简介
在计算机视觉的进阶学习中,dlib 库是一款不可多得的 "瑞士军刀"------ 它以简洁的 API 封装了复杂的机器视觉算法,尤其在人脸分析、特征提取等领域表现突出,既能满足科研实验的快速验证需求,也能支撑工业级项目的落地开发。如果你已经掌握了 OpenCV 的基础操作,却在人脸关键点定位、疲劳检测、人脸追踪等进阶场景中感到困惑,那么这篇系列教学将为你搭建从 "基础" 到 "实战" 的桥梁。
一、认识dlib库
dlib是一个适用于C++和Python的第三方库。包含机器学习、计算机视觉和图像处理的工具包,被广泛的应用于机器人、嵌入式设备、移动电话和大型高性能计算环境。是开源许可用户免费使用。
opencv优缺点:
优点
1)可以在CPU上实时工作;
2)简单的架构;
3)可以检测不同比例的人脸。
缺点
1)会出现大量的把非人脸预测为人脸的情况;
2)不适用于非正面人脸图像;
3)不抗遮挡。
dlib优缺点:
优点
1)适用于正面和略微非正面的人脸;
2)语法极简单
3)再小的遮挡下仍可工作。
缺点
1)不能检测小脸,因为它训练数据的最小人脸尺寸为80×80,较小尺寸的人脸数据需自己训练检测器;
2)边界框通常排除前额的一部分甚至下巴的一部分;
3)不适用于侧面和极端非正面,如俯视或仰视。
安装dlib库方法
1、pip install dlib --i 镜像地址
2、找到dlib库的whl文件进行安装
但是对于第一种方法可能会报下面的错
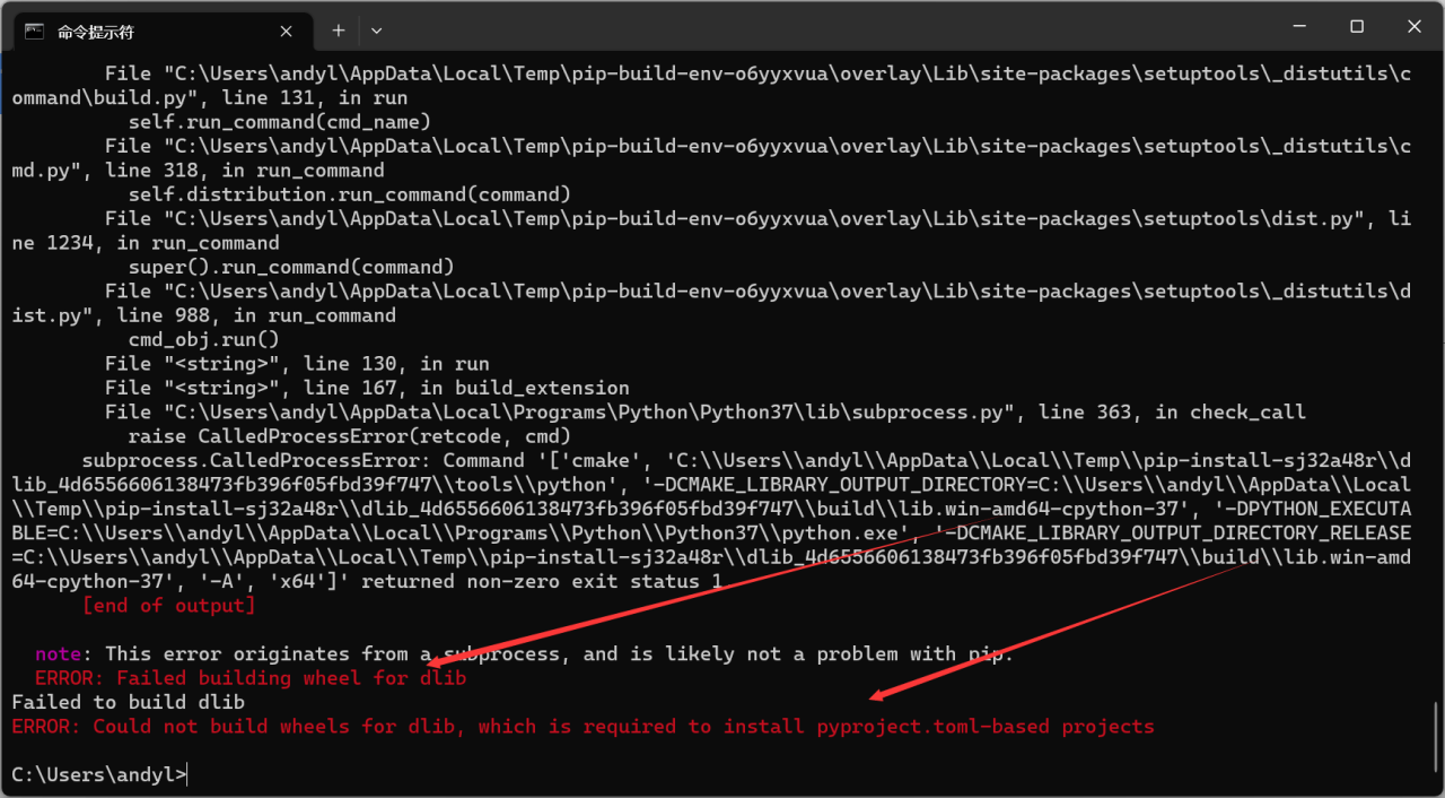
原因是dlib库是基于c++开发使用的,需要下载c++的环境软件才行,所有建议使用第二种方法找whl文件,使用pip install 加路径安装方法。
dlib人脸检测
python
import cv2
import dlib
# get_frontal_face_detector()生成人脸检测器
# 使用HOG算法、线性分类器、金字塔图像结构和滑动窗口检测等技术。
# 比opencv提供的harr级联分类器效果更好
detector = dlib.get_frontal_face_detector() # 构造脸部位置检测器HOG
img = cv2.imread("hr.jpg")
# faces = detector(image,n)使用人脸检测器返回检测到的人脸框
# 参数: image: 待检测的可能含有人脸的图像。
# 参数n: 表示采用上采样的次数。上采样会让图像变大,能够检测到更多人脸对象,提高小人脸的检测效果
# 通常建议将此参数设置为0或1。较大的值会增加检测的准确性,但会降低处理速度。
# 返回值faces: 返回检测图像中的所有人脸框。
faces = detector(img, 0)
for face in faces: # 对每个人脸框进行逐个处理
# 获取人脸框的坐标
x1 = face.left()
y1 = face.top()
x2 = face.right()
y2 = face.bottom()
# 绘制人脸框
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示捕获到的各个人脸框
