[1. ELK 概述](#1. ELK 概述)
[2. Elasticsearch 核心知识](#2. Elasticsearch 核心知识)
[3. Logstash 核心知识](#3. Logstash 核心知识)
[4. Kibana 核心知识](#4. Kibana 核心知识)
[5. 为什么要用 ELK](#5. 为什么要用 ELK)
[6. 完整日志系统特征](#6. 完整日志系统特征)
[7. ELK 工作原理](#7. ELK 工作原理)
[附录:本次 ELK 部署与调试中遇到的问题总结](#附录:本次 ELK 部署与调试中遇到的问题总结)
[1. Logstash 配置语法错误](#1. Logstash 配置语法错误)
[2. JAVA_HOME 未设置](#2. JAVA_HOME 未设置)
[3. Filebeat 连接 Logstash 报 "connection refused"](#3. Filebeat 连接 Logstash 报 “connection refused”)
[4. Logstash Beats 插件报 "地址已在使用"](#4. Logstash Beats 插件报 “地址已在使用”)
[5.Elasticsearch 报错问题:Java 环境找不到](#5.Elasticsearch 报错问题:Java 环境找不到)
[6. Kibana / Elasticsearch 配置小坑](#6. Kibana / Elasticsearch 配置小坑)
前言
在分布式系统和微服务架构成为主流的今天,日志管理已成为运维工作的核心挑战。面对海量且分散的日志数据,传统的命令行工具显得力不从心。
ELK Stack(Elasticsearch、Logstash、Kibana)作为开源日志解决方案的标杆,能够实现日志的集中收集、实时分析和可视化展示,让运维人员从繁琐的日志排查中解放出来。
本文将以实战为核心,手把手带你搭建一套完整可用的ELK系统。无论你是运维工程师还是开发人员,都能通过本文掌握企业级日志平台的构建方法。
现在,让我们开始这场日志管理的技术之旅!
相关知识简介
1. ELK 概述
ELK 是 Elasticsearch、Logstash 和 Kibana 三个开源工具的组合,提供一套完整的日志集中处理与分析解决方案:
-
Elasticsearch:核心搜索和分析引擎,用于存储日志并提供全文检索、聚合分析能力。
-
Logstash:数据收集与处理管道,从多种来源采集数据、清洗、转换后输出到 Elasticsearch。
-
Kibana:可视化与交互式分析工具,基于 Elasticsearch 数据构建仪表盘、图表和报告。
ELK Stack 能帮助企业统一收集、存储和分析来自多台服务器、不同应用的日志数据,适合日志分析、实时监控、数据可视化等场景。
2. Elasticsearch 核心知识
-
核心功能:全文检索、实时数据分析、分布式架构、RESTful API。
-
架构组件:集群、节点、索引、文档、分片、副本。
-
典型场景:日志和事件数据分析、全文搜索应用、监控与告警、商业智能。
-
优缺点:性能高、可扩展、灵活;但内存消耗大、管理复杂。
3. Logstash 核心知识
Logstash 是数据收集引擎,支持动态从各种数据源收集数据并进行过滤、分析、统一格式化后输出。
-
特点:多源数据采集、灵活过滤处理、丰富输出插件、插件可扩展、实时处理。
-
使用场景:日志收集与分析、数据清洗与转换、数据流整合。
