大型语言模型(入门篇)B
- 一、提示词
-
- [1. 什么是提示词?](#1. 什么是提示词?)
- [2. 基本提示技巧](#2. 基本提示技巧)
- [3. 提供示例(少样本提示)](#3. 提供示例(少样本提示))
- [4. 控制输出长度和格式](#4. 控制输出长度和格式)
- [5. 常见提示问题](#5. 常见提示问题)
- 二、不同的大语言模型
-
- [1. 基础模型概览](#1. 基础模型概览)
- [2. 通用模型与专用模型对比](#2. 通用模型与专用模型对比)
- [3. 开放模型与封闭模型对比](#3. 开放模型与封闭模型对比)
- [4. 模型大小与能力](#4. 模型大小与能力)
- [5. 模型使用方法](#5. 模型使用方法)
一、提示词
1. 什么是提示词?
简单来说,可以将大型语言模型(LLM)想象成一位知识渊博、功能多样的助手,能够理解并生成人类语言。然而,像任何助手一样,它需要指令才能明白你需要它完成什么样的任务。这个指令,即你提供给LLM以引导其行为的文本,被称为提示词 。
交互通常遵循以下流程:

提示词可以有多种形式,例如:
- 一个问题:地球和月球之间的距离是多少?
- 一条指令:将以下句子翻译成英文"你最近好吗?"
- 一项创意文本请求:写一个关于机器人发现音乐的短故事。
- 待补充文本:关于学习编程最重要的一点是?
- 一项带有上下文的指令:根据以下文章摘要,建议三个可能的博客文章标题:文章摘要...
提示词的用途是多方面的:
- 任务明确:它清楚地指明你希望LLM执行的任务
- 提供背景:它向LLM提供所需的背景信息或数据以便操作
- 塑造输出:它可以知道所需响应的格式、语气、长度或风格
2. 基本提示技巧
1)明确具体,直接表达:
提示LLM最直接的方法是清晰地说明你希望它做什么,模糊的提示通常会产生通用或意料之外的输出。具体的提示能引导LLM进行有侧重的比较,而模糊的提示可能会得到一个宽泛的概述、一段历史课程,或完全不同的内容。
模糊: "告诉我关于可再生能源的信息。"
具体: "请解释太阳能与风能在住宅使用方面的主要优点和缺点。"
2)定义角色或人设:
你可以让LLM采纳一个特定角色或人设,从而很大程度上影响回复的风格、语气和内容。分配一个角色有助于LLM调整其语言、复杂度和侧重。
无角色: "解释光合作用。"
有角色: "请像给五年级科学课学生讲课一样解释光合作用。"
3)指定所需的输出格式:
LLM可以生成多种格式的文本。如果你需要以特定方式组织信息,请明确要求,这会省去你之后格式化输出的时间。
无格式: "烤面包的步骤是什么?"
有格式:"用带编号的列表列出烘烤一个简单白面包的步骤。"
4)使用清晰的动作动词:
用有力的动作动词开始你的提示,清晰地界定任务。
不要用: "关于火星的信息。"
请用:"总结火星的主要地质特征。"或"列出未来十年计划前往火星的漫游车任务。"或"解释火星为何呈现红色。"
5)从简单开始并反复修改:
当你刚开始使用提示时,通常最好从一个简单、直接的提示开始,看看LLM生成了什么。如果结果不太对劲,不要气馁,根据输出优化你的提示。提示常常是一个迭代过程。一次就得到完美输出并非总是必要或预期的。尝试不同的变体是与LLM高效沟通的常见做法。
3. 提供示例(少样本提示)
尽管清晰的指令对于LLM交互非常重要,但有时仅告诉模型该做什么是不够的。想象一下,你试图通过仅仅描述规则来教别人玩一个新游戏,与向他们演示几轮游戏的效果对比。通常,看到示例会使任务变得更加清晰。这就是少样本提示 的用武之地。
少样本提示不是仅仅依靠指令(有时这被称为零样本提示),而是将你希望LLM执行的任务示例直接包含在你的提示中。你向模型展示你期望的模式、格式或响应类型。只提供一个示例被称为单样本提示,而提供多个(通常是2到5个)则被称为少样本提示。
一个典型的少样本提示包括:
可选但推荐)指令: 简要描述任务。
示例: 提供一个或多个输入和期望输出的配对。
你的最终输入: 你希望模型实际处理的查询或输入。
例如:对电影评论的情感进行分类。
零样本提示(仅指令):
-将以下电影评论的情感分类为积极、消极或中立。
评论:这部电影非常棒,必看!
