本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网
0 概述
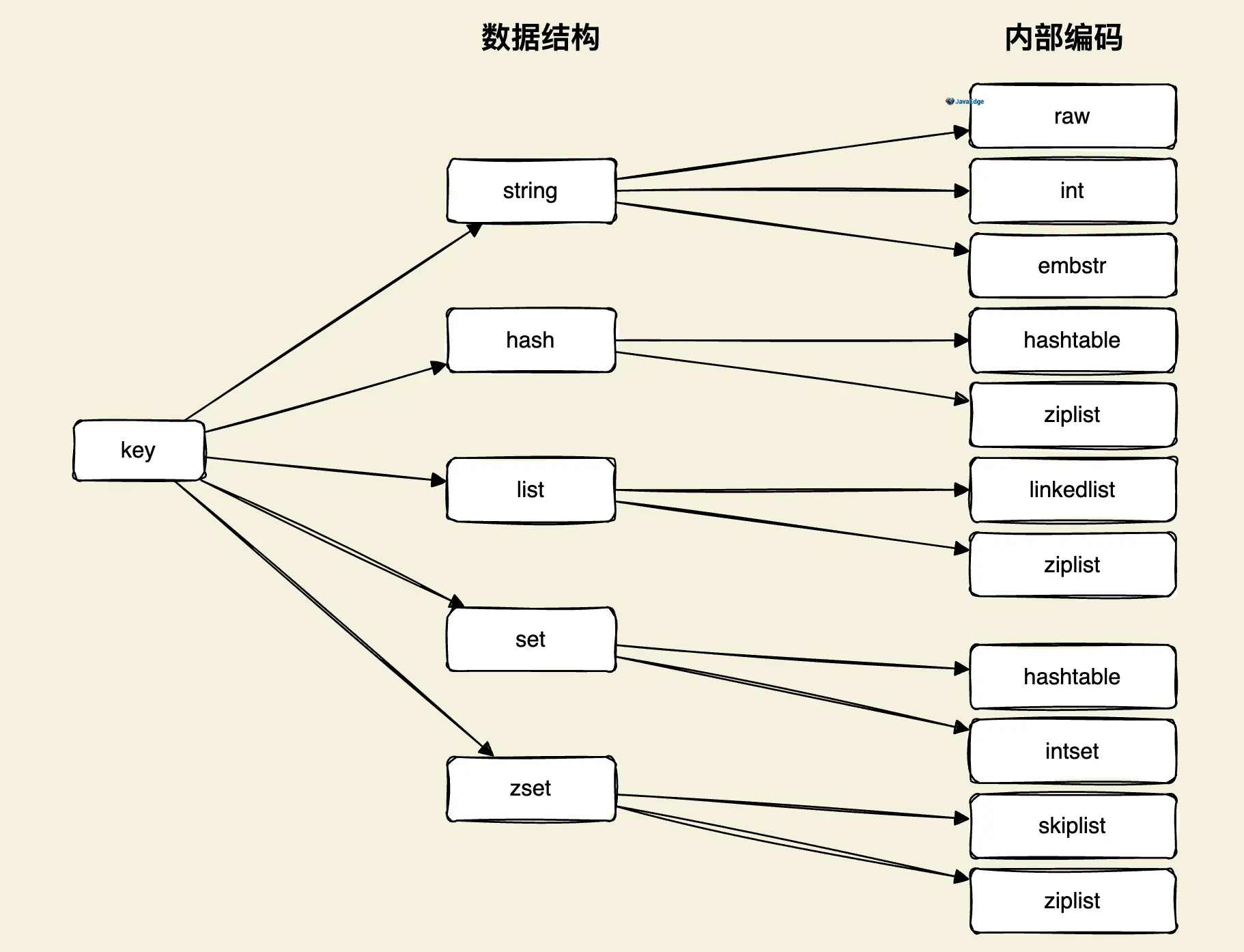
数据结构和内部编码
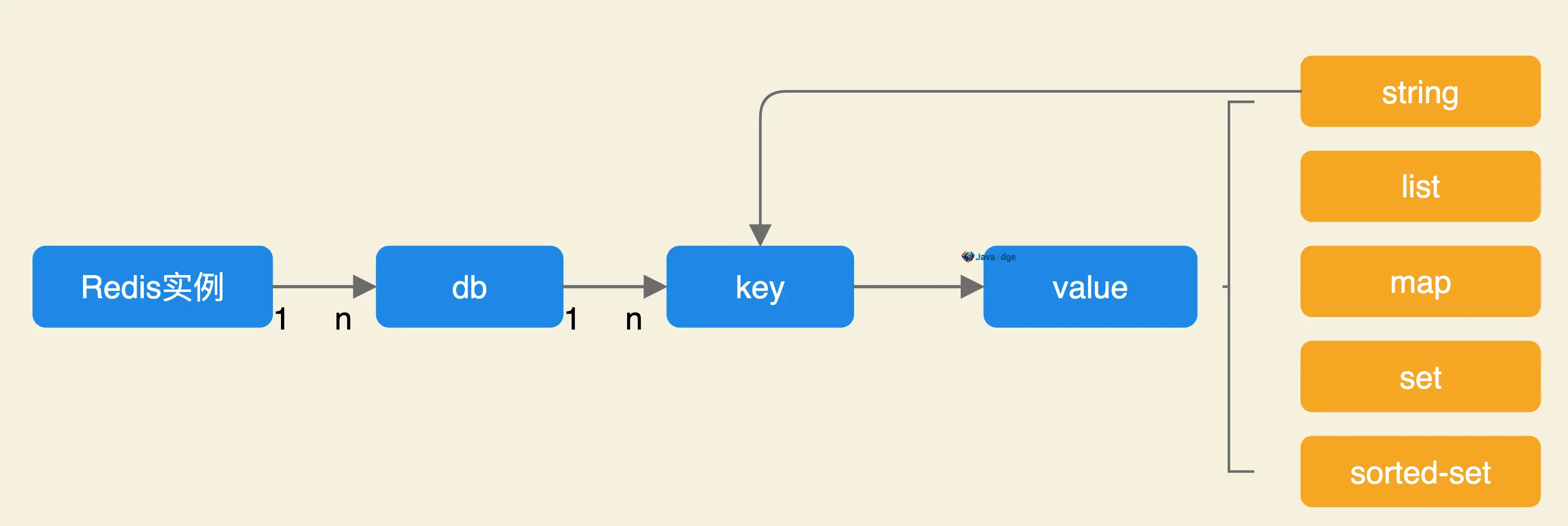
无传统关系型数据库的 Table 模型
schema所对应的db仅以编号区分。同一 db 内,key 作为顶层模型,它的值是扁平化的。即 db 就是key的命名空间。
key的定义通常以 : 分隔,如:Article:Count:1
常用的Redis数据类型有:string、list、set、map、sorted-set
redisObject通用结构
Redis中的所有value 都是以object 的形式存在的,其通用结构:
c
typedef struct redisObject {
// type数据类型:指 string、list 等类型
unsigned type:4;
// 编码方式:这些结构化类型具体实现方式,同一类型可有多种实现。如string可用int实现,也可用char[];list可用ziplist或链表实现
unsigned encoding:4;
/**
* 对象最后一次被访问的时间
* 本对象的空转时长,用于有限内存下长时间不访问的对象清理
* 记录LRU信息,LRU_BITS=24 bits
* LRU time(LRU时钟值) (relative to global lru_clock,相对于全局LRU时钟) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time).
*/
unsigned lru:LRU_BITS;
// 对象引用计数,用于GC
int refcount;
// 指向实际值的指针 数据指针:指向以 encoding 方式实现这个对象实际实现者的地址。如:string 对象对应的SDS地址(string的数据结构/简单动态字符串)
void *ptr;
} robj;单线程

单线程为何这么快?
