从Ascend C算子开发视角看CANN的"软硬协同"
- 写在最前面
-
- 引言:当软件试图控制"流水线"
- [一、 编程模型视角:软件定义的流水线](#一、 编程模型视角:软件定义的流水线)
-
- [1.Host 侧:Tiling(切分)的智慧](#1.Host 侧:Tiling(切分)的智慧)
- [2. Device 侧:Kernel(核函数)的执行](#2. Device 侧:Kernel(核函数)的执行)
- [二、 物理底座:认识你的"施工队" (AI Core)](#二、 物理底座:认识你的“施工队” (AI Core))
- [三、 存储与搬运:一场"螺蛳壳里做道场"的游戏](#三、 存储与搬运:一场“螺蛳壳里做道场”的游戏)
- [四、 核心脉络:典型数据流与指令流](#四、 核心脉络:典型数据流与指令流)
-
- [1. 典型数据流 (Data Flow)](#1. 典型数据流 (Data Flow))
- [2. 典型指令流 (Instruction Flow)](#2. 典型指令流 (Instruction Flow))
- [五、 Ascend C编程模型:流水线上的"艺术"](#五、 Ascend C编程模型:流水线上的“艺术”)
-
- 1、SPMD:一生万物
- [2、核心范式:TQue 与 流水线](#2、核心范式:TQue 与 流水线)
- 3、同步机制:红绿灯
- [六、 总结:Ascend C 到底在控制什么?](#六、 总结:Ascend C 到底在控制什么?)

🌈你好呀!我是 是Yu欸 🚀 感谢你的陪伴与支持~ 欢迎添加文末好友 🌌 在所有感兴趣的领域扩展知识,不定期掉落福利资讯(*^▽^*)
写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
引言:当软件试图控制"流水线"
在AI算力飙升的今天,我们手里的NPU(神经网络处理器)越来越像一座精密的巨型工厂。以往,我们习惯用"黑盒"的方式去使用它------喂入数据,等待结果。但在大模型训练和极致推理优化的深水区,这种模式行不通了。
