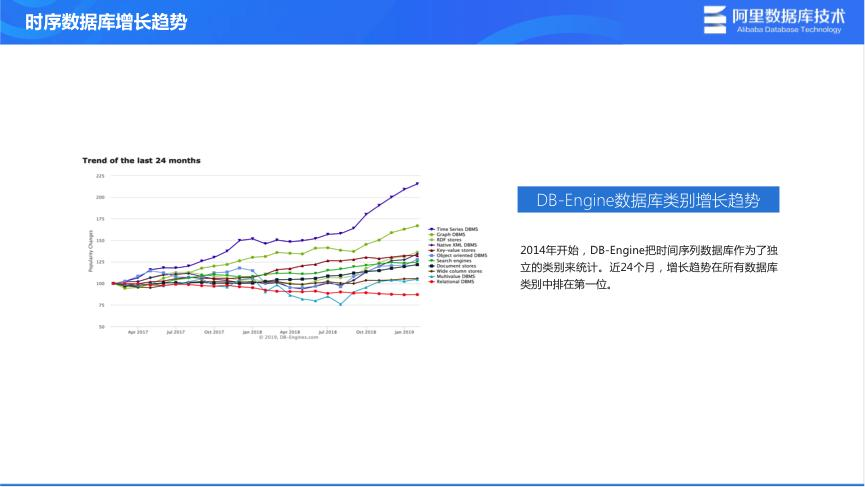
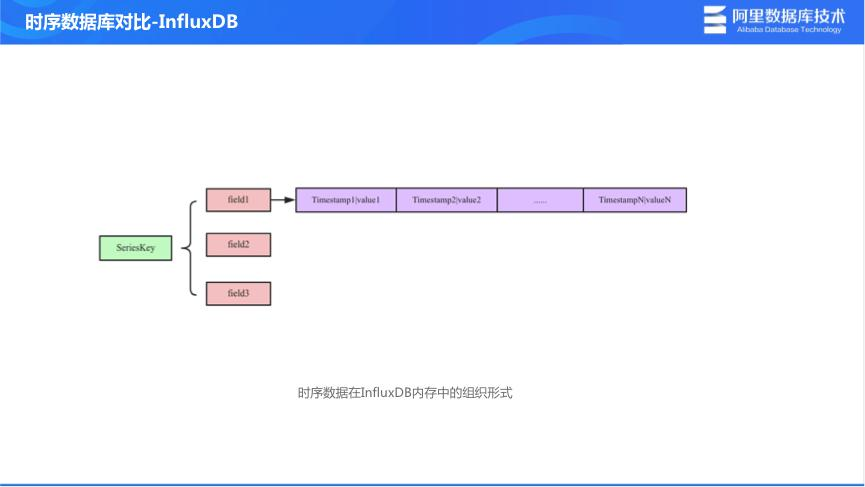
概念解析
在物联网设备每秒产生百万级数据点、工业传感器全年无休监测生产线、金融系统毫秒级记录交易流水的今天,时序数据的爆炸式增长 正给传统数据管理体系带来严峻挑战。这类以时间戳为核心标识、具有高频写入、批量读取、生命周期明确特征的数据(如CPU使用率、温度监测值、股价波动),传统关系型数据库因行存储架构和低效压缩机制,往往陷入写入瓶颈或存储成本失控的困境[1](https://blog.csdn.net/nal/article/details/148649872)[2](https://juejin.cn/post/7467164101136990227)。此时,时序数据库(Time Series Database, TSDB) 作为专为时间序列数据设计的专用系统应运而生,其核心价值在于通过深度优化的存储引擎和算法,实现对海量时序数据的高效写入、压缩存储与实时分析[3](https://www.taosdata.com/tdengine/time-series-database/best-practices-of-time-series-database)。
核心定义与特性
时序数据库本质上是时间序列数据的专用管理系统 ,具备三大核心能力:首先是时间戳索引优化 ,所有数据按时间顺序存储,支持纳秒级精度的时间定位,确保时序关联性不丢失[4](https://www.163.com/dy/article/JHE799FG0556AA9H.html);其次是高吞吐写入机制 ,例如 InfluxDB 采用 TSM(Time Series Measurement)存储引擎,单机可实现每秒数十万数据点的写入性能,满足物联网传感器等高并发场景需求[5](https://www.influxdata.com/?ref=NEOXION.NET%20ultimate.internet.link.collection);最后是极致数据压缩 ,通过 Gorilla 算法等专用压缩技术,可实现 10:1 无损压缩,大幅降低存储成本------想象一下,1 TB 原始传感器数据经压缩后仅需 100 GB 存储空间,这对需要长期保存历史数据的企业而言意义重大[1](https://blog.csdn.net/nal/article/details/148649872)。
时序数据的核心构成单元
- 时间戳(Timestamp):数据产生的精确时刻,支持 Unix 时间戳或 ISO 8601 格式,精度可达纳秒级,是时序数据的"生命线"。
- 指标(Metric):被监测的具体对象,如"cpu.usage.percent""temperature.room1"。
- 标签(Tags):用于多维度分类的键值对,如"server=web01, region=us-east-1",决定数据查询的灵活性。
- 数据点(Point) :最小数据单元,结构示例:
{"timestamp": "2024-01-15T10:30:00Z", "metric": "cpu.usage", "tags": {"server": "web01"}, "value": 85.6}[1](https://blog.csdn.net/nal/article/details/148649872)。
主流分类与代表产品
根据部署方式和授权模式,时序数据库可分为三大类:开源型 如 InfluxDB、Prometheus,凭借活跃社区和免费特性成为开发者首选,InfluxDB 3.0 更基于 Rust 语言重构,引入 FDAP 技术栈提升性能[6](https://m.book118.com/html/2025/0226/7123133116010041.shtm)[7](https://www.influxdata.com/products/influxdb-overview/);商业型 如 Oracle TimesTen,提供企业级 SLA 和专属支持,但需付费使用[6](https://m.book118.com/html/2025/0226/7123133116010041.shtm);云原生型 如 AWS Time Series Database,按需付费且免硬件维护,适合弹性扩展场景[6](https://m.book118.com/html/2025/0226/7123133116010041.shtm)。此外,TimescaleDB 等"混血儿"通过 PostgreSQL 扩展实现,既保留 SQL 兼容性,又获得时序优化能力,成为传统数据库用户的过渡选择[8](https://www.timescale.com/cloud-pg-performance/)。
与传统关系型数据库的本质差异
传统关系型数据库(RDBMS)设计初衷是处理结构化事务数据(如订单、用户信息),而时序数据库则针对时间序列数据的特殊规律深度优化,二者在核心架构上存在显著区别:
