文章目录
- 前言
- 协程
- channel
-
- [1. 创建与关闭](#1. 创建与关闭)
- [2. 读写](#2. 读写)
- [3. 无缓冲](#3. 无缓冲)
- [4. 有缓冲](#4. 有缓冲)
- [5. 单向管道](#5. 单向管道)
- [6. for range](#6. for range)
前言
本篇文章仅为学习go的一些记录。
参考链接:点击跳转
协程
go语言中可以用go这个关键字很轻松的开启一个协程,如何理解协程?可以理解为更轻量级的线程,线程栈比较大,调度也需要内核参与,所以比较消耗资源,且效率较低(与协程相比),协程栈比较小,调度也不需要内核,在应用层即可完成调度,不需要切换上下文,所以效率更高。
比较简单的理解方式就是,假设线程正在cpu运行,协程就相当于一个一个的函数,需要运行哪个就把这个协程放到线程里,进行运行,当a协程阻塞了,那应用层就把a协程拿出来,换上b协程去线程里跑,就这个意思。
在go里协程是由go自己的调度器进行调度的。
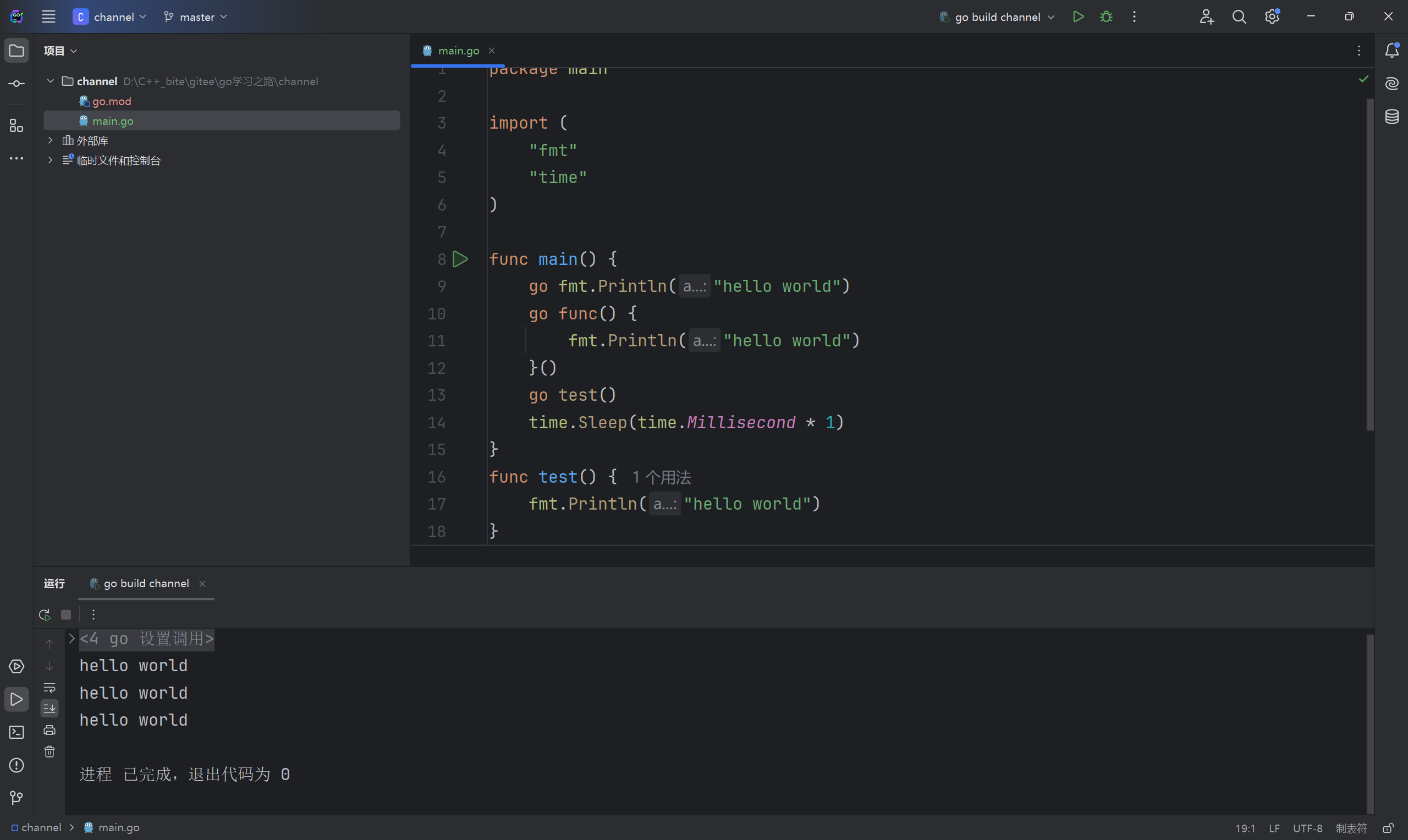
在 Go 中,创建一个协程十分的简单,仅需要一个 go 关键字,就能够快速开启一个协程,go 关键字后面必须是一个函数调用。例子如下
go
func main1() {
//go make([]int, 10)
go fmt.Println("hello world")
go func() {
fmt.Println("hello world")
}()
go test()
time.Sleep(time.Millisecond * 1)
}