- 纯内存
- 非阻塞I/O
- 避免线程切换和竞态消耗
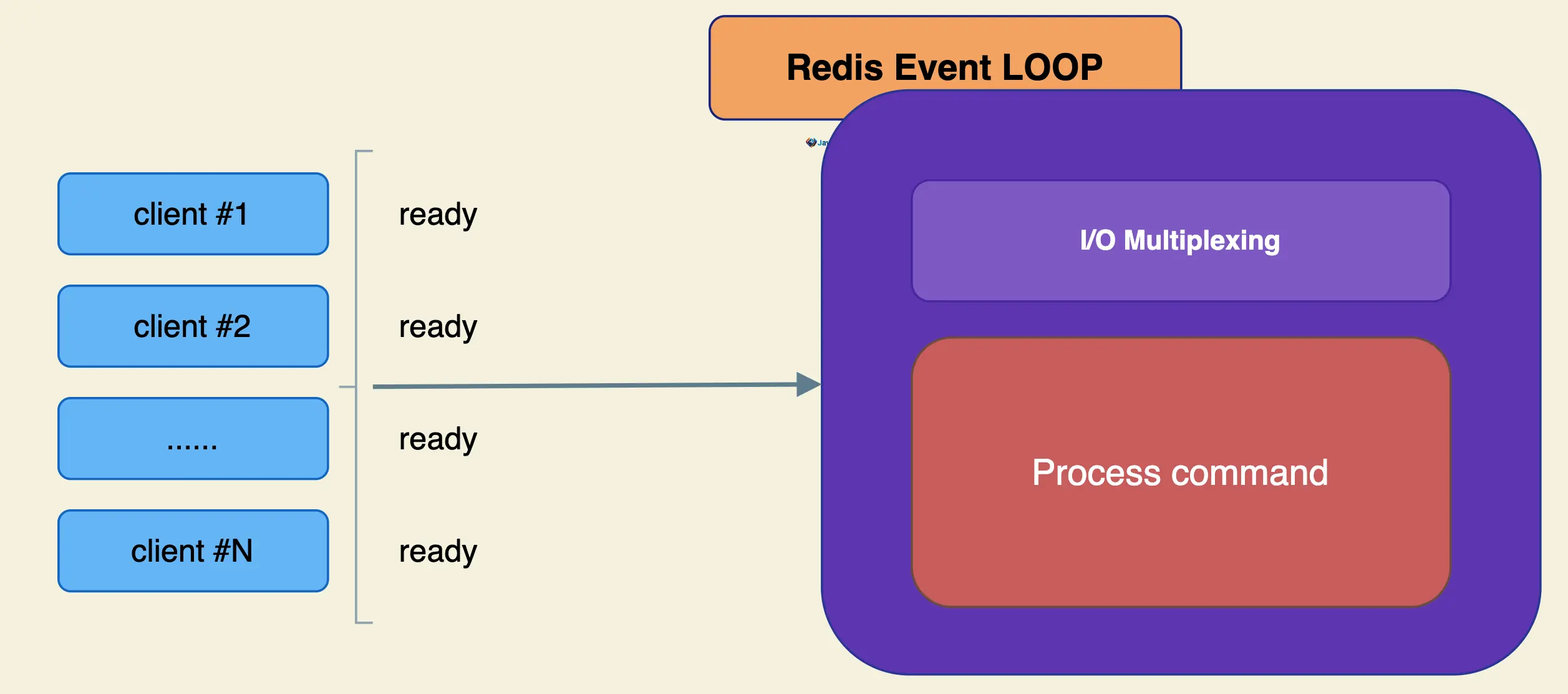
- 一次只运行一条命令
- 拒绝长(慢)命令:keys, flushall, flushdb, slow lua script, mutil/exec, operate big value(collection)
- 其实不是单线程 fysnc file descriptor close file descriptor
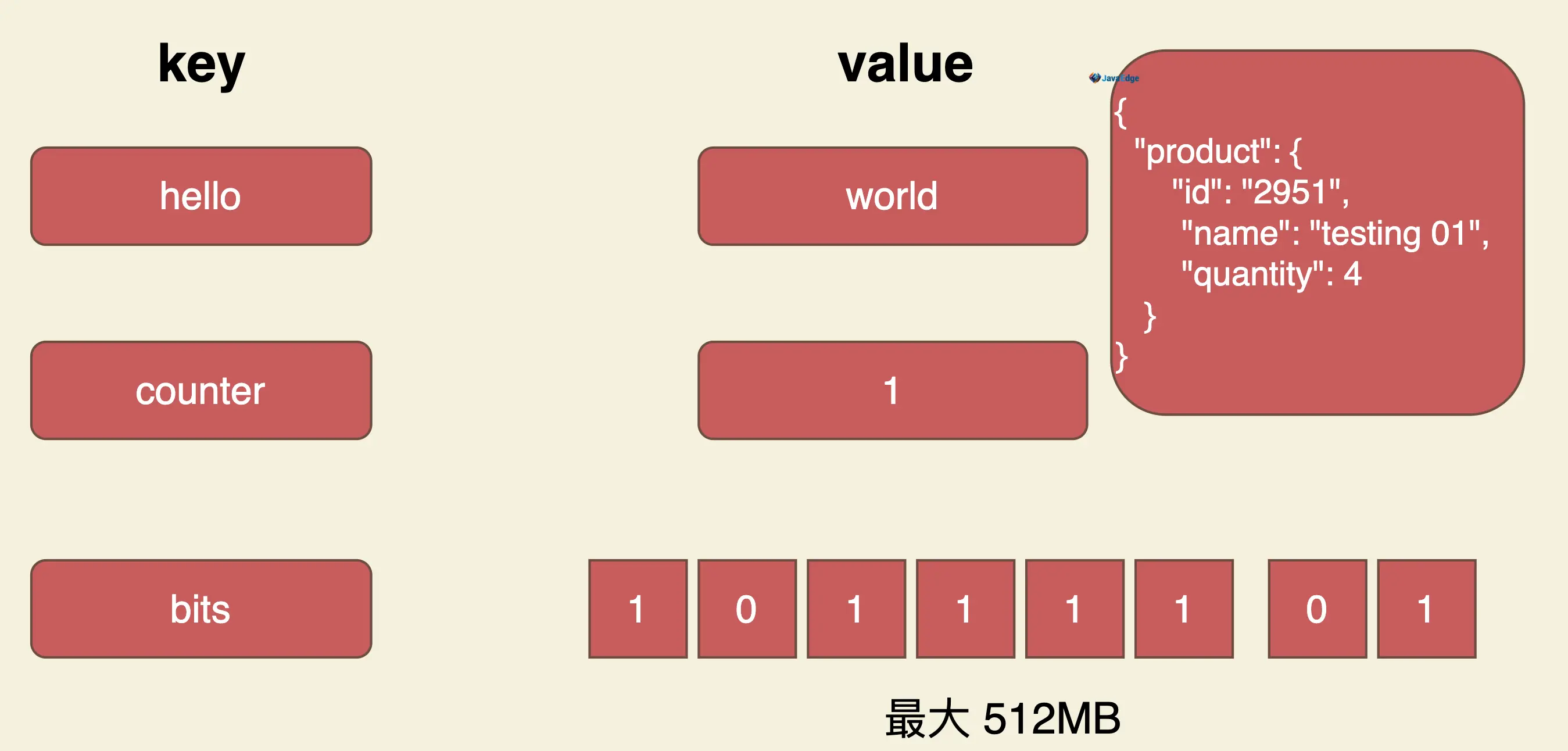
1 string
Redis中的 string 可表示很多语义
- 字节串(bits)
- 整数
- 浮点数
redis会按具体场景完成自动转换,并按需选取底层的实现方式。如整数可由32-bit/64-bit、有符号/无符号承载,以适应不同场景对值域的要求。
字符串键值结构,也能是JSON串或XML结构
内存结构
在Redis内部,string的内部以 int、SDS(简单动态字符串 simple dynamic string)作为存储结构
- int 用来存放整型
- SDS 用来存放字节/字符和浮点型SDS结构
SDS
c
typedef struct sdshdr {
// buf中已经占用的字符长度
unsigned int len;
// buf中剩余可用的字符长度
unsigned int free;
// 数据空间
char buf[];
}结构图:
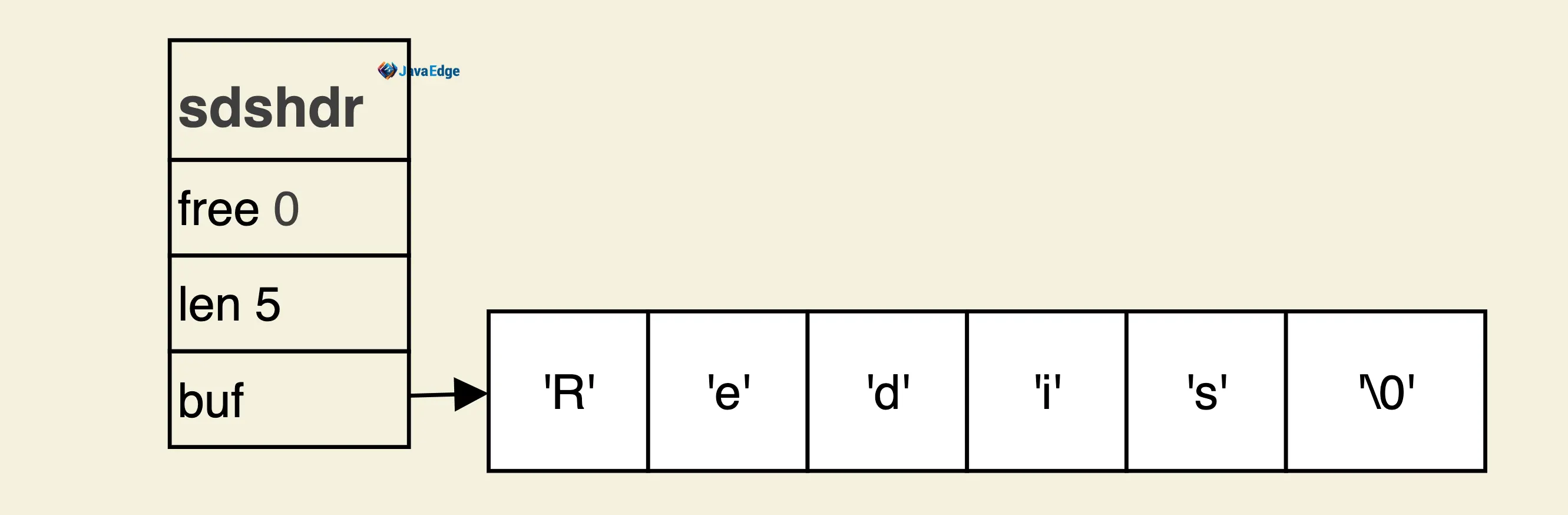
存储内容为"Redis",Redis用类似C语言存储方法,用'\0'结尾(仅是定界符)。 SDS的free 空间大小为0,当free > 0时,buf中的free 区域的引入提升了SDS对字符串的处理性能,可减少处理过程中的内存申请和释放次数。
buf的扩缩容
当对SDS 进行操作时,若超出容量。SDS会对其进行扩容,触发条件如下:
- 字节串初始化时,buf的大小 = len + 1,即加上定界符'\0'刚好用完所有空间
- 当对串的操作后小于1M时,扩容后的buf 大小 = 业务串预期长度 * 2 + 1,也就是扩大2倍。
- 对于大小 > 1M的长串,buf总是留出 1M的 free空间,即2倍扩容,但是free最大为 1M。
字节串与字符串
SDS中存储的内容可以是ASCII 字符串,也可以是字节串。由于SDS通过len 字段来确定业务串的长度,因此业务串可以存储非文本内容。对于字符串的场景,buflen 作为业务串结尾的'\0' 又可以复用C的已有字符串函数。
SDS编码的优化
value在内存中有2个部分:redisObject和ptr指向的字节串部分。创建时,通常要分别为2个部分申请内存,但是对于小字节串,可一次性申请。