cv2.imshow("result", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
然后以摄像头为检测,我们进行两个对比发现dilb的检测效果你opencv的检测效果总体是比较好的,一些被遮挡住的opencv是检测不出来的,但是dlib还是可以继续检测到人脸
python
import cv2
import dlib
# --- 初始化 ---
# 1. 检测器实例化 (放在循环外部以提高效率)
dlib_detector = dlib.get_frontal_face_detector()
# 2. 加载 OpenCV 的 Haar 级联分类器
# 请确保 'haarcascade_frontalface_default.xml' 文件在你的项目目录下,
# 或者提供其完整路径。
opencv_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
if opencv_cascade.empty():
print("错误:无法加载 Haar 级联分类器文件。请检查文件路径是否正确。")
exit()
# 3. 打开摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Cannot open camera")
exit()
# --- 主循环 ---
while True:
ret, frame = cap.read()
if not ret:
print("不能读取摄像头")
break
# --- 分支一:使用 dlib 进行人脸检测 ---
# 创建帧的副本,防止与 OpenCV 的绘制操作冲突
frame_dlib = frame.copy()
dlib_faces = dlib_detector(frame_dlib, 0)
for face in dlib_faces:
x1, y1, x2, y2 = face.left(), face.top(), face.right(), face.bottom()
cv2.rectangle(frame_dlib, (x1, y1), (x2, y2), (255, 0, 0), 2) # 绿色框
cv2.imshow("dlib ", frame_dlib)
# --- 分支二:使用 OpenCV Haar 级联进行人脸检测 ---
# 创建帧的副本
frame_opencv = frame.copy()
# 转换为灰度图,Haar 级联需要灰度图
gray = cv2.cvtColor(frame_opencv, cv2.COLOR_BGR2GRAY)
opencv_faces = opencv_cascade.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=8, minSize=(30, 30))
print(f"OpenCV 发现 {len(opencv_faces)} 张人脸!")