情感:少样本提示(指令和示例):
-将以下电影评论的情感分类为积极、消极或中立。
评论:我喜欢表演,故事情节也很引人入胜。
情感:积极
评论:情节可预测,节奏感觉很慢。
情感:消极
评论:这是一部还算可以的电影,不好也不坏。
情感:中立
评论:这部电影非常棒,必看!
情感:4. 控制输出长度和格式
1)控制输出长度的方法
LLM没有像文字处理器那样严格遵循的内置字数计数器,但你可以在提示词中给出清晰的指令,引导它们生成特定长度的回复。
- 明确长度要求: 最直接的方法就是直接提出要求。
- 指定项目数量: 对于列表或要点,要求一个具体数量是有效的方法。
- 使用相对词语(谨慎使用): 像"简要地"、"短小"或"详细"这样的词语可以影响长度,但它们是主观的,大型语言模型的理解可能会有所不同。明确的限定通常更可靠。
大型语言模型是概率性地生成文本,通常是逐字(或逐token)生成。尽管模型会尝试遵循长度限制,但可能无法完全精准,尤其是在字符数或精确字数方面。不过,提供这些限制会大大增加获得接近你所需长度输出的可能性。
2)控制输出格式的方法
通常,你需要LLM的回复是特定结构,你可以通过细致的提示来引导模型生成格式化的输出。
- 请求特定格式: 直接告诉模型你希望的输出格式。
- 使用示例(少量示例提示): 正如之前讨论的,提供示例是向模型展示你预期准确格式的有效方式。
注意: 精准控制长度和格式可能需要尝试几次。如果第一次回复不完全是你想要的,就改进你的提示词。更具体些,调整你的限定,或者添加更清晰的示例。迭代是常态。
5. 常见提示问题
1)模糊不清或缺乏具体性
LLM对清晰、明确的指令响应最佳。如果你的提示过于模糊或容易被误解,模型可能会猜测你的意图,其猜测可能是错误的。它缺少人类用来弥补空白的上下文和常识性推理。
2)模型"幻觉"或编造的信息
你可能观察到的一种特殊行为是,LLM生成的文本听起来合理且自信,但实际上是错误的或完全捏造的。这常被称为"幻觉"。发生这种情况是因为LLM本质上是预测机器。它们根据从大量训练数据中学习到的模式生成文本,目标是统计上的可能性,而非事实准确性。如果生成一个编造的"事实"比表达不确定性或检索正确信息更符合模式,模型就可能这样做。
3)过于通用或重复的回复
