
大家好啊,blog 一年多不更新了,估计权重都掉完了,也不知道最后有多少人能看到。
从去年五月份开始,工作上因组织架构变动,我从原来做的性能优化领域转向了 AI,具体内容因为保密协议的问题也不能多说,所以就长时间不更新了。今年的话工作方向又有了一些变动,主要是在做一些 GUI Agent 的事情。
时间过去了一年,但对于编程领域却是天翻地覆。随着 Cursor/Claude Code 等工具的推出,大家基本都脱离了古法编程的束缚(先别说生成的代码对不对,你就说快不快吧);不少的部门也不满足于外部编程工具的提效,也开始搞自己内部的 Agent,试图在业务和工程上双重提效。由于最近的工作会和大模型团队合作比较多,我对此的体感反而感受更深一些,这里面的感触以后有机会可以和大家慢慢说。
除去上面的寒暄,今天的技术话题就聊些简单的。
自从「多模态大模型」开始发展,向模型传入图片内容就成了各类 Agent 系统绕不开的话题。出于一些安全上的考虑,一些大模型早期还只支持 base64 编码的图片上传,让网络请求的 post body 变得又臭又长。
随着 2024 年 computer use 和 browser use 等概念的提出,这些相关的 Agent 会涉及到大量的截图,然后把截图发给大模型以供决策并提供下一次 loop 的 action。而这些截图大部分都是以 base64 的格式存在的,相关的 GUI Agent 需要从这些 base64 image 中读取「格式/长宽」等 meta 信息,然后做一系列的逻辑处理。
常规做法
如果 Agent 的技术栈是 JS/TS,那么常规的处理流程是把 base64 image 先全量转为 binary image,然后再借助 jimp/sharp 等图片处理 lib,从中获取相关的 meta 信息(直接向 Claude Code 提需求其实也是类似的处理方法)。
typescript
// Jimp
import { Jimp } from "jimp";
const buffer = Buffer.from(base64Data, 'base64');
const image = await Jimp.fromBuffer(buffer);
console.log(image.mime, image.width, image.height)
// sharp
import sharp from "sharp";
const buffer = Buffer.from(base64Data, 'base64');
const metadata = await sharp(imageBuffer).metadata();
console.log(metadata.format, metadata.width, metadata.height)这种方式从最终结果 上看没什么问题,但是在性能和效率上有以下的不足:
- 引用 jimp 等通用 image lib 会增大包体积,但只用了很少的功能,有些大炮打蚊子
- 全量转换为 binary,会带来内存的不必要增加,比如说一个 4MB 的 base64 image,转为 binary 后内存会增加 3MB,如果 lib 内部解码为 BMP 等通用的 bitmap 格式,内存会根据 宽/高/位深 有 十几到几十MB 的占用涨落