for (x, y, w, h) in opencv_faces:
cv2.rectangle(frame_opencv, (x, y), (x + w, y + h), (255, 0, 0), 2) # 蓝色框
cv2.imshow("OpenCV ", frame_opencv)
# --- 退出条件 ---
# 等待 1 毫秒,监听按键。如果按下 'q' 键,则退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# --- 资源释放 ---
cap.release()
cv2.destroyAllWindows()二、dlib---人脸应用实例---表情识别
人在微笑时,嘴角会上扬,嘴的宽度和与整个脸颊(下颌)的宽度之比变大。

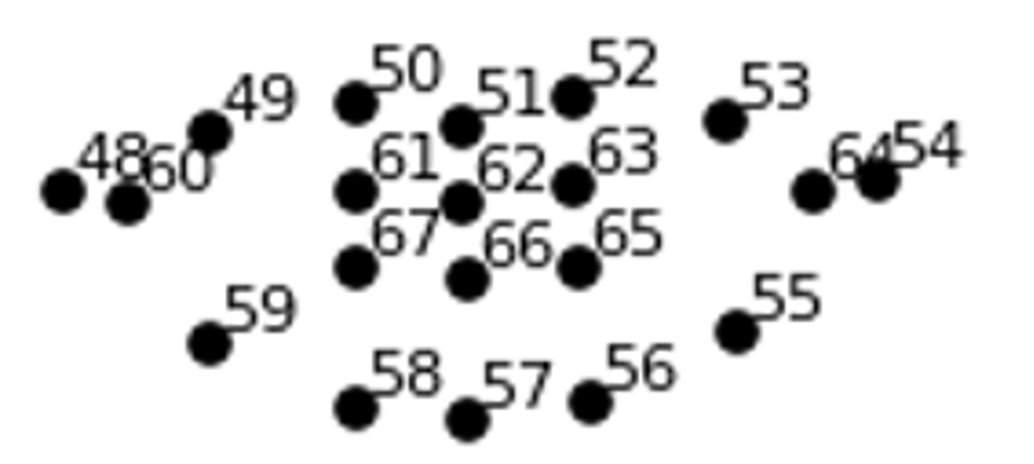
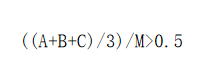
代码实现
python
import numpy as np
import cv2
import dlib
img = cv2.imread("shuge.jpg")# 读取图像
detector = dlib.get_frontal_face_detector()#构造人脸检测器
faces = detector(img, 0)#检测人脸
#dlib.shape_predictor载入模型(加载预测器)
# 可以从https://github.com/davisking/dlib-models下载
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
for face in faces: #获取每一张脸的关键点(实现检测)
shape=predictor(img, face)# 获取关键点
# 将关键点转换为坐标(x,y)的形式
# landmarks = np.matrix([[p.x, p.y] for p in shape.parts()])
landmarks = np.array([[p.x, p.y] for p in shape.parts()])
#绘制每一张脸的关键点(绘制shape中的每个点)
for idx, point in enumerate(landmarks):
# pos = (point[0, 0], point[0, 1])# 当前关键的坐标
pos = [point[0],point[1]]# 当前关键的坐标
# 针对当前关键点,绘制一个实心圆
cv2.circle(img, pos, radius=2, color=(0, 255, 0), thickness=-1)
# 普通大小的等宽字体
cv2.putText(img, str(idx), pos, cv2.FONT_HERSHEY_SIMPLEX, 0.4,
(255, 255, 255), 1, cv2.LINE_AA) # 线条类型:抗锯齿线条。
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()
摄像头版
python
import numpy as np
import cv2
import dlib
detector = dlib.get_frontal_face_detector()#构造人脸检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
img = cv2.VideoCapture(0)
if not img.isOpened():
print("Cannot open camera")
exit()
# --- 主循环 ---
while True:
ret, frame = img.read()
if not ret:
print("不能读取摄像头")
break
faces = detector(frame, 0)#检测人脸
#dlib.shape_predictor载入模型(加载预测器)
# 可以从https://github.com/davisking/dlib-models下载
for face in faces: #获取每一张脸的关键点(实现检测)
shape=predictor(frame, face)# 获取关键点
# 将关键点转换为坐标(x,y)的形式
# landmarks = np.matrix([[p.x, p.y] for p in shape.parts()])
landmarks = np.array([[p.x, p.y] for p in shape.parts()])