为什么我的算子跑不满算力?为什么数据搬运占用了80%的时间?
要回答这些问题,我们需要打破软件和硬件的界限。
在昇腾 CANN (Compute Architecture for Neural Networks) 的架构体系中,Ascend C 编程语言被推向了舞台中央。虽然 CANN 依然保留着经典的五层架构作为坚实的底座,但对于追求极致性能的算子开发者而言,视角已经从"调用层级"转向了更扁平、更直接的 "主机-设备(Host-Device)协同编程模型"。
站在 算子开发者 的视角,看一看基于 Ascend C 的代码是如何在底层 达芬奇(Da Vinci)架构 的物理流水线上流动的。
一、 编程模型视角:软件定义的流水线
图注:Ascend C 算子逻辑架构。左侧 Host 负责切分策略(Tiling),右侧 Device (Kernel) 负责计算执行。图片来源: 昇腾社区 CANN 8.3 文档
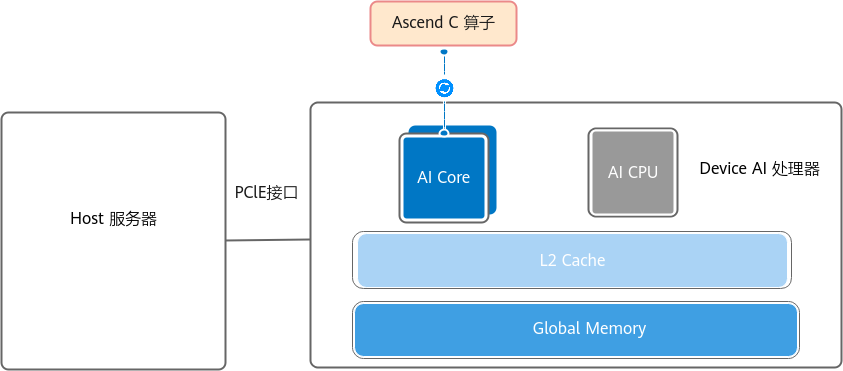
当我们谈论"CANN的新架构体验"时,我们实际上是在谈论 Ascend C 的 SPMD(单程序多数据)编程模型 。这不是替代了CANN原有的架构图,而是将物理硬件的抽象直接映射到了代码逻辑中。
核心逻辑非常简单:Host 侧决定"怎么切",Device 侧决定"怎么算"。
1.Host 侧:Tiling(切分)的智慧
在处理动态 Shape(形状可变)的场景时,AI Core 内部有限的缓存(L1/UB 通常仅几百 KB)无法一次性容纳巨大的 Tensor(几百 MB)。
- 痛点:数据太大,"胃口"太小。
- 解决 :Host 侧运行的 Tiling 函数,本质上是在计算**"这一刀该切多大"**。它根据当前输入数据的 Shape 和硬件的 Core 数量,动态计算出
