本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
让AI从一个"通才"变成"专才"的魔法钥匙!
你是否曾经好奇,像ChatGPT这样的大模型为什么既能写诗又能编程,既能聊天又能翻译?这背后的秘密就在于两个关键过程:预训练和微调。
今天,我们就来彻底搞懂这两个让AI变得如此强大的核心概念。
1 预训练:给AI做通才教育
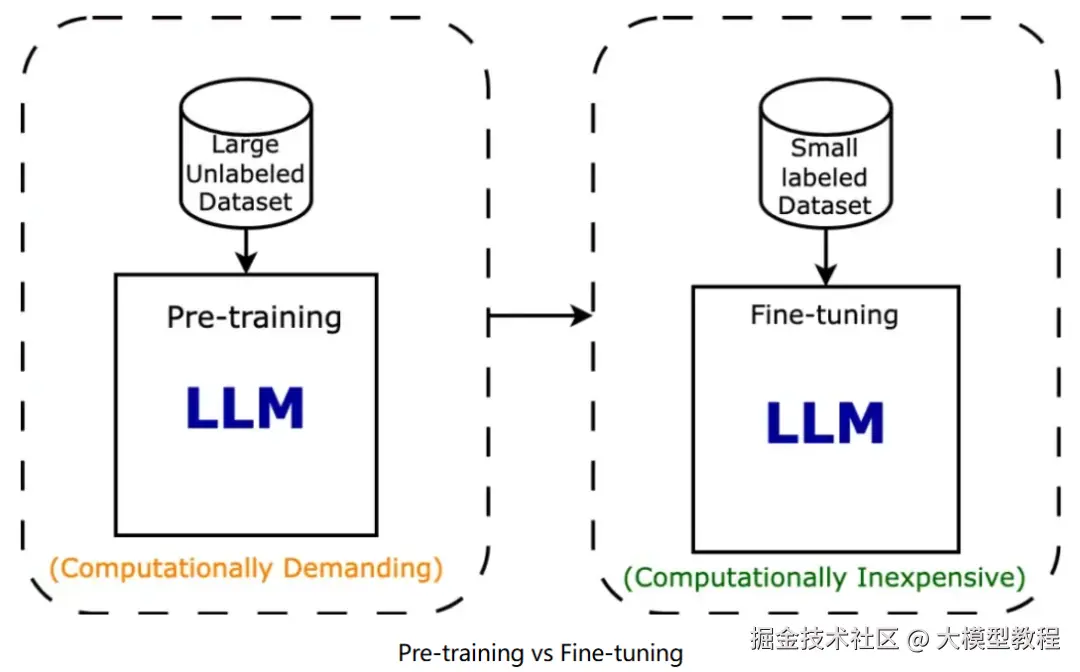
想象一下,你要培养一个天才儿童。首先你会让他广泛阅读各种书籍------文学、历史、科学、艺术,建立一个广阔的知识基础。这个过程就相当于AI的预训练。
🚀 预训练(Pre-tuning)是什么?
预训练是指让大模型在海量无标注数据上进行训练,学习语言、逻辑和知识的基本规律的过程。这就像是让AI参加一场超大规模的"题海战术"。
🌉 预训练的特点:
- 数据量极大:通常需要TB级别的文本数据
- 计算资源消耗巨大:需要成千上万的高性能GPU训练数周甚至数月。
- 自我学习:通过自监督学习方式,不需要人工标注的数据。
- 通用性强:训练出的模型具有广泛的知识和能力。
🌐 为什么需要预训练?
目的是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而提升模型在目标任务上的表现和泛化能力。
2 微调:让AI成为专才
有了广博的知识基础后,这个天才儿童现在要成为某个领域的专家了------比如医生、律师或工程师。这就是微调的过程。
🚀 微调(Fine-tuning)是什么?
微调是指在预训练的基础上,使用特定领域的有标注数据对模型进行进一步训练,使其适应特定任务或领域。
🌉 微调的特点:
- 数据量相对较小:通常只需要成千上万条标注数据。
- 训练时间短:几小时到几天就能完成。
- 任务特定:针对具体应用场景进行优化。
- 效果显著:能大幅提升在特定任务上的性能。
🌐 为什么需要微调?
- 解决预训练模型的"知识幻觉":让模型输出更准确可靠。
- 适应特定领域:如医疗、法律、金融等专业领域。
- 遵循特定规则和格式:满足实际应用的需求
对齐人类价值观:使模型输出更符合伦理和道德标准。

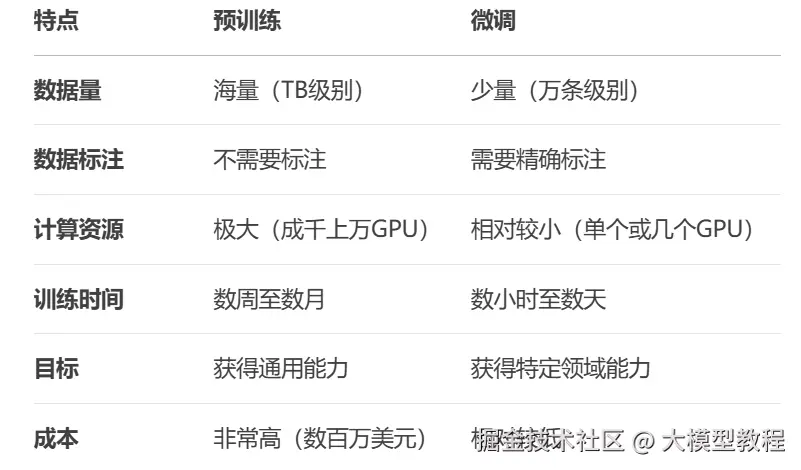
3 预训练 vs 微调
预训练与微调最大的区别在于它们的目的和训练过程。
✅ 预训练旨在让模型学习到语言的基本规律和结构,通常是在庞大的通用数据集上进行,目标是获得广泛的知识。而微调则是在特定任务的数据集上进一步训练模型,目标是让模型针对特定任务做出最优化的调整。
✅ 预训练的重点是学习广泛的语言表示,包括语言结构、语义关系和常识推理,使模型具备泛化能力,而微调的重点是针对特定任务或领域进行优化,提高其在特定任务上的精度和表现。
💡 前者通常需要大规模的计算资源,而后者则更多关注如何通过少量数据高效地调整模型。
4 实际应用及建议
案例1:医疗诊断助手
预训练:让模型学习医学文献、教科书、研究论文。
微调:使用医生标注的病例数据,训练模型进行疾病诊断。
案例2:代码生成工具
预训练:在GitHub等平台的代码数据上训练。
微调:使用特定编程范式或公司代码规范的示例进行微调。
案例3:客服机器人
预训练:学习通用对话和语言理解能力。
微调:使用公司具体的产品信息和客服对话记录进行微调。
🔧 给开发者的建议:
✅ 不要重复造轮子:大多数情况下,不需要从头预训练,可以直接使用已有的预训练模型。
✅ 数据质量大于数量:精心标注的少量数据比大量低质数据更有效。
✅ 选择合适的微调方法:根据任务需求和资源条件选择全参数微调或参数高效微调。
✅ 持续迭代:微调是一个不断改进的过程,需要根据反馈持续优化。
5 总结
💡 预训练让模型获得了通用能力和知识基础,微调让模型具备了专业能力和实用价值。它们就像培养人才的过程:先通过通识教育打下宽广基础,再通过专业培训成为领域专家。
正是这种组合,让AI既能拥有广博的知识,又能具备专业的技能,最终成为我们工作和生活中的得力助手。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。