本篇文章Navigating Key Decisions in Machine Learning (ML) System Deployment为机器学习系统的部署提供了实用的决策指导。技术亮点在于详细阐述了推理类型、服务平台和可扩展性策略,强调了如何根据不同需求选择合适的架构。适用场景包括实时预测和批量推理,适合需要高可用性和低延迟的应用,如推荐系统和用户画像
文章目录
- [1 引言](#1 引言)
- [2 什么是机器学习系统](#2 什么是机器学习系统)
- [3 ML模型部署的三大要素](#3 ML模型部署的三大要素)
-
- [3.1 推理类型](#3.1 推理类型)
-
- [3.1.1 批量推理](#3.1.1 批量推理)
- [3.1.2 实时推理](#3.1.2 实时推理)
-
- [3.1.2.1 流式实时推理](#3.1.2.1 流式实时推理)
- [3.1.2.2 请求-响应实时推理](#3.1.2.2 请求-响应实时推理)
- [4 ML系统部署平台介绍](#4 ML系统部署平台介绍)
-
- [4.1 容器编排](#4.1 容器编排)
- [4.2 FaaS --- 无服务器函数](#4.2 FaaS — 无服务器函数)
- [4.3 容器化无服务器](#4.3 容器化无服务器)
- [5 可伸缩性与可靠性](#5 可伸缩性与可靠性)
-
- [5.1 横向扩展](#5.1 横向扩展)
- [5.2 负载均衡器作为促成因素](#5.2 负载均衡器作为促成因素)
- [5.3 故障转移策略](#5.3 故障转移策略)
- [6 实践案例](#6 实践案例)
-
- [6.1 推理类型](#6.1 推理类型)
- [6.2 服务平台](#6.2 服务平台)
- [6.3 扩展策略](#6.3 扩展策略)
- [7 结论](#7 结论)

1 引言
机器学习(ML)系统是一个全面的基础设施,旨在开发、部署和维护生产环境中的ML模型。
该系统对于确保模型可靠、可伸缩和高性能至关重要,可有效防止模型退化和基础设施瓶颈等问题。
在本文中,我将详细介绍关键的部署决策,包括推理类型的选择、服务平台以及可伸缩性策略。
2 什么是机器学习系统
机器学习(ML)系统指的是架构和构建整个基础设施的全面过程,用于在生产环境中开发、部署、监控和维护机器学习模型。
下图展示了设计ML系统的范围:

*图:ML系统设计流程
该过程涵盖了模型的端到端工作流,确保整个系统实现核心原则:
- 可靠性:即使在某些故障下也能正确且持续地运行。
- 可伸缩性:处理不断增长的数据量、用户和请求。
- 性能:满足特定的延迟(速度)要求和准确性基准。
- 安全性:保护敏感数据和模型。
- 可维护性:易于更新、调试和随时间演进。
- 成本效益:优化资源使用。
这些原则对于系统持续提供最佳预测至关重要,同时防止由以下因素导致的次优性能:
- 概念漂移:输入特征与目标变量之间的关系开始发生变化。
- 数据漂移:用于训练模型的输入特征属性开始发生变化。
- 基础设施瓶颈:系统无法处理不断增长的请求,导致其性能下降和用户体验不佳。
- 缺乏警报系统:问题未被发现,直到在生产中造成重大损害。
在下一节中,我将详细介绍部署阶段的实际决策点。
3 ML模型部署的三大要素
在部署ML模型时,三个关键决策对于满足核心系统原则至关重要:
- 推理类型 :模型将如何提供预测?
- 服务平台 :容器编排还是无服务器函数更适合?
- 可伸缩性与可靠性 :系统能否处理预期负载和潜在故障?
