背景
系统里有两个服务,使用Netty构建的http服务,主要用来处理物联网设备的上下行数据的处理,没有任何业务逻辑的处理,也没有任何和数据库的交互等。但是有两个问题一直存在着,一个是系统运行一段时间后,可能是3个月或者半年(因为是一个类似数据通道的服务,所以基本没有改动的需求),服务就会出现OOM. 二是重启之后,过一段时间系统创建的线程会慢慢增高且不会释放
系统OOM

可以看到是因为无法再创建线程而导致JVM抛出****OOM ,常见的OOM报错有
arduino
Java heap space(堆内存溢出)- 这是最常见的OOM类型
原因:堆内存不足,无法容纳更多对象
通常由内存泄漏或创建过大对象引起
PermGen space(永久代溢出)- 在Java 8之前常见
原因:永久代(存储类元数据)空间不足
在Java 8中已被Metaspace取代
Metaspace(元空间溢出)- Java 8及以后版本中替代PermGen
原因:元空间(存储类元数据)空间不足
可以通过-XX:MaxMetaspaceSize调整
StackOverflowError(栈溢出)
原因:线程栈空间不足,通常由无限递归引起
不是OOM异常,但与内存相关
Direct buffer memory(直接缓冲区内存溢出)
原因:直接内存(堆外内存)不足
可以通过-XX:MaxDirectMemorySize调整
GC overhead limit exceeded(GC开销超过限制)
原因:GC花费过多时间回收内存,但回收效果不佳
Unable to create new native thread(无法创建新本地线程)
原因:系统级线程创建受限,可能是系统资源不足
Out of memory(一般性内存溢出)- 系统创建大量线程并一直居高不下
系统重启一段时间后,会发现服务创建了大量的线程并且线程一直维持在一个很高的水位,且没有减少的倾向

综合上面1.1 和 1.2 中的信息,所有的现象都指向服务创建了大量线程,且如果发生JVM OOM, 也是因为创建大量线程而导致OOM(并不是内存不够的问题)。 最后可以得出初步可能的结论: 这两个服务可能存在线程资源泄露的问题,导致创建的线程资源无法被回收,同时也存在内存泄露 (持有锁(ReentrantLock)的线程因为某种原因永远无法释放锁,那么所有等待这个锁的线程将永远阻塞,它们引用的 ReentrantLock 锁对象也将永远无法被回收,从而导致内存泄漏)
一处非常可疑的地方
