AWS下载sentinel-2原始影像
今天我在做一个模型的时候需要保持sentinel-2的原始波段分辨率(10m、20m和60m)。GEE下载的波段都是重采样之后的,因此打算从AWS下载欧空局官方的原始数据。
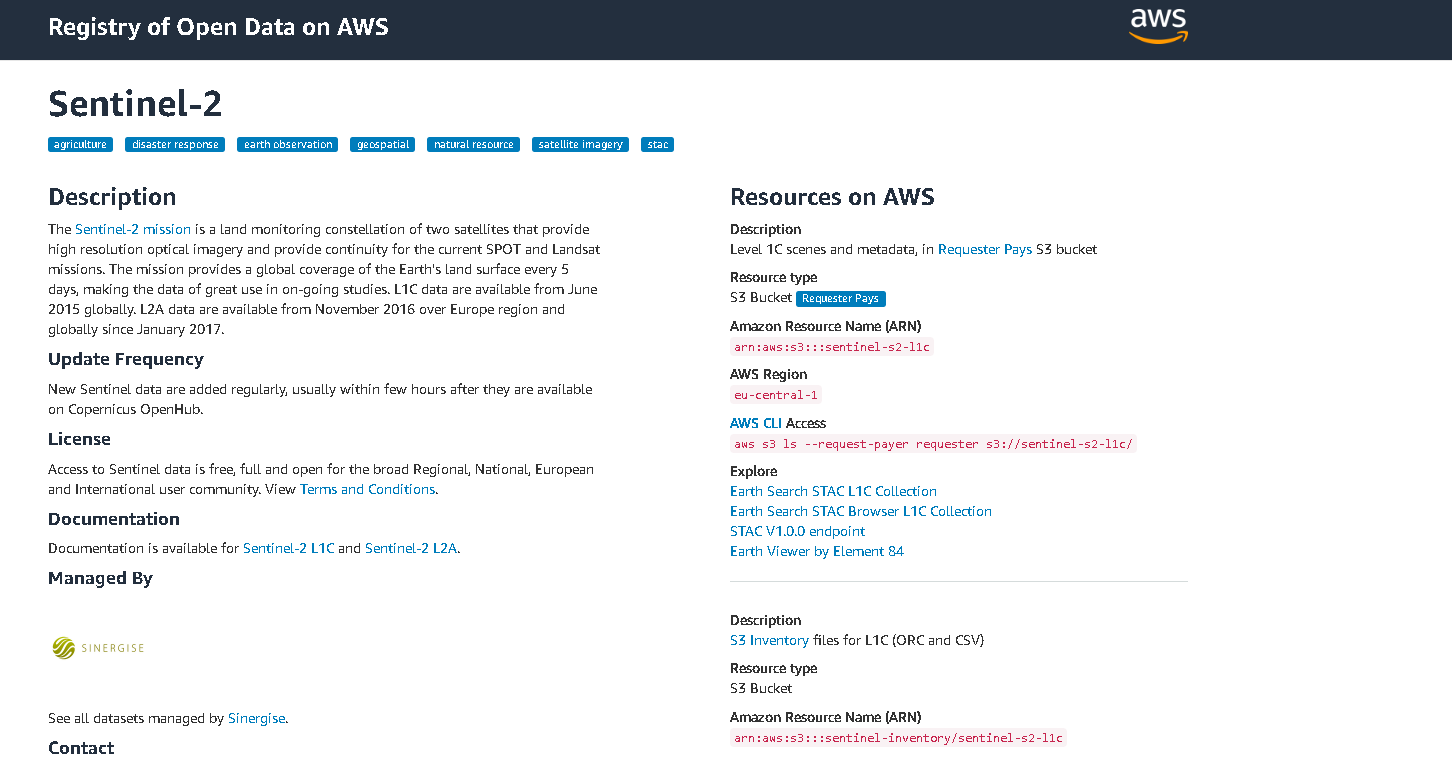
服务器多快,原始数据的下载就有多快。

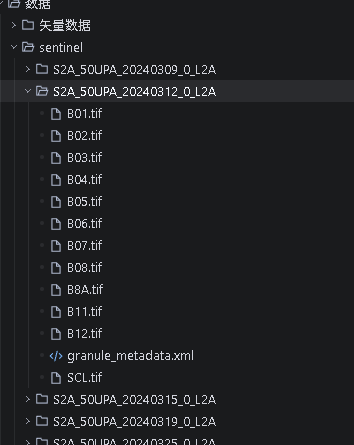
相关代码如下:
python
# -*- coding: utf-8 -*-
"""
Sentinel-2 Level-2A 原始数据下载脚本
功能:从AWS STAC目录搜索并下载Sentinel-2 L2A数据
作者:锐多宝 (ruiduobao)
日期:2025年
"""
import os
import json
import logging
import requests
import sys
import time
import threading
import signal
import hashlib
import random
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
from pystac_client import Client
from tqdm import tqdm
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
from threading import Lock
# =============================================================================
# 1. 下载参数配置
# =============================================================================
# STAC Catalog API 地址,基于AWS文档
STAC_API_URL = "https://earth-search.aws.element84.com/v1/"
# Sentinel-2 L2A 数据集名称
COLLECTION = 'sentinel-2-l2a'
# 您指定的下载条件
START_DATE = "2024-03-01T00:00:00Z"
END_DATE = "2024-10-31T23:59:59Z"
#填入影像行列号
TILE_IDS = ['50UPA', '50UQA', '50UPV', '50UQV']
SATELLITE_PLATFORM = 'sentinel-2a'
# 云量过滤限制(筛选掉云量50%以上的影像)
CLOUD_COVER_LIMIT = 50 # 最大云量百分比
# 您需要下载的波段 (包括对本地处理至关重要的SCL场景分类波段和元数据)
# 使用STAC中的实际资产键名
BANDS_TO_DOWNLOAD = [
'coastal', # B01 - Coastal aerosol
'blue', # B02 - Blue
'green', # B03 - Green
'red', # B04 - Red
'rededge1', # B05 - Red edge 1
'rededge2', # B06 - Red edge 2
'rededge3', # B07 - Red edge 3
'nir', # B08 - NIR
'nir08', # B8A - NIR narrow
'swir16', # B11 - SWIR 1
'swir22', # B12 - SWIR 2
'scl', # Scene Classification Layer
'granule_metadata' # 元数据文件
]
# 本地保存下载数据的主目录 - 修改为用户指定的路径
OUTPUT_DIR = r"K:\sentinel"
# 下载链接保存文件路径
DOWNLOAD_LINKS_FILE = os.path.join(OUTPUT_DIR, "download_links.json")
# 日志文件路径
LOG_FILE = os.path.join(OUTPUT_DIR, "download_log.txt")
# 多进程下载的最大线程数(进一步降低并发数以提高稳定性)
MAX_WORKERS = 1
# 下载进度保存文件路径
PROGRESS_FILE = os.path.join(OUTPUT_DIR, "progress.json")
# 下载重试配置
MAX_RETRIES = 5 # 最大重试次数
RETRY_DELAY_BASE = 2 # 重试基础延迟(秒)
CHUNK_SIZE = 8192 # 下载块大小
TIMEOUT = 30 # 请求超时时间(秒)
REQUEST_INTERVAL = 0.5 # 请求间隔(秒),避免过于频繁的网络请求
# =============================================================================
# 2. 辅助功能函数
# =============================================================================
def safe_paginated_search(search, max_pages=5, timeout_per_page=60, search_name="搜索"):
"""
安全的分页搜索函数,包含超时机制和错误处理
Args:
search: STAC搜索对象
max_pages: 最大页数
timeout_per_page: 每页的超时时间(秒)
search_name: 搜索名称,用于日志显示
Returns:
list: 搜索到的影像列表
"""
items = []
page_count = 0
logger = logging.getLogger(__name__)
try:
for page in search.pages():
page_count += 1
logger.info(f"{search_name} - 正在处理第 {page_count} 页...")
# 使用线程和超时机制获取页面数据
page_items = []
page_error = None
def get_page_items():
nonlocal page_items, page_error
try:
page_items = list(page)
except Exception as e:
page_error = e
# 启动获取线程
thread = threading.Thread(target=get_page_items)
thread.daemon = True
thread.start()
thread.join(timeout=timeout_per_page)
if thread.is_alive():