BlockDim(核数)和TileSize(切片大小)。 - 注意:虽然 Tiling 是高性能算子开发的标配,但它并非强制。对于极其简单的静态小算子,你甚至可以硬编码,但在通用的高性能场景下,Tiling 是通过软件挖掘硬件并行度的关键一环。
2. Device 侧:Kernel(核函数)的执行
Kernel 函数是真正的"打工人"。一份 C++ 代码会被复制到芯片上成千上万个 AI Core 中并行执行。每个 Core 领取属于自己的任务包,只处理自己那一亩三分地的数据。
二、 物理底座:认识你的"施工队" (AI Core)
一切软件逻辑,最终都要落地到硬件执行。在昇腾处理器中,最小的计算与调度单元被称为 AI Core。Ascend C 算子(Kernel)最终就是在这里运行。
为了实现极致的能效比,AI Core 内部组建了一支分工明确、高度专业化的"施工队":
1、三大计算工种
这三类单元虽然都在 AI Core 内部,但它们的职责完全不同:
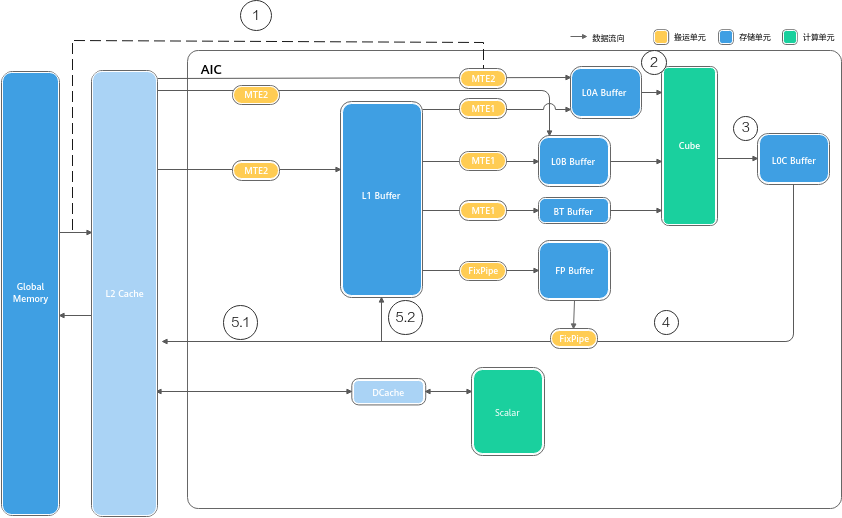
- Cube Unit(矩阵搬砖工):
它是绝对的算力担当,专门干重活。它只做一件事:矩阵乘法。哪怕是简单的加法,它也得凑成矩阵去算。
它的特点是"吞吐量巨大",一铲子下去(一个指令周期),能算完一个 16 × 16 × 16 16\times16\times16 16×16×16 的立方体运算。
它比较挑剔,原料必须放在 L0 Buffer(L0A/L0B)里才肯干活。
图注:Cube计算单元数据访问。亮部分为Cube计算单元及其访问的存储单元,其中L0A存储左矩阵,L0B存储右矩阵,L0C存储矩阵乘的结果和中间结果。图片来源: 昇腾社区 CANN 8.3 文档
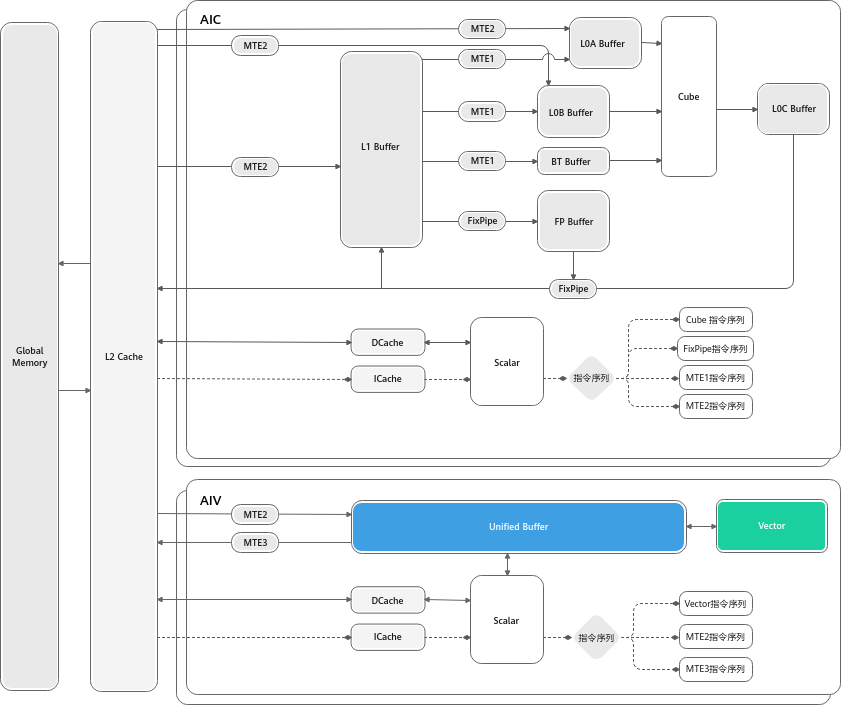
- Vector Unit(向量精细工):
它负责精细活。Cube干不了的非矩阵运算(如激活函数ReLU、归一化LayerNorm、倒数Reciprocal)都归它管。
