1、什么是CUDA?
CUDA(Compute Unified Device Architecture)是由 NVIDIA 开发的一种并行计算平台和编程模型。
它的主要目标是: 让程序员可以使用 GPU(图形处理器)来执行通用计算任务,而不仅仅是图形渲染。
通过 CUDA,开发者可以编写程序,把计算密集型任务交给 GPU 的大量核心同时执行,从而显著加快处理速度特别适用于矩阵计算、深度学习、科学模拟等大规模数据并行任务。
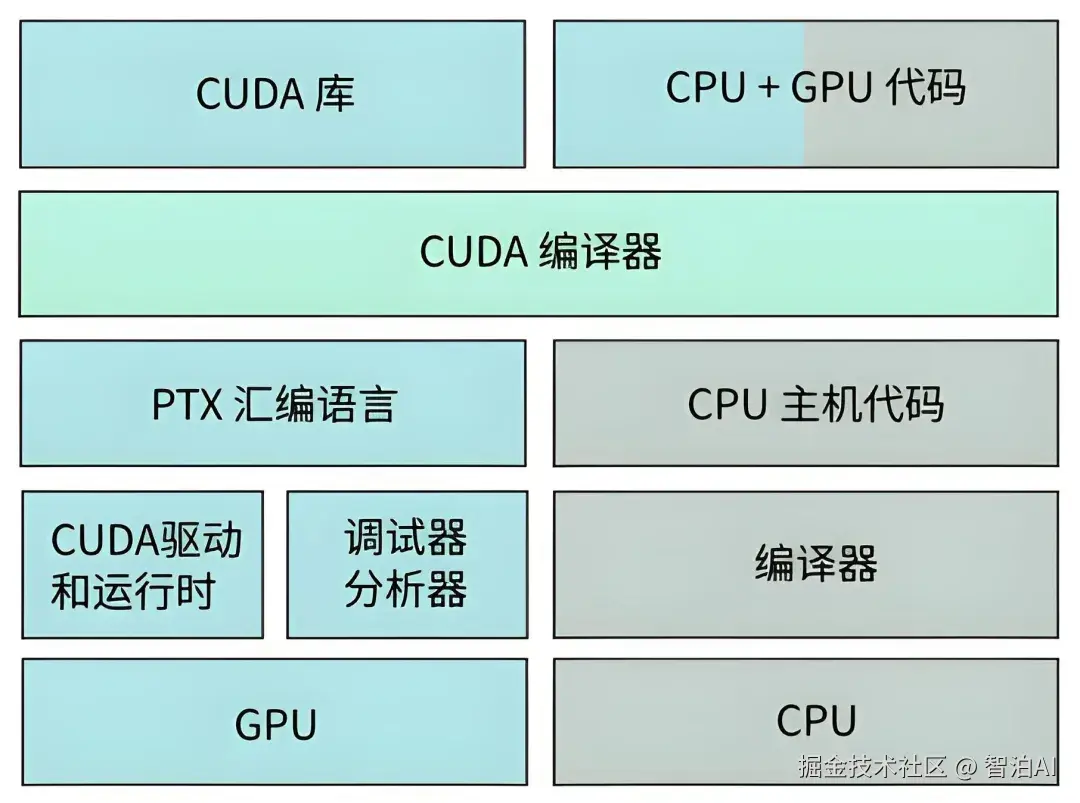
2、先简单回顾一下GPU的特点
关于 CPU 和 GPU 的区别,上一篇笔记已详细介绍,简单来说:
CPU(中央处理器) : 适合处理逻辑复杂、流程分支多的任务,核心数量少但强大。
GPU(图形处理器) : 拥有大量简单的核心,非常适合执行大量重复性的计算任务,也就是所谓的"数据并行"。
举个例子:
当你需要给一百万张照片调亮度时,CPU 就像雇了几个专业修图师,每人一张一张地处理,虽然技术好但人少。
而 GPU 像是一支庞大的流水线大军,每人同时处理一小部分,人数极多且任务简单,能大规模并行处理,因此整体速度远远超过 CPU。
CUDA 提供了一种框架,使得程序员可以"指挥"GPU来完成这些计算密集型的通用任务。
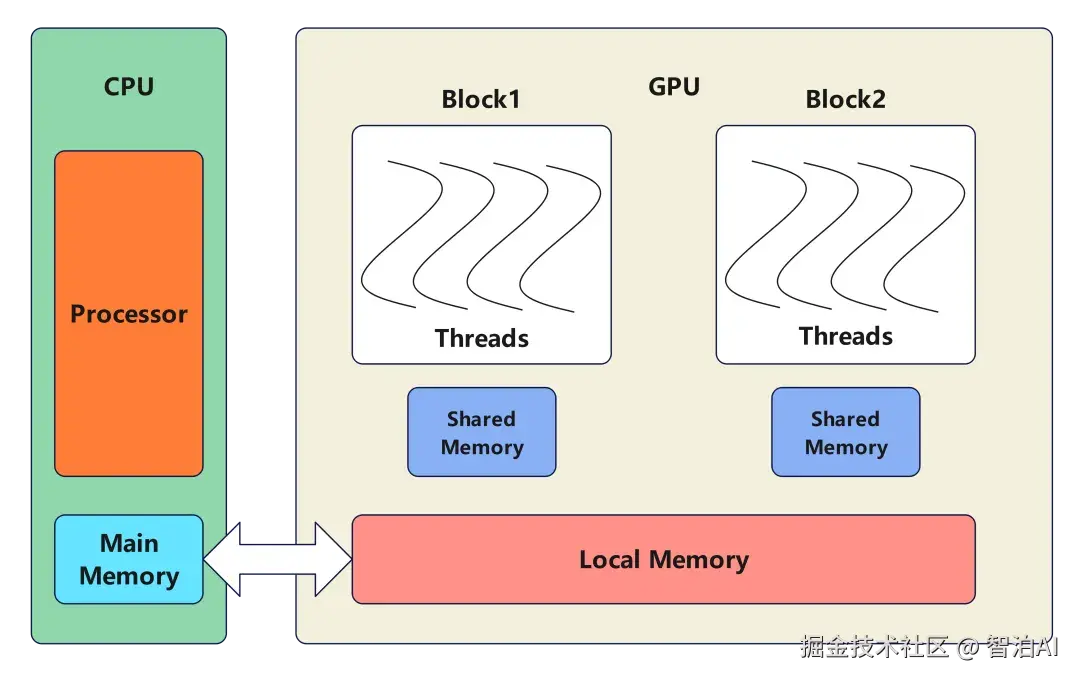
3、CUDA的运行机制
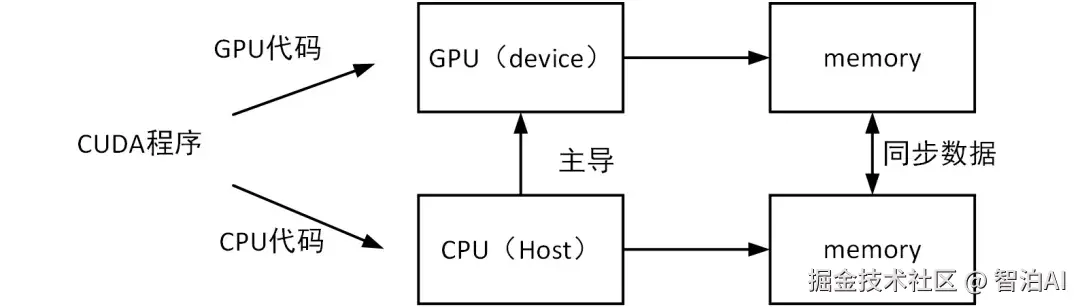
CUDA 程序中有两个主要的角色:
