万亿参数!阿里 Qwen3-Max 大模型正式发布!
核心亮点先摆这儿:
9 月 24 日云栖大会刚发的 Qwen3-Max,参数超 1 万亿,LMArena 榜单干过 GPT-5-Chat 拿第三;
编程能力 69.6 分(SWE-Bench),写代码堪比资深程序员;
API 输入最低 0.006 元 / 千 token,Qwen Chat 还能免费薅;
分 Base、Instruct、Thinking 三个版本,Instruct 版已能直接用。

image-20250925153241195
发布会现场直击:万亿参数模型登场
9 月 24 日云栖大会开幕式上,通义千问团队一亮相就炸了场 ------Qwen3-Max 正式发布,号称 "阿里史上最强"。现场屏幕闪过关键数据:总参数超 1 万亿,预训练啃了 36T tokens 的数据,比上一代模型多了不止一个量级。最惊喜的是 Instruct 版当天就上线了 Qwen Chat(chat.qwen.ai)和阿里云百炼平台,不用等内测直接冲。
image-20250925153423888
阿里这波属于 "发布会即上线",比某些 "画饼半年不上线" 的厂商实在多了,手速快的已经开始用它写周报了。
性能实测:真能打过 GPT-5-Chat?
先看权威榜单:LMArena 文本排行榜里,Qwen3-Max 排全球第三,直接把 GPT-5-Chat 挤到第四。编程圈最认的 SWE-Bench Verified 测试里,它拿了 69.6 分,意味着现实中 69.6% 的编程 bug 能靠它解决。我试了个复杂的 Python 数据可视化需求,以前得调半小时的代码,它 1 分钟就出了可运行版本,还贴心加了注释。
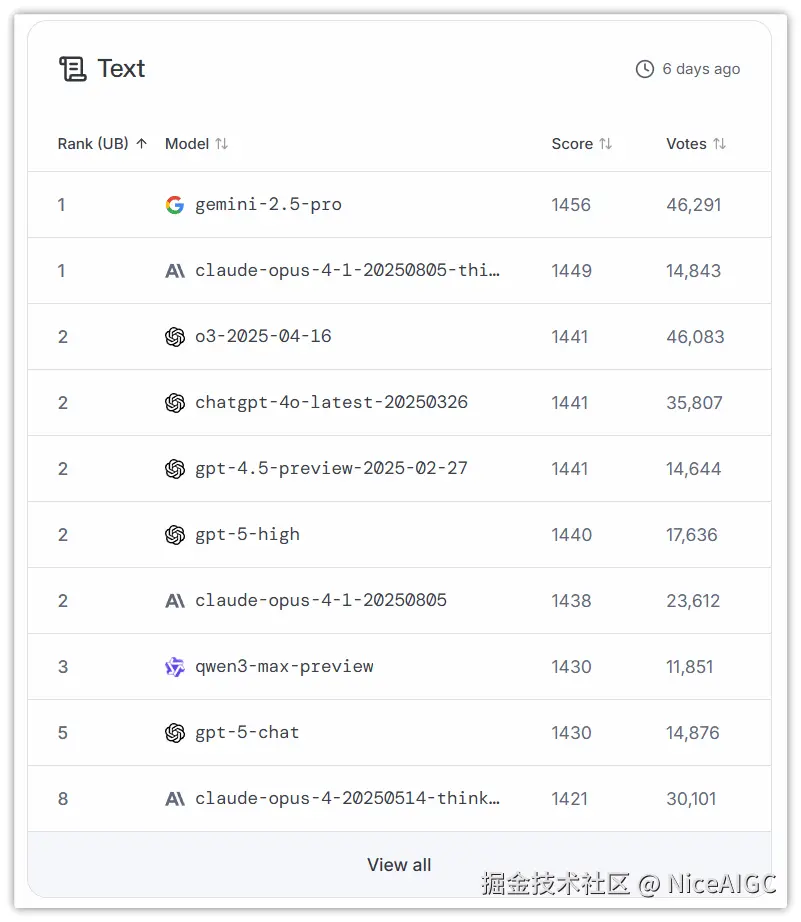
image-20250925153510915
用榜单数据和实测体验说话,不是空喊 "性能强"。简单说,写代码、处理文本这些活儿,它已经是全球第一梯队水平。
价格刺客?不,是阶梯友好型
阿里云百炼的定价表很实在:输入分三档,0-32k token 只要 0.006 元 / 千 token,就算用到 252k 长文本,也才 0.015 元 / 千 token;输出对应 0.024 到 0.06 元 / 千 token。对比上一代 Qwen-Max-0919 的固定价,现在小用量用户能省一大笔,比如写篇 500 字短文,输入输出加起来才几分钱。

image-20250925153610140
小打小闹几乎不花钱,企业批量用也扛得住,比某些 "按次收费" 的模型良心多了。
万亿参数咋练出来的?
Qwen3-Max 用了 MoE 模型结构,还加了 "global-batch load balancing loss" 技术,训练时没出现过 loss 尖刺,一气呵成。更牛的是训练效率:MFU 比上一代高 30%,长序列训练吞吐快 3 倍,硬件故障损失还降了五分之四。简单说,阿里把 "练 AI" 的成本和时间都压下来了。
解释:这些技术词看着唬人,核心就是 "花更少钱、更少时间,练出更强模型"。对用户来说,这意味着后续模型更新会更快,成本也难涨上去。
虽然没正式上线,但团队放了个大招:Qwen3-Max-Thinking 推理增强版,在 AIME 25、HMMT 这些数学基准测试里都拿了满分,甚至达到奥林匹克数学竞赛满分水平。这意味着以后解复杂数学题、做逻辑推理,它可能比学霸还靠谱。
结尾聊两句:你最想用它干啥?
Qwen3-Max 这波发布,既有能立刻上手的 Instruct 版,又有让人期待的 Thinking 版,价格还挺亲民。不管是写代码、处理长文档,还是以后解数学题,好像都能派上用场。