作者:来自 Elastic Alexander Dávila

学习 Elasticsearch 中文档分块的基础知识,比较不同的分块策略,并了解你的分块选择如何影响搜索质量和相关性。
Elasticsearch 与行业领先的 Gen AI 工具和提供商有原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量数据库构建可用于生产的应用。
为了为你的用例构建最佳搜索解决方案,现在可以开始免费的 cloud 试用,或者在本地机器上尝试 Elastic。
在设计语义搜索引擎、RAG 应用或任何使用 embeddings 的系统时,有一个决定会直接影响搜索质量:如何对数据进行分块。
分块是将大文本拆分为更小的、语义上有意义的片段,这些片段可以单独进行 embedding 并被检索。当你处理的文档长度超过 embedding 模型的上下文窗口,或者当你需要检索特定相关片段而不是整个文档时,分块就变得必要。传统文本搜索按原样索引文档,而基于向量的系统需要采用不同的方法,主要有两个原因:
-
Embedding 模型有 token 限制,限制了每次能处理的文本量。例如,ELSER 和 e5-small 的限制是 512 个 token。为了生成有意义的 embedding,我们必须拆分文本;否则,超过限制的 token 信息会丢失。
-
LLM 也有 token 限制,并且注意力范围有限;因此,只发送相关分块而不是整个文档效率更高。分块不仅能得到更好的结果,还能降低超过 token 限制的风险。
请记住,你选择的具体 embedding 模型会对分块策略产生重大影响:
-
上下文窗口更大的模型允许使用更大的分块,从而保留更多上下文,而上下文较小的模型则需要更积极的分块。
-
有些模型针对较短的片段进行了优化,而另一些则在处理段落时效果更好。
在这篇博客中,我们将讨论分块的基础知识,并探讨使用分块策略如何影响 Elasticsearch 中的语义搜索结果。
什么是分块?
分块是在创建 embeddings 并建立索引之前,通常将大型文档拆分为更小片段的过程。与其将一份 50 页的文本转换成一个单一的 embedding,分块会把它拆分成更小的逻辑单元,从而可以单独进行搜索。
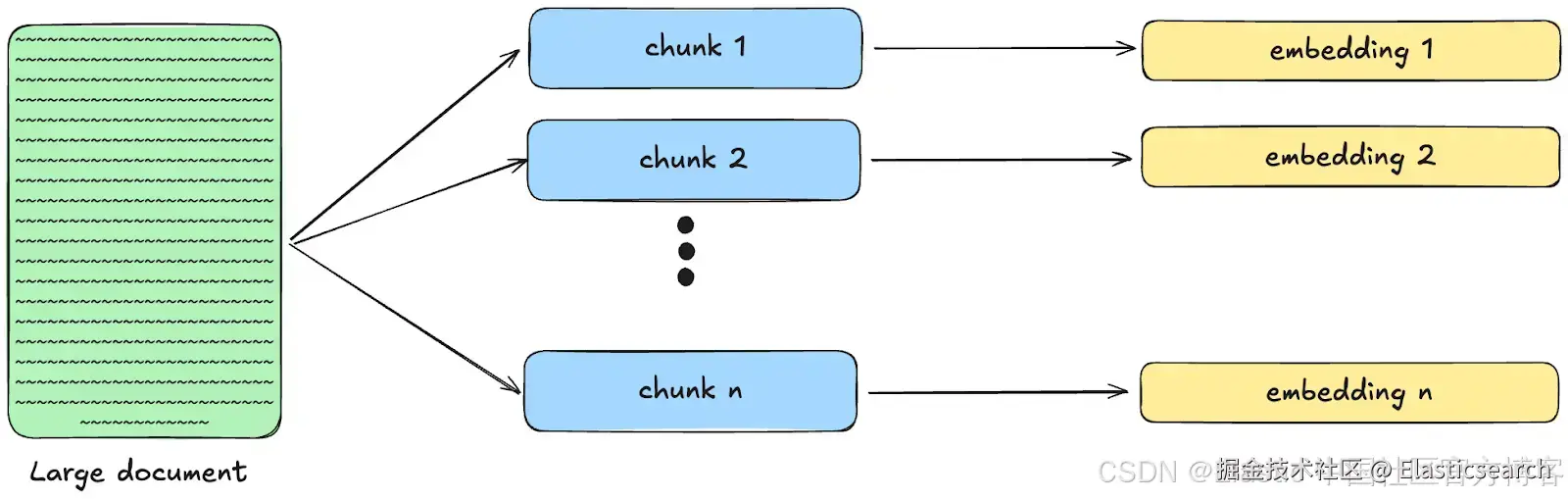
在 Elasticsearch 中,semantic_text 字段类型会使用分块将文本拆分为更小的片段,然后自动生成 embeddings。
为什么分块对搜索质量很重要?