-
轻量替代方案:
-
Filebeat:轻量级日志收集器,安装在客户端把日志直接发到 Logstash 或 Elasticsearch。
-
Fluentd:资源占用更少,在 Kubernetes 集群中常与 Elasticsearch 组成 EFK 方案。
-
4. Kibana 核心知识
Kibana 是 Elasticsearch 的可视化面板。
-
主要功能:丰富的数据可视化、交互式仪表板、日志搜索与管理、时间序列分析、报警与监控、基于角色的访问控制、地理可视化、报表生成。
-
使用场景:集中化日志管理与分析、实时监控、业务数据分析、安全分析、机器学习与趋势预测。
-
工作原理:Kibana 自身不存储数据,通过 REST API 从 Elasticsearch 查询数据并展示。
5. 为什么要用 ELK
传统的 grep/awk 在单机日志上还能用,但在多台服务器、大规模分布式环境下检索和统计困难、效率低。ELK 提供集中化收集、索引、可视化分析,大幅提高排障、监控和决策效率。
6. 完整日志系统特征
-
收集:多源日志采集。
-
传输:稳定解析和过滤并传输到存储系统。
-
存储:集中存储日志数据。
-
分析:友好的 UI 分析界面。
-
告警:支持错误报告和监控。
7. ELK 工作原理
-
在需要收集日志的服务器上部署 Logstash(或使用 Filebeat 先收集到日志服务器)。
-
Logstash 收集日志并格式化后写入 Elasticsearch。
-
Elasticsearch 对数据进行索引和存储。
-
Kibana 从 Elasticsearch 查询数据并生成图表展示。
实验环境规划(本次实验未使用node2,配置仅供参考)
| 节点名称 | IP地址 | 部署服务 |
|---|---|---|
| Node1 | 192.168.114.252 | Elasticsearch、Kibana |
| Node2 | 192.168.10.14 | Elasticsearch |
| Apache节点 | 192.168.114.251 | Logstash、Apache |
| Filebeat节点 | 192.168.114.253 | Filebeat |
基础环境准备
系统配置
在所有节点上执行以下操作:
bash
# 关闭防火墙和SELinux
systemctl stop firewalld
setenforce 0
# 设置主机名(分别在对应节点执行)
hostnamectl set-hostname node1 # Node1节点
hostnamectl set-hostname node2 # Node2节点
hostnamectl set-hostname apache # Apache节点
hostnamectl set-hostname filebeat # Filebeat节点
# 配置主机解析
echo "192.168.114.252 node1" >> /etc/hosts
echo "192.168.10.14 node2" >> /etc/hosts
echo "192.168.114.251 apache" >> /etc/hosts
echo "192.168.114.253 filebeat" >> /etc/hosts
# 安装Java环境
yum -y install java
java -versionElasticsearch集群部署
安装Elasticsearch