系统在启动类启动的过程中会创建一个全局的线程池,线上的服务都是走的else中的逻辑,也就是创建一个cached类型的线程池,使用这种线程池的原因,主要有几方面的原因,主要是为了能及时处理物联网设备下发的指令。但其实这种方式也隐藏了一个极大的风险,就是当系统某个时刻有大量的物联网设备需要下发指令或者有上行时,会瞬间创建大量的线程,可能会让服务瘫痪。不过目前还没有遇到这种问题,但是仔细想了下,cached类型线程池中线程的存活时间是60s 之后就会回收,而系统不会24小时有大量的设备进行操作的,所以不可能线程只增长不减少的,所以应该还是存在某处线程泄露的问题。需要继续深入排查

排查
排查方向
因为是线程相关的问题,且正在运行的服务并没有内存溢出等方面的紧急问题,优先通过jstack pid来查看服务的线程堆栈,看看服务的线程的状态
方式
- 通过在不同的时间点对其中一个服务(此服务线程创建最多-一直居高不下) 服务执行jstack dump其线程堆栈进行分析
- 分别在不同的date 每隔10s , 以及每隔30s 进行jstack dump线程堆栈
过程分析
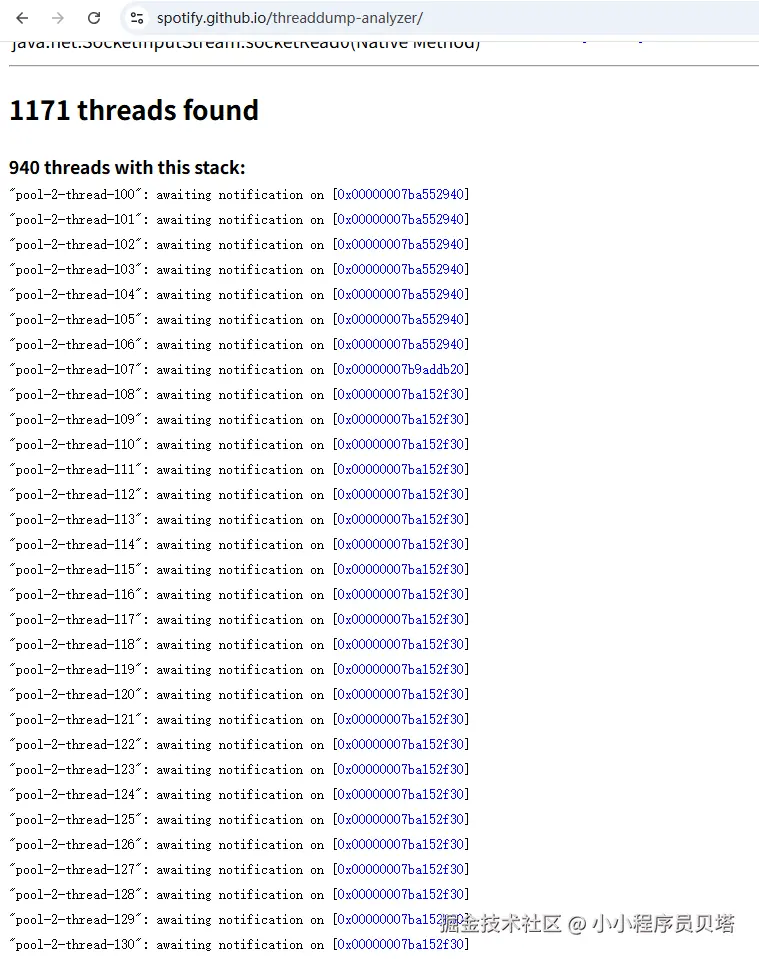
可以看到基本上服务创建的总线程数在5200左右,而其中就有4500+的线程是一直阻塞的状态
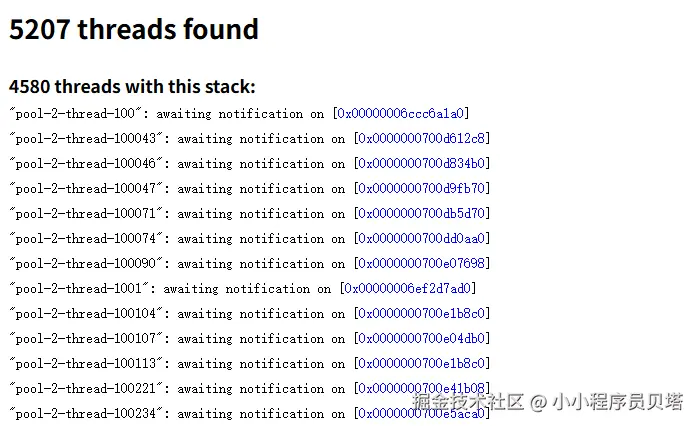
抽取其中一批阻塞线程,对比不同时间点时线程状态,通过对比 -- jstack 在线分析工具
其中某一天某个时刻
4580个阻塞线程中的143个线程等待在同一个锁对象上,这是阻塞在一个对象上最多的一组线程,下文都是以这个锁对象和阻塞的线程组为例进行分析的
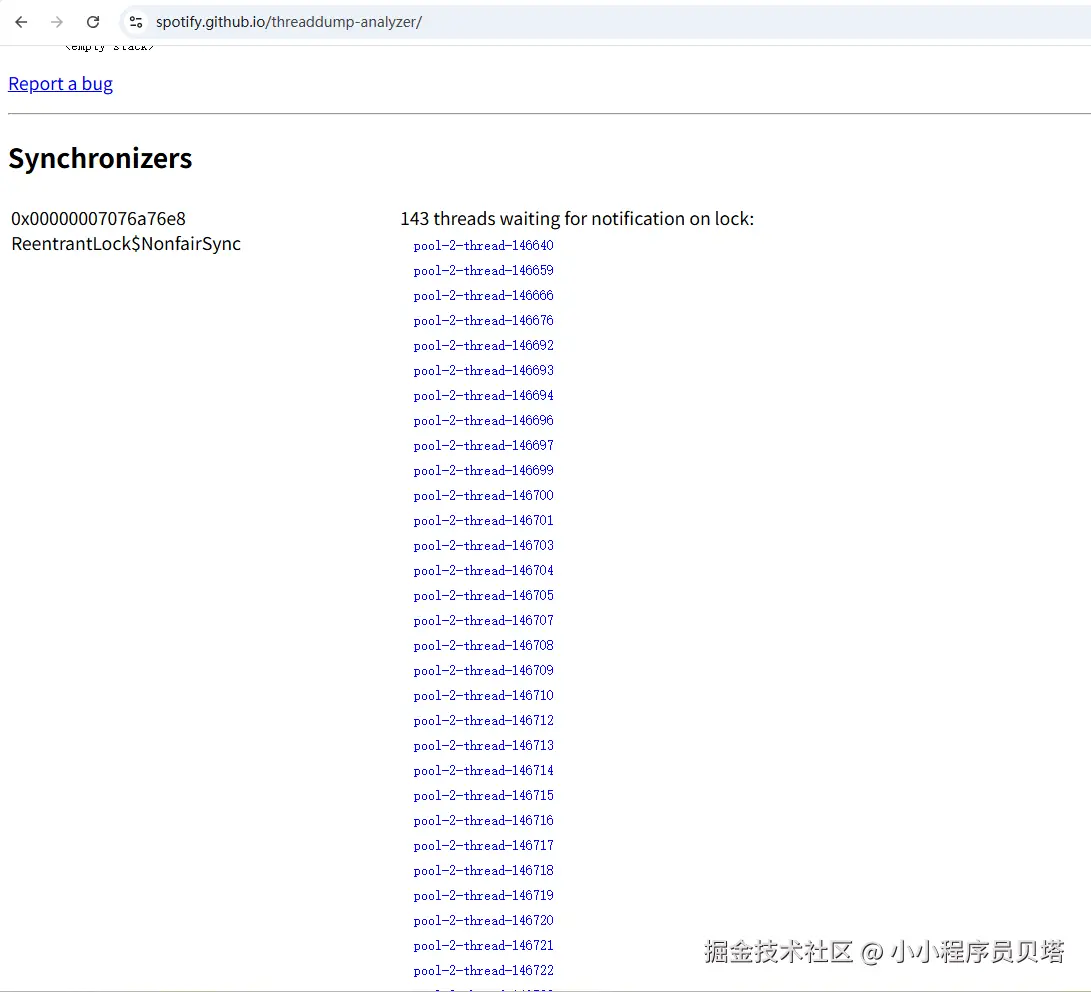
另外一天的某个时间点

两个时间点之间隔了几天,但是发现这143个线程一模一样(线程name是唯一的,说明至少在这几天里这些线程一直是处于等待存活状态) ,也就是一直waiting 在一个锁对象上,而且这些线程一直没变,唯一变化的就是获取锁的对象(为什么等待的锁对象地址发生了变化,见下面的疑问解答)
线程的堆栈如下:
php