incr userid:pageview(单线程:无竞争)。缓存视频的基本信息(数据源在MySQL)
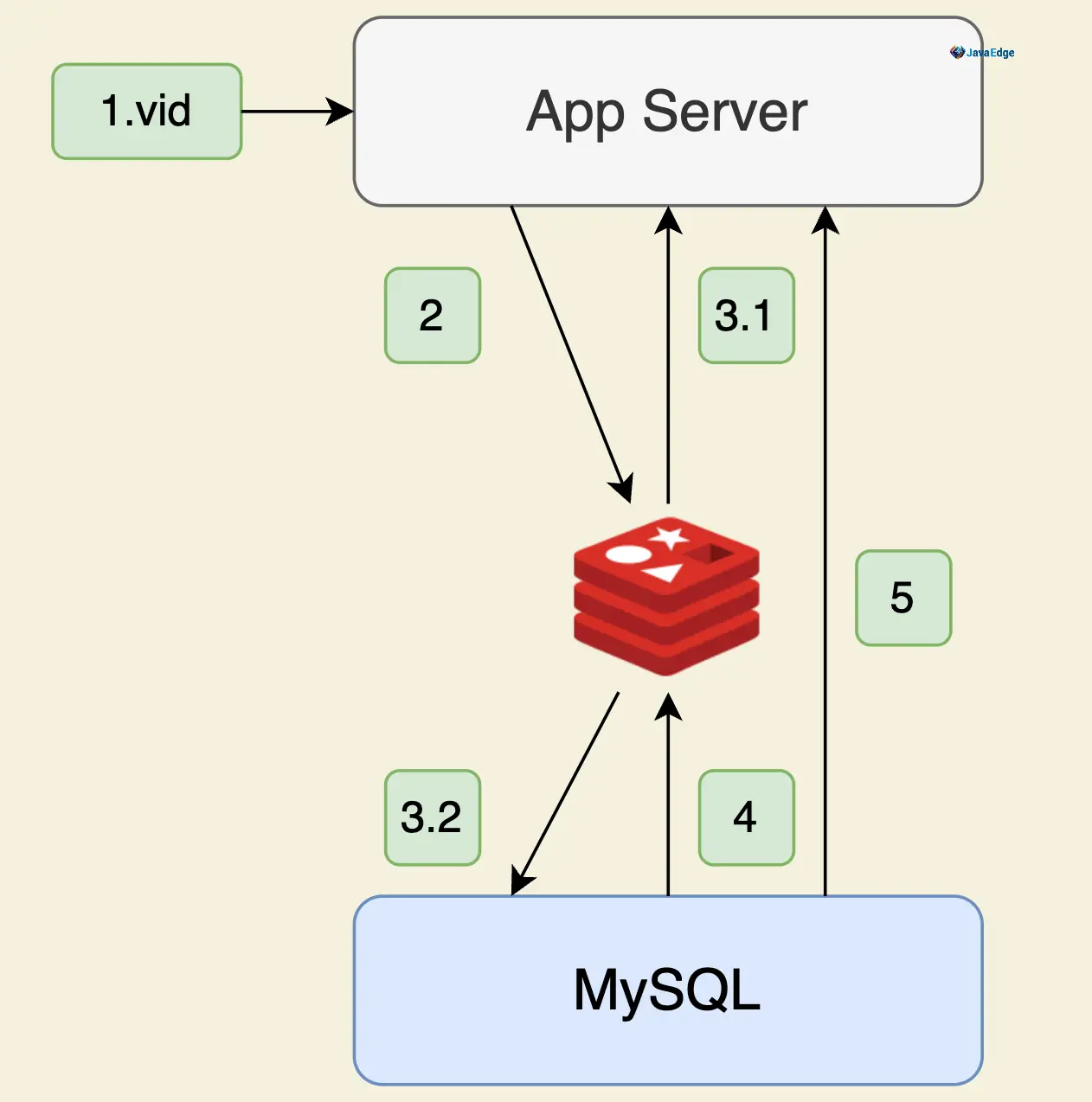
java
public VideoInfo get(Long id) {
String redisKey = redisPrefix + id;
VideoInfo videoInfo e redis.get(redisKey);
if (videoInfo == null) {
videoInfo = mysql.get(id);
if (videoInfo != null) {
// 序列化
redis.set(redisKey serialize(videoInfo)):
}
}
} 实现分布式id生成器
incr id (原子操作)
set setnx setxx
- set key value #不管key是否存在,都设置 o(1)
- setnx key value #key不存在,才设置 o(1)
- set key value xx #key存在,才设置 o(1)
mget mset
mget key1 key2 key3 #批量获取key,原子操作 o(n) mset key1 valuel key2 value2 key3 value3 #批量设置key-value o(n)
n次get

n次get = n次网络时间 + n次命令时间
1次mget
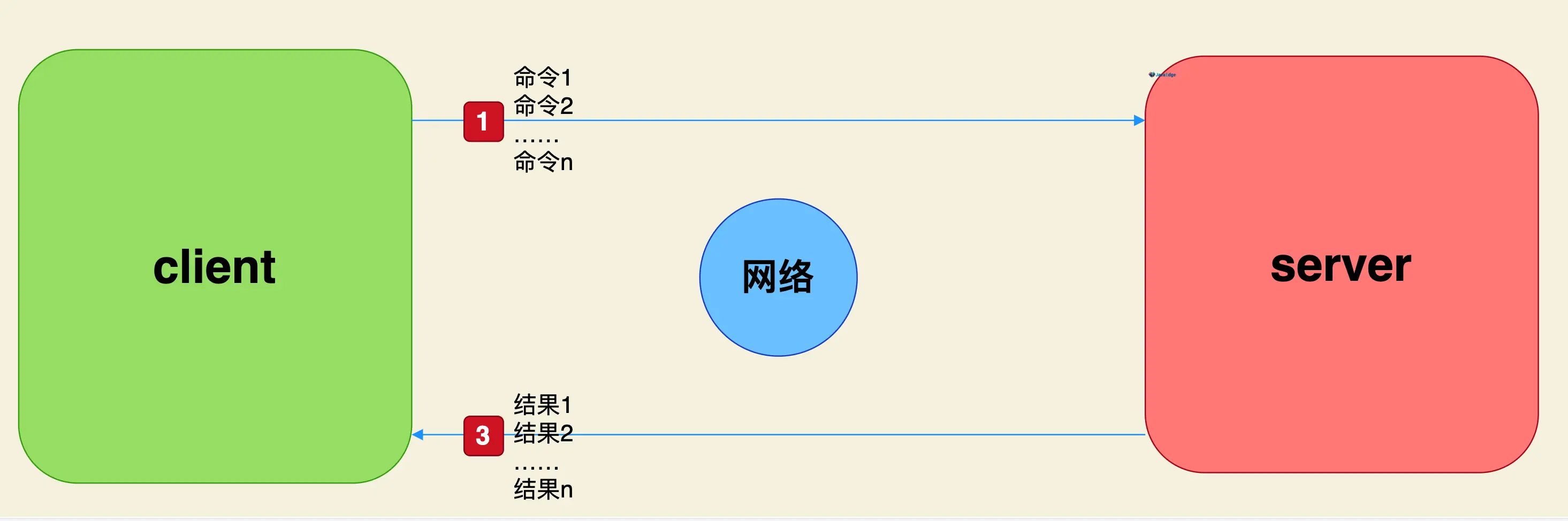
1次mget = 1次网络时间 + n次命令时间
getset、append、strlen
getset key newvalue #set key newvalue 并返回旧的value O(1) append key value #将value追加到旧的value O(1) strlen key #返回字符串的长度(注意中文) O(1)
incrbyfloat getrange setrange
bash
#增加key对应的值3.5 o(1)
incrbyfloat key 3.5
#获取字符串指定下标所有的值 o(1)
getrange key start end
#设置指定下标所有对应的值 o(1)
setrange key index value字符串总结
| 命令 | 含义 | 复杂度 |
|---|---|---|
| set key value | 设置key-value | O(1) |
| get key | 获取key-value | O(1) |
| del key | 删除key-value | O(1) |
| setnx setxx | 根据key是否存在设置key-value | O(1) |
| Incr decr | 计数 | O(1) |