| 对比维度 | 传统关系型数据库 | 时序数据库 |
|---|---|---|
| 存储引擎 | 行存储为主,强调事务一致性 | 列存储/混合存储,优化时间分区 |
| 写入性能 | 每秒数千级写入,受事务锁限制 | 每秒数十万级写入,LSM Tree/TSM 引擎 |
| 查询优化 | 基于主键/索引的随机查询 | 基于时间范围的批量聚合查询 |
| 数据生命周期 | 需手动分区/清理 | 自动降采样(Downsampling)与 TTL |
| 典型场景 | 电商订单、财务报表 | 物联网监控、系统运维、金融高频交易 |
例如,当需要查询"过去 24 小时全球 10 万台服务器的平均 CPU 使用率"时,RDBMS 需扫描大量行数据并关联多张表,而时序数据库可通过时间分区索引 直接定位目标数据块,并利用预计算聚合结果返回,查询效率提升 10-100 倍[9](https://www.taosdata.com/tdengine-engineering/24986.html)。这种架构差异使得时序数据库在高频写入、时间范围分析场景中具有不可替代性,成为数据爆炸时代的关键基础设施。
应用场景
时序数据库正以"数据引擎"的角色渗透到千行百业,尤其在物联网、金融、AI等数据密集型领域展现出不可替代的价值。以下结合2024-2025年最新实践,从领域-案例-技术支撑-价值四维度解析其落地图景。
工业物联网:从设备监控到智能制造的核心引擎
工业场景已成为时序数据库最大应用市场,2025年全球工业时序数据规模预计突破80 ZB ,年增速达45%。头部企业通过"边缘+云"架构实现全链路数据掌控:
- 智能制造 :蘑菇物联基于TDengine构建公辅能源云智控平台,每天处理超100 GB IoT数据,服务1600余家 工业企业,通过超级表模型对空压机、冷水机等设备进行层级化管理,结合流计算实现按需供能,帮助某汽车零部件厂节能18% ,年降本超600万元 [10](https://www.cnblogs.com/taosdata/p/18972305)。
- 车联网 :中移物联网采用TDengine 3.0集群支撑海量轨迹数据存储,稳定管理2000亿行 车辆位置信息,每天写入约2亿行 轨迹点,单设备单日轨迹查询响应时间小于0.1秒 ,为智能调度和安全预警提供实时数据底座[10](https://www.cnblogs.com/taosdata/p/18972305)。
- 高端制造 :中航成飞、德国宝马等企业通过IoTDB的树模型映射飞机机身、汽车生产线的物理层级关系,实现对焊接温度、扭矩等工艺参数的毫秒级采集,不良品率降低12% [11](https://www.modb.pro/db/1846121358616522752)[12](https://blog.csdn.net/focus_on_data/article/details/146318228)。
技术支撑 :TDengine的超级表模型解决设备多维度标签管理难题,流计算引擎实现边缘端实时聚合;IoTDB的分层存储策略将热数据查询延迟压缩至5毫秒内 ,冷数据存储成本降低70%。
金融科技:从高频交易到风险防控的实时屏障
金融领域对时序数据库的需求聚焦于低延迟写入 与复杂指标计算 ,2025年该领域时序数据市场规模预计达12亿美元。
- 高频交易场景 :某头部券商采用TDengine替代传统关系型数据库后,股票行情数据写入延迟从秒级 降至0.1秒 ,支持每秒50万笔 订单数据处理,在2024年A股"极端行情日"中,系统稳定性较同业提升30% [3](https://www.taosdata.com/tdengine/time-series-database/best-practices-of-time-series-database)。
- 风险管理 :Capital One通过InfluxDB构建实时指标监控平台,整合信用卡交易、服务器负载等10万+指标 ,结合机器学习模型预测流动性风险,异常交易识别准确率提升25% ,欺诈损失减少1.2亿美元/年 [13](https://www.influxdata.com/customer/capital-one/)。
- 加密货币市场 :Coinbase利用TimescaleDB存储比特币、以太坊的10亿级 订单簿数据,支持分钟级K线生成和套利策略回测,交易策略迭代周期从周级 缩短至日级 [14](https://www.timescale.com/crypto/?rel=outbound)。
技术支撑 :TDengine的列式存储与预计算引擎实现高吞吐写入;TimescaleDB的时间分区表优化历史数据查询,较PostgreSQL原生性能提升100倍 [15](https://www.slingacademy.com/article/how-to-integrate-timescaledb-with-postgresql-for-financial-data-analysis/)。
