7.1 Flink快速入门
7.1.2 Flink的最简安装
1. Flink安装和配置
解压Flink安装包
bash
cd /home/hadoop/app
tar -zxvf flink-1.9.1-bin-scala_2.11.tgz创建软链接
bash
ln -s flink-1.9.1 flink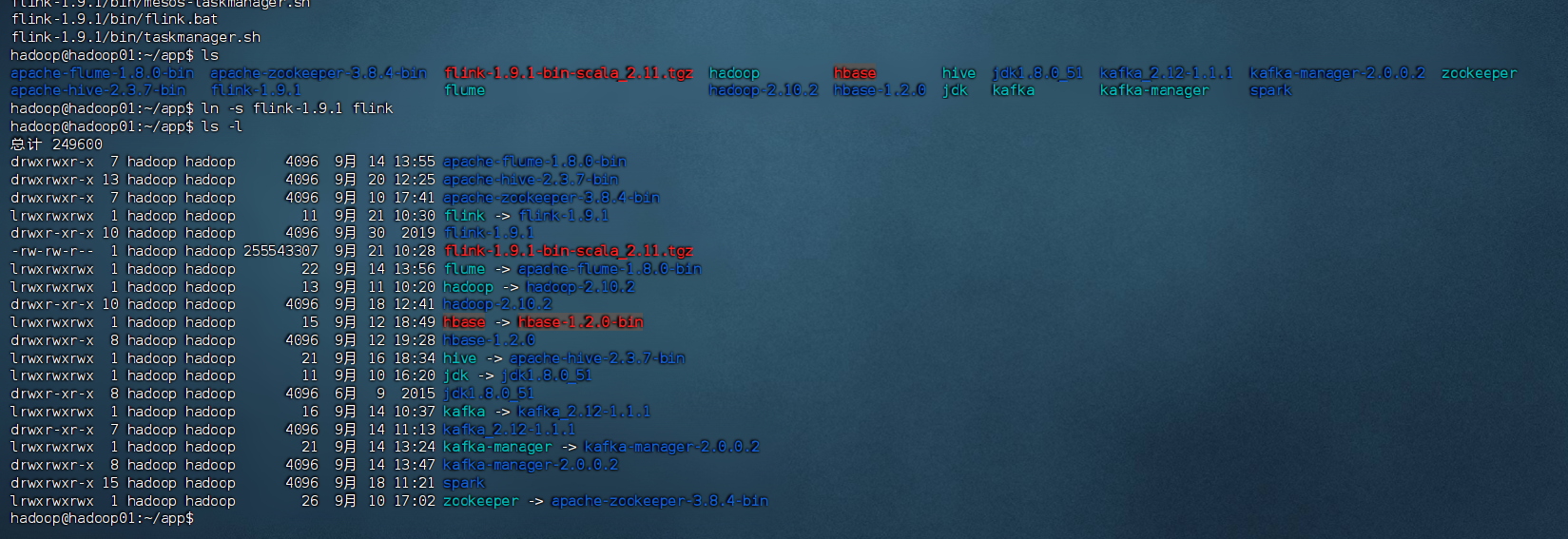
2. 准备测试数据
创建测试文件
bash
cd /home/hadoop/app/flink
cat > djt.log << EOF
hadoop hadoop hadoop
spark spark spark
flink flink flink
EOF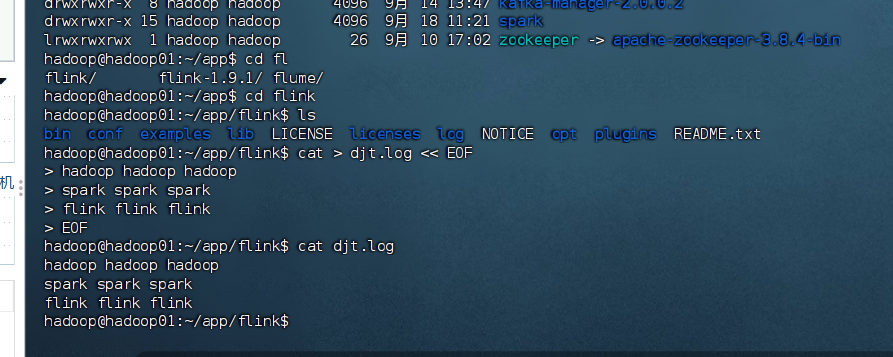
3. Flink Shell测试
启动Flink Scala Shell
bash
cd /home/hadoop/app/flink
bin/start-scala-shell.sh local
4.在Scala Shell中执行WordCount
scala
// 读取本地文件
val lines = benv.readTextFile("/home/hadoop/app/flink/djt.log")
// 执行WordCount统计
val wordcounts = lines.flatMap(_.split("\\s+")).map((_, 1)).groupBy(0).sum(1)
// 打印结果
wordcounts.print()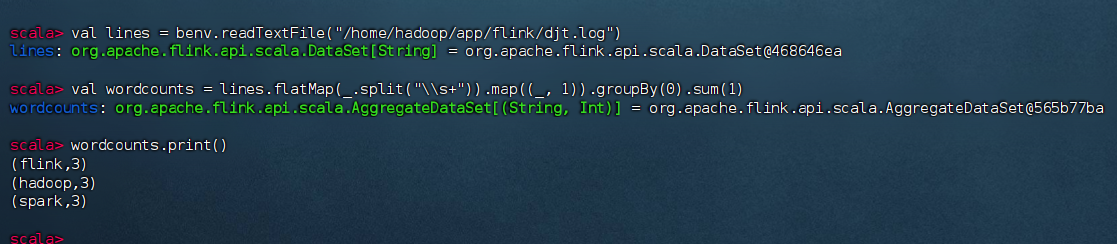
输入:quit即可退出
7.1.3 Flink实现WordCount
1.创建Maven项目
解压配套资源7.3/代码,进入 learningflink1.9
添加pom.xml依赖
xml
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.9.1</version>
</dependency>
</dependencies>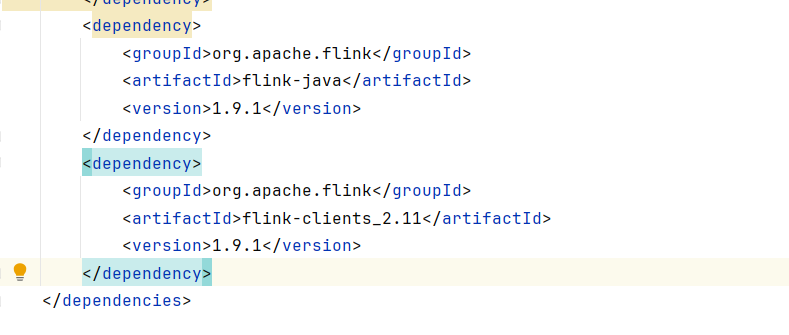
2.创建WordCount.java
java
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
import org.apache.flink.util.Preconditions;
public class WordCount {
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
//env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = null;
if (params.has("input")) {
// union all the inputs from text files
text = env.readTextFile("input");
Preconditions.checkNotNull(text, "Input DataSet should not be null.");
} else {
// get default test text data
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
text = WordCountData.getDefaultTextLineDataSet(env);
}
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}3.创建WordCountData.java
java
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
public class WordCountData {
public static final String[] WORDS = new String[] {
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them.To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};
public static DataSet<String> getDefaultTextLineDataSet(ExecutionEnvironment env) {
return env.fromElements(WORDS);
}
}
4.运行WordCount程序
- 右键点击WordCount.java
- 选择"Run 'WordCount.main()'"
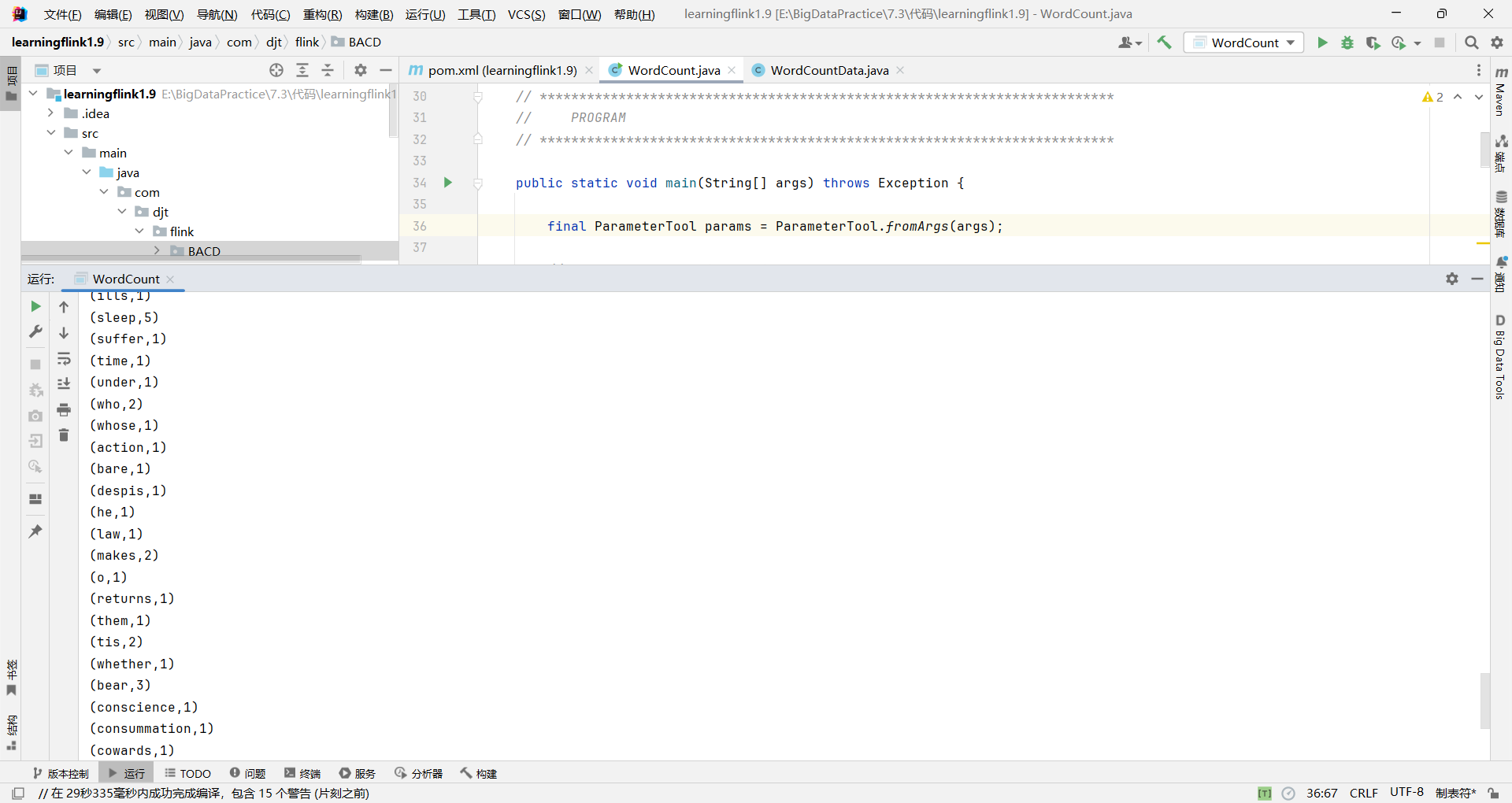
5. 验证结果
7.2 Flink分布式集群的构建
7.2.2 Flink Standalone模式集群的构建
1. 环境准备
确保以下服务已启动
bash