func test() {
fmt.Println("hello world")
}
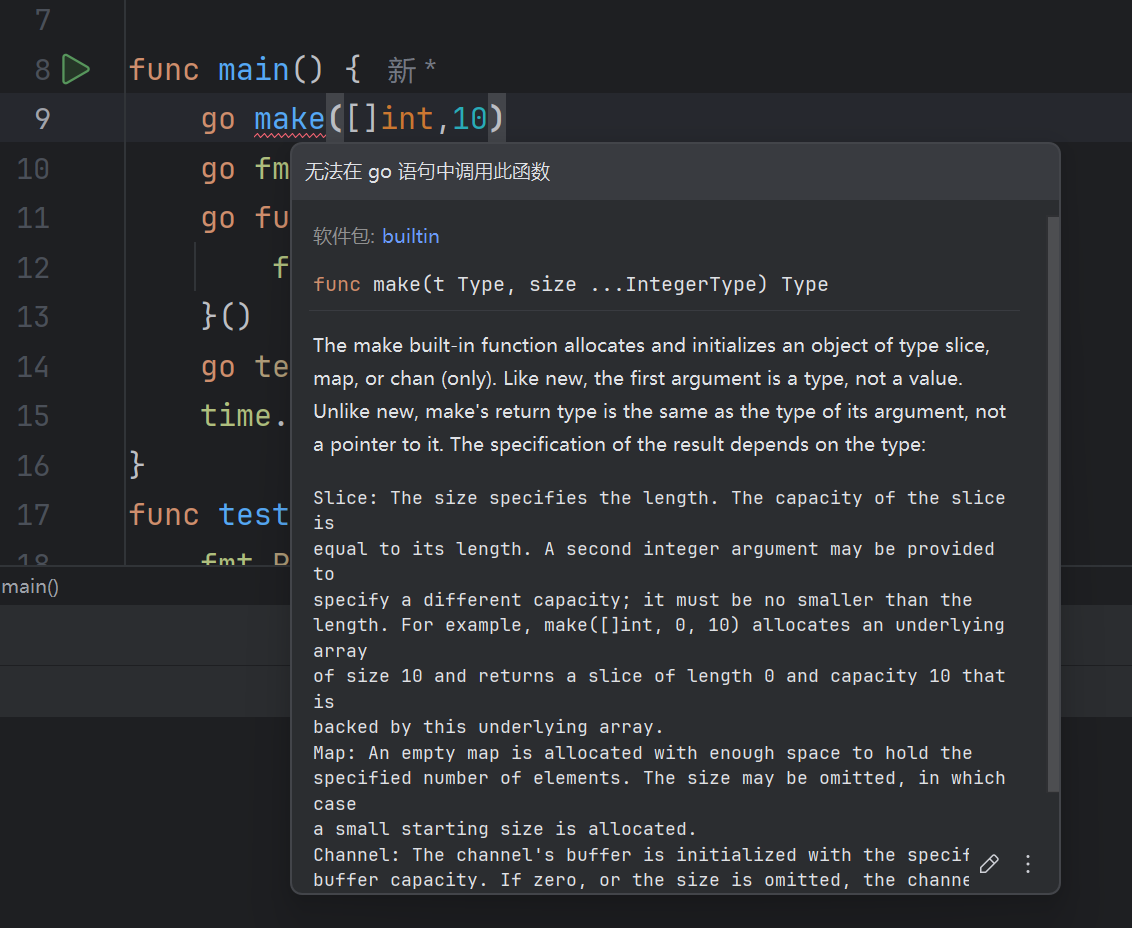
但是go后面不可以跟具有返回值的内置函数,错误示例如下:
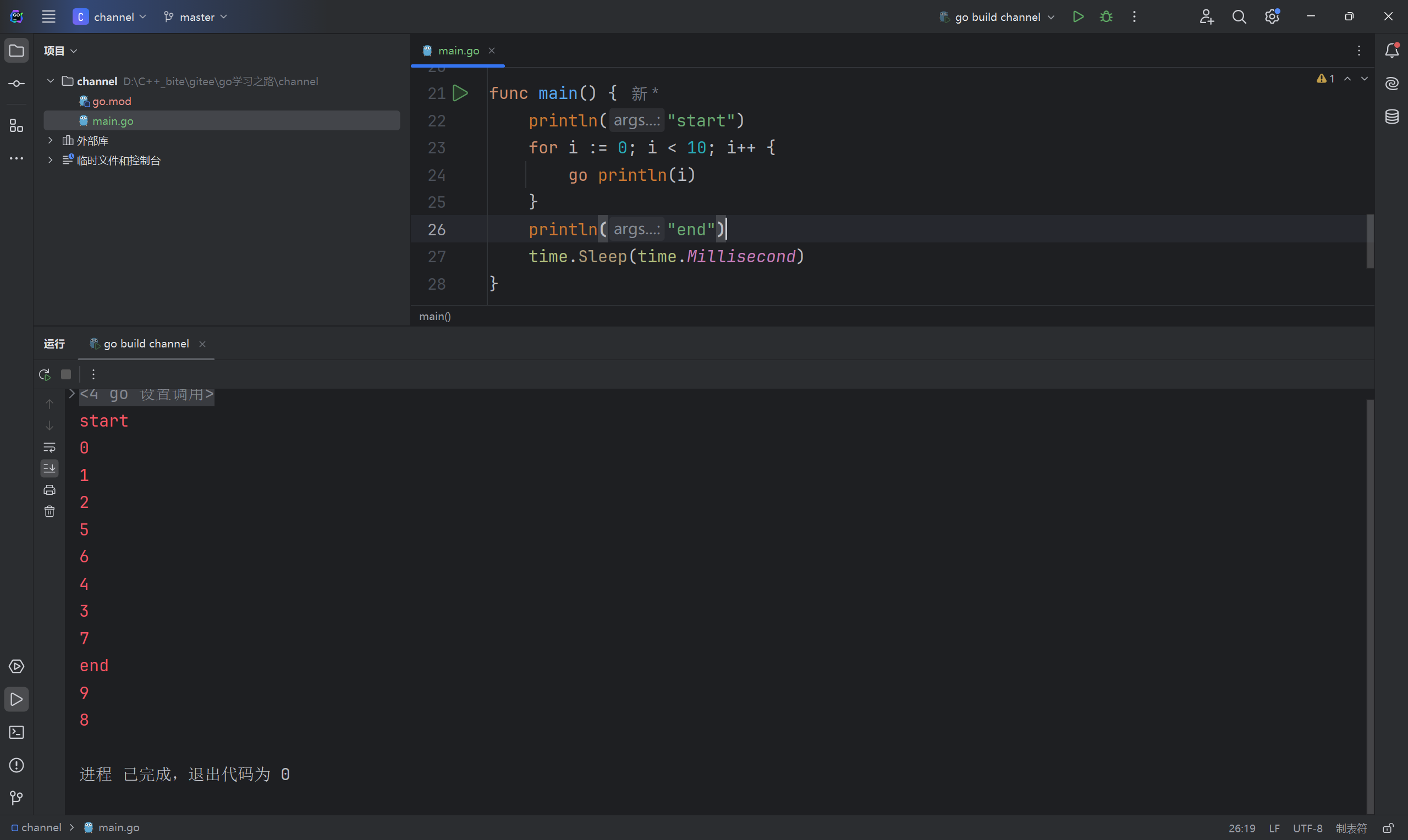
协程的运行顺序是不确定的,所以下面的程序会出现乱序的情况,而且main函数是主协程,一旦主协程退出了,其它协程也都会推出,所以要确保其它协程都运行完,主协程才能退出,所以在main函数最后可以添一个sleep函数,让main函数最后停留一点时间,我们这里协程都比较简单,几乎一瞬间就都执行完毕了,所以停留个1ms就行了。
go
func main2() {
println("start")
for i := 0; i < 10; i++ {
go println(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
println("end")
}
想让协程按顺序执行我们可以在每次执行完一次for循环就sleep一下,让这次开启的协程执行完毕,再开启下一个协程,这样就可以顺序打印了。
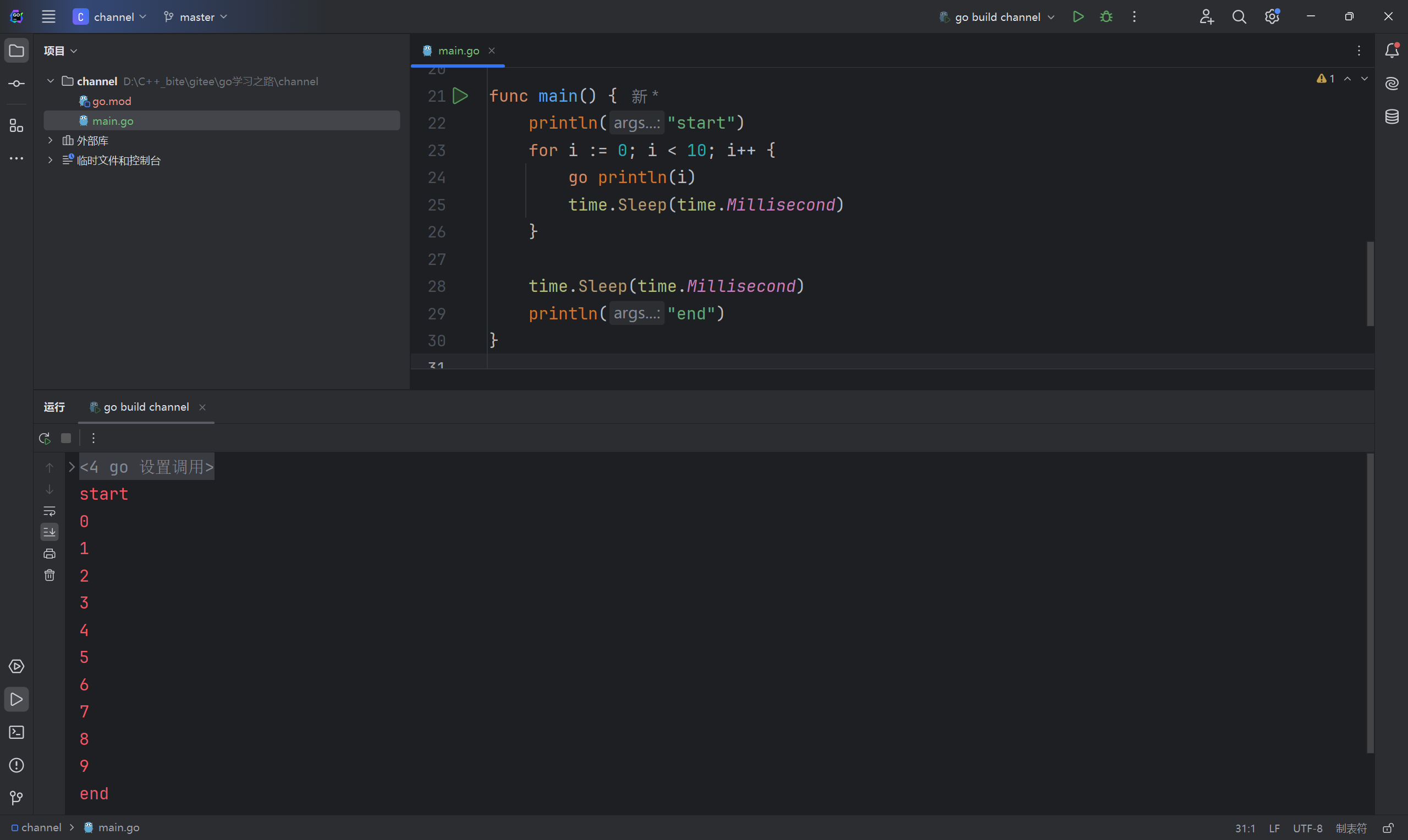
不过还是有问题的,上面那个代码能过那是因为我们知道开启的协程几乎可以在一瞬间完成,但是在实际生产中,我们是无法预估到底需要多长时间才能运行完的。此外对于并发的程序而言,不可控的因素非常多,执行的时机,先后顺序,执行过程的耗时等等都会影响最终的结果,例如下面这个程序就没能完整打印结果,甚至每次运行的结果都会不一样。
