用 LangChain + Zod 构建类型安全的 AI 结构化输出 ------ 从"一句话解释 Promise"开始
大模型很聪明,但也很"自由"。
你让它解释 Promise,它可能回你一段优美的散文;
你想要一个干净的 JSON,它却在前后加上"好的!""希望这对你有帮助!"。
这种"自由发挥"在聊天场景很友好,但在工程实践中却是灾难------ 我们无法把一段不确定的文本,直接当作结构化数据使用。
你有没有想过,如何让大模型(LLM)不只是"聊天",而是成为一个可靠的数据生成器?
比如:输入 "Promise",让它返回一个严格符合以下格式的 JSON:
json
{
"name": "Promise",
"core": "用于处理异步操作的对象",
"useCase": ["AJAX 请求", "定时器封装"],
"difficulty": "中等"
}这听起来简单,但实际开发中会遇到三大难题:
- 模型总爱加解释文字 ,导致无法直接
JSON.parse - 字段名或类型可能出错 (比如把
useCase写成usecase) - TypeScript 拿不到精确类型 ,只能用
any
而解决这些问题的答案,就藏在三行代码里:
js
const schema = z.object({ ... });
const parser = new JsonOutputParser(schema);
const instructions = parser.getFormatInstructions();本文将带你一步步拆解这段代码背后的原理,理解 LangChain + Zod 如何协同工作 ,实现端到端的类型安全、结构化 AI 输出。
🧩 一、Zod:不只是校验,更是"数据契约"
❓ 什么是 Zod?
Zod 是一个 TypeScript 优先的运行时校验库。它允许你用代码定义"合法数据长什么样"。
比如:
js
const FrontendConceptSchema = z.object({
name: z.string().describe('概念名称'),
core: z.string().describe('核心要点'),
useCase: z.array(z.string()).describe('常见使用场景'),
difficulty: z.enum(['简单', '中等', '复杂']).describe('学习难度')
});✅ z.object() 到底创建了什么?
它不是创建一个普通对象 ,而是创建了一个 Zod Schema(校验规则) ,这个 schema 具备三重能力:
| 能力 | 说明 |
|---|---|
| 运行时校验 | 通过 .parse(data) 验证数据是否合法 |
| 静态类型推导 | type T = z.infer<typeof schema> 自动获得 TypeScript 类型 |
| 元信息描述 | .describe() 可被其他工具(如 LangChain)读取 |
💡 所以,
FrontendConceptSchema本质上是一个 "数据契约" ------ 它告诉全世界:"只有符合这个结构的数据,才是合法的。"
🔍 二、JsonOutputParser:翻译官 + 质检员
现在问题来了:如何让 LLM 理解这个"契约"?
答案是:JsonOutputParser。
js
const jsonParser = new JsonOutputParser(FrontendConceptSchema);很多人以为它只是一个"JSON 解析器",其实它的角色更丰富:
👨🏫 角色一:翻译官(指导模型怎么写)
它调用 .getFormatInstructions(),把 Zod Schema 自动翻译成一段自然语言指令:
json
{
"name": string // 概念名称
"core": string // 核心要点
"useCase": string[] // 常见使用场景
"difficulty": "简单" | "中等" | "复杂" // 学习难度
}
*/这段文本会被插入到提示词中,明确告诉模型:"你必须按这个格式输出,不能多、不能少、不能错。"
🌟 这就是为什么你需要显式传入
format_instructions: jsonParser.getFormatInstructions()------
LangChain 不会自动填充它,这是你主动连接"schema"和"提示词"的桥梁。
👮 角色二:质检员(检查模型有没有写对)
当模型返回文本后,JsonOutputParser 会:
- 尝试提取 JSON(如匹配
json{...}) - 用
FrontendConceptSchema.parse(...)进行 Zod 校验 - 如果字段缺失、类型错误、枚举值非法 → 抛出
ZodError - 只有完全合规的数据才会返回
✅ 这相当于双重保险:
- 前验:用提示词引导模型输出合规格式
- 后验:用 Zod 校验兜底,防止"幻觉"污染业务逻辑
⚙️ 三、完整流程:从提示词到类型安全对象
让我们把所有零件组装起来:
js
// 1. 初始化模型
const model = new ChatDeepSeek({
model: 'deepseek-reasoner',
temperature: 0,
});
// 2. 构建强约束提示词
const prompt = PromptTemplate.fromTemplate(`
你是一个只会输出 JSON 的 API,不允许输出任何解释性文字。
⚠️ 你必须【只返回】符合以下 Schema 的 JSON:
{format_instructions}
前端概念:{topic}
`);
// 3. 创建解析链
const chain = prompt.pipe(model).pipe(jsonParser);
// 4. 调用
const response = await chain.invoke({
topic: 'Promise',
format_instructions: jsonParser.getFormatInstructions(),
});
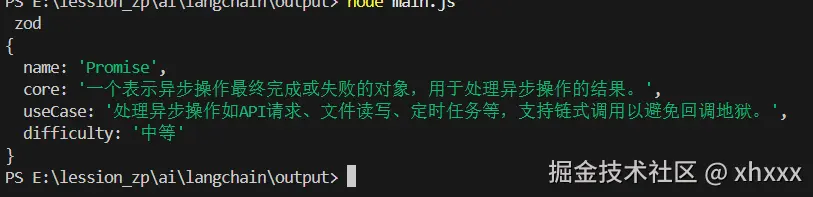
console.log(response);
// {
// name: 'Promise',
// core: '...',
// useCase: [...],
// difficulty: '中等'
// }此时,response 的类型已被 TypeScript 精确推导为:
css
{
name: string;
core: string;
useCase: string[];
difficulty: "简单" | "中等" | "复杂";
} 无需手写 interface,类型与校验逻辑完全同步!
无需手写 interface,类型与校验逻辑完全同步!
🧱 四、这一切,都建立在 JavaScript 模块化之上
你可能没注意到,但这段代码本身就是 现代 JS 模块化思想的典范:
js
import { ChatDeepSeek } from '@langchain/deepseek'; // 模型模块
import { PromptTemplate } from '@langchain/core/prompts'; // 提示词模块
import { JsonOutputParser } from '@langchain/core/output_parsers'; // 解析模块
import { z } from 'zod'; // 校验模块
import 'dotenv/config'; // 配置模块每个 import 都代表一个独立、可复用、职责单一的功能单元。这种设计使得:
- 依赖清晰,无全局污染
- 功能解耦,易于测试和替换(比如换
ChatOpenAI只需改一行) - 支持 tree-shaking,打包体积更小
💡 没有 ES Modules,就没有现代 AI 应用的工程化。
✅ 五、为什么这套方案值得在生产环境使用?
| 优势 | 说明 |
|---|---|
| 类型安全 | 编译时 + 运行时双重保障,告别 any |
| 抗幻觉 | 强提示 + Zod 校验,大幅降低无效输出 |
| 可维护 | 修改 schema,提示词和校验自动同步 |
| 可扩展 | 易于拆分为 schemas/、chains/、services/ 等模块 |
| 国产友好 | DeepSeek 等国产模型完美支持 |
🚀 结语:让 AI 成为可靠的"数据工人"
过去,我们把 LLM 当作"聪明的聊天机器人";
现在,借助 LangChain + Zod,我们可以把它变成遵守契约的数据生成器。
而这背后的核心思想是:
用代码定义结构(Zod),用提示词引导行为(LangChain),用校验确保结果(JsonOutputParser)。
这不仅是技术组合,更是一种AI 工程化思维 ------
不信任黑盒输出,用契约和验证构建可靠系统。
下次当你需要从 AI 中提取结构化数据时,不妨试试这套模式。你会发现,AI 不仅能"说人话",还能"写对数据"。