# 启动Zookeeper集群(所有节点)
[hadoop@hadoop01 ~]$ /home/hadoop/app/zookeeper/bin/zkServer.sh start
[hadoop@hadoop02 ~]$ /home/hadoop/app/zookeeper/bin/zkServer.sh start
[hadoop@hadoop03 ~]$ /home/hadoop/app/zookeeper/bin/zkServer.sh start
# 启动HDFS集群
[hadoop@hadoop01 ~]$ start-dfs.sh
# 验证服务状态
[hadoop@hadoop01 ~]$ jps
# 应该看到:QuorumPeerMain, NameNode, DataNode, SecondaryNameNode2. Flink安装和配置
解压Flink(已在hadoop01完成)
bash
[hadoop@hadoop01 app]$ ls
flink-1.9.1 # 确认已解压修改flink-conf.yaml配置文件
bash
[hadoop@hadoop01 conf]$ cd /home/hadoop/app/flink-1.9.1/conf
[hadoop@hadoop01 conf]$ vim flink-conf.yaml添加以下配置:
yaml
# JobManager地址
jobmanager.rpc.address: hadoop01
# 槽位配置为3
taskmanager.numberOfTaskSlots: 3
# 设置并行度为3
parallelism.default: 3
# 高可用模式,必须为Zookeeper
high-availability: zookeeper
# 配置独立Zookeeper集群地址
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181
# 添加Zookeeper根节点
high-availability.zookeeper.path.root: /flink
# 添加Zookeeper的cluster-id节点
high-availability.cluster-id: /cluster_one
# JobManager的元数据持久化保存的位置
#high-availability.storageDir: hdfs://mycluster/flink/ha/
high-availability.storageDir: hdfs://hadoop01:9000/flink/ha/
env.java.home: /home/hadoop/app/jdk
fs.hdfs.hadoopconf: /home/hadoop/app/hadoop/etc/hadoop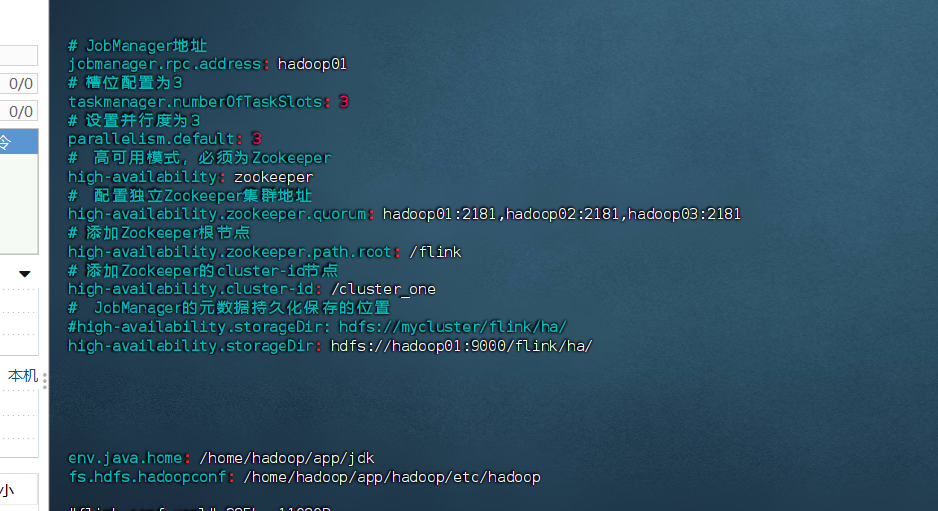
修改masters文件
bash
[hadoop@hadoop01 conf]$ vim masters内容如下:
hadoop01:8081
hadoop02:8081
hadoop03:9081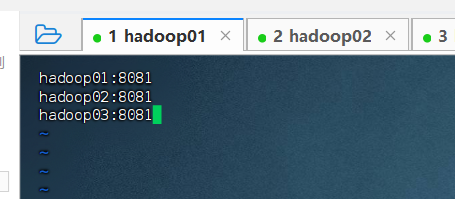
修改slaves文件
bash
[hadoop@hadoop01 conf]$ vim slaves内容如下:
hadoop01
hadoop02
hadoop03
3. 添加Hadoop依赖包
jar包链接:https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/
下载并放置hadoop shaded包
bash
# 将flink-shaded-hadoop-2-uber-2.8.3-10.0.jar放到flink的lib目录
[hadoop@hadoop01 lib]$ cd /home/hadoop/app/flink-1.9.1/lib
# 确保jar包已存在,如果没有请从指定地址下载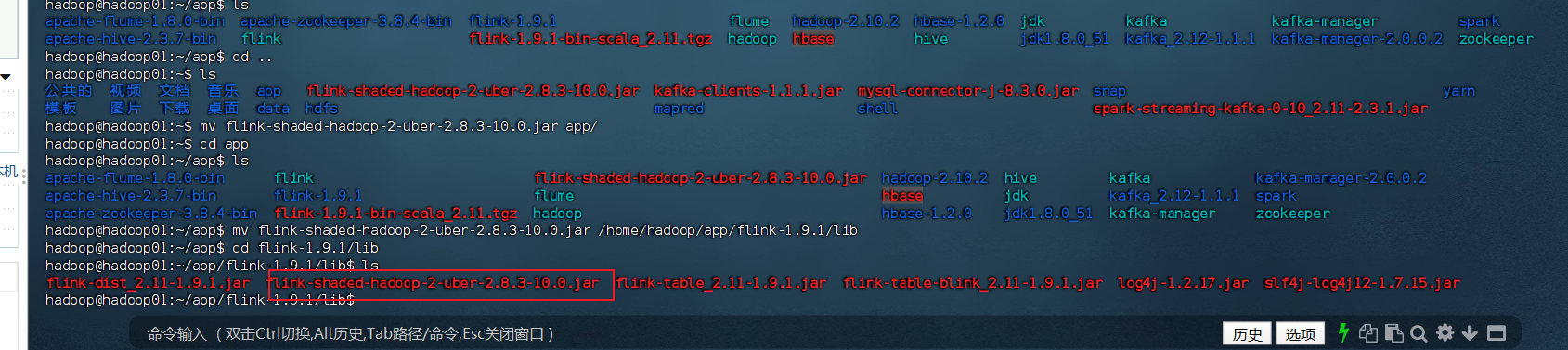
4. 分发Flink到其他节点
远程复制到hadoop02和hadoop03
bash
[hadoop@hadoop01 app]$ scp -r flink-1.9.1 hadoop@hadoop02:/home/hadoop/app/
[hadoop@hadoop01 app]$ scp -r flink-1.9.1 hadoop@hadoop03:/home/hadoop/app/创建软链接(所有节点)
bash
# hadoop02
[hadoop@hadoop02 app]$ ln -s flink-1.9.1 flink
# hadoop03
[hadoop@hadoop03 app]$ ln -s flink-1.9.1 flink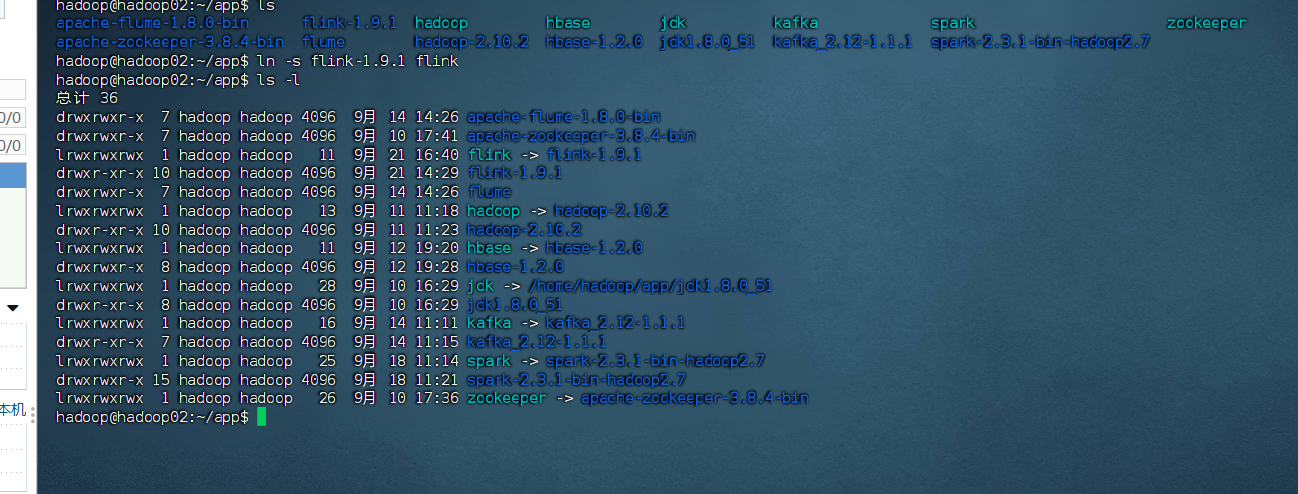
5. 修改备用节点配置
修改hadoop02的flink-conf.yaml
bash
[hadoop@hadoop02 conf]$ cd /home/hadoop/app/flink/conf
