大模型的架构,要彻底进化了?
昨晚开始,AI 圈都在研究一个神奇的新物种 ------Code World Model(CWM)。

Meta 重组后的 AI 部门推出的首个重磅研究,是一个世界模型,用来写代码的。
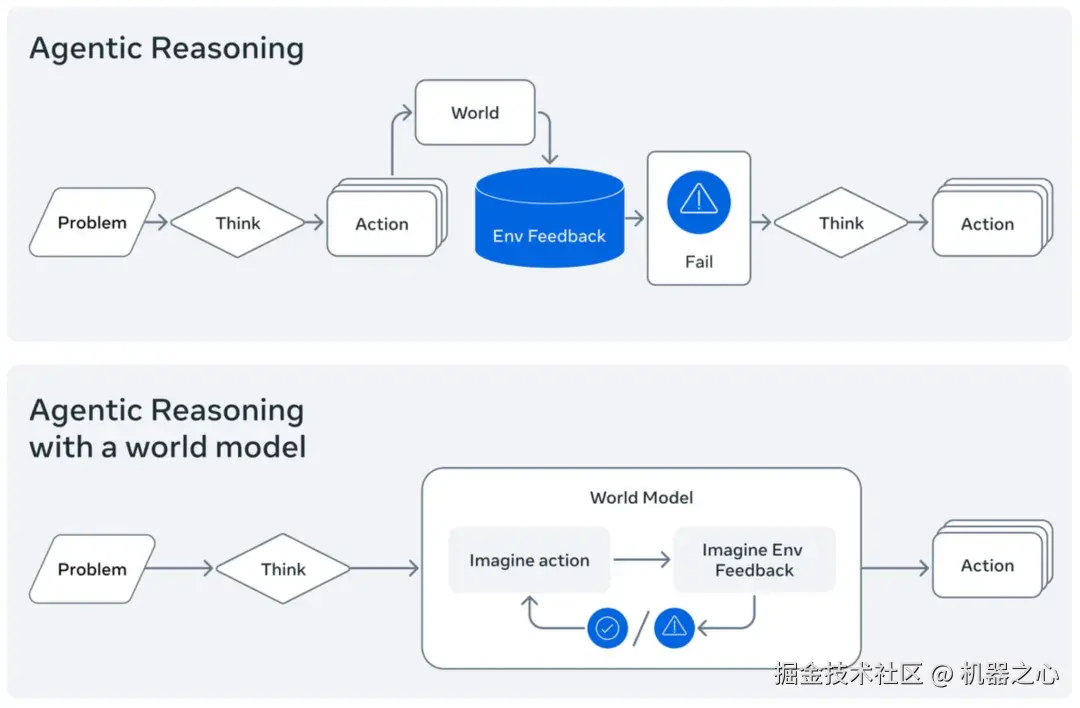
它和「传统」的大语言模型(LLM)思路不同,理论是这样的:
当人类进行计划时,我们会在脑海中想象不同行动可能带来的结果。当我们推理代码时,我们会在心中模拟其部分执行过程。当前一代的大语言模型在这方面表现不佳,往往难以做到真正的推理和模拟。那么,一个经过显式训练的代码世界模型(Code World Model)是不是能够开启新的研究方向呢?
