TL;DR
- 场景:分布式系统需要集中式日志/搜索/可视化与告警。
- 结论:用 Elasticsearch 8.x + Logstash + Kibana 形成统一采集→索引→分析闭环,先小步上线再按吞吐扩容。
- 产出:架构要点提炼、版本适配矩阵
ELK
集中式日志系统
日志,对于任何系统来说都是重要的组成部分,在计算机系统里面,更是如此。但是由于现在的计算机系统大多比较复杂,狠毒哦系统都不是在一个地方,甚至都是跨国界的,即使在一个地方的系统,也有不同的来源,比如:操作系统、应用服务、业务逻辑等等。他们都在不停的产生各种各样的日志数据,根据不完全统计,我们每天大约要生产2EB的数据。
面对海量的数据,又是分布式在各个不同的地方,如果我们需要去查找一些重要的信息,难道还是使用传统的方法,去登陆到一台机器上看看吗?看来传统的工具和方法是非常笨拙和低效的。于是,一些聪明人就提出了建立一套集中的方法,把不同来源的数据集中整合到一个地方。 一个完整的集中式日志系统,是离不开以下几个主要特点的:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持UI分析
- 警告-能够提供错误报告,监控机制
#ELK协议栈介绍和体系结构
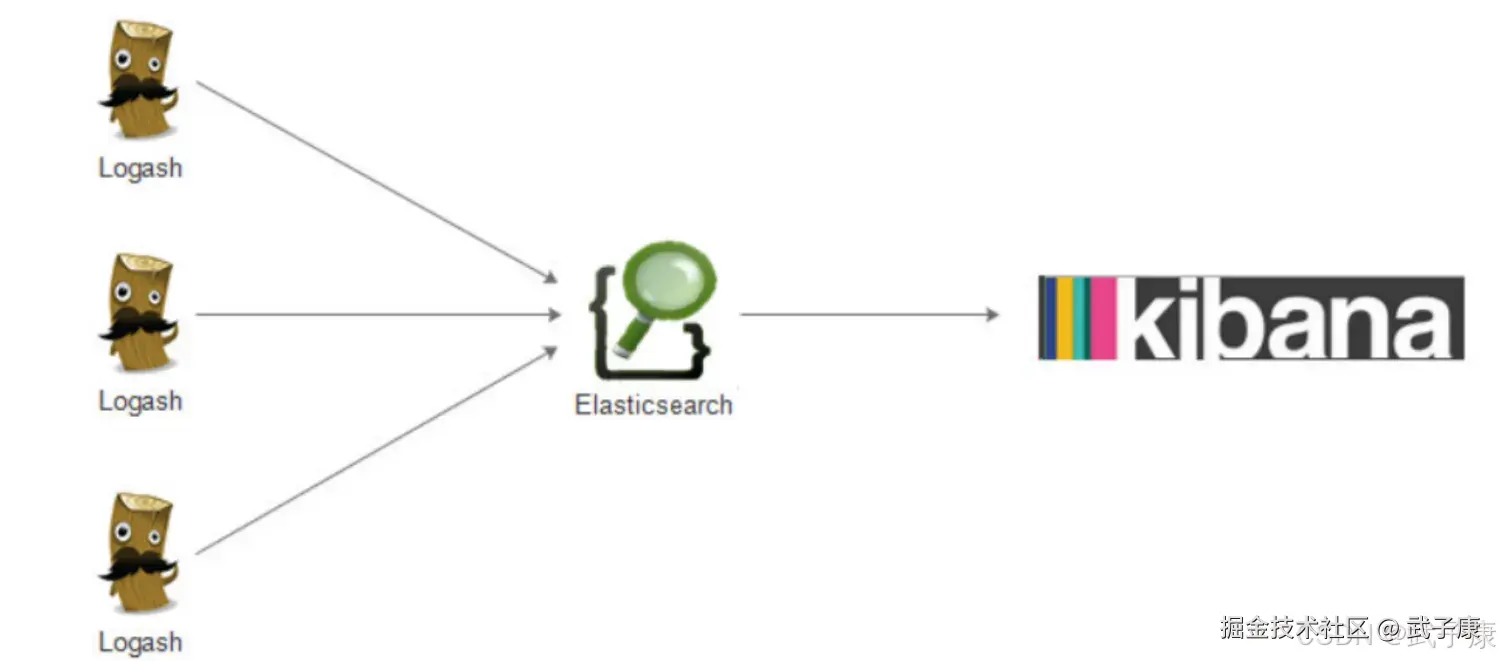 ELK其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写(Elasticsearch ES),Logstash、Kibana。这三款都是开源软件,配合使用,而先后又归于 Elasttic.co 公司名下,简称 ELK 协议栈。
ELK其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写(Elasticsearch ES),Logstash、Kibana。这三款都是开源软件,配合使用,而先后又归于 Elasttic.co 公司名下,简称 ELK 协议栈。
Elasticsearch
Elasticsearch 是一个基于 Lucene 的开源搜索引擎,主要用于实时全文搜索、分析、日志管理和数据存储。由于其高度扩展性和分布式架构,Elasticsearch 被广泛应用于企业搜索、监控系统、日志分析、推荐系统等场景。