如果在生成 embeddings 之前不进行分块,可能会遇到一些问题,例如:
-
LLM 上下文窗口和注意力限制 :LLM 的上下文 token 数量有限。如果我们为了一个小片段的相关内容而输入全部文本,就更容易触及限制。此外,即使文本在上下文窗口范围内,LLM 也会出现注意力问题,比如 "中间遗失" 现象,在大段文本中忽略重要信息。
-
Embedding 质量和数据丢失:从大文档生成的 embedding 可能过于宽泛,无法很好地捕捉单一概念,导致信息稀释。较小的分块能生成更专注的 embedding,更好地表示信息。另一方面,如果文本超过模型的 token 限制,超出的信息会直接丢失,因为在生成 embedding 时不会被考虑。
-
结果可读性:分块能生成更容易被人类阅读的结果。你无需通读整篇文档,只需检索相关的部分即可。
分块大小与搜索精度的关系
-
较小的分块:能提供更精确的匹配,但可能缺乏足够的上下文来理解信息。
-
较大的分块 :包含更多上下文,但可能涉及多个概念,导致匹配不够精确。
目标是在尽量减少信息量的同时,仍保留有用的上下文。一般来说,可以这样考虑:
-
较小的分块:
-
需要高度具体的事实性答案(如查找定义、日期或特定步骤)
-
文档包含许多独立的、自成一体的概念
-
-
较大的分块:
-
上下文对理解至关重要(如分析论点、叙事或复杂解释)
-
文档中的概念相互依赖,拆分会导致语义丢失
-
可以用自己的内容进行测试。如果结果中无关内容过多,说明分块太大;如果答案缺乏足够的上下文,说明分块太小。
分块策略
Elasticsearch 允许我们选择不同的方法来拆分文档。你可以使用这个对比表来选择最适合你用例的策略,取决于你的文档结构和所使用的模型:
| 策略 | 工作原理 | 内容类型 | 优点 | 缺点 |
|---|---|---|---|---|
| Sentence(句子) | 在句子边界拆分,保留完整句子 | 任何文本 • 保持清晰的句子结构 | • 保持清晰的句子结构和语法上下文 • 自然的阅读流 • 精度与上下文的良好平衡 | • 可能产生不均匀的分块大小 • 可能将相关概念拆分到不同句子中 |
| Word(词) | 按单个单词拆分,直到达到大小限制 | 任何文本内容 | • 分块大小一致 • token 数量可预测 | • 可能在句子中途拆分 • 可读性差 • 可能丢失语义意义 |
| Recursive(递归) | 使用可配置的分隔符(标题、换行),如果不可用则回退到句子拆分 | 具有清晰层级的结构化文档 | • 尊重文档结构 • 分隔符配置灵活 • 回退系统 | • 需要理解文档结构 • 配置更复杂 • 可能产生非常不均匀的分块 |
| None(无分块) | 不分块 ------ 处理整个文本或预定义分块 | 短文档或当你在外部控制分块时 | • 保留完整上下文 • 方法简单 | • 受模型 token 限制,可能导致信息丢失 • 可能降低搜索精度 • 对大文档性能较差 |
现在我们来看看每种策略的实际效果:
句子分块
这种策略将文本拆分为一个或多个完整句子,以在句子层面上优先保证可读性和语义连贯性。
输入:
kotlin
`Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality.`AI写代码结果数组(max_chunk_size: 50,sentence_overlap: 1):
css
`
1. [ "Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives and reduces costs.",3. "Early detection of diseases saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality." ]
`AI写代码单词分块
这种策略将文本拆分为单个单词,直到达到 max_chunk_size。这样可以保证分块大小一致,为处理和存储提供可预测性。但缺点是可能将相关上下文拆分到多个分块中。
输入:
kotlin
`Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality.`AI写代码结果数组(max_chunk_size: 25,overlap: 5):
markdown
`
1. [
2. "Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives",
4. "saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality."