3.1 推理类型
推理是指训练好的模型对新的、未见过的数据提供预测的过程。
推理类型分为批量推理 和实时推理。
选择哪种类型取决于模型将提供的预测类型。
3.1.1 批量推理
批量推理以每日或每周等预定间隔处理并存储大量数据的预测。
客户端随后查询此预测存储以检索结果。
下图展示了批量推理架构的工作原理:
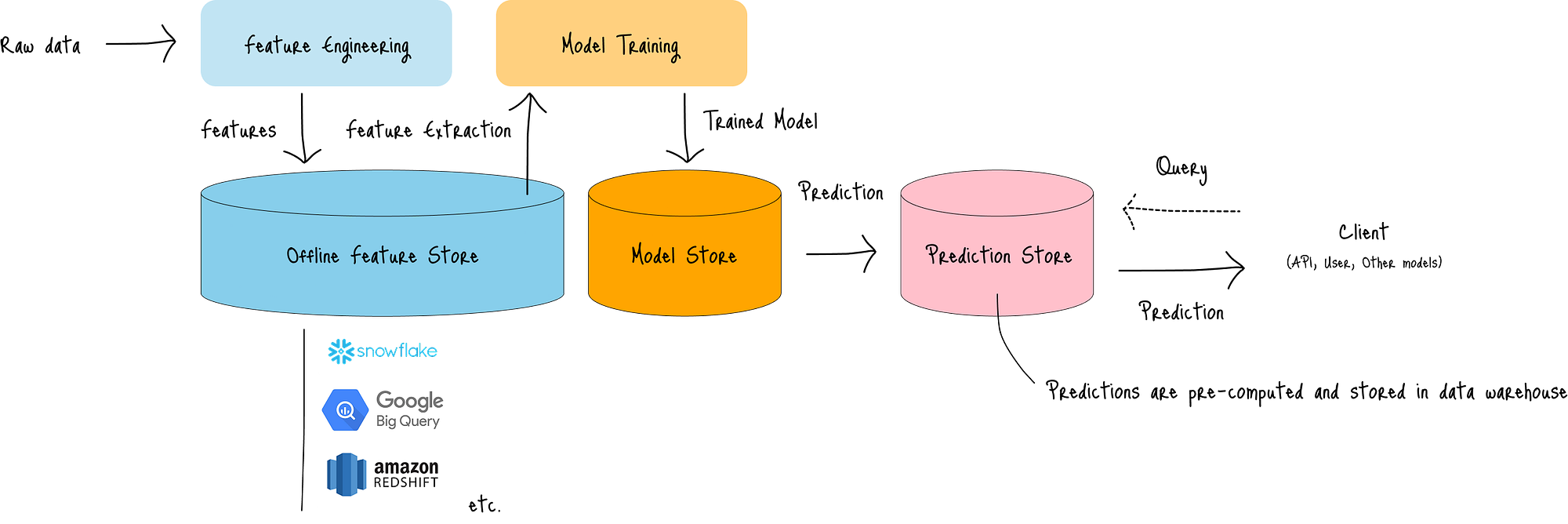
*图:批量推理架构
每个批次,系统都会执行以下步骤:
- 从离线特征存储中拉取预处理的特征(蓝色),
- 将训练好的模型存储在模型存储中(橙色),以及
- 生成并将预测存储在预测存储中(粉色)。
这种架构最适合以下情况:
- 不需要即时预测,例如预测每日客户流失或计算每周销售预测以进行库存管理。
- 追求成本效益,通过利用更便宜、不那么即时的计算资源。
其缺点包括:
- 数据与预测之间存在时间间隔:需要等待下一个批次才能将数据变化反映到预测中。
主要服务提供商:
- 云批量处理服务(AWS Batch、Google Cloud Dataflow、Azure Batch),
- 数据仓库解决方案(Snowflake、Databricks)。
3.1.2 实时推理
另一方面,实时推理通过实时将输入数据馈送到模型中,在几毫秒内提供预测。
根据预测的提供方式,有两种类型:
- 流式实时推理:持续提供预测,无需显式客户端请求。
- 请求-响应(非流式)实时推理:根据客户端离散的、单独的请求提供预测。
3.1.2.1 流式实时推理
流式实时推理主动地对新的、连续的数据流生成预测,而无需客户端的特定请求。
下图展示了其架构:
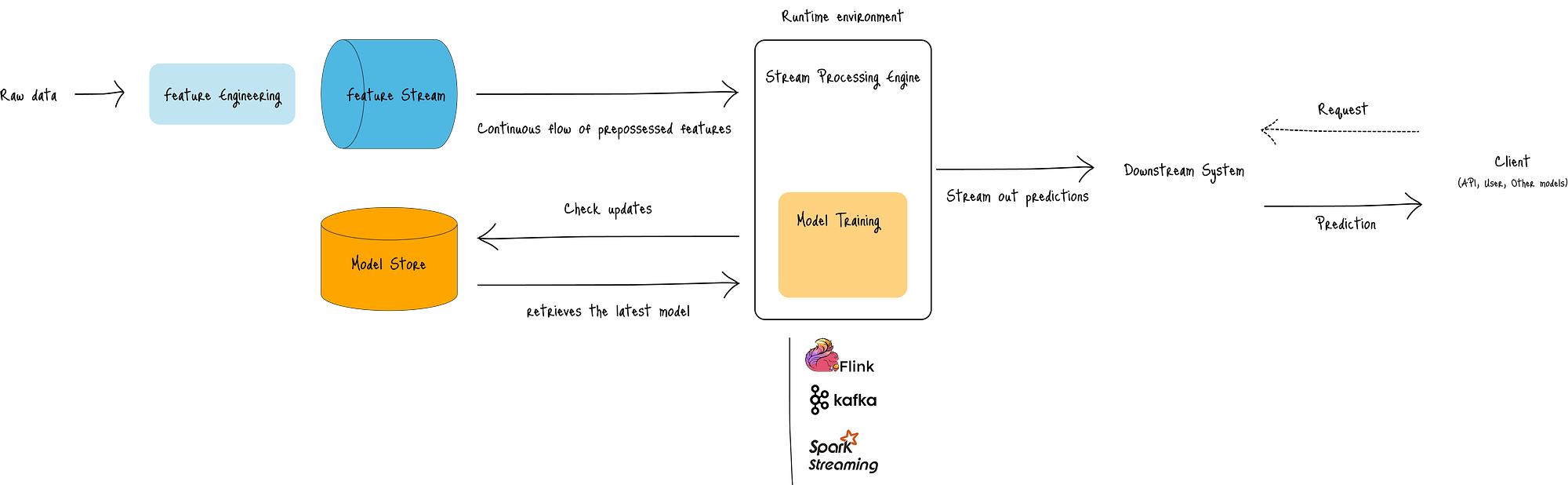
图:流式实时推理架构
在该架构中,数据作为连续的、无界流(特征流,蓝色)流动。
然后,流处理引擎(白色框)为模型创建运行时环境,并持续执行以下操作:
- 从特征流接收数据,
- 从模型存储中检索最新模型,以及
- 将预测流式传输到下游系统,如消息队列、API和其他应用程序。