它的特点是"灵活",支持SIMD(单指令多数据),一次处理一条向量。
它的工作台是 Unified Buffer (UB),所有数据必须先搬到 UB 才能被处理。
图注:__Vector计算单元数据访问。Vector所有计算的源数据以及目标数据都要求存储在Unified Buffer中,Vector__指令__的首地址和操作长度有对齐要求,通常要求32B对齐,具体对齐要求参考__API__的约束描述。图片来源: 昇腾社区 CANN 8.3 文档
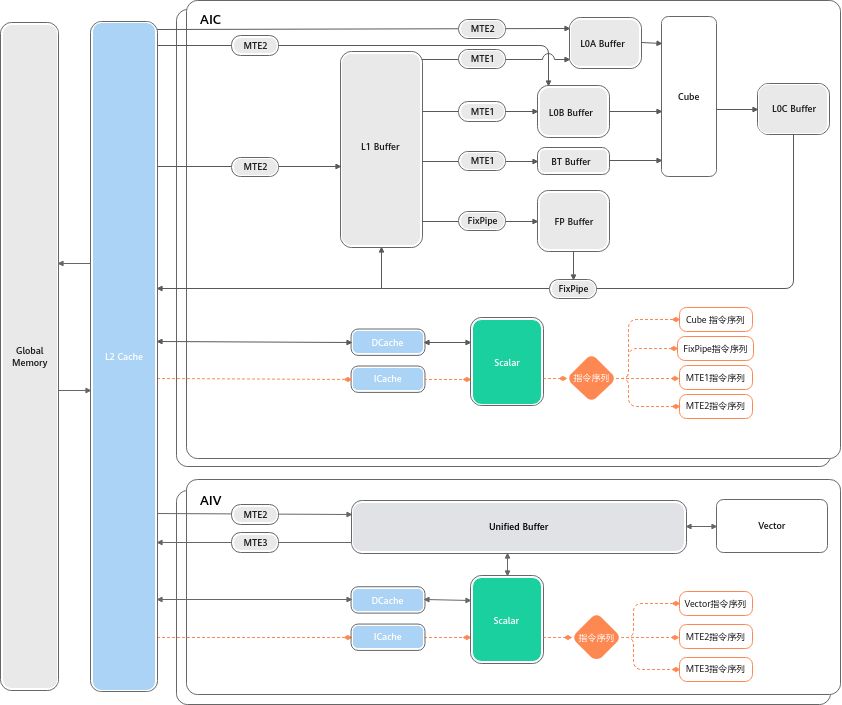
- Scalar Unit(工头):
它就是AI Core里的小CPU。它不直接干重活,而是负责读代码(指令)、做逻辑判断(if/else)、算地址索引,然后给Cube和Vector派活。
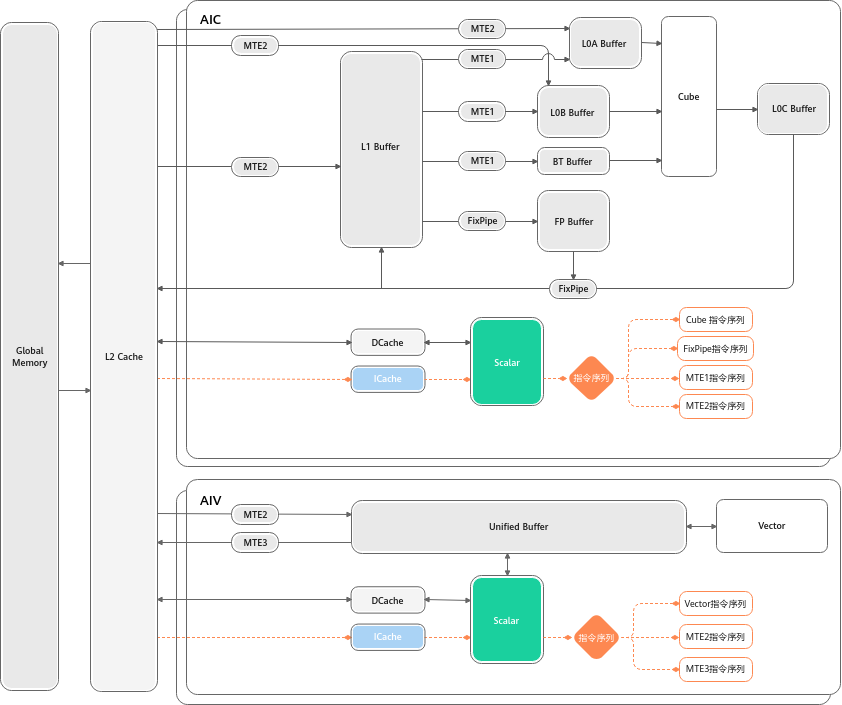
图注:Scalar 对 指令 和数据的访问__。Scalar执行__标量__运算指令时,执行标准的ALU(Arithmetic Logic Unit)语句,ALU需要的代码段和数据段(栈空间)都来自于GM,ICache(Instruction Cache)用于缓存代码段,缓存大小与硬件规格相关,比如为16K或32K,以2K为单位加载;DCache(Data Cache)用于缓存数据段,大小也与硬件规格相关,比如为16K,以Cache Line(64Byte)为单位加载。考虑到核内访问效率最高,应尽量保证代码段和数据段被缓存在ICache和DCache,避免核外访问; 同时根据数据加载单位不同,编程时可以考虑单次加载数据大小,来提升加载效率。例如在DCache加载数据时,当数据__内存__首地址与Cache Line(64Byte)对齐时,加载效率最高。图片来源: 昇腾社区 CANN 8.3 文档
2、两种工作模式
在不同型号的昇腾芯片上,这些工种的组织方式是不一样的,这也是 CANN 文档中提到的"工作模式".
