目录
[为什么需要 MVCC?------ 解决并发问题](#为什么需要 MVCC?—— 解决并发问题)
[MVCC 是如何工作的?](#MVCC 是如何工作的?)
[1. 数据版本链(核心存储)](#1. 数据版本链(核心存储))
[2. Read View(读视图 - 决定能看到哪个版本)](#2. Read View(读视图 - 决定能看到哪个版本))
[3. Undo Log(实现版本链的基础)](#3. Undo Log(实现版本链的基础))
[MVCC 的优缺点](#MVCC 的优缺点)
MVCC ,全称为 Multi-Version Concurrency Control ,中文是多版本并发控制。
它是一种数据库管理系统常用的技术,用于高效地处理多用户环境下的读写并发冲突,从而在保证数据一致性的同时,大幅提高性能。
它的核心思想非常直观:不为数据行加锁,而是为每次写操作创建数据的一个新版本(快照)。这样,读操作和写操作可以同时进行,因为读操作可以去读旧版本的数据,而写操作则创建新版本。
为什么需要 MVCC?------ 解决并发问题
在没有 MVCC 的锁机制下(如简单的行锁),当多个事务同时访问数据库时:
-
写会阻塞读:一个事务正在更新某行数据时会加锁,其他事务想要读取这行数据就必须等待,直到写操作完成并释放锁。
-
读会阻塞写:一个事务正在读取某行数据时也会加锁,其他事务想要更新这行数据同样必须等待。
-
性能瓶颈:在高并发场景下,这种频繁的加锁、等待、释放锁会导致大量的性能开销和延迟。
MVCC 完美地解决了这个"读-写冲突"问题,它让:
-
读不阻塞写:一个事务在读取数据时,另一个事务可以同时修改该数据。
-
写不阻塞读:一个事务在修改数据时,另一个事务可以同时读取该数据的旧版本。
MVCC 是如何工作的?
MVCC 的实现细节因数据库而异(如 MySQL InnoDB 和 PostgreSQL 的实现方式就不同),但其核心原理是相通的。主要依赖以下三个关键技术点:
1. 数据版本链(核心存储)
数据库中的每一行数据都不会直接被覆盖更新。相反,每次更新时,都会创建该行数据的一个新版本 ,并将旧版本保留。这些版本通过指针或事务ID相互链接,形成一个版本链。
在 MySQL InnoDB 中:
每行记录都有两个(或三个)隐藏字段:
-
DB_ROW_ID:行ID(如果表没有主键,InnoDB 会自动生成这个隐藏字段作为聚簇索引的键)。 -
DB_ROLL_PTR:回滚指针。这个指针指向该行数据的前一个旧版本(存储在 Undo Log 中)。通过这个指针,可以追溯该行的所有历史版本。 -
DB_TRX_ID:最后修改该行数据的事务ID。当一个事务对某行进行修改时,会将其唯一的事务ID写入这个字段。
2. Read View(读视图 - 决定能看到哪个版本)
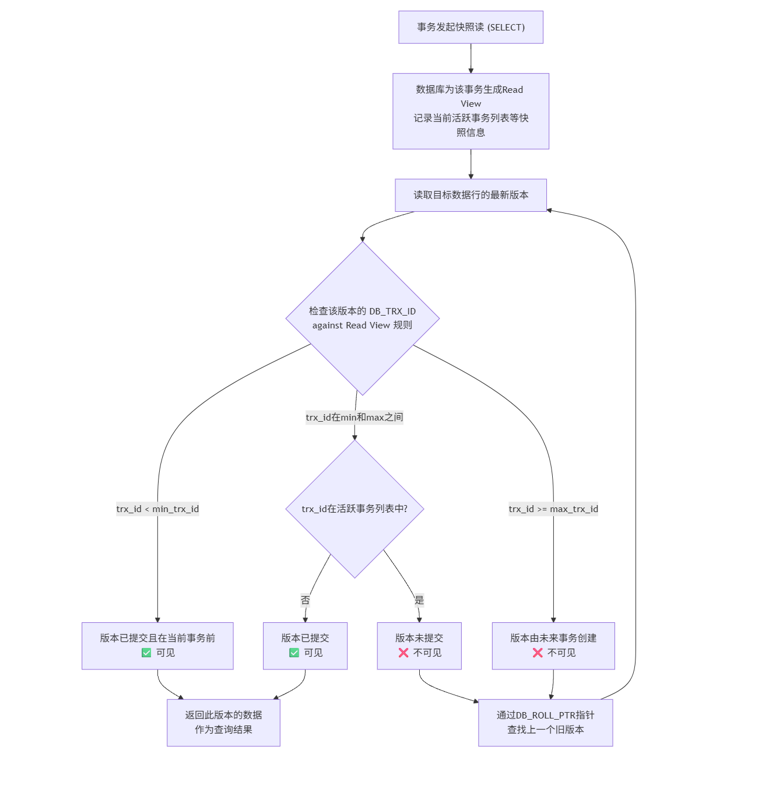
当一个事务执行快照读 (普通的 SELECT 语句,不加锁)时,数据库会为这个事务生成一个Read View(读视图)。这个 Read View 就像是给数据库拍了一张"快照",它定义了当前事务能看到哪些数据版本。
Read View 主要包含以下信息:
-
m_ids:生成 Read View 时,系统中活跃(尚未提交)的所有事务ID列表。 -
min_trx_id:m_ids中最小的那个事务ID。 -
max_trx_id:生成 Read View 时,系统将要分配给下一个新事务的ID。 -
creator_trx_id:创建这个 Read View 的事务自己的ID。
版本可见性规则 :
事务根据 Read View 和版本链中每个版本的 DB_TRX_ID 来判断某个版本是否可见:
-
如果被访问版本的
DB_TRX_ID<min_trx_id,说明该版本在当前事务开始前就已经提交,可见。 -
如果被访问版本的
