Redis 全面深入解析:从核心原理到高可用架构
一、Redis 全面概述
1.1 什么是 Redis?
Redis(Remote Dictionary Server)是一个开源的、基于内存的键值存储系统,由 Salvatore Sanfilippo 开发。它不仅仅是一个简单的键值存储,更是一个多功能的数据结构服务器,支持字符串、哈希、列表、集合、有序集合等多种数据类型。
1.2 Redis 核心特性
- 内存存储:数据主要存储在内存中,提供极高的读写性能
- 数据持久化:支持 RDB 和 AOF 两种持久化方式
- 丰富的数据类型:支持多种数据结构,适应不同场景需求
- 原子操作:所有操作都是原子性的,支持事务
- 高可用性:通过哨兵模式和集群模式提供高可用解决方案
- 发布/订阅:支持消息发布订阅模式
- Lua 脚本:内置 Lua 脚本引擎,支持执行复杂操作
1.3 Redis 典型应用场景
- 缓存系统:减轻数据库压力,提升系统性能
- 会话缓存:分布式会话存储
- 排行榜系统:利用有序集合实现实时排行
- 消息队列:使用列表实现简单的消息队列
- 社交网络:实现关注列表、粉丝列表等功能
- 实时系统:使用发布订阅实现实时消息推送
二、Redis 核心架构与原理
2.1 单线程模型设计
Q: Redis 为什么采用单线程模型?
Redis 采用单线程模型处理命令请求,主要基于以下考虑:
- 避免上下文切换开销:多线程模型的上下文切换会消耗大量 CPU 资源
- 避免锁竞争:单线程模型天然避免了多线程环境下的锁竞争问题
- 内存操作瓶颈:Redis 的性能瓶颈主要在内存访问和网络 I/O,而非 CPU
- 简单可靠:单线程模型使代码更简单,更容易维护和调试
cs
// 简化的 Redis 事件循环伪代码
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 处理时间事件(如定时任务)
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 处理文件事件(如网络请求)
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}2.2 I/O 多路复用机制
Redis 使用 I/O 多路复用技术来处理大量客户端连接,支持 select、epoll、kqueue 等多种实现:
cs
// 简化的 Redis 事件循环伪代码
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 处理时间事件(如定时任务)
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 处理文件事件(如网络请求)
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}2.3 内存管理机制
Redis 使用自己的内存分配器 jemalloc,并实现了复杂的内存管理策略:
- 内存淘汰策略:当内存不足时,根据配置的策略淘汰数据
- 内存碎片整理:通过 active defragmentation 机制减少内存碎片
- 对象共享:对于小整数等常用对象,使用对象共享减少内存使用
三、Redis 数据结构深度解析
3.1 字符串(String)
底层实现:
- 使用简单动态字符串(SDS)实现
- SDS 结构包含长度信息和预分配空间
cpp
struct sdshdr {
int len; // 已使用长度
int free; // 未使用长度
char buf[]; // 字节数组
};优势:
- O(1) 时间复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少内存重分配次数
- 二进制安全
3.2 列表(List)
底层实现:
- 3.2 版本前:使用 ziplist 或 linkedlist
- 3.2 版本后:统一使用 quicklist
cpp
// quicklist 结构
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // 元素总数
unsigned long len; // quicklistNode 数量
int fill : 16; // ziplist 大小限制
unsigned int compress : 16; // 压缩深度
} quicklist;3.3 哈希(Hash)
底层实现:
- 元素较少时使用 ziplist
- 元素较多时使用 hashtable