5. ]
`AI写代码递归分块
这种策略根据分隔符列表(如换行符)拆分文本。它按顺序并递归地应用分隔符。如果在应用所有分隔符后分块仍然过大,则回退到句子拆分。该策略对格式化内容(如 markdown 文档)尤其有效。
输入:
bash
`
1. # Climate Change Solutions
3. ## Renewable Energy
4. Solar and wind power are becoming cost-competitive with fossil fuels. Investment in clean energy infrastructure creates jobs.
6. ## Carbon Capture
7. Direct air capture technology removes CO2 from the atmosphere. These systems require significant energy input but show promise for large-scale deployment.
9. ## Policy Changes
10. Government regulations can accelerate the transition to clean energy through carbon pricing and renewable energy mandates.
`AI写代码结果数组(max_chunk_size: 30,separators: "#", "\\n\\n"):
swift
`
1. [
2. "# Climate Change Solutions\n\n## Renewable Energy\nSolar and wind power are becoming cost-competitive with fossil fuels. Investment in clean energy infrastructure creates jobs.",
4. "## Carbon Capture\nDirect air capture technology removes CO2 from the atmosphere. These systems require significant energy input but show promise for large-scale deployment.",
6. "## Policy Changes\nGovernment regulations can accelerate the transition to clean energy through carbon pricing and renewable energy mandates."
7. ]
`AI写代码无分块
这种 "策略" 禁用分块,从完整文本创建 embedding。它适用于较小的文本和始终需要完整上下文的文档。这种策略的潜在问题是,模型在生成 embedding 时可能丢弃多余的 token。
输入:
kotlin
`Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality.`AI写代码结果:
css
`["Artificial intelligence is transforming healthcare through predictive analytics. Machine learning algorithms can analyze patient data to identify risk factors. Early detection of diseases saves lives and reduces costs. However, data privacy remains a critical concern. Healthcare providers must balance innovation with patient confidentiality."]`AI写代码关键分块参数
Elastic 提供了以下分块策略的自定义参数:
-
overlap:分块之间重叠的单词数量,仅在单词(word)策略中使用。
-
sentence_overlap:分块之间重叠的句子数量,仅在句子(sentence)策略中使用。
-
separator_group:递归分块(recursive)策略的预定义分隔符列表,可为 "markdown" 或 "plaintext"。
-
separators:递归分块策略的自定义分隔符列表,可以是普通字符串或正则表达式。
-
strategy:选择的策略(sentence、word、recursive 或 none)。
-
max_chunk_size:分块的最大大小,以单词数计算。
Elasticsearch 中的分块
通过一个实际示例来看 Elasticsearch 中分块的工作原理。
分块设置在创建推理端点时指定,当你索引文档时,Elasticsearch 会自动处理分块过程。
在以下示例中,我们将创建一个带有句子分块策略的 text_embedding 推理端点,并检查分块是如何生成以及在语义查询中如何被找到的:
1)创建推理端点:
bash
`
1. PUT _inference/text_embedding/my-embedding-model
2. {
3. "service": "elasticsearch",
4. "service_settings": {
5. "num_allocations": 1,
6. "num_threads": 1,
7. "model_id": ".multilingual-e5-small_linux-x86_64"
8. },
9. "chunking_settings": {
10. "strategy": "sentence",
11. "max_chunk_size": 40,
12. "sentence_overlap": 0
13. }
14. }
`AI写代码这里,我们使用最大分块大小为 40 个单词,并且分块之间没有重叠。句子策略会在自然句子边界拆分文本。
确保你已部署 multilingual e5 small 模型。该模型的最大 token 窗口为 512。
2)使用 semantic_text 字段创建索引,该字段使用我们新的推理端点:
bash
`
1. PUT chunking_test
2. {
3. "mappings": {
4. "properties": {
5. "my-semantic-field": {
6. "type": "semantic_text",
7. "inference_id": "my-embedding-model"
8. }
9. }
10. }
11. }
`AI写代码当你索引文档时,Elasticsearch 会自动应用分块策略,并在 my-semantic-field 字段为每个分块创建 embeddings。
3)将示例文档索引到我们的索引中:
markdown
`
1. PUT chunking_test/_doc/1
2. {
3. "my-semantic-field": "Making perfect coffee requires attention to several key factors. Water temperature should be between 195-205°F for optimal extraction. Grind size affects brewing time and flavor strength significantly. Use a 1:15 coffee to water ratio for most brewing methods. Brewing time varies by method: pour-over takes 3-4 minutes while espresso takes 25-30 seconds. Fresh beans roasted within two weeks produce the best results."