有时,LLM的输出会感觉平淡、通用或重复,特别是对于创意任务或提示简单时。模型可能会回归到训练数据中最常见的模式,导致缺乏新意的文本。
4)难以遵循复杂指令
LLM可以处理多部分指令,但其能力有局限。如果一个提示包含过多步骤、限制或条件逻辑,模型可能会遗漏部分、感到困惑或执行错误。
5)提示措辞的敏感性
你可能会发现,略微不同的提问方式会产生显著不同的结果。确切的词语、标点符号和句子结构会影响模型的理解和后续输出。
6)回复中的偏见
LLM从人类生成的大量文本数据中学习。不幸的是,这些数据包含各种社会偏见(与性别、种族、年龄等相关)。因此,LLM有时会在其回复中反映甚至放大这些偏见,即使提示无意引出它们。
二、不同的大语言模型
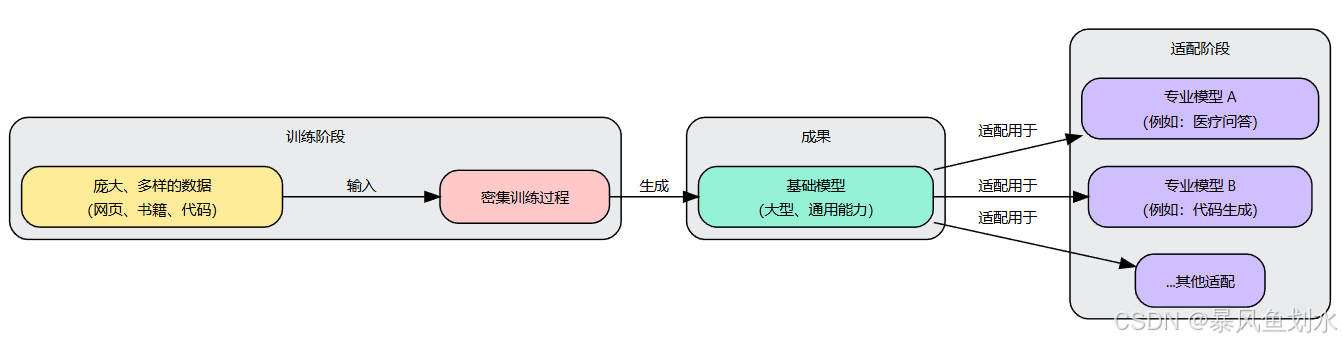
1. 基础模型概览
基础模型可以看作一个非常大型、多用途的大型语言模型,它经历了对广泛的通用文本数据进行的大规模初步训练。它并没有专门为某一项任务训练,而是从训练数据中学到了对语言、语法、事实、推理能力等方面的广泛理解。
基础模型界定的特点:
- 训练数据广泛: 它们是基于极其多样和庞大的数据集进行训练的,通常包括网页、书籍、文章和代码。
- 通用能力: 由于它们的广泛训练,基础模型通常可以"开箱即用"地完成许多不同任务。这些任务可能包括回答问题、总结文本、翻译语言、编写不同类型的创意内容以及生成代码。
- 规模庞大: 基础模型通常是最大型的LLM之一,通常包含数十亿甚至数万亿个参数。
- 作为基础: 基础模型作为基础或起点。其他更专业化的模型通常是通过使用一个预训练的基础模型,并将其调整以适应特定任务或使用场景来创建的。这个过程通常被称为微调。
基础模型如此重要的原因:
基础模型是通过对多样化数据进行广泛训练而创建的,并且可以作为创建更专业化模型的基础。
2. 通用模型与专用模型对比
| 通用模型 | 专用模型 |
|---|---|
| 在多样化的网络规模数据上训练。 | 在特定方面数据上训练/微调。 |
| 知识广博:它们对许多主题都具有广泛的理解,尽管有时是表层的。 | 专门知识丰富: 它们在特定方面(例如,医学、法律、金融、软件开发)拥有丰富的知识。 |
| 任务灵活: 它们无需专门的重新训练即可尝试多种任务。 | 任务准确度高: 它们在其专长范围内的任务上通常能实现卓越的性能、准确性和可靠性。 |