配置参数:
bash
hash-max-ziplist-entries 512 # 哈希元素数量阈值
hash-max-ziplist-value 64 # 哈希元素值大小阈值3.4 集合(Set)
底层实现:
- 元素为整数且数量较少时:intset
- 其他情况:hashtable
3.5 有序集合(ZSet)
底层实现:
- 使用跳跃表(skiplist)和哈希表共同实现
- 跳跃表用于支持范围操作
- 哈希表用于支持 O(1) 复杂度的单个元素查询
cs
// 跳跃表节点结构
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;四、Redis 持久化机制详解
4.1 RDB 持久化

工作原理: RDB 通过创建数据快照来实现持久化,有两种触发方式:
- 手动触发:执行 SAVE 或 BGSAVE 命令
- 自动触发:根据配置文件中的保存条件自动触发
配置示例:
bash
save 900 1 # 900秒内至少有1个key发生变化
save 300 10 # 300秒内至少有10个key发生变化
save 60 10000 # 60秒内至少有10000个key发生变化RDB执行原理
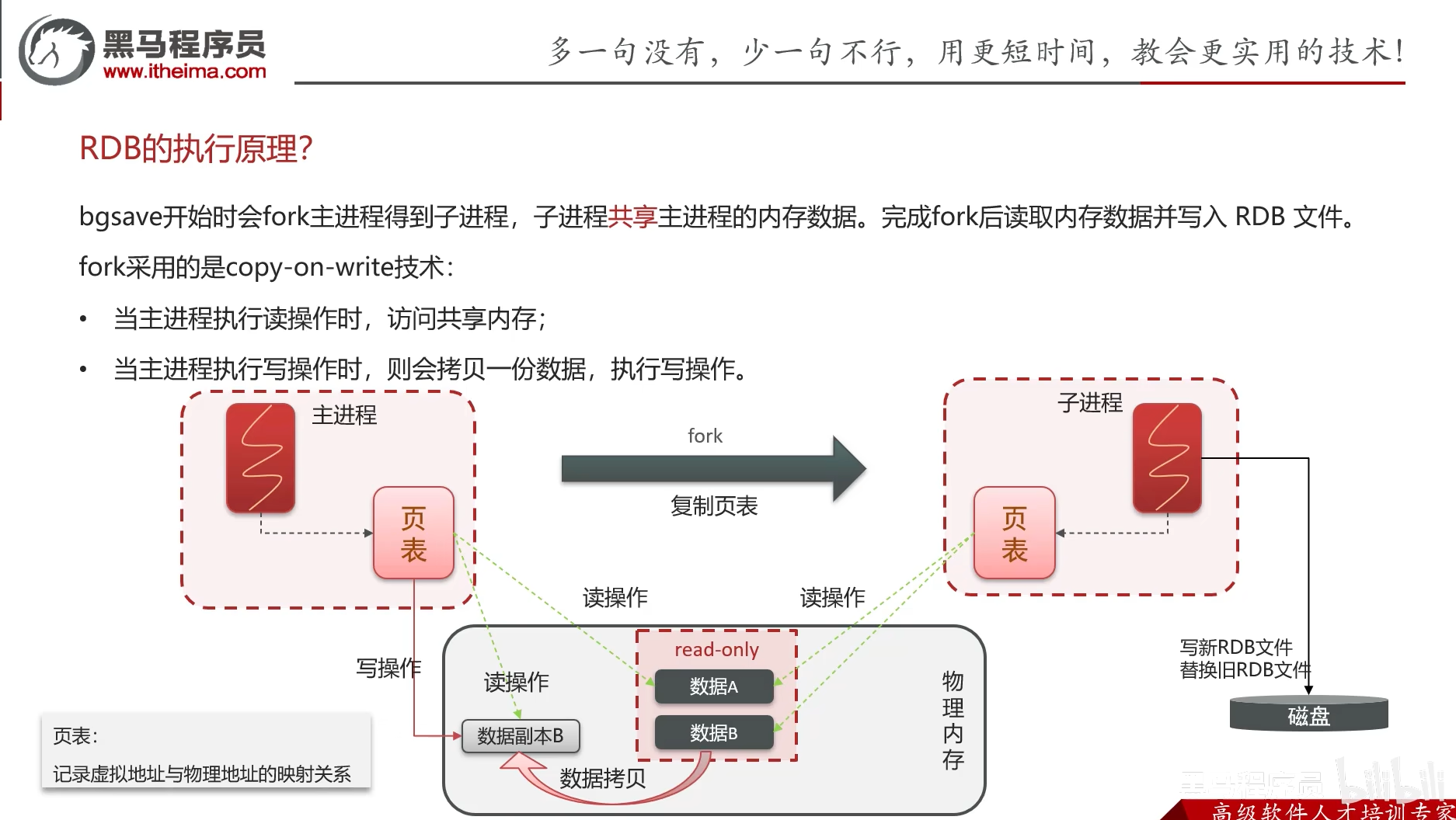
优缺点分析:

-
优点:
- 文件紧凑,适合备份和灾难恢复
- 恢复大数据集时速度比 AOF 快
- 最大化 Redis 性能(fork 子进程处理)
-
缺点:
- 可能丢失最后一次快照后的数据
- 大数据集时 fork 操作可能造成服务短暂停顿
4.2 AOF 持久化

工作原理: AOF 通过记录每个写操作命令来实现持久化,支持三种同步策略:
- always:每个写命令都同步到磁盘,最安全但性能最低
- everysec:每秒同步一次,平衡安全性和性能(默认配置)
- no:由操作系统决定同步时机,性能最好但最不安全
AOF 重写机制: 为了解决 AOF 文件不断增大的问题,Redis 提供了 AOF 重写机制:

- 创建一个新的 AOF 文件,包含重建当前数据集所需的最小命令集合
- 使用后台进程进行重写,不影响主进程处理请求
配置示例:
bash
appendonly yes # 开启 AOF
appendfilename "appendonly.aof" # AOF 文件名
appendfsync everysec # 同步策略
auto-aof-rewrite-percentage 100 # 文件增长比例阈值
auto-aof-rewrite-min-size 64mb # 文件大小阈值4.3 混合持久化(Redis 4.0+)
Redis 4.0 引入了混合持久化方式,结合了 RDB 和 AOF 的优点:
bash
aof-use-rdb-preamble yes # 开启混合持久化工作流程:
- 定期生成 RDB 快照并写入 AOF 文件
- 后续的写操作命令以 AOF 格式追加到文件
- 重启时先加载 RDB 部分,再重放 AOF 命令
五、Redis 高可用与集群
5.1 主从复制
复制原理:
- 建立连接:从节点连接到主节点,发送 SYNC 命令
- 生成 RDB:主节点执行 BGSAVE 生成 RDB 文件
- 传输 RDB:主节点将 RDB 文件发送给从节点
- 加载 RDB:从节点清空数据,加载 RDB 文件
- 命令传播:主节点将后续的写命令发送给从节点
复制配置:
bash
# 在从节点配置
replicaof <masterip> <masterport>
masterauth <password> # 如果主节点有密码5.2 哨兵模式(Sentinel)
哨兵功能:
- 监控:检查主从节点是否正常运行
- 通知:通过 API 向管理员或其他程序发送故障通知
- 自动故障转移:主节点故障时,自动将从节点升级为主节点
- 配置提供者:客户端连接时提供当前主节点信息
哨兵配置:
bash
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1故障转移流程:
- 多个哨兵确认主节点下线
- 选举领头哨兵
- 领头哨兵执行故障转移
- 选择新的主节点
- 通知其他从节点切换主节点
- 更新配置并通知客户端
5.3 集群模式(Cluster)
数据分片: Redis 集群使用哈希槽(hash slot)进行数据分片:
- 总共 16384 个哈希槽
- 每个键通过 CRC16 校验后对 16384 取模决定所属槽位
- 每个节点负责一部分哈希槽