logger.warning(f"{search_name} - 第 {page_count} 页获取超时 ({timeout_per_page}秒),跳过")
continue
if page_error:
logger.error(f"{search_name} - 第 {page_count} 页获取失败: {str(page_error)}")
continue
items.extend(page_items)
logger.info(f"{search_name} - 第 {page_count} 页获取到 {len(page_items)} 个影像")
if page_count >= max_pages:
logger.info(f"{search_name} - 已达到最大页数限制 ({max_pages}),停止获取")
break
# 添加短暂延迟,避免请求过快
time.sleep(0.5)
except KeyboardInterrupt:
logger.info(f"{search_name} - 用户中断搜索")
except Exception as e:
logger.error(f"{search_name} - 搜索过程中发生错误: {str(e)}")
return items
# 全局会话对象,避免重复创建和询问代理设置
_global_session = None
_session_lock = threading.Lock()
# 全局文件锁和进度锁,确保线程安全
_file_locks = {} # 文件路径 -> 锁对象的映射
_file_locks_lock = Lock() # 保护_file_locks字典的锁
_progress_lock = Lock() # 保护进度数据的锁
def setup_session_with_proxy_and_retry():
"""
设置带有代理和重试机制的requests会话(单例模式)
"""
global _global_session
# 使用线程锁确保线程安全
with _session_lock:
if _global_session is not None:
return _global_session
session = requests.Session()
logger = logging.getLogger(__name__)
# 设置代理(如果需要)
proxy_port = 7890
proxies = {
'http': f'http://127.0.0.1:{proxy_port}',
'https': f'http://127.0.0.1:{proxy_port}'
}
# 检查是否需要使用代理(只询问一次)
use_proxy = input("是否使用代理服务器?(y/n,默认n): ").lower().strip() == 'y'
if use_proxy:
session.proxies.update(proxies)
logger.info(f"已配置代理服务器: 127.0.0.1:{proxy_port}")
else:
logger.info("不使用代理服务器")
# 设置重试策略
retry_strategy = Retry(
total=3, # 总重试次数
backoff_factor=1, # 重试间隔倍数
status_forcelist=[429, 500, 502, 503, 504], # 需要重试的HTTP状态码
allowed_methods=["HEAD", "GET", "OPTIONS"] # 允许重试的HTTP方法
)
# 创建适配器并挂载到会话
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# 设置超时时间
session.timeout = 30 # 30秒超时
_global_session = session
return session
def test_network_connectivity():
"""
测试网络连接性
"""
logger = logging.getLogger(__name__)
logger.info("开始网络连接测试...")
# 测试基本网络连接
test_urls = [
# "https://www.google.com",
"https://earth-search.aws.element84.com/v1/",
"https://aws.amazon.com"
]
session = setup_session_with_proxy_and_retry()
for url in test_urls:
try:
logger.info(f"测试连接: {url}")
response = session.get(url, timeout=10)
if response.status_code == 200:
logger.info(f"✓ 连接成功: {url}")
else:
logger.warning(f"⚠ 连接异常: {url} - 状态码: {response.status_code}")
except Exception as e:
logger.error(f"✗ 连接失败: {url} - 错误: {str(e)}")
return session
def setup_logging():
"""配置日志记录系统"""
# 确保输出目录存在
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 配置日志格式
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(LOG_FILE, encoding='utf-8'),
logging.StreamHandler() # 同时输出到控制台
]
)
return logging.getLogger(__name__)
def save_download_links(items):
"""保存所有下载链接到JSON文件"""
logger = logging.getLogger(__name__)
logger.info(f"开始保存 {len(items)} 个场景的下载链接...")
print(f"正在保存 {len(items)} 个场景的下载链接...")
download_data = {
"search_date": datetime.now().isoformat(),
"search_parameters": {
"start_date": START_DATE,
"end_date": END_DATE,
"tile_ids": TILE_IDS,
"platform": SATELLITE_PLATFORM,
"cloud_cover_limit": f"< {CLOUD_COVER_LIMIT}%"
},
"items": []
}
for item in items:
item_data = {
"scene_id": item.id,