go
func main3() {
fmt.Println("start")
for i := 0; i < 10; i++ {
go hello(i)
time.Sleep(time.Millisecond)
}
time.Sleep(time.Millisecond)
fmt.Println("end")
}
func hello(i int) {
// 模拟随机耗时
time.Sleep(time.Millisecond * time.Duration(rand.Intn(1000)))
fmt.Println(i)
}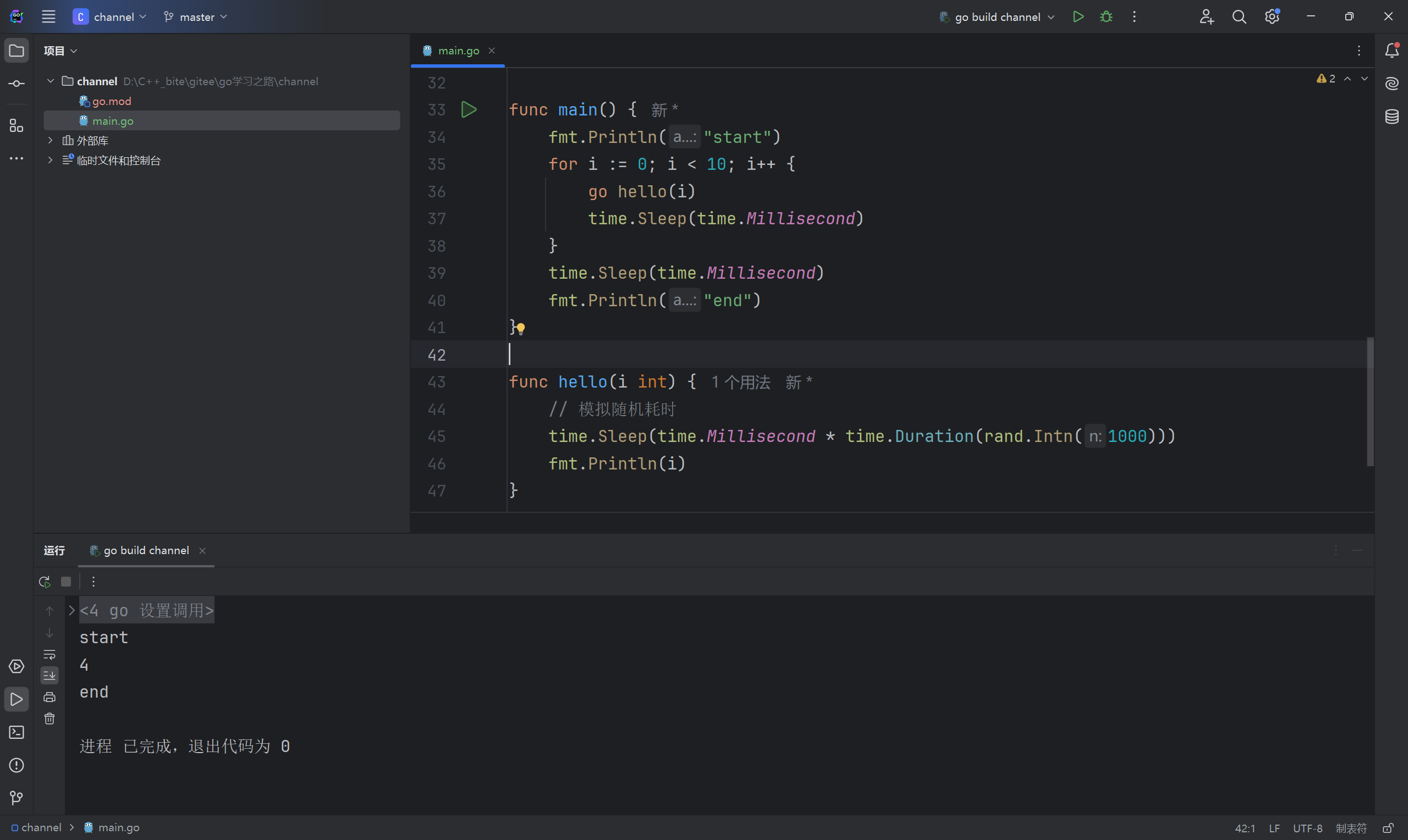
因此 time.Sleep 并不是一种良好的解决办法,go语言中内置了一些并发控制的手段来解决这些问题,常用的并发控制方法有三种:
- channel:管道
- WaitGroup:信号量
- Context:上下文
三种方法有着不同的适用情况,WaitGroup 可以动态的控制一组指定数量的协程,Context 更适合子孙协程嵌套层级更深的情况,管道更适合协程间通信。对于较为传统的锁控制,Go 也对此提供了支持:
- Mutex:互斥锁
- RWMutex :读写互斥锁
下面我们先来介绍用来协程之间通信的管道即channel
channel
channel可以简单理解为一个队列,且这个队列go已经给你封装好了,而且是并发安全的,你直接创建一个channel拿去到各个协程里读写就好了,不用担心并发安全问题。
1. 创建与关闭
