Apache Doris 简介
什么是 Apache
Apache Doris 是一个基于 MPP 的实时数据仓库,以其极快的查询速度而闻名。对于大型数据集的查询,它可以在亚秒级返回结果。它既支持高并发的点查询,也支持高吞吐量的复杂分析。它可用于报表分析、即席查询、统一数据仓库和数据湖查询加速。基于 Apache Doris,用户可以构建用于用户行为分析、A/B 测试平台、日志分析、用户画像分析和电商订单分析的应用程序。
Apache Doris,原名 Palo,最初是为了支持百度的广告报告业务而创建的。它于 2017 年正式开源,并于 2018 年 7 月由百度捐赠给 Apache 软件基金会,由孵化器项目管理委员会成员在 Apache 导师的指导下运营。2022 年 6 月,Apache Doris 从 Apache 孵化器毕业,成为顶级项目。截至 2024 年,Apache Doris 社区已聚集了来自数百家不同行业公司的 600 多名贡献者,月活跃贡献者超过 120 人。
Apache Doris 拥有广泛的用户基础,已在全球超过 5000 家公司的生产环境中使用,其中包括抖音、百度、腾讯、网易等巨头,并广泛应用于金融、零售、电信、能源、制造、医疗等行业。
使用
如下图所示,数据源经过各种数据集成和处理后,通常会被接入实时数仓 Doris 和离线 Lakehouse(例如 Hive、Iceberg、Hudi),广泛应用于 OLAP 分析场景。
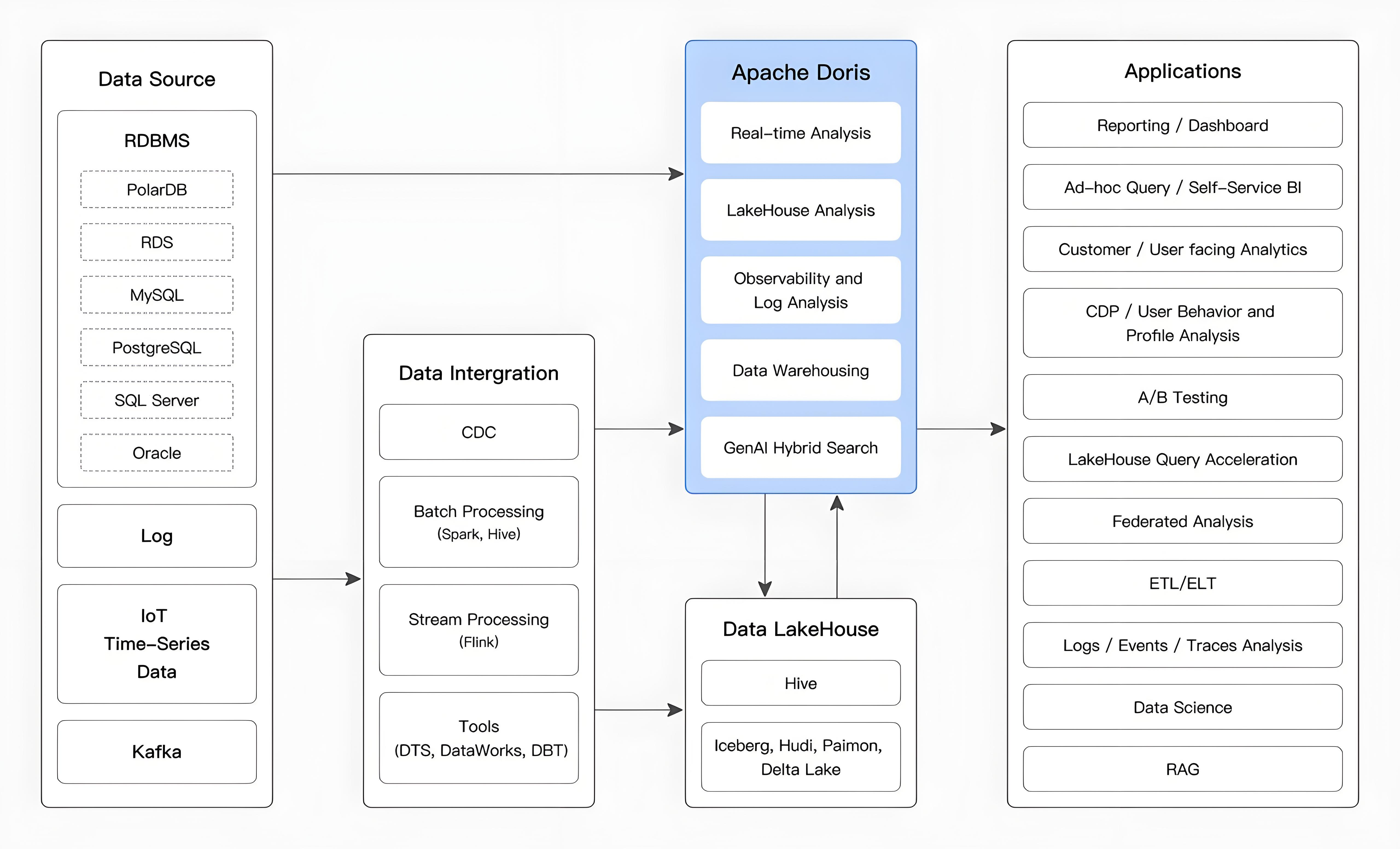
Apache Doris 广泛应用于以下场景:
-
实时数据分析 :
-
实时报告和决策 :Doris 为企业内部和外部使用提供实时更新的报告和仪表板,支持自动化流程中的实时决策。
-
临时分析 :Doris 提供多维数据分析功能,支持快速商业智能分析和临时查询,帮助用户从复杂数据中快速发现见解。
-
用户画像与行为分析 :Doris 可以分析用户的参与度、留存度、转化度等行为,同时支持人群洞察、人群选择等场景进行行为分析。