集群节点通信: 使用 Gossip 协议进行节点间通信:
- 每个节点维护集群元数据
- 通过 PING/PONG 消息交换信息
- 自动检测节点故障和恢复
集群配置:
bash
# 节点配置
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
cluster-require-full-coverage no
# 创建集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1六、Redis 高级特性与优化
6.1 事务处理
Redis 事务通过 MULTI、EXEC、DISCARD 和 WATCH 命令实现:
bash
WATCH key1 key2 # 监视键
MULTI # 开始事务
SET key1 value1 # 命令入队
SET key2 value2 # 命令入队
EXEC # 执行事务事务特性:
- 原子性:事务中的命令要么全部执行,要么全部不执行
- 隔离性:事务执行过程中不会被其他客户端命令打断
- 不支持回滚:Redis 事务执行失败后不会回滚
6.2 Lua 脚本
Redis 内置 Lua 脚本引擎,支持执行复杂操作:
Lua
-- 限流脚本示例
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local expire_time = tonumber(ARGV[2])
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then
return 0
else
redis.call('INCR', key)
redis.call('EXPIRE', key, expire_time)
return 1
end脚本优势:
- 减少网络开销:多个操作在一个脚本中执行
- 原子性:脚本执行期间不会执行其他命令
- 复用性:脚本可以被缓存和重复使用
6.3 管道技术(Pipeline)
管道技术用于批量执行命令,减少网络往返时间:
python
# Python 示例
pipe = redis_client.pipeline()
for i in range(1000):
pipe.set(f'key:{i}', f'value:{i}')
pipe.execute()6.4 内存优化策略
优化技巧:
- 使用适当的数据类型:根据场景选择最节省内存的数据结构
- 使用哈希分片:对大哈希进行分片存储
- 使用整数集合:当集合元素都是整数时使用 intset
- 配置合理的内存淘汰策略:
惰性删除和定期删除:


如何配置淘汰策略
在Redis配置文件redis.conf中,可以通过maxmemory-policy参数设置淘汰策略,例如:
maxmemory-policy allkeys-lru也可以通过运行时命令动态修改:
bash
CONFIG SET maxmemory-policy volatile-lfu数据淘汰策略
数据的淘汰策略:当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
Redis支持8种不同策略来选择要删除的key:
unoeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
uvolatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
uallkeys-random:对全体key ,随机进行淘汰。
uvolatile-random:对设置了TTL的key ,随机进行淘汰。
uallkeys-lru: 对全体key,基于LRU算法进行淘汰
uvolatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
uallkeys-lfu: 对全体key,基于LFU算法进行淘汰
uvolatile-lfu: 对设置了TTL的key,基于LFU算法进行淘汰
策略选择建议
LRU(Least Recently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU(Least Frequently Used)最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。

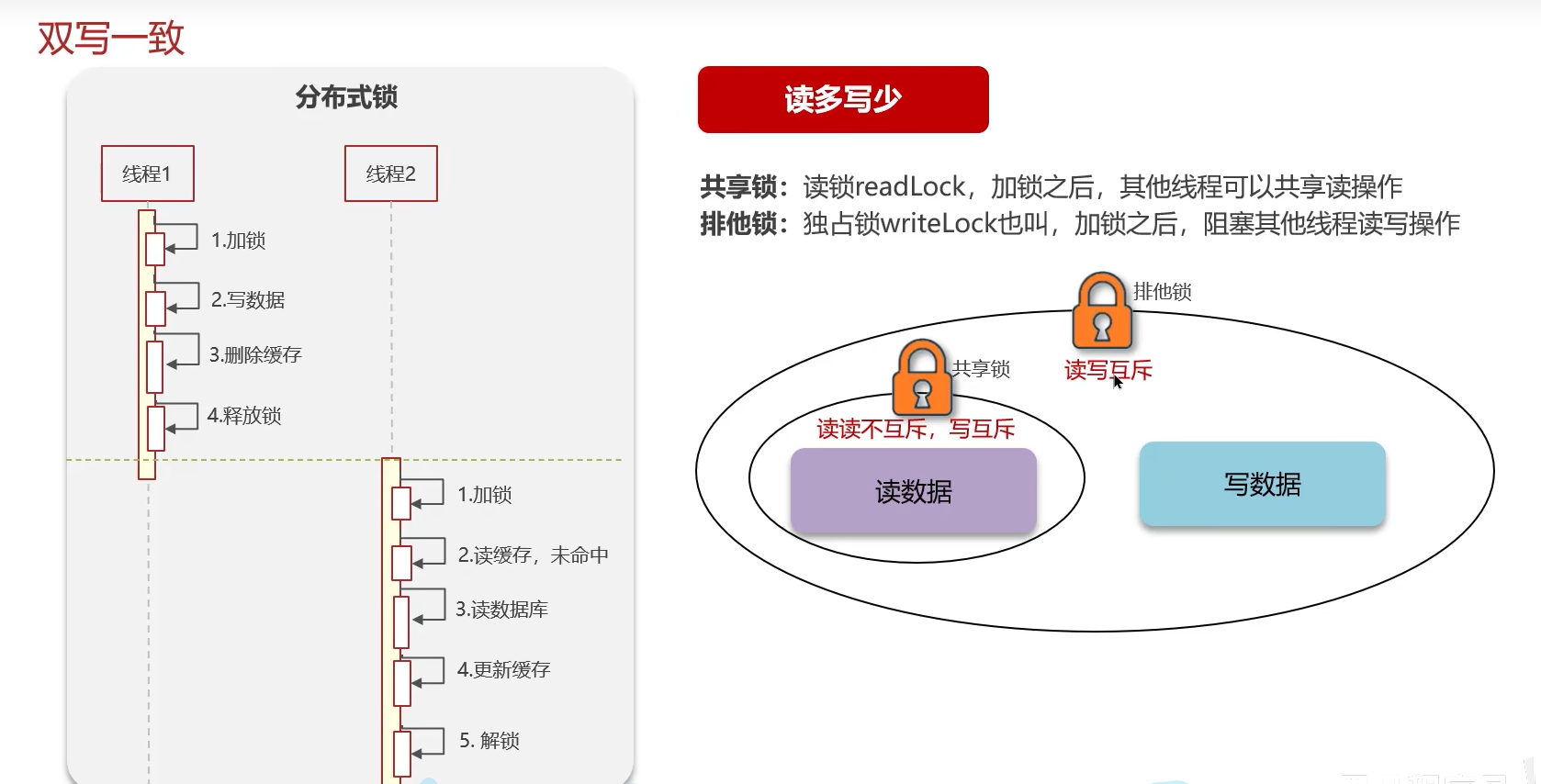
6.5 分布式锁
1、redis分布式锁,是如何实现的?