性能优化
根据之前的经验,对于原始的 base64 image,我们获取的主要 meta 信息就是 mime, width 和 height。而所有的图片格式为了能在全平台流转和编解码,都有非常严谨的 RFC 定义。并且我们要获取的 meta 信息,都记录在图片二进制格式的 header chunk 里,所以我们只要找到相关信息的位置并读取就可以拿到想要的数据了。
基本原理
这样说比较抽象,我们拿经典的 PNG 图片为例看一下它的二进制构成。
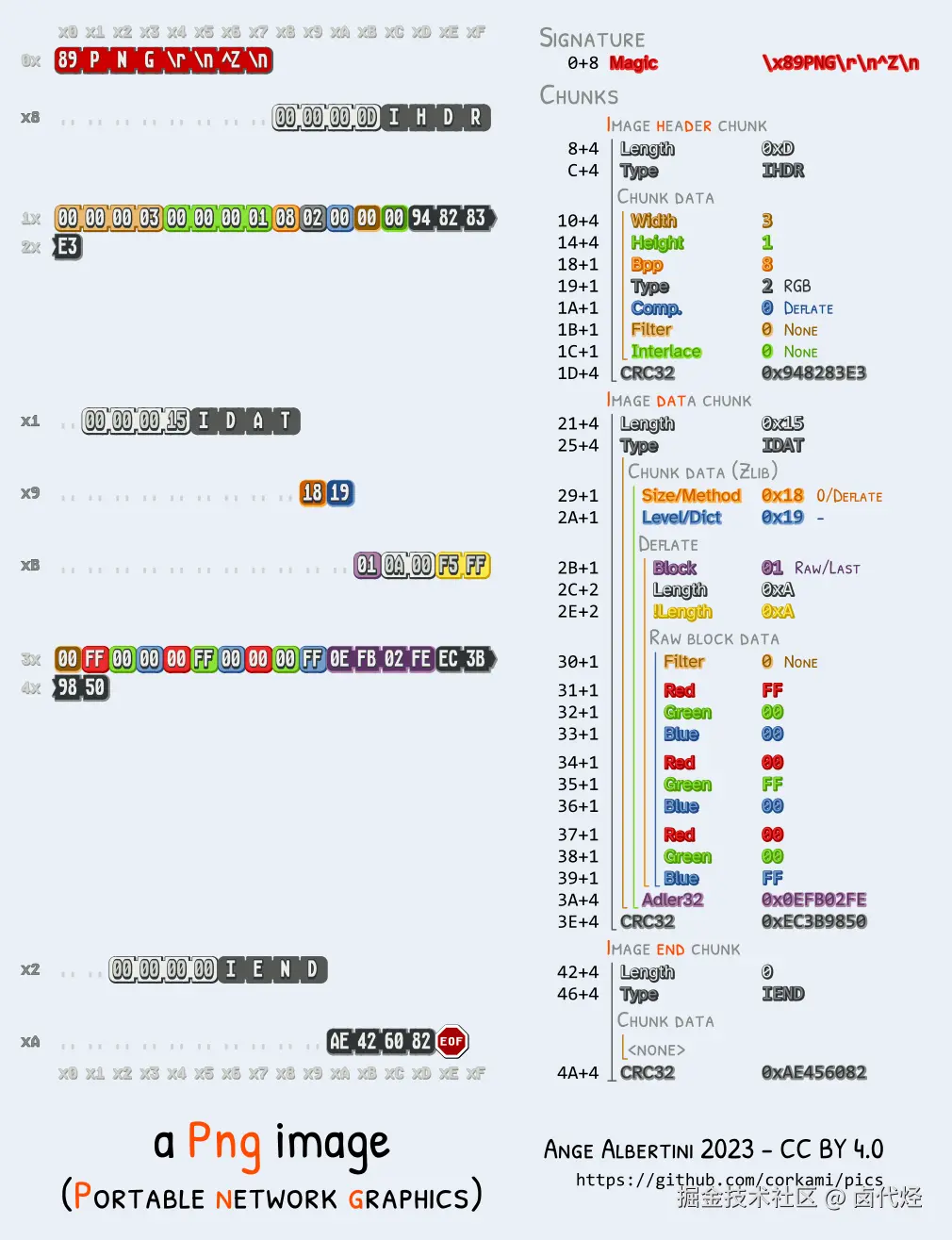
从上图我们可以看出,一个 png 图片主要是 4 部分组成:
- signature : 也就是 png 图片的 magic number,固定为
\x89PNG\r\n^Z\n,这样解码器可以通过头 8 个字节就能快速判断出数据类型 - IHDR: image header chunk,里面标注了各种 meta 信息,比如说 width/height/bit depth 等
- IDAT: image data chunk,png data 数据,因为不是本文重点暂时忽略
- IEND : image trailer chunk,标记 png 图片的结束。其实 png 结束后还可以附加其余信息(相关玩法可见 热更新-隐写术)
从上面内容我们可以看出,对于 png 图片:
- 我们只需要读前 8 bytes 的内容就可以快速判断出 base64 image 的 mime 类型
- 直接读取 10+4 和 14+4 bytes 的内容,就可以确定 PNG 图片的宽高
也就是说,对于任意大小的 PNG 图片,我们只需要读取前 23 bytes 的内容就拿到 mime & width & height,其它图片格式同理。
其它的图片二进制格式如下:
| 格式 | 二进制格式解析 |
|---|---|
| PNG | github.com/corkami/pic... |
| JPEG | github.com/corkami/pic... |
| GIF | github.com/corkami/pic... |
| BMP | github.com/corkami/pic... |
| WEBP | datatracker.ietf.org/doc/rfc9649... |
获取类型
就如前文,我们只需要通过 image 的 Magic Number 就能判断 mime。
这里需要注意的是,有很多的 base64 image 会在前面加个 DataURI 的前缀(例如 data:image/png;base64,iVBOR...),这个前缀的 mimeType 是不一定准确的,比如说下面这个图片,前缀说它是 png,但它实际上是 webp(最后还是浏览器兜底按 Magic Number 显示出来了):
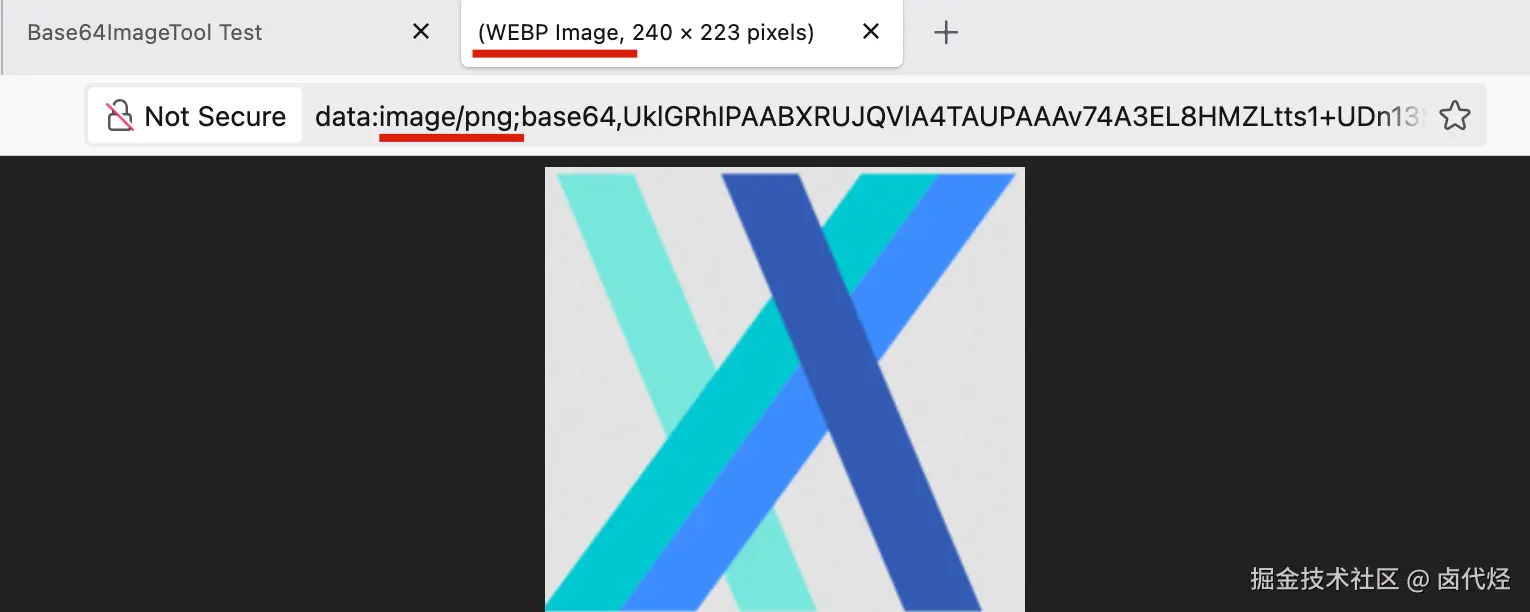
Maigc Number 转为 base64 字符串后,因为 Magic Number 是确定的,所以转换后的 string 也是确定的。一般来说,我们只需要匹配前 8 个字符(也就是前 6 个 byte)就可以快速判断出图片类型:
