📚 Repo Wiki 是 Qoder 平台的核心功能之一,它能够自动为代码仓库生成结构化的技术文档,包括工程架构、模块关系、API 手册等,并持续跟踪代码变更以保持文档的时效性。以下是其详细原理及工作流程的解析:
一、Repo Wiki 的核心功能
1.自动文档生成
Repo Wiki 通过扫描代码仓库,自动提取以下内容:
- 架构图谱 :项目整体结构、模块划分和技术栈。
- 依赖关系 :模块间的调用和依赖关系(如数据库、API、第三方服务)。
- 核心代码解读 :关键类、方法的功能说明(例如生成流程图、UML 图)。
- 隐性知识显性化 :将设计决策、历史变更原因等隐含知识转化为结构化文档。
2.持续跟踪与同步
-
当代码提交(Git HEAD 变更)时,Repo Wiki 会触发增量更新,仅分析修改部分,智能合并新旧知识,确保文档与代码一致。
-
支持手动编辑和自定义文档内容,同时通过自动检测机制提醒用户更新滞后文档。
3.协作与共享
- 文档可导出为 Markdown 或推送至 Git 仓库,实现团队共享和协作编辑。
二、生成原理与技术流程
Repo Wiki 的生成过程分为四个核心阶段,其工作原理如下图所示:
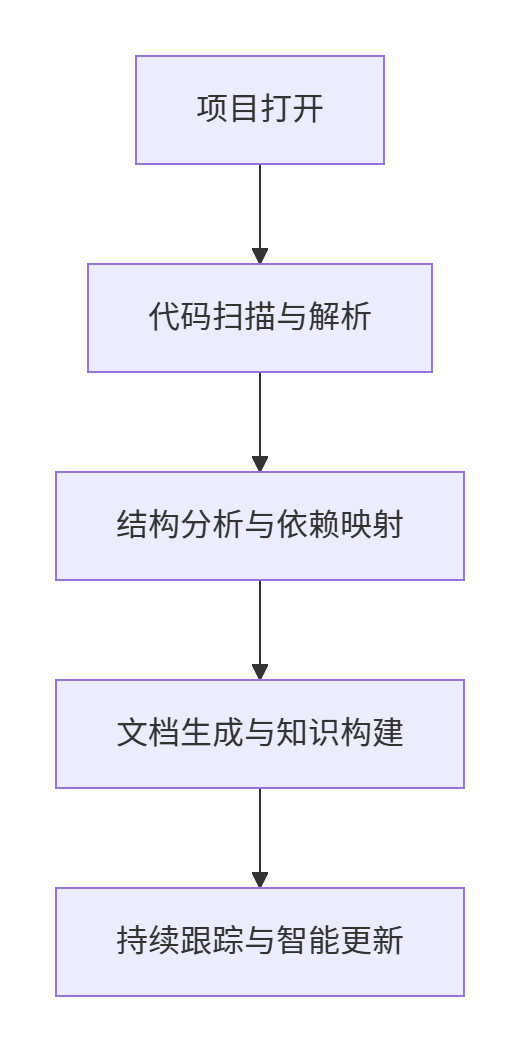
1.项目分析与代码扫描
-
触发条件 :首次打开项目或 Git 提交时自动启动。
-
扫描范围 :解析所有代码文件(支持最多 6,000 个文件),忽略构建产物等无关文件(通过
.gitignore优化)。 -
技术实现:基于静态代码分析技术,提取语法树(AST)、依赖关系(如 import 语句)、注释和代码逻辑。
2.结构分析与依赖映射
-
架构理解:识别项目整体架构(如微服务、单体应用)和设计模式。
-
依赖图谱构建:生成模块间调用关系图(例如使用 Graphviz 或 Mermaid 图表),标注核心业务流程。
-
功能映射 :将代码组件与业务功能关联(例如
UploadController负责文件分片合并)。
3.文档生成与知识构建
-
隐性知识提取:通过代码上下文推断设计决策(例如为什么选择 Kafka 作为消息队列)。
-
多格式输出:生成包含文字说明、流程图、架构图的 Markdown 文档(例如系统上下文图、RAG 实现细节)。
-
存储位置 :文档保存在项目内的
.qoder/wiki目录中,与代码共存。
4.智能更新机制
-
增量分析:仅分析变更文件,减少处理时间。
-
冲突解决:当代码与文档不一致时,自动标记冲突并提示用户处理。
-
记忆系统:结合长短期记忆功能,记录用户偏好和项目历史,优化后续生成。
三、项目分析与代码扫描详解
代码扫描与解析的目标是将源代码文本 转化为计算机可理解和处理的结构化表示 (主要是抽象语法树 - AST 和 符号表 - Symbol Table)。这个过程通常按以下顺序进行:

1.词法分析 (Lexical Analysis)
目标 :将源代码的字符序列 分解成有意义的词法单元。
-
输入 :源代码字符串(如
int sum = a + b;)。 -
输出 :词法单元流。
-
核心算法/技术:
-
正则表达式 (Regular Expressions):定义每种词法单元(Token)的模式。
-
