简介
【Xmind思维导图】行人重识别 https://ai.xmind.cn/share/tKN4Ny6M
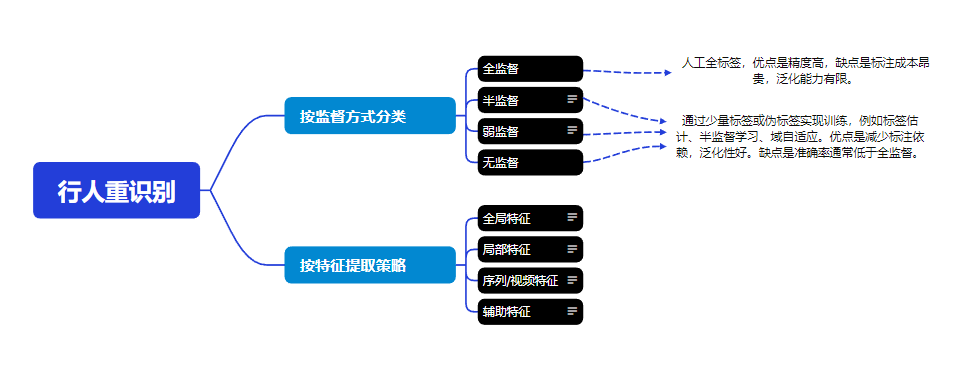
ReID 全称行人重识别(P-edestrian Re-identification,ReID),其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。上述为两种传统的分类方法。
按监督方式
简述
在机器学习兴起的时期,大多数行人重识别方法都依赖人工标注的数据标签 ,通过监督学习 来驱动模型训练。这类方法往往能够获得较高的识别准确率,但标注过程费时费力,效率低下,并且由于模型在固定数据上的过度拟合,泛化能力往往不足。随着深度神经网络的快速发展,行人重识别进入了深度学习主导的阶段 ,监督学习方法成为主流,大量工作集中在全局特征、局部特征、时序特征以及注意力机制等方面的优化,进一步推动了识别精度的提升。然而,监督学习的瓶颈在于对大规模、精细化标注数据的依赖,这在实际应用场景中代价高昂。为此,研究者逐渐探索弱监督和无监督的方法,通过伪标签估计、半监督学习或跨域自适应等策略来减少对人工标注的依赖。这类方法虽然在精度上尚未全面超越全监督,但在提升模型泛化性、降低数据标注成本方面展现出巨大的潜力,成为未来的重要发展方向。
疑问
监督学习中特征表示学习和深度度量学习是什么?
- 定义:
特征表示学习(又名表征学习,Feature Representation Learning / Feature Representation Learning)指从原始数据(图像、语音、振动信号等)中自动学习一个低维、可区分的表示(representation),使得这些表示能够更好地服务于分类、聚类、回归等任务。
深度度量学习定义是在深度学习框架下学习一个"度量函数 (metric function)"或嵌入空间,使得:
-
相同类别样本之间的距离尽可能小
-
不同类别样本之间的距离尽可能大
- 目标:
特征表示学习:
-
提取能够区分不同类别的特征
-
压缩数据维度,去除冗余和噪声
-
让"相似数据"在特征空间中靠近,"不相似数据"分开
深度度量学习:
不是单纯做分类,而是让特征空间本身具有良好的几何结构,方便后续检索、聚类、匹配。
3.区别与联系
| 对比维度 | 特征表示学习 | 深度度量学习 |
|---|---|---|
| 关注点 | 学到"什么样的特征"能表示数据 | 学到"特征之间的距离/相似性"如何衡量 |
| 目标 | 提取判别性、鲁棒性的表示 | 让嵌入空间几何结构更合理 |
| 任务导向 | 可用于分类、聚类、生成等广泛任务 | 主要用于检索、匹配、验证任务 |
| 方法关系 | 表示学习是基础 | 度量学习是在表示学习基础上优化"相似性" |
| 举例 | CNN 提取图像 embedding | Triplet Loss 优化 embedding 间距离 |
深度度量学习一定包含表征学习 ,但它在表征学习的基础上 进一步优化了度量关系。
可以说监督学习=表征学习吗?