l我们当使用的redisson实现的分布式锁,底层是setnx和lua脚本(保证原子性)
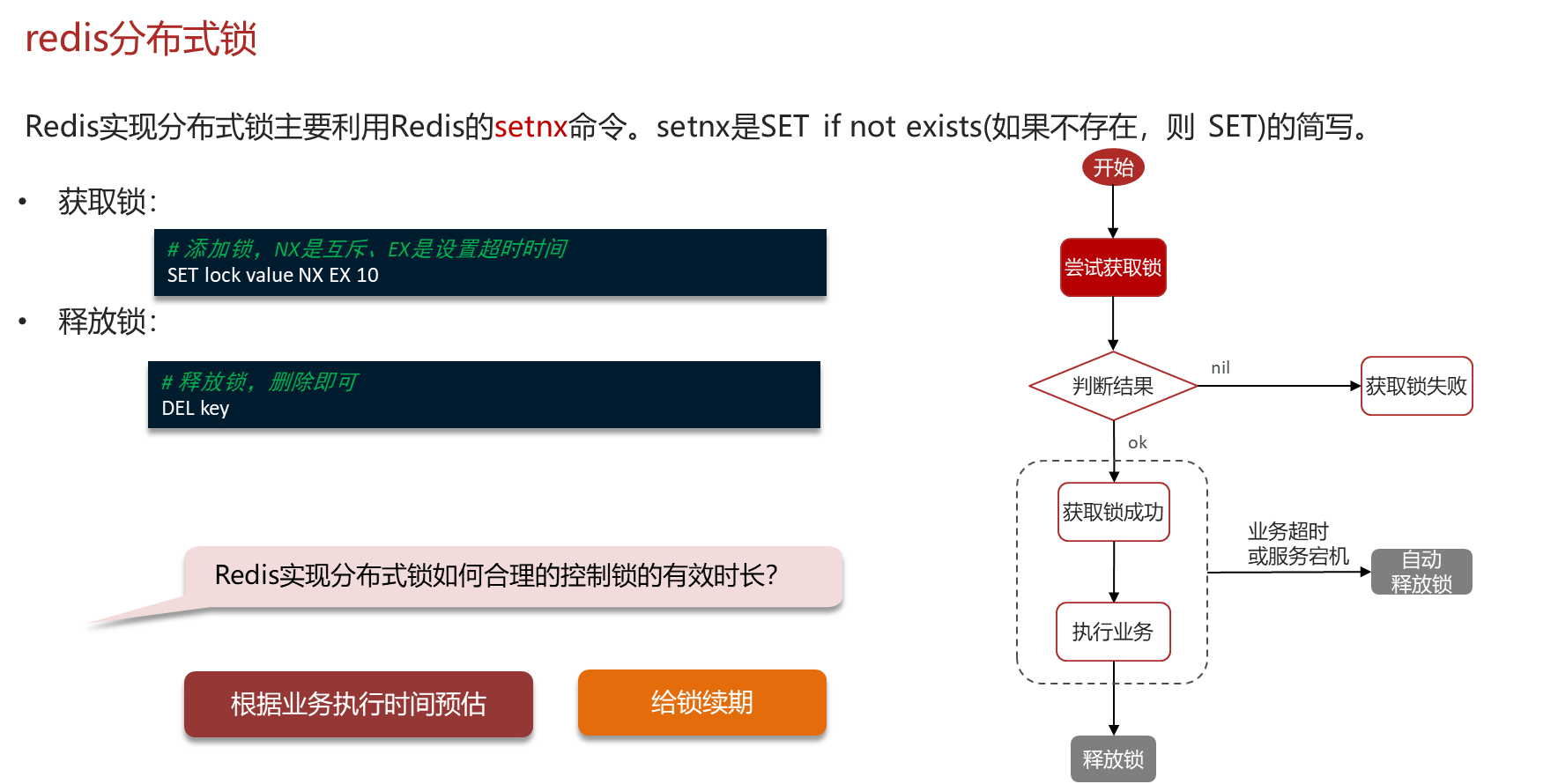
2、Redisson实现分布式锁如何合理的控制锁的有效时长?