有限状态自动机 (Finite Automata) :实现正则表达式的识别引擎。词法分析器本质上是一个确定有限状态自动机 (DFA)。
-
最长匹配原则 (Longest Match) :当多个模式可能匹配时,选择匹配字符数最多的那个(例如
int是关键字,而不是i、in)。 -
消除歧义规则:处理空格、注释、不同语言的关键字/标识符规则等。
-
过程详解:
-
扫描 (Scanning):逐个字符读取源代码。
-
分类 (Classification):根据预定义的模式(正则表达式)识别字符序列属于哪种词法单元。
-
生成 Token:为识别出的序列生成一个 Token 对象,通常包含:
Token Type:标识符、关键字、字面量、运算符、分隔符等。
Lexeme:匹配到的实际字符串(如 "sum", "+")。
Location:在源代码中的位置(行号、列号)。
示例:
源代码:int sum = a + b;
词法单元流:
[KEYWORD, "int"]
[IDENTIFIER, "sum"]
[OPERATOR, "="]
[IDENTIFIER, "a"]
[OPERATOR, "+"]
[IDENTIFIER, "b"]
[DELIMITER, ";"]Qoder 应用 :Qoder 的词法分析器需要支持多种编程语言的词法规则(如 Python 的缩进、Java 的注解、Go 的 :=)
2.语法分析 (Syntax Analysis / Parsing)
目标 :根据编程语言的语法规则 ,将词法单元流组织成一个层次化的树形结构 ------抽象语法树 (AST)。检查代码结构是否符合语法规范。
-
输入:词法单元流。
-
输出 :抽象语法树 (AST)。
-
理论基础 :形式文法 (通常是上下文无关文法 - Context-Free Grammar, CFG)。
-
核心算法/技术:
-
自顶向下解析 (Top-Down Parsing):
-
递归下降解析 (Recursive Descent Parsing):为每个语法规则编写一个递归函数。易于手动实现,适合较简单的语法。
-
LL 解析器 (LL Parsers) :从左向右读取输入,构建最左推导。使用预测分析表决定使用哪个产生式。常见 LL(1)(向前看 1 个 Token)。
-
-
自底向上解析 (Bottom-Up Parsing):
-
LR 解析器 (LR Parsers):从左向右读取输入,构建最右推导的逆过程。功能强大,能处理更复杂的语法。常见 LR(0), SLR(1), LALR(1), LR(1)。工具如 Yacc/Bison 生成 LALR(1) 解析器。
-
移进-归约 (Shift-Reduce):核心操作是"移进"(将 Token 移入栈)和"归约"(将栈顶符合某产生式右部的符号串替换为该产生式的左部非终结符)。
-
-
过程详解:
-
语法规则定义:使用形式文法(如 BNF, EBNF)描述语言结构。例如:
Statement := VariableDeclaration | ExpressionStatement | ...
VariableDeclaration := Type Identifier ('=' Expression)? ';'
Type := 'int' | 'string' | 'float' | ...