DB_TRX_ID>=max_trx_id,说明该版本是由在当前事务开始之后才开启的事务修改的,不可见。 -
如果
min_trx_id<=DB_TRX_ID<max_trx_id,则需要判断DB_TRX_ID是否在m_ids(活跃事务列表)中:-
如果在,说明创建该版本的事务当时还未提交,该版本不可见。
-
如果不在,说明创建该版本的事务当时已经提交,该版本可见。
-
如果某个版本对当前事务不可见,就顺着回滚指针 DB_ROLL_PTR 找到上一个版本,重复上述判断规则,直到找到最老的、对其可见的版本为止。
3. Undo Log(实现版本链的基础)
Undo Log (回滚日志)是 MVCC 能够实现的关键。旧的数据版本并不是直接存储在表空间中,而是存储在 Undo Log 中。那个
DB_ROLL_PTR回滚指针指向的就是 Undo Log 中的记录。通过 Undo Log,不仅可以构建出版本链,还能够在事务回滚时,将数据恢复到事务开始前的状态。
一个简单的例子
假设:
-
事务A(ID=10)开始,要读取某行数据
X。 -
此时,事务B(ID=20)已经修改了
X为X1并提交。 -
同时,事务C(ID=30)正在修改
X为X2,但还未提交。
此时,数据库中存在 X 的多个版本:当前值是 X2(由事务C修改,未提交),上一个版本是 X1(由事务B修改,已提交),最早版本是 X。
当事务A执行 SELECT * FROM table WHERE ... 时:
-
数据库为事务A生成一个 Read View,其中
m_ids包含 30(活跃事务),min_trx_id=30,max_trx_id=31。 -
事务A首先找到最新的版本
X2,其DB_TRX_ID=30。 -
根据规则判断:
30在m_ids中且30>=min_trx_id,所以X2对事务A不可见。 -
通过回滚指针找到上一个版本
X1,其DB_TRX_ID=20。 -
判断:
20<min_trx_id(30),所以X1对事务A可见。
因此,事务A读到的值是 X1,完全不受未提交的事务C的影响,也无需等待任何锁。
MVCC 的优缺点
优点:
-
高并发:极大地提高了读-写并发性能,读不阻塞写,写不阻塞读。
-
避免幻读 :在可重复读(Repeatable Read) 隔离级别下,通过 MVCC 可以避免大部分幻读现象(MySQL InnoDB 还通过 Next-Key Lock 进一步保证)。
-
高性能:避免了大量的加锁开销。
缺点:
-
额外存储:需要存储数据的多个版本,会占用更多的磁盘空间。
-
维护开销:需要维护版本链和清理不再需要的旧版本数据(Purge 操作)。
-
复杂性:实现逻辑比简单的锁机制复杂得多。
假设我们有一行数据 X,它经历了三次修改。MVCC 会通过隐藏字段 DB_TRX_ID 和 DB_ROLL_PTR 形成一个版本链。
| 操作序列 (按时间顺序) | 表中数据(隐藏字段) | 版本链说明 |
|---|---|---|
| 初始状态 | 值: X DB_TRX_ID: 5 DB_ROLL_PTR: NULL |
由事务5插入或更新。它是链头,没有更旧的版本。 |
← 事务20更新为 X1 |
值: X1 DB_TRX_ID: 20 DB_ROLL_PTR: --> (指向X的指针) |
最新版本是X1。回滚指针指向旧版本X。 |
← 事务30更新为 X2 |
值: X2 DB_TRX_ID: 30 DB_ROLL_PTR: --> (指向X1的指针) |
当前最新版本 是X2。回滚指针指向X1,而X1又指向X,形成一条链。 |
总结
MVCC 是现代数据库(如 MySQL InnoDB, PostgreSQL, Oracle 等)实现高并发事务的核心技术。它通过为数据创建多个版本 ,并结合 Read View 机制来决定事务应该看到哪个版本的数据,从而在不加锁的情况下实现了非阻塞的读操作,完美地平衡了并发性能和数据一致性。