"datetime": item.datetime.isoformat(),
"cloud_cover": item.properties.get('eo:cloud_cover'),
"mgrs_tile": item.properties.get('sentinel:mgrs_tile'),
"assets": {}
}
# 保存所有需要下载的资产链接
for band in BANDS_TO_DOWNLOAD:
if band in item.assets:
asset = item.assets[band]
item_data["assets"][band] = {
"href": asset.href,
"filename": os.path.basename(asset.href)
}
download_data["items"].append(item_data)
# 保存到JSON文件
with open(DOWNLOAD_LINKS_FILE, 'w', encoding='utf-8') as f:
json.dump(download_data, f, ensure_ascii=False, indent=2)
return download_data
def load_download_links():
"""从JSON文件加载下载链接"""
if os.path.exists(DOWNLOAD_LINKS_FILE):
with open(DOWNLOAD_LINKS_FILE, 'r', encoding='utf-8') as f:
return json.load(f)
return None
def load_progress():
"""加载下载进度"""
if os.path.exists(PROGRESS_FILE):
try:
with open(PROGRESS_FILE, 'r', encoding='utf-8') as f:
return json.load(f)
except (json.JSONDecodeError, IOError):
return {}
return {}
def save_progress(progress_data):
"""保存下载进度"""
try:
os.makedirs(os.path.dirname(PROGRESS_FILE), exist_ok=True)
with open(PROGRESS_FILE, 'w', encoding='utf-8') as f:
json.dump(progress_data, f, ensure_ascii=False, indent=2)
except Exception as e:
logging.getLogger(__name__).error(f"保存进度失败: {str(e)}")
def get_file_size(url, session=None, timeout=30):
"""获取远程文件大小"""
try:
if session is None:
session = requests.Session()
response = session.head(url, timeout=timeout)
response.raise_for_status()
content_length = response.headers.get('content-length')
if content_length:
return int(content_length)
# 如果HEAD请求没有返回content-length,尝试GET请求的前几个字节
response = session.get(url, headers={'Range': 'bytes=0-0'}, timeout=timeout)
if response.status_code == 206: # Partial Content
content_range = response.headers.get('content-range', '')
if content_range.startswith('bytes'):
total_size = content_range.split('/')[-1]
if total_size.isdigit():
return int(total_size)
return None
except Exception:
return None
def verify_file_integrity(file_path, expected_size=None):
"""验证文件完整性"""
if not os.path.exists(file_path):
return False
# 检查文件大小
if expected_size is not None:
actual_size = os.path.getsize(file_path)
if actual_size != expected_size:
return False
# 检查文件是否可读且不为空
try:
if os.path.getsize(file_path) == 0:
return False
with open(file_path, 'rb') as f:
f.read(1) # 尝试读取第一个字节
return True
except Exception:
return False
def calculate_retry_delay(attempt, base_delay=RETRY_DELAY_BASE):
"""计算指数退避延迟时间"""
# 指数退避 + 随机抖动
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
return min(delay, 60) # 最大延迟60秒
def get_file_lock(file_path):
"""获取文件锁,确保每个文件只有一个锁对象
Args:
file_path (str): 文件路径
Returns:
Lock: 文件锁对象
"""
with _file_locks_lock:
if file_path not in _file_locks:
_file_locks[file_path] = Lock()
return _file_locks[file_path]
def safe_update_progress(progress_data, file_key, update_data):
"""线程安全地更新进度数据
Args:
progress_data (dict): 进度数据字典
file_key (str): 文件键名
update_data (dict): 更新的数据
"""
with _progress_lock:
progress_data[file_key] = update_data
def safe_save_progress(progress_data):
"""线程安全地保存进度数据
Args:
progress_data (dict): 进度数据字典