Expression := Identifier | Literal | BinaryExpression | ...
BinaryExpression := Expression Operator Expression
Operator := '+' | '-' | '*' | '/' | ... -
构建语法树:解析器根据语法规则,将 Token 流组合成树节点。AST 节点代表语法结构(如函数声明、变量赋值、循环语句、二元表达式),不包含无关细节(如分号、括号的位置信息通常被丢弃或简化存储)。
-
错误处理:当遇到不符合语法的 Token 序列时,报告语法错误并进行可能的恢复(如跳过 Token 或插入虚拟 Token)
示例:
源代码:int sum = a + b;
简化 AST 结构:
VariableDeclaration
├── Type: "int"
├── Identifier: "sum"
└── Initializer: BinaryExpression
├── LeftOperand: Identifier("a")
├── Operator: "+"
└── RightOperand: Identifier("b")Qoder 应用:Qoder 需要为每种支持的编程语言构建或集成强大的解析器(如使用 Tree-sitter、ANTLR 等解析器生成器,或集成特定语言的官方解析器如 Java Parser、Python ast 模块),生成该语言的 AST。
3.语义分析 (Semantic Analysis)
目标 :在 AST 的基础上,检查代码的含义 是否符合语言规范,并收集相关信息。它关注的是上下文相关的规则。
-
输入:语法正确的 AST。
-
输出 :带丰富语义信息的 AST + 符号表 (Symbol Table)。标记语义错误。
-
核心任务:
-
作用域管理 (Scope Management):建立和维护作用域层级(全局作用域、函数作用域、块作用域),确定标识符在哪个作用域有效。
-
符号表构建 (Symbol Table Construction):
-
符号定义 :遍历 AST,遇到声明(变量、函数、类、参数等)时,在当前作用域 的符号表中添加条目。条目包含名称、类型、种类(变量/函数/类)、作用域、定义位置等信息。
-
符号引用 :遇到使用标识符(如变量名、函数调用)时,在符号表中查找该标识符的声明。查找通常从当前作用域开始,逐级向外(父作用域)查找,直到找到或报错。
-
-
类型检查 (Type Checking):
-
类型推导 (Type Inference) :在可能的情况下自动推导表达式或变量的类型(如
var x = 10;推导x为int)。 -
类型兼容性检查 :检查赋值、函数调用参数传递、运算符操作等是否符合类型规则(如不能将
string赋值给int,函数调用参数类型和数量是否匹配)。
-
-
其他语义规则检查:
-
变量是否在使用前声明并初始化?
-
函数是否有返回值?返回值类型是否匹配?
