explain analyze和直接执行SQL时间相差10倍?

脑子转了半天不知从何入手,同事们说vacuum analyze 、重启一下看看、断开重连看看、换个工具看看。
我首先对表进行vacuum analyze,发现这个情况竟然还存在。
其次我使用psql 通过远程链接的方式进去,执行时间并不长。也只是19秒,这里explain (analyze,buffers) 也是19秒是正常的。通过show all检查了psql 和dbeaver的参数情况,也没有什么区别。
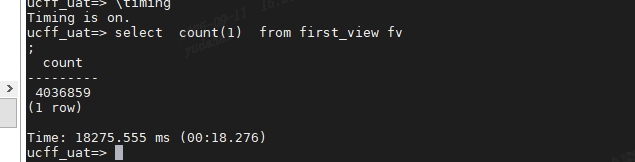
这里就奇怪了。问了一下同事,说是有可能两次SQL走的执行计划不同。
此时我就纳闷dbeaver和psql会影响执行计划?explain analyze 和直接跑SQL还能走不同的执行计划?
先上auto_explain看看
sql
LOAD 'auto_explain';
## 变更postgresql.conf的以下参数配置。
session_preload_libraries = 'auto_explain';
auto_explain.log_analyze = on;
auto_explain.log_buffers = on;
auto_explain.log_min_duration = 15000;操作完以上配置,再把SQL执行一遍,毫无意外explain (analyze,buffers) 和直接跑SQL 依然有较大差距(在dbeaver客户端依然是稳定复现),且仔细一看其真实的扫描行数两者也有区别。
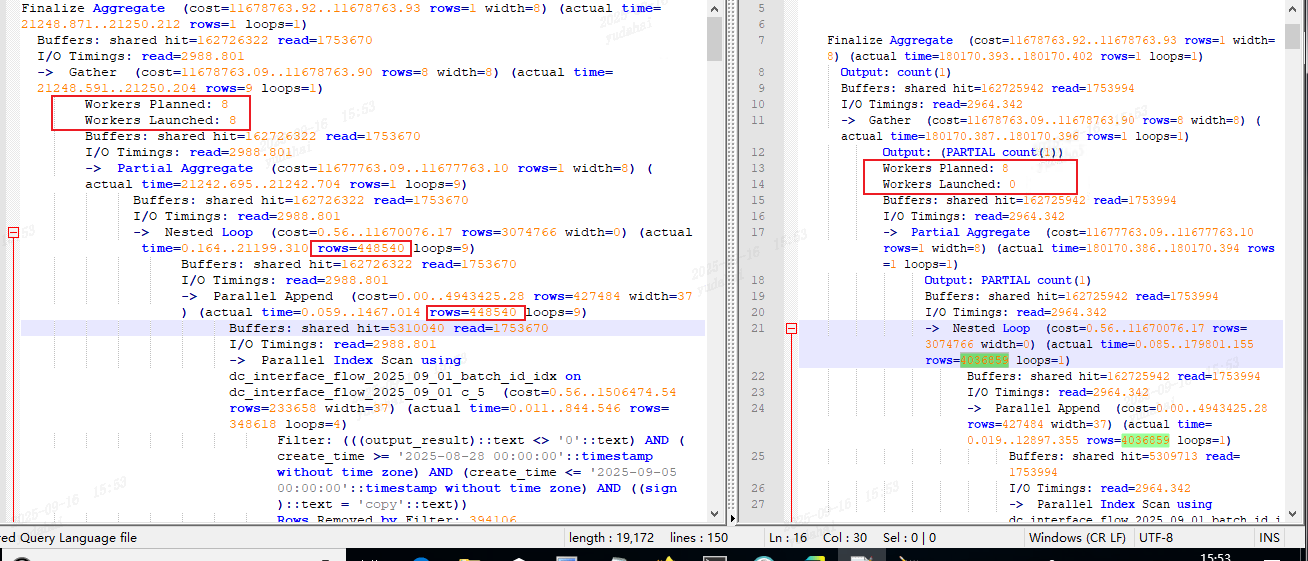
执行计划使用的Nested Loop,以上驱动表的统计信息有所区别。
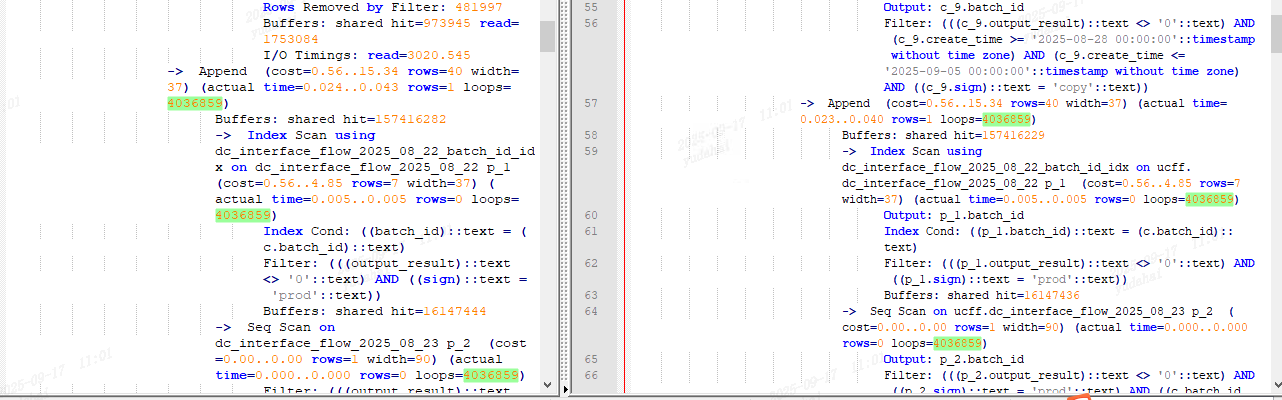