主要特点
- 实时分析
- 分布式实时文件存储,并将每一个字段都编入索引
- 文档导向,所有的对象全部是文档
- 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards和Replicas)。
- 接口友好、支持JSON
核心功能
- 全文搜索:Elasticsearch 可以快速、高效地进行全文搜索,支持模糊匹配、通配符查询、布尔查询等。
- 分布式架构与高可用性:集群由多个节点组成,每个节点负责不同的数据分片,确保数据在多个节点上冗余存储,以提高系统的容错能力和高可用性。
- 实时数据分析:支持实时数据插入、更新和查询,适合日志分析、监控等对时效性要求高的应用场景。
- 支持多种数据类型:支持结构化、半结构化和非结构化数据,如 JSON、文本、地理位置数据等。
- RESTful API:Elasticsearch 采用 RESTful 风格的 API,通过 HTTP 接口与客户端交互,易于集成。
基本架构
集群(Cluster)
- 定义:集群是由多个相互连接的 Elasticsearch 节点组成的集合,它们共同工作以提供分布式搜索和分析能力。
- 唯一标识 :每个集群必须有一个唯一的名称(默认是
elasticsearch),用于区分不同的集群环境(如开发、测试、生产)。 - 数据一致性:集群通过分布式架构确保数据的高可用性和一致性。例如,当一个节点故障时,其他节点会自动接管其工作,保证服务不中断。
- 典型应用场景:跨数据中心的日志分析系统可能需要多个集群协同工作,每个集群处理特定区域的数据。
节点(Node)
- 定义:节点是集群中的一个 Elasticsearch 实例,通常运行在独立的服务器或容器中。
- 角色分类 :
- 主节点(Master Node):负责集群管理操作(如创建/删除索引、节点状态监控)。生产环境中建议配置 3 个专用主节点以避免脑裂问题。
- 数据节点(Data Node):存储索引数据并执行数据相关的操作(如搜索、聚合)。需要较高的磁盘和内存资源。