| mget mset | 批量操作key-value | O(n) |
String类型的value基本操作
针对数字类型的操作:
| 操作 | 描述 |
|---|---|
| inc | 将指定key内容+1 |
| decr | 将指定key内容-1 |
| incrby | 将指定key的内容增加指定值 |
| decrby | 将指定key的内容减少指定值 |
| incrbyfloat | 将指定key的内容减少指定的浮点值 |
针对字符串类型的操作:
| 操作 | 描述 |
|---|---|
| append | 将指定字符串添加到key的value后 |
| getrange | 对字符串value做范围截取 |
| setrange | 对字符串的指定start和end 做覆盖操作 |
| strlen | 获取字符串value的长度 |
| getbit | 对字符串value,获取指定偏移量上的bit(位) |
| setbit | 将字符串value视为bit,并设置给定起始位置设置值 |
| bitcount | 将字符串value视为bit,并统计1的数量 |
| bitop | 对多个key的value做位运算,如:XOR、OR、AND、NOT |
string类型value还有一些CAS原子操作,如:get、set、set value nx(如果不存在就设置)、set value xx(若存在就设置)。
String类型是二进制安全的,即在Redis中String类型可包含各种数据,比如一张JPEG图片或者是一个序列化的Ruby对象。一个String类型的值最大长度512M。
场景
- 原子计数器,使用INCR家族命令:INCR, DECR, INCRBY
- 使用APPEND命令给一个String追加内容
- 做一个随机访问的向量(Vector),使用GETRANGE和 SETRANGE
- 使用GETBIT 和SETBIT方法,在一个很小的空间中编码大量的数据或创建一个基于Redis的Bloom Filter 算法
2 List
可从头部(左侧)加入元素,也可以从尾部(右侧)加入元素。有序列表。
可通过lrange命令,即从某元素开始读取多少元素,可基于list实现分页查询,这就是基于redis实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
搞个简单的消息队列,从list头推进去,从list尾拉出来。
List类型中存储一系列String值,这些String按照插入顺序排序。
2.1 数据结构
List 类型的value对象,由 linkedlist 或 ziplist 实现,满足以下任一条件,会从 ziplist 升级为 linkedlist:
- 元素个数 > list-max-ziplist-entries(默认 512)