Meta 刚发布的这个 CWM,是一个 320 亿参数的开放权重 LLM,以推动基于世界模型的代码生成研究。
CWM 是一个稠密的、仅解码器结构的 LLM,支持最长 131k tokens 的上下文长度。独立于其世界建模能力,CWM 在通用编程与数学任务上表现出强大性能:
-
SWE-bench Verified(含测试时扩展):pass@1 65.8%
-
LiveCodeBench:68.6%
-
Math-500:96.6%
-
AIME 2024:76.0%
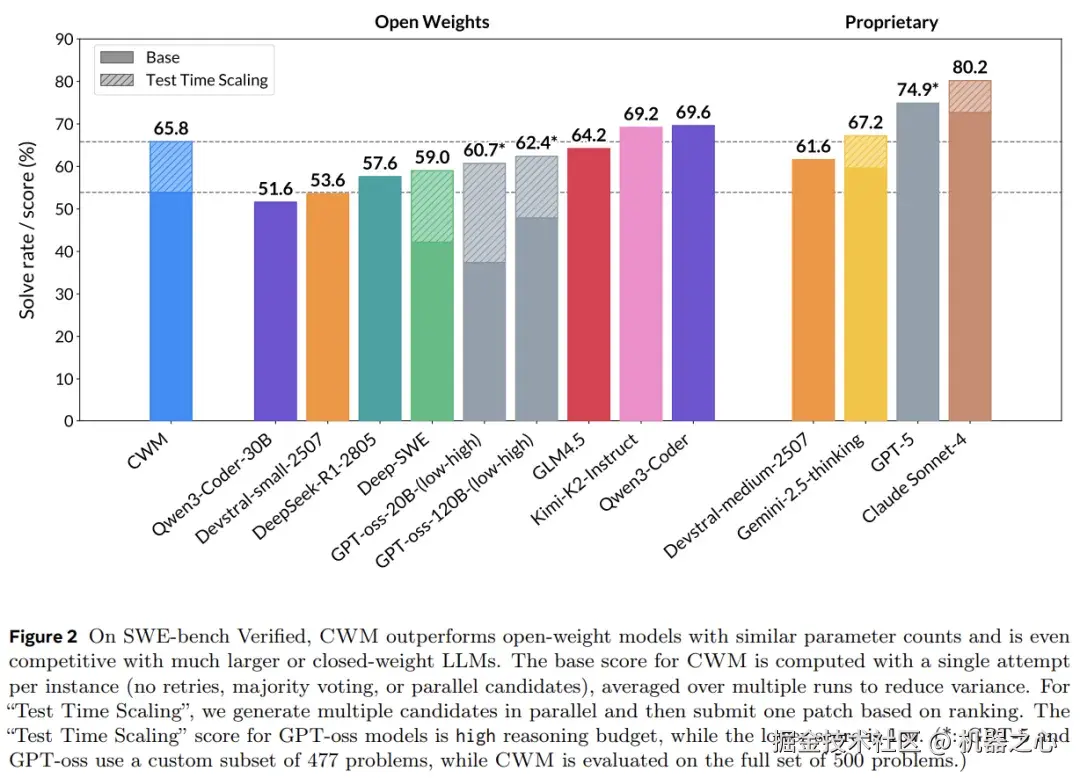
可见,虽然 CWM 的绝对性能还不算太高,但它在 30B 级别模型的横向对比上性能已算不错。
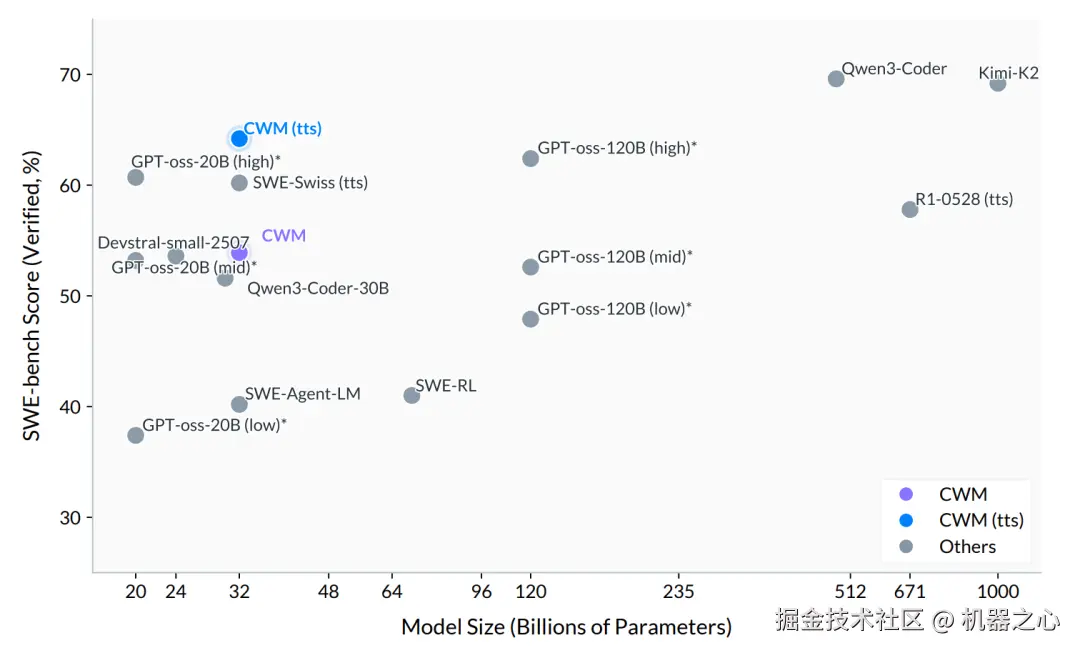
SWE-bench Verified pass@1 分数
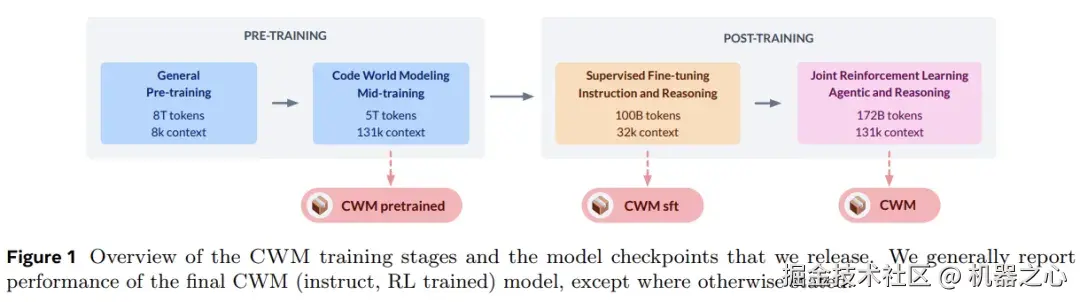
为了提升代码理解能力,而不仅仅局限于从静态代码训练中学习,Meta FAIR CodeGen 团队在 Python 解释器和智能体式 Docker 环境中使用了大量观测 - 动作轨迹进行中间训练(mid-train),并在可验证编码、数学和多轮软件工程环境中进行了大规模多任务推理强化学习(RL)。
