Elasticsearch(ES)的持久化机制是保障数据不丢失的核心,其设计基于 Lucene 的底层存储模型 + ES 自身的分布式协调能力,核心目标是在 "高性能读写" 和 "数据可靠性" 之间做平衡。理解其原理需从 "数据写入流程""持久化核心组件""故障恢复机制" 三个维度拆解,以下是结构化解析:
一、先明确核心前提:ES 的 "分层存储" 模型
ES 的数据存储分为 内存层 和 磁盘层,持久化的本质是 "将内存中的数据安全刷写到磁盘",但并非实时刷盘(否则会严重影响写入性能),而是通过 "缓冲 + 日志" 的机制异步落地:
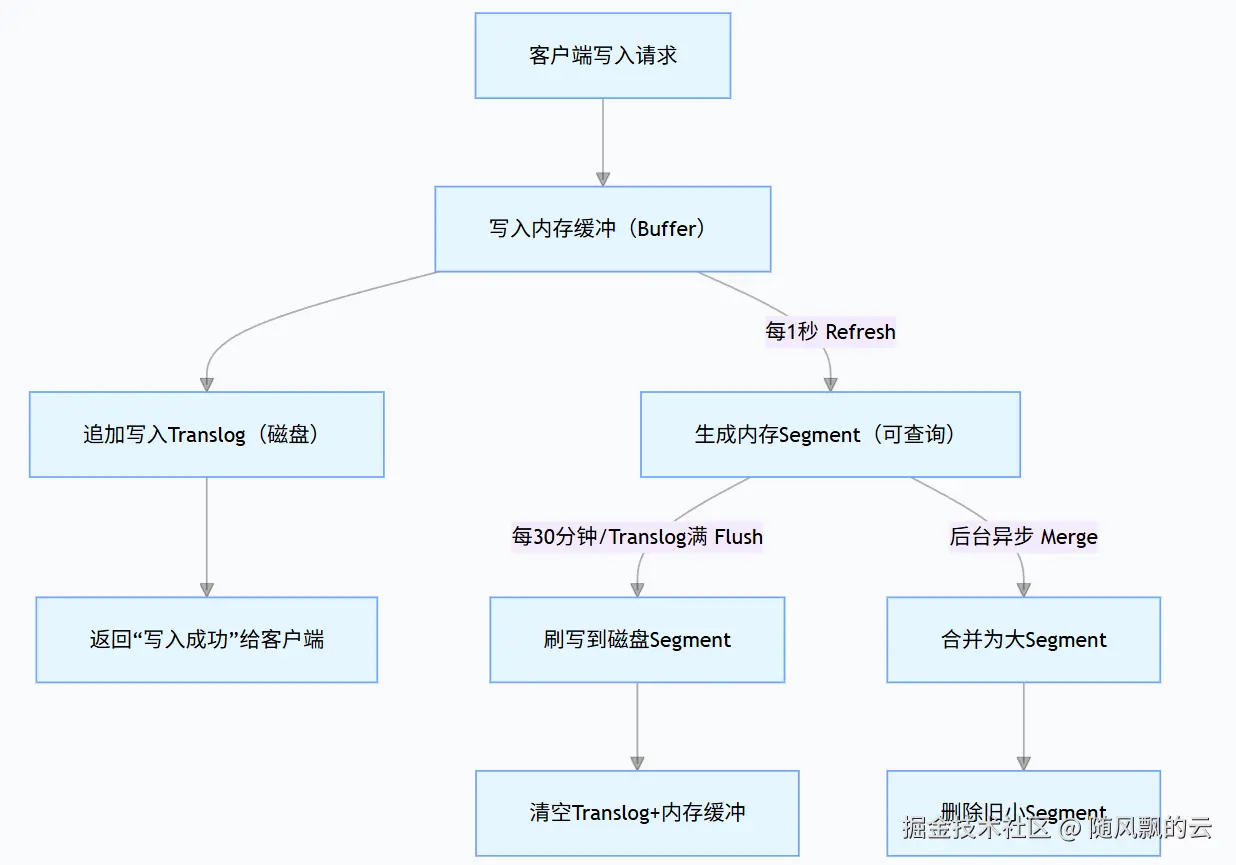
写入请求 → 内存缓冲(Buffer)→ 磁盘日志(Translog)→ 内存分段(Segment)→ 磁盘分段(Lucene索引文件)- 内存层:用于临时存储待写入数据,提供高吞吐写入;
- 磁盘层:最终数据存储位置,保障数据永久不丢失。
二、ES 持久化的核心组件与工作原理
ES 的持久化依赖两个关键组件:Translog(事务日志) 和 Lucene 的 Segment(分段索引) ,二者协同工作,确保 "写入不丢失、查询高性能"。
1. Translog:数据安全的 "第一道防线"(防止内存数据丢失)
Translog 是 ES 的事务日志,本质是一个 追加写的磁盘文件,用于记录所有未被刷写到 Lucene 索引的数据。其核心作用是 "崩溃恢复"------ 当 ES 节点宕机时,可通过 Translog 恢复未持久化的内存数据。
(1)Translog 的工作流程
-
写入时:
- 客户端发送写入请求(Index/Update/Delete);
- ES 先将数据写入 内存缓冲(In-Memory Buffer) ,同时追加写入 Translog(磁盘文件) ;
- 写入 Translog 成功后,立即向客户端返回 "成功"(此时数据已持久化到 Translog,即使节点宕机也能恢复);
- 内存缓冲中的数据暂不刷盘,继续累积以提升写入效率。
-
关键特性:
-
追加写:避免随机 IO,提升写入性能;
-
同步刷盘策略:
- 默认:每 5 秒自动刷盘(可通过
index.translog.sync_interval配置); - 触发式刷盘:当 Translog 文件大小超过阈值(默认 512MB,
index.translog.flush_threshold_size),或写入请求数达到阈值时,主动刷盘; - 同步刷盘(Sync):确保数据物理写入磁盘(而非操作系统缓存),依赖操作系统的
fsync调用。
- 默认:每 5 秒自动刷盘(可通过
-
-