"""
with _progress_lock:
save_progress(progress_data.copy()) # 复制一份数据来保存
def get_download_statistics(progress_data):
"""统计下载状态
Args:
progress_data (dict): 进度数据字典
Returns:
dict: 各状态的文件数量统计
"""
with _progress_lock:
stats = {
'completed': 0,
'downloading': 0,
'error': 0,
'pending': 0,
'total': len(progress_data)
}
for file_info in progress_data.values():
status = file_info.get('status', 'pending')
if status in stats:
stats[status] += 1
else:
stats['pending'] += 1
return stats
# =============================================================================
# 3. 脚本执行逻辑
# =============================================================================
def download_file(url, local_path, logger=None, progress_data=None, file_key=None):
"""使用断点续传下载文件并显示进度条(线程安全版本)
Args:
url (str): 下载链接
local_path (str): 本地保存路径
logger: 日志记录器
progress_data (dict): 进度数据字典
file_key (str): 文件在进度数据中的键名
Returns:
bool: 下载是否成功
"""
filename = os.path.basename(local_path)
if progress_data is None:
progress_data = {}
if file_key is None:
file_key = local_path
# 获取文件锁,确保同一文件不会被多个线程同时下载
file_lock = get_file_lock(local_path)
with file_lock:
# 确保目录存在
os.makedirs(os.path.dirname(local_path), exist_ok=True)
# 首先检查进度数据中的状态,避免重复处理
with _progress_lock:
current_status = progress_data.get(file_key, {}).get('status', 'pending')
# 如果文件已经标记为完成,直接返回(避免重复检查和打印)
if current_status == 'completed':
# 只在调试模式下记录,避免重复打印
if logger:
logger.debug(f"文件已完成下载(跳过重复检查): {filename}")
return True
# 如果文件正在下载中,等待其他线程完成
if current_status == 'downloading':
if logger:
logger.debug(f"文件正在被其他线程下载: {filename}")
return True
# 获取远程文件大小
session = setup_session_with_proxy_and_retry()
remote_size = get_file_size(url, session, TIMEOUT)
# 检查文件是否已完整下载(只检查一次)
if os.path.exists(local_path):
if verify_file_integrity(local_path, remote_size):
message = f"文件已存在且完整: {filename}"
print(f" - {message}")
if logger:
logger.info(message)
# 使用线程安全的进度更新,标记为完成
safe_update_progress(progress_data, file_key, {
'status': 'completed',
'size': remote_size or os.path.getsize(local_path),
'downloaded': remote_size or os.path.getsize(local_path)
})
return True
else:
# 文件不完整,准备断点续传
if logger:
logger.info(f"文件不完整,准备断点续传: {filename}")
# 开始下载(支持断点续传)
for attempt in range(MAX_RETRIES):
try:
# 获取已下载的文件大小
resume_pos = 0
if os.path.exists(local_path):
resume_pos = os.path.getsize(local_path)
# 设置请求头支持断点续传
headers = {}
if resume_pos > 0 and remote_size and resume_pos < remote_size:
headers['Range'] = f'bytes={resume_pos}-'
mode = 'ab' # 追加模式
desc_prefix = "续传"
else:
resume_pos = 0
mode = 'wb' # 覆写模式
desc_prefix = "下载"
# 发起下载请求
response = session.get(url, headers=headers, stream=True, timeout=TIMEOUT)
# 检查响应状态
if headers.get('Range') and response.status_code not in [206, 200]:
# 服务器不支持断点续传,重新下载
resume_pos = 0
mode = 'wb'
desc_prefix = "重新下载"
response = session.get(url, stream=True, timeout=TIMEOUT)
response.raise_for_status()
# 添加请求间隔,避免过于频繁的网络请求
time.sleep(REQUEST_INTERVAL)
# 获取总文件大小
if remote_size is None:
content_length = response.headers.get('content-length')
if content_length:
if response.status_code == 206:
# 部分内容响应,从Content-Range获取总大小
content_range = response.headers.get('content-range', '')
if '/' in content_range:
remote_size = int(content_range.split('/')[-1])
else:
remote_size = int(content_length)
total_size = remote_size or 0
downloaded_size = resume_pos
# 使用线程安全的进度更新
safe_update_progress(progress_data, file_key, {
'status': 'downloading',
'size': total_size,
'downloaded': downloaded_size,
'attempt': attempt + 1
})
# 开始下载
with open(local_path, mode) as f:
with tqdm(
total=total_size,
initial=downloaded_size,
unit='iB',
unit_scale=True,
desc=f" - {desc_prefix} {filename}",
leave=False
) as bar:
start_time = time.time()
last_update = start_time
speed_samples = [] # 存储最近的速度样本
last_speed_check = start_time
last_downloaded = downloaded_size
for chunk in response.iter_content(chunk_size=CHUNK_SIZE):
if chunk:
f.write(chunk)
chunk_size = len(chunk)
downloaded_size += chunk_size
bar.update(chunk_size)
current_time = time.time()
# 计算下载速度(每秒更新一次)
if current_time - last_speed_check >= 1.0:
time_diff = current_time - last_speed_check
bytes_diff = downloaded_size - last_downloaded
current_speed = bytes_diff / time_diff # bytes/second
# 保持最近10个速度样本用于平均计算
speed_samples.append(current_speed)
if len(speed_samples) > 10:
speed_samples.pop(0)
# 计算平均速度
avg_speed = sum(speed_samples) / len(speed_samples)
# 更新进度条描述,显示速度
speed_mb = avg_speed / (1024 * 1024) # MB/s
if speed_mb >= 1.0:
speed_str = f"{speed_mb:.1f} MB/s"
else:
speed_kb = avg_speed / 1024 # KB/s
speed_str = f"{speed_kb:.1f} KB/s"
bar.set_description(f" - {desc_prefix} {filename} ({speed_str})")
# 使用线程安全的进度更新
safe_update_progress(progress_data, file_key, {
'downloaded': downloaded_size,
'speed': avg_speed
})
last_speed_check = current_time
last_downloaded = downloaded_size
# 验证下载完整性
if verify_file_integrity(local_path, total_size):
message = f"下载成功: {filename}"
if logger:
logger.info(message)
# 使用线程安全的进度更新
safe_update_progress(progress_data, file_key, {
'status': 'completed',
'size': total_size,
'downloaded': total_size
})
return True
else:
raise Exception("文件完整性验证失败")
except requests.exceptions.RequestException as e:
error_msg = f"网络错误 (尝试 {attempt + 1}/{MAX_RETRIES}) - {filename}: {str(e)}"
print(f" - {error_msg}")
if logger:
logger.warning(error_msg)
# 使用线程安全的进度更新
safe_update_progress(progress_data, file_key, {
'status': 'error',
'size': remote_size or 0,
'downloaded': os.path.getsize(local_path) if os.path.exists(local_path) else 0,
'attempt': attempt + 1,
'error': str(e)
})
if attempt < MAX_RETRIES - 1:
delay = calculate_retry_delay(attempt)
print(f" - {delay:.1f}秒后重试...")
time.sleep(delay)
except Exception as e:
error_msg = f"未知错误 (尝试 {attempt + 1}/{MAX_RETRIES}) - {filename}: {str(e)}"
print(f" - {error_msg}")
if logger:
logger.error(error_msg)
# 更新进度状态
progress_data[file_key] = {
'status': 'error',
'size': remote_size or 0,
'downloaded': os.path.getsize(local_path) if os.path.exists(local_path) else 0,
'attempt': attempt + 1,
'error': str(e)
}
if attempt < MAX_RETRIES - 1:
delay = calculate_retry_delay(attempt)
print(f" - {delay:.1f}秒后重试...")