Host(主机) : 指的是 CPU 和它的内存,负责程序控制、数据准备和任务调度。
Device(设备) : 指的是 GPU 和它的内存,专门执行大规模并行任务。
程序的一般执行流程如下:
主机准备好数据
将数据从主机内存复制到设备内存(通过 PCle 总线)
GPU 并行处理这些数据
结果传回主机
主机进行后续处理或输出
这种协同架构被称为"异构计算模型"强调 CPU 和GPU 分工合作,各自负责擅长的任务。
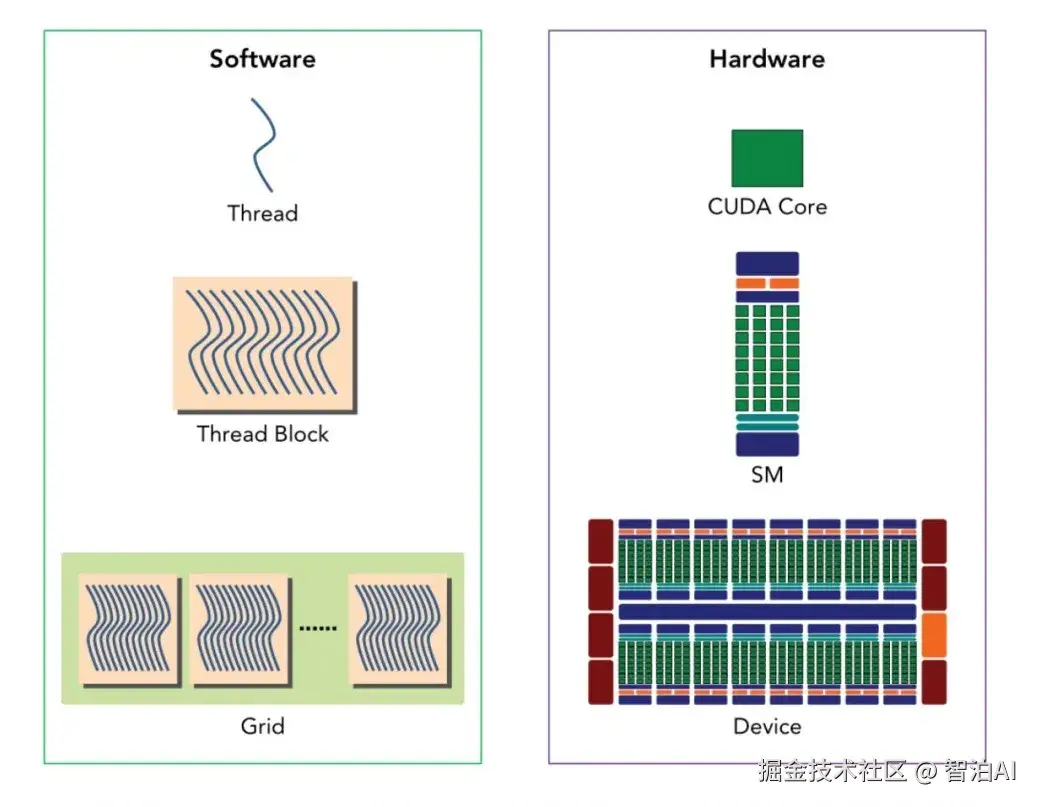
4、CUDA的编程模型
CUDA 将并行任务分解为多个线程(Thread),再组织为线程块(Block)和网格(Grid),这是CUDA程序的核心执行模型。
线程: 最小的并行执行单元。每个线程处理一小块数据(如一张图片中的一个像素或矩阵的一行)。
线程块: 一组线程组成一个线程块,块内线程可以共享内存并相互通信。
网格: 多个线程块组成一个网格,网格描述了整个并行任务的规模。
结构关系如下:

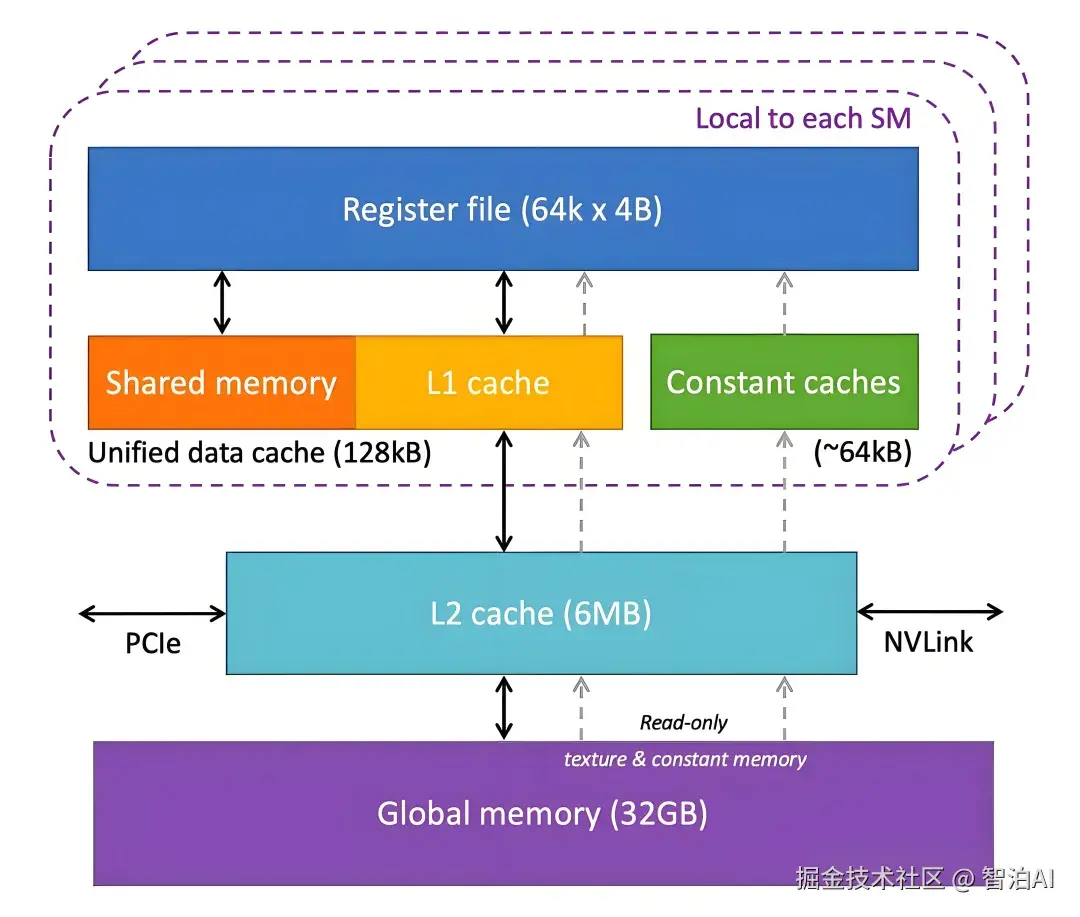
与 GPU 硬件结构的对应关系:
CUDA 程序运行时,这些软件结构会映射到 GPU的物理硬件上。
SM(Streaming Multiprocessor): GPU 中的一个处理模块,用于执行线程块。一个线程块会被分配到一个SM 上,一个SM可以运行多个线程块。
CUDA Cores(已逐渐改名为 Streaming Processors,SP): SM内的基本执行核心,负责执行线程中的算术和逻辑指令。