4. }
`AI写代码该文档将根据我们的句子策略自动拆分为多个分块。
4)对索引执行语义搜索:
markdown
`
1. GET /chunking_test/_search
2. {
3. "fields": [
4. "_inference_fields"
5. ],
6. "query": {
7. "semantic": {
8. "field": "my-semantic-field",
9. "query": "how much time should I brew my coffee for?"
10. }
11. },
12. "highlight": {
13. "fields": {
14. "my-semantic-field": {
15. "order": "score",
16. "number_of_fragments": 1
17. }
18. }
19. }
20. }
`AI写代码让我们分部分来看查询:
markdown
`
1. "fields": [
2. "_inference_fields"
3. ],
`AI写代码这里,我们请求返回 title 和 inference 字段;这些字段包含有关端点、模型和分块的信息。
json
`
1. "query": {
2. "semantic": {
3. "field": "my-semantic-field",
4. "query": "how much time should I brew my coffee for?"
5. }
6. }
`AI写代码这是对 my-semantic-field 的语义查询,它会自动使用我们在第 1 步创建的推理端点,搜索与 user_query 中的词匹配的内容。
markdown
`
1. "highlight": {
2. "fields": {
3. "my-semantic-field": {
4. "order": "score",
5. "number_of_fragments": 1
6. }
7. }
8. }
`AI写代码这一部分会返回从文本生成的分块的最高命中结果。
现在的响应:
markdown
`
1. "hits": [
2. {
3. "_index": "chunking_test",
4. "_id": "1",
5. "_score": 0.9537368,
6. "_source": {
7. "my-semantic-field": "Making perfect coffee requires attention to several key factors. Water temperature should be between 195-205°F for optimal extraction. Grind size affects brewing time and flavor strength significantly. Use a 1:15 coffee to water ratio for most brewing methods. Brewing time varies by method: pour-over takes 3-4 minutes while espresso takes 25-30 seconds. Fresh beans roasted within two weeks produce the best results.",
8. "_inference_fields": {
9. "my-semantic-field": {
10. "inference": {
11. "inference_id": "my-embedding-model",
12. "model_settings": {
13. "service": "elasticsearch",
14. "task_type": "text_embedding",
15. "dimensions": 384,
16. "similarity": "cosine",
17. "element_type": "float"
18. },
19. "chunks": {
20. "my-semantic-field": [
21. {
22. "start_offset": 0,
23. "end_offset": 135,
24. "embeddings": [
25. -0.047878783,
26. ...
27. 0.02849774
28. ]
29. },
30. {
31. "start_offset": 135,
32. "end_offset": 261,
33. "embeddings": [
34. -0.019347992,
35. ...
36. 0.046932716
37. ]
38. },
39. {
40. "start_offset": 261,
41. "end_offset": 356,
42. "embeddings": [
43. -0.021673936,
44. ...
45. 0.03294023
46. ]
47. },
48. {
49. "start_offset": 356,
50. "end_offset": 418,
51. "embeddings": [
52. 0.027161874,
53. ...
54. 0.033048477
55. ]
56. }
57. ]
58. }
59. }
60. }
61. }
62. },
63. "highlight": {
64. "my-semantic-field": [
65. "Brewing time varies by method: pour-over takes 3-4 minutes while espresso takes 25-30 seconds. "
66. ]
67. }
68. }
69. ]
`AI写代码让我们拆解响应:
原始内容:
json
`
1. "_source": {
2. "my-semantic-field": "Making perfect coffee requires attention to several key factors..."
3. }
`AI写代码被索引的完整原始文本。
分块详情:
bash
`1. "_inference_fields": {
2. "my-semantic-field": {
3. "inference": {
4. "inference_id": "my-embedding-model",
5. "chunks": {
6. "my-semantic-field": [
7. {
8. "start_offset": 0,
9. "end_offset": 135,
10. "embeddings": [
11. -0.047878783,
12. ...
13. 0.02849774
14. ]
15. },
16. {
17. "start_offset": 135,
18. "end_offset": 261,
19. "embeddings": [
20. -0.019347992,
21. ...
22. 0.046932716
23. ]
24. },
25. {
26. "start_offset": 261,
27. "end_offset": 356,
28. "embeddings": [
29. -0.021673936,
30. ...