"pool-2-thread-146841" #48580367 prio=5 os_prio=0 tid=0x00007ff4ac0a4800 nid=0x3107 waiting on condition [0x00007ff352b9b000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007076a76e8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at com.ph.ph.Gateway.execute(GateWay.java:184)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
php
"pool-2-thread-146841" #48580367 prio=5 os_prio=0 tid=0x00007ff4ac0a4800 nid=0x3107 waiting on condition [0x00007ff352b9b000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007076669c0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at com.ph.ph.Gateway.execute(GateWay.java:184)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750) 线程都是因为走到了 com.ph.ph.Gateway.execute(GateWay.java:184) 方法 而导致的阻塞, 查看这个服务这个代码的地方, 发现 com.ph.ph.Gateway.execute(GateWay.java:184) 的实现中有bug,会导致在并发场景下,线程死锁进而导致线程资源泄漏和内存泄漏的问题
kotlin
## DeviceContext 通过继承ReentrantLock 拥有了锁的能力
@Override
public boolean executeCmd(DeviceContext dtx) {
if (dtx== null) {
return false;
}
// dtx.lock 先获取锁
dtx.lock();
// 此处如果提前返回,则会导致获取到的锁,无法被释放
if (dtx.getCurrentCmd() != null) {
return true;
}
Command cmd = Dep.ApiService.getCmd(dtx);
String deviceCode = dtx.getDeviceCode();
// 此处如果提前返回,则会导致获取到的锁,无法被释放