Go 中通过关键字 chan 来代表管道类型,同时也必须声明管道的存储类型,来指定其存储的数据是什么类型,下面的例子是一个普通管道的模样。
go
var ch chan int这是一个管道的声明语句,此时管道还未初始化,其值为 nil,不可以直接使用
可以用make创建一个channel
go
make(chan type,size)
//type表示管道的类型,size表示管道的大小,size不写默认容量为0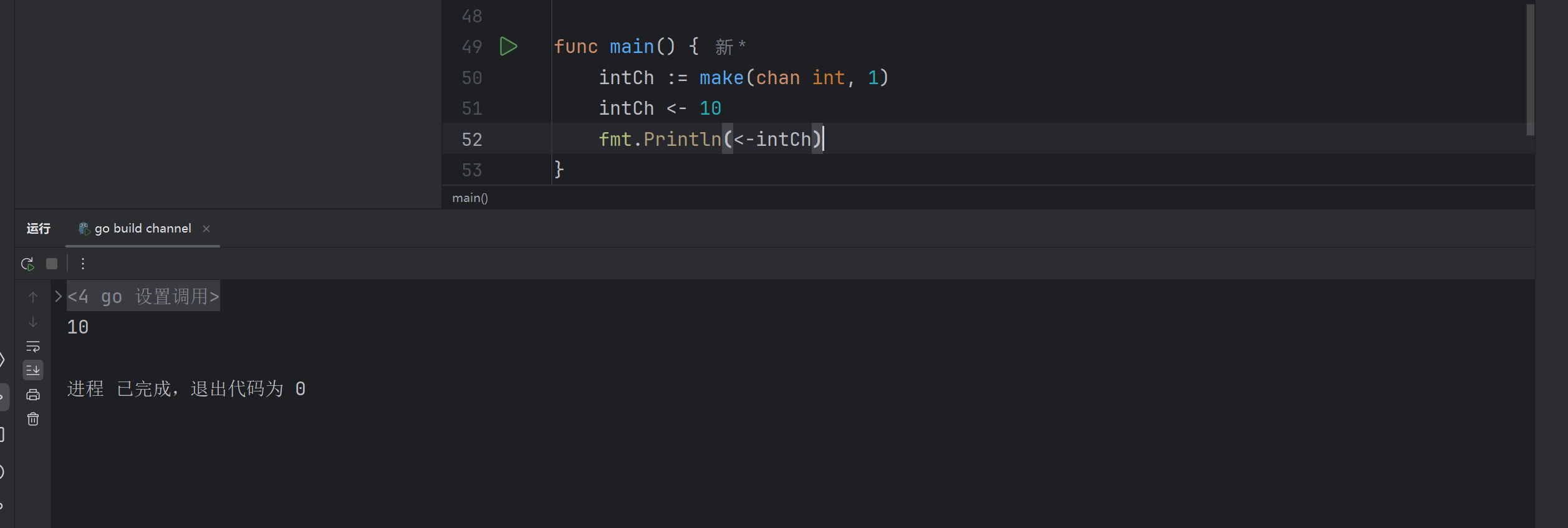
使用完管道之后需要用close关闭管道例如:
go
func main() {
intCh := make(chan int)
// do something
close(intCh)
}2. 读写
对于一个管道而言,Go 使用了两种很形象的操作符来表示读写操作:
-
ch <-:表示对一个管道写入数据
-
<- ch:表示对一个管道读取数据
-
<- 很生动的表示了数据的流动方向,来看一个对 int 类型的管道读写的例子
go
func main() {
// 如果没有缓冲区则会导致死锁
intCh := make(chan int, 1)
defer close(intCh)
// 写入数据
intCh <- 114514
// 读取数据
fmt.Println(<-intCh)
}上面的例子中创建了一个缓冲区大小为 1 的 int 型管道,对其写入数据 114514,然后再读取数据并输出,最后关闭该管道。对于读取操作而言,还有第二个返回值,一个布尔类型的值,用于表示数据是否读取成功
go