流式实时推理最适合以下情况:
- 应用程序需要对实时事件、持续演变的数据和预测做出反应(例如,传感器数据、点击流、金融交易),以及
- 对传入数据有低延迟和高吞吐量要求。
其缺点包括:
- 当流涉及多个处理步骤时,增加端到端延迟和调试复杂性,以及
- 由于数据量意外激增而导致高成本的风险。
主要服务提供商:
- 流处理框架:Apache Kafka、Apache Flink、Apache Spark Streaming、Amazon Kinesis、Google Cloud Pub/Sub、Azure Event Hubs。
- 专用服务框架:TensorFlow Serving、TorchServe、Triton Inference Server。
- 基于云的托管服务:AWS SageMaker Endpoints、Google Cloud Vertex AI Endpoints、Azure Machine Learning Endpoints。
3.1.2.2 请求-响应实时推理
请求-响应实时推理根据客户端的离散请求进行预测,并立即返回响应。
下图展示了其架构:
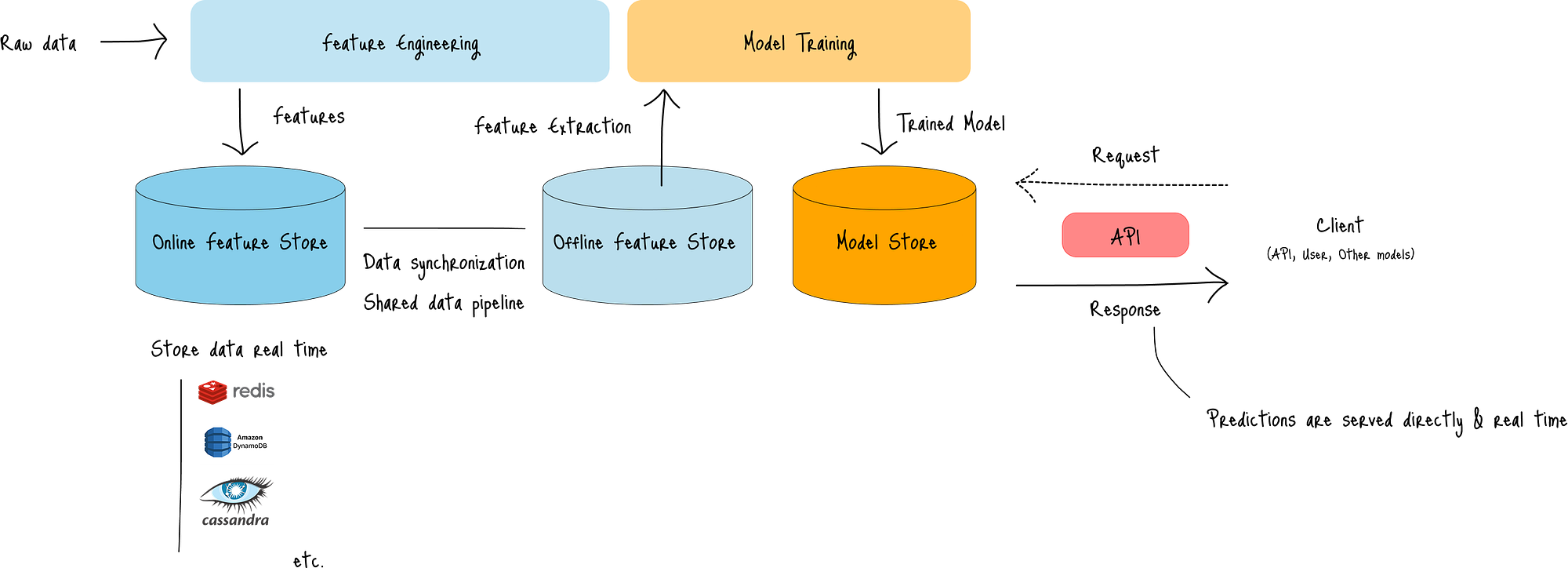
图:请求-响应实时推理架构
与流式实时推理类似,输入数据持续流入系统,其中:
- 将预处理的特征存储在在线特征存储中,
- 将特征与离线特征存储同步,
- 从离线特征存储中检索特征,以及
- 训练并将模型存储在模型存储中。
当客户端通过API端点发送请求时,模型会在几毫秒内提供预测。
这种架构最适合:
- 交互式应用程序,其中客户端在需要时直接从模型接收预测。
主要服务提供商:
- ML模型服务API:TensorFlow Serving、TorchServe、BentoML。
- 基于云的托管推理端点:AWS SageMaker Endpoints、Google Cloud Vertex AI Endpoints。
4 ML系统部署平台介绍
ML系统中的服务平台是指用于在生产环境中部署、管理和运行训练好的模型的基础设施和工具。