AI与向量数据:大模型时代的"记忆中枢"
随着生成式AI爆发,时序数据库开始承担向量嵌入存储角色,2025年相关应用场景增速预计达150%。
- 语义搜索 :某电商平台采用Timescale Vector存储商品描述的10亿级 向量嵌入,结合时序特征(如用户点击序列)实现动态推荐,商品点击率提升22% ,转化率提高15% [16](https://blog.csdn.net/2501_92325368/article/details/148534750)。
- 图像检索 :Google Cloud利用InfluxDB存储卫星图像的特征向量,支持实时比对灾害前后地表变化,森林火灾识别速度从小时级 压缩至5分钟内 [17](https://www.influxdata.com/)。
- 模型监控 :OpenAI通过InfluxDB收集GPT-4推理时的GPU利用率、Token生成速度 等指标,设置动态阈值警报,模型异常率降低40% ,服务可用性保持99.99% [18](https://www.influxdata.com/blog/algorithmia-ml-model-performance-visualization-made-easy-with-this-influxdb-template/)。
技术支撑 :Timescale Vector的向量-时序混合索引支持"语义+时间"联合查询;InfluxDB 3.0的列式存储将向量检索延迟控制在毫秒级。
监控与运维:从被动响应到主动预警的范式转变
监控场景占据时序数据库35% 的市场份额,云原生与边缘计算推动其向"全域可观测"演进。
- 云原生监控 :Prometheus成为Kubernetes生态标配,某互联网大厂通过Prometheus监控5000+节点 的容器集群,结合Thanos实现跨地域数据联邦,CPU使用率异常检测准确率达98% ,故障恢复时间缩短60% [19](https://blog.csdn.net/Moonlight_Dream/article/details/151085589)。
- 企业级SaaS监控 :RingCentral基于InfluxDB栈构建监控即服务(MaaS)平台,覆盖云PBX、视频会议等四大产品支柱 的200+指标 ,服务中断预警提前量从5分钟 延长至30分钟 ,用户满意度提升18% [20](https://www.influxdata.com/blog/building-a-metrics-alerts-as-a-service-maas-monitoring-solution-using-the-influxdb-stack/)。
- 边缘设备监控 :西门子在风力发电机边缘网关部署轻量级TSDB,实时采集叶片振动、齿轮箱温度数据,通过时序异常检测模型预测故障,单机维护成本降低25% ,发电量提升8% [21](https://www.influxdata.com/blog/how-supralog-built-an-online-incremental-machine-learning-pipeline-with-influxdb-for-capacity-planning/)。
技术支撑:Prometheus的拉取式采集适配动态容器环境;InfluxDB的TICK栈(Telegraf+InfluxDB+Chronograf+Kapacitor)实现"采集-存储-可视化-告警"全链路闭环。
能源与公用事业:从粗放管理到精细运营的能效革命
能源领域时序数据呈现"高并发写入+长周期存储 "特征,2025年单厂级数据规模普遍突破10 PB/年。
- 智能电网 :国家电网通过IoTDB存储全网2亿+ 智能电表数据,结合历史负荷曲线预测区域用电高峰,峰谷调节精度提升30% ,弃风弃光率降低15% [11](https://www.modb.pro/db/1846121358616522752)。
- 油气开采 :BP石油采用InfluxDB监控深海钻井平台的压力、流量传感器数据,构建预测性维护模型,设备非计划停机时间减少40% ,单平台年节省维护成本800万美元 [22](https://www.influxdata.com/lp/why-influxdb-for-energy-and-utilities/)。
- 城市能源优化 :慕尼黑机场基于TDengine分析航站楼空调、照明的能耗时序特征,结合光照、人流数据动态调节,年节电1200万度 ,碳排放量减少8000吨 [23](http://www.linkedin.com/company/tdengine)。
技术支撑 :IoTDB的时间分区与值压缩技术将电表数据存储成本降低60%;InfluxDB的Flux脚本支持复杂能效指标(如EUI建筑能耗指数)的实时计算。
各领域数据规模与增长趋势
- 工业物联网:2025年全球设备连接数将达750亿 ,年数据增量超50 ZB