ints, ok := <-intCh管道中的数据流动方式与队列一样,即先进先出(FIFO),协程对于管道的操作是同步的,在某一个时刻,只有一个协程能够对其写入数据,同时也只有一个协程能够读取管道中的数据。
3. 无缓冲
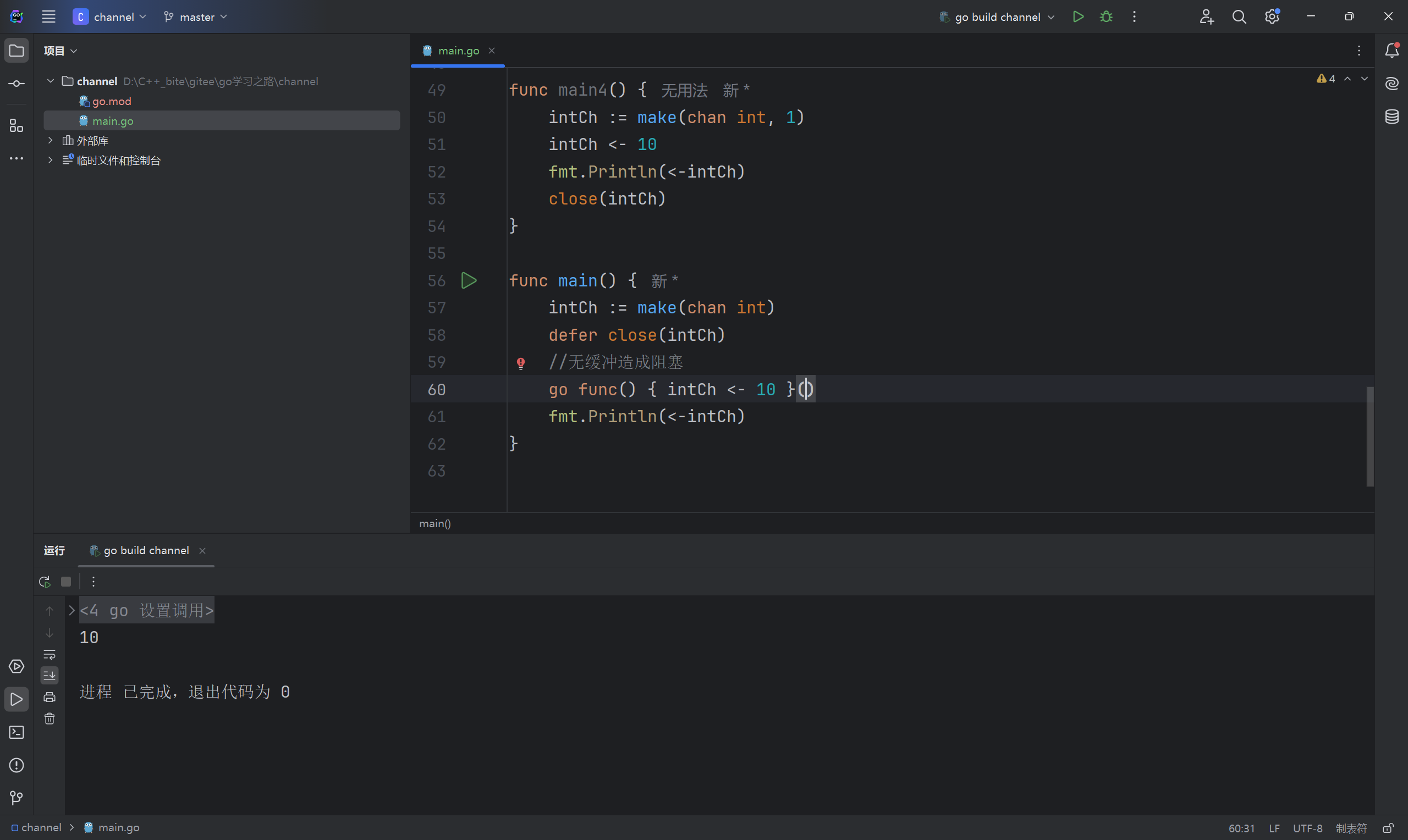
无缓冲对应的情况就是size为0,这个时候你如果只有一个协程对它进行写或读都会被阻塞,只有在某个时刻,有俩协程同时一个对它写一个对它读,这样才不会阻塞,程序才能正常运行。
下面的例子表明只在主协程里对intch进行写入,然后进行读取,但是读取之这一行代码是执行不到的,因为在上面一行,对这个无缓冲的管道进行写入就已经阻塞了,所以导致程序运行不下去了。
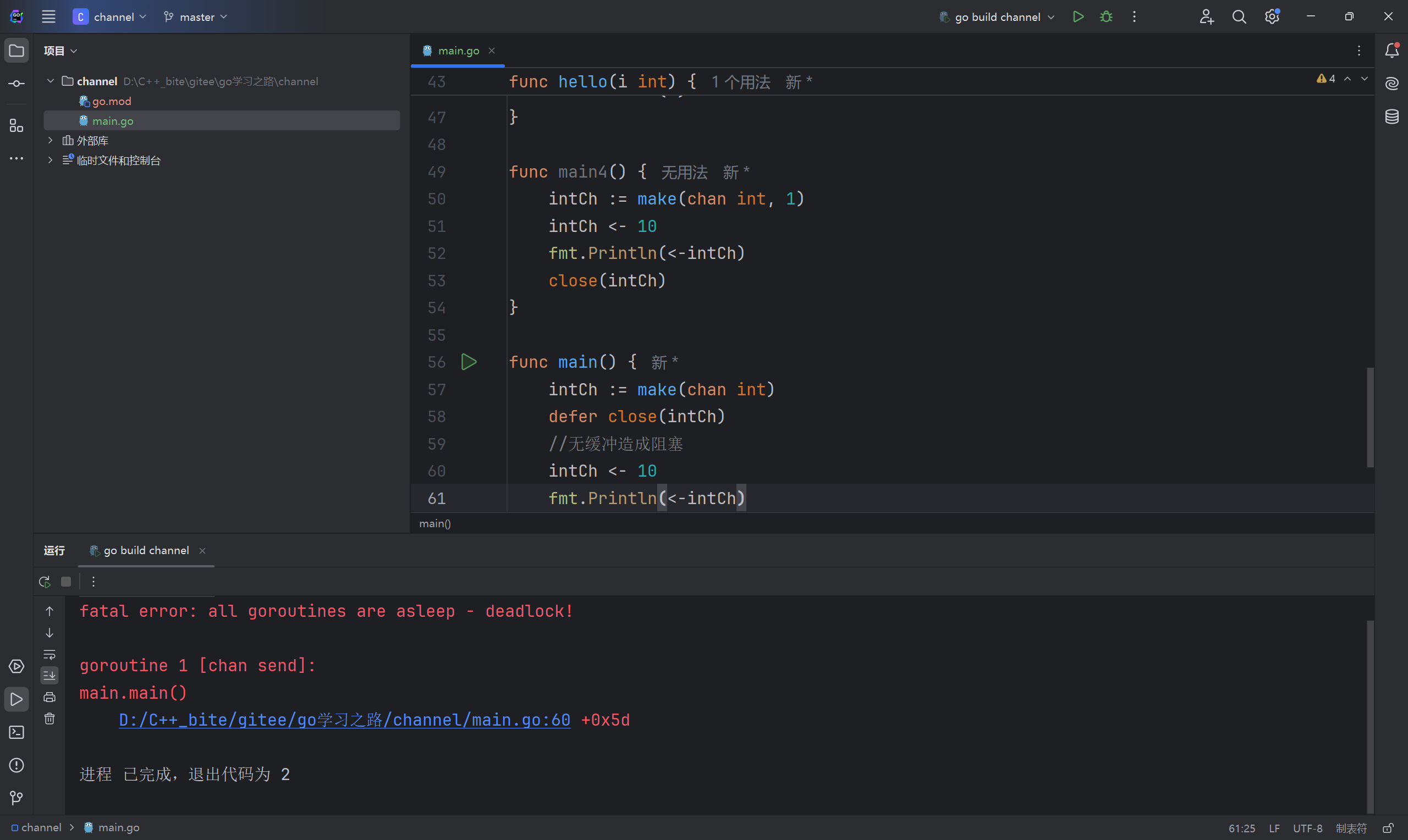
无缓冲管道不能在一个协程里同步的试用,我们单独开一个协程往channel里写,然后在主协程里读,这样就可以正常运行了。
4. 有缓冲
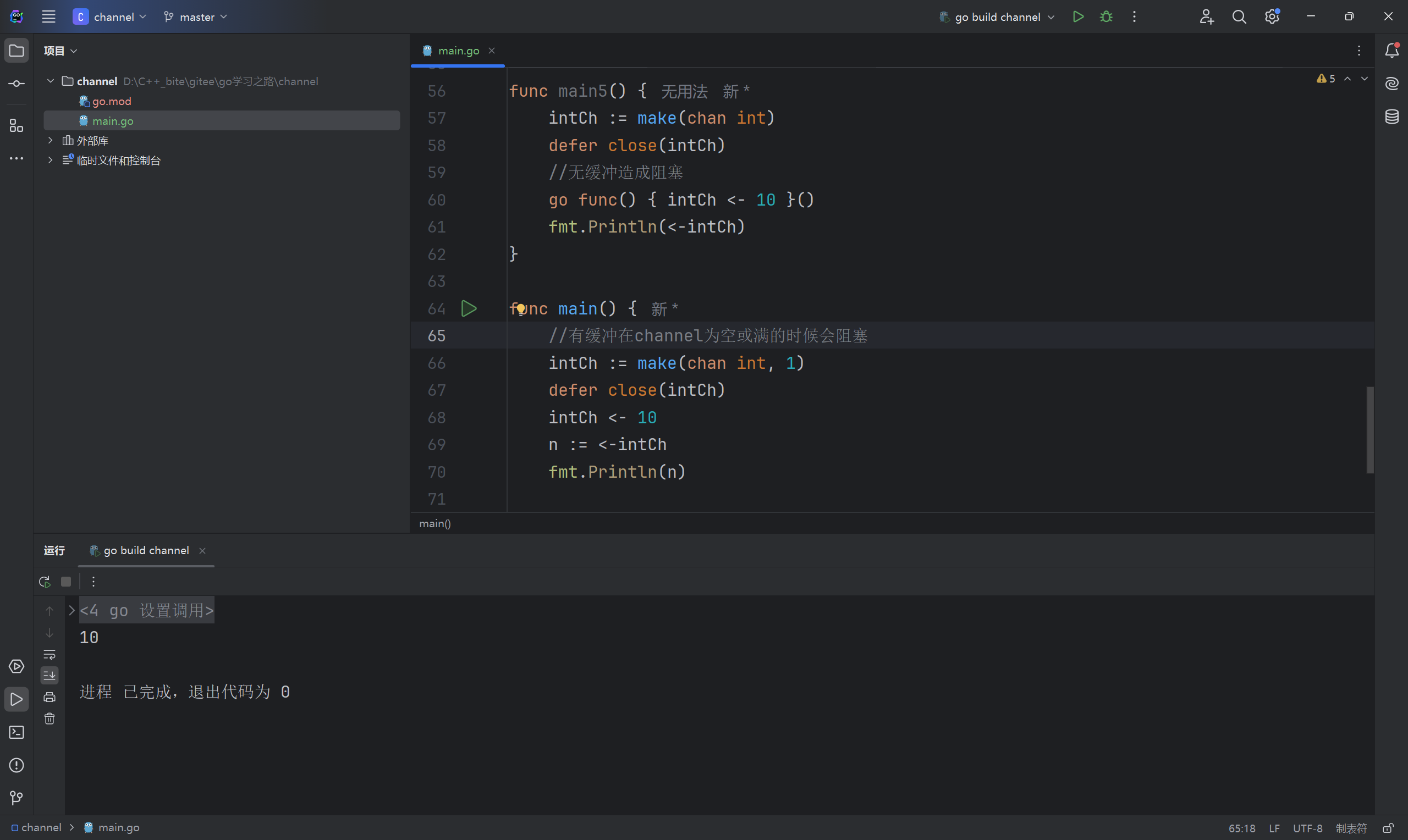
有缓冲的channel就类似与一个队列了,它会在队列为满或者队列为空的时候被阻塞。写入的时候如果缓冲区没满就可以继续写入,直到缓冲区满了写入才会被阻塞;读取的时候如果缓冲区有数据就不会被阻塞,只有缓冲区为空的时候读取才会被阻塞。
下面的例子就是写了个缓冲区大小为1的管道,可以同步的写入一个数据,然后再读出来,不会像无缓冲内样阻塞。
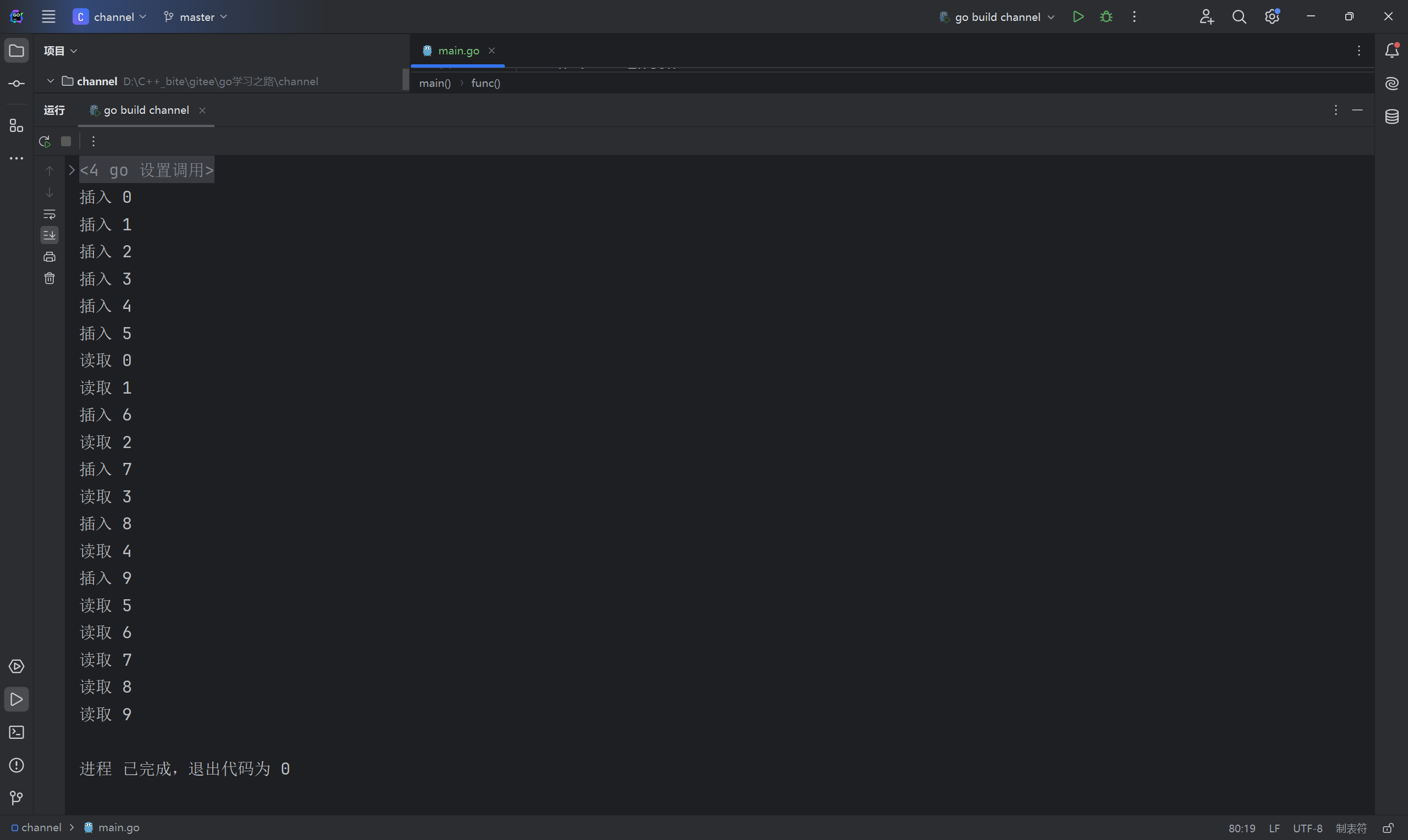
这里总共创建了 3 个管道,一个有缓冲管道用于协程间通信,两个无缓冲管道用于同步父子协程的执行顺序。负责读的协程每次读取之前都会等待 1 毫秒,负责写的协程一口气做多也只能写入 5 个数据,因为管道缓冲区最大只有 5,在没有协程来读取之前,只能阻塞等待。