[hadoop@hadoop02 conf]$ vim flink-conf.yaml修改JobManager地址:
yaml
jobmanager.rpc.address: hadoop02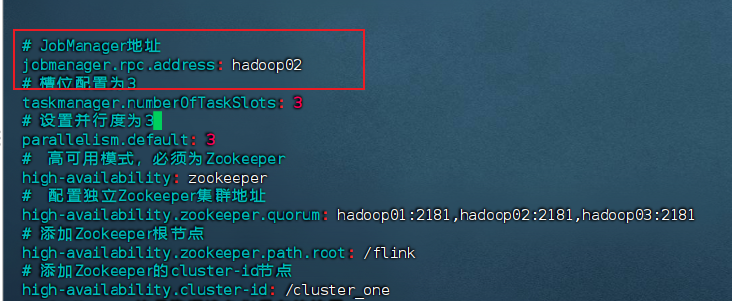
6. 启动Flink集群
启动集群
bash
#在hadoop01运行
cd /home/hadoop/app/flink
bin/start-cluster.sh
# 检查进程
jps问题解决:报错找不到jdk路径
bash
# 进入 Flink 目录
cd /home/hadoop/app/flink
# 设置正确的 JAVA_HOME(根据你的实际路径)
export JAVA_HOME=/home/hadoop/app/jdk
# 将 JAVA_HOME 添加到 Flink 配置文件中
echo "env.java.home: $JAVA_HOME" >> conf/flink-conf.yaml
# 验证配置
cat conf/flink-conf.yaml | grep java.home\
# 分发
scp conf/flink-conf.yaml hadoop02:/home/hadoop/app/flink/conf/
scp conf/flink-conf.yaml hadoop03:/home/hadoop/app/flink/conf/验证启动状态
bash
# 检查进程
[hadoop@hadoop01 flink]$ jps
# 应该看到:StandaloneSessionClusterEntrypoint (JobManager)
[hadoop@hadoop02 flink]$ jps
[hadoop@hadoop03 flink]$ jps
# 应该看到:TaskManagerRunner (TaskManager)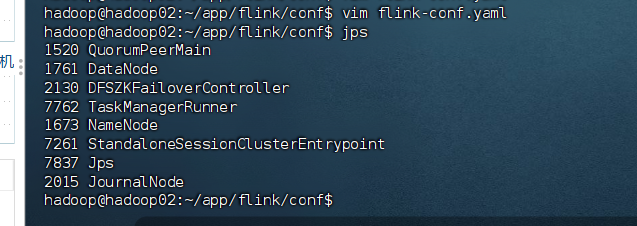
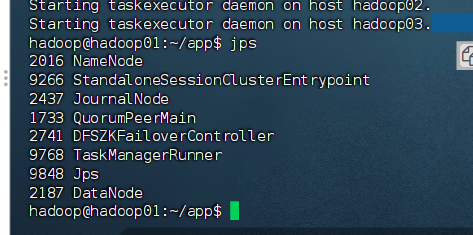
问题解决:
启动时候hadoop03没跟着启动,于是尝试单独启动:
bash
$FLINK_HOME/bin/taskmanager.sh start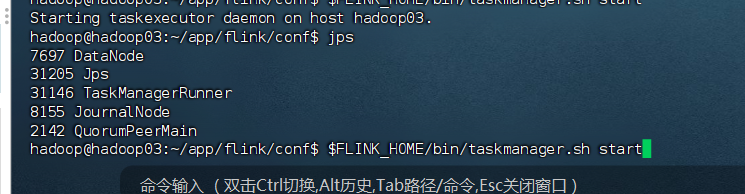
7. Web界面查看
访问Flink Web UI
在浏览器中输入:http://hadoop01:8081/
应该能看到:
- 1个JobManager(hadoop01:8081)
- 3个TaskManager(每个节点1个)
- 总共9个Task Slots(3节点 × 3槽位)
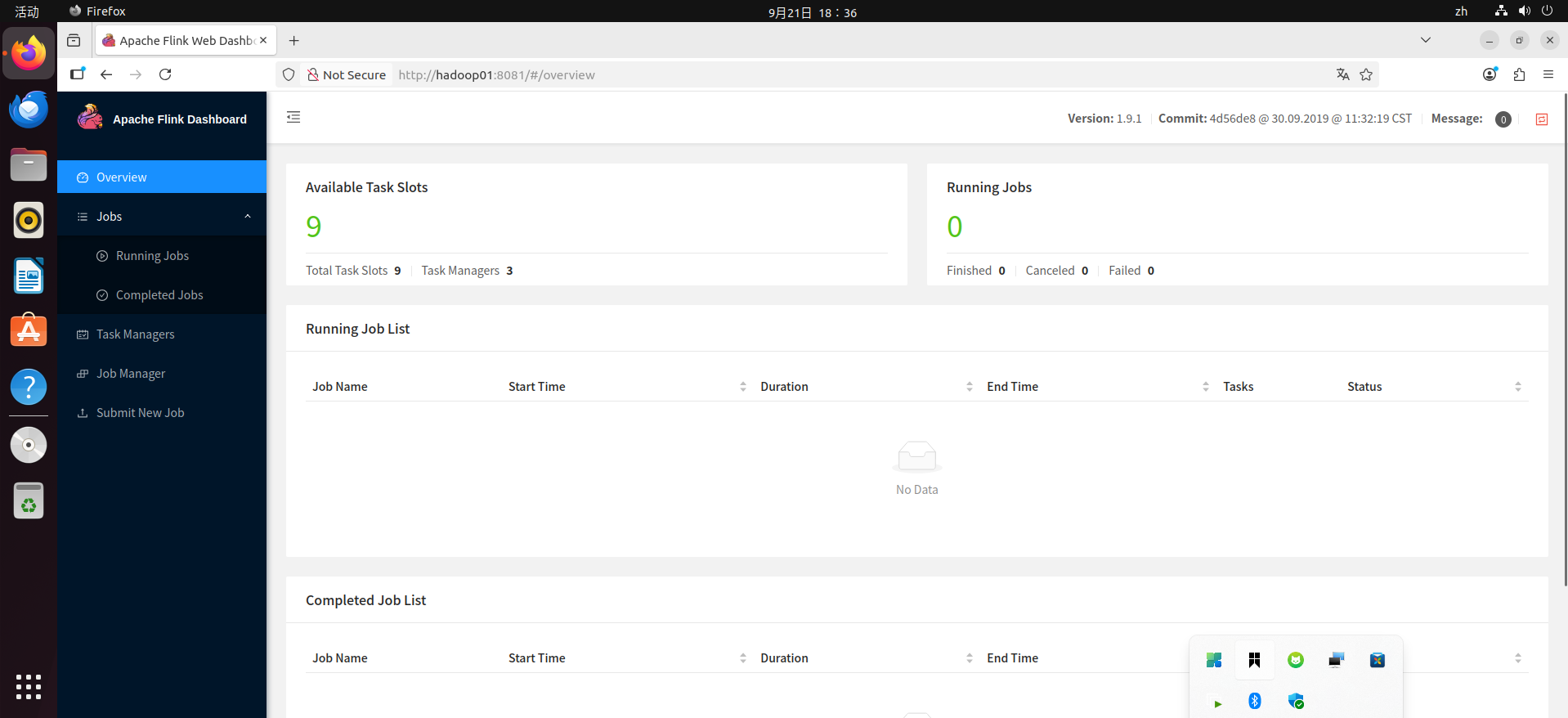
8. 测试运行WordCount
准备测试数据
bash
# 检查HDFS上的测试文件
[hadoop@hadoop01 hadoop]$ cd /home/hadoop/app/hadoop
[hadoop@hadoop01 hadoop]$ bin/hdfs dfs -ls /test
[hadoop@hadoop01 hadoop]$ bin/hdfs dfs -cat /test/djt.txt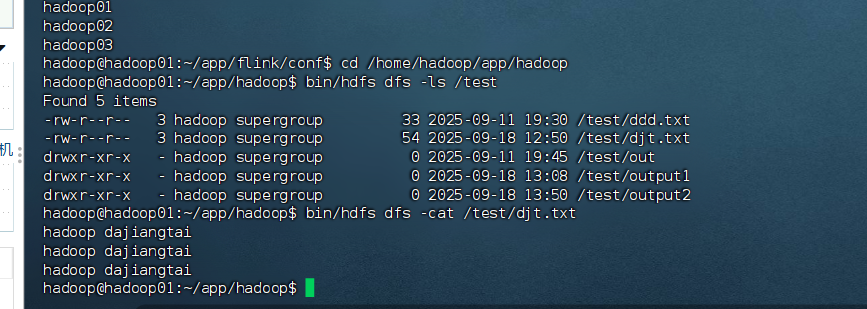
提交WordCount作业
bash
[hadoop@hadoop01 flink]$ cd /home/hadoop/app/flink
[hadoop@hadoop01 flink]$ bin/flink run -c org.apache.flink.examples.java.wordcount.WordCount examples/batch/WordCount.jar --input hdfs://mycluster/test/djt.txt --output hdfs://mycluster/test/output2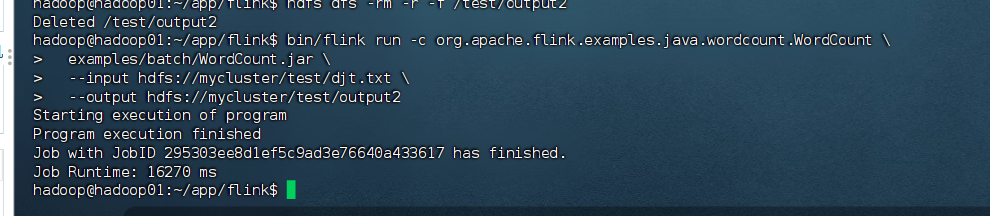
查看运行结果
bash
[hadoop@hadoop01 hadoop]$ bin/hdfs dfs -cat /test/output2/*
# 应该输出:
# dajiangtai 3
# hadoop 3
9. 停止集群
bash
# 停止Flink集群
[hadoop@hadoop01 flink]$ bin/stop-cluster.sh
# 停止HDFS
[hadoop@hadoop01 hadoop]$ sbin/stop-dfs.sh
# 停止Zookeeper
[hadoop@hadoop01 ~]$ /home/hadoop/app/zookeeper/bin/zkServer.sh stop7.2.3 Flink on YARN模式集群的构建
(1):下载并解压 Flink
- 登录到你的
hadoop01节点。 - 进入
/home/hadoop/app目录。 - 执行以下命令
bash
# 进入应用目录
cd /home/hadoop/app
# 创建目标目录
mkdir flink-on-yarn
