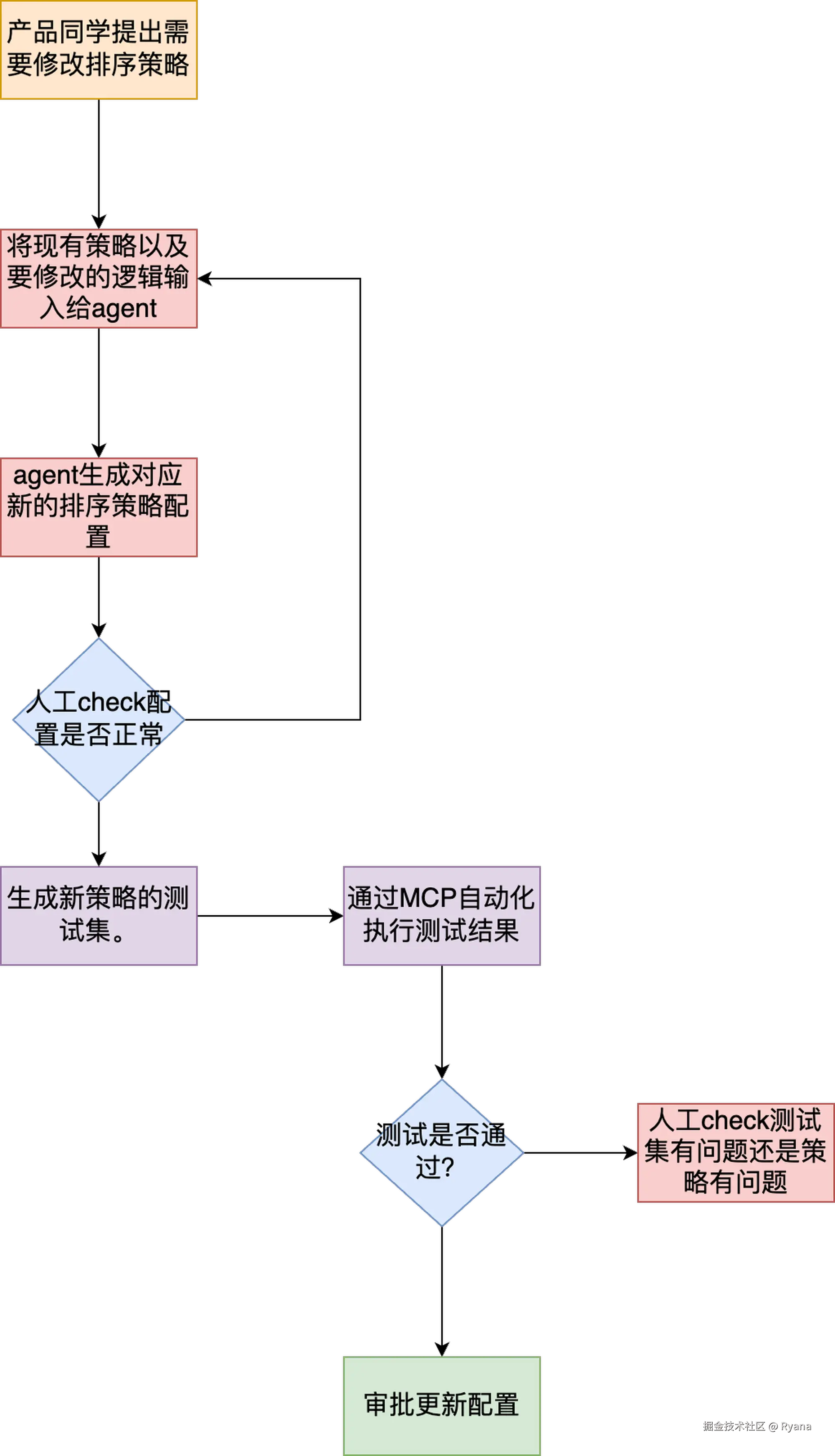
届时或许真的可以实现一句话就可以修改对应策略!
4.3 拓展:Redis的Zset是如何相同分数下key的有序性的
众所周知,redis的有序集合主要使用跳表的数据结构来实现的,以下是一个跳表节点的定义:
arduino
typedef struct zskiplistNode {
robj *obj; // 成员的字符串值(Redis 字符串对象)
double score; // 成员的分数
struct zskiplistNode *backward; // 后退指针(仅底层有意义)
struct zskiplistLevel {
struct zskiplistNode *forward; // 同一层级的前进指针
unsigned int span; // 与前向节点的距离(用于排名计算)
} level[]; // 柔性数组,存储各层级的信息
} zskiplistNode;主要关注obj(也就是member的key值)和score(也就是member的value值)两个字段。当zset中有数据插入时,会先比较score值的大小,如果score值一样,则会按照obj的字典序进行排序。 这样的话当n个member的value一样时,就会按照member的key值进行排序。
同理,以后大家如果有别的场景需要向zset中存取数据,但是受限于double类型时(例如要按照字符串排序、或者数字长度太长),都可以使用所有的member的value相同,然后把要排序的字符串拼接在key里即可。
五、思考和总结
在完成产品需求时,研发同学往往容易陷入一个惯性:产品给出什么需求,我们就机械地实现什么功能。这种做法短期内看似能快速交付,但长期来看,系统会不断堆积"硬编码"逻辑,形成复杂而脆弱的技术债。每次迭代都要重新打开核心代码、重新理解业务逻辑、重新测试上线,最终演变为低效、难维护的局面。
研发工作并不仅仅是"把需求翻译成代码",更重要的是在实现过程中保持技术思考,主动去抽象和沉淀。 其实在这块我之前做的也不好,之前的理解是产品让做什么就做什么,不需要思考太多的东西,也不想去思考太多的东西。短期来看,这样确实既省事又省"脑子"。但是如果不能做到每次做需求的时候"再多想一步" ,长期来看有两个坏处:一是增加了系统的维护成本和不稳定性,二是对自己来说也没有提升,可替代性极高。
这背后的关键思维是:研发不止要解决"当下的问题",还要预判"未来可能的问题" 。当我们意识到排序策略会频繁变化,就应该从一开始就避免"硬编码陷阱",而是用可配置、可扩展的方式来承载变化。这样做的结果是,未来新增一个规则因子,不再需要大规模修改代码,而只需扩展配置,极大地降低了维护成本。
总结来说,优秀的研发不是需求的被动执行者,而是方案的设计者和系统的守护者。需求告诉我们"做什么",但研发需要思考"怎么做才更合理、更可持续" 。唯有如此,我们才能不断提升系统的可维护性和研发效能,让技术真正成为业务长期发展的"助推器",而不是"绊脚石"。
六、附录
help.youzan.com/displaylist...