go
func main7() {
ch := make(chan int, 5)
chR := make(chan struct{})
chW := make(chan struct{})
defer func() {
close(ch)
close(chR)
close(chW)
}()
go func() {
for i := 0; i < 10; i++ {
ch <- i
fmt.Println("插入", i)
}
chW <- struct{}{}
}()
go func() {
for i := 0; i < 10; i++ {
fmt.Println("读取", <-ch)
time.Sleep(time.Millisecond)
}
chR <- struct{}{}
}()
<-chW
<-chR
}
通过内置函数 len 可以访问管道缓冲区中数据的个数,通过 cap 可以访问管道缓冲区的大小。
go
func main() {
ch := make(chan int, 5)
ch <- 1
ch <- 2
ch <- 3
fmt.Println(len(ch), cap(ch))
}此处我们可以利用无缓冲设计出一个让主协程等待子协程执行完毕在退出的程序。
那就是创建个无缓冲channel然后在子协程的最后进行写入,在主协程的最后进行读取,这样当子协程没执行完之前,主协程的读channel就会阻塞,直到子协程往channel里写数据。
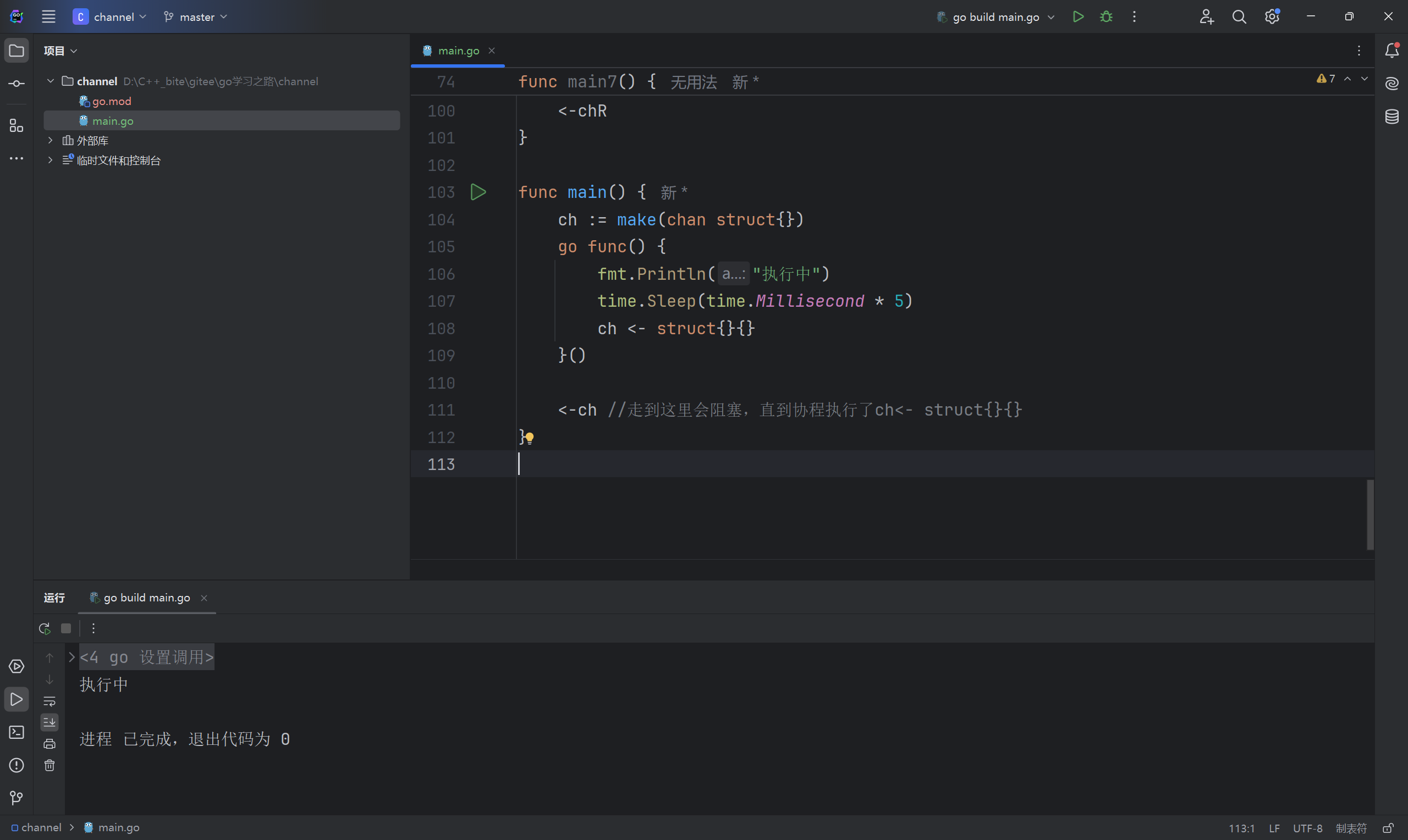
