在我们设计出前面的基础底层框架后,我们就其实已经能够写下第一个简单的基本的测试用例
测试用例设计(testset、data)
 因此,我们就创建了两个包
因此,我们就创建了两个包
-
testset 用于存储py文件,写下接口API测试用例
-
data 用于存储yaml文件,导入对应参数,给接口提供对应的入参
testset 下python文件的写法据我所知给几点参考:
- 命名规范:- 所有的测试文件都应该以 test_ 开头
- 一个对应API测试用例要包括:封装好的http请求工具,数据加载工具,断言工具(根据业务需求设计),json(一些数据处理库)
- 测试数据:从yaml文件中加载
数据加载工具(data_loader)
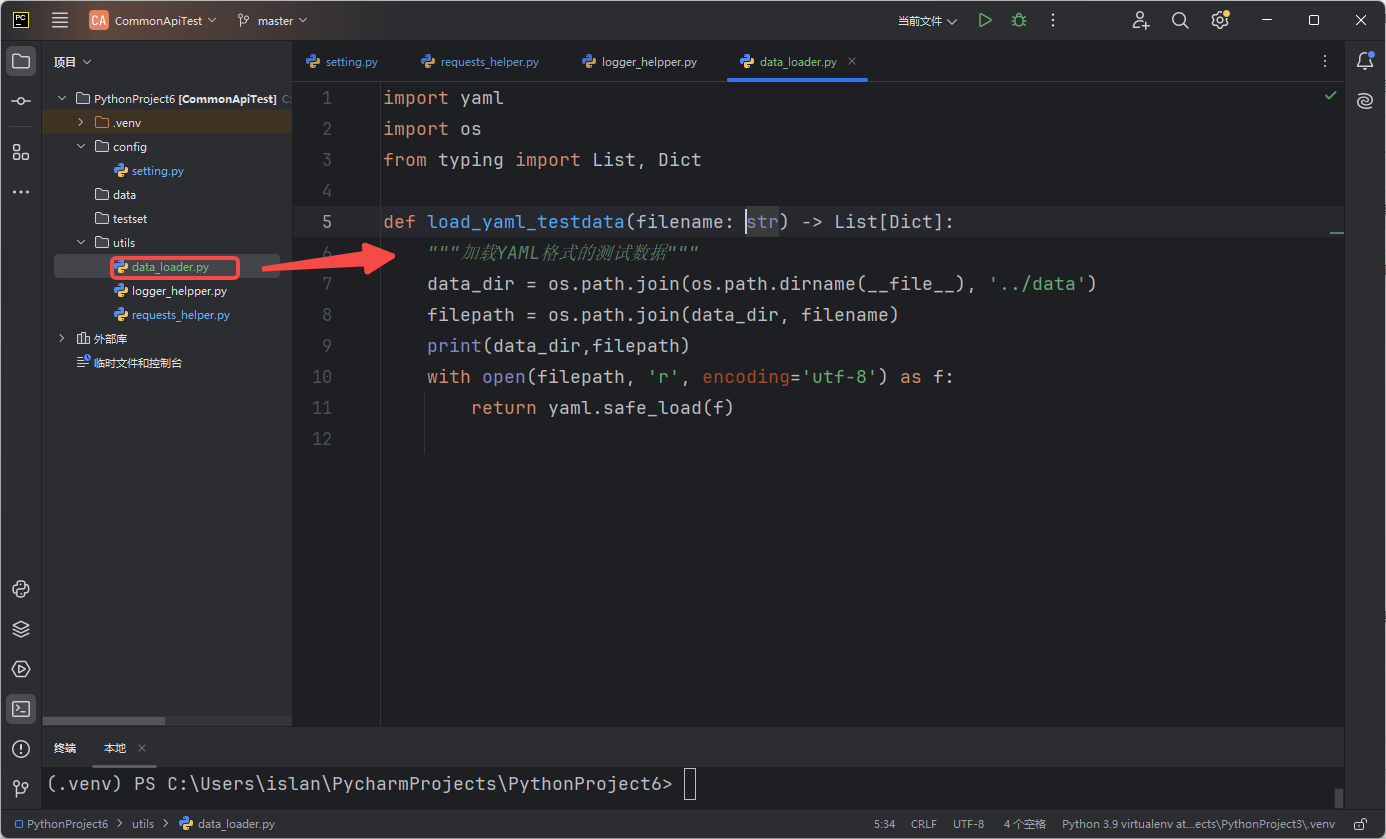
import yaml
import os
from typing import List, Dict
def load_yaml_testdata(filename: str) -> List[Dict]:
"""加载YAML格式的测试数据"""
data_dir = os.path.join(os.path.dirname(__file__), '../data')
filepath = os.path.join(data_dir, filename)
print(data_dir,filepath)
with open(filepath, 'r', encoding='utf-8') as f:
return yaml.safe_load(f)不过总的来说
你可以把 `data_loader.py` 想象成一个 "数据搬运工" 。
它的主要工作就是:
去 data 文件夹里找数据 : 你的测试用例需要各种数据才能运行,比如登录的用户名密码、商品的价格、订单的详情等等。这些数据都放在了 data 文件夹里,而且是用一种叫做 YAML 的文件格式写的(就像一个清单)。
把数据读出来: 这个"数据搬运工"会打开你指定的 YAML 文件,把里面的数据一行一行地读出来。
把数据整理好,交给测试用例 : 读出来的数据它会整理成 Python 能理解的格式(通常是字典和列表),然后交给你的测试用例去使用。
为什么需要这个"数据搬运工"呢?