主要架构包括:
- 容器编排,
- 无服务器函数(Function-as-a-Service (FaaS)),以及
- 容器化无服务器。
选择取决于控制、成本和流量模式。
4.1 容器编排
容器编排是一种架构,其中多个应用程序被容器化并进行编排,以作为整个系统进行管理、协调和部署。
此图显示了编排器管理包含Docker容器的多个应用程序节点:
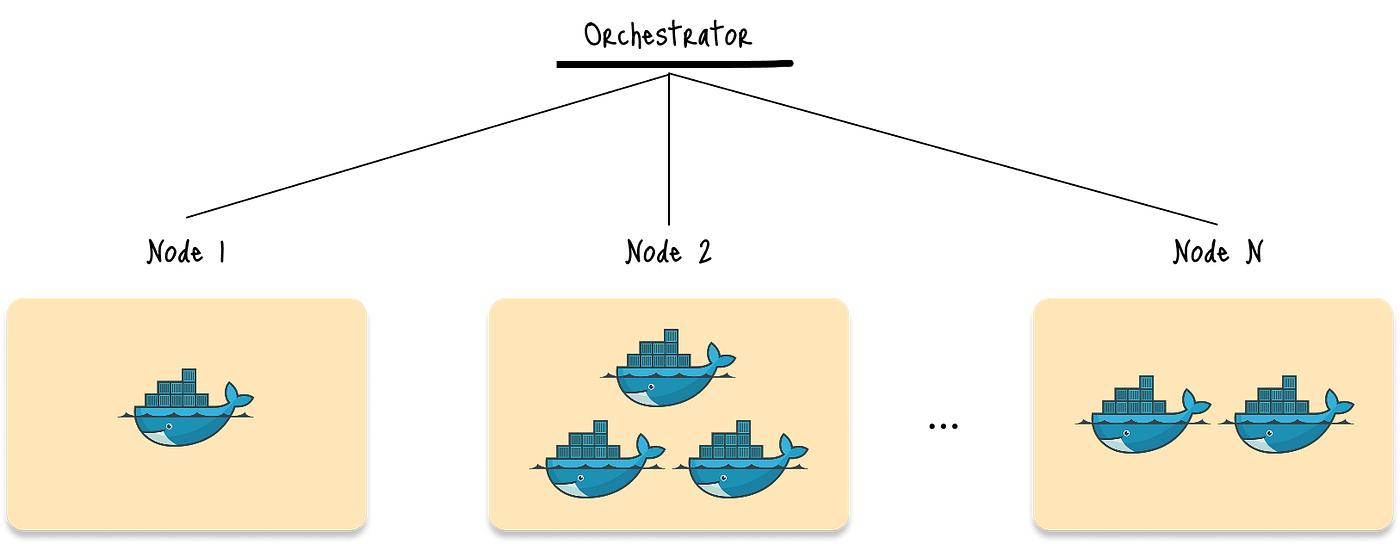
图:简化的容器编排架构
在这种架构中,编排器处理以下任务:
- 在主机上调度容器,
- 管理资源分配,
- 促进容器间通信,
- 推出更新,以及
- 从故障中自动恢复。
这种架构最适合以下情况:
- 处理复杂的微服务架构,其中系统需要扩展许多相互连接的微服务,同时满足一致的基线容量。
- 运行有状态应用程序,如容器内的数据库、消息队列。
- 最大化跨不同云提供商或云与本地之间的可移植性。
其缺点包括:
- 设置和管理编排平台的操作复杂性,以及
- 许多节点和容器(包括空闲容器)之间的成本和资源管理。
主要参与者:
- Kubernetes (K8s):容器编排的事实标准,所有主要云提供商都提供托管服务。
- Amazon ECS (Elastic Container Service):AWS的专有容器编排服务。
- Docker Swarm:Docker的原生编排解决方案,比Kubernetes设置更简单,但对于大规模部署而言功能较少。
4.2 FaaS --- 无服务器函数
无服务器函数 (FaaS) 是一组代码,响应事件(如HTTP请求、文件上传或队列中的消息)而运行。
FaaS的本质是:
- 事件驱动:函数由事件触发。
- 无状态:函数的每次执行都独立于其他执行。执行之间不存储任何数据。
- 短暂性:函数生命周期短,仅在执行期间存在。
在FaaS中,云提供商动态管理基础设施,并根据实际执行时间收费。
这种架构最适合:
- 追求资源和成本效益,适用于间歇性使用。