Translog 的清理:当内存缓冲的数据被刷写到 Lucene 的 Segment(磁盘)后,对应的 Translog 记录会被标记为 "已持久化",后续会通过 "合并 Segment" 或 "手动触发 Flush" 时清理旧的 Translog 文件。
2. Lucene Segment:数据持久化的 "最终载体"(查询性能的核心)
ES 的底层存储依赖 Lucene,而 Lucene 的索引由多个 不可变的 Segment 文件 组成(Segment 一旦写入磁盘,就无法修改,只能通过新增、删除标记、合并来维护)。ES 的 "刷盘(Flush)" 操作,本质就是将内存缓冲中的数据写入 Lucene 的 Segment 文件。
(1)Segment 的工作流程
-
刷新(Refresh):生成内存 Segment(提升查询可见性) :
- 默认每 1 秒,ES 会将内存缓冲中的数据写入 内存中的 Segment(In-Memory Segment) ,并清空内存缓冲;
- 此时数据未写入磁盘,但已可被查询(这就是 ES"近实时(NRT)查询" 的原理);
- 注意:Refresh 操作不涉及磁盘 IO(仅内存操作),所以性能极高,但数据未持久化到磁盘,若节点宕机,这部分数据需通过 Translog 恢复。
-
刷盘(Flush):将内存 Segment 写入磁盘(最终持久化) :
-
Flush 是真正的 "持久化" 操作,触发时机:
- 自动触发:默认每 30 分钟(
index.flush_interval); - 触发式:Translog 文件大小达到阈值(默认 512MB),或手动执行
POST /index/_flush;
- 自动触发:默认每 30 分钟(
-
操作过程:
- 先将当前内存中的 Segment 刷写到磁盘(生成
.seg文件); - 执行
fsync确保数据物理落地; - 清空 Translog 文件(仅保留未刷盘的新数据)。
- 先将当前内存中的 Segment 刷写到磁盘(生成
-
-
Segment 合并(Merge):优化查询性能:
- 由于 Segment 不可变,每次 Refresh 会生成新的小 Segment,长期下来会导致 Segment 数量过多(影响查询效率,因为查询需遍历所有 Segment);
- ES 会后台异步合并小 Segment 为大 Segment(由 Lucene 的
MergePolicy控制),合并完成后删除旧的小 Segment 和对应的删除标记; - 合并过程会消耗磁盘 IO 和 CPU,ES 默认会限制合并速度(
indices.queries.bool.max_clause_count),避免影响业务。
3. 核心组件协同流程图(可视化理解)
三、故障恢复机制:如何保障数据不丢失?