同样可以利用channel模仿互斥锁,类似于信号量:
go
var count = 0
// 缓冲区大小为1的管道
var lock = make(chan struct{}, 1)
func add() {
//加锁
lock <- struct{}{}
count += 1
//解锁
<-lock
}
func sub() {
//加锁
lock <- struct{}{}
count -= 1
//解锁
<-lock
}5. 单向管道
双向管道指的是既可以写,也可以读,即可以在管道两边进行操作。单向管道指的是只读或只写的管道,即只能在管道的一边进行操作。手动创建的一个只读或只写的管道没有什么太大的意义,因为不能对管道读写就失去了其存在的作用。单向管道通常是用来限制通道的行为,一般会在函数的形参和返回值中出现,例如用于关闭通道的内置函数 close 的函数签名就用到了单向通道。
go
func close(c chan<- Type)或者time包下的after函数(作用是在一段时间后向返回的管道内发送时间)
go
func After(d Duration) <-chan Timeclose 函数的形参是一个只写通道,After 函数的返回值是一个只读通道,所以单向通道的语法如下:
- 箭头符号 <- 在前,就是只读通道,如 <-chan int
- 箭头符号 <- 在后,就是只写通道,如 chan<- string
当尝试对只读的管道写入数据时,将会无法通过编译
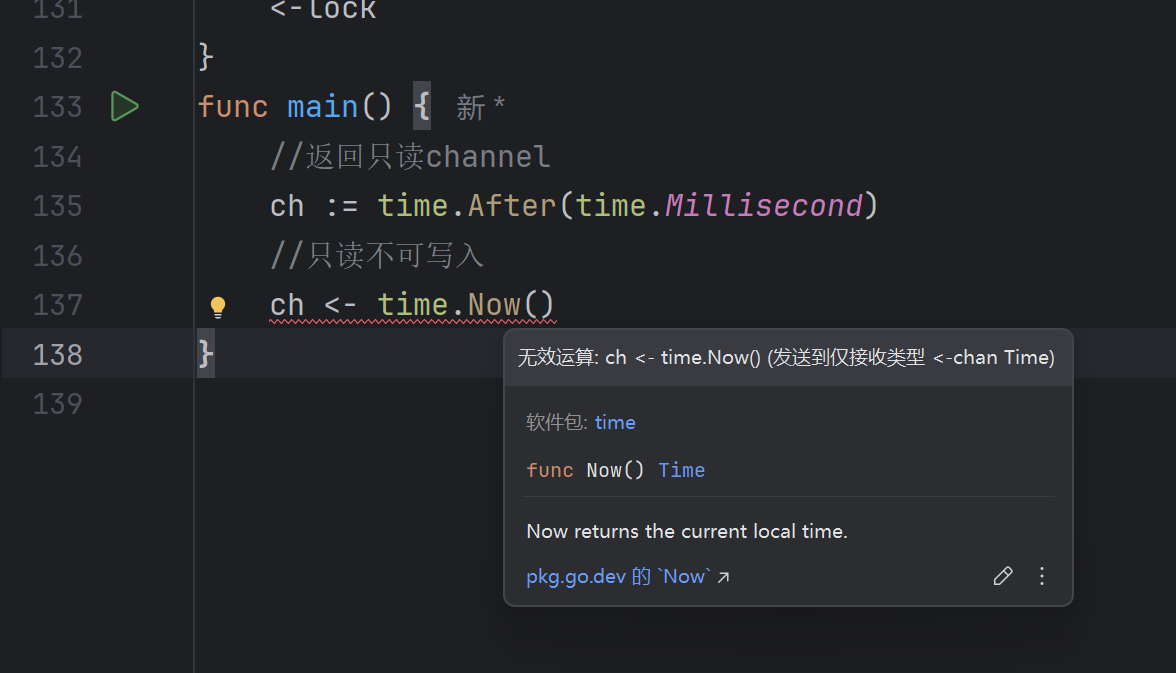