#绘制每一张脸的关键点(绘制shape中的每个点)
for idx, point in enumerate(landmarks):
# pos = (point[0, 0], point[0, 1])# 当前关键的坐标
pos = [point[0],point[1]]# 当前关键的坐标
# 针对当前关键点,绘制一个实心圆
cv2.circle(frame, pos, radius=2, color=(0, 255, 0), thickness=-1)
# 普通大小的等宽字体
cv2.putText(frame, str(idx), pos, cv2.FONT_HERSHEY_SIMPLEX, 0.4,
(255, 255, 255), 1, cv2.LINE_AA) # 线条类型:抗锯齿线条。
cv2.imshow("img", frame)
cv2.waitKey(2)
cv2.destroyAllWindows()三、dlib---人脸应用实例---疲劳检测
通过眼睛的纵横比来判断眼睛是否闭合。从而判断人是否处于疲劳状态


如果需要更多关键点,可使用百度人脸关键点检测
代码实现
python
"""疲劳检测,可用于驾驶员监控、学员上课状态检测等。"""
import numpy as np
import dlib
import cv2
from sklearn.metrics.pairwise import euclidean_distances # 计算欧氏距离
from PIL import Image, ImageDraw, ImageFont # pip install pillow
def eye_aspect_ratio(eye):
# 计算眼睛纵横比
A = euclidean_distances(eye[1].reshape(1, 2), eye[5].reshape(1, 2))
B = euclidean_distances(eye[2].reshape(1, 2), eye[4].reshape(1, 2))
C = euclidean_distances(eye[0].reshape(1, 2), eye[3].reshape(1, 2))
ear = ((A + B) / 2.0) / C # 纵横比
return ear
def cv2AddChineseText(img, text, position, textColor=(255, 0, 0), textSize=30):
# 完善中文显示函数
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
"simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
def drawEye(eye): # 绘制眼眶凸包
eyeHull = cv2.convexHull(eye)
cv2.drawContours(frame, [eyeHull], -1, color=(0, 255, 0), thickness=-1)
COUNTER = 0 # 闭眼持续次数统计
detector = dlib.get_frontal_face_detector() # 构造脸部位置检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") # 读取人脸关键点定位模型
# 尝试不同的摄像头索引,0通常是默认摄像头,有些设备可能需要1或2
cap = cv2.VideoCapture(0)
# 检查摄像头是否成功打开
if not cap.isOpened():
print("无法打开摄像头,请检查设备是否正常连接")
exit()
while True:
ret, frame = cap.read()
# 检查是否成功获取帧
if not ret:
print("无法获取视频帧,可能是摄像头已断开")
break
# 确保帧有有效尺寸
if frame is None or frame.shape[0] == 0 or frame.shape[1] == 0:
print("获取到空帧,跳过")
continue
faces = detector(frame, 0) # 获取人脸
for face in faces: # 循环遍历每一个人脸
shape = predictor(frame, face) # 获取关键点