让测试代码更干净 : 如果把所有测试数据都写在测试代码里,代码会变得又长又乱。有了"数据搬运工",测试代码就只管测试逻辑,数据的事情交给它。
一个测试跑多组数据 : 比如你想测试登录功能,用不同的用户名密码都试一遍。你可以在 YAML 文件里写好几组用户名密码,然后"数据搬运工"会把它们一组一组地拿给测试用例去跑,非常高效。
`data_loader.py` 就是帮你把测试需要的数据,从专门存放数据的文件里,方便、安全地取出来。
测试框架基础(confest.py、pytest.ini)
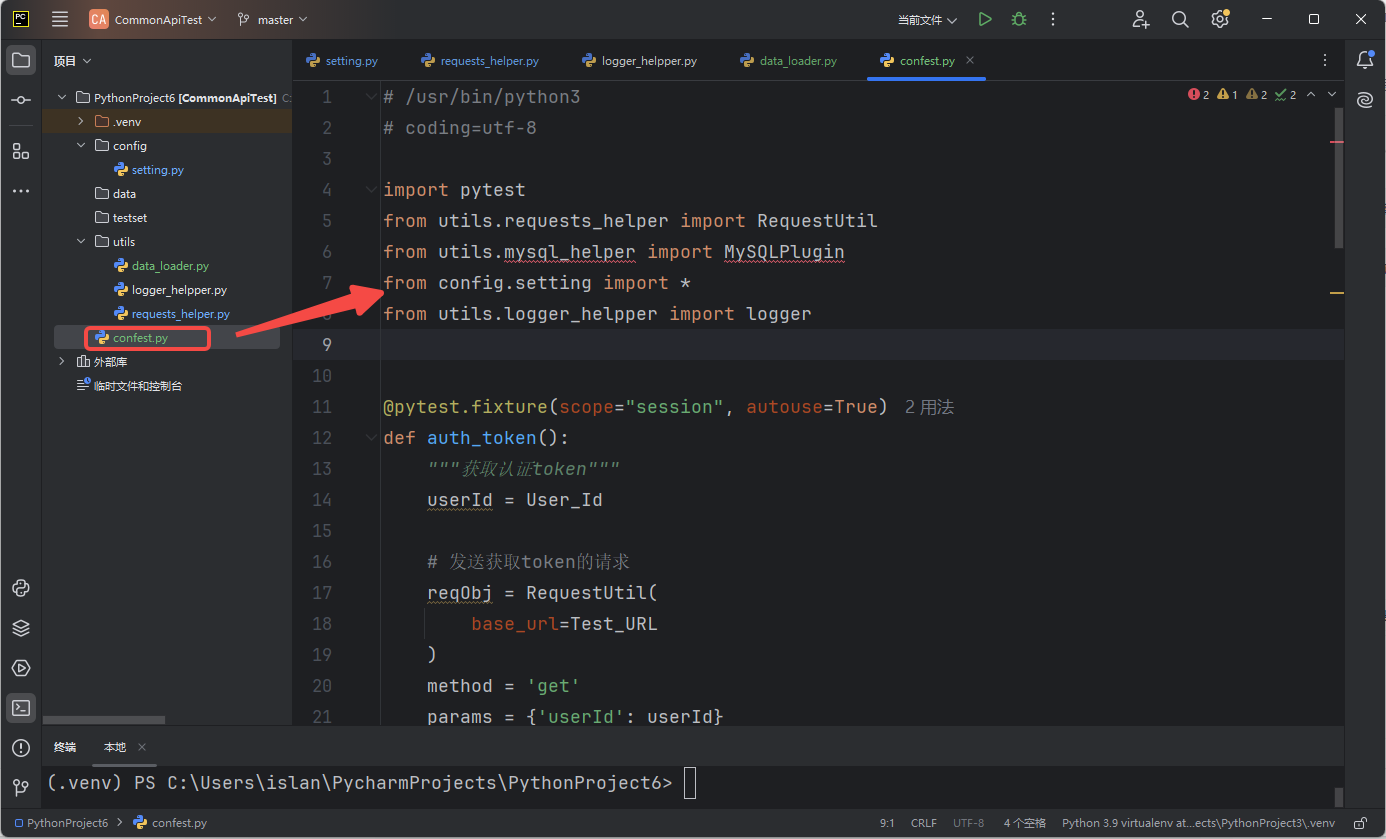
import pytest
from utils.requests_helper import RequestUtil
from utils.mysql_helper import MySQLPlugin
from config.setting import *
from utils.logger_helpper import logger
@pytest.fixture(scope="session", autouse=True)
def auth_token():
"""获取认证token"""
userId = User_Id
# 发送获取token的请求
reqObj = RequestUtil(
base_url=Test_URL
)
method = 'get'
params = {'userId': userId}
try:
response = reqObj.send_request(method, endpoint=Auth_URL, params=params)
if response.status_code == 200:
token = response.json().get('data', {})
# logger.debug(f"Token Info: {token}")
return token
except Exception as e:
# logger.error(f"获取token失败: {str(e)}")
pytest.fail(f"获取token失败: {str(e)}")
@pytest.fixture(scope="session", autouse=True)
def api_client(auth_token: str):
"""创建带有认证token的请求客户端"""
# 完成请求头的设置
headers = {
'Content-Type': 'application/json',
'Authorization': f"Bearer {auth_token}"
}
# 创建客户端实例
client = RequestUtil(
base_url=Test_URL,
default_headers=headers,
timeout=30
)
yield client
# 测试结束后可以在这里添加清理逻辑
logger.debug("测试结束,清理请求客户端")
def pytest_sessionfinish(session):
"""修正后的测试结果统计"""
# 获取终端报告器
reporter = session.config.pluginmanager.get_plugin('terminalreporter')
# 统计实际失败数(排除标记允许失败的用例)
actual_failures = 0
if reporter:
actual_failures = len(reporter.stats.get('failed', []))
logger.debug(f"实际失败用例数: {actual_failures}")
# 设置退出码(保留原始退出码逻辑)
session.exitstatus = 1 if actual_failures == 0 else 1
@pytest.fixture(scope="session", autouse=True)
def mysql_client():
config = {
"host": DB_Host,
"user": DB_User,
"password": DB_Pwd,
"port": DB_Port,
"database": DB_Schema,
}
client = MySQLPlugin(config=config)
yield client
# 测试结束后可以在这里添加清理逻辑
client.close()
logger.debug("测试结束,关闭所有数据库连接池")confest.py 中所定义的 fixture 和 hook,它们提供了测试前置条件和后置清理的能力。
具体来说,fixture是提供共享的测试资源和功能,他要做的有很多,比如登录凭证、数据库连接、HTTP 客户端等,这些是很多测试用例都需要用到的东西。
hook则是定义测试生命周期中的钩子函数(Hooks): 在测试开始前、结束后,或者在收集测试用例时执行一些特定的操作。
同时,
我们同样在confest.py 中看到导入了对应的mysql_helpper.py,
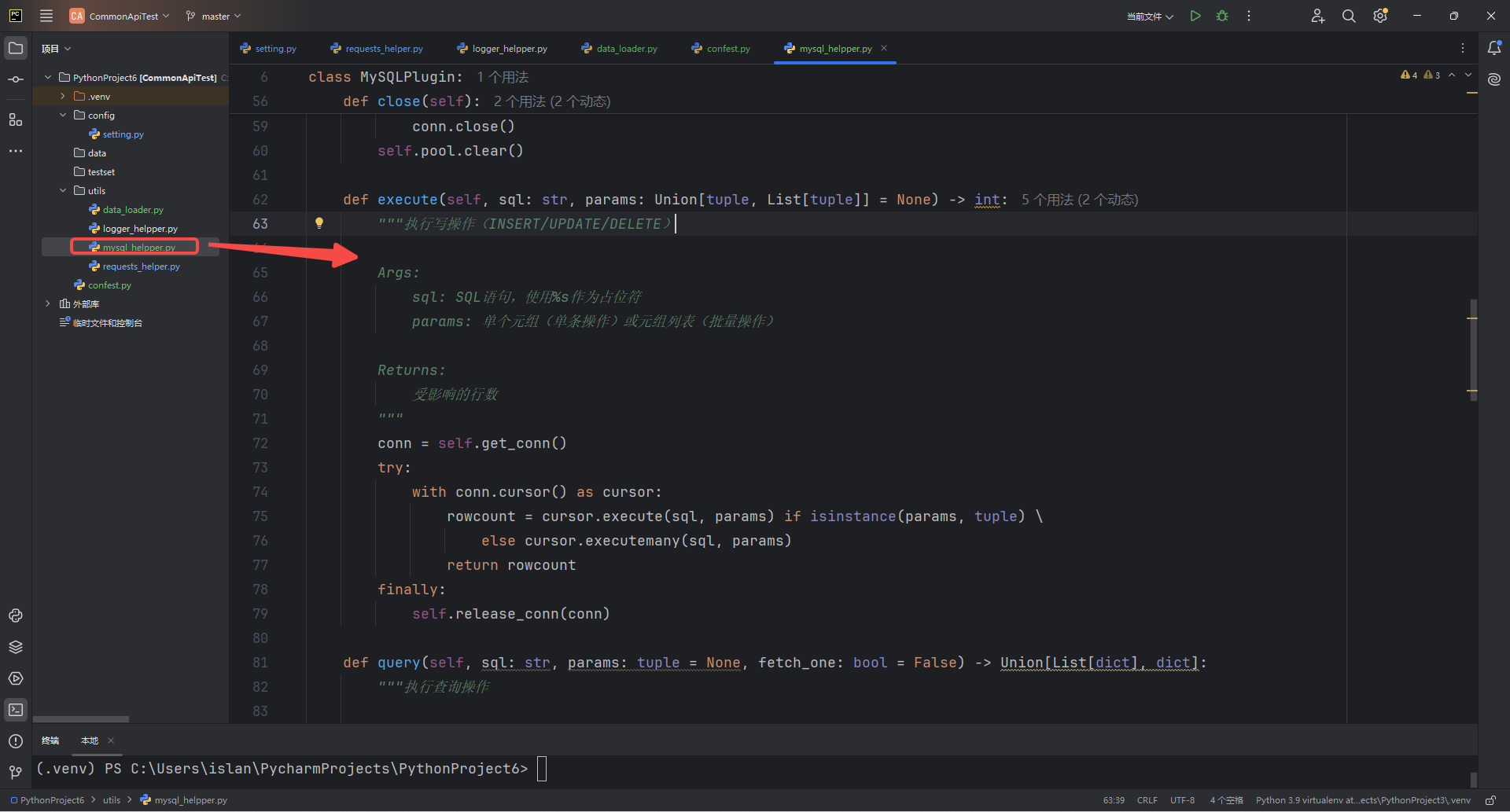
import pymysql
from pymysql import cursors
from typing import Union, List, Dict, Any
class MySQLPlugin:
"""MySQL数据库操作插件
功能特性:
- 支持连接池管理
- 自动提交事务机制
- 类型提示和参数化查询
- 灵活的查询结果返回格式
- 上下文管理器支持
示例配置:
config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'secret',
'database': 'my_db',
'pool_size': 5
}
"""
def __init__(self, config: dict):
self.config = config
self.pool = []
self._create_pool()
def _create_pool(self):
"""创建连接池"""
for _ in range(self.config.get('pool_size', 3)):
conn = pymysql.connect(
host=self.config['host'],
port=self.config['port'],
user=self.config['user'],
password=self.config['password'],
database=self.config['database'],
cursorclass=cursors.DictCursor,
autocommit=True
)
self.pool.append(conn)
def get_conn(self):
"""从连接池获取连接"""
if not self.pool:
self._create_pool()