在最新的 Atlas A2 训练/推理系列 产品中,这支队伍出现了一种新的组织形式------分离模式:
- Cube Core (AIC):只有矩阵搬砖工和工头。
**图1 **分离模式示意图(N的取值以硬件平台信息获取接口获取的数值为准)
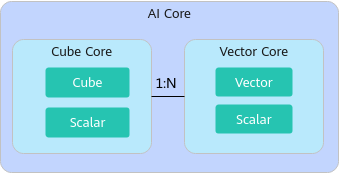
- Vector Core (AIV):只有向量精细工和工头。
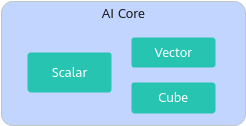
这就像把"砌墙的"和"装修的"分到了不同的车间,互不干扰,由系统按比例(如1:N)组合调用。
**图2 **耦合模式示意图
三、 存储与搬运:一场"螺蛳壳里做道场"的游戏
算力再强,数据供不上也是白搭。AI Core 内部设计了一套极其复杂的"物流系统"来确保存储和计算的平衡。
Ascend C编程最核心的难点,也是CANN架构最精妙的地方,在于对内存的显式管理。
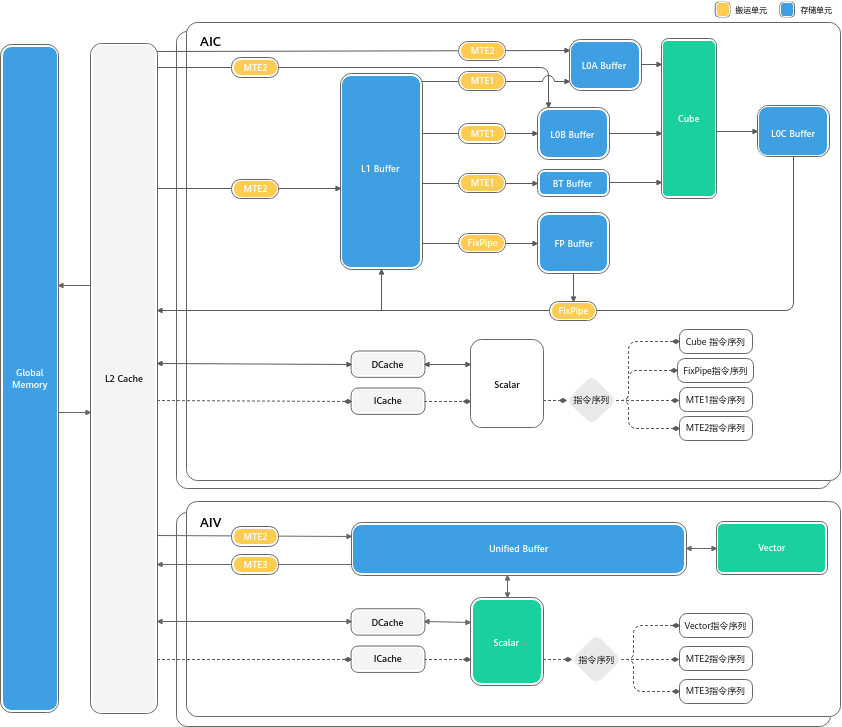
1、仓库(存储单元)
Ascend C 编程中提到的 LocalTensor,实际上就对应着下面这些物理 Buffer:
- Unified Buffer (UB) :Vector 的专用案板。Ascend C 中最常用的 Buffer,几乎所有 Vector 运算都要经过它。
- L1 Buffer :中转仓库。容量较大,用于暂存从片外运进来的数据,给 Cube 备货。
- L0 Buffer (A/B/C) :Cube 的专用料斗。L0A/B 存输入矩阵,L0C 存计算结果。
- BiasTable / Fixpipe Buffer:存放偏置项和量化参数的专用小柜子。
**图注 **存储单元。
2、为什么不能直接用全局内存?
Global Memory (GM) 就像远在郊区的"总仓库",容量大但速度慢。如果Cube计算每一次都要去GM拿数据,那99%的时间都浪费在路上了。
所以,AI Core内部建了几个"临时中转站":
- L1 Buffer:Cube的大型中转站。
- L0 Buffer (A/B/C):Cube的"手边料斗"。L0A/L0B放输入矩阵,L0C放结果。
- Unified Buffer (UB) :Vector的"专用案板"。所有Vector的计算,数据必须先搬到UB里才能开始!