为支持进一步的代码世界建模研究,Meta 开放了模型在 中间训练(mid-training)、SFT 和 RL 阶段的检查点。

-
论文标题:CWM: An Open-Weights LLM for Research on Code Generation with World Models
-
HuggingFace:huggingface.co/facebook/cw...
借助 CWM,Meta 提出了一个强大的测试平台,以探索世界建模在改进代码生成时的推理与规划能力方面的机会。
该研究展示了世界模型如何有益于智能体式编码,使得 Python 代码执行能够逐步模拟,并展示了推理如何从这种模拟中受益的早期结果。
在该研究中,Meta 似乎从传统开发的过程中汲取了灵感。优秀程序员会在上手写代码之前先在脑内推演,而现在基于大语言模型的代码生成工具,是在基于海量数据生成对相关代码的「模仿」。看起来像是对的,和真正理解写出的代码之间总会有点 gap。
一个明确训练的代码世界模型,应该能够预测自己行为的后果,进而作出判断实现有效的决策。
有一个很有意思的例子,大模型总是会犯些低级错误,比如数不清楚「strawberry」里有几个「r」。
而采用 CWM,就可以对一段统计 "strawberry" 中字母 "r" 的代码执行过程进行追踪。可以将其类比为一个神经版的 pdb ------ 你可以将其设置在任意初始帧状态下,然后推理过程就能够在 token 空间中调用这一工具来进行查询。