-
-
Lakehouse 分析 :
-
Lakehouse 查询加速 :Doris 通过其高效的查询引擎加速 Lakehouse 数据查询。
-
联合分析 :Doris 支持跨多个数据源的联合查询,简化架构并消除数据孤岛。
-
实时数据处理 :Doris 融合了实时数据流和批量数据处理能力,满足高并发、低延迟的复杂业务需求。
-
-
基于 SQL 的可观察性 :
- 日志和事件分析 :Doris 支持对分布式系统中的日志和事件进行实时或批量分析,帮助识别问题并优化性能。
总体
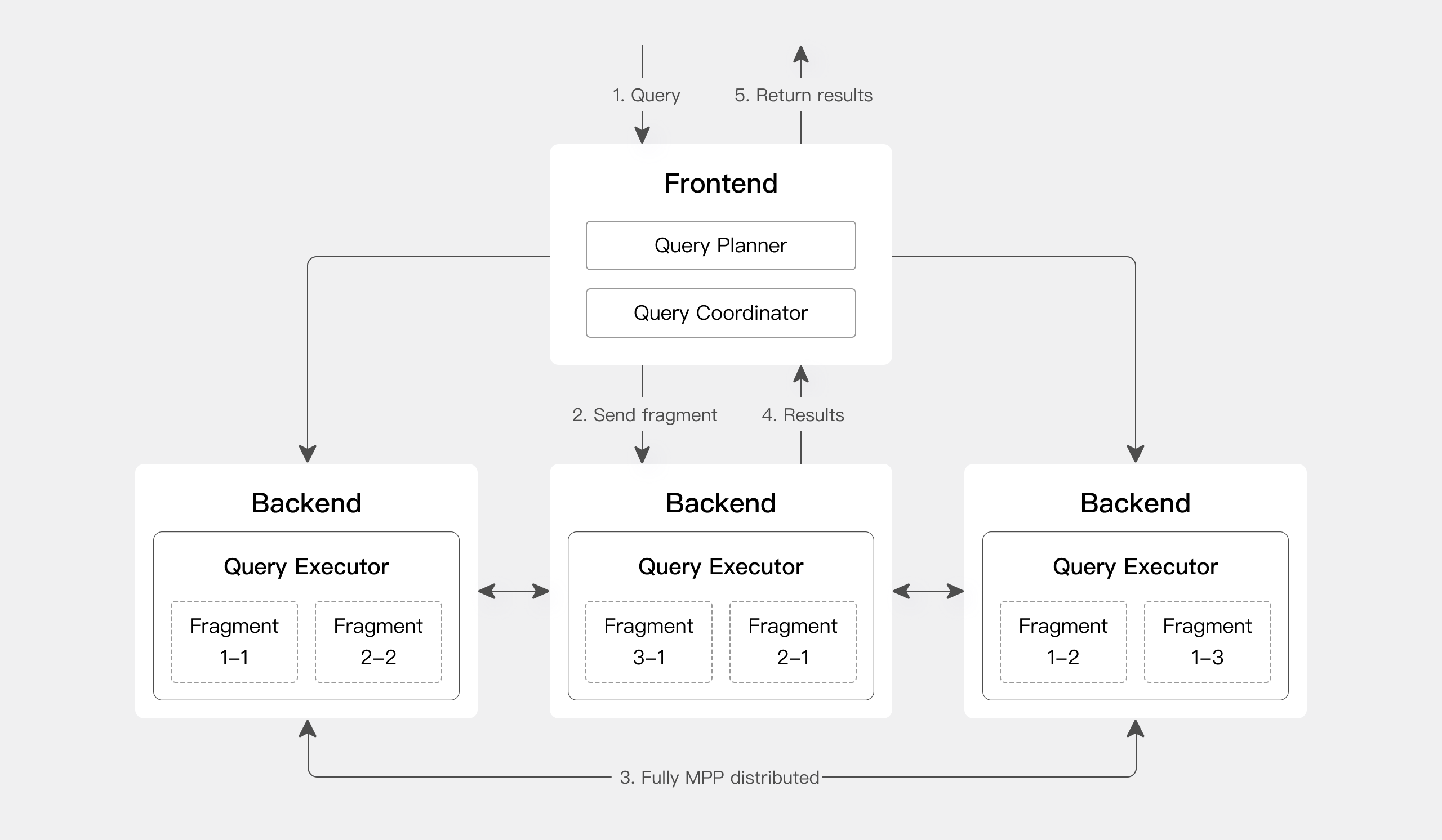
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各种客户端工具访问 Apache Doris,并与 BI 工具无缝集成。部署 Apache Doris 时,您可以根据硬件环境和业务需求,选择存储计算一体化架构或存储计算分离架构。