全监督学习 ≠ 表征学习 。它们有交叉,但不是等价关系。
交集:
-
在全监督学习中,常常隐含着表征学习。例如 CNN 在做图像分类时,前几层卷积其实就是在学习"表征";最后一层 softmax 才是分类器。
-
所以很多深度监督模型 = 分类 + 表征。
区别:
-
全监督 ≠ 必然有好表征
模型可能过拟合标签,而学不到通用特征。
-
表征学习 ≠ 一定需要全监督
表征学习可以是无监督(自编码器、对比学习)、半监督、弱监督。
-
目标不同
全监督:最小化预测误差。表征学习:得到可迁移、可区分、鲁棒的表示。
总结类比:
-
全监督学习:老师给标准答案,你只要学会考试答对题就行。
-
表征学习:你要学会"解题方法",不仅能答这套题,还能迁移到新题。
弱监督和半监督的区别?
数据标签方面:半监督学习的数据是少量精确标签 和大量无标签 ,弱监督学习是标签不完整/不精细/有噪声。
问题类型方面:半监督主要应对的问题是如何利用无标签样本 ,而弱监督是为了研究如何处理低质量标签。
两者关系:半监督是弱监督的一种"不完整监督"情况,理论上弱监督范围更大且涵盖半监督在内。
学术界一般把 弱监督 (Weakly Supervised Learning, WSL) 分为三类:
-
不完整监督 (Incomplete Supervision)
-
只有一部分样本有标签,大部分没有。
-
典型:半监督学习 (Semi-Supervised Learning)。
-
例子:1000 张图片里,只有 100 张标注了类别,剩下 900 张无标签。
-
-
不精确监督 (Inexact Supervision)
-
所有样本有标签,但标签粒度不够细。
-
例子:医学影像数据,标签只告诉你"这张 CT 有肿瘤",但没标出肿瘤的精确位置。
-
多实例学习 (Multiple Instance Learning, MIL) 就是这种情况。
-
-
不准确监督 (Inaccurate Supervision)
-
所有样本有标签,但部分标签是错误的(噪声标签)。
-
例子:网络爬虫自动抓取的图像,有的"狗"图片其实是"猫"。
-
一句话记忆:
半监督:监督很少,但很"干净"。
弱监督:监督不少,但"不够好"。
弱监督和无监督面临的主要问题?
弱监督 = 监督信号存在但不完整/不精确/不准确,因此核心挑战主要有:
1. 标签噪声问题
弱监督常依赖自动标注、众包标注或迁移标注,标签容易出错。
噪声标签会误导模型,导致过拟合"错误模式"。
2. 标签粒度不足
只能得到粗粒度标签(如"这张影像有肿瘤",但没有具体位置)。
模型难以从粗标签中学习到细粒度特征。
3. 数据分布不均衡
真实环境中,异常/故障样本远少于正常样本。
少量弱监督样本可能不足以代表真实分布,影响泛化性能。
4. 模型训练稳定性差
弱监督信号本身有缺陷,可能导致训练过程不稳定。
需要设计鲁棒的损失函数或正则化手段来缓解。
5. 可解释性问题
弱监督模型往往依赖隐含特征或对齐机制,难以解释模型如何从"不完全/不精确"信息中学习到有效模式。
无监督 = 完全没有标签,依靠数据的结构或相似性来学习。挑战主要有:
1. 缺乏明确监督信号
没有标签作为"标准答案",模型学习目标不明确。
很难验证聚类或特征学习的结果是否"正确"。
2. 聚类结果可解释性差
模型可能学到"数学上的簇",但未必对应有意义的类别。
难以直接用于实际决策。
3. 模式易受噪声干扰
无监督方法对数据质量敏感,噪声点可能严重影响聚类/特征学习。
4. 评估困难
没有标签时,如何评价模型性能是个难题。
只能依赖内部指标(如轮廓系数)或间接验证。
5. 对超参数敏感
聚类数目 (k)、相似度度量方式等对结果影响很大。
缺乏统一的调参依据。
一句话记忆:
弱监督 的问题是 "监督信号质量不够好"。
无监督 的问题是 "完全没有监督信号"。
按特征提取方式
简述
在早期的行人重识别研究中,研究者通常依赖全局特征 ,即将整张行人图像编码为一个向量来进行匹配。这类方法实现简单,并在小规模数据集上表现良好,但在面对姿态变化、光照差异和遮挡时,往往难以保持鲁棒性。随着研究的深入,人们逐渐意识到单一的全局特征难以全面表达行人信息,于是提出了局部特征学习 的思路,例如通过人体水平分割或姿态估计,将图像划分为若干区域,从而捕捉更具判别性的细节特征。这种方法有效缓解了遮挡和姿态差异带来的影响。与此同时,视频序列特征学习 逐渐受到关注,通过引入时序建模、步态特征以及循环神经网络,能够在连续帧中提取运动信息,使得表示更加贴近真实监控场景。进一步地,辅助特征与多模态方法被引入,例如人体属性、语义信息、文本描述乃至生成对抗网络(GAN)生成的数据,以丰富特征表达、缓解数据稀缺和风格差异问题。总体来看,特征提取方式的演进体现了从单一、粗粒度的表征到多源、细粒度、多模态的融合,显著提升了ReID模型在复杂场景下的鲁棒性与泛化能力。
疑问
注意力机制学的是全局特征还是局部特征?
注意力机制(Attention Mechanism)到底学的是 全局特征 还是 局部特征,要看它的具体设计与应用。
很多人刚接触"注意力机制 (Attention Mechanism)"时,会以为它就是模仿人类注意力,把"重要的特征"挑出来。但实际上,注意力中的"注意"并不是直接在学"特征" ,而是一种 加权信息交互机制。
注意力机制本质上是一种自适应特征建模方式。在标准自注意力中,每个位置都与全局进行交互,因而侧重于全局特征的建模;而在局部注意力或窗口化注意力中,注意力权重仅限于邻域范围,从而侧重于局部特征的学习。实际应用中,往往结合全局与局部注意力,以同时捕捉细粒度特征与长程依赖关系。
1. 标准注意力机制(Self-Attention, Transformer里用的)
-
核心思想:每个位置的表示,都和所有位置的表示计算相关性(点积或加权和)。
-
结果:
-
它能够捕捉 全局依赖关系,因为任何一个位置都能"看见"全局。
-
特别适合处理长序列、全局模式(比如一句话中远距离词之间的依赖)。
-
-
结论 :标准 self-attention 偏 全局特征学习。
2. 局部注意力(Local Attention / Window Attention)
-
在一些任务中(如图像识别、视频建模),只对邻近区域计算注意力。
-
结果:
-
关注的是局部范围内的依赖关系,类似于卷积提取局部特征。
-
比如 Swin Transformer 用滑动窗口注意力,学到的是局部+层次化特征。
-
-
结论 :局部注意力偏 局部特征学习。
3. 混合式(Global + Local Attention)
-
现实应用常常结合:
-
局部注意力 → 保留空间/时间上的细节(局部纹理、短时冲击信号)
-
全局注意力 → 发现长距离依赖和整体模式(整体工况趋势)
-
-
在故障诊断里:
-
局部注意力能抓住振动信号中的 瞬时冲击特征
-
全局注意力能建模 周期性模式或跨时间依赖
-
多模态和跨模态的区别?
| 维度 | 多模态 (Multimodal) | 跨模态 (Cross-modal) |
|---|---|---|
| 核心问题 | 如何 融合 不同模态的信息 | 如何 对齐/转换 不同模态的信息 |
| 数据输入 | 同时有多模态(图像+文本+信号) | 主要输入一个模态,目标在另一个模态 |
| 典型任务 | 多模态分类、情感分析、诊断 | 跨模态检索、翻译、生成 |
| 举例 | 列车振动+温度信号联合诊断 | 振动信号 → 故障文字标签 |