CWM 的 Python 跟踪格式。 在给定源代码上下文与跟踪起始点标记的情况下,CWM 预测一系列的调用栈帧,表示程序状态及相应的执行动作。
CWM 模型基于大量编码数据和定制的 Python + Bash 世界建模数据进行训练,使其能够模拟 Python 函数的执行以及 Bash 环境中的智能体交互。
在 Meta 进行的更多实验中,CWM 在有无测试时扩展(tts)的情况下均达到了同类最佳性能,分别取得了 65.8% 和 53.9% 的成绩。需要注意的是,GPT-oss 的分数是基于 500 道题中的 477 道子集计算得出的。
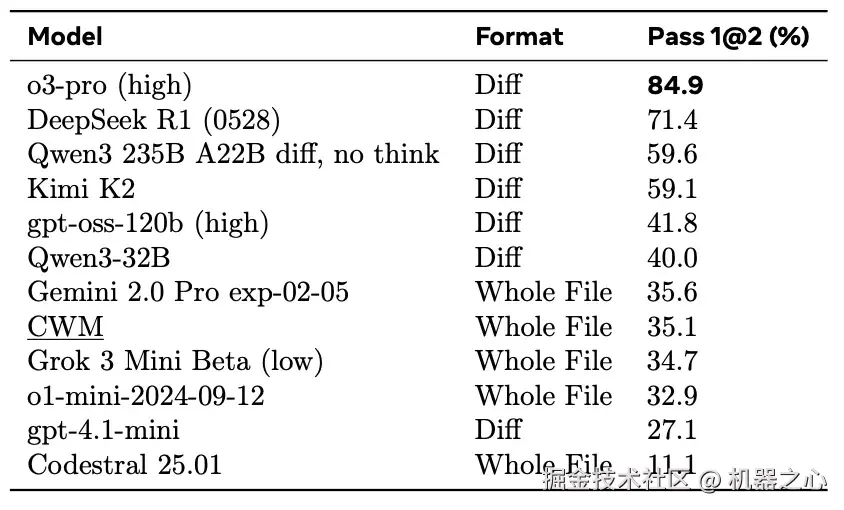
CWM 与基线模型在 Aider Polyglot 上的结果,取自官方排行榜。
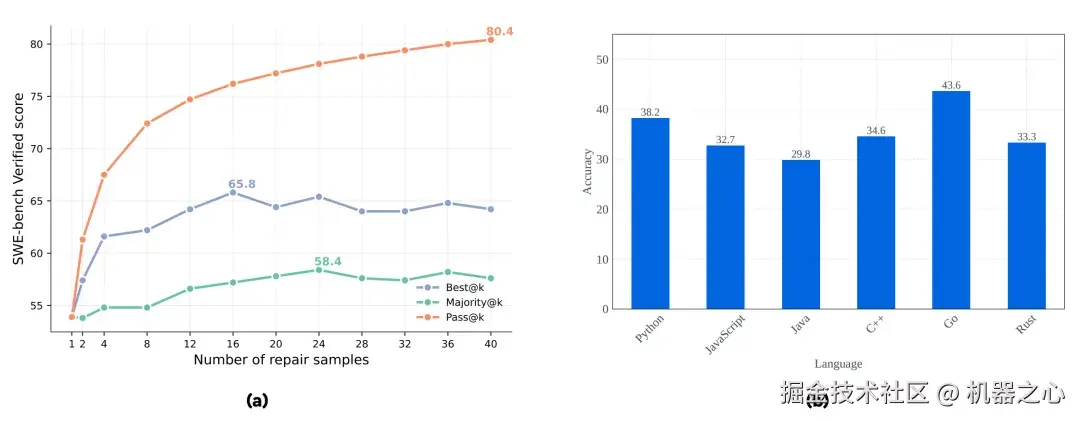
在 SWE-bench Verified 上,结合本文提出的 best@k 方法与多数投票(majority voting)的测试时扩展(TTS),能够显著提升 CWM 的 pass@1 得分,如图(a)所示。
在 Aider Polyglot 基准上,采用整文件编辑格式(whole file edit format)时,CWM 在不同编程语言上的准确率表现如图(b)所示。