# 解压时把内容放到 flink-on-yarn 下
tar -zxvf flink-1.9.1-bin-scala_2.11.tgz -C flink-on-yarn --strip-components=1
(2):配置 Hadoop 环境变量
-
编辑用户环境变量配置文件:
bashvim ~/.bashrc -
在文件末尾添加以下行,请将
/home/hadoop/app/hadoop/etc/hadoop替换为你实际的 Hadoop 配置目录路径:bashexport HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop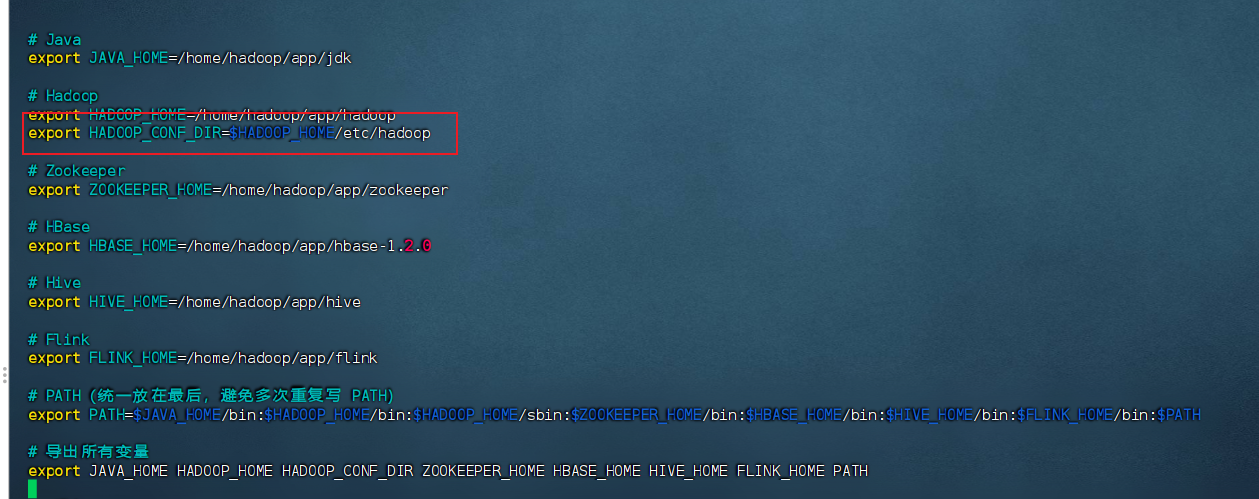
-
保存退出后,使环境变量立即生效:
bashsource ~/.bashrc -
验证配置是否正确:
bashecho $HADOOP_CONF_DIR #分发 # 从 hadoop01 分发到 hadoop02 和 hadoop03 scp ~/.bashrc hadoop02:~/ scp ~/.bashrc hadoop03:~/ source ~/.bashrc
(3):添加 Hadoop 依赖包
-
将下载好的 jar 包(例如 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar)上传到 Flink 的
lib目录下:bashmv flink-shaded-hadoop-2-uber-2.8.3-10.0.jar /home/hadoop/app/flink-on-yarn/lib -
确保该目录下有且只有一个
flink-shaded-hadoop-2-uberjar 包 ,多个可能会引起冲突。

(4):测试运行
先启动zookeeper,hdfs,yarn集群
bash
cd /home/hadoop/app/zookeeper/bin
./zkServer.sh start
start-dfs.sh
start-yarn.sh一定要确保hadoop01和hadoop02上都有ResourceManager代表yarn启动了,如果没有启动,可以单个启动
bash
yarn-daemon.sh start resourcemanager模式一:YARN Session(共享集群)
先在 hadoop01 上创建一个 Flink session:
bash
cd /home/hadoop/app/flink-on-yarn
bin/yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test_flink_cluster
#内存不足用:
cd /home/hadoop/app/flink-on-yarn
bin/yarn-session.sh -n 1 -s 1 -jm 768 -tm 768 -nm test_flink_cluster参数说明:
-n 2→ 2 个 TaskManager-s 2→ 每个 TaskManager 2 个 slot-jm 1024→ JobManager 内存 1GB-tm 1024→ 每个 TaskManager 内存 1GB-nm test_flink_cluster→ YARN 应用名称
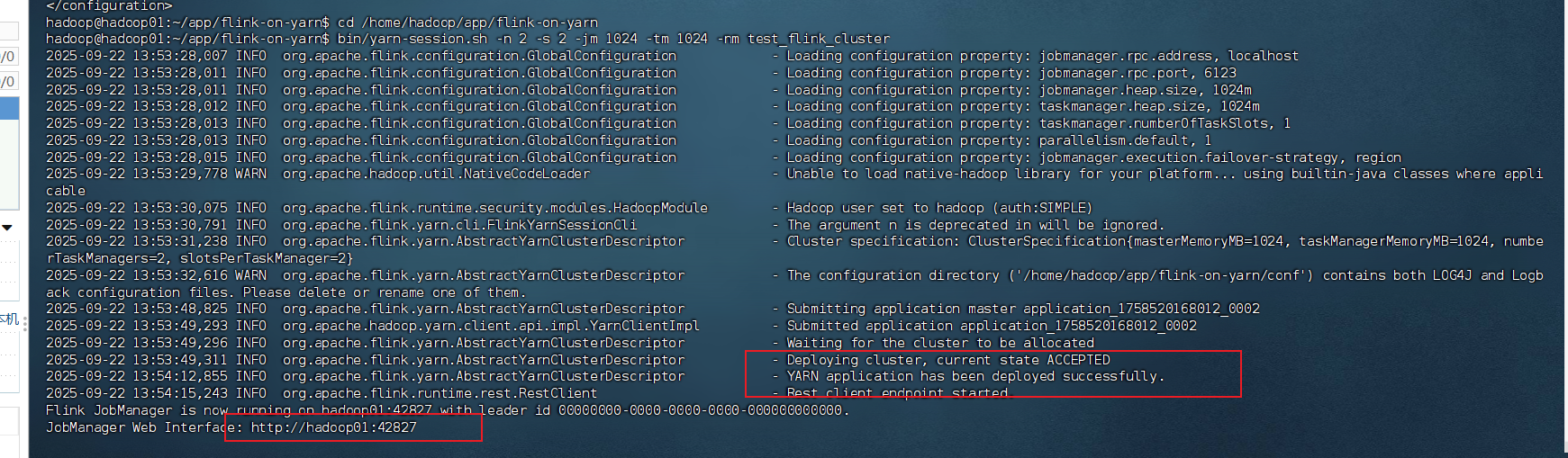
检查进程:
bash
jps
# 应该能看到 FlinkYarnSessionCli 和 YarnSessionClusterEntrypoint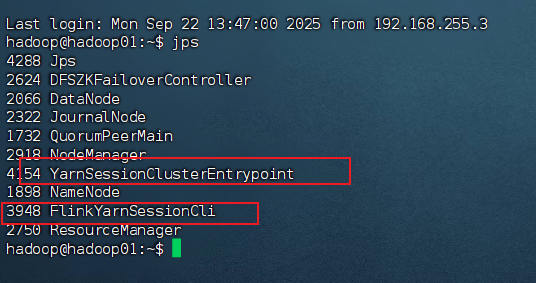
可通过浏览器访问:http://hadoop01:42827/
查看应用 ID:
bash
cd /home/hadoop/app/hadoop
bin/yarn application -list | grep test_flink_cluster | awk '{print $1}'
# 比如返回 application_1758520168012_0004
提交 WordCount Job 到该 session:
bash
cd /home/hadoop/app/flink-on-yarn
bin/flink run -yid application_1758520168012_0004 \
-c org.apache.flink.examples.java.wordcount.WordCount \
examples/batch/WordCount.jar \
--input hdfs://mycluster/test/djt.txt \
--output hdfs://mycluster/test/output3查看结果:
bash
cd /home/hadoop/app/hadoop
bin/hdfs dfs -cat /test/output3/*模式二:每个 Job 独立运行
直接提交 Job,不依赖常驻 session。
bash
cd /home/hadoop/app/flink-on-yarn
bin/flink run -m yarn-cluster -p 2 -yn 2 -ys 2 -yjm 1024 -ytm 1024 \