- 任一元素长度 > list-max-ziplist-value 字节(默认 64 字节)
2.1.1 linkedlist实现
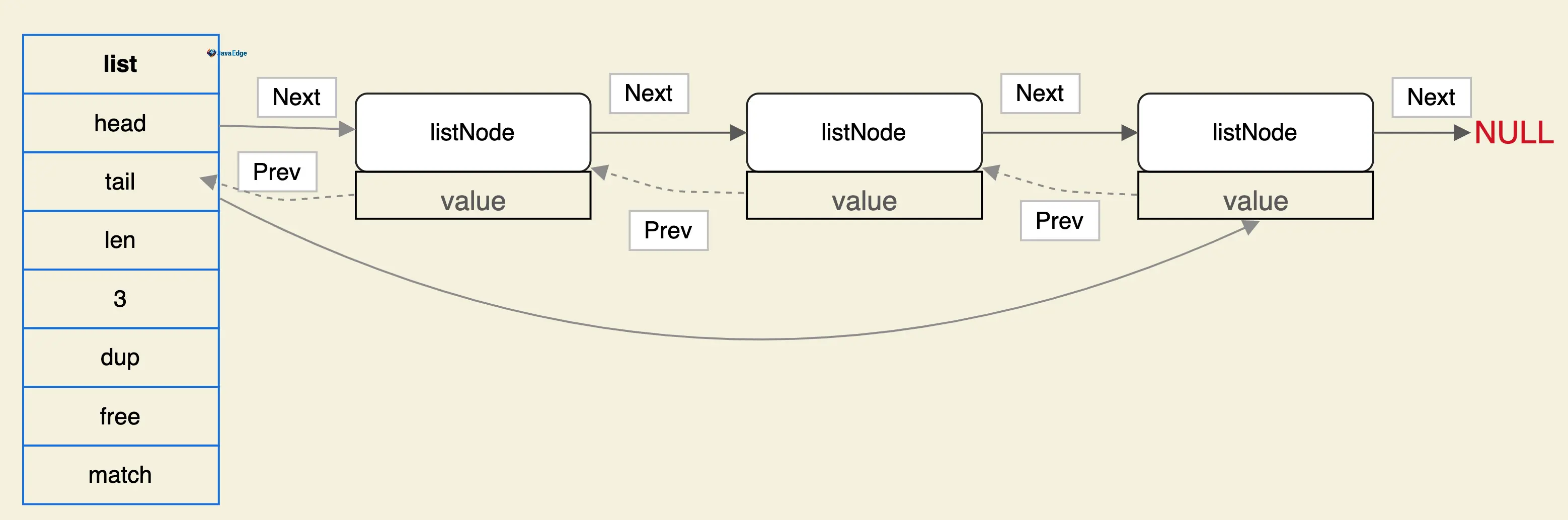
双向链表:
c
typedef struct list {
// 头结点
listNode *head;
// 尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void * ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表长度
unsigned long len;
} list;
// Node节点结构
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;linkedlist结构图:
2.1.2 ziplist实现
存储在连续内存

- zlbytes,ziplist 的总长度
- zltail,指向最末元素
- zllen,元素的个数
- entry,元素内容
- zlend,恒为0xFF,作为ziplist的定界符
linkedlist和ziplist的rpush、rpop、llen的时间复杂度都是O(1):
- ziplist的lpush、lpop都会牵扯到所有数据的移动,时间复杂度为O(N) 由于List的元素少,体积小,这种情况还是可控的。
ziplist的Entry结构:
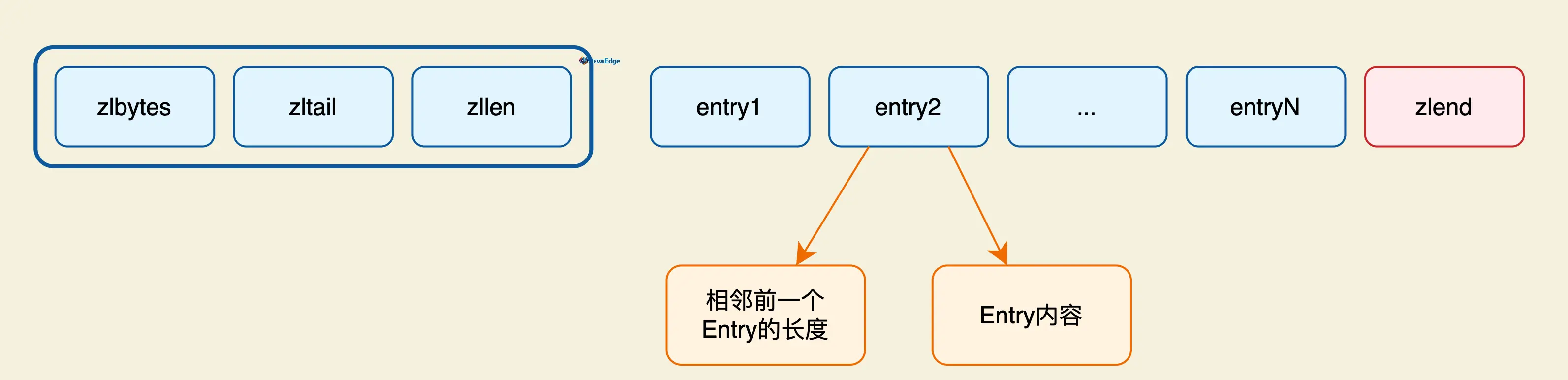
记录前一个相邻的Entry的长度,便于双向遍历,类似linkedlist的prev指针。
ziplist是连续存储,指针由偏移量来承载。Redis中实现了2种方式:
- 当前邻Entry的长度小于254时,prevlen 只用 1 字节存储长度
- 否则,prevlen 用 5 字节存储:第 1 个字节固定为 254(十六进制 FE),表示后面跟着一个 4 字节的长度。 后面 4 个字节用小端序存储前一个 entry 的实际长度。
当前一个Entry长度变化时,可能导致后续的所有空间移动,虽然这种情况发生可能性较小。
Entry内容本身是自描述的,意味着第二部分(Entry内容)包含了几个信息:Entry内容类型、长度和内容本身。而内容本身包含:类型长度部分和内容本身部分。类型和长度同样采用变长编码:
-
00xxxxxx :string类型;长度小于64,0~63可由6位bit 表示,即xxxxxx表示长度
-
01xxxxxx|yyyyyyyy : string类型;长度范围是64, 16383,可由14位 bit 表示,即xxxxxxyyyyyyyy这14位表示长度。
-
10xxxxxx|yy..y(32个y) : string类型,长度大于16383.