return self.pool.pop()
def release_conn(self, conn):
"""归还连接到连接池"""
self.pool.append(conn)
def close(self):
"""关闭连接池"""
for conn in self.pool:
conn.close()
self.pool.clear()
def execute(self, sql: str, params: Union[tuple, List[tuple]] = None) -> int:
"""执行写操作(INSERT/UPDATE/DELETE)
Args:
sql: SQL语句,使用%s作为占位符
params: 单个元组(单条操作)或元组列表(批量操作)
Returns:
受影响的行数
"""
conn = self.get_conn()
try:
with conn.cursor() as cursor:
rowcount = cursor.execute(sql, params) if isinstance(params, tuple) \
else cursor.executemany(sql, params)
return rowcount
finally:
self.release_conn(conn)
def query(self, sql: str, params: tuple = None, fetch_one: bool = False) -> Union[List[dict], dict]:
"""执行查询操作
Args:
fetch_one: 是否只获取第一条结果
"""
conn = self.get_conn()
try:
with conn.cursor() as cursor:
cursor.execute(sql, params)
return cursor.fetchone() if fetch_one else cursor.fetchall()
finally:
self.release_conn(conn)
# 以下是快捷方法
def insert(self, table: str, data: dict) -> int:
"""插入单条数据"""
columns = ', '.join(data.keys())
placeholders = ', '.join(['%s'] * len(data))
sql = f"INSERT INTO {table} ({columns}) VALUES ({placeholders})"
return self.execute(sql, tuple(data.values()))
def update(self, table: str, updates: dict, where: str, where_params: tuple) -> int:
"""更新数据"""
set_clause = ', '.join([f"{k} = %s" for k in updates])
sql = f"UPDATE {table} SET {set_clause} WHERE {where}"
return self.execute(sql, tuple(updates.values()) + where_params)
def delete(self, table: str, where: str, where_params: tuple) -> int:
"""删除数据"""
sql = f"DELETE FROM {table} WHERE {where}"