- 不可预测的流量,其中云提供商处理的自动扩展确保了高效的资源利用。
其缺点包括:
- 冷启动:当函数最近未被调用时,运行时环境初始化会导致延迟。
- 包大小限制:函数对内存或执行持续时间有严格限制。
- 无状态性:在整个系统中维护状态需要外部服务(数据库、缓存),这增加了架构的复杂性。
4.3 容器化无服务器
容器化无服务器在无服务器平台上运行容器而不是代码,提供了容器化和FaaS的混合优势。
这种架构最适合:
- 可以利用容器化优势的应用程序,例如使用特定版本的Python或拥有大量依赖项。
- 将现有容器化应用程序转移到无服务器,而无需进行大量重构。
其缺点与FaaS类似,但由于容器大小较大或容器中的操作复杂,往往会使冷启动时间更长。
主要的FaaS/容器化无服务器提供商包括:
- 主要云提供商的FaaS,如AWS Lambda、Azure Functions、Google Cloud Functions。
- Cloudflare Workers:一个无服务器平台,在Cloudflare的全球网络边缘运行JavaScript、WASM和其他代码。
5 可伸缩性与可靠性
一旦我们选择了部署方法,设计系统以处理不同的工作负载并在系统受损时仍能保持运行至关重要。
在本节中,我将介绍ML系统中水平扩展 与负载均衡 和故障转移策略的核心概念。
5.1 横向扩展
横向扩展 指的是将工作负载分布到多个实例(机器或容器)上,而不是增加单个实例的资源(纵向扩展)。
下图展示了横向扩展和纵向扩展之间的主要区别:
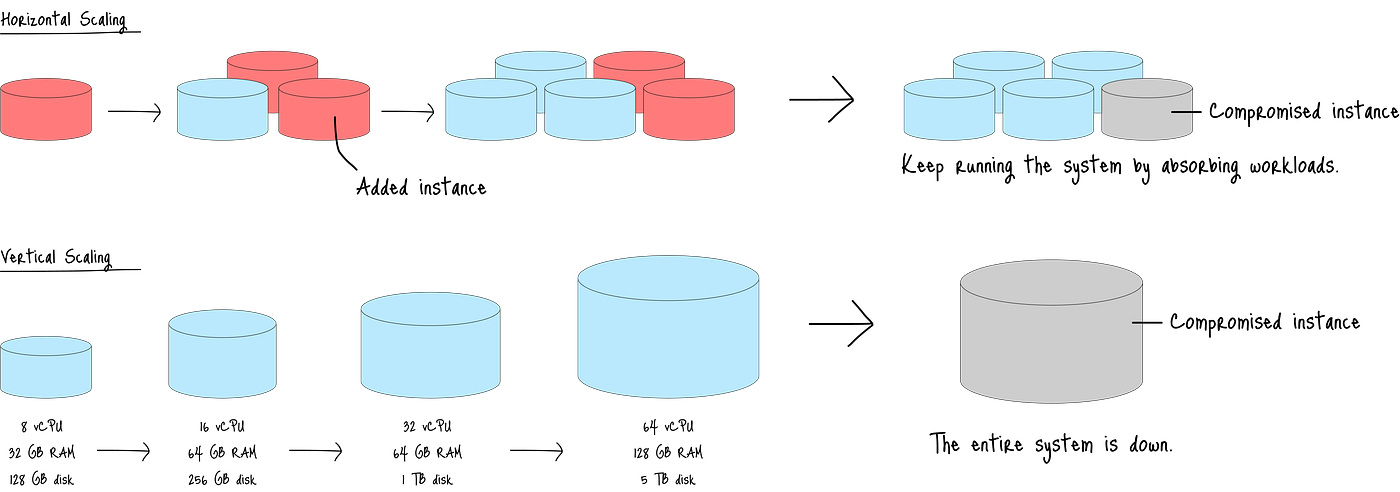
图:横向扩展与纵向扩展的比较
横向扩展通过增加更多实例来增加系统容量。
因此,当一个实例发生故障时,其余实例可以吸收其工作负载,确保服务持续。
另一方面,纵向扩展依赖于单个更大的实例,如果该实例受损,则存在系统完全崩溃的风险。
尽管所有推理都必须如此,但高吞吐量、低延迟的机器学习推理尤其偏爱这种方法,因为它提供了弹性(随需求增长和收缩)并通过接管受损实例的工作负载来确保高可用性。