typescript
const IMAGE_TYPE_MAP = new Map<string, ImageType>([
['/9j/', 'jpeg'], // JPEG: FF D8 FF
['iVBORw', 'png'], // PNG: 89 50 4E 47
['UklGR', 'webp'], // WebP: 52 49 46 46
['R0lGOD', 'gif'], // GIF: 47 49 46 38
['Qk', 'bmp'], // BMP: 42 4D
]);
// use
const prefix = base64Image.substring(0, 8);
for (const [signature, type] of IMAGE_TYPE_MAP) {
if (prefix.startsWith(signature)) {
return type;
}
}获取宽高
获取宽高会稍微麻烦一些,因为不像 Magic Number 都放在最开始的地方,各个图片规范都不太一样,但最后的方案都大差不差,一般都在前 32 bytes 里有描述。我们可以只取 base64 的前 n 个字符,然后转换为 binary 读取相关位置的数据。这样做要比图片全量转换内存增量要小的多。
就拿 PNG 图片为例,从 PNG RFC 可知,PNG 是按大端序 存储的(也就是高位字节在前),宽度和高度都占用 4 个字节 。就拿 PNG 的 width 来说,它占据的是 bytes[16], bytes[17], bytes[18], bytes[19]。
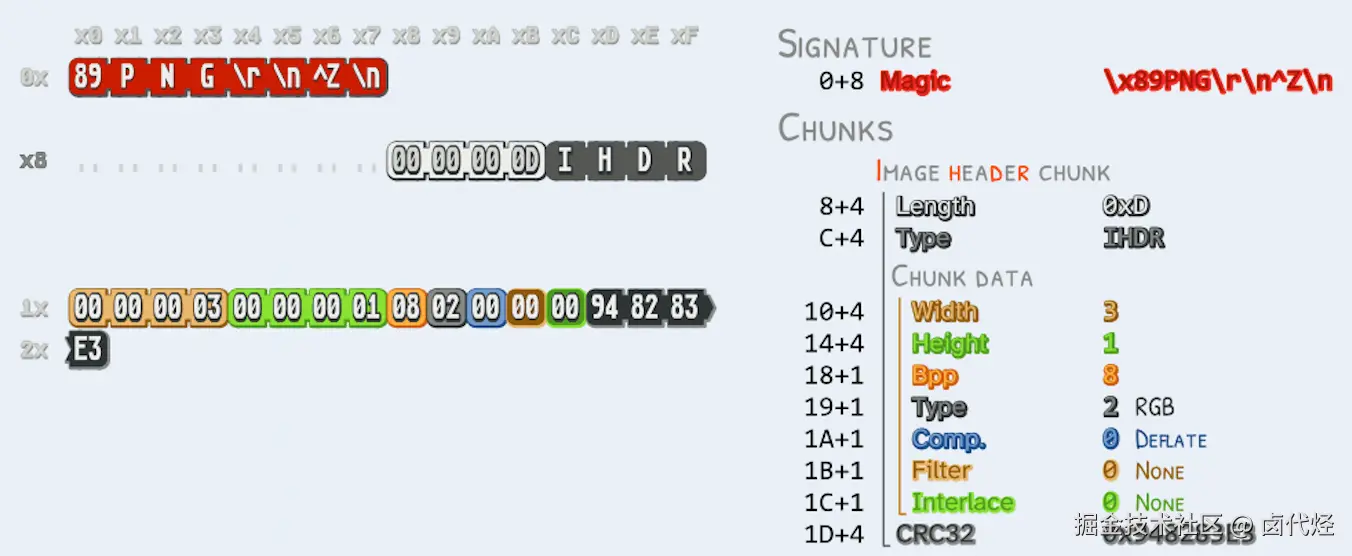
All integers that require more than one byte must be in network byte order
Width and height give the image dimensions in pixels. They are 4-byte integers . Zero is an invalid value. The maximum for each is (2^31)-1 in order to accommodate languages that have difficulty with unsigned 4-byte values.
假设 width 的值是 1920(十进制),十六进制为 0x00000780,32 位二进制表示就是 00000000 00000000 00000111 10000000,那么在 PNG 里的存储关系就是:
bytes[16]=0x00(二进制00000000)bytes[17]=0x00(二进制00000000)bytes[18]=0x07(二进制00000111)bytes[19]=0x80(二进制10000000)
那么把离散的 bytes[16], bytes[17], bytes[18], bytes[19] 按大端序组合为一个 32 位整数,那么首先要做左移运算,统一为 32 位:
| 位数 | 原始(8 位) | 操作(左移) | 移动后(32 位) |