| ------ | 效率: 它们有时会更小、更快地完成特定任务,因为它们无需承担与其功能无关的知识负担。 |
| 基础特性: 许多通用模型作为"基础模型",在此之上可以开发出更专业的模型。 | ------ |
| 例子: 像OpenAI的GPT系列(生成式预训练Transformer)、谷歌的Gemini或Anthropic的Claude等模型都是通用大型语言模型的知名例子。 | 例子:BioBERT: 为理解生物医学文本而微调,对分析研究论文或临床笔记很有用。代码生成模型: 如GitHub Copilot(最初由OpenAI Codex提供支持),这些模型专门针对大量源代码进行训练,以协助开发人员编写和调试代码。 |
| 权衡: 它们的优势在于范围广。然而,对于高度具体或技术性任务,通用模型可能不如针对该特定用途训练的模型表现得准确或高效。它可能提供听起来合理但错误的信息,特别是在小众方面。 | 权衡:它们的优势在于在指定用途内的准确度和精确性。然而,如果让一个专业的医疗大型语言模型写诗或翻译斯瓦希里语,它很可能会表现不佳或拒绝,因为那超出了它的专业范围。 |
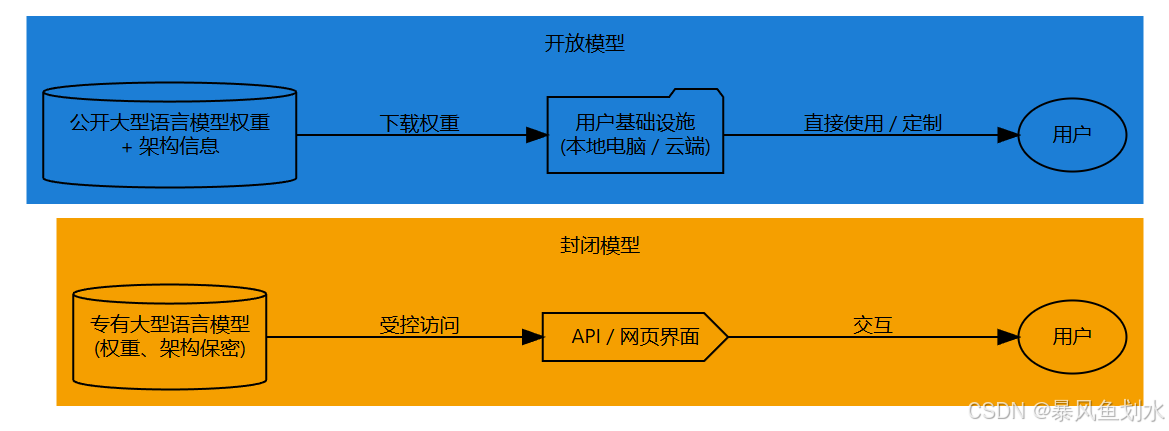
3. 开放模型与封闭模型对比
| 开放模型 | 封闭模型 |
|---|---|
| 由特定公司开发、拥有和管理。 | 也可称之为开源模型,提供更大的访问权限和透明度。 |
| 专有模型,内部运行方式、特定训练数据,甚至通常是完整的模型架构都由创建它们的厂商保密。通常通过受控界面与这些模型交互,最常见的是由供应商提供的应用程序编程接口(API)或基于网络的聊天应用程序。 | 模型的架构细节、训练过的参数(权重)是公开发布的。有时,训练数据的细节甚至数据本身也会被分享。这使得任何具备必要技能和计算资源的人都可以自行查看、修改和运行模型。 |
| 访问通常受到管理,并常常根据模型的使用量收取费用(例如,每处理一个token的成本)。 | 模型权重通常可以下载,可以在自己的硬件上(如果足够强大)或在云计算平台上运行这些模型。 |
| 特点:高性能、易用性、透明度有限、定制性较低、供应商依赖性 | 特点:透明度、定制性、控制权、社区创新、资源需求、性能差异 |