3、MTE与搬运通路
为了把数据在这些仓库之间挪来挪去,硬件里有一组专门的搬运工,叫 MTE (Memory Transfer Engine)。
- MTE1 :负责**"内转"** 。主要路径是
L1 -> L0。 - MTE2:负责把货物从 郊区仓库(GM) 拉到 核心中转站(L1/UB)。
- MTE3:负责把做好的菜从 核心(UB) 运回 郊区仓库(GM)。
- FixPipe:负责**"后处理"** 。Cube 算完的结果(L0C),经过它进行量化或格式转换后,写回 GM 或 L1。
Ascend C的本质,就是写代码指挥MTE、Cube、Vector这三拨人配合工作。
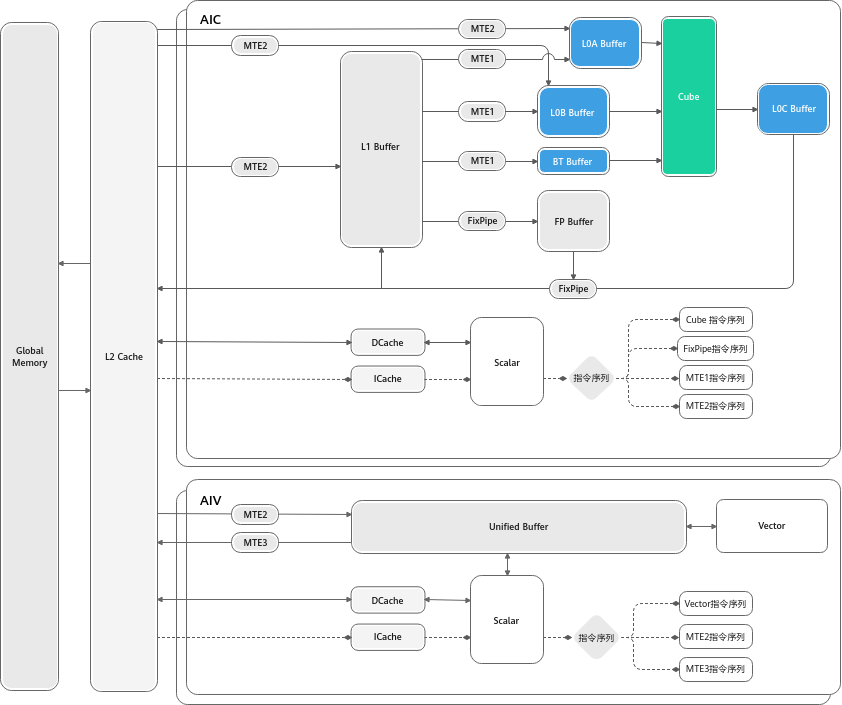
四、 核心脉络:典型数据流与指令流
理解了硬件组件,我们就能看懂数据和指令是怎么流动的。这是写好 Ascend C 代码的关键。
1. 典型数据流 (Data Flow)
Ascend C 的 DataCopy 接口,本质上就是在驱动数据走下面这两条路:
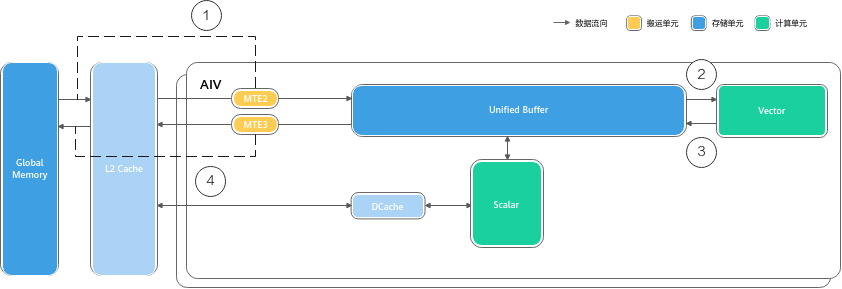
- 路径 A:Vector 计算流(灵巧型)
plain
graph LR
GM[Global Memory] -->|MTE2 搬入| UB
UB -->|Vector 计算| UB
UB -->|MTE3 搬出| GM- 解读: 数据从大仓库直接拉到 UB 案板,切完菜(计算),再直接送回大仓库。路径短,延迟低。
- 路径 B:Cube 计算流(吞吐型)
- 代码段
plain
graph LR
GM -->|MTE2| L1
L1 -->|MTE1| L0A/L0B
L0A/L0B -->|Cube 计算| L0C
L0C -->|FixPipe| GM- 解读: 这是一个深度的流水线。数据要经过多级缓存(L1->L0),虽然路径长,但可以通过双缓冲(Double Buffering) 机制,让搬运和计算完美重叠。
2. 典型指令流 (Instruction Flow)
如果你看懂了指令流,你就明白了为什么昇腾能做到"极致并行"。
所有的指令最初都进入 ICache 。Scalar 单元 读取这些指令后,会像分发传单一样,把不同类型的指令发射到不同的独立队列中:
- Vector****指令 → \rightarrow → 扔进
Vector Queue - **Cube **指令 → \rightarrow → 扔进
Cube Queue - 搬运****指令 → \rightarrow → 扔进
MTE Queue
关键点: 这些队列是并行工作的!