在Node1和Node2节点上执行:
bash
cd /opt
rpm -ivh elasticsearch-6.6.1.rpm
systemctl daemon-reload
systemctl enable elasticsearch.service配置Elasticsearch
编辑配置文件 /etc/elasticsearch/elasticsearch.yml:
yaml
cluster.name: my-elk-cluster #17行,取消注释,指定集群名字
node.name: node1 # 23行,Node2节点改为node2
path.data: /data/elk_data #33行,取消注释,指定数据存放路径
path.logs: /var/log/elasticsearch/ #37行,取消注释,指定日志存放路径
bootstrap.memory_lock: false #43行,取消注释,改为在启动的时候不锁定内存
network.host: 0.0.0.0 #55行,取消注释,设置监听地址,0.0.0.0代表所有地址
http.port: 9200 #59行,取消注释,ES 服务的默认监听端口为9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"] #68行,取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2启动并验证
bash
# 创建数据目录
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data
# 启动服务
systemctl start elasticsearch
# 验证服务
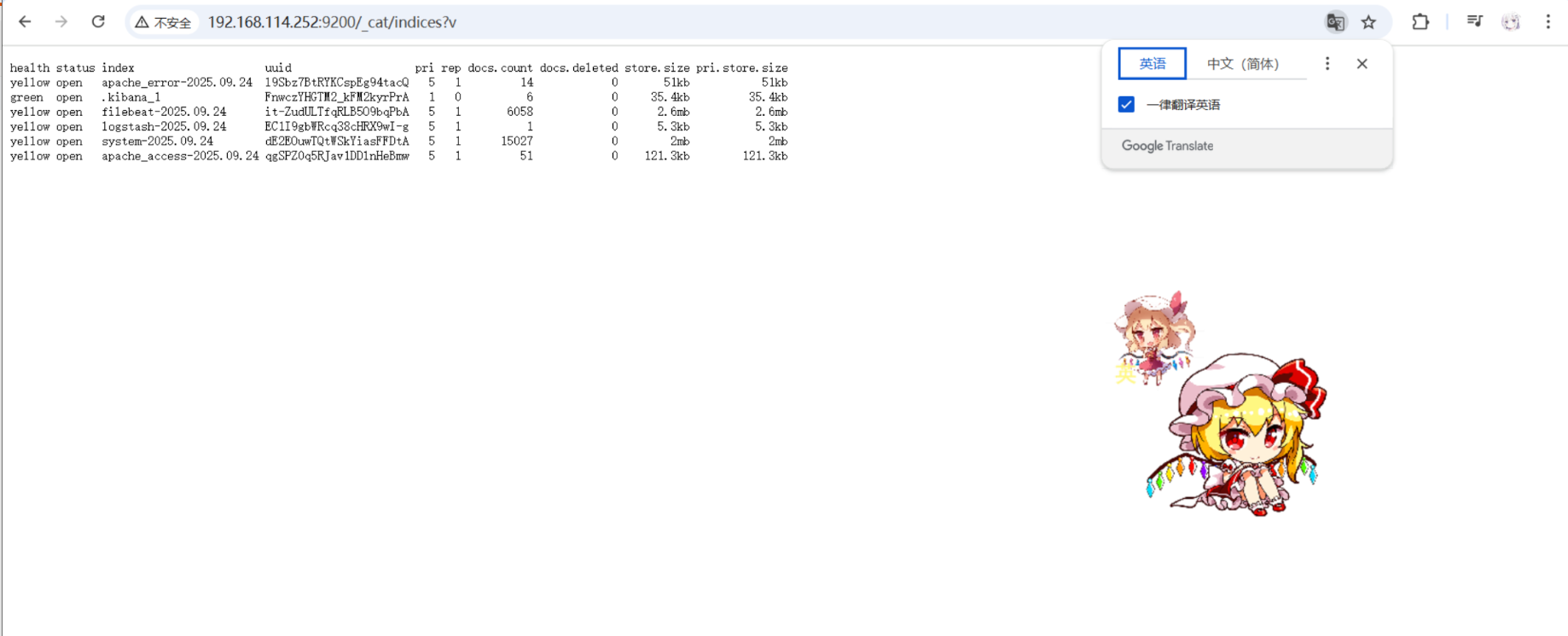
netstat -antp | grep 9200访问 http://192.168.114.252:9200 查看节点信息,访问 http://192.168.114.252:9200/_cluster/health?pretty 查看集群健康状态。
安装Elasticsearch-head管理界面
安装依赖环境
在Node1节点上安装Node.js和PhantomJS:
bash
# 安装Node.js
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure
make && make install
# 安装PhantomJS
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin安装并启动Elasticsearch-head
bash
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
# 配置Elasticsearch支持跨域
echo "http.cors.enabled: true" >> /etc/elasticsearch/elasticsearch.yml
echo "http.cors.allow-origin: \"*\"" >> /etc/elasticsearch/elasticsearch.yml
systemctl restart elasticsearch
# 启动head服务
cd /usr/local/src/elasticsearch-head/