德哥:"并行的我印象中是展示的某个worker的统计信息不知道现在代码改了没"
对比执行计划:
·auto_explain获取到直接跑SQL的执行计划其Workers Loaunched 0。
·而使用explain anlyze 的执行计划其Workers Loaunched 8。是用到了8个并行工作组。
当Workers Loaunched 0 且Workers Planned 8,其parallel 都是由单一的work节点进行scan。这两种情况下其leader统计出来的统计信息也有区别。
初步咋一看 ,在Workers Loaunched 0 的情况下其驱动表的(sum(rows*loop))真实扫描行数的总和正好等于append节点的真实扫描行数
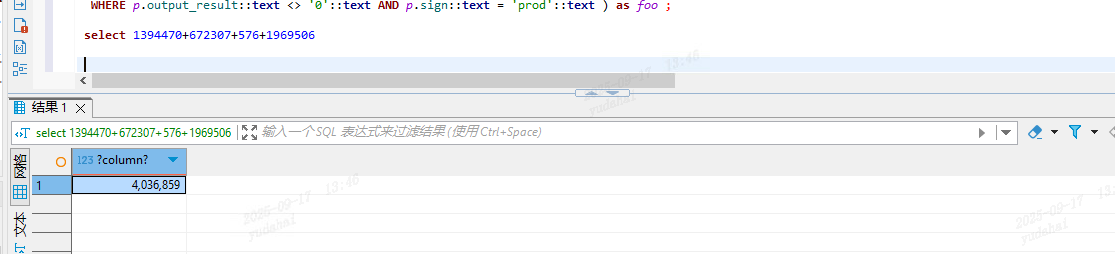
在Workers Loaunched 8 的情况下其驱动表的统计信息就有所不同,其真实扫描行数
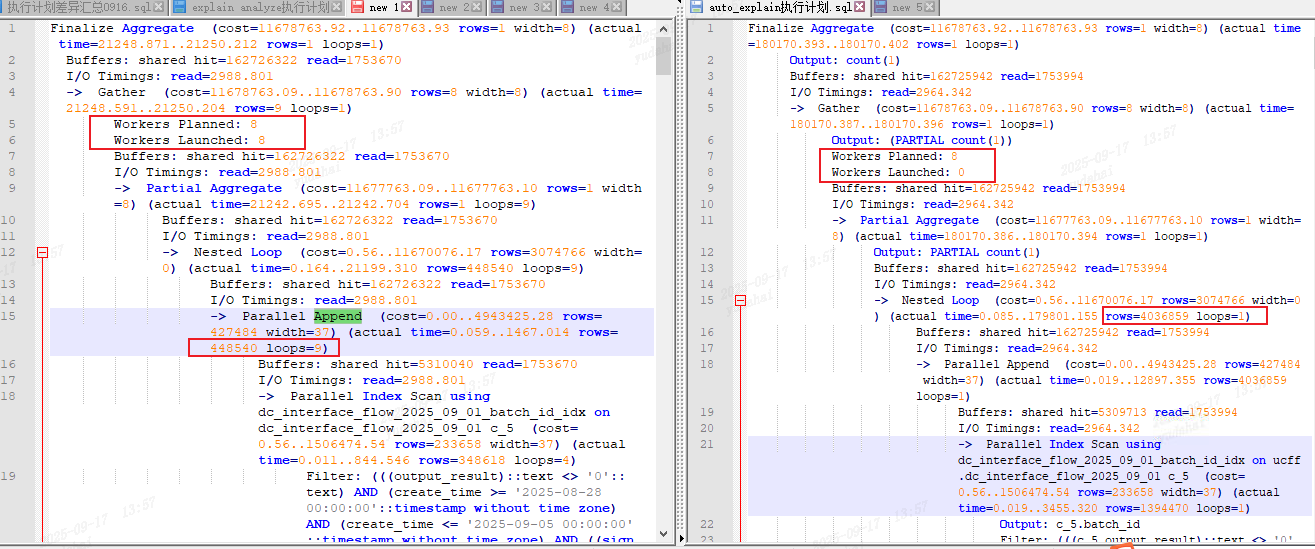
448540*9=4036860 正好比真实扫描行数多1。这里parallel是8+1(leader节点),
由于真实行数为4036859/9(8 works + leader)≈ 448539.8888
所以该append节点的真实扫描行数并非是精确的。可能由于边界重叠或任务重复领取或者非平均分配导致。
具体该段的算法,待后续看完这相关的源码的上下文,在下一篇文章中再做解释。
为什么explain analyze可以启动并行工作组,直接执行SQL就无法启动并行工作组?
执行的时间差距较大,还是因为并行工作组的未能启用导致。那为什么直接跑并行工作组就起不来呢?
首先,并行的工作组是向parallel worker pool进行申请,plan->num_workers; 。如果work pool中无法满足所需数量,此时便不会为其分配并行工作组。由于当前环境无法进行debug,这个在本地环境复现了我再在后续文章中更新。
这里排除了参数的影响
/**检查并行相关参数**/
select current_setting('enable_parallel_append') as enable_parallel_append
,current_setting('enable_parallel_hash') as enable_parallel_hash
--,current_setting('force_parallel_mode') as force_parallel_mode --16以后取消该参数
,current_setting('parallel_leader_participation') as parallel_leader_participation
,current_setting('max_parallel_workers') as max_parallel_workers
,current_setting('max_parallel_workers_per_gather') as max_parallel_workers_per_gather
,current_setting('max_worker_processes') as max_worker_processes;max_parallel_workers
👉 实例级别最多能开多少个并行 worker。
max_worker_processes
👉 后台总 worker 数量上限,低于 max_parallel_workers 时会限制并行。
max_parallel_workers_per_gather
👉 单个 Gather/Gather Merge 节点最多能用多少个 worker。