当 ES 节点宕机重启时,会通过以下步骤恢复数据,确保持久化的可靠性:
- 节点启动时,先加载磁盘上的所有 Lucene Segment 文件(这是已持久化的数据);
- 读取 Translog 文件,将其中未刷写到 Segment 的数据(即宕机前写入内存缓冲但未 Flush 的数据)重新写入内存;
- 执行一次 Flush 操作,将恢复到内存的数据刷写到新的 Segment 文件;
- 清空旧的 Translog,启动正常服务。
- 结论:只要 Translog 文件未损坏,即使节点宕机,数据也不会丢失(Translog 本身是追加写的磁盘文件,损坏概率极低)。
四、关键配置参数(面试高频)
| 配置参数 | 作用 | 默认值 |
|---|---|---|
index.translog.sync_interval |
Translog 自动刷盘间隔 | 5s |
index.translog.flush_threshold_size |
Translog 触发 Flush 的文件大小阈值 | 512MB |
index.flush_interval |
自动 Flush 间隔(仅对旧数据有效,优先看 Translog 大小) | 30m |
index.refresh_interval |
自动 Refresh 间隔(控制查询可见性) | 1s |
indices.memory.index_buffer_size |
内存缓冲的总大小(所有索引共享) | 堆内存的 10% |
-
优化建议:
- 写入密集型场景(如日志采集):可增大
refresh_interval(如 5s),减少 Refresh 次数,提升写入性能; - 数据安全性要求高的场景(如交易数据):可减小
translog.sync_interval(如 1s),降低数据丢失风险(但会轻微影响写入性能)。
- 写入密集型场景(如日志采集):可增大
五、常见误区澄清(面试避坑)
-
"ES 写入成功后数据就一定不会丢失?" 是的。因为写入成功的前提是 "数据已追加到 Translog 并刷盘"(默认 5s 内),即使节点宕机,重启后可通过 Translog 恢复,除非 Translog 文件物理损坏(极端情况)。
-
"Refresh 和 Flush 的区别?"
- Refresh:内存→内存 Segment,提升查询可见性(近实时),不持久化到磁盘;
- Flush:内存 Segment→磁盘 Segment,最终持久化,清空 Translog。
-
"Segment 为什么不可变?"
- 优点:避免随机 IO,提升写入和查询性能;支持并发查询(无需锁);
- 缺点:删除数据时只能标记为 "已删除"(合并时才真正删除),更新数据本质是 "删除旧文档 + 写入新文档"。
六、总结
ES 的持久化机制核心是 "Translog 保障数据安全 + Lucene Segment 保障查询性能" :
- 写入时:通过 "内存缓冲 + Translog" 实现高吞吐写入,同时确保数据不丢失;
- 查询时:通过 "Refresh 生成内存 Segment" 实现近实时查询;
- 持久化时:通过 "Flush 刷写磁盘 Segment" 实现数据永久存储;
- 优化时:通过 "Segment 合并" 提升查询效率。