npm run start &访问 http://192.168.114.252:9100 即可管理Elasticsearch集群。
Logstash部署与配置
安装Logstash
在Apache节点上执行:
bash
#安装apache服务
yum -y install httpd
systemctl start httpd
cd /opt
rpm -ivh logstash-6.6.1.rpm
systemctl start logstash
systemctl enable logstash
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/测试Logstash功能
bash
# 测试标准输入输出
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
# 测试写入Elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.114.252:9200"] } }'配置系统日志收集
创建配置文件 /etc/logstash/conf.d/system.conf:
ruby
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.114.252:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}设置日志文件权限并重启服务:
bash
chmod +r /var/log/messages
systemctl restart logstashKibana数据可视化
安装Kibana
在Node1节点上执行:
bash
cd /opt
rpm -ivh kibana-6.6.1-x86_64.rpm配置Kibana
编辑 /etc/kibana/kibana.yml:
yaml
server.port: 5601 --2--取消注释,Kiabana 服务的默认监听端口为5601
server.host: "0.0.0.0" --7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
elasticsearch.hosts: ["http://192.168.114.252:9200"] --28--取消注释,设置和 Elasticsearch 建立连接的地址和端口
kibana.index: ".kibana" --37--取消注释,设置在 elasticsearch 中添加.kibana索引启动并访问
bash
systemctl start kibana
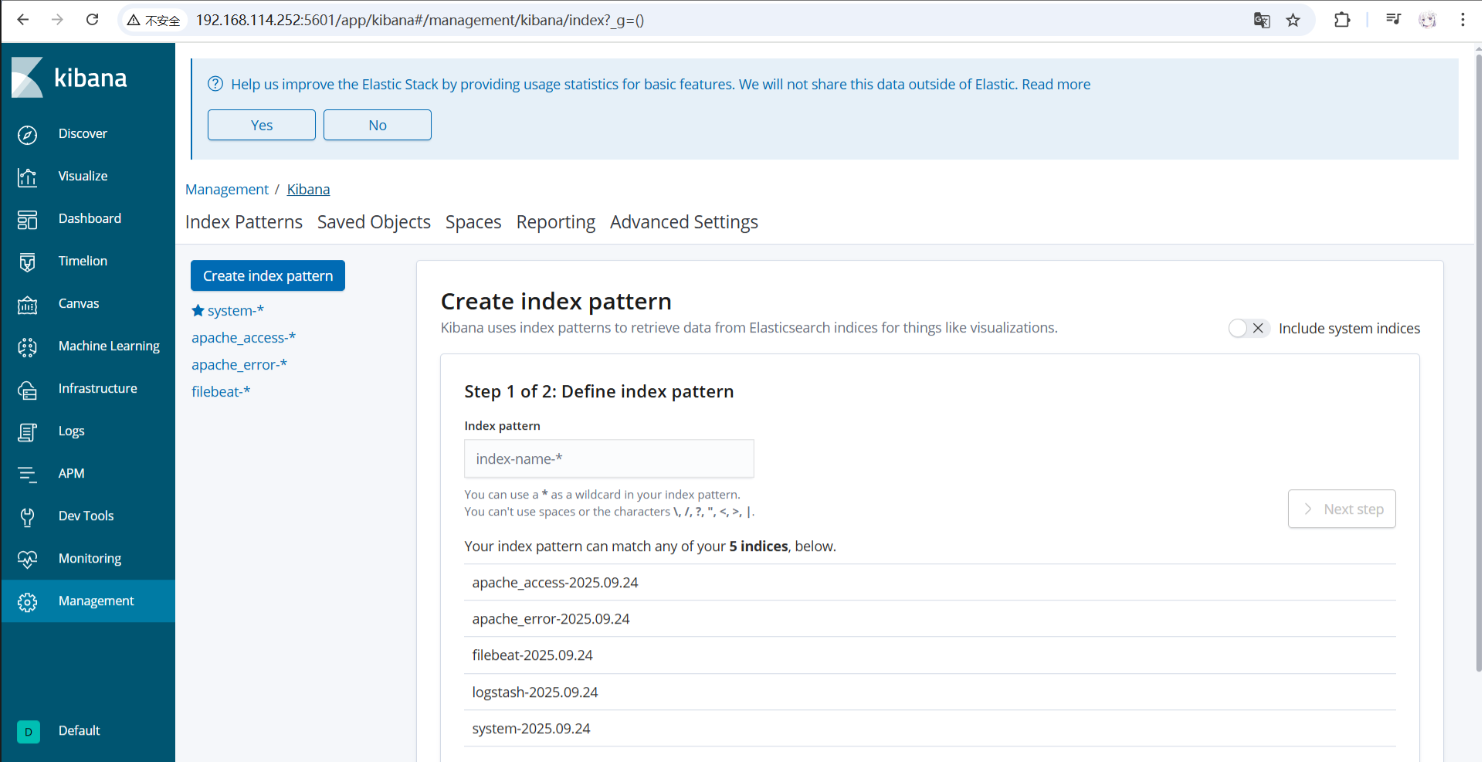
systemctl enable kibana访问 http://192.168.114.252:5601,创建索引模式 system-* 即可查看系统日志。
Apache日志收集实战
安装Apache服务
bash
yum -y install httpd
systemctl start httpd配置Logstash收集Apache日志
创建配置文件 /etc/logstash/conf.d/apache_log.conf:
ruby
input {
file {
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file {