- 协调节点(Coordinating Node):接收客户端请求并将任务分发到其他节点,最后聚合结果。在大型集群中可独立部署以减轻主节点和数据节点负载。
- 配置示例 :通过
node.roles: [ data, master ]参数指定节点角色。
索引(Index)
- 类比关系:类似于关系型数据库中的"表",但设计上更灵活,无需预定义严格的结构(支持动态映射)。
- 组成 :
- 分片(Shard):每个索引被水平分割为多个分片(默认 1 个主分片),实现数据分布式存储和并行处理。
- 副本(Replica) :每个分片可以有多个副本(默认 1 个),提供故障恢复能力。例如,设置
number_of_replicas: 2表示每个主分片有 2 个副本。
- 生命周期管理:可通过 ILM(Index Lifecycle Management)自动实现索引的滚动创建(如每天生成新索引)、归档和删除。
文档(Document)
- 基本单元:以 JSON 格式存储的数据记录,例如一条商品信息或日志条目。
- 唯一标识 :通过
_id字段唯一标识(可自动生成或手动指定),结合索引名称构成全局唯一性(类似<index>/<type>/<id>的路径)。 - 元数据字段 :除用户自定义数据外,每个文档包含系统元数据如
_version(乐观锁控制)、_source(原始 JSON 内容)等。 - 示例:
json
{
"_index": "products",
"_id": "101",
"_source": {
"name": "Wireless Mouse",
"price": 29.99,
"category": "Electronics"
}
}分片与副本(Shard & Replica)
为了实现水平扩展,索引被分成多个主分片(Primary Shard)。每个主分片可以有多个副本(Replica Shard),提高容错性和读取性能。
查询与分析
查询 DSL(Query DSL):Elasticsearch 使用 JSON 格式的 DSL(Domain-Specific Language)进行查询,包括:
- Match Query:进行全文搜索。
- Term Query:精确匹配某一字段的值。
- Range Query:进行范围查询(如时间范围)。