- 金融交易:高频交易场景单交易所日数据量突破10 TB ,年增速35%
- AI向量数据:语义搜索场景向量嵌入规模年增长200% ,单模型训练数据超10亿向量
- 能源监控:单风电场传感器日采集数据8 TB ,预测性维护渗透率从2022年17% 升至2025年43%

从工业传感器到金融K线,从AI向量到城市能源,时序数据库正成为数字经济的"神经中枢"。其核心价值不仅在于存储海量时间序列数据,更在于通过实时分析-历史挖掘-预测建模的全链路能力,将数据转化为可行动的洞察------这正是企业在"实时化、智能化"时代保持竞争力的关键所在。未来,随着边缘计算与AI大模型的深度融合,时序数据库将进一步向"数据处理+智能决策"一体化平台演进。
技术选型
时序数据库选型需兼顾性能、成本与生态的动态平衡。2024-2025年主流产品通过架构革新与协议升级持续突破边界,企业需结合场景特性构建科学决策框架。
三维评估模型:性能、成本与生态的核心博弈
性能维度:从百万级写入到亚秒级响应
- InfluxDB 3.0 :采用Apache Arrow+Parquet格式重构存储引擎,写入性能提升10倍,查询性能提升100倍,单机可处理每秒数百万时序数据点,支持无限基数场景下的实时分析[2](https://juejin.cn/post/7467164101136990227)[24](https://www.influxdata.com/products/influxdb3/)。
- TDengine 3.0 :通过超级表(STable)模型与原生分布式架构,实现380万点/秒的写入性能,压缩比达8:1,同时支持行存储与列存储双引擎,适配工业物联网高频采集场景[25](https://www.taosdata.com)[26](https://www.jiangyoupai.com/p/hRrgqRrL-RBYx6rdjRtL)。
- TimescaleDB :作为PostgreSQL扩展,依托自动时间分区与索引技术,时序查询速度比传统PostgreSQL快10-100倍,单表支持10亿级数据,冷数据压缩率达90%,适合金融时间序列分析[15](https://www.slingacademy.com/article/how-to-integrate-timescaledb-with-postgresql-for-financial-data-analysis/)[27](https://www.timescale.com/time-series-b/)。
- Prometheus 3.0 :原生支持OTLP协议,单机写入性能达10万点/秒,通过Remote Write 2.0协议优化数据传输,减少网络消息量60%、内存分配90%,成为Kubernetes监控的标杆选择[28](http://www.163.com/dy/article/JLA8GOUU0511D3QS.html)[29](https://prometheus.io/docs/introduction/faq/)。
成本维度:从存储压缩到生态复用
- 存储优化 :InfluxDB 3.0通过Parquet格式与S3对象存储实现4.5倍存储缩减,存储成本降低90%;TDengine存储空间仅为MySQL方案的1/7,工业场景部署可节省硬件投入[7](https://www.influxdata.com/products/influxdb-overview/)[10](https://www.cnblogs.com/taosdata/p/18972305)。
- 生态复用 :TimescaleDB直接复用PostgreSQL生态,支持pgvector向量扩展与AI语义搜索,避免多数据库维护成本;Prometheus与云原生工具链(Grafana、Alertmanager)无缝集成,降低DevOps团队学习成本[19](https://blog.csdn.net/Moonlight_Dream/article/details/151085589)[30](https://cerebralvalley.ai/blog/timescale-is-making-postgresql-better-for-ai-1tiUqSzGsSn76ORZVfMwOk)。
生态维度:从插件集成到云边协同
- InfluxDB :提供300+ Telegraf数据采集插件,支持5000+预构建集成,覆盖从边缘设备到云端的全场景部署,其Cloud Serverless方案按使用量付费,适合中小规模 workload[31](https://www.influxdata.com/get-influx/)[32](https://www.influxdata.com/solutions/devops-monitoring/)。