-c org.apache.flink.examples.java.wordcount.WordCount \
examples/batch/WordCount.jar \
--input hdfs://mycluster/test/djt.txt \
--output hdfs://mycluster/test/output4查看结果:
bash
cd /home/hadoop/app/hadoop
bin/hdfs dfs -cat /test/output4/*7.3
7.3.3 Flink DataStream 用户行为实时分析
一、业务代码实现
-
Maven 项目
使用书里提到的
learningflink1.9项目。 -
在 pom.xml 中引入依赖:
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.1</version>
</dependency>- GlobalConfig 类:
java
public class GlobalConfig implements Serializable {
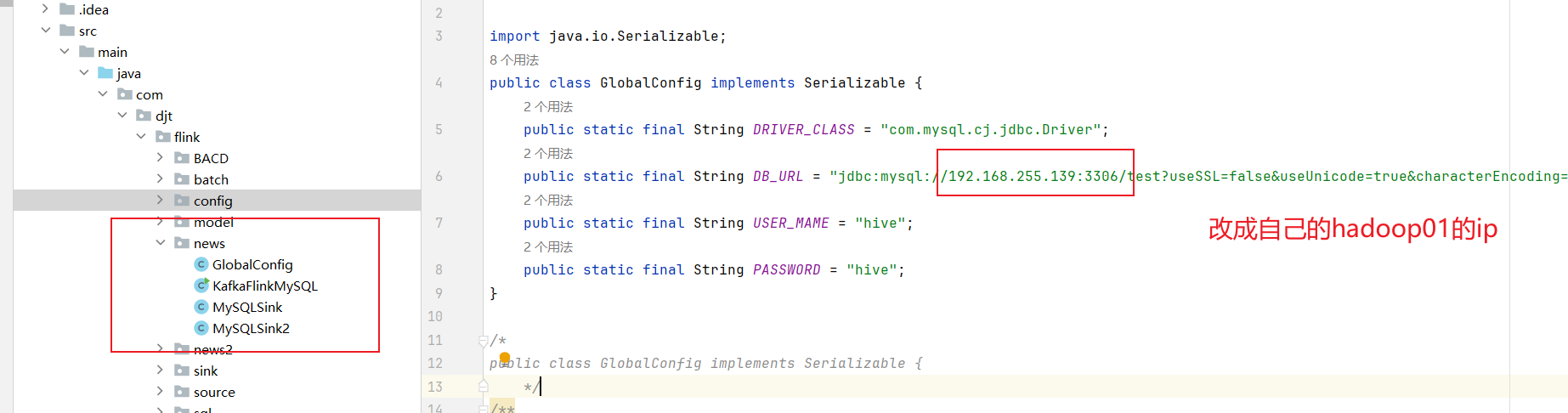
public static final String DRIVER_CLASS = "com.mysql.cj.jdbc.Driver";
public static final String DB_URL =
"jdbc:mysql://192.168.255.139:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai";
public static final String USER_MAME = "hive";
public static final String PASSWORD = "hive";
}
- KafkaFlinkMySQL 类:
java
import java.util.Properties;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
public class KafkaFlinkMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop01:9092,hadoop02:9092,hadoop03:9092");
properties.setProperty("group.id", "sogoulogs");
FlinkKafkaConsumer<String> myConsumer =
new FlinkKafkaConsumer<>("sogoulogs", new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<String> filter = stream.filter((value) -> value.split(",").length==6);
DataStream<Tuple2<String, Integer>> newsCounts =
filter.flatMap(new LineSplitter()).keyBy(0).sum(1);
newsCounts.addSink(new MySQLSink());
DataStream<Tuple2<String, Integer>> periodCounts =
filter.flatMap(new LineSplitter2()).keyBy(0).sum(1);
periodCounts.addSink(new MySQLSink2());
env.execute("FlinkMySQL");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String,Integer>> out) {
String[] tokens = value.toLowerCase().split(",");
out.collect(new Tuple2<>(tokens[2], 1));
}
}
public static final class LineSplitter2 implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String,Integer>> out) {
String[] tokens = value.toLowerCase().split(",");
out.collect(new Tuple2<>(tokens[0], 1));
}
}
}- MySQLSink 类 (书上的原文,只改
USER_MAME为USER_NAME):
java
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MySQLSink extends RichSinkFunction<Tuple2<String, Integer>> {
private Connection connection;