-
1111xxxx :integer类型,integer本身内容存储在xxxx 中,只能是1~13之间取值。也就是说内容类型已经包含了内容本身。
-
11xxxxxx :其余情况,Redis用1个字节的类型长度表示了integer的其他几种情况,如:int_32、int_24等。 由此可见,ziplist 的元素结构采用的是可变长的压缩方法,针对于较小的整数/字符串的压缩效果较好
-
LPUSH:头部加入一个新元素
-
RPUSH:尾部加入一个新元素
在一个空的K执行这些操作时,会创建一个新list。当一个操作清空了一个list时,该list对应的key会被删除。若使用一个不存在的K,就会使用一个空list。
bash
LPUSH mylist a # 现在list是 "a"
LPUSH mylist b # 现在list是"b","a"
RPUSH mylist c # 现在list是 "b","a","c" (注意这次使用的是 RPUSH)list的最大长度是2^32 -- 1个元素(4294967295,一个list中可以有多达40多亿个元素)。
从时间复杂度的角度来看,Redis list类型的最大特性是:即使是在list的头端或者尾端做百万次的插入和删除操作,也能保持稳定的很少的时间消耗。在list的两端访问元素是非常快的,但是如果要访问一个很大的list中的中间部分的元素就会比较慢了,时间复杂度是O(N)
2.2 适用场景
粉丝列表
bash
key = 某大v
value = [zhangsan, lisi, wangwu]-
文章的评论列表
-
社交中作为时间表的建模,LPUSH在用户时间线中加入新元素,再用LRANGE获得最近加入的元素
-
可将LPUSH、LTRIM结合用来实现定长列表,列表中只保存最近N个元素
-
做MQ,依赖BLPOP这种阻塞命令
3 Set
类似List,但无序且元素不重复。
向集合中添加多次相同的元素,集合中只存在一个该元素。实际应用中,意味着在添加一个元素前不需要先检查元素是否存在。
支持多个服务器端命令来从现有集合开始计算集合,所以执行集合的交集,并集,差集都很快。
set的最大长度是2^32 -- 1个元素(一个set中可多达40多亿个元素)。
3.1 数据结构
Set在Redis中以intset 或 hashtable存储:
- 对于Set,HashTable的value永远为NULL
- 当Set中只包含整型数据时,采用intset作为实现
intset
核心元素是一个字节数组,从小到大有序的存放元素
c
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;结构图:
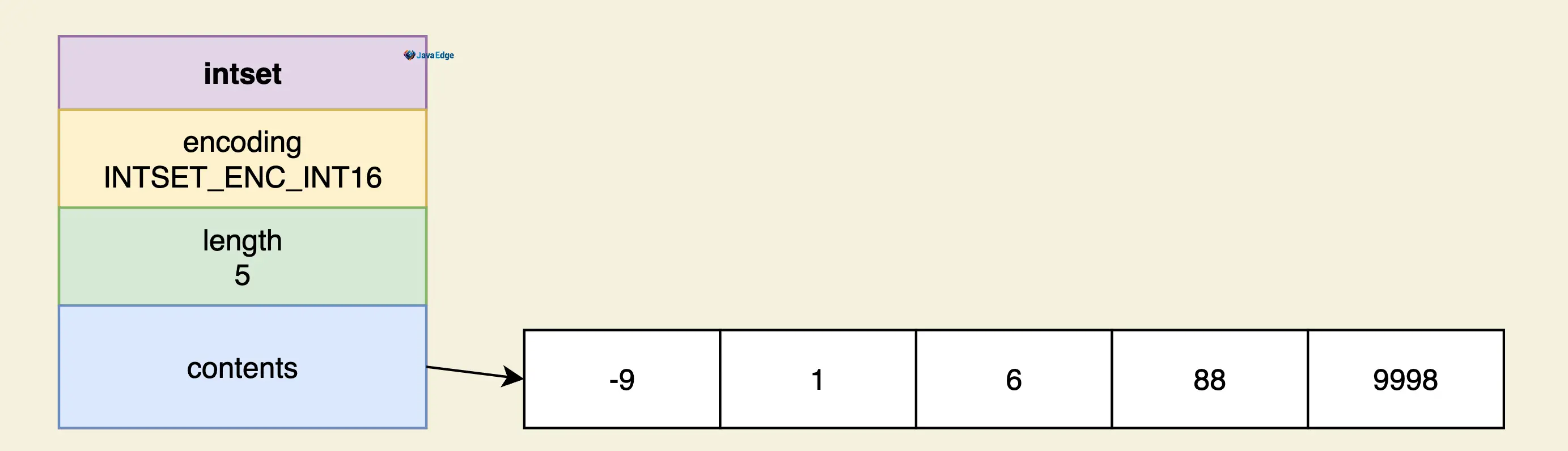
因为元素有序排列,所以SET的获取操作采用二分查找,复杂度为O(log(N))。
进行插入操作时:
- 首先通过二分查找到要插入位置
- 再对元素进行扩容
- 然后将插入位置之后的所有元素向后移动一个位置
- 最后插入元素
时间复杂度为O(N)。为使二分查找的速度足够快,存储在content 中的元素是定长的。
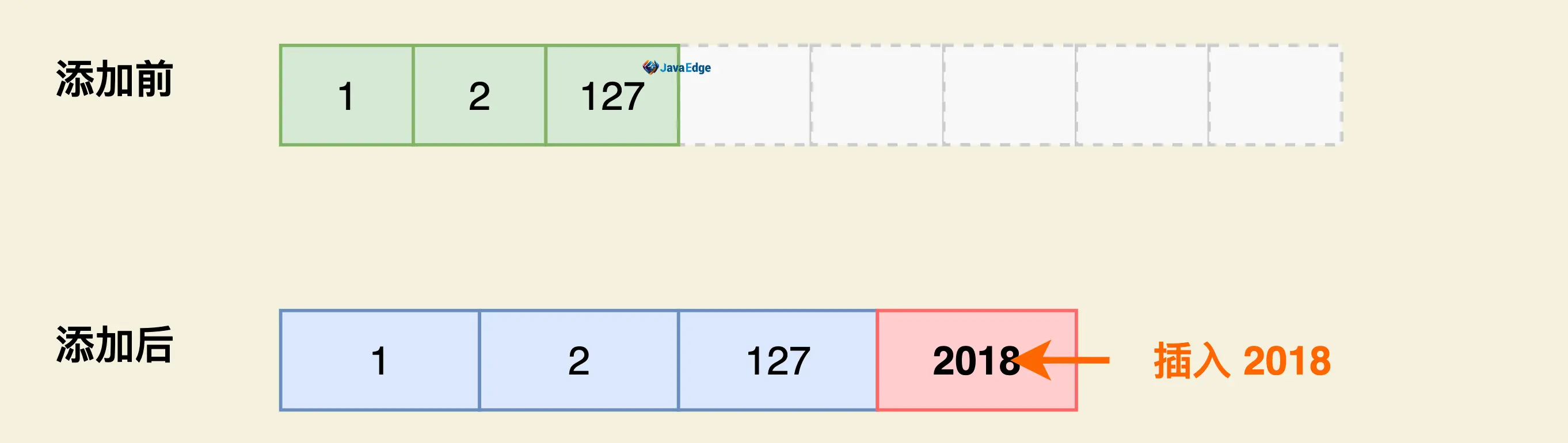
插入2018时,所有元素向后移动,且不会发生覆盖。当Set中存放的整型元素集中在小整数范围-128, 127内时,可大大节省内存空间。
IntSet支持升级,不支持降级。
3.2 API
基本操作
| 操作 | 命令 | 描述 |
|---|---|---|
| sadd | sadd key member [member ...] |
将一个或多个member放入集合 |
| srem | srem key member [member ...] |
移除一个或多个member |
| sismember | sismember key member |
检查member是否在集合中 |
| scard | scard key |
返回集合中元素的个数 |
| smembers | smembers key |
返回集合中所有的元素 |
| srandmember | srandmember key [count] |
随机返回1个(默认)或多个成员 |
复合操作
| 操作 | 命令 | 描述 |
|---|---|---|
| sinter | sinter key [key...] |
返回多个集合的交集 |
| sunion | sunion key [key...] |
返回多个集合的并集 |
| sdiff | sdiff key [key...] |
返回第一个集合与后面所有集合的差集 |
复合存储
| 操作 | 命令 | 描述 |
|---|---|---|
| sinterstore | sinterstore destination key [key...] |
与sinter类似,不过将结果集存储放到destination集合中 |
| sunionstore | sunionstore destination key [key...] |
与sunion类似,将结果集存储放到destination中 |
| sdiffstore | sdiffstore destination key [key...] |
与sdiff类似,将结果集存储放到destination中 |
3.3 适用场景
无序集合,自动去重,数据太多时不推荐用。对数据快速全局去重,若系统集群部署,就需基于redis进行全局set去重。
可基于set玩交集、并集、差集操作,如交集:
- 把两个人的粉丝列表整一个交集,看看俩人的共同好友
- 把两个大v的粉丝都放在两个set中,对两个set做交集
全局这种计算开销也大。
-
记录唯一的事物:如想知访问某博客的IP地址,不要重复的IP,这种情况只需要在每次处理一个请求时简单的使用SADD命令就可以了,可确保不会插入重复IP
-
表示关系:可用Redis创建一个标签系统,每个标签使用一个Set表示。然后可用SADD把具有特定标签的所有对象的所有ID放在表示这个标签的Set中。如想知道同时拥有三个不同标签的对象,那么使用SINTER
-
可使用SPOP或 SRANDMEMBER命令从集合中随机的提取元素。
4 Hash
一般可将结构化的数据,如一个对象(前提是这个对象未嵌套其他对象)缓存在Redis。每次读写缓存时,直接操作hash里的某字段。
json
key=150
value={
"id": 150,
"name": "JavaEdge",
"age": 18
}hash类的数据结构,主要存放一些对象,缓存一些简单对象,后续操作时,可直接仅修改该对象中的某个字段值。
c
value={
"id": 150,
"name": "JavaEdge",
"age": 25
}因为Redis本身是一个KV存储结构,Hash结构可理解为subkey - subvalue 这里面的subkey - subvalue只能是
- 整型
- 浮点型
- 字符串
因为Map的 value 可表示整型和浮点型,因此Map也可用 hincrby 对某个field的value值做自增操作。