- TDengine :采用边缘-云架构,支持多级存储(热数据SSD、冷数据对象存储),与OPC、MQTT等工业协议原生对接,全球部署超10万个实例,GitHub Star数超17k[33](https://gitee.com/taosdata?skip_mobile=true)[34](https://tdengine.com/ems/)。
主流产品核心特性对比表
| 产品 | 2024-2025新特性 | 性能指标 | 适用场景 | 部署成本 |
|---|---|---|---|---|
| InfluxDB 3.0 | Apache Arrow+Parquet格式、SQL查询支持 | 写入提升10倍,查询提升100倍 | DevOps监控、IoT数据平台 | 云服务按需付费,存储成本降低90% |
| TDengine 3.0 | 超级表模型、内置流计算 | 380万点/秒写入,压缩比8:1 | 工业互联网、车联网 | 开源免费,硬件成本节省70% |
| TimescaleDB | pgvector兼容、AI语义搜索 | 单表10亿级数据,查询提速10-100倍 | 金融时序分析、混合数据场景 | 复用PostgreSQL生态,学习成本低 |
| Prometheus 3.0 | OTLP协议原生支持、Remote Write 2.0 | 单机10万点/秒,联邦部署支持千万级序列 | Kubernetes监控、微服务可观测性 | 开源免费,需自建高可用集群 |
分角色决策路径:从需求到选型的精准匹配
数据库工程师视角 :优先关注写入性能与扩展性。工业物联网场景首选TDengine,其分布式架构支持节点线性扩展,380万点/秒写入能力满足高频采集需求;大规模DevOps监控可考虑InfluxDB 3.0,Apache Arrow格式优化使查询延迟降至毫秒级[24](https://www.influxdata.com/products/influxdb3/)[25](https://www.taosdata.com)。
DevOps从业者视角 :生态集成能力是关键。Prometheus 3.0通过OTLP协议与现代可观测性工具链无缝对接,配合Grafana可视化与Alertmanager告警,形成完整监控闭环;若需同时处理时序数据与关系数据,TimescaleDB的PostgreSQL扩展特性可直接复用现有SQL技能栈[28](http://www.163.com/dy/article/JLA8GOUU0511D3QS.html)[35](https://github.com/timescale/)。
技术决策者视角 :TCO(总拥有成本)需综合评估。中小团队推荐Prometheus+Grafana组合,开源免费且社区支持完善;金融机构可选择TimescaleDB,利用PostgreSQL生态降低迁移成本;超大规模IoT平台优先InfluxDB Cloud Dedicated,单租户架构保障数据隔离与合规性[8](https://www.timescale.com/cloud-pg-performance/)[31](https://www.influxdata.com/get-influx/)。
选型决策树:动态场景下的路径指引
实际选型需结合三大核心维度:
- 数据规模:百万级/秒写入选TDengine/InfluxDB,千万级序列需Prometheus联邦部署;
- 实时性要求:毫秒级响应优先InfluxDB 3.0,离线分析可考虑TimescaleDB的连续聚合功能;
- 部署环境:Kubernetes集群首选Prometheus,边缘设备适配TDengine轻量级部署,混合云架构推荐InfluxDB的多云同步能力。
通过动态平衡性能需求、成本预算与生态兼容性,企业可构建适配自身业务增长的时序数据基础设施。
实践指南
时序数据库的落地实践需直面三大核心挑战:高并发写入场景下的数据模型适配、万亿级数据量的查询性能优化、以及存储成本与访问效率的平衡。2024 年技术演进下,主流数据库通过架构创新与算法优化给出了差异化解决方案,以下从数据模型设计、索引策略、压缩算法三大维度展开实践指南。
数据模型设计:从设备特性到架构选型
核心问题:如何在多设备、高频采集场景下,兼顾写入吞吐量与查询灵活性?传统关系型数据库的"一表多设备"模式会导致索引膨胀,而简单分表又难以应对标签维度的复杂筛选。
解决方案对比:
-
TDengine:"超级表 + 子表"的设备级隔离
基于"一个设备一张表"的设计哲学,通过超级表(STABLE) 定义设备共性结构(指标字段),子表(TABLE) 绑定设备唯一标签(如设备 ID、位置),实现数据的逻辑聚合与物理隔离。例如消防设备监控中,创建包含电流、温度等指标的超级表,每个设备对应独立子表,既避免单表写入竞争,又支持按标签快速筛选:
sql-- TDengine 超级表示例(消防设备监控) CREATE STABLE electrical_fire_device ( ts timestamp, residual_current float, -- 剩余电流 A_phase_temperature float -- A相温度 ) TAGS ( device_address varchar(32), -- 设备地址(标签) building_id varchar(32) -- 楼宇ID(标签) ); -- 自动创建子表(设备级隔离) INSERT INTO device_001 USING electrical_fire_device TAGS ('BuildingA-3F', 'B101') VALUES (NOW(), 3.2, 45.6);2024 年演进:支持按测点采集频率拆分多超级表(如秒级、分钟级测点分表),解决混合采样率场景下的存储碎片化问题。
-
TimescaleDB:PostgreSQL 生态的时间分区表
基于 PostgreSQL 扩展实现超表(Hypertable),自动按时间(如按天)或空间维度拆分分区,同时保留 SQL 兼容性。适合需与关系数据关联分析的场景,例如金融交易监控中,将历史数据压缩归档,实时数据保持热分区:
sql-- TimescaleDB 超表创建(金融交易监控) CREATE TABLE transactions ( time TIMESTAMP NOT NULL, device_id TEXT, amount FLOAT ); -- 转换为按时间分区的超表 SELECT create_hypertable('transactions', 'time', chunk_time_interval => INTERVAL '1 day'); -- 旧数据自动压缩(最佳实践) ALTER TABLE transactions SET (timescaledb.compress, timescaledb.compress_orderby = 'time'); SELECT add_compression_policy('transactions', INTERVAL '30 days'); -- 30天前数据压缩
最佳实践:
- 物联网场景优先选择 TDengine,设备标签静态且查询多按设备维度聚合时,子表设计可提升写入性能 3 - 5 倍。
- 需与业务数据(如用户信息)关联分析时,TimescaleDB 的 PostgreSQL 兼容性更具优势,支持 JOIN、事务等传统 SQL 特性。
索引策略:从查询模式到性能突围
核心问题:时序数据查询多为"时间范围 + 标签筛选"(如"查询 BuildingA 过去 24 小时的温度异常"),传统 B - Tree 索引在高基数标签(如百万级设备 ID)下效率低下。
解决方案创新:
-
GreptimeDB 倒排索引:高基数标签的查询加速器
2024 年引入倒排索引 针对标签值建立映射,将"标签值 → 时间序列"的查询复杂度从 O(n) 降至 O(log n)。实测显示,在包含 100 万设备标签的数据集上,筛选特定区域设备的查询性能提升 5 - 10 倍,尤其适用于地理分布式监控场景。
-
复合索引与部分索引的精准应用
TimescaleDB 与 PostgreSQL 生态支持时间 + 标签复合索引,结合部分索引减少冗余:
sql-- 复合索引(近期数据高频查询) CREATE INDEX idx_recent_device ON transactions (device_id, time DESC) WHERE time > NOW() - INTERVAL '7 days'; -- 仅索引近7天数据 -- 部分索引(特定标签维度优化) CREATE INDEX idx_critical_devices ON transactions (time) WHERE device_id IN ('server-001', 'server-002'); -- 核心设备单独索引
最佳实践:
- 写入密集型场景(如每秒 10 万 + 点)优先依赖时序数据库原生的时间分区,避免过度建索引拖慢写入。
- 高基数标签(如设备 ID、用户 ID)优先使用倒排索引或哈希索引,低基数标签(如区域、类型)可采用 B - Tree 索引。
压缩算法:数据类型驱动的存储优化
核心问题:时序数据中浮点型(如温度、电压)、整型(如计数器)、字符串(如状态标签)的压缩特性差异显著,单一算法难以兼顾压缩率与解压速度。
解决方案匹配:
-
浮点型数据:Delta + 简单 8B 编码
TDengine 针对连续采样的浮点数据(如传感器读数),采用Delta 编码 (存储差值)+ 简单 8B 编码 (压缩重复模式),压缩率可达 10:1 - 20:1,且解压速度快,适合实时查询场景。
-
整型数据:RLE + 字典编码
InfluxDB 3.0 对计数器类整型数据(如请求次数)使用游程编码(RLE) 压缩连续重复值,结合字典编码映射高频标签值,压缩率可达 20:1 以上,且支持列式存储提升扫描效率。
-
字符串数据:LZ4 通用压缩
对于低基数字符串标签(如"正常/异常"状态),TimescaleDB 采用 LZ4 压缩,平衡压缩率与 CPU 开销,避免过度压缩导致查询延迟。