return self.execute(sql, where_params)
# 事务支持
def begin_transaction(self):
"""开启事务"""
conn = self.get_conn()
conn.autocommit(False)
return conn
def commit(self, conn):
"""提交事务"""
conn.commit()
self.release_conn(conn)
def rollback(self, conn):
"""回滚事务"""
conn.rollback()
self.release_conn(conn)
# 上下文管理器支持
def __enter__(self):
self.conn = self.begin_transaction()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type:
self.rollback(self.conn)
else:
self.commit(self.conn)
# 数据库相关内容填写
if __name__ == "__main__":
DB_Host = ""
DB_User = ""
DB_Pwd = ""
DB_Port = 3
DB_Schema = ""
config = {
"host": DB_Host,
"port": 3,
"user": DB_User,
"password": DB_Pwd,
"database": DB_Schema,
"pool_size": 3
}
db = MySQLPlugin(config)在攥写这个页面的代码时,相当于你是一个DBA ,你要做到包括能够连接数据库、连接池管理、执行SQL语句、事务管理、结果处理(字典格式)、错误处理、易用性 。其中连接池管理就是意味着每次应该不是新建连接,而是维护一个连接池,重复利用连接;
这个功能有点类似于java的JDBC。
pytest.ini 是 Pytest 测试框架的配置文件。你可以把它想象成 Pytest 的 "使用说明书" 或者 "设置面板" ,比如:
-
去哪里通过修改这个文件,你可以告诉 Pytest 怎么运行你的测试找测试文件?
-
测试报告怎么生成?
-
哪些测试用例需要特殊标记?
[pytest]
addopts = -vs --alluredir=./allure-results --clean-allurediraddopts = -vs
testpaths = ./testset/
;python_files = test_xxx.py
python_classes = Test*
python_functions = test_*markers =
app: 小程序模块测试
business: 业务模块测试
common: 公共模块测试
mall: 商城模块测试
manager: 管理模块测试
product: 商品模块测试
task: 任务模块测试
smoke: 冒烟测试
performance: 性能测试
not_ready: 未完成的接口测试
sqlcheck: 数据库校验
代码当中:
addopts = -vs --alluredir=./allure-results --clean-alluredir与生成Allure报告相关
testpaths、files这些告诉了我们测试用例存放的位置
markers 就是自定义的测试注解,给相关的测试函数打上标签