if (cmd == null) {
//...... 发送ack的逻辑
return true;
}
// 此处如果提前返回,则会导致获取到的锁,无法被释放
if (!dtx.isOnline()) {
log.error( "设备[{}]不在线,下发命令失败" , meterCode);
return false;
}
try {
//.................. 其他逻辑
return true;
} catch (Exception e) {
log.error( "设备[" + meterCode + "]-下发命令出错: " , e);
return this.updateAndSendNextCmd(dtx, cmd, Constant.CMD_STATUS_FAILED);
} finally {
dtx.unlock();
}
}可以看到 dtx.lock(); 之后,有多处提前返回的地方,会导致对MeterContext获取到的锁没有被释放,而线程就退出了,导致后续所有在同一个 DeviceContext 实例上需要下发命令的线程都无法获取锁等永久等待。
上面的代码写于几年之前,因为服务已经在线上运行很久,且没有需求的变动,中间也发生几次事故,比如设备的指令下不下去,当时也是一直在排查网关转发后的业务服务去排查无法下发的原因,重没想到这个运行良久的网关的代码会有bug。 为什么这次开始排查网关服务了呢?原因有
1、上线了一个服务监控面板,抓取到这个网关服务的线程数量一直很高,且在不断增高,问题得以暴露
2、这期间服务又出现一个OOM(如上),且正在做服务的改造优化,所以需要自己排查下问题的原因
尝试复现-(只是一种可能的场景)
找到了一处bug,那是不是就是这个原因呢,其实还是需要进行场景还原和问题复现的
由于线上物联网设备和这个网关服务的实际交互场是比较复杂且出问题的时候肯定是比较特殊的场景(正常情况下不会出现这种问题),且此系统发生问题的时候也没有清晰的日志能复原链路,只能通过分析代码交互逻辑构造一种可能出现的链路进行复现
复现场景选择
通过分析代码,大部分正常情况下,这种商业设备是多帧上告的,且如果不是最后一帧的话,业务系统是不会下发指令给网关的,只有在最后一帧的时候才会给网关下发指令,且命令下发和上告时互斥的。
但是在网关接收到设备的上告数据的时候,网关会先给设备回复一个ACK(是一个同步Http请求流程),之后才会通过MQ把设备的上告数据下发给业务系统。