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.114.252:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.114.252:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}执行收集命令:
bash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/apache_log.conf在Kibana中创建 apache_access-* 和 apache_error-* 索引模式即可查看Apache日志。
Filebeat轻量级日志收集
安装Filebeat
在Filebeat节点上执行:
bash
cd /opt
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64 /usr/local/filebeat
#rpm方式
rpm -ivh filebeat-6.6.1-x86_64.rpm 配置Filebeat
编辑 /usr/local/filebeat/filebeat.yml:
yaml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/*.log
fields:
service_name: filebeat
log_type: log
service_id: 192.168.114.253
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.114.251:5044"]注:rpm 方式的路径在/etc/filebeat/filebeat.yml
配置Logstash接收Filebeat数据
在Apache节点创建 /etc/logstash/conf.d/logstash.conf:
ruby
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.114.252:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}启动Filebeat:
bash
cd /usr/local/filebeat
./filebeat -e -c filebeat.yml
#启动 logstash
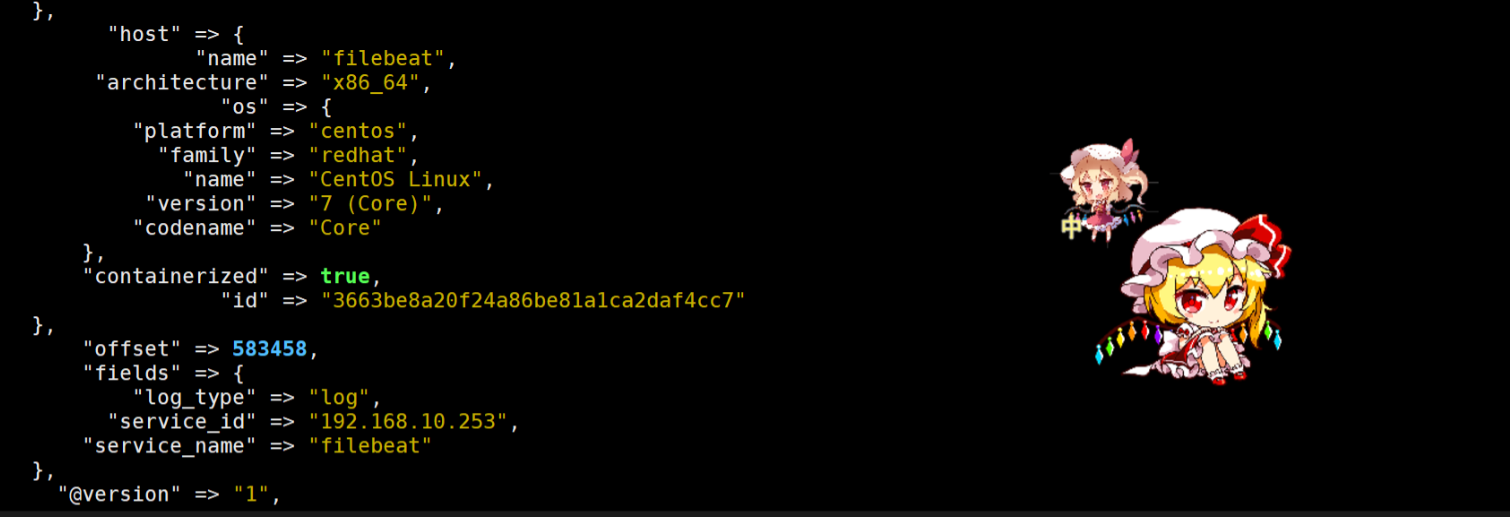
logstash -f logstash.conf在Kibana中创建 filebeat-* 索引模式查看数据。
相关实验截图
小结
通过以上步骤,我们搭建了一个完整的企业级日志分析系统:Elasticsearch 负责存储和检索,Logstash(或 Filebeat)负责收集与处理,Kibana 负责可视化展示。系统具备实时采集、集中存储、可视化分析、报警监控等特性,适合企业级生产环境。
附录:本次 ELK 部署与调试中遇到的问题总结
1. Logstash 配置语法错误
-
表现 :启动日志中出现
Expected one of #, if, ", ', } at line... -
原因 :
.conf文件中存在全角空格、Tab、引号、或者花括号不匹配。 -
解决:
-
用纯 ASCII 空格重新整理配置。
-
sudo /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t检查语法。 -