private PreparedStatement preparedStatement;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
super.open(parameters);
Class.forName(GlobalConfig.DRIVER_CLASS);
connection = DriverManager.getConnection(GlobalConfig.DB_URL, GlobalConfig.USER_NAME, GlobalConfig.PASSWORD);
}
@Override
public void close() throws Exception {
super.close();
if(preparedStatement != null){
preparedStatement.close();
}
if(connection != null){
connection.close();
}
super.close();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
try {
String name = value.f0.replaceAll("[\\[\\]]", "");
int count = value.f1;
String querySQL="select 1 from newscount where name = '"+name+"'";
String updateSQL="update newscount set count = "+count+" where name = '"+name+"'";
String insertSQL="insert into newscount(name,count)values ('"+name+"', "+count+")";
preparedStatement = connection.prepareStatement(querySQL);
ResultSet resultSet = preparedStatement.executeQuery();
if(resultSet.next()){
preparedStatement.executeUpdate(updateSQL);
}else{
preparedStatement.execute(insertSQL);
}
}catch (Exception e){
e.printStackTrace();
}
}
}- MySQLSink2 类(同理,书上原文,拼写修正):
java
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MySQLSink2 extends RichSinkFunction<Tuple2<String, Integer>> {
private Connection connection;
private PreparedStatement preparedStatement;
@Override
public void open(org.apache.flink.configuration.Configuration parameters) throws Exception {
super.open(parameters);
Class.forName(GlobalConfig.DRIVER_CLASS);
connection=DriverManager.getConnection(GlobalConfig.DB_URL, GlobalConfig.USER_NAME, GlobalConfig.PASSWORD);
}
@Override
public void close() throws Exception {
super.close();
if(preparedStatement != null){
preparedStatement.close();
}
if(connection != null){
connection.close();
}
super.close();
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
try {
String logtime = value.f0;
int count = value.f1;
String querySQL="select 1 from periodcount where logtime = '"+logtime+"'";
String updateSQL="update periodcount set count = "+count+" where logtime ='"+logtime+"'";
String insertSQL="insert into periodcount(logtime,count) values ('"+logtime+"',"+count+")";
preparedStatement = connection.prepareStatement(querySQL);