开放模型与封闭模型的核心区别在于模型本身的访问权限和控制权。封闭模型提供服务,而开放模型提供底层组件。
4. 模型大小与能力
LLM的"大小"通常通过参数的总数量来衡量。参数更多的模型有更多的"旋钮"可以调整,这通常使其能从训练数据中学到更复杂的模式和细节。模型大小差异很大:
- 小型模型可能有数百万或数十亿参数
- 中型模型通常在数百亿参数的量级
- 大型模型可能拥有数千亿甚至数万亿参数
参数更多的模型通常表现出:
- 知识范围更广: 它们经过更多样的数据训练,有更大的容量存储和回溯信息。
- 复杂任务表现更佳: 需要较深层次推理、创造性、多步骤指令或理解细微语境的任务,通常能从大型模型中获益。
- 语言理解能力提升: 大型模型通常对语法、风格、语气和语境有更好的掌握。它们往往能更准确地遵循指令,并生成更连贯、更像人类的文本。
尽管大型模型通常拥有更强大的能力,但大小并非决定一切,它也需要考虑其它因素:
- 计算成本: 训练大型模型需要巨大的计算能力(如GPU或TPU等专用硬件)、能源和时间,运行(或推理)这些大型模型也需要大量的计算资源。
- 速度: 相比更小、更灵活的模型,大型模型处理输入和生成输出通常需要更长时间。
- 可访问性: 训练甚至运行最大型模型所需的资源,可能会限制拥有大量资金和基础设施的组织才能使用它们。小型模型通常更容易部署在标准硬件甚至移动设备上。
- 专用性: 专门为特定任务(如情感分析或两种特定语言之间的翻译)训练或微调的小型模型,在该特定任务上的表现可能优于大型通用模型,同时效率也更高。
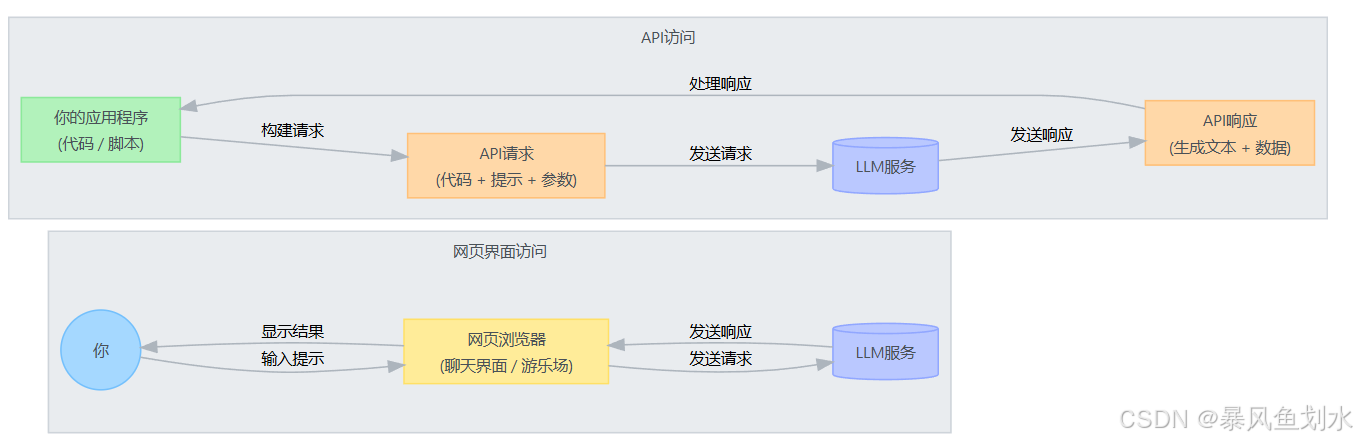
5. 模型使用方法
访问和使用LLM主要有两种方法:基于网络的界面和应用程序编程接口(API),示意图如下。
| 网页界面 | 应用程序编程接口 |
|---|---|
| 由LLM创建者或第三方服务商提供的专用网站或在线工具。 | 让你的应用程序能够以编程的方式向LLM服务发送请求,并接收生成的文本。 |
| 优点:易于使用、及时反馈、查看功能 | 优点:整合能力、自动化、更强的控制、可扩展性 |
| 缺点:自动化有限、控制较少、潜在使用限制 | 缺点:需要编程、需要设置、潜在成本 |