5.2 负载均衡器作为促成因素
当横向扩展向系统添加更多实例时,需要负载均衡器来在实例之间分配传入请求。
下图显示了ML系统负载均衡的四种主要策略:
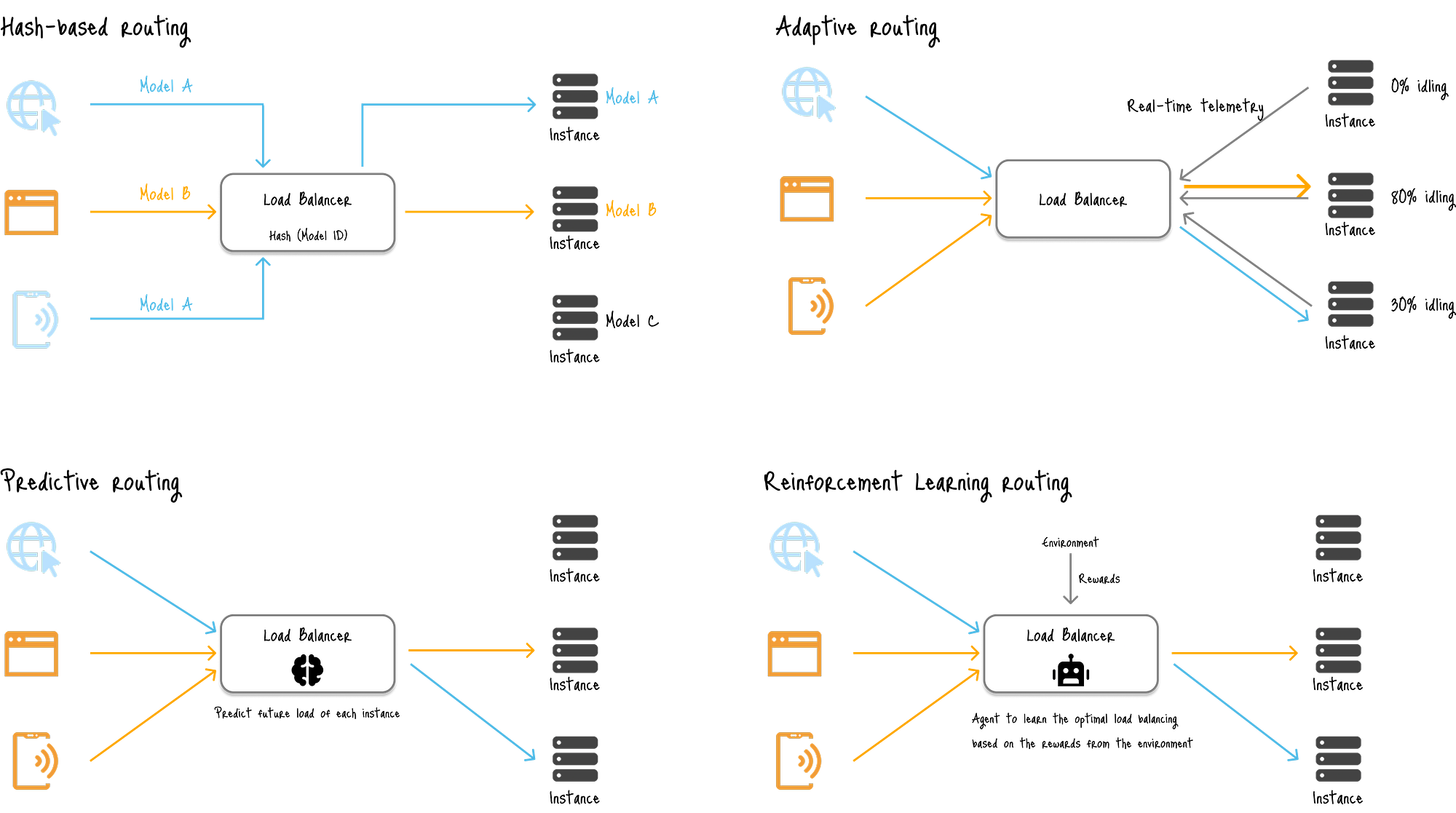
图:ML系统中负载均衡的四种主要策略
按简单程度排序:
- 基于哈希的路由(左上)使用模型ID或用户会话ID将特定模型的所有请求路由到托管该模型的实例,从而减少冷启动时间。
- 基于资源的(自适应)负载均衡(右上)使用来自每个服务器的实时遥测数据,根据当前的CPU/GPU利用率、内存使用情况或队列长度做出智能路由决策,将新请求发送到具有足够空闲资源的服务器。
- 预测性负载均衡(左下)利用RNN家族模型预测未来的流量模式,以便在预期流量激增时主动扩展服务器。
- 基于强化学习(RL)的负载均衡 (右下)通过试错学习负载均衡的最佳策略,使用RL算法,其中代理试图最大化从环境中获得的奖励。
主要服务:
- 托管云服务提供商:AWS Elastic Load Balancing (ELB)、Google Cloud Load Balancing、Azure Load Balancer。
- Nginx:一个流行的开源Web服务器,也可以作为HTTP、HTTPS、TCP和UDP流量的负载均衡器。
- HAProxy:一个免费的开源解决方案,专门设计用于TCP和基于HTTP的应用程序的可靠负载均衡和代理。
5.3 故障转移策略
在扩展系统时,ML系统必须具备故障转移策略,这一点至关重要。
冗余是指在系统中复制组件,以便健康的组件能够立即接管故障的组件。
其示例包括:
- 构建多个实例,在不同的可用区中托管相同的模型,以确保有备份。
- 构建一个主服务器和一个冷备用服务器,其中备用服务器仅在主服务器故障后手动上线。
优雅降级是指系统在组件故障时仍能保持功能,而不是完全崩溃的能力。
例如,当主模型崩溃时,系统会回退到模型的先前版本或资源密集度较低的模型,以仍然提供预测。
主要服务提供商包括:
- 托管ML服务平台(如AWS、Google Cloud Vertex AI、Azure Machine Learning)。
- 断路器(例如,Hystrix、Resilience4j)。
- API设计中的回退机制。
- 队列系统(Kafka、RabbitMQ)。
这些过程旨在优先考虑可用性而非性能,确保应用程序保持高可用性,即使其性能受到影响。
在处理低流量或非关键应用程序时,扩展/故障转移策略是不必要的。
6 实践案例
在本节中,我将以个人推荐引擎为例,演示如何在部署阶段设计ML系统。
该图展示了推荐引擎的架构:
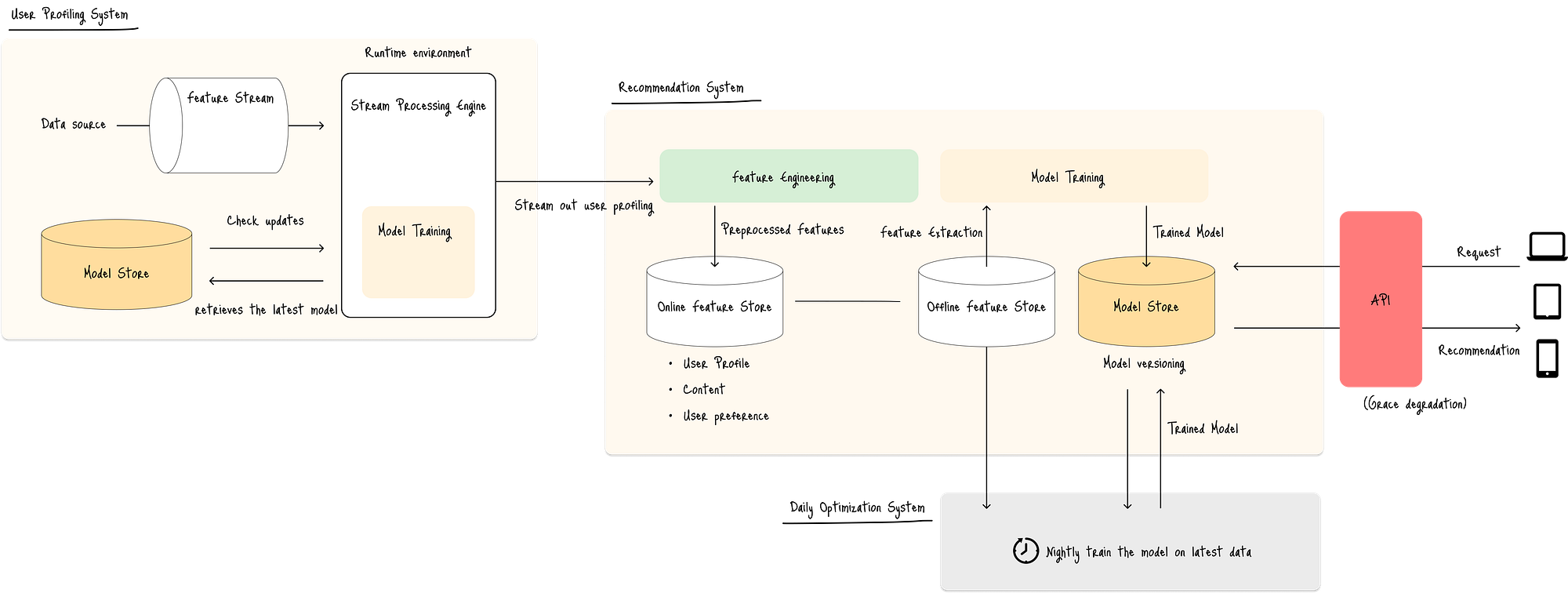
图:个人推荐引擎的ML系统架构
推荐引擎由三个主要组件组成:
- 主推荐系统(图中居中)提供个性化推荐。
支持系统:
- 用户画像系统(图中左侧)检索点击流数据并构建实时用户画像,包括浏览信息。
- 每日优化系统(图中灰色框)从用户画像系统检索聚合画像数据,并每晚重新训练模型。
6.1 推理类型
由于每个组件处理不同类型的数据和任务,该引擎使用混合推理架构来创建健壮的解决方案:
推荐系统
- 实时请求-响应推理,在用户访问网站时即时提供预测。
用户画像系统
- 流式实时推理方法,主动地用持续的点击流数据更新画像,即使在用户没有发出任何请求时也是如此。
每日优化系统
- 批量推理,具有专门用于重新训练模型的计划任务。
6.2 服务平台
每个组件将在不同的服务平台上交付:
推荐系统 --- 容器化无服务器
请求-响应推荐系统需要在用户每次访问网站时快速提供预测。
这种工作负载高度可变,活动爆发后是低流量时期。
容器化无服务器是该系统的绝佳选择,因为它提供了对运行时环境的更多控制,这对于可能需要特定库或更大内存占用的系统至关重要。
用户画像系统 --- 容器编排
用户画像系统持续处理点击流数据流。
这是一个长时间运行、有状态的工作负载,需要持续、高吞吐量的处理。
容器编排(例如,Kubernetes)是该系统的理想选择,因为它可以为需要持续运行的系统提供对资源分配、状态管理和持续操作的精细控制。