-
循环内
break/continue是否在合法位置? -
类是否实现了所有接口方法?
-
访问控制(
public/private)是否合规?
-
-
符号表示例:
作用域层级:
Global Scope
├── Symbol: ClassA (Class)
├── Symbol: functionX (Function) -> Scope: functionX
│ ├── Symbol: param1 (Parameter, int)
│ ├── Symbol: localVar (Variable, string)
│ └── Inner Block Scope (e.g., inside if)
│ └── Symbol: tempVar (Variable, float)
└── Symbol: globalVar (Variable, double)Qoder 应用 :语义分析是 Qoder 理解代码含义 的关键。符号表帮助 Qoder 准确解析跨文件的引用(如 import/using)、理解变量/函数/类的类型和关系,为后续的依赖映射和架构分析提供坚实基础。类型信息对于推断 API 参数、返回值至关重要。
四、结构分析与依赖映射原理详解
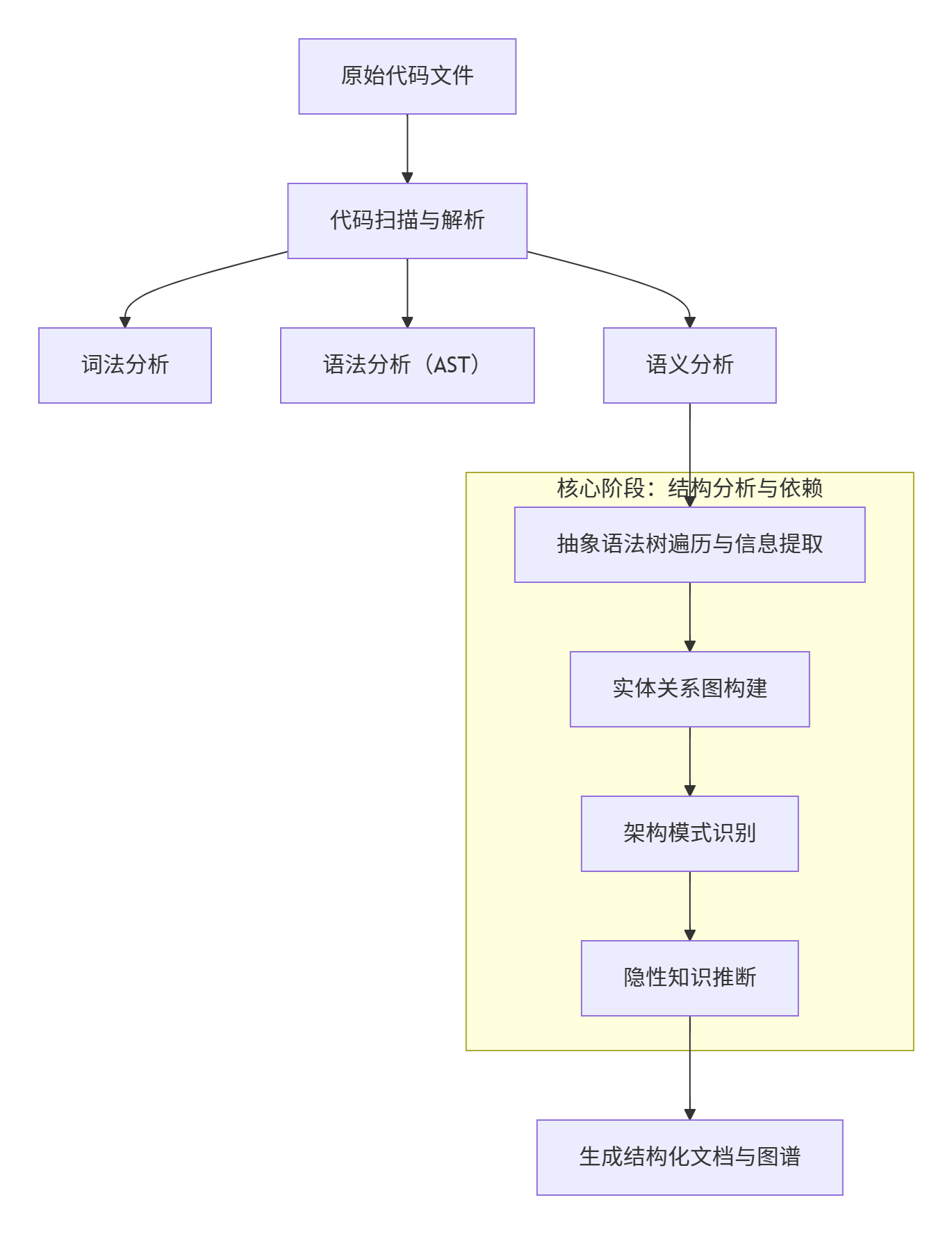
该阶段输入的是上一步"代码扫描与解析"产生的抽象语法树 和符号表 。输出是一个丰富的项目知识图谱。
步骤 1:AST 遍历与实体提取
-
操作:分析器会像游客一样系统地遍历 AST 的每个节点。
-
目标:识别并提取代码中的"实体"(Entities)。
-
模块/包/命名空间 :基于目录结构或
package/namespace声明。 -
类/结构体/接口:识别它们的名称、继承关系、实现的接口。
-
函数/方法:提取其名称、参数列表(类型)、返回值类型。
-
变量/字段/属性:识别其类型和作用域(公共、私有等)。
-
-
结果:获得一个包含所有关键代码实体的列表。
步骤 2:依赖关系映射
这是最核心的一步,目的是回答"谁使用了谁"的问题。分析器通过检查实体的 AST 节点来建立连接。
-
导入(Import)依赖:
-
原理 :分析
import,require,using等语句。 -
例如 :文件
A.py中包含import B,则建立A依赖B的关系。这是最明显、最顶层的依赖。
-
-
类型引用(Type Reference)依赖:
-
原理:在代码体中,当一个实体被用作类型时,即产生依赖。
-
例如:
-
声明一个变量:
B b = new B();(类A依赖类B) -
方法参数或返回值:
public B process(A a) { ... }(方法process依赖类A和B)
-
-
-
函数调用(Function Call)依赖:
-
原理:分析函数调用表达式。
-
例如 :在类
A的方法中调用了类C的method1(),则建立A到C的依赖关系。
-
-