- Bool Query:组合多个查询条件(如 AND、OR)。
聚合(Aggregation):用于对大数据集进行分组统计和分析,如求平均值、最大值、最小值等。支持以下类型:
- Bucket Aggregation:按条件分组,如基于时间的日期直方图。
- Metric Aggregation:求和、计数、平均值等。
- Pipeline Aggregation:基于前一个聚合结果计算的二次聚合。
典型应用场景
- 日志分析和监控:与 Logstash 和 Kibana 组合形成 ELK(Elastic Stack),用于实时日志监控和数据可视化。
- 企业级搜索引擎:支持全文搜索、推荐系统、网站内容搜索等。
- 电商平台:用于实现商品搜索和推荐功能。
- 地理空间数据查询:支持 geo_point 和 geo_shape 类型数据,用于存储和分析位置数据。
- 数据仓库分析:支持大数据实时分析,替代部分传统 OLAP 系统。
Logstash
Logstash是一个具有实时渠道能力的数据收集引擎,使用JRuby语言编写,作者是世界著名的运维工程师乔丹西塞(JordanSissel) 主要特点有:
- 几乎可以访问任何数据
- 可以和多种外部应用结合
- 支持弹性扩展
- Shipper - 发送日志数据
- Broker - 收集数据 缺省内置Redis
- Indexer - 数据写入
Kibana
Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写的,为 Elasticsearch 提供可视化分析和Web平台,它可以在Elasticsearch的索引中查找,交互数据,生成各种维度的表图。
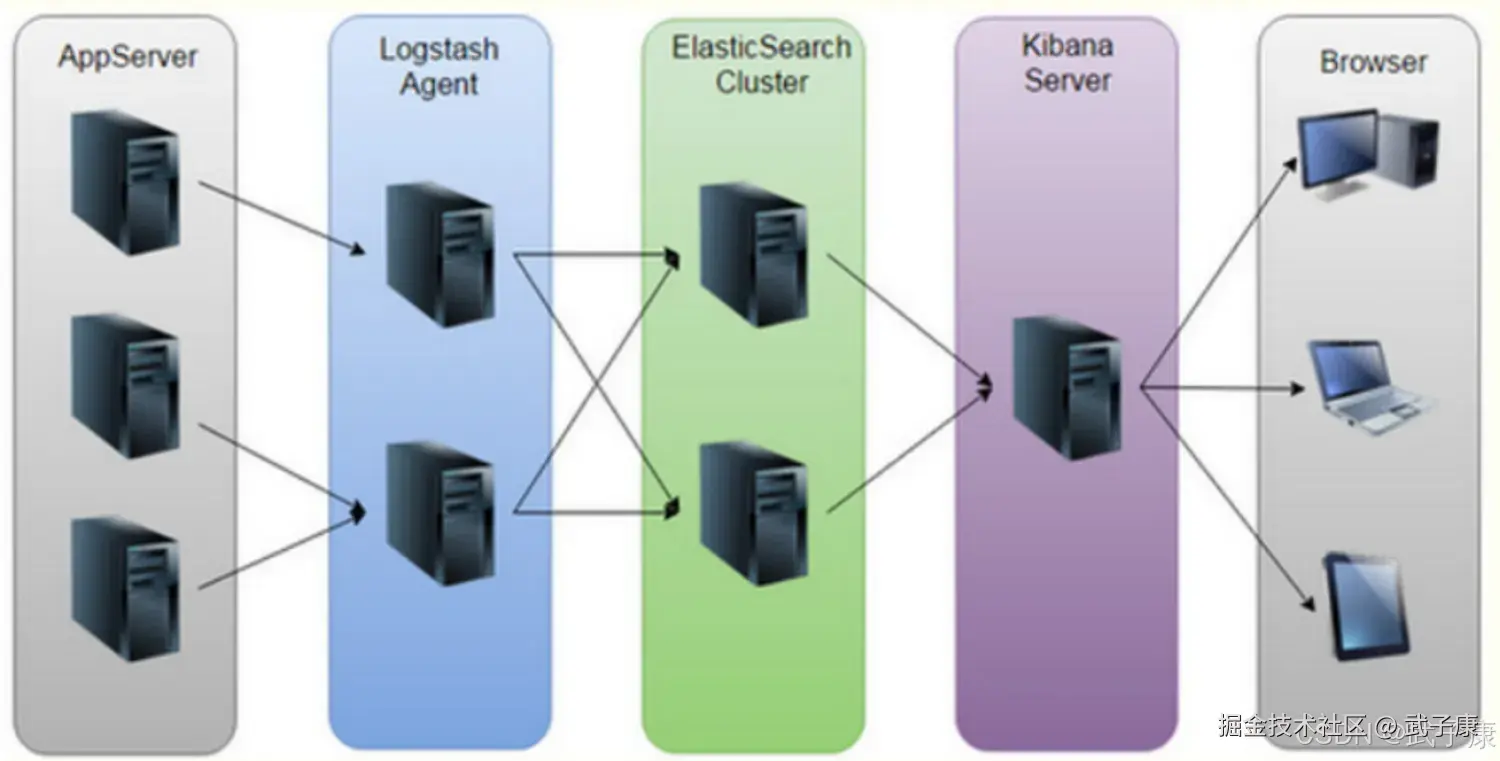
ELK整体架构
参考文档
- ELK官网:www.elastic.co/
- ELK官网文档:www.elastic.co/guide/index...
- ELK中文手册:www.elastic.co/guide/cn/el...
- ELK中文社区:elasticsearch.cn/
- ELK API :www.elastic.co/guide/en/el...