存储计算一体化
Apache Doris 的存储计算一体化架构简洁易维护,如下图所示,它仅由两类进程组成:
-
前端(FE): 主要负责处理用户请求、查询解析和规划、元数据管理和节点管理任务。
-
后端 (BE): 主要负责数据存储和查询执行。数据被分区成多个分片,并以多个副本的形式存储在 BE 节点上。
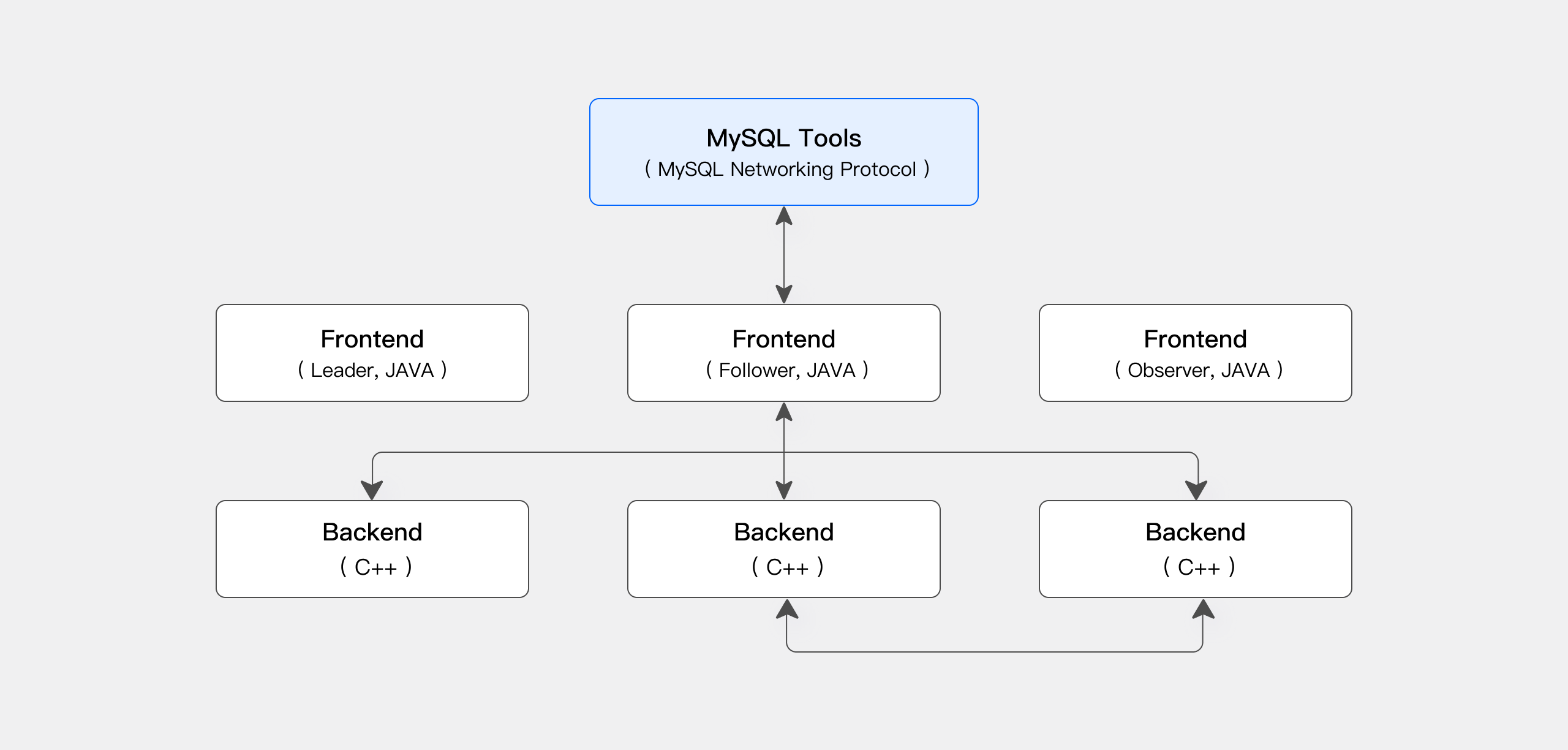
在生产环境中,可以部署多个 FE 节点用于容灾,每个 FE 节点维护一份完整的元数据副本。FE 节点分为三种角色:
| 角色 | 功能 |
|---|---|
| 掌握 | FE Master节点负责元数据的读写操作,当Master中发生元数据变更时,通过BDB JE协议同步给Follower或Observer节点。 |
| 追随者 | Follower节点负责读取元数据,如果Master节点发生故障,可以选举一个Follower节点作为新的Master。 |