这意味着,当 MTE 正在搬运第 2 块数据时,Vector 可能正在计算第 1 块数据。这就是硬件级的流水线并行。
**图 **指令分类处理机制
五、 Ascend C编程模型:流水线上的"艺术"
理解了硬件,再看Ascend C的代码结构,你就会发现它完全是硬件逻辑的映射。
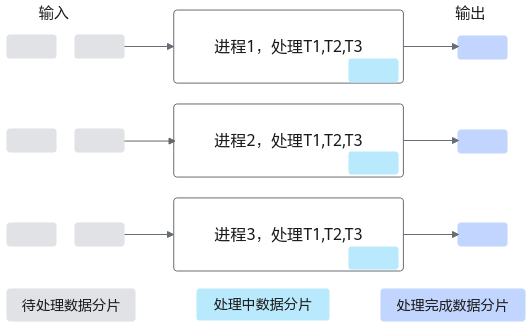
1、SPMD:一生万物
Ascend C采用 SPMD (Single Program, Multiple Data) 模式。
你只需要写一份代码(Kernel),系统会把它复制到芯片上成千上万个AI Core里同时运行。
- 关键点 :每个Core怎么知道自己该干哪部分活?通过
GetBlockIdx()拿到自己的身份证号,然后去Global Memory里认领属于自己的那块数据切片。
**图 **SPMD数据并行示意图
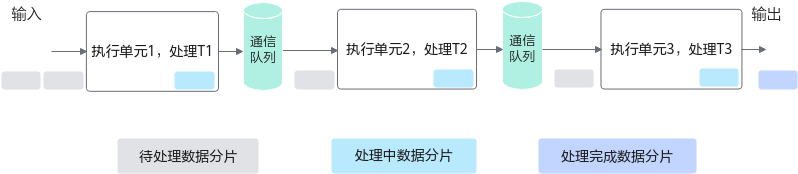
2、核心范式:TQue 与 流水线
怎么让MTE搬运的时候,Cube不闲着?CANN设计了一套标准的流水线(Pipeline)编程范式。
想象一个做菜的过程:买菜(CopyIn) -> 切菜(Compute) -> 上菜(CopyOut)。
如果顺序执行,买菜时厨师在玩手机。
Ascend C引入了 TQue (任务队列) 来实现流水线并行:
- 阶段1 :MTE把第一波菜买回来,放进
Q_in队列。 - 阶段2 :
- Vector从
Q_in拿菜去切。 - 同时,MTE转头去买第二波菜。
- Vector从
- 双缓冲 (Double Buffering):为了极致效率,我们通常申请两块内存(Ping-Pong)。当Vector在处理Buffer A时,MTE正在往Buffer B里写数据。
**图 **流水线并行示意图
3、同步机制:红绿灯
因为大家是并行干活的,必须有红绿灯(同步)机制。
- EnQue (入队):MTE喊话:"菜买回来了(Buffer已满),厨师你可以拿了!"
- DeQue** (出队)**:厨师喊话:"菜我切完了(Buffer已空),搬运工你可以拿去装下一波菜了!"