5.1 内存数据结构
hash有HashTable 和 ziplist 两种实现。对于数据量较小的hash,使用ziplist 实现。
5.1.1 HashTable实现
HashTable在Redis中分为3层,自底向上:
- dictEntry:管理一个field - value 对,保留同一桶中相邻元素的指针,以此维护Hash 桶中的内部链
- dictht:维护Hash表的所有桶链
- dict:当dictht需要扩容/缩容时,用户管理dictht的迁移
dict是Hash表存储的顶层结构
c
// 哈希表(字典)数据结构,Redis 的所有键值对都会存储在这里。其中包含两个哈希表。
typedef struct dict {
// 哈希表的类型,包括哈希函数,比较函数,键值的内存释放函数
dictType *type;
// 存储一些额外的数据
void *privdata;
// 两个哈希表
dictht ht[2];
// 哈希表重置下标,指定的是哈希数组的数组下标
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 绑定到哈希表的迭代器个数
int iterators; /* number of iterators currently running */
} dict;Hash表的核心结构是dictht,它的table 字段维护着 Hash 桶,桶(bucket)是一个数组,数组的元素指向桶中的第一个元素(dictEntry)。
c
typedef struct dictht {
//槽位数组
dictEntry **table;
//槽位数组长度
unsigned long size;
//用于计算索引的掩码
unsigned long sizemask;
//真正存储的键值对数量
unsigned long used;
} dictht;结构图:
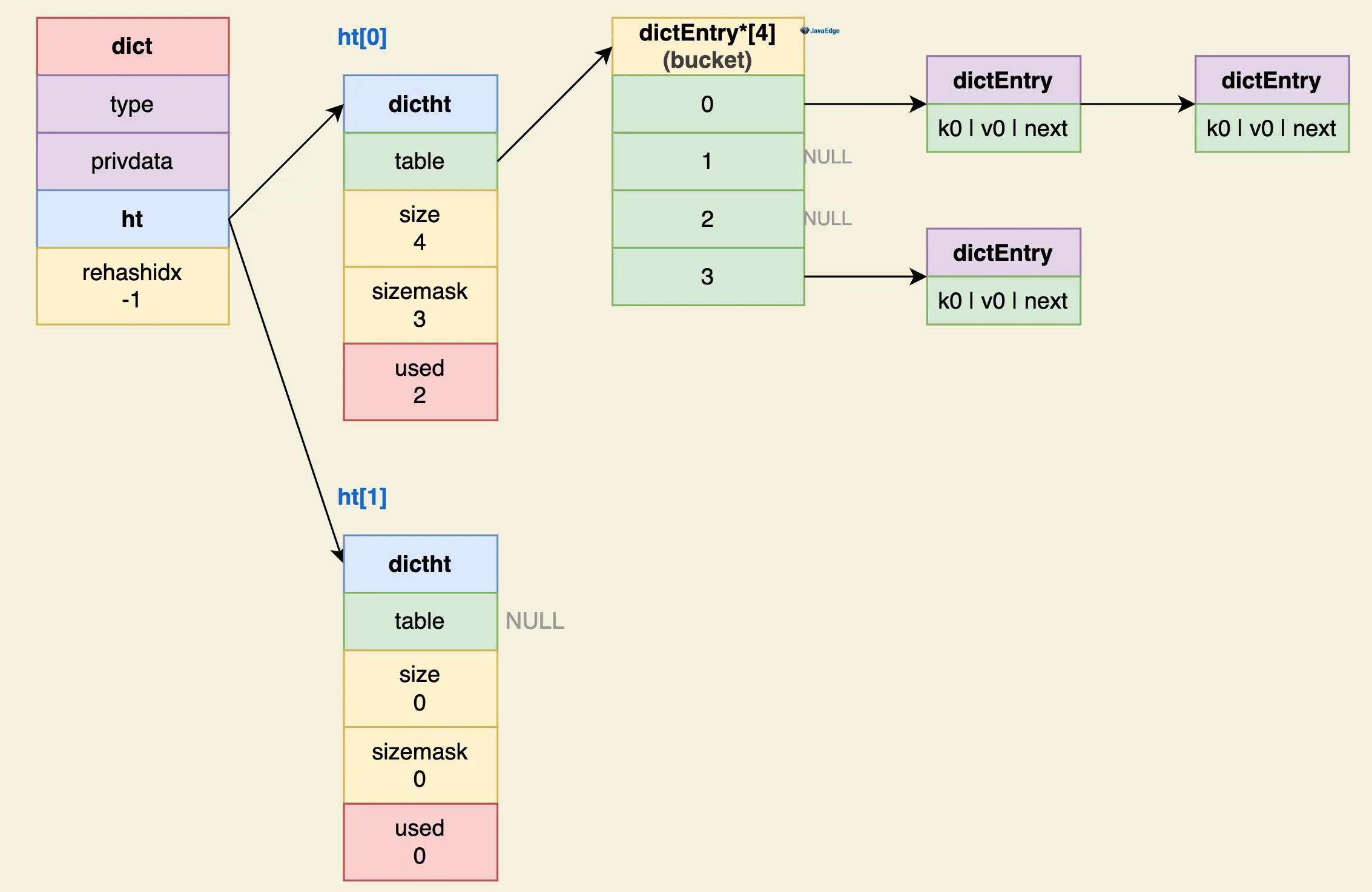
Hash表使用【链地址法】解决Hash冲突。当一个 bucket 中的 Entry 很多时,Hash表的插入性能会下降,此时就需要增加bucket的个数来减少Hash冲突。
Hash表扩容
和大多数Hash表实现一样,Redis引入负载因子,判定是否需增加bucket个数:
bash
负载因子 = Hash表中已有元素 / bucket数量扩容后,bucket 数量是原先2倍。目前有2 个阀值:
-
<1:一定不扩容
-
>5:一定扩容
-
1 ~ 5 之间:Redis 若未进行
bgsave/bdrewrite操作时则会扩容 -
当key - value 对减少时,低于0.1时会进行缩容。缩容之后,bucket的个数是原先的0.5倍
5.1.2 ziplist 实现
和List#ziplist实现类似,都是通过Entry 存放元素。不同的是,Map#ziplist的Entry个数总是2的整数倍:
- 第奇数个Entry存放key
- 下个相邻Entry存放value
ziplist承载时,Map的大多数操作不再是O(1),而是由Hash表遍历,变成链表遍历,复杂度变为O(N)。 由于Map相对较小时采用ziplist,采用Hash表时计算hash值的开销较大,因此综合起来ziplist性能相对好一些。
哈希键值结构
特点
- Map的map
- Small redis
- field不能相同,value可相同
bash
hget key field O(1)
# 获取 hash key 对应的 field 的 value
hset key field value O(1)
# 设置 hash key 对应的 field 的 value
hdel key field O(1)
# 删除 hash key 对应的 field 的 value5.2 实操
bash
127.0.0.1:6379> hset user:1:info age 23
(integer) 1
127.0.0.1:6379> hget user:1:info age
"23"
127.0.0.1:6379> hset user:1:info name JavaEdge
(integer) 1
127.0.0.1:6379> hgetall user:1:info
1) "age"
2) "23"
3) "name"
4) "JavaEdge"
127.0.0.1:6379> hdel user:1:info age
(integer) 1
127.0.0.1:6379> hgetall user:1:info
1) "name"
2) "JavaEdge"
bash
hexists key field O(1)
# 判断hash key是否有field
hlen key O(1)
# 获取hash key field的数量
bash
127.0.0.1:6379> hgetall user:1:info
1) "name"
2) "JavaEdge"
127.0.0.1:6379> HEXISTS user:1:info name
(integer) 1
127.0.0.1:6379> HLEN user:1:info
(integer) 1
bash
hmget key field1 field2... fieldN O(N)
# 批量获取 hash key 的一批 field 对应的值
hmset key field1 value1 field2 value2...fieldN valueN O(N)
# 批量设置 hash key的一批field value
java
redis-cli
127.0.0.1:6379> hmset user:2:info age 30 name kaka page 50
OK
127.0.0.1:6379> hlen user:2:info
(integer) 3
127.0.0.1:6379> hmget user:2:info age name
1) "30"
2) "kaka"记录网站每个用户个人主页的访问量
bash
hincrby user:1:info pageview count缓存视频的基本信息(数据源MySQL)伪代码
java
public VideoInfo get(long id) {
String redisKey = redisPrefix + id;
Map<String,String> hashMap = redis.hgetAll(redisKey);
VideoInfo videoInfo = transferMap ToVideo(hashMap);
if (videoInfo == null) {
videoInfo = mysql.get(id);
if (videoInfo != nul) {
redis.hmset(redisKey transferVideo ToMap(videoInfol);
}
}
return videoInfo;
}
bash
hgetall key O(N) 小心使用,牢记单线程!!!