31. 0.03294023
32. ]
33. },
34. {
35. "start_offset": 356,
36. "end_offset": 418,
37. "embeddings": [
38. 0.027161874,
39. ...
40. 0.033048477
41. ]
42. }
43. ]
44. }
45. }
46. }
47. }`AI写代码这显示了:
-
start_offset/end_offset:每个分块在原始文本中开始和结束的字符位置
-
embeddings:每个分块的向量表示(e5-small 模型为 384 维)
-
分块数量:在此示例中,我们的咖啡冲泡文本生成了 4 个分块
最佳匹配分块:
markdown
`
1. "highlight": {
2. "my-semantic-field": [
3. "Brewing time varies by method: pour-over takes 3-4 minutes while espresso takes 25-30 seconds."
4. ]
5. }
`AI写代码高亮显示了对于我们的查询 "how much time should I brew my coffee for?" 得分最高的具体分块,展示了即使精确词不匹配,语义搜索也能找到最相关的内容。
分块策略实验
设置
我们将使用一些美洲国家的 Wikipedia 页面。这些页面包含较长文本,可以演示分块策略与不分块策略的区别。我们准备了一个仓库,用于获取 Wikipedia 内容,并创建相应的推理端点和映射以上传数据。
1)克隆仓库:
bash
`
1. git clone https://github.com/Alex1795/embeddings_chunking_strategies_blog.git
2. cd embeddings_chunking_strategies_blog
`AI写代码2)安装所需库:
go
`pip install -r requirements.txt`AI写代码3)设置环境变量:
ini
`
1. export ES_HOST="your-elasticsearch-endpoint"
2. export ES_API_KEY="your-api-key"
`AI写代码4)运行 set_up.py 文件:
go
`python set_up.py`AI写代码该脚本执行以下步骤:
-
创建两个推理端点,都使用 ELSER 模型生成稀疏 embeddings:
-
sentence-chunking-demo:使用句子分块策略,最大分块大小为 80,句子重叠为 1
-
none-chunking-demo:不使用任何分块策略
-
-
为索引 countries_wiki 创建映射,包括 wiki_article 字段的两个多字段(mulitfield):
-
wiki_article.sentence:使用 sentence-chunking-demo 推理端点
-
wiki_article.none:使用 none-chunking-demo 推理端点
-
-
获取每个国家的 Wikipedia 文章,并将标题和内容分别上传到我们新索引的 country 和 wiki_article 字段
这可能需要几分钟;请记住,Elastic 会在 semantic_text 字段上进行分块并生成 embeddings。如果一切顺利,你将看到过程正确完成:
运行语义搜索
脚本 run_semantic_search.py 实现了多个辅助函数,在两个 semantic_text 字段上执行相同的语义搜索,并以表格形式打印结果以便比较。你可以直接这样执行脚本:
go
`python run_semantic_search.py`AI写代码你将看到 demo_queries 列表中定义的每个查询的结果(可在此添加你自己的查询进行测试):
ini
`
1. demo_queries = [
2. "countries in the inca empire",
3. "coffee production",
4. "oil and petroleum exports",
5. "beach destinations",
6. "hockey"
7. ]
`AI写代码结果
让我们查看 demo 中查询的一些结果:
Query: countries in the inca empire
Strategy: sentence chunking

我们得到了预期结果:秘鲁、厄瓜多尔、玻利维亚、智利、阿根廷,以及相关分块。例如,对于阿根廷,我们得到了一条非常具体的信息:
arduino