每日优化系统 --- 容器编排
该系统涉及计划任务,如模型重新训练,这是一个资源密集型的批处理作业。
容器编排是定义Kubernetes中批处理作业的绝佳选择,该作业按计划运行。
编排器将启动必要的容器,执行训练管道,然后在完成后拆除资源。
6.3 扩展策略
每个组件都有不同的需求,因此单一的扩展策略对所有组件来说都不是最优的。
推荐系统
推荐系统需要低延迟和高可用性。
这里最好的策略是基于哈希的路由 和基于资源的负载均衡的组合。
- 基于哈希的路由 :通过对用户ID进行哈希,将用户的请求一致地路由到同一服务器,确保用户的最新画像信息随时可用。这通过避免每次请求都从画像系统或数据库中重新获取数据,显著降低了延迟。
- 基于资源的负载均衡作为回退。如果哈希到的服务器过载,系统可以动态地将请求路由到另一个具有可用资源的服务器,确保即使在高负载下也能快速响应。
这种混合方法提供了缓存(低延迟)和动态路由(高可用性)的优势。
当整个系统崩溃时,系统还会回退到显示通用热门内容而不是个性化推荐。
用户画像系统
这里最好的负载均衡策略是基于资源的(自适应)负载均衡,因为处理需求会根据用户活动量而波动。
自适应策略可以根据CPU、内存和网络利用率等实时指标,将新的数据流路由到最不繁忙的服务器。
这可以防止任何单个服务器成为瓶颈,并确保数据流得到高效处理。
每日优化系统
这里最好的策略是基于资源的负载均衡 与批处理调度器相结合。
批处理作业关乎吞吐量和资源的高效利用。
系统需要尽快处理大量数据。
基于资源的负载均衡器可以将批处理作业路由到具有最多可用计算能力(例如,空闲CPU和GPU周期)的服务器,确保训练过程在最短时间内完成,而不会干扰实时推理系统。
调度器,如Kubernetes CronJobs,可以管理这些作业的运行时间。
7 结论
部署生产就绪的机器学习系统需要多学科方法,融合机器学习、软件工程和运维方面的专业知识。
在实践案例中,我们研究了一个混合架构,其中多个推理相结合以提供预测。
通过仔细考虑上述方面,我们可以为受众提供健壮、可伸缩且具有影响力的解决方案。