内容目录
一、详细介绍
网站流量统计系统是一款简单实用的网站流量统计系统。
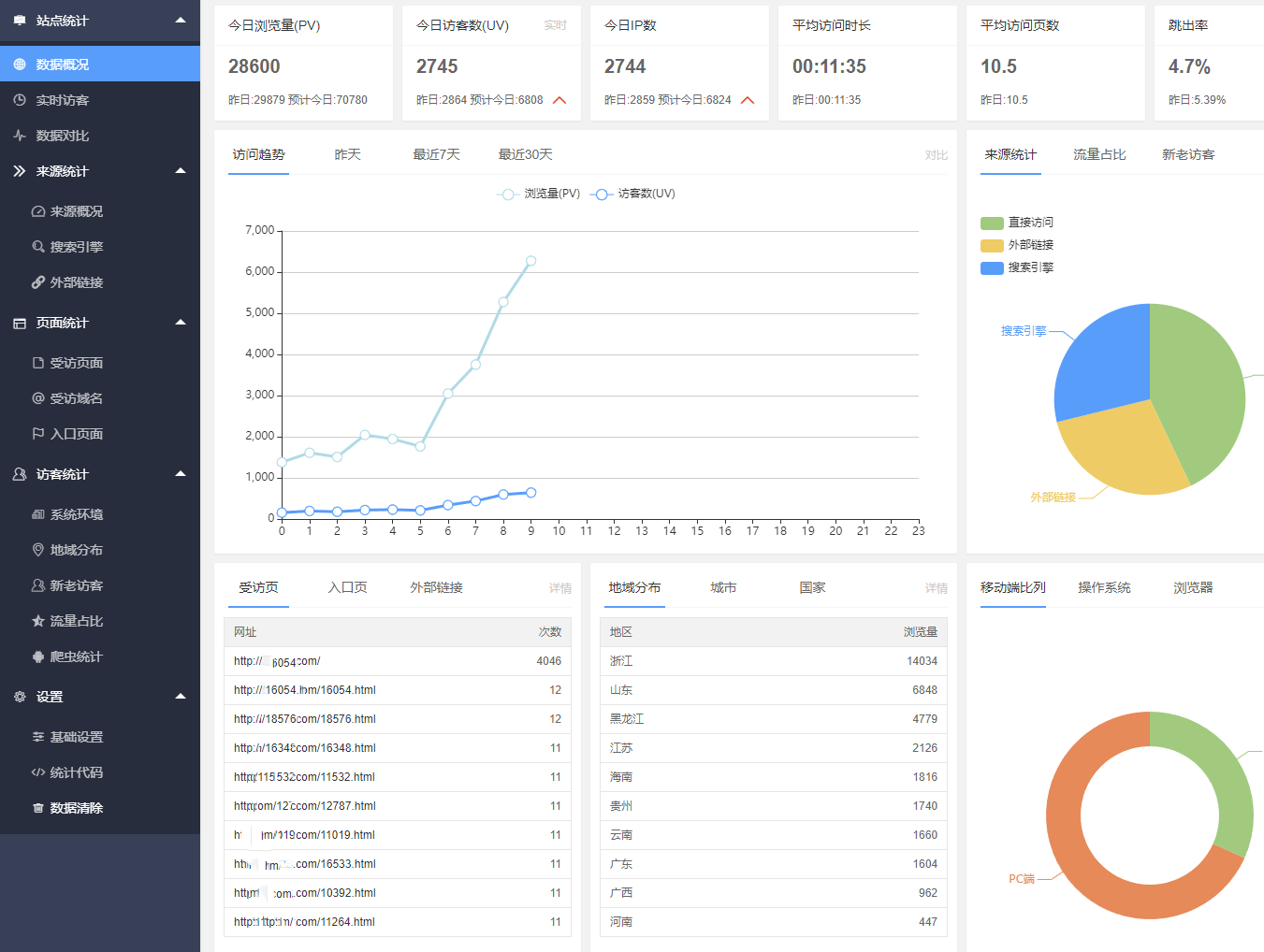
数据概况:显示PV、UV、IP等数据,方便查看。
实时访客:显示访客会话列表,查看访客访问明细。
数据对比:对比2段时间之间的PV、UV、IP、平均访问时长、页数、蜘蛛、爬虫等数据。
来源统计
来源概况:显示直接访问、外部链接、搜索引擎之间的访问量比例。
搜索引擎:各个搜索引擎来源的比例外部链接:按访问量排序外部链接页面统计
受访页面:按访问量排序受访页面受访域名:按访问量排序受访域名
入口页面:每次会话时,首次访问的页面访客统计
系统环境:显示访客的移动端、操作系统、浏览器比例
地域分布:按访问量排序省、城市、国家
新老访客:显示新老访客比例
流量占比:显示用户、蜘蛛、爬虫之间的访问量比例
爬虫统计:按访问量排序蜘蛛与爬虫,显示蜘蛛与爬虫的详细访问记录
设置
基础设置:开启与关闭蜘蛛或爬虫日志
统计代码:开关自动加载代码,获取统计代码
数据清除:清除缓存数据与访问记录数据
二、效果展示
1.部分代码
代码如下(示例):
php
function configShow() {
if($class=C('cms:class:get',@$_GET['hash'])) {
$homeroute=array();
foreach ($GLOBALS['route'] as $thisroute) {
if(isset($thisroute['uri']) && $thisroute['uri']=='/' && !isset($thisroute['domain'])){
$homeroute[$thisroute['classhash']]=1;
}
}
if(!$class['enabled'] || !$class['module']){
$homeroute=array();
}elseif(count($homeroute)<2){
$homeroute=array();
}elseif($domainbind=C('cms:class:get','domainbind')){
if($domainbind && $domainbind['enabled']){
$homeroute=array();
}
}
if(isset($_GET['nobread']) && $_GET['nobread']==1){
$nobread=true;
}else{
$nobread=false;
}
V('template_config',array('hash'=>$class['hash'],'classname'=>$class['classname'],'homeroute'=>count($homeroute),'nobread'=>$nobread));
}
}2.效果图展示