返回 hash key 对应所有的 filed 和 value
hvals key O(N)
返回 hash key 对应所有的 filed 的 value
hkeys key O(N)
返回 hash key 对应所有 filed用户信息,string实现:
java
Key user:1
value(serializable:json,xml,protobuf)
{
"id": 1,
"name": "JavaEdge",
"age": 18,
"pageView": 500000
}
set user:1 serialize(userinfo)5.3 适用场景
用户信息
方便单条更新,但信息非整体,不便管理:
用户信息(string实现-v2)
java
41
set user:1:age 41
key value
user:1:name world
user:1:age 40
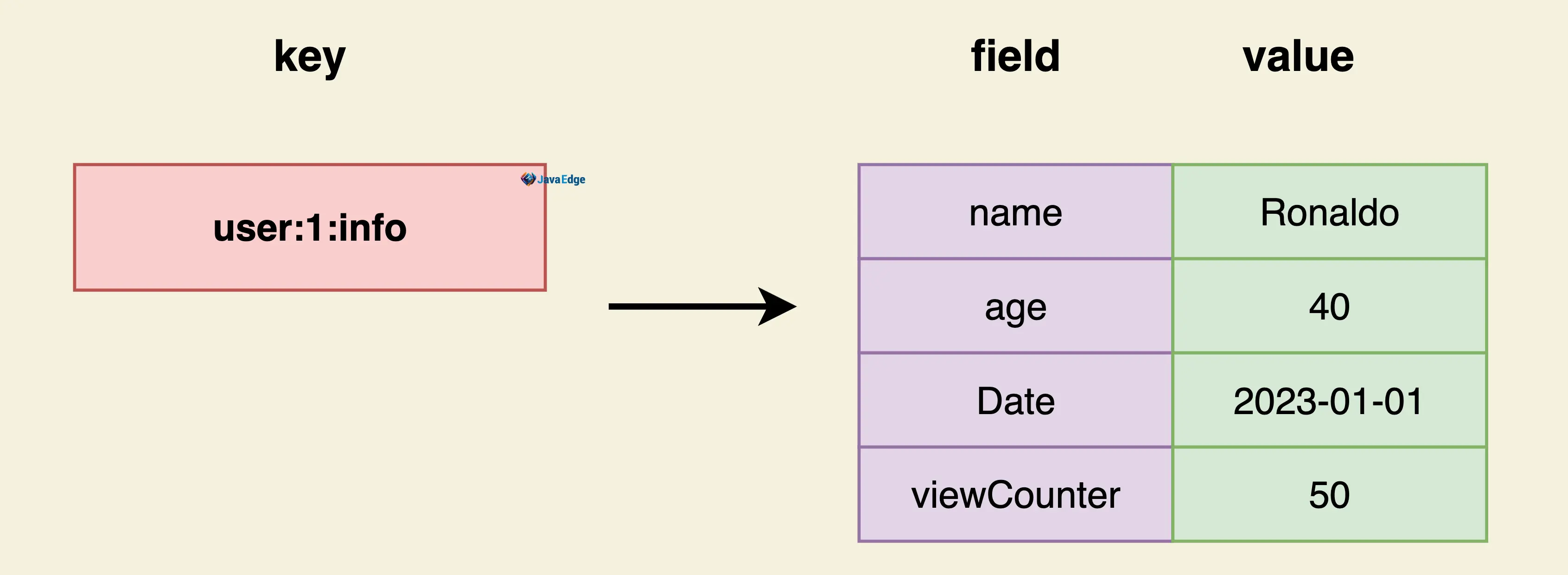
user:1:pageView 500000用户信息(hash)
java
key field value
user:1:info → name ronaldo
age 40
pageView 500000
key field value
┌─────────────┬─────────────────┐
user:1:info ────────> │ name │ ronaldo │
├─────────────┼─────────────────┤
│ age │ 41 │
├─────────────┼─────────────────┤
│ pageView │ 500000 │
├─────────────┼─────────────────┤
│ link │ tv.sohu.com │
└─────────────┴─────────────────┘
hset user:1:info age 41
hset user:1:info link tv.sohu.com3种方案比较:
| 命令 | 优点 | 缺点 |
|---|---|---|
| string v1 | 编程简单 可能节约内存 | 1. 序列化开销 2. 设置属性要操作整个数据 |
| string v2 | 直观 可以部分更新 | 1. 内存占用较大 2. key较为分散 |
| hash | 直观 节省空间 可以部分更新 | 1. 编程稍微复杂 2. ttl不好控制 |
hsetnx、hincrby、hincrbyfloat
bash
# 设置hash key对应field的value(如field已经存在,则失败) o(1)
hsetnx key field value
# hash key对应的field的value自增intCounter o(1)
hincrby key field intCounter
#hincrby浮点数版 o(1)
hincrbyfloat key field floatCounter5.4 小结
| 命令 | 复杂度 |
|---|---|
| hget hset hdel | O(1) |
| hexists | O(1) |
| hincrby | O(1) |
| hgetall hvals hkeys | O(n) |
| hmget hmset | O(n) |
Redis Hashes 保存String域和String值之间的映射,所以它们是用来表示对象的绝佳数据类型(比如一个有着用户名,密码等属性的User对象)
go
| `1` | `@cli` |
| `2` | `HMSET user:1000 username antirez password P1pp0 age 34` |
| `3` | `HGETALL user:1000` |
| `4` | `HSET user:1000 password 12345` |
| `5` | `HGETALL user:1000` |一个有着少量数据域(这里的少量大概100上下)的hash,其存储方式占用很小的空间,所以在一个小的Redis实例中就可以存储上百万的这种对象
Hash的最大长度是2^32 -- 1个域值对(4294967295,一个Hash中可以有多达40多亿个域值对)。
5 Sorted Set
6 Bitmaps
位图类型,String类型上的一组面向bit操作的集合。由于 strings是二进制安全的blob,并且它们的最大长度是512m,所以bitmaps能最大设置 2^32个不同的bit。
7 HyperLogLogs
pfadd/pfcount/pfmerge。
redis使用标准错误小于1%的估计度量结束。
无需与需要统计的项相对应的内存,而是使用的内存恒定不变。最坏只需12k,就可计算接近2^64个不同元素的基数。
8 GEO
geoadd/geohash/geopos/geodist/georadius/georadiusbymember
Redis 3.2推出,可将用户给定的地理位置(经、纬度)信息储存起来并操作。
本文由博客一文多发平台 OpenWrite 发布!