ResultSet resultSet = preparedStatement.executeQuery();
if(resultSet.next()){
preparedStatement.executeUpdate(updateSQL);
}else{
preparedStatement.execute(insertSQL);
}
}catch (Exception e){
e.printStackTrace();
}
}
}二、打通实时计算流程
去navicat里面把原始数据删除避免混淆

-
启动 MySQL 服务
启动 MySQL,保持
newscount、periodcount两张表存在。 -
启动 Zookeeper 集群
bashcd /home/hadoop/app/zookeeper bin/zkServer.sh start -
启动 Kafka 集群
每个节点执行:
bashcd /home/hadoop/app/kafka bin/kafka-server-start.sh -daemon config/server.properties -
启动 Flink 实时应用
在 IDEA 里右击
KafkaFlinkMySQL→ Run。
-
启动 Flume 聚合服务
在 hadoop02、hadoop03 各自目录:
bashcd /home/hadoop/app/flume bin/flume-ng agent -n a2 -c conf -f conf/xxx.conf -Dflume.root.logger=INFO,console & -
启动 Flume 采集服务
在 hadoop01:
bashcd /home/hadoop/app/flume bin/flume-ng agent -n a1 -c conf -f conf/xxx.conf -Dflume.root.logger=INFO,console & -
模拟产生数据
在 hadoop01:
bashcd /home/hadoop/shell/bin ./sogoulogs.sh
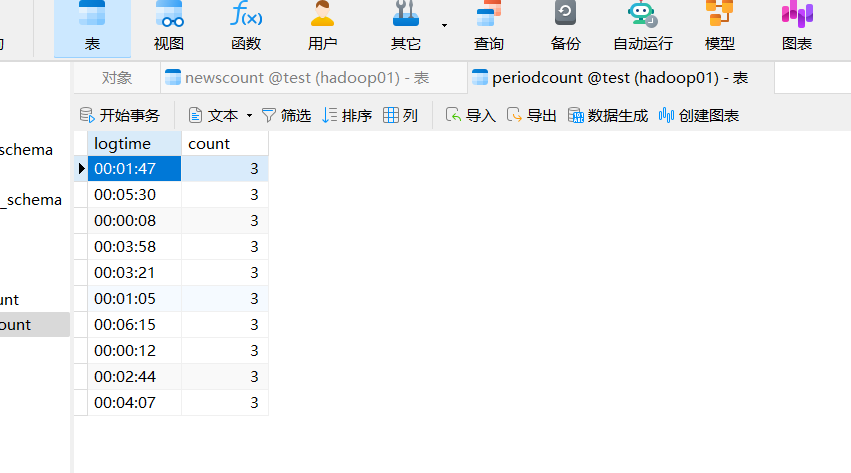
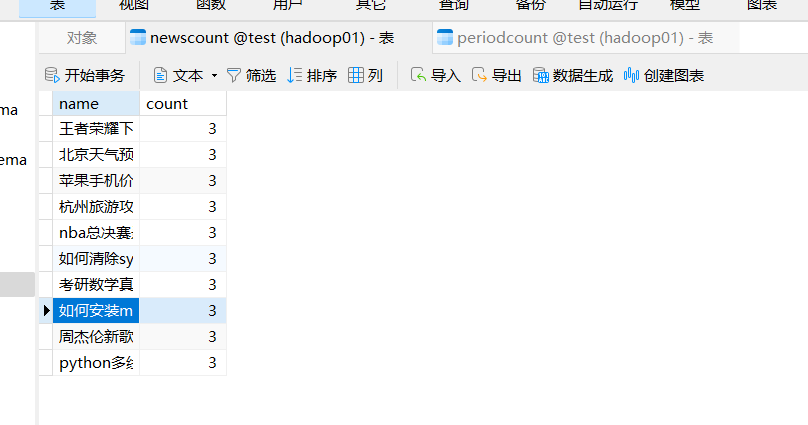
-
查询分析结果
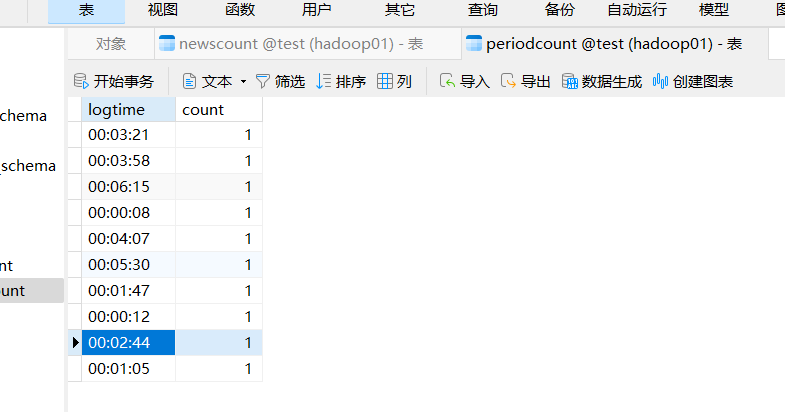
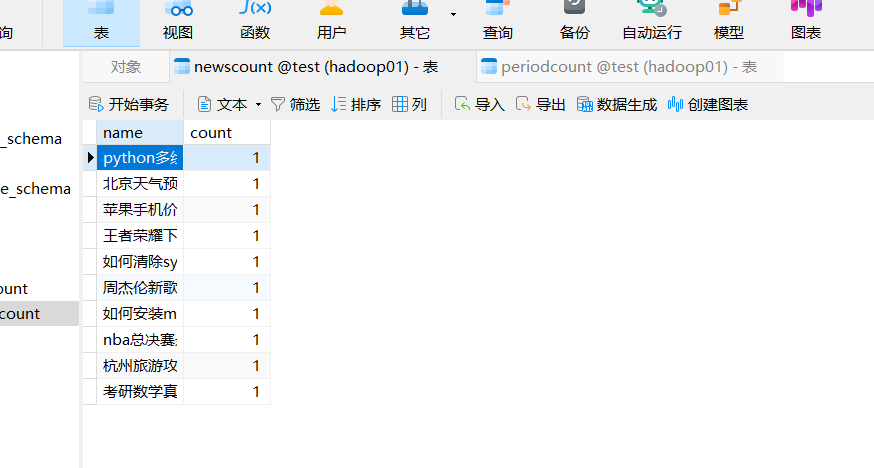
去navicat查看结果
7.4
7.4.3 Flink DataSet用户行为离线分析
一、业务代码实现
(1)在 pom.xml 中引入 MySQL 依赖
书上原文就是这两段:
xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.1</version>
</dependency>
<!-- 如果你是 MySQL 8.0,必须再加 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
(2)GlobalConfig.java
java
package com.djt.flink.news2;
import java.io.Serializable;
public class GlobalConfig implements Serializable {
/**
* 数据库driver class
*/
public static final String DRIVER_CLASS = "com.mysql.cj.jdbc.Driver";
/**
* 数据库jdbc url
*/
public static final String DB_URL = "jdbc:mysql://192.168.20.123:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai";
/**
* 数据库user name
*/
public static final String USER_MAME = "hive";
/**
* 数据库password
*/
public static final String PASSWORD = "hive";
/**
* 插入newscount表
*/
public static final String SQL="insert into newscount (name,count) values (?,?)";
/**
* 插入periodcount表
*/
public static final String SQL2="insert into periodcount (logtime,count) values (?,?)";
}
(3)FlinkDataSetMySQL.java
java
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.io.jdbc.JDBCOutputFormat;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
public class FlinkDataSetMySQL {