|---|---|---|---|
| bytes16 | 00000000 | << 24 | 00000000 00000000 00000000 00000000 |
| bytes17 | 00000000 | << 16 | 00000000 00000000 00000000 00000000 |
| bytes18 | 00000111 | << 8 | 00000000 00000000 00000111 00000000 |
| bytes19 | 10000000 | 不移动 | 00000000 00000000 00000000 10000000 |
最后以「按位或」合并所有结果:
typescript
00000000 00000000 00000000 00000000 (bytes[16])
| 00000000 00000000 00000000 00000000 (bytes[17])
| 00000000 00000000 00000111 00000000 (bytes[18])
| 00000000 00000000 00000000 10000000 (bytes[19])
-----------------------------------------
= 00000000 00000000 00000111 10000000 (最终结果)写为真实的代码就是这样:
typescript
export function parsePngDimensions(bytes: Uint8Array): ImageDimensions {
// PNG dimensions are at bytes 16-23 (big-endian)
const width = (bytes[16] << 24) | (bytes[17] << 16) | (bytes[18] << 8) | bytes[19];
const height = (bytes[20] << 24) | (bytes[21] << 16) | (bytes[22] << 8) | bytes[23];
return { width, height };
}
// use
const header = base64image.substring(0, 48);
const binaryHeader = new Uint8Array(Buffer.from(header, 'base64'));
const { width, height } = parsePngDimensions(binaryHeader);按同样的思路,只需要注意字节序和 width/height 在实际二进制数据中的位置,就可以一一解析各种图片格式。这种繁琐的工作,只需要把上面的逻辑给 Claude Code/Cursor 再加上对应的 RFC 参考,就能直接生成其他图片格式的解析代码了。
当然,生成的代码有可能有错误,这里就需要花费一些时间再做人工 review 并补上单测,这部分其实是在整体工作中最耗时的一块儿,因为 AI 目前还不能背锅。
总结
使用这个思路,可以有效把读取 meta 信息时的内存增量控制在几十个字节内,优化整体性能。