在redisson的分布式锁中,提供了一个WatchDog(看门狗),一个线程获取锁成功以后, WatchDog会给持有锁的线程续期(默认是每隔10秒续期一次)
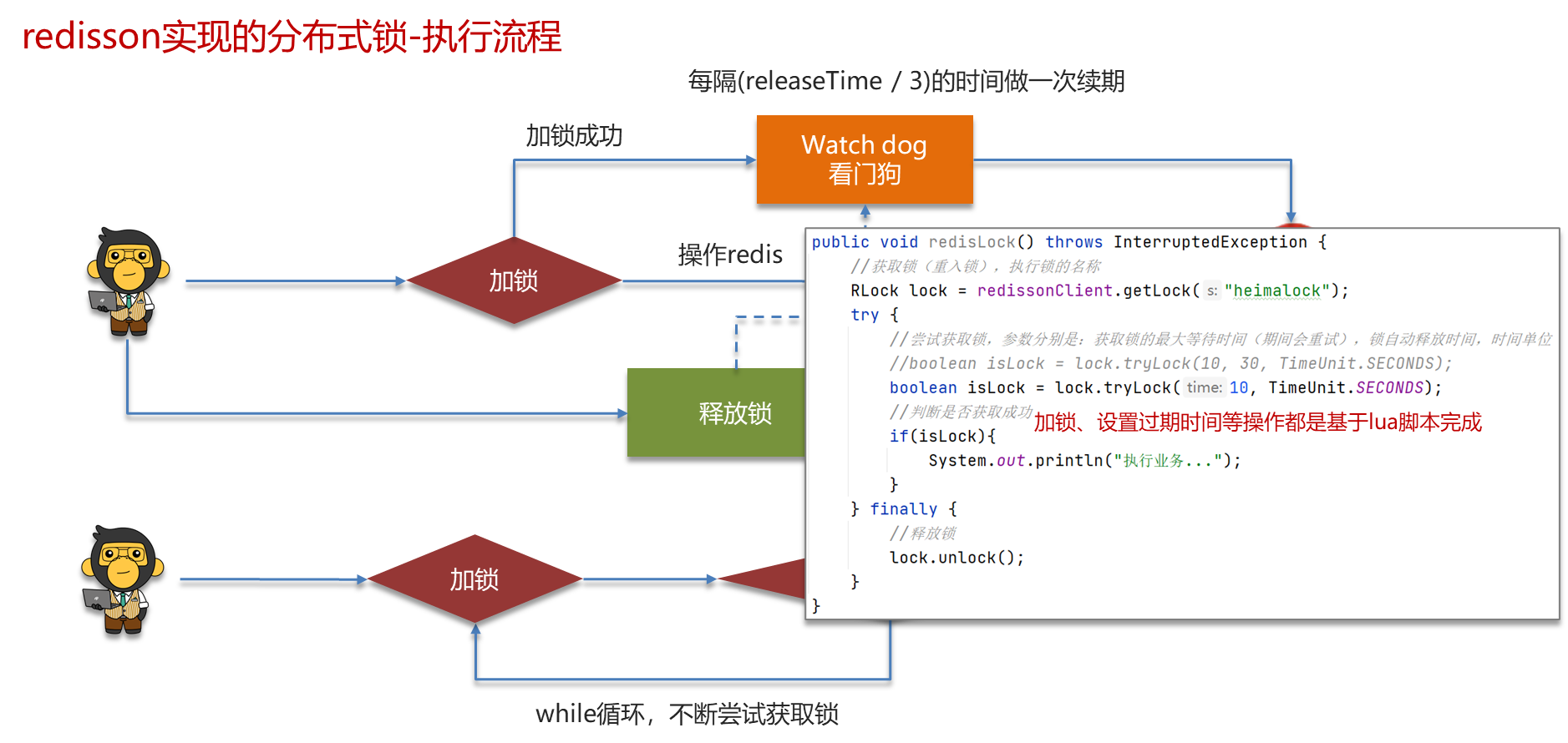
3、Redisson的这个锁,可以重入吗?
可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用的hash结构,来存储线程信息和重入的次数

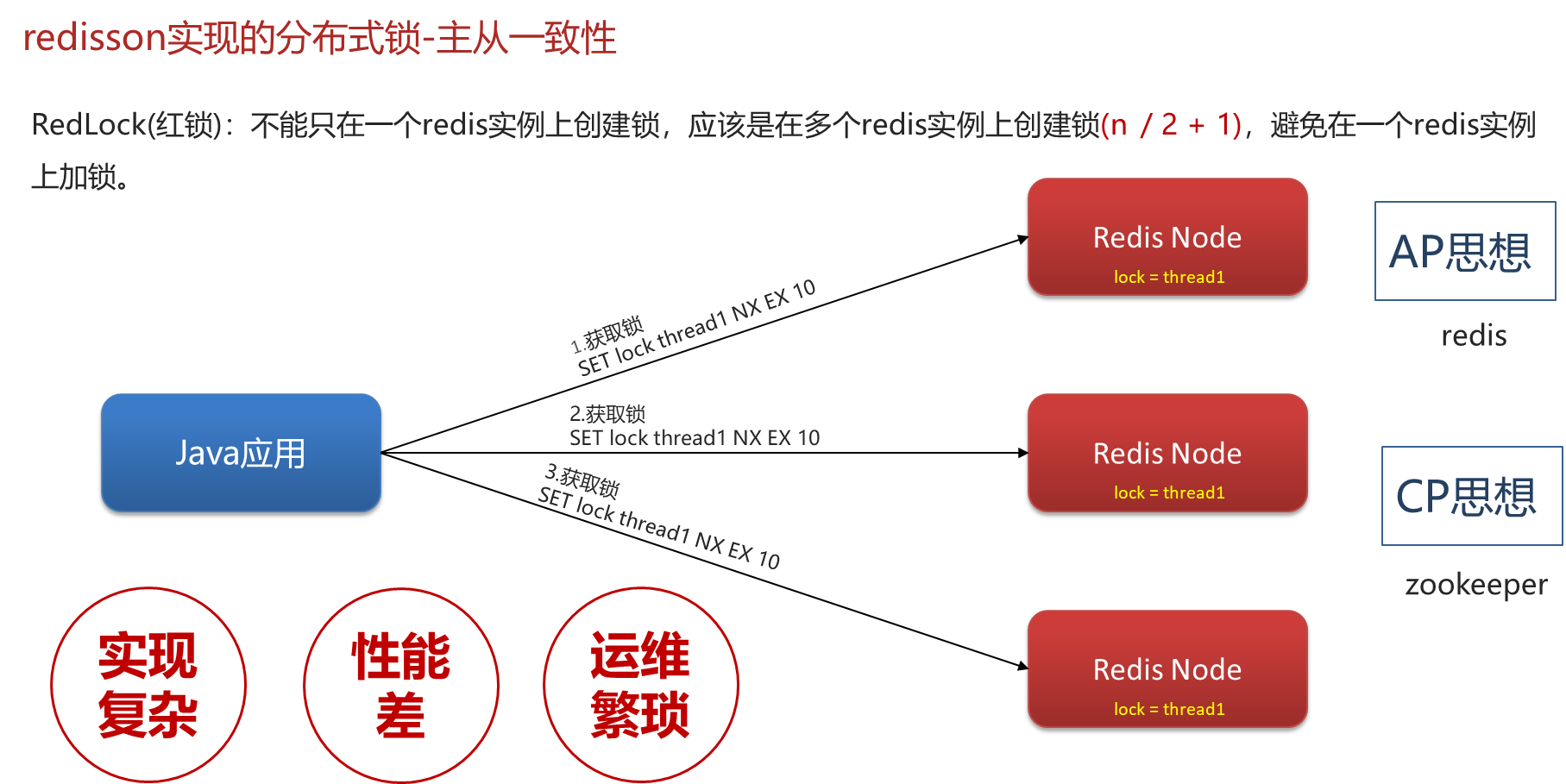
4、Redisson锁能解决主从数据一致的问题吗
不能解决,但是可以使用redisson提供的红锁来解决,但是这样的话,性能就太低了,如果业务中非要保证数据的强一致性,建议采用zookeeper实现的分布式锁
七、Redis 常见问题与解决方案
7.1 缓存穿透
问题描述:大量请求查询不存在的数据,导致请求直接打到数据库
解决方案:
- 缓存空值:对查询结果为空的情况也进行缓存
- 布隆过滤器:在缓存前增加布隆过滤器层
java
// 布隆过滤器示例
public class BloomFilter {
private BitSet bitSet;
private int size;
private HashFunction[] hashFunctions;
public boolean mightContain(String key) {
for (HashFunction func : hashFunctions) {
if (!bitSet.get(func.hash(key) % size)) {
return false;
}
}
return true;
}
}7.2 缓存击穿
问题描述:热点 key 过期时大量请求直接访问数据库