Tensor Cores: SM 内专用于矩阵运算的单元,特别适合深度学习模型训练和推理。
Warp 是 GPU 中的基本调度单位,通常由32个线程组成。执行线程块时,GPU 会将其中的线程划分为若干warp,并以 warp 为单位进行统一调度和执行。
5、CUDA关键组成与核心概念
CUDA 的并行计算依赖软硬件的紧密协作。以下是开发者常用的几个核心模块:
CUDA C/C++
CUDA C/C++是对标准 C/C++的扩展,通过添加特定关键字(如 _global)和 API,让开发者能够编写在GPU 上执行的并行代码。
CUDA Kernel(内核函数)
Kernel 是运行在 GPU 上的并行函数。每次调用时,GPU 会启动大量线程并发执行。它是CUDA 并行计算的基本执行单元。
nvcc 编译器
nvcc是CUDA的专用编译器,负责将CUDA代码(如CUDA Kernel)转换成 GPU 能运行的程序。
CUDA 驱动与运行时
运行时(Runtime): 提供内存分配、kernel启动等高级 API,开发者主要与这一层打交道。
驱动(Driver): 管理设备和资源,负责与 GPU 的底层交互。
CUDA Stream
CUDA Stream 是用于控制 GPU 操作执行顺序的机制默认所有操作在一个 stream 中顺序执行,使用多个stream 则可实现计算与传输或多个 kernel 的并行执行。
CUDA 加速库
CUDA 提供了一系列现成的高性能工具库,开发者可以直接调用而不用自己写底层代码:
cuBLAS: 快速处理矩阵运算
cuDNN: 专为深度学习优化的常用操作
cuFFT: 快速完成傅里叶变换
Thrust: 提供类似 C++ STL 的并行算法
TensorRT: 专门加速深度学习模型的推理
这些库已经被集成到 PyTorch、TensorFlow 等主流框架中,让 GPU 加速变得简单易用。
6、CUDA与PyTorch等框架的关系
在深度学习开发中,开发者通常无需直接编写CUDA 代码,而是通过如 PyTorch 这样的高层框架,间接利用CUDA 控制 GPU 并行计算的能力。
以 PyTorch 为例:
使用简单: 开发者使用 Python 语言定义模型结构、训练流程,无需关心底层的硬件调用细节。
自动算子映射: 当调用如 torch.mm 或 nn.Conv2d 这样的运算时,PyTorch 会自动将这些操作映射为对应的CUDA 内核(kernel),并通过CUDA 的调度机制(如stream)快速执行。
数据迁移透明: 当你使用 .to('cuda')将数据或模型从CPU 迁移到 GPU 时,PyTorch 会自动调用 CUDA 底层接口,完成内存拷贝与格式转换等步骤。
底层加速: 在训练和推理过程中,PyTorch会根据具体操作调用如 CUDNN、CUBLAS 等NVIDIA 提供的高性能计算库,也可能使用框架自定义的 CUDA kernel 来提升计算效率。
简而言之: PyTorch 屏蔽了CUDA 的复杂性,让开发者专注于模型设计与实验,同时依然可以充分利用 GPU的并行计算优势。