双向管道可以转换为单向管道,反过来则不可以。通常情况下,将双向管道传给某个协程或函数并且不希望它读取/发送数据,就可以用到单向管道来限制另一方的行为。
go
func main10() {
ch := make(chan int, 1)
write(ch)
fmt.Println(<-ch)
}
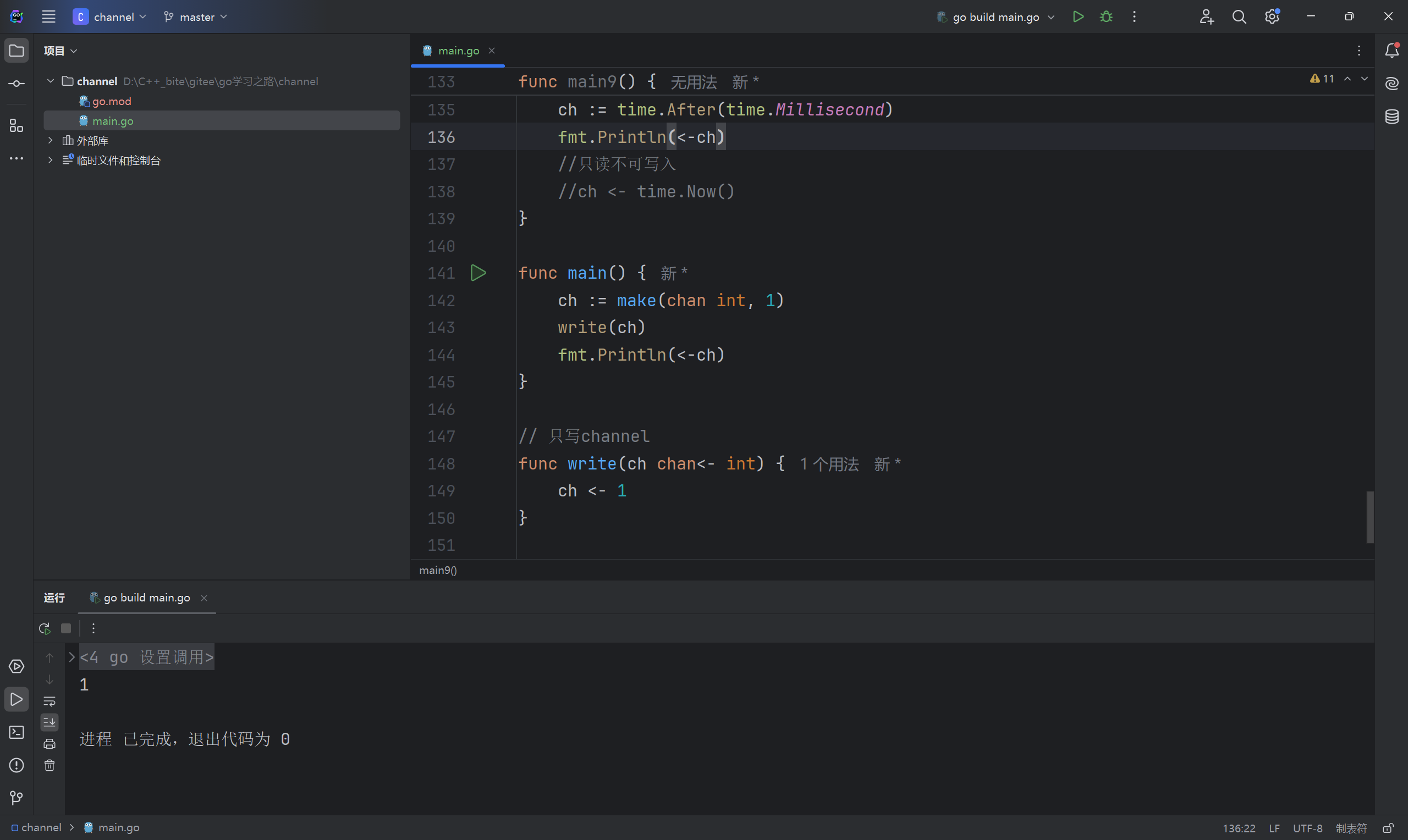
// 只写channel
func write(ch chan<- int) {
ch <- 1
}
6. for range
for range会不断从channel里读取数据,当管道缓冲区为空或无缓冲时,就会阻塞等待,直到有其他协程向管道中写入数据才会继续读取数据。
go
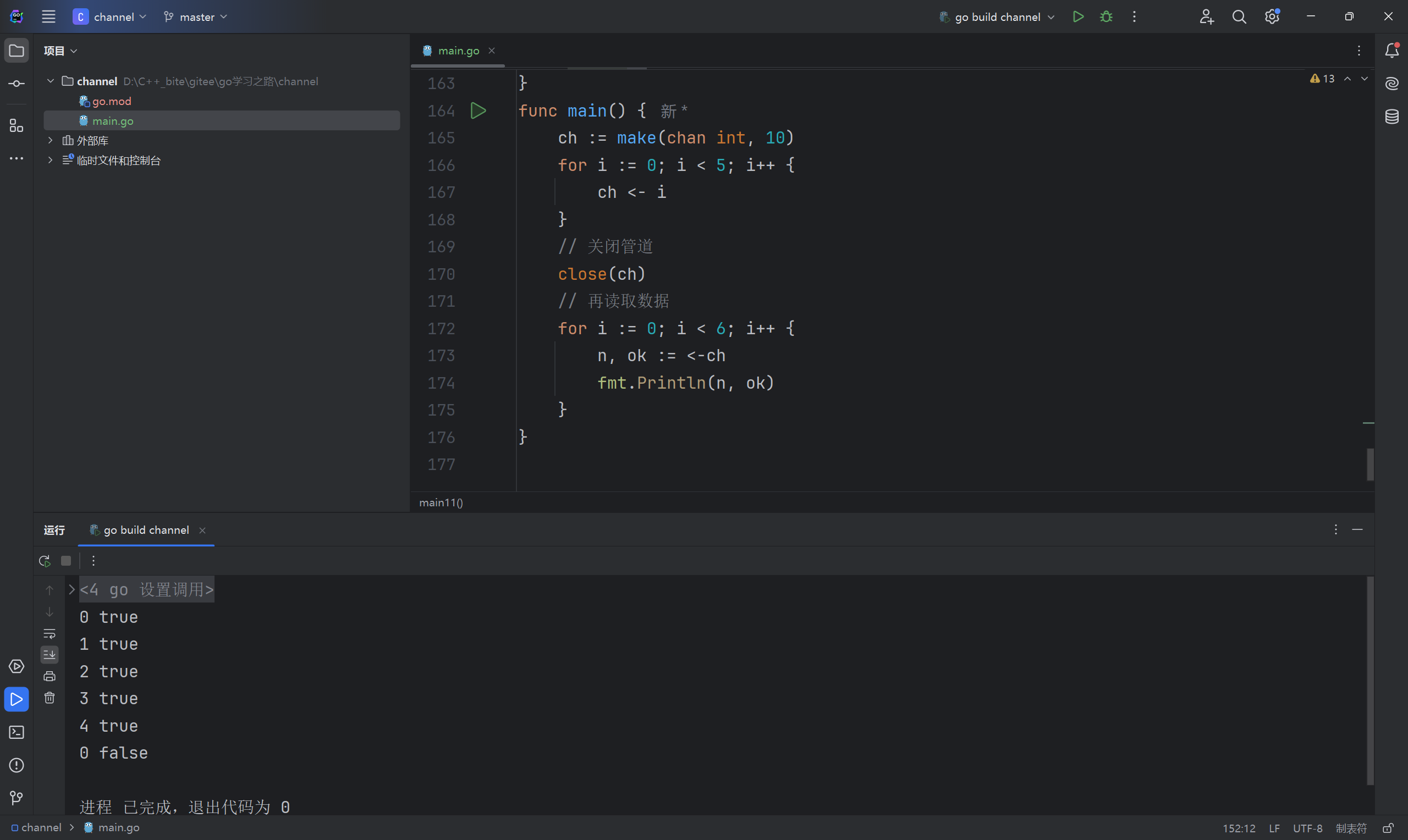
func main11() {
ch := make(chan int, 10)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
}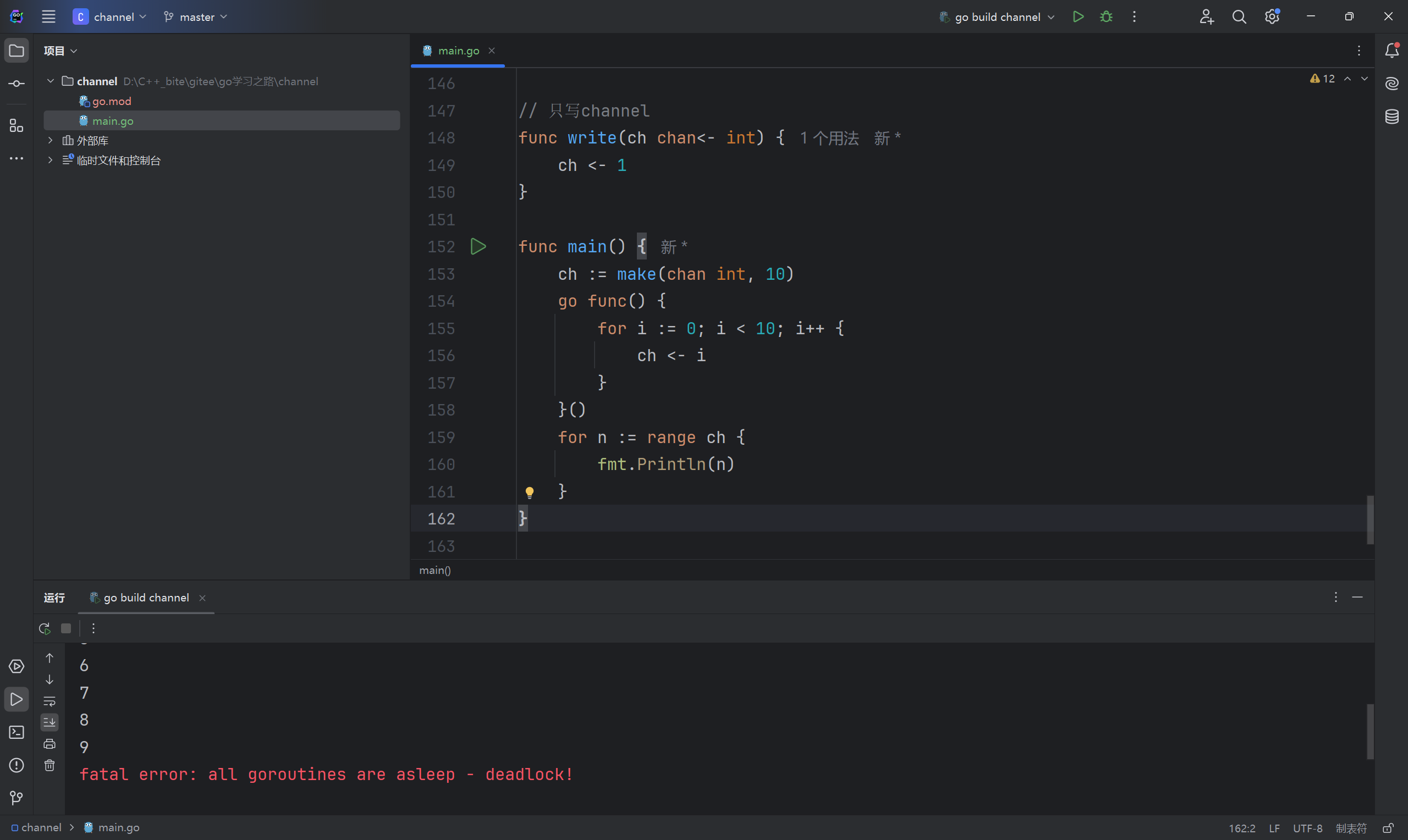
发生死锁的原因是子协程结束了,但是主协程for range还是阻塞等着读取数据。
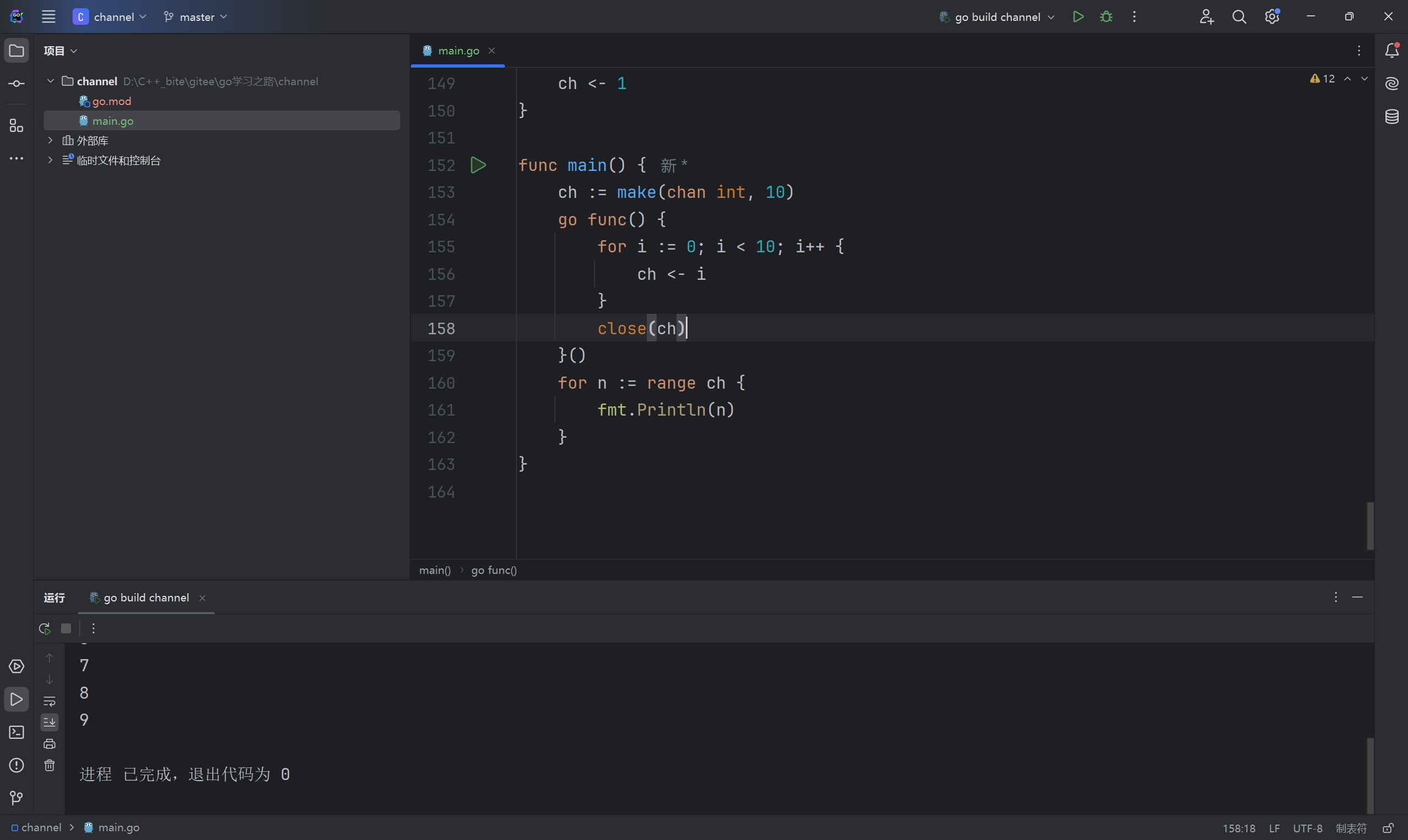
写完后关闭管道,上述代码便不再会发生死锁。前面提到过读取管道是有两个返回值的,for遍历管道时,当无法成功读取数据时,便会退出循环。第二个返回值指的是能否成功读取数据,而不是管道是否已经关闭,即便管道已经关闭,对于有缓冲管道而言,依旧可以读取数据,并且第二个返回值仍然为 true。