在Ascend C代码中,这些复杂的硬件同步逻辑被封装成了简单的 EnQue / DeQue 接口,开发者只要照着模板填空,就能写出跑满流水线的代码。
plain
// ...
namespace AscendC {
class MyKernel {
public:
__aicore__ inline MyKernel() {}
__aicore__ inline void Init(__gm__ uint8_t* src0Gm, __gm__ uint8_t* src1Gm, __gm__ uint8_t* dstGm)
{
src0Global.SetGlobalBuffer((__gm__ half*)src0Gm);
src1Global.SetGlobalBuffer((__gm__ half*)src1Gm);
dstGlobal.SetGlobalBuffer((__gm__ half*)dstGm);
pipe.InitBuffer(srcQue0, 1, BLOCK_SIZE * sizeof(half));
pipe.InitBuffer(srcQue1, 1, BLOCK_SIZE * sizeof(half));
pipe.InitBuffer(dstQue0, 1, BLOCK_SIZE * sizeof(half));
}
__aicore__ inline void Process()
{
for (int i = 0; i < REPTIMES; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t i)
{
srcQue0.AllocTensor<half>(src0Local);
srcQue1.AllocTensor<half>(src1Local);
DataCopy(src0Local, src0Global[i*BLOCK_SIZE], BLOCK_SIZE);
DataCopy(src1Local, src1Global[i*BLOCK_SIZE], BLOCK_SIZE);
srcQue0.EnQue(src0Local);
srcQue1.EnQue(src1Local);
}
__aicore__ inline void Compute(int32_t i)
{
srcQue0.DeQue<half>(src0Local);
srcQue1.DeQue<half>(src1Local);
dstQue0.AllocTensor<half>(dstLocal);
Add(dstLocal, src0Local, src1Local, BLOCK_SIZE);
dstQue0.EnQue<half>(dstLocal);
srcQue0.FreeTensor(src0Local);
srcQue1.FreeTensor(src1Local);
}
__aicore__ inline void CopyOut(int32_t i)
{
dstQue0.DeQue<half>(dstLocal);
DataCopy(dstGlobal[i*BLOCK_SIZE], dstLocal, BLOCK_SIZE);
dstQue0.FreeTensor(dstLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 0> srcQue0, srcQue1;
TQue<QuePosition::VECOUT, 0> dstQue0;
GlobalTensor<half> src0Global, src1Global, dstGlobal;
LocalTensor<half> src0Local;
LocalTensor<half> src1Local;
LocalTensor<half> dstLocal;
};
} // namespace AscendC
// ...六、 总结:Ascend C 到底在控制什么?
回看 Ascend C 的编程范式,你会发现它所有的设计都是为了配合上述的硬件逻辑:
- TQue 队列 :是为了配合 Scalar 的指令发射机制,实现不同单元(MTE/Vector)之间的异步****并行。
- PipeBarrier / WaitFlag:是因为不同队列跑得快慢不一,开发者必须在代码里手动插入"红绿灯"(同步指令),防止 Vector 还没算完,MTE 就把数据覆盖了。
- Tiling(切分):是因为 L1/UB 的容量有限(通常几百 KB),必须把以 GB 计的模型数据切成小块,分批塞进 AI Core 处理。
一句话总结: CANN 8.3 带来的 Ascend C,不再试图对开发者隐藏硬件细节,而是将 Cube/Vector/Scalar 的三级流水线 和 L1/L0/UB 的多级缓存 直接暴露出来。
当你写下一行 DataCopy 时,你不是在调函数,你是在指挥 MTE 引擎发动引擎;当你写下一行 SetFlag 时,你是在控制 Scalar 单元按下同步的红灯。 这就是昇腾高性能计算的真相。
欢迎扫码预约昇腾CANN官方直播,获取更多一线解读:


参考资料
- Ascend C 算子开发指南 (CANN 8.3 商用版)
- 链接:(https://www.hiascend.com/document/detail/zh/canncommercial/83RC1/opdevg/Ascendcopdevg/atlas_ascendc_10_0008.html)
- 说明:包含最新的Ascend C编程范式、SPMD模型及流水线同步机制详解。
- 昇腾AI处理器逻辑架构详解
- 链接:(https://www.hiascend.com/document/detail/zh/canncommercial/83RC1/opdevg/Ascendcopdevg/atlas_ascendc_10_00027.html)
- 说明:官方文档关于AI Core、Cube/__Vector__单元及分离/耦合__架构的详细定义。
- 昇腾社区(HiAscend)
- 链接:https://www.hiascend.com
- 说明:获取最新CANN版本更新日志及开发者资源的入口。
hello,我是 是Yu欸。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。