time.sleep(delay)
# 所有重试都失败了
final_error = f"下载失败,已重试 {MAX_RETRIES} 次: {filename}"
print(f" - {final_error}")
if logger:
logger.error(final_error)
return False
def download_scene_files(scene_data, logger, progress_data=None):
"""下载单个场景的所有文件(线程安全版本,修复无限循环)
Args:
scene_data (dict): 场景数据,包含scene_id和assets信息
logger: 日志记录器
progress_data (dict): 进度数据字典(每个线程独立副本)
Returns:
tuple: (scene_id, success_count, total_count)
"""
scene_id = scene_data['scene_id']
scene_dir = os.path.join(OUTPUT_DIR, scene_id)
try:
os.makedirs(scene_dir, exist_ok=True)
except Exception as e:
logger.error(f"创建目录失败 {scene_dir}: {str(e)}")
return scene_id, 0, len(scene_data['assets'])
if progress_data is None:
progress_data = {}
success_count = 0
total_count = len(scene_data['assets'])
processed_files = set() # 添加已处理文件集合,防止重复处理
logger.info(f"开始下载场景: {scene_id}")
print(f"\n--- 正在处理影像: {scene_id} ---")
print(f" 日期: {scene_data['datetime'][:10]}")
print(f" 云量: {scene_data['cloud_cover']}%")
print(f" 瓦片ID: {scene_data['mgrs_tile']}")
# 下载所有资产文件
try:
# 将assets转换为列表,确保迭代的确定性
assets_list = list(scene_data['assets'].items())
logger.debug(f"场景 {scene_id} 包含 {len(assets_list)} 个文件: {[band for band, _ in assets_list]}")
for i, (band, asset_info) in enumerate(assets_list):
file_url = asset_info['href']
file_name = asset_info['filename']
local_filepath = os.path.join(scene_dir, file_name)
file_key = f"{scene_id}_{band}"
# 防止重复处理同一文件
if file_key in processed_files:
logger.warning(f"文件 {file_name} 已处理过,跳过重复处理")
continue
processed_files.add(file_key)
# 添加详细调试信息
logger.debug(f"处理文件 {i+1}/{len(assets_list)}: {file_name} (场景: {scene_id}, 波段: {band})")
try:
if download_file(file_url, local_filepath, logger, progress_data, file_key):
success_count += 1
logger.debug(f"文件下载成功: {file_name}")
else:
logger.warning(f"文件下载失败: {file_name}")
except Exception as e:
logger.error(f"下载文件时发生异常 {file_name}: {str(e)}")
# 定期保存进度(减少保存频率,避免过多I/O)
if (i + 1) % 5 == 0: # 每5个文件保存一次进度
try:
safe_save_progress(progress_data)
logger.debug(f"已保存进度,处理了 {i+1}/{len(assets_list)} 个文件")
except Exception as e:
logger.warning(f"保存进度失败: {str(e)}")
logger.info(f"场景 {scene_id} 下载完成: {success_count}/{total_count} 文件成功")
print(f" 完成: {success_count}/{total_count} 文件")
print("-" * (len(scene_id) + 20))
except Exception as e:
logger.error(f"场景 {scene_id} 下载过程中发生异常: {str(e)}")
print(f" 错误: 场景 {scene_id} 下载异常: {str(e)}")
return scene_id, success_count, total_count
def download_with_multiprocessing(download_data, logger):
"""使用多进程下载所有场景数据(修复版本)
Args:
download_data (dict): 包含所有场景信息的数据
logger: 日志记录器
Returns:
dict: 下载统计信息
"""
items = download_data['items']
total_scenes = len(items)
total_success = 0
total_files = 0
failed_scenes = []
completed_scenes = 0
# 加载现有进度(主进度数据)
main_progress_data = load_progress()
logger.info(f"开始多进程下载,共 {total_scenes} 个场景,使用 {MAX_WORKERS} 个线程")
print(f"\n开始下载 {total_scenes} 个场景,使用 {MAX_WORKERS} 个并行线程...\n")
# 添加超时机制的线程池
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# 为每个线程创建独立的进度数据副本,避免线程间竞争
future_to_scene = {}
for item in items:
# 为每个场景创建独立的进度数据副本
scene_progress_data = main_progress_data.copy()
future = executor.submit(download_scene_files, item, logger, scene_progress_data)
future_to_scene[future] = {
'scene_id': item['scene_id'],
'progress_data': scene_progress_data
}
logger.info(f"已提交 {len(future_to_scene)} 个下载任务")
# 处理完成的任务(添加超时机制)
with tqdm(total=total_scenes, desc="总体进度", unit="场景") as pbar:
try:
# 使用超时机制处理任务完成
for future in as_completed(future_to_scene, timeout=3600): # 1小时超时
scene_info = future_to_scene[future]
scene_id = scene_info['scene_id']
scene_progress_data = scene_info['progress_data']
try:
# 添加超时到future.result()
result = future.result(timeout=300) # 5分钟超时
scene_id, success_count, total_count = result
total_files += total_count
total_success += success_count
completed_scenes += 1
if success_count < total_count:
failed_scenes.append(scene_id)
logger.warning(f"场景 {scene_id} 部分文件下载失败: {success_count}/{total_count}")
else:
logger.info(f"场景 {scene_id} 下载完成: {success_count}/{total_count}")
# 合并场景进度数据到主进度数据
with _progress_lock:
main_progress_data.update(scene_progress_data)
# 每完成一个场景就保存进度
try:
safe_save_progress(main_progress_data)
except Exception as save_e:
logger.warning(f"保存进度失败: {str(save_e)}")
# 添加调试信息
logger.debug(f"已完成场景: {completed_scenes}/{total_scenes}")
except Exception as e:
error_msg = f"场景 {scene_id} 处理失败: {str(e)}"
logger.error(error_msg)
print(f"错误: {error_msg}")
failed_scenes.append(scene_id)
completed_scenes += 1
# 更新进度条(确保在任何情况下都能更新)
try:
pbar.update(1)
# 计算成功率
success_rate = (total_success / total_files * 100) if total_files > 0 else 0
pbar.set_postfix({
'已完成': completed_scenes,
'成功文件': total_success,
'总文件': total_files,
'成功率': f'{success_rate:.1f}%'
})
# 强制刷新进度条显示
pbar.refresh()
except Exception as pbar_e:
logger.warning(f"更新进度条失败: {str(pbar_e)}")
# 即使进度条更新失败,也要确保基本信息输出
print(f"进度: {completed_scenes}/{total_scenes} 场景完成")
except Exception as e:
logger.error(f"下载过程中发生异常: {str(e)}")
print(f"下载过程中发生异常: {str(e)}")
# 尝试取消未完成的任务
for future in future_to_scene:
if not future.done():
future.cancel()
logger.info(f"已取消未完成的任务: {future_to_scene[future]['scene_id']}")
# 最终保存进度
safe_save_progress(main_progress_data)
logger.info(f"下载完成统计: 完成场景 {completed_scenes}/{total_scenes}, 成功文件 {total_success}/{total_files}")
# 返回统计信息
stats = {
'total_scenes': total_scenes,
'completed_scenes': completed_scenes,
'total_files': total_files,
'successful_files': total_success,
'failed_scenes': failed_scenes,
'success_rate': (total_success / total_files * 100) if total_files > 0 else 0
}
return stats
def main():
"""主函数:搜索并下载数据"""
# 初始化日志系统
logger = setup_logging()
logger.info("=" * 60)
logger.info("Sentinel-2 L2A 数据下载脚本启动")
logger.info(f"输出目录: {OUTPUT_DIR}")
logger.info(f"搜索参数: {START_DATE} 到 {END_DATE}")
logger.info(f"瓦片ID: {TILE_IDS}")
logger.info(f"平台: {SATELLITE_PLATFORM}")
logger.info(f"云量限制: < {CLOUD_COVER_LIMIT}%(筛选掉云量{CLOUD_COVER_LIMIT}%以上的影像)")
print("\n" + "=" * 60)
print("Sentinel-2 Level-2A 原始数据下载脚本")
print("作者:锐多宝 (ruiduobao)")
print("=" * 60)
try:
# 首先检查是否已有下载链接文件
download_data = load_download_links()
if download_data:
print(f"\n发现已保存的下载链接文件: {DOWNLOAD_LINKS_FILE}")
print(f"搜索日期: {download_data['search_date'][:19]}")
print(f"包含 {len(download_data['items'])} 个场景")
# 检测是否在交互环境中运行
import sys
if sys.stdin.isatty():
# 交互模式:询问用户
try:
user_input = input("\n是否使用已保存的链接进行下载?(y/n,默认y): ").strip().lower()
if user_input in ['', 'y', 'yes']:
logger.info("使用已保存的下载链接")
print("\n使用已保存的下载链接...")
else:
download_data = None
except (EOFError, KeyboardInterrupt):
# 如果输入被中断,默认使用已保存的链接
logger.info("输入被中断,默认使用已保存的下载链接")
print("\n默认使用已保存的下载链接...")
else:
# 非交互模式:自动使用已保存的链接
logger.info("非交互模式,自动使用已保存的下载链接")
print("\n自动使用已保存的下载链接...")
# 如果没有保存的链接或用户选择重新搜索,则进行STAC搜索
if not download_data:
print("\n没有找到已保存的下载链接,开始进行STAC搜索...")
logger.info("没有找到已保存的下载链接,开始进行STAC搜索...")
