一、PostgreSQL 基础存储逻辑(TimescaleDB 继承此机制)
TimescaleDB 是 PostgreSQL 的扩展,因此数据文件的底层存储逻辑完全继承 PostgreSQL。在 PostgreSQL 中:
-
每个数据库对应
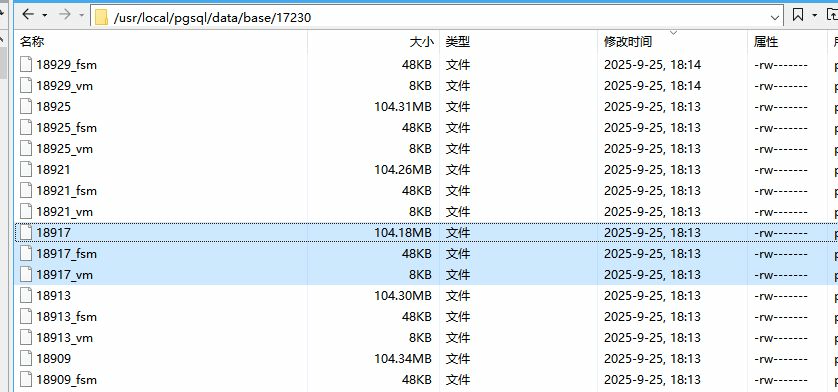
$PGDATA/base/<数据库 OID>目录(截图中路径为/usr/local/pgsql/data/base/17230,17230是数据库的 OID)。 -
每个表(包括超表、普通表、分块后的 Chunk)对应一个关系文件节点(relfilenode) ,存储在数据库目录下的子目录中,子目录名即 relfilenode(如截图中的
18925、18917等)。
二、TimescaleDB 超表的"物理分块"特性
TimescaleDB 超表的核心是水平分块(Chunking) :超表会被按时间范围(或其他维度)拆分为多个Chunk,每个 Chunk 是一个独立的 PostgreSQL 表(在底层存储上与普通表无差异)。
因此,超表的"物理存储"本质是多个 Chunk 对应的 PostgreSQL 表的集合,每个 Chunk 都有自己的 relfilenode 和数据文件。
三、数据文件类型及作用(以截图为例)
截图中展示了多个文件,核心类型包括主数据文件 、_fsm文件、_vm文件,以下逐一解释:
1. 主数据文件(如 18925、18917等)
-
作用 :存储表的行数据,是表的核心存储载体。
-
结构:
-
PostgreSQL 页面大小默认 8KB,数据文件按"页面"组织,每个页面存储若干行数据。
-
单个数据文件最大为 1GB(可通过参数调整),超过 1GB 时会自动生成分片文件 (如
18925.1、18925.2...),每个分片仍为 1GB 内。
-
-
示例 :截图中
18925大小为 104.31MB,是某张表(或 Chunk)的主数据文件,存储该对象的实际行数据。
2. _fsm文件(如 18925_fsm、18917_fsm)
-
全称:Free Space Map(空闲空间映射)。
-
作用 :跟踪数据文件中哪些页面有空闲空间,帮助 PostgreSQL 高效分配存储(如 INSERT 时快速找到有足够空间的页面,避免频繁页面分裂)。
-
特性:
-
每个主数据文件对应一个
_fsm文件。 -
文件大小固定为 8KB(与 PostgreSQL 页面大小一致,按"页面"管理空闲空间信息)。
-
3. _vm文件(如 18925_vm、18917_vm)
-
全称:Visibility Map(可见性映射)。
-
作用 :记录数据文件中哪些页面的所有元组对所有事务可见(即已提交且未被后续事务修改)。
-
特性:
-
每个主数据文件对应一个
_vm文件。 -
加速
VACUUM(跳过无需清理死元组的页面)和查询(跳过需检查可见性的页面),提升性能。 -
文件大小固定为 8KB(同页面大小)。
-
四、TimescaleDB 超表的文件"映射关系"
超表 → 多个 Chunk(每个 Chunk 是 PostgreSQL 表)→ 每个 Chunk 对应一套数据文件(主数据文件 + _fsm+ _vm+ 可能的分片文件)。
例如:
-
超表
metrics按时间分块为chunk_2023Q1、chunk_2023Q2... -
chunk_2023Q1对应 relfilenode18925,其文件为18925(主数据)、18925_fsm、18925_vm... -
chunk_2023Q2对应 relfilenode18917,其文件为18917(主数据)、18917_fsm、18917_vm...
五、额外补充:元数据与索引文件
除了上述数据文件,TimescaleDB 超表还涉及:
-
系统表元数据 :超表的定义(如分块策略、维度列)存储在
_timescaledb_catalog模式的系统表中(如hypertables、chunks)。 -
索引文件:超表的索引(如时间索引、哈希索引)也以独立 PostgreSQL 表存在,对应自己的 relfilenode 和数据文件(结构与普通表一致)。
总结
TimescaleDB 超表的数据文件本质是多个 PostgreSQL 表(Chunk)的文件集合,每个 Chunk 包含:
-
主数据文件(存储行数据,超 1GB 分片);
-
_fsm文件(空闲空间管理); -
_vm文件(可见性优化)。
这种设计既复用了 PostgreSQL 成熟的存储引擎,又通过"分块"实现了时序数据的高效水平扩展。