# 将关键点转换为坐标(x,y)的形式
shape = np.array([[p.x, p.y] for p in shape.parts()])
rightEye = shape[36:42] # 右眼
leftEye = shape[42:48] # 左眼
rightEAR = eye_aspect_ratio(rightEye)
leftEAR = eye_aspect_ratio(leftEye)
ear = (leftEAR + rightEAR) / 2.0
if ear < 0.3:
COUNTER += 1
if COUNTER >= 50:
frame = cv2AddChineseText(frame, text="!!!危险!!!", position=(250, 250))
else:
COUNTER = 0
drawEye(leftEye)
drawEye(rightEye)
info = f"EAR: {ear[0][0]:.2f}"
frame = cv2AddChineseText(frame, info, position=(0, 30))
# 再次检查帧有效性后再显示
if frame is not None and frame.shape[0] > 0 and frame.shape[1] > 0:
cv2.imshow("Frame", frame)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
# 释放资源
cap.release()
cv2.destroyAllWindows()这段代码使用计算机视觉技术实时检测人的眼睛开合状态,从而判断是否处于疲劳状态。它主要依赖于三个核心库:
- OpenCV (
cv2): 用于视频捕获、图像处理和显示。 - dlib: 用于高精度的人脸检测和 facial landmark(人脸关键点)定位。
- scikit-learn: 用于计算关键点之间的欧氏距离,这是判断眼睛开合的关键。
整个流程可以概括为:
- 捕获视频: 从电脑摄像头读取实时画面。
- 人脸检测: 在每一帧画面中找到人脸的位置。
- 关键点定位: 对检测到的人脸,精确找出 68 个特征点(如眼角、鼻尖、嘴角等)。
- 提取眼睛: 从 68 个关键点中筛选出构成左眼和右眼的 12 个点。
- 计算 EAR: 计算眼睛的纵横比(Eye Aspect Ratio, EAR)。当眼睛睁开时,EAR 值较大;当眼睛闭上时,EAR 值接近 0。
- 疲劳判断: 通过设定一个 EAR 阈值(如 0.3)和一个连续闭眼帧数阈值(如 50),来判断是否发生了长时间闭眼,即疲劳状态。
- 结果显示: 将 EAR 值和疲劳警告(如果检测到)实时叠加显示在视频画面上。
逐段代码详解
核心功能函数
a. eye_aspect_ratio(eye): 计算眼睛纵横比
python
def eye_aspect_ratio(eye):
# 计算眼睛纵横比
A = euclidean_distances(eye[1].reshape(1, 2), eye[5].reshape(1, 2))
B = euclidean_distances(eye[2].reshape(1, 2), eye[4].reshape(1, 2))
C = euclidean_distances(eye[0].reshape(1, 2), eye[3].reshape(1, 2))
ear = ((A + B) / 2.0) / C # 纵横比
return ear这个函数实现了下面的公式:EAR = (||p2 - p6|| + ||p3 - p5||) / (2 * ||p1 - p4||)
其中 p1 到 p6 是构成眼睛的 6 个关键点,它们的排列顺序是固定的(由 dlib 模型定义)。
A和B是眼睛上下眼睑之间的垂直距离。C是眼睛左右眼角之间的水平距离。
当眼睛睁开时,A 和 B 的值较大,EAR 值也较大。当眼睛闭上时,A 和 B 的值趋近于 0,EAR 值也趋近于 0。这个比值对头部姿态和人脸大小不敏感,非常鲁棒。
注意 : euclidean_distances 返回的是一个 2D 数组(例如 [[distance]]),所以最终的 ear 也是一个数组。在后续使用时,需要用 ear[0][0] 来获取其数值。
b. cv2AddChineseText(img, text, ...): 在 OpenCV 图像上添加中文
python