所以当同时在线的设备量很大且都在上告的时候,网关给公有设备厂商下发的ACK就可能存在丢失的情况,设备没有收到ACK,就会不断重复上告。然后网关就会不断通过MQ给业务系统数据,业务系统接收到设备上告数据之后会通过MQ给网关不断下发需要下发到设备的命令,这个时候在上面的代码里,同一个设备上下文上就会形成多个线程同时竞争一把锁的情况,且会出现当一个线程获取锁之后,提前退出。导致等在这个锁的这一组线程全都无法释放,形成死锁,造成线程资源泄露,以及线程持有的设备上下文资源泄露 。链路如下:
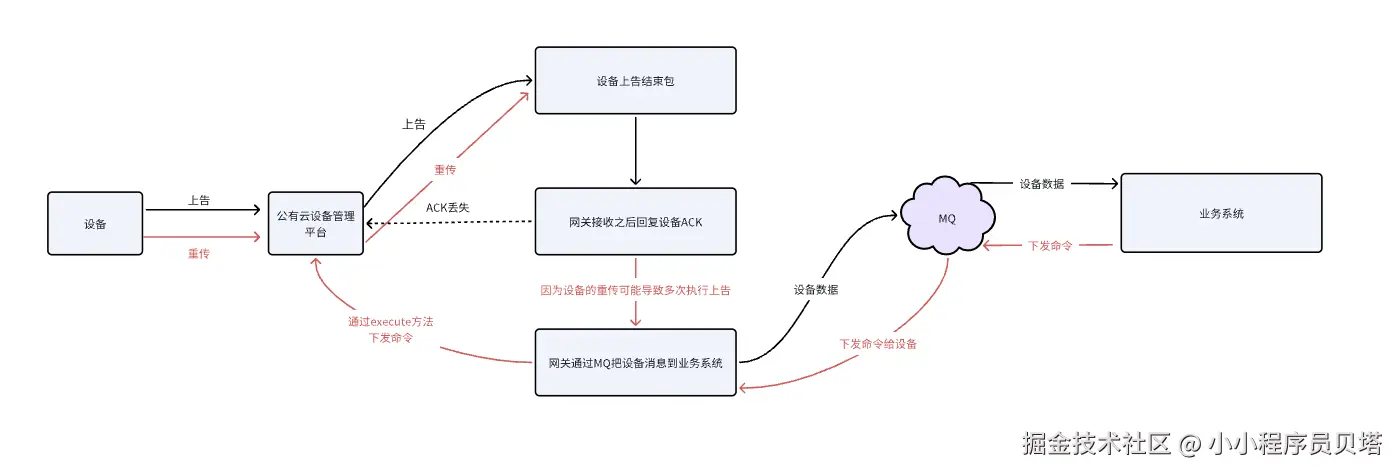
简单来说就是:
当系统在一定并发量设备同时在线的时候,设备可能会重传结束帧包,导致并发多次上告网关,网关多次下发命令给到业务系统, 业务系统会给网关下发命令,网关每次收到之后都会执行 Gateway .executeCmd(dtx) , 导致同一个 DeviceContext 上等待执行命令的线程被卡死
所以压测复现场景如下:通过对同一个设备 每秒50次 ,持续5分钟进行上告,使用jmeter进行压测,观察网关的线程情况
压测时间 18:54 ~ 18:59 左右, 可以看到在并发情况下,即使在压测结束之后线程也继续维持在高水位而不释放线程
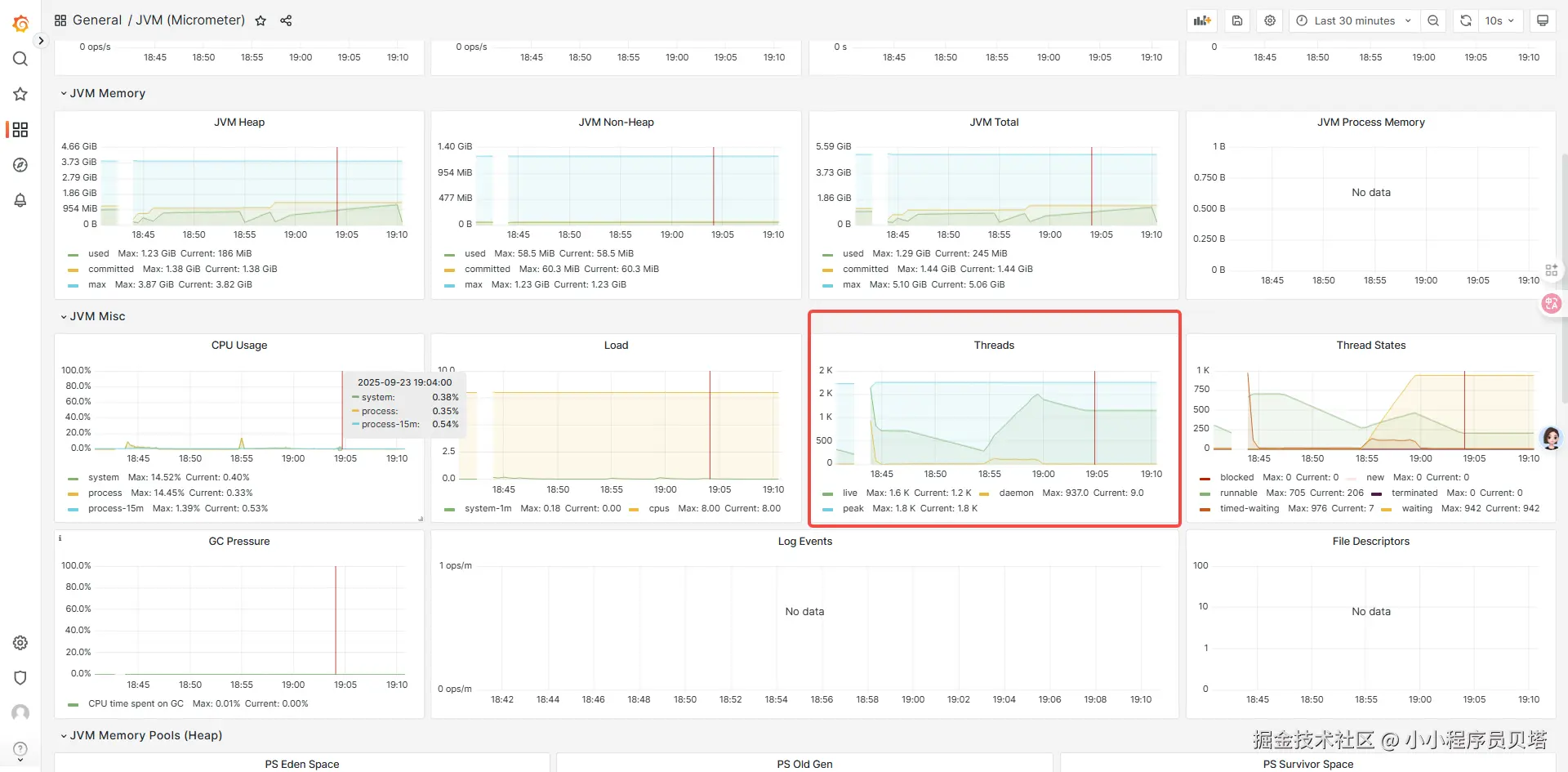
通过 jstack dump 线程然后分析可以看到: 大部分线程被阻塞在了 at com.ph.ph.Gateway.execute 和线上的jstack线程堆栈是一样的
疑问点
服务OOM以及线程数量很高且不回收的问题算是找到了根源,但是在排查的过程中还有一些问题需要搞清楚,这些小细节也是对一些知识点的查缺补漏
为什么所有 wait for 的锁对象在jstack线程堆栈中没有找到任何一个线程持有?
正常情况下,被阻塞的线程等待的锁一定是被一个正在runnable的线程持有的,但是在任何时候的jstack线程堆栈中都没有找到相应的持有锁的线程
原因是:之前持有锁的线程任务 在获取锁之后,由于一些条件提前退出了,然后线程消亡,锁一直未释放,被阻塞的线程将一直阻塞不会被唤醒,同时这些阻塞的线程持有的 DeviceContext 也不会被垃圾回收,导致线程资源泄漏和内存泄漏
锁对象地址为什么会变化?