使用案例
- 2013年初,GitHub抛弃了Solr,采取Elasticsearch来做PB级的搜索,"Github使用Elasticsearch搜索20TB的数据,包括13亿文件和1300亿航代码"
- 维基百科,启动Elasticsearch为基础的核心搜索架构
- SoundCloud,SoundCloud使用Elasticsearch为1.8亿用户提供即时而精准的音乐搜索服务
- 百度,百度目前广泛使用Elasticsearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示、辅助定位分析实例异常或业务异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等)。单集群最大100台机器,200个ES节点,每天导入30TB+数据。
- 新浪使用ES分析处理32亿条实时日志
- 阿里使用ES构建自己的日志采集和分析系统
对比Solr
-
分布式管理机制
- Solr 依赖 ZooKeeper 进行集群管理和配置同步,需要额外部署和维护 ZooKeeper 集群
- Elasticsearch 内置分布式协调功能(基于 Zen Discovery 模块),无需额外组件即可实现节点发现、集群状态管理等功能,部署更简单
-
数据格式支持
- Solr 支持多种数据格式:
- XML
- CSV
- JSON
- 二进制格式(如 PDF、Word 等通过 Tika 解析)
- Elasticsearch 仅原生支持 JSON 格式,但可以通过 Logstash 等工具进行格式转换后导入
- Solr 支持多种数据格式:
-
功能生态对比
- Solr 官方提供完整功能套件:
- 数据导入处理器(DIH)
- 丰富的查询分析器
- 图形化管理界面
- Elasticsearch 采用"核心+插件"架构:
- 专注索引和搜索核心功能
- 高级功能(如机器学习、告警等)通过插件实现
- 拥有更活跃的第三方插件生态
- Solr 官方提供完整功能套件:
-
搜索性能特点
- Solr 优势场景:
- 传统批处理式搜索(如电商商品目录搜索)
- 复杂条件组合查询
- 对查询延迟要求不高的场景
- Elasticsearch 优势场景:
- 实时搜索(如日志分析、监控系统)
- 近实时(NRT)索引更新(默认 1s 刷新间隔)
- 高吞吐量的数据写入场景
- 典型应用案例:ELK 日志分析栈中的日志检索
- Solr 优势场景:
-
补充对比维度
- 学习曲线:
- Solr 配置相对复杂,需要理解多个配置文件
- Elasticsearch REST API 更符合现代开发习惯
- 社区支持:
- Elasticsearch 拥有更活跃的开发者社区
- Solr 在企业级应用中仍有稳定用户群
- 学习曲线:
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 集群 Yellow/Red & 分片 UNASSIGNED | 节点掉线/磁盘水位/路由限制 | _cluster/health、_cat/shards、ES 日志 |
释放磁盘/调 cluster.routing.allocation.*;reroute 或恢复节点后自动分配 |
| 写入被拒(429/CircuitBreakingException) | JVM heap 压力/字段爆炸 | _nodes/stats、GC 日志、索引写入速率 |
控制字段基数与映射;禁用不必要 fielddata;增内存/扩节点;批量写入节流 |
| 慢查询/CPU 飙升 | 通配/前缀正则、深分页、脚本聚合 | 搜索慢日志、profile API |
用 keyword 精确匹配;改 search_after/point in time;必要时预聚合 |
| Kibana "server is not ready" | ES 未就绪/版本不匹配/权限问题 | Kibana 日志、/api/status |
对齐版本;校验 elasticsearch.hosts 与用户权限;等待 ES 绿/黄后再启动 |
| Logstash 队列阻塞/丢数据 | 输出端背压/PQ 满/插件异常 | /var/lib/logstash/queue、管道监控 API |
提升输出吞吐/并发;扩大 PQ;启用 DLQ;修复异常插件或目标端 |
| 时间轴错乱/图表空洞 | 时区处理不一致/字段非 date |
_mapping、样例文档 |
统一用 @timestamp(UTC);显式 date 类型与 timezone;在 Ingest 规范化时间 |
| 映射冲突/同字段不同类型 | 多源写入未控 schema | GET _mapping、模板检查 |
固化 Index Template;冲突字段改名或重建索引+reindex |
ES 启动报 vm.max_map_count 过低 |
OS 虚拟内存限制 | ES 启动日志 | sysctl -w vm.max_map_count=262144 并写入系统配置;重启 ES |
| SSL 握手失败/PKIX 错误 | 证书 CN/SAN 不匹配/CA 链缺失 | Kibana/Logstash/ES 日志 | 重新签发含正确 SAN 的证书;统一信任链;校验 ssl.* 配置 |
| 索引只读(磁盘高水位) | 磁盘 > 高水位触发保护 | 集群日志、_cluster/settings |
清理磁盘/扩容;下调阈值;解锁:index.blocks.read_only_allow_delete=false |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解