建议写入配置前先用检测工具检测一下语法空格等问题,修改后再用
-
2. JAVA_HOME 未设置
-
表现 :
could not find java; set JAVA_HOME or ensure java is in PATH,但是echo$PATH有jdk -
原因:RPM 包未正确加载系统的 JDK 路径。
-
解决 :在
/etc/sysconfig/logstashJAVA_HOME=/usr/local/jdk1.8.0_91并systemctl daemon-reload后重启。 -
注:没有/etc/sysconfig/logstash的话就创建然后添加JAVA_HOME=/usr/local/jdk1.8.0_91字段后尝试重启
3. Filebeat 连接 Logstash 报 "connection refused"
-
表现 :Filebeat 报
Failed to connect to backoff(async(tcp://IP:5044)): dial tcp ... connect: connection refused -
原因:
-
Logstash 没有监听该 IP/端口;
-
Filebeat 指向了错误的 IP;
-
防火墙阻挡 5044 端口。
-
-
解决:
-
ss -lntp | grep 5044确认 Logstash 是否监听。 -
校对 Filebeat 配置中的
hosts。 -
开放防火墙端口
firewall-cmd --add-port=5044/tcp --permanent. -
注:可能是没写logstash.conf配置文件。。。
-
4. Logstash Beats 插件报 "地址已在使用"
-
表现 :Logstash 日志
Error: 地址已在使用 (Java::JavaNet::BindException) -
原因 :同一个 pipeline 里出现多个
beats { port => 5044 }或多个 pipeline 抢同一端口。 -
解决:
-
/etc/logstash/conf.d/里只保留一个 beats input。 -
或在
/etc/logstash/pipelines.yml把不同 pipeline 分开。 -
或者改用不同端口。
-
注:可能是服务冲突了,停止服务后再logstash -f logstash.conf
-
5.Elasticsearch 报错问题:Java 环境找不到
错误现象:
-
could not find java; set JAVA_HOME or ensure java is in PATH -
虽然系统中有 Java,但 Elasticsearch 服务运行时找不到
根本原因:
-
Systemd 服务运行时使用独立的环境变量,不继承用户环境
-
Java 路径未在系统级配置中设置
解决方案:
bash
#在 Elasticsearch 配置中设置
sudo vi /etc/sysconfig/elasticsearch
添加:JAVA_HOME=/usr/local/jdk1.8.0_916. Kibana / Elasticsearch 配置小坑
-
Elasticsearch 集群节点名、IP、数据目录权限需提前设置好。
-
Kibana 的
server.host要改为0.0.0.0才能外网访问。 -
在 Kibana 中要根据实际索引模式创建 Index Pattern 才能看到数据。