最佳实践:
- 通过数据生命周期管理自动匹配压缩策略:TDengine 可设置数据库级保留策略
CREATE DATABASE db KEEP 365;,旧数据自动应用更高压缩等级。 - 混合数据类型表建议按数据类型拆分存储(如单独存储字符串标签表),避免单一压缩算法互相干扰。
设计流程与工具链集成
结合上述实践,时序数据库设计可遵循以下流程(参考"时序数据库数据模型设计流程图"):
- 标签选择:筛选高频查询的维度(如设备 ID、区域)作为标签,避免将低基数或写入时才确定的属性设为标签。
- 分区键设计:时间分区为主(如按天/小时),设备分区为辅(如 TDengine 子表、TimescaleDB 空间分区)。
- 压缩算法匹配:浮点型用 Delta 编码,整型用 RLE,字符串用 LZ4,结合数据保留策略动态调整。
工具链集成方面,2024 年主流方案包括:
- 数据采集:InfluxDB Telegraf(5000 + 预构建连接器)、Prometheus 指标库(覆盖 Java / Python / Go 等语言)。
- 可视化:Grafana 原生支持 TDengine / TimescaleDB / InfluxDB,通过模板快速构建设备监控面板。
- 高可用:RingCentral 案例中,采用双 Kapacitor 实例 + 告警复制机制,支持单环境 50k + 触发器,避免单点故障。
实践 checklist
✅ 数据模型:设备测点频率 > 3 种时,优先 TDengine 多超级表设计
✅ 索引策略:百万级设备标签场景启用倒排索引,查询延迟降低 5 倍以上
✅ 压缩配置:浮点型数据压缩率目标设为 15:1,通过 EXPLAIN ANALYZE 验证性能
✅ 工具集成:用 Telegraf + InfluxDB 3.0 构建边缘 - 云端一体化采集 pipeline
通过以上框架,可在保证高写入性能(每秒数十万点)的同时,兼顾复杂查询灵活性与存储成本优化,适配物联网、工业监控、金融交易等多场景需求。
未来趋势
技术突破:AI 融合、云原生架构与边缘协同的创新演进
时序数据库的技术突破正沿着智能化、弹性化、分布式 三大方向深度演进。在 AI 融合领域,Timer 3.0 提出的二维注意力机制 成为解决时序数据非线性预测问题的关键,该机制通过时空双维度特征捕捉,有效提升工业设备故障预警、用户行为预测等场景的准确率[36](https://www.influxdata.com/resources/enabling-predictive-analytics-with-influxDB/)。与此同时,InfluxDB、TDengine 等数据库通过集成机器学习引擎(如 InfluxDB 的 AI 异常检测 pipeline、TDengine 的 TDgpt 智能体),实现实时高级统计分析与模型推理,推动时序数据从"记录"向"预测"升级[25](https://www.taosdata.com)[37](https://www.influxdata.com/event/meet-influxdb-at-hannover-messe-2025/)。
云原生架构的革新则显著降低了时序数据管理成本。传统集中式架构因存储与计算耦合,面临扩展受限、资源利用率低等问题;而 InfluxDB 3.0 采用对象存储与计算解耦方案 ,结合 Apache Parquet 列存格式,使存储成本降低 70% 以上,同时查询性能提升 100 倍[2](https://juejin.cn/post/7467164101136990227)[7](https://www.influxdata.com/products/influxdb-overview/)。Prometheus 3.0 进一步优化数据传输机制,其 RemoteWrite 2.0 技术将网络消息量减少 60%、内存需求降低 90%,并支持 OpenTelemetry 的 OTLP 协议,强化了与开源可观测性生态的兼容性[38](https://m.sohu.com/a/846257585_122004016/)。
边缘计算与云端协同成为处理物联网海量时序数据的核心模式。"边缘采集-云端训练-模型下沉"闭环 通过在边缘网关部署轻量级 TSDB(如 TDengine Edge)实时处理传感器数据,仅将关键特征同步至云端训练模型,再将优化后的模型下沉至边缘节点,实现本地毫秒级响应与全局智能优化的平衡[2](https://juejin.cn/post/7467164101136990227)[39](https://blog.csdn.net/2502_92631100/article/details/150212119)。
场景落地:从工业监控到智能预测的全领域渗透