public static void main(String[] args) throws Exception {
// 获取 Flink 的运行环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取数据
DataSet<String> ds = env.readTextFile(args[0]);
// 对数据进行过滤
DataSet<String> filter = ds.filter((value) -> value.split(",").length == 6);
// 统计所有新闻话题浏览量
DataSet<Tuple2<String, Integer>> newsCounts =
filter.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
// 数据转换
DataSet<Row> outputData = newsCounts.map(new MapFunction<Tuple2<String, Integer>, Row>() {
public Row map(Tuple2<String, Integer> t) throws Exception {
Row row = new Row(2);
row.setField(0, t.f0.replaceAll("[\\[\\]]", ""));
row.setField(1, t.f1.intValue());
return row;
}
});
// 数据输出到 newscount 表
outputData.output(JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername(GlobalConfig.DRIVER_CLASS)
.setDBUrl(GlobalConfig.DB_URL)
.setUsername(GlobalConfig.USER_NAME)
.setPassword(GlobalConfig.PASSWORD)
.setQuery(GlobalConfig.SQL)
.finish());
// 统计所有时段新闻浏览量
DataSet<Tuple2<String, Integer>> periodCounts =
filter.flatMap(new LineSplitter2()).groupBy(0).sum(1);
// 数据转换
DataSet<Row> outputData2 = periodCounts.map(new MapFunction<Tuple2<String, Integer>, Row>() {
public Row map(Tuple2<String, Integer> t) throws Exception {
Row row = new Row(2);
row.setField(0, t.f0);
row.setField(1, t.f1.intValue());
return row;
}
});
// 数据输出到 periodcount 表
outputData2.output(JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername(GlobalConfig.DRIVER_CLASS)
.setDBUrl(GlobalConfig.DB_URL)
.setUsername(GlobalConfig.USER_NAME)
.setPassword(GlobalConfig.PASSWORD)
.setQuery(GlobalConfig.SQL2)
.finish());
// 执行 Flink 程序
env.execute("FlinkDataSetMySQL");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split(",");
out.collect(new Tuple2<>(tokens[2], 1));
}
}
public static final class LineSplitter2 implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split(",");
out.collect(new Tuple2<>(tokens[0], 1));
}
}
}二、打通离线计算流程
-
启动 MySQL 服务
确保
newscount和periodcount两张表存在去navicat把表数据清空
-
准备测试数据
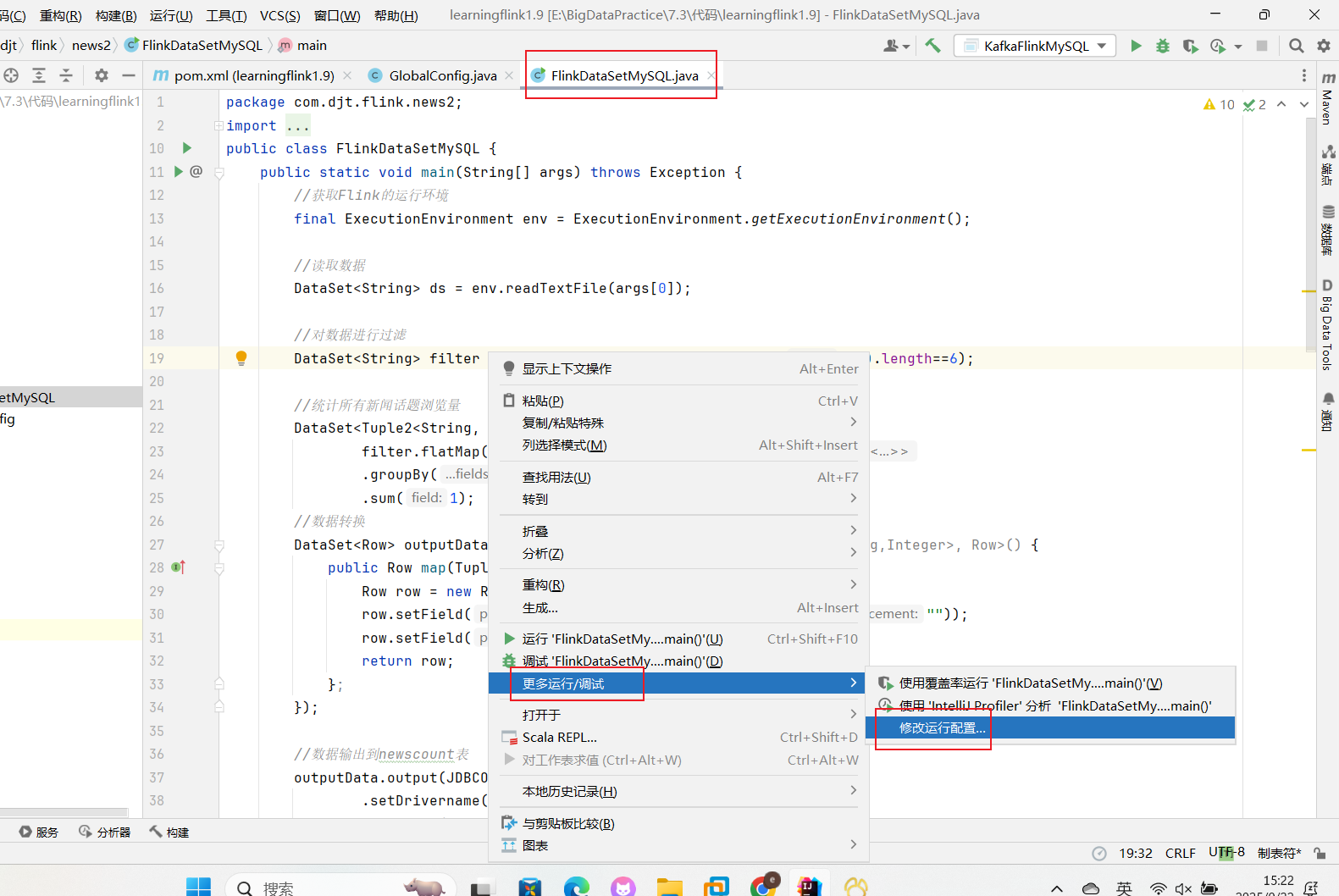
在idea里面修改运行配置
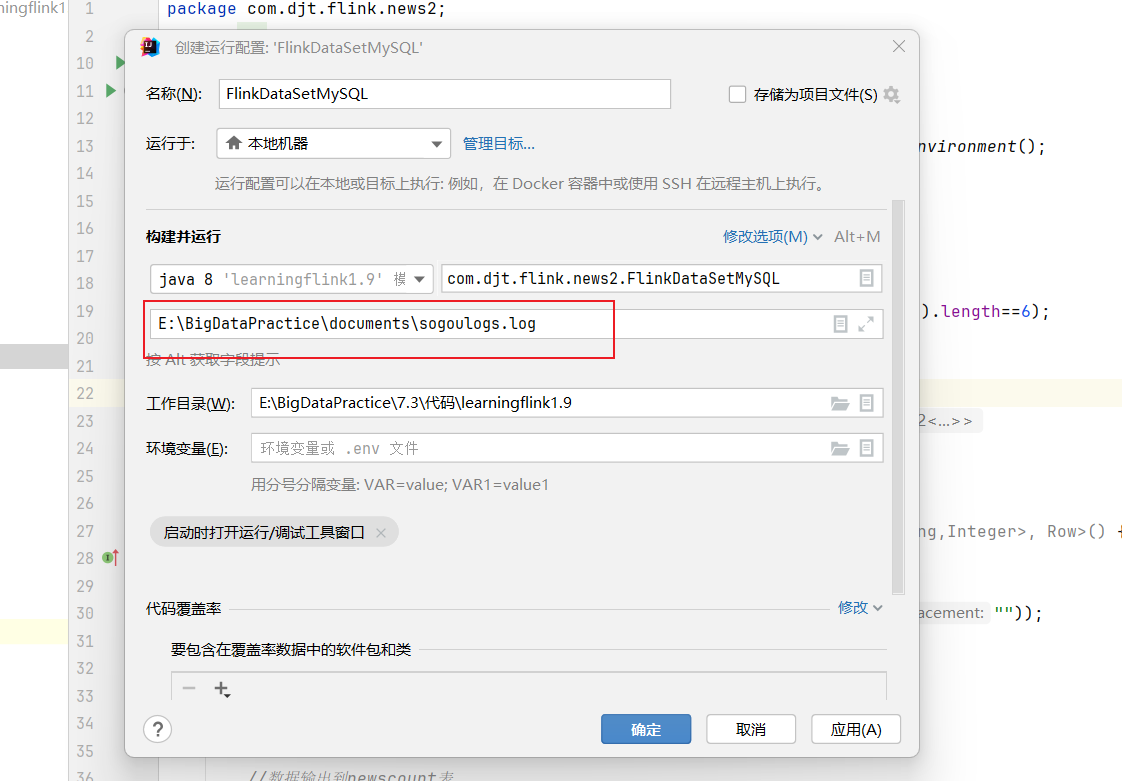
-
启动 Flink DataSet 离线应用
- 在 IDEA 中右击
FlinkDataSetMySQL→ Run。 - 本地运行即可;也可以打包 jar 提交到 Flink 集群。
- 在 IDEA 中右击
-
查询分析结果
去navicat查看结果