`"the advanced Diaguita sedentary trading culture in the northwest, which was conquered by the Inca Empire around 1480"`AI写代码如我们所见,我们可以轻松确定每个文档出现在结果中的原因。
Query: countries in the inca empire
Strategy: no chunking
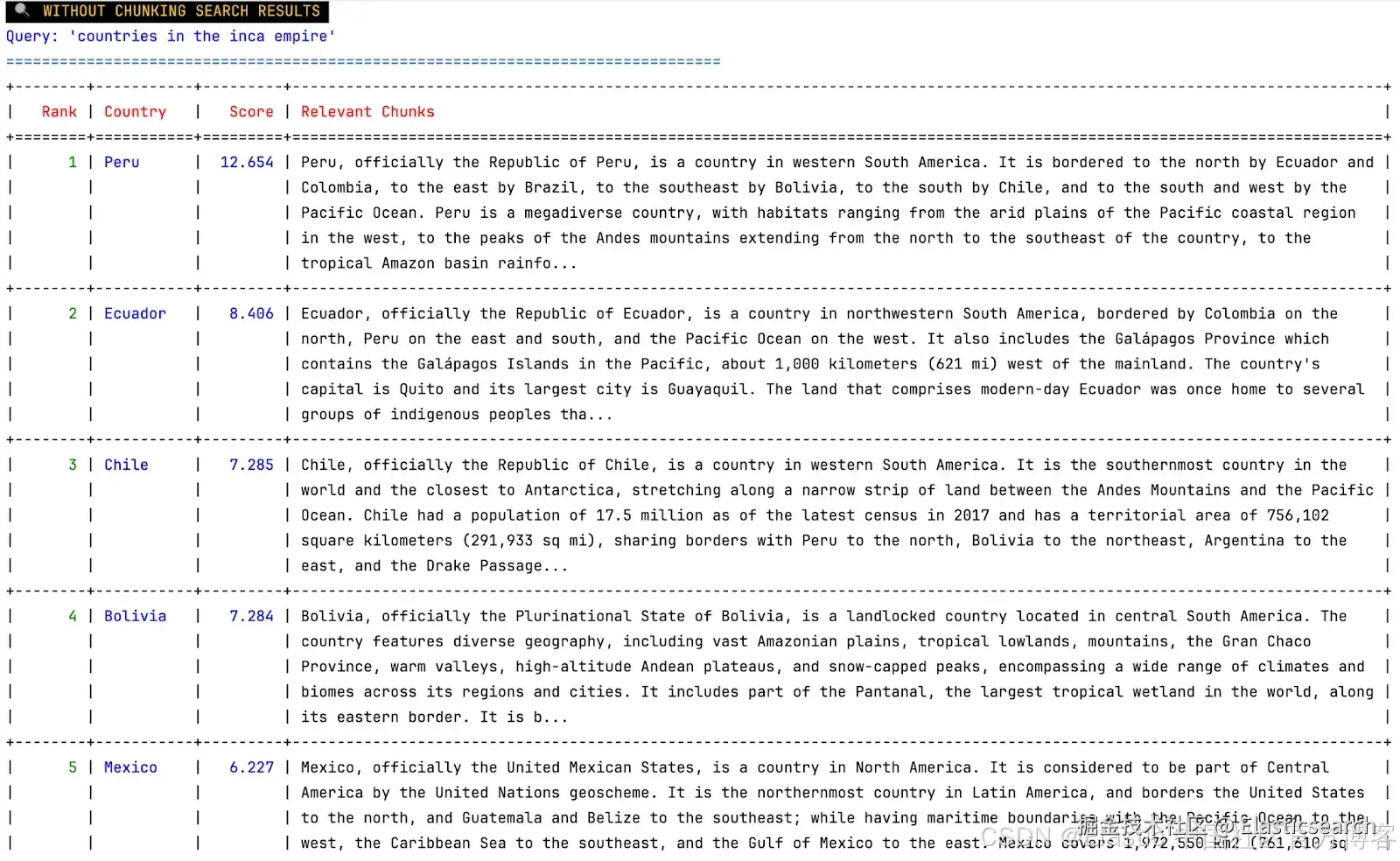
这里我们可以看到前四个结果相同,但最后出现了墨西哥,它根本不是印加帝国的一部分。我们还可以看到整篇文档作为一个相关分块被接收,因此无法真正判断这些文档为何相关。问题在于 embedding 是由文本的前 512 个 token 生成的,因此丢失了大量信息。很可能,我们无法获得每个国家历史的任何信息。
Query: hockey
Strategy: sentence chunking
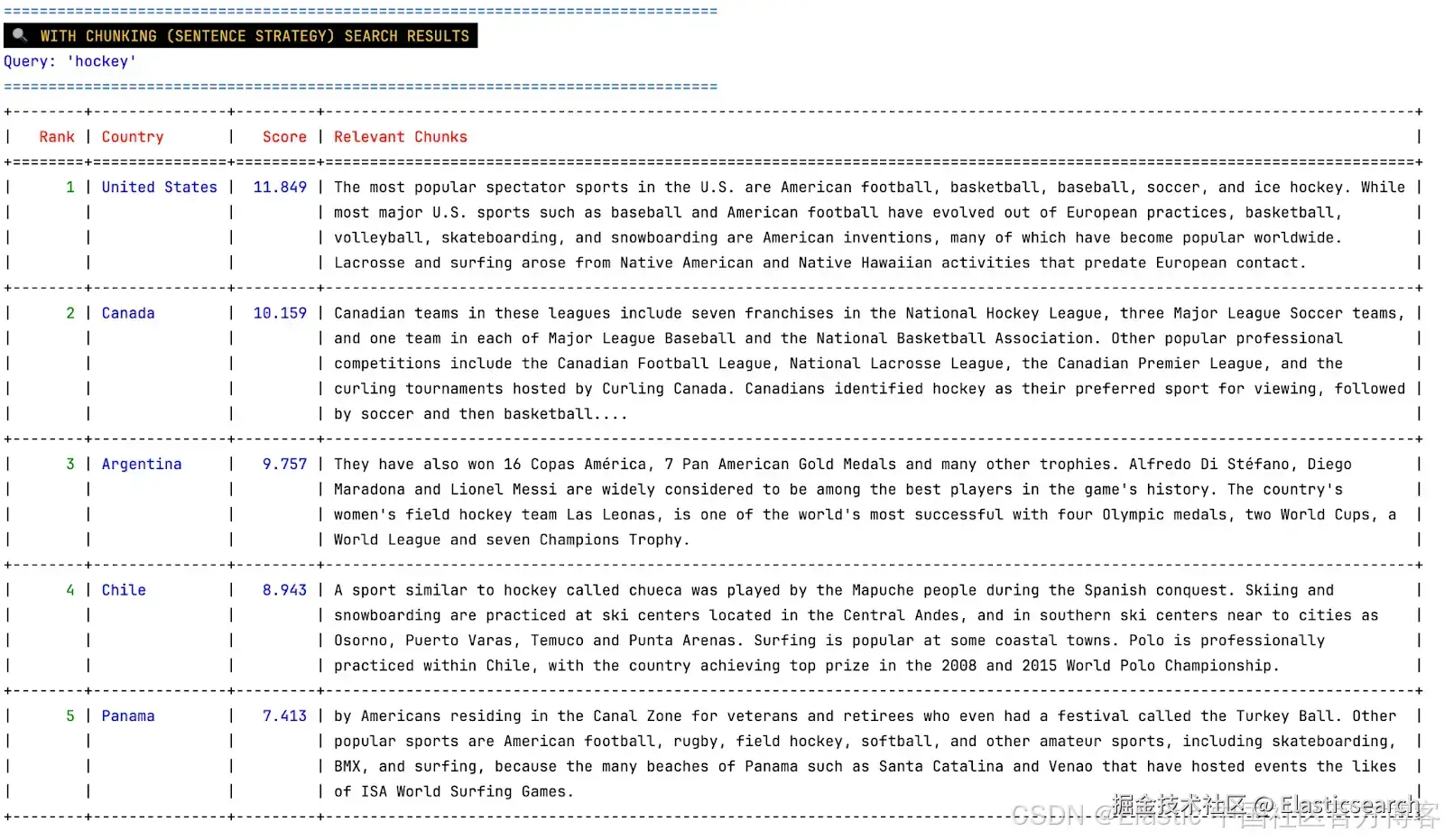
我们可以看到与 hockey 直接相关的国家,如美国和加拿大,以及阿根廷、智利和巴拿马。在相关分块列中,我们可以看到 hockey 在每篇文章中的提及情况。
Query : hockey
Strategy: no chunking

在这些结果中,我们可以看到通常与 hockey(或冬季运动)无关的国家。由于相关文本是整篇文章,我们无法真正知道这些国家为何出现在结果中。此外,注意分数比之前低得多;这表明这些结果可能根本不理想,只是"最接近"查询,但关联性很低。
结论
如我们所见,使用分块策略可以提升结果质量。没有分块,我们会遇到以下问题:
-
无关结果(如印加帝国中的墨西哥):当文本超过 embedding 模型的 token 限制时,一些数据在生成 embedding 时被排除,导致信息丢失。
-
结果解释困难:即使结果相关,从整篇文本中也很难解释某个文档为何出现,而从相关分块中则更容易。这在验证结果和建立用户信任时可能成为问题。
-
效率问题:如果我们将结果发送给下游 LLM,整篇文档会迅速占用上下文窗口,并包含大量无关信息,导致 token 成本增加和响应质量下降。
总之,当处理超过模型 token 限制的文本时,使用分块策略总是一个好主意。它可以提升结果质量并降低成本,是设计 AI 系统时的基础策略。