# 先进行网络连接测试
print("\n开始网络连接测试...")
session = test_network_connectivity()
print(f"\n连接到 STAC 目录: {STAC_API_URL}")
logger.info(f"连接到 STAC 目录: {STAC_API_URL}")
# 配置环境变量以支持代理(如果用户选择了代理)
if hasattr(session, 'proxies') and session.proxies:
os.environ['HTTP_PROXY'] = session.proxies.get('http', '')
os.environ['HTTPS_PROXY'] = session.proxies.get('https', '')
logger.info("已设置代理环境变量")
client = Client.open(STAC_API_URL)
# 构建搜索查询(移除云量限制)
print("\n正在搜索符合条件的影像...")
# 对于多个瓦片ID,我们需要分别搜索每个瓦片然后合并结果
def parse_mgrs_tile(tile_id):
"""解析MGRS瓦片ID为组件"""
if len(tile_id) == 5:
utm_zone = int(tile_id[:2])
latitude_band = tile_id[2]
grid_square = tile_id[3:5]
return utm_zone, latitude_band, grid_square
return None, None, None
all_items = []
for tile_id in TILE_IDS:
print(f"正在搜索瓦片: {tile_id}")
logger.info(f"搜索瓦片: {tile_id}")
utm_zone, latitude_band, grid_square = parse_mgrs_tile(tile_id)
if utm_zone and latitude_band and grid_square:
logger.info(f" 解析为: UTM Zone={utm_zone}, Latitude Band={latitude_band}, Grid Square={grid_square}")
tile_search = client.search(
collections=[COLLECTION],
datetime=[START_DATE, END_DATE],
query={
"mgrs:utm_zone": {"eq": utm_zone},
"mgrs:latitude_band": {"eq": latitude_band},
"mgrs:grid_square": {"eq": grid_square},
"platform": {"eq": SATELLITE_PLATFORM},
"eo:cloud_cover": {"lt": CLOUD_COVER_LIMIT} # 过滤云量
}
)
# 使用安全的分页获取机制搜索每个瓦片
tile_items = safe_paginated_search(tile_search, max_pages=20, timeout_per_page=60, search_name=f"瓦片{tile_id}搜索")
logger.info(f"瓦片 {tile_id} 找到 {len(tile_items)} 景影像")
print(f"瓦片 {tile_id}: 找到 {len(tile_items)} 景影像")
all_items.extend(tile_items)
else:
logger.error(f"无法解析瓦片ID: {tile_id}")
print(f"错误: 无法解析瓦片ID: {tile_id}")
items = all_items
logger.info(f"搜索完成,总共找到 {len(items)} 景影像")
print(f"\n查询完毕. 根据您的条件共找到 {len(items)} 景影像。")
if not items:
logger.warning("未找到符合条件的影像")
print("未找到符合条件的影像,请检查您的参数。")
return
# 保存下载链接
print("\n正在保存下载链接...")
download_data = save_download_links(items)
logger.info(f"下载链接已保存到: {DOWNLOAD_LINKS_FILE}")
print(f"下载链接已保存到: {DOWNLOAD_LINKS_FILE}")
# 开始多进程下载
print(f"\n准备下载 {len(download_data['items'])} 个场景的数据...")
start_time = datetime.now()
# 使用多进程下载
stats = download_with_multiprocessing(download_data, logger)
# 计算总耗时
end_time = datetime.now()
duration = end_time - start_time
# 输出最终统计信息
print("\n" + "=" * 60)
print("下载完成统计")
print("=" * 60)
print(f"总场景数: {stats['total_scenes']}")
print(f"总文件数: {stats['total_files']}")
print(f"成功下载: {stats['successful_files']}")
print(f"成功率: {stats['success_rate']:.1f}%")
print(f"总耗时: {duration}")
if stats['failed_scenes']:
print(f"\n失败的场景 ({len(stats['failed_scenes'])} 个):")
for scene in stats['failed_scenes']:
print(f" - {scene}")
# 记录最终统计到日志
logger.info("下载任务完成")
logger.info(f"统计信息: {stats['successful_files']}/{stats['total_files']} 文件成功,成功率 {stats['success_rate']:.1f}%")
logger.info(f"总耗时: {duration}")
if stats['failed_scenes']:
logger.warning(f"失败的场景: {stats['failed_scenes']}")
print("\n所有下载任务完成。")
logger.info("=" * 60)
except KeyboardInterrupt:
logger.info("用户中断下载")
print("\n\n用户中断下载。")
except Exception as e:
error_msg = f"程序执行出错: {str(e)}"
logger.error(error_msg)
print(f"\n错误: {error_msg}")
raise
if __name__ == "__main__":
main()