def cv2AddChineseText(img, text, position, textColor=(255, 0, 0), textSize=30):
# 完善中文显示函数
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype(
"simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)为什么需要这个函数? OpenCV 的 cv2.putText() 函数对中文支持不佳,通常会显示为乱码。这个函数通过以下步骤解决了这个问题:
- 将 OpenCV 的 BGR 格式图像转换为 PIL 支持的 RGB 格式。
- 使用 PIL 的
ImageDraw和ImageFont来绘制中文文本。 ImageFont.truetype("simsun.ttc", ...)加载了一个中文字体文件。注意: "simsun.ttc" 是 Windows 系统下的宋体字体。如果你的系统是 Linux 或 macOS,你需要更换为系统中存在的中文字体路径,例如/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc。- 将绘制好文本的 PIL 图像再转换回 OpenCV 的 BGR 格式,以便后续显示。
c. drawEye(eye): 绘制眼睛区域
python
def drawEye(eye): # 绘制眼眶凸包
eyeHull = cv2.convexHull(eye)
cv2.drawContours(frame, [eyeHull], -1, color=(0, 255, 0), thickness=-1)这个函数用于可视化眼睛的位置。
cv2.convexHull(eye): 计算构成眼睛的 6 个点的凸包。凸包可以理解为能把所有点都包起来的最小凸多边形,对于眼睛来说,它就是眼眶的轮廓。cv2.drawContours(...): 在视频帧frame上绘制这个凸包轮廓。thickness=-1表示将轮廓内部填充为指定颜色(这里是绿色(0, 255, 0))。
主程序和视频处理循环
python
COUNTER = 0 # 闭眼持续次数统计
detector = dlib.get_frontal_face_detector() # 构造脸部位置检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") # 读取人脸关键点定位模型
# 尝试不同的摄像头索引,0通常是默认摄像头,有些设备可能需要1或2
cap = cv2.VideoCapture(0)COUNTER: 一个计数器,用于累计连续检测到闭眼的帧数。detector: 创建一个 dlib 的人脸检测器。predictor: 创建一个关键点预测器。关键点 : 你需要从 dlib 官网下载shape_predictor_68_face_landmarks.dat这个模型文件,并将其放在与你的 Python 脚本相同的目录下。cap: 创建一个视频捕获对象,0表示使用默认的摄像头。
计算 EAR 并判断疲劳
python
rightEAR = eye_aspect_ratio(rightEye)
leftEAR = eye_aspect_ratio(leftEye)
ear = (leftEAR + rightEAR) / 2.0 # 取左右眼的平均值
if ear < 0.3: # EAR阈值,小于此值认为是闭眼
COUNTER += 1
if COUNTER >= 50: # 连续闭眼帧数阈值
frame = cv2AddChineseText(frame, text="!!!危险!!!", position=(250, 250))
else:
COUNTER = 0
drawEye(leftEye)
drawEye(rightEye)- 分别计算左右眼的 EAR,然后取平均值作为最终的 EAR。
if ear < 0.3:: 这是一个经验性的阈值。大多数研究和实践表明,当 EAR 小于 0.2 或 0.3 时,可以认为眼睛是闭合的。你可以根据实际情况微调这个值。- 如果检测到闭眼,
COUNTER加 1。如果COUNTER累积到 50(即连续 50 帧都检测到闭眼),则认为发生了疲劳,并在画面上显示警告信息。假设视频的帧率是 30fps,那么 50 帧大约相当于 1.6 秒。 - 如果眼睛是睁开的(
ear >= 0.3),则将COUNTER重置为 0,并调用drawEye函数来可视化眼睛区域。