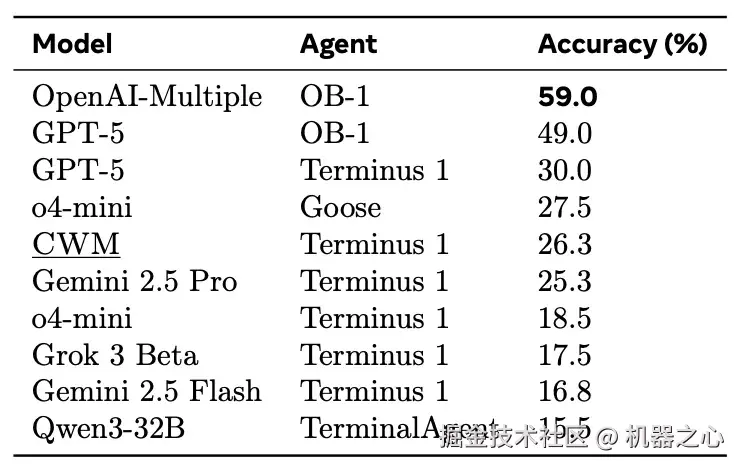
Terminal-Bench 上 CWM 与各基线模型的结果,取自官方排行榜。
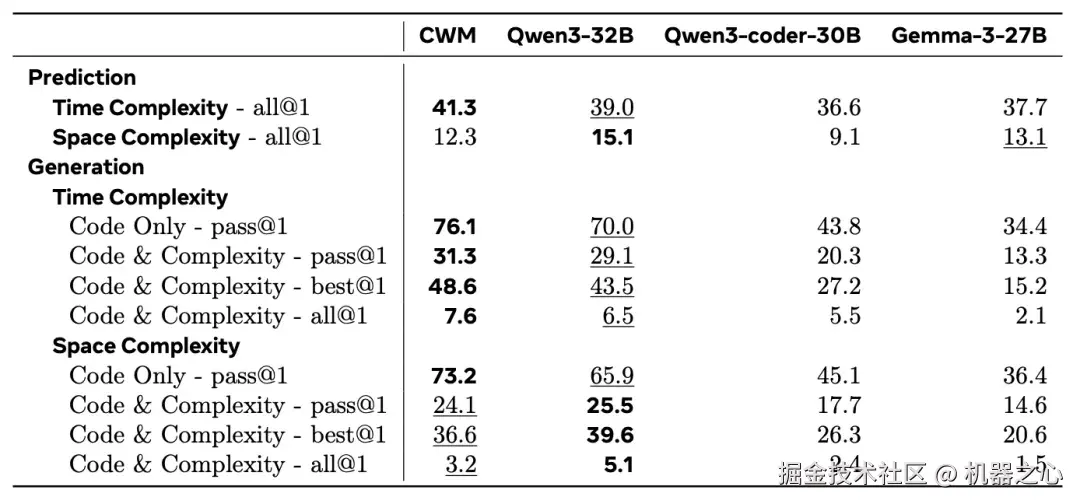
BigOBench 结果
在时间与空间复杂度的预测和生成两类任务上,将 CWM 与 Qwen3-32B(带推理能力)、Qwen3-coder-30B 以及 Gemma-3-27B 进行了对比。在时间复杂度预测与生成的全部指标上,CWM 均超越了基线模型。在空间复杂度生成方面,CWM 在仅代码模式下的 pass@1 上取得最佳成绩,并在其余指标中排名第二。
Meta 团队的愿景是让代码世界模型弥合语言层面的推理与可执行语义之间的鸿沟。
消融实验已经表明,世界建模数据、Python 执行轨迹以及可执行的 Docker 环境,能够直接提升下游任务表现。更广泛地说,CWM 提供了一个强有力的试验平台,支持未来在零样本规划、具身的链式思维、以及稀疏且可验证奖励的强化学习等方向的研究。
世界模型应当能够改进强化学习,因为那些已经熟悉环境动态的智能体,可以更专注于学习哪些动作能够带来奖励。尽管如此,要在预训练阶段跨任务地持续发挥世界模型的优势,仍需要进一步研究。最终,能够推理自身动作后果的模型,将在与环境的交互中更为高效,并有望扩展其能够处理的任务复杂度。
更多细节,请参阅原论文。