解决方案:
- 永不过期(逻辑过期):对极热点数据设置永不过期
- 互斥锁:使用分布式锁保证只有一个线程重建缓存
java
# 使用 SETNX 实现分布式锁
SET lock_key unique_value NX PX 300007.3 缓存雪崩
问题描述:大量 key 同时过期,导致所有请求直接访问数据库
解决方案:
- 随机过期时间:给缓存过期时间加上随机值
- 二级缓存:使用本地缓存 + Redis 缓存的多级缓存架构
- 高可用架构:使用 Redis 集群保证服务可用性
7.4 数据一致性
保证策略:
- 先更新数据库,再删除缓存(延迟双删)
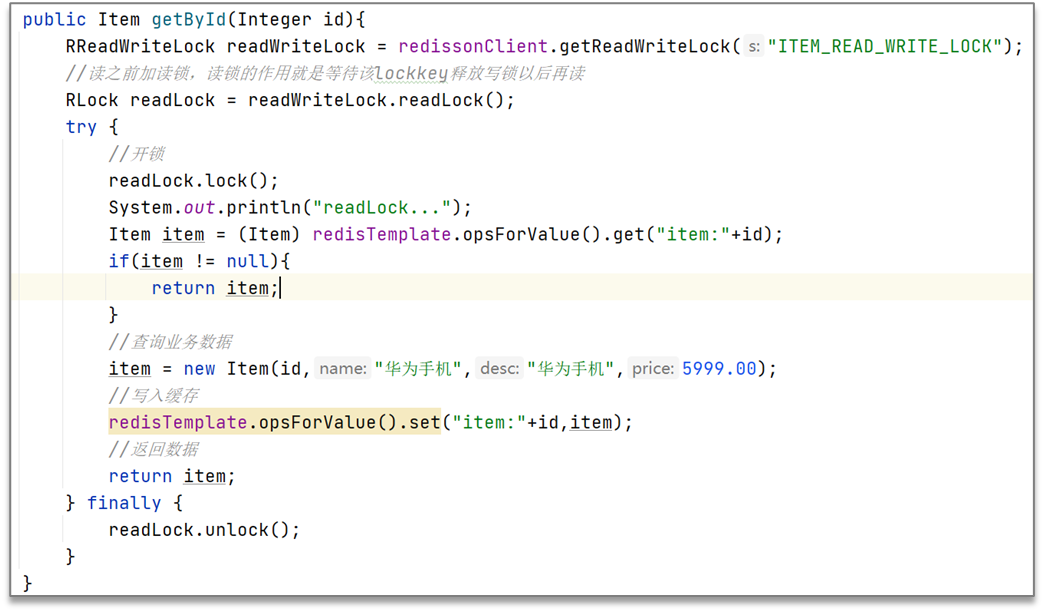
读之前添加读锁
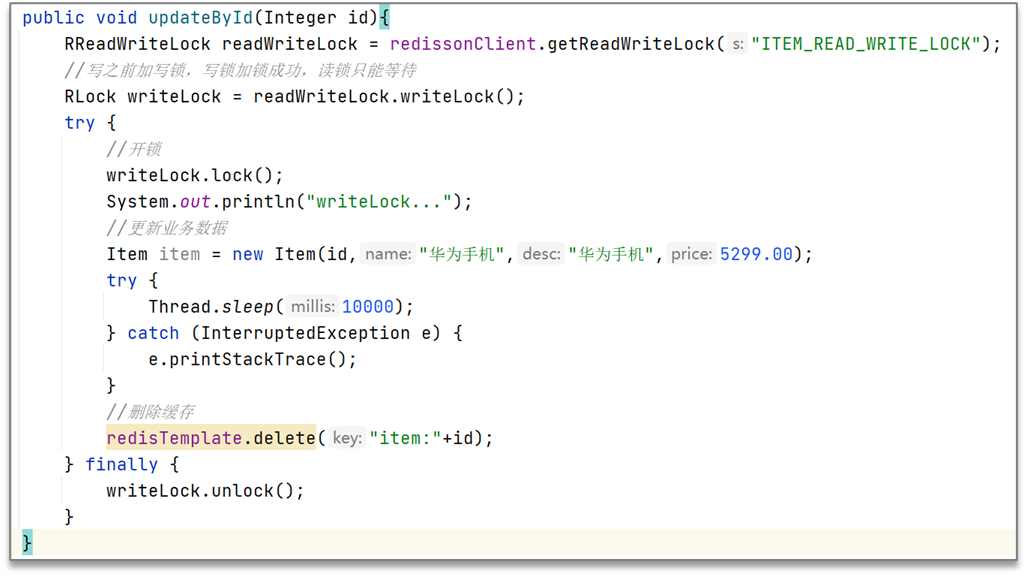
写之前加写锁
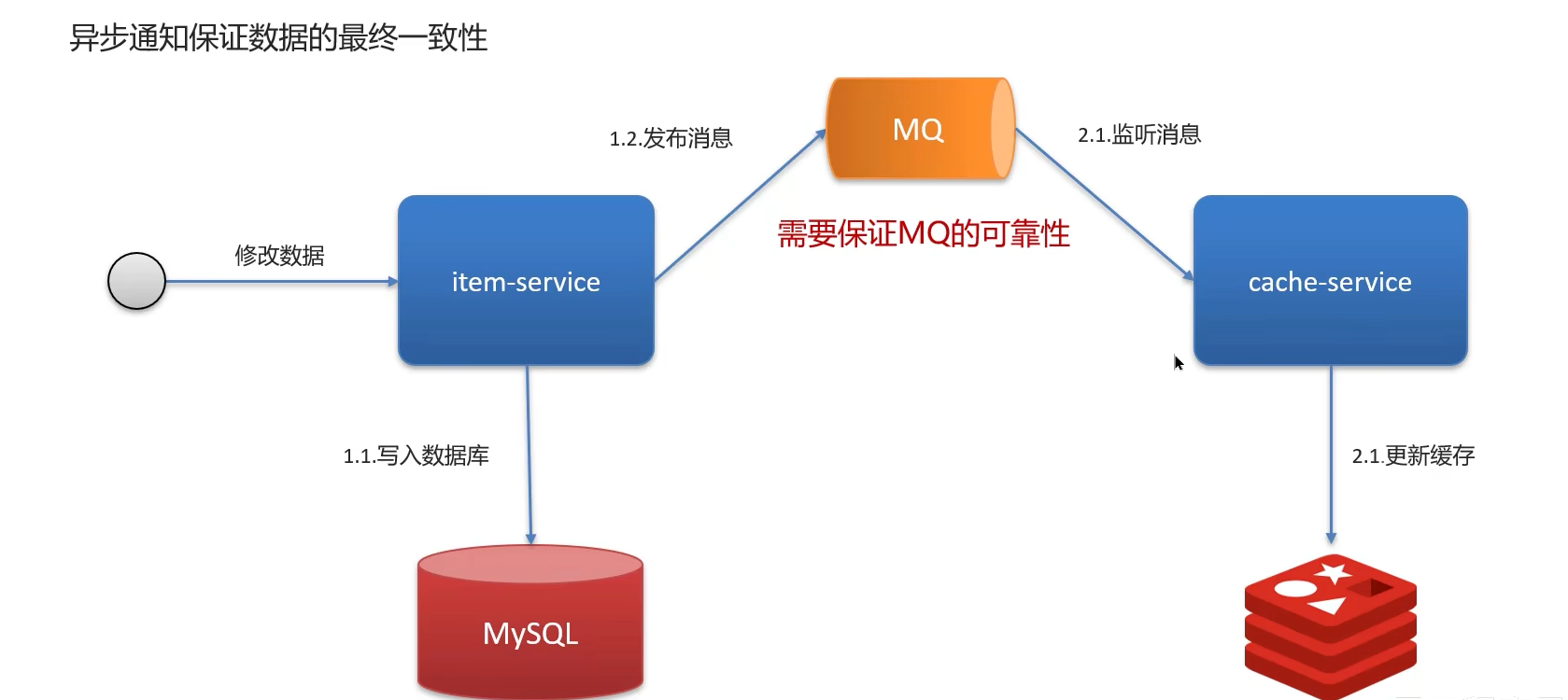
2、使用消息队列确保最终一致性
3、使用 Canal 等工具监听数据库变更
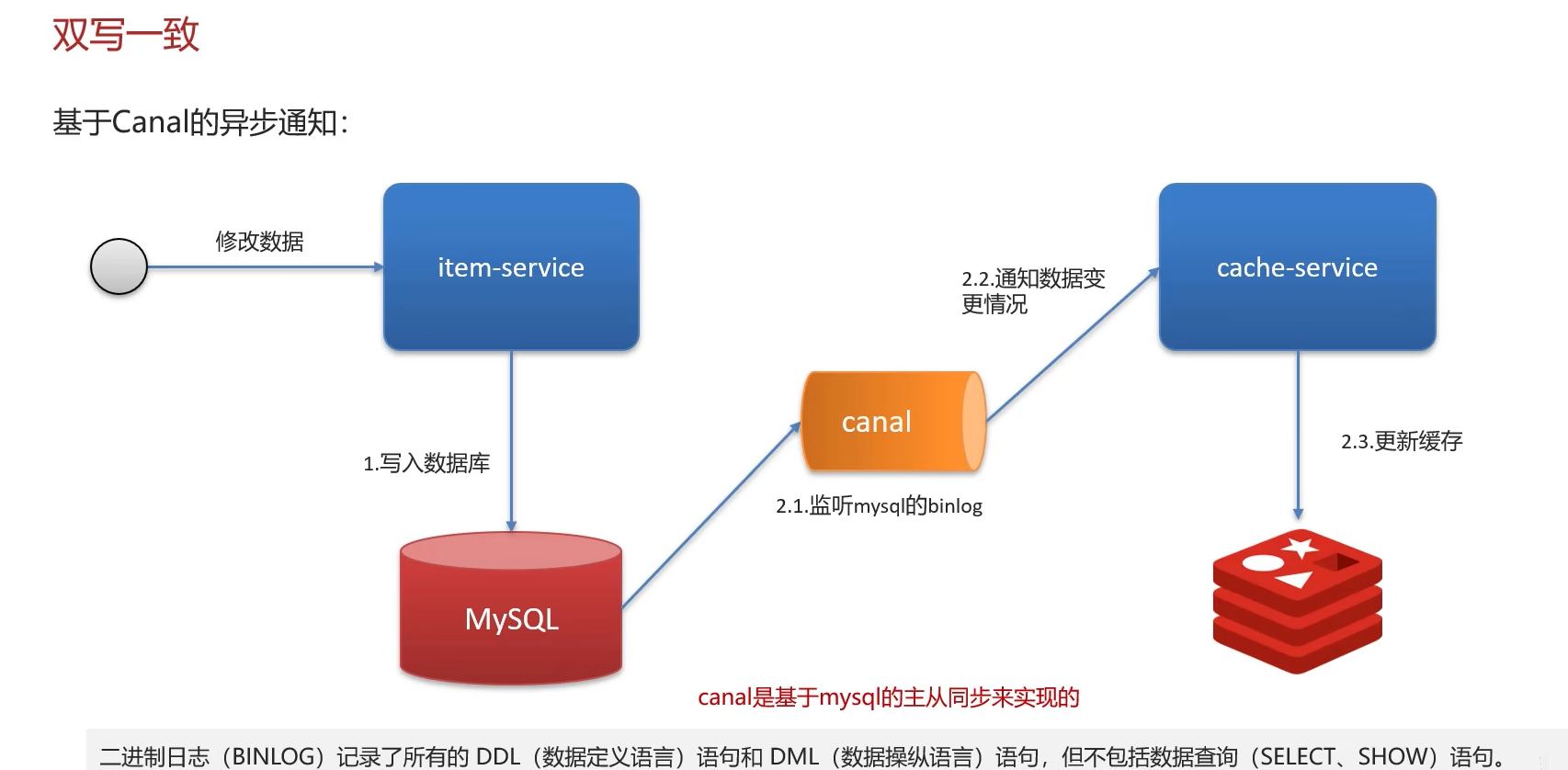
总结
允许延时一致的业务,采用异步通知
①使用MQ中间中间件,更新数据之后,通知缓存删除
②利用canal中间件,不需要修改业务代码,伪装为mysql的一个从节点,canal通过读取binlog数据更新缓存
强一致性的,采用Redisson提供的读写锁
①共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
②排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作
八、Redis 监控与运维
8.1 监控指标
关键监控指标:
- 内存使用情况:used_memory、used_memory_rss