技术创新已在多行业形成规模化落地。在 工业物联网领域 ,InfluxDB 与机器学习工具链集成,帮助制造企业通过设备振动、温度等时序数据预测潜在故障,使生产线停机时间减少 30%[36](https://www.influxdata.com/resources/enabling-predictive-analytics-with-influxDB/)。AWS Timestream 则聚焦能源行业,通过实时分析风电设备的转速、电压数据,优化发电效率达 15%[6](https://m.book118.com/html/2025/0226/7123133116010041.shtm)。
金融与 IT 运维场景中,Prometheus 与 Kubernetes 的深度集成成为云原生监控标配,其"原生直方图"功能可精准捕捉服务响应时间分布,结合 AlertManager 实现异常告警自动化[40](https://prometheus.io/docs/prometheus/3.0/feature_flags/)。阿里云 TSDB 则通过"时序数据 + 向量数据库"融合架构,支持金融交易异常检测,将欺诈识别延迟压缩至毫秒级[25](https://www.taosdata.com)[30](https://cerebralvalley.ai/blog/timescale-is-making-postgresql-better-for-ai-1tiUqSzGsSn76ORZVfMwOk)。
企业级实践呈现**"开源 + 商业支持"双轨模式**:中小企业倾向于 TimescaleDB、VictoriaMetrics 等开源方案,利用其低成本与高灵活性构建监控系统;大型企业如 Oracle、Microsoft 则通过自治数据库和智能分析功能,巩固私有云生态,平衡性能与生态锁定风险[41](https://www.rockdata.net/zh-cn/posts/db-engines-ranking-2505/)[42](https://wenku.csdn.net/doc/5tphdtwi58)。
挑战展望:生态博弈与技术融合的未来命题
时序数据库的发展仍面临多重挑战。开源与闭源的博弈持续深化 :当前开源数据库市场份额达 39.5%,MySQL 企业版收入年增 18%,闭源厂商通过"开源社区版 + 商业高级功能"模式重构规则,迫使企业在成本与技术支持间艰难抉择[41](https://www.rockdata.net/zh-cn/posts/db-engines-ranking-2505/)。高基数场景优化成为技术瓶颈,尽管 InfluxDB 3.0 宣称支持"无限基数",但千万级活动时序序列仍需稀疏索引、标签前缀压缩等技术突破[2](https://juejin.cn/post/7467164101136990227)。
未来 5-10 年,量子加密与区块链融合 将重塑数据安全边界。量子加密集成可解决边缘节点数据传输的隐私泄露风险,而区块链账本技术则为时序数据提供不可篡改的溯源能力,适用于电力交易、供应链监控等场景[39](https://blog.csdn.net/2502_92631100/article/details/150212119)[43](https://cloud.tencent.com/developer/article/2560282?policyId=1004)。此外,时序大模型的"一库一模型"架构有望突破传统"单模型对应单任务"局限,通过海量数据训练获得通用时序理解能力,成为工业智能化转型的核心支撑[44](https://blog.csdn.net/qq_35760825/article/details/145437780)。
关键技术节点前瞻
- 2026-2027 年:量子加密集成进入商用验证阶段,边缘时序数据库实现端到端加密
- 2028-2030 年:区块链账本与时序数据融合技术成熟,金融、能源等行业规模化应用
- 典型实践:AWS Timestream 计划 2026 年推出量子加密预览版,阿里云 TSDB 已启动区块链溯源试点[6](https://m.book118.com/html/2025/0226/7123133116010041.shtm)[25](https://www.taosdata.com)
随着全球时序数据年生成量突破 100 ZB,数据库技术将向"实时化、智能化、边缘化"加速演进,而生态协同与标准化(如 FDAP 栈、OTLP 协议)将成为竞争的关键制高点[43](https://cloud.tencent.com/developer/article/2560282?policyId=1004)[45](https://www.influxdata.com/use-cases/monitoring/)。
概念解析部分配图
应用场景部分配图
技术选型部分配图
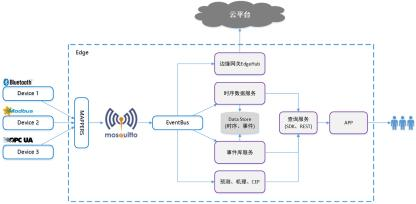
实践指南部分配图
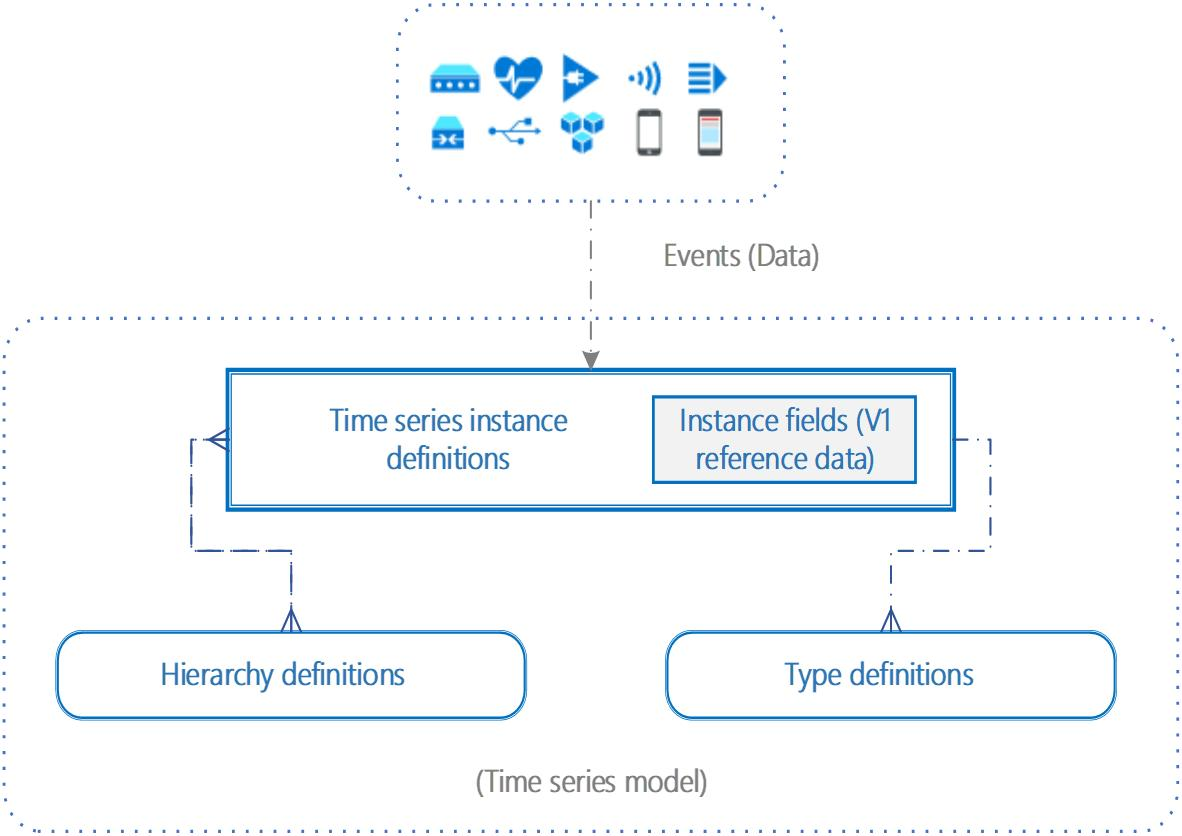
未来趋势部分配图