继承与实现(Inheritance & Implementation):
-
原理 :分析
extends,implements,:等关键字。 -
例如 :
class Dog extends Animal,建立Dog到Animal的强依赖("是一个"的关系)。
-
通过以上分析,Qoder 能够在内存中构建一个有向图,其中节点是代码实体,边是它们之间的各种依赖关系。这个图就是项目结构的"数字孪生"。
步骤 3:架构模式识别
在拥有依赖图之后,系统会运用图论算法来分析图的整体形态,从而推断项目的架构。
-
识别模块边界:通过聚类算法(如 Louvain 社区发现算法)找出图中连接密集的节点群。这些群落通常对应一个功能模块或子系统。
-
推断架构风格:
-
分层架构:如果依赖图显示出严格的单向依赖层(如 UI -> Service -> Repository -> Model),系统可推断为分层架构。
-
微服务架构 :如果发现多个独立的、内部高内聚、相互间低耦合的图群落,并且每个群落有自己明确的入口(如
main类),则可推断为微服务架构。 -
插件化架构:如果能识别出一个核心模块(Hub)和多个都依赖于此核心、但彼此独立的模块(Plugins)。
-
步骤 4:隐性知识推断
这是 Qoder 更智能化的体现,它通过启发式规则和模式匹配来推测设计意图。
-
设计模式推测:
-
如果发现一个类持有一个接口类型的字段,并且该接口只有一个实现类,同时在代码中找到了创建该实现类的实例并赋值给接口字段的地方,它可能推断出使用了工厂模式。
-
如果发现一个类的方法实现非常复杂,但被一个更简单的高层方法所调用,它可能提示这里用了模板方法模式。
-
-
核心业务流程梳理:
- 通过跟踪关键实体(如
OrderService)的方法调用链,可以拼接出"创建订单"这个业务流程的大致步骤,即使没有文档说明。
- 通过跟踪关键实体(如
-
技术决策推断:
- 通过分析引入的第三方库(如
@KafkaListener),系统可以知道项目使用了 Kafka 作为消息队列。
- 通过分析引入的第三方库(如
五、应用场景与案例
1.新项目启动
-
自动生成架构图、API 手册和依赖关系文档,帮助团队快速搭建框架。
-
案例:基于 Spring Boot 的照片管理应用,生成上传、预览、下载模块的完整文档。
2.遗留系统维护
-
解析"祖传代码"的逻辑,解决文档缺失问题(例如分析 Elasticsearch 混合检索的 KNN 权重)。
-
案例:在 Kafka 警告日志分析中,Repo Wiki 解释重连机制的正常行为。
3.团队知识沉淀
- 通过共享 Wiki 目录,促进团队成员间的知识传承和协作。
六、优势与局限性
-
优势:
-
降低理解成本:新手可快速掌握复杂项目结构。
-
提升 AI 辅助精度:为 Quest Mode 提供上下文,确保代码生成符合项目规范。
-
-
局限性:
-
文件数量限制(最多 6,000 个文件),需通过忽略目录优化。
-
依赖 Git 仓库,频繁提交可能导致生成中断。
-