- 命令统计:ops_per_sec、instantaneous_ops_per_sec
- 客户端连接数:connected_clients
- 持久化状态:rdb_last_save_time、aof_current_size
- 复制状态:master_link_status、master_sync_in_progress
8.2 常用运维命令
bash
# 查看服务器信息
INFO
# 查看内存使用情况
INFO memory
# 查看持久化信息
INFO persistence
# 查看复制信息
INFO replication
# 查看客户端连接
CLIENT LIST
# 慢查询日志
SLOWLOG GET 108.3 性能优化建议
- 合理配置最大内存:避免内存交换影响性能
- 使用连接池:减少连接建立开销
- 批量操作:使用 pipeline 或 mget/mset
- 避免大键:单个键的值不宜过大
- 合理配置持久化策略:根据业务需求选择 RDB 或 AOF
九、Redis 与其他技术对比
9.1 Redis vs Memcached
| 特性 | Redis | Memcached |
|---|---|---|
| 数据类型 | 丰富的数据结构 | 仅字符串 |
| 持久化 | 支持 | 不支持 |
| 复制 | 支持 | 不支持 |
| 事务 | 支持 | 不支持 |
| 内存模型 | 多种淘汰策略 | LRU |
9.2 Redis vs MongoDB
| 特性 | Redis | MongoDB |
|---|---|---|
| 数据模型 | 键值对 | 文档型 |
| 查询能力 | 简单 | 丰富 |
| 持久化 | 可选 | 内置 |
| 扩展性 | 水平扩展 | 水平扩展 |
| 适用场景 | 缓存、队列 | 主数据库 |
十、Redis 最佳实践
10.1 键命名规范
bash
# 使用冒号分隔的层次结构
user:123:profile
order:456:items
article:789:comments
# 避免过长的键名
# 错误:this_is_a_very_long_redis_key_name_that_should_be_avoided
# 正确:short:key:name10.2 连接池配置
java
// Jedis 连接池配置示例
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100); // 最大连接数
config.setMaxIdle(20); // 最大空闲连接数
config.setMinIdle(5); // 最小空闲连接数
config.setMaxWaitMillis(1000); // 获取连接时的最大等待时间
config.setTestOnBorrow(true); // 在获取连接的时候检查连接有效性
JedisPool pool = new JedisPool(config, "localhost", 6379);10.3 安全配置
java
# 设置密码认证
requirepass your_strong_password
# 重命名危险命令
rename-command FLUSHALL ""
rename-command CONFIG ""
# 绑定特定 IP
bind 127.0.0.1
# 启用保护模式
protected-mode yes本文全面深入地介绍了 Redis 的各个方面,从基础概念到高级特性,从核心原理到实践应用。掌握这些知识将帮助您在 Redis 相关面试和实际工作中游刃有余。建议结合实际项目经验,深入理解每个概念的实际应用场景。