可以确定的是这些线程一直在存活着,线程name一直没变,但是等待的锁对象的id一直在变,如果说这些线程已经没有任何线程可以唤醒他们了,那么他们将永远等待在同一个对象上,也就是 - parking to wait for <0x00000007076669c0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync) 中的地址不应该变化的
但是通过jstack 拉取不同时间点的发现这个锁对象地址不是固定的,这又是为什么呢?
猜想应该是 JVM垃圾回收导致对象的移动,随之锁对象的地址也发生了变化。通过jstat 命令查看服务上的gc情况,可以看到gc是频繁的,同时下文也有相应的方法进行验证(通过jcmd GC.run 手动触发服务gc,重新 jstack dump线程堆栈就可以看到等待线程等待的锁的地址发生了变化)
下面是通过jstat -gcutil pid 拉取的服务的gc的情况,可以看到gc很频繁,其实系统的压力已经挺大的了(本身系统的并发量也高,然后还有内存泄露)
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.74 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706
78.00 0.00 93.78 99.72 97.79 95.17 2332486 16218.238 20613 10381.468 26599.706- 是否会影响表的命令下发?之前的代码对业务的影响是什么?
因为系统还有一个 超时任务的兜底,在 DeviceContext 超时之后(也就是长时间没有上告或者没有命令需要下发或者超时未收到命令的回复),超时任务会将 DeviceContext 从全局缓存中移除,下次设备上告会重新创建DeviceContext,此时就可以正常进行获取锁的操作了,不过任然会有可能经历上面的死锁的流程
但是如果对于一个已经死锁的DeviceContext,此时后续还有任务下发,是下发不下去的,因为任何线程都无法再获取MeterContext上的锁了,在去年出过几次重大事故,当时就是大量设备在线,且不断上告,导致同一个DeviceContext不会超时,且后续线程无法获取锁,导致命令一直下发不下去
总结
通过一次对线上服务OOM 以及 线程资源使用很高且不释放的 等问题的排查,在没有发生事故的现场以及日志的情况下,通过严谨的代码分析和逻辑推演,以及合理使用工具,发现了系统中存在的严重问题(存在有几年了),为系统的稳定性排除了一个大雷,同时在这个过程中也积累了解决JVM OOM等问题的经验,同时也将之前书本上对JVM的了解转变成了一次生产的实践