| 观察者 | Observer 节点负责读取元数据,主要用于提高查询并发度,不参与集群领导节点选举。 |
FE 和 BE 进程均支持水平扩展,单集群可支持数百台机器和数十PB的存储容量。FE 和 BE 进程采用一致性协议,确保服务高可用和数据高可靠。存储计算一体化架构高度集成,显著降低分布式系统的操作复杂度。
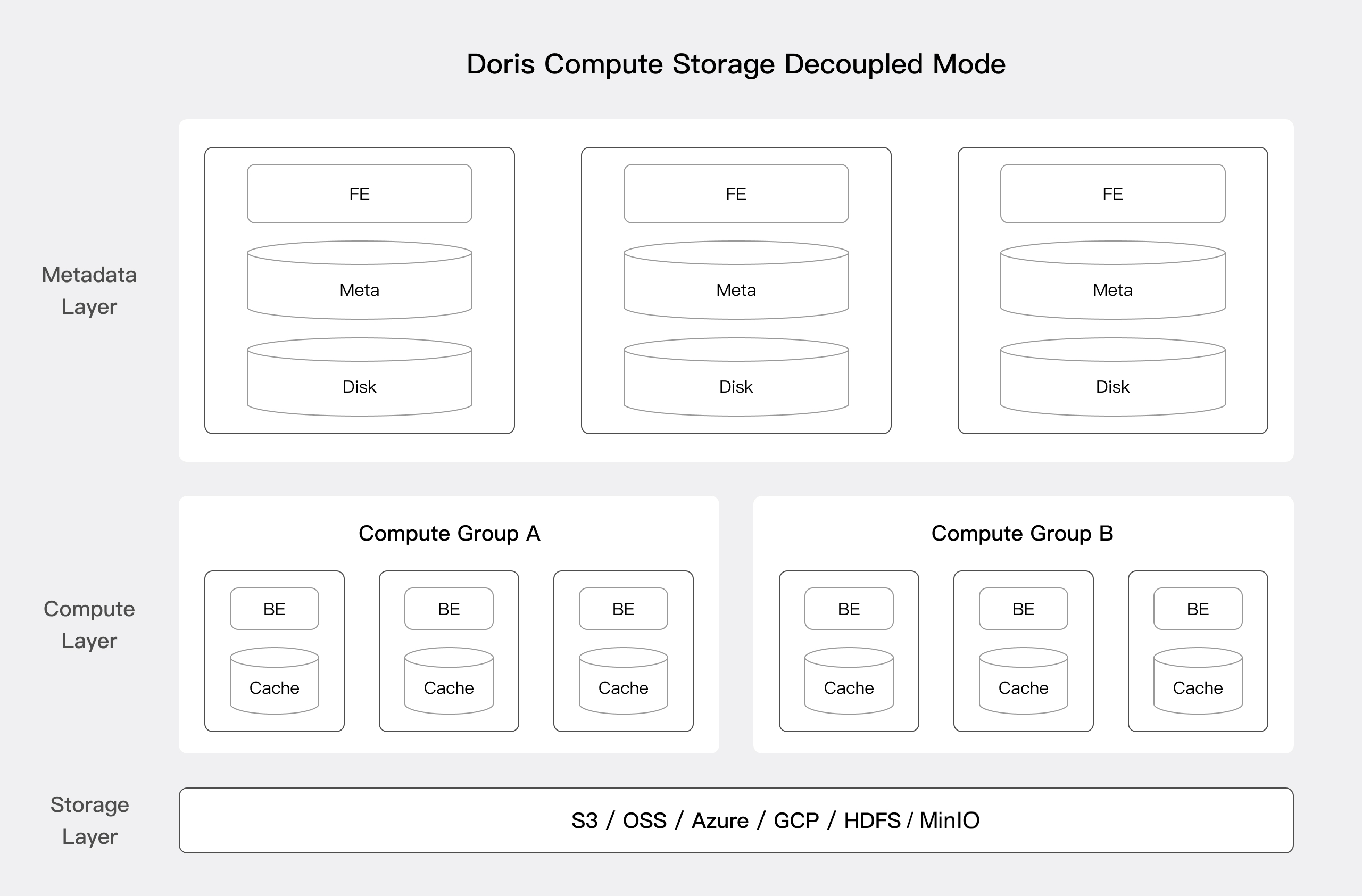
计算-存储
从 3.0 版本开始,可以选择计算存储解耦的部署架构。Apache Doris 的计算存储解耦版本采用统一的共享存储层作为数据存储空间。通过存储和计算的分离,用户可以独立地扩展存储容量和计算资源,从而实现最佳的性能和成本效率。如下图所示,计算存储解耦架构分为三层:
-
元数据层 :元数据层主要负责请求规划、查询解析和规划以及元数据的存储和管理。
-
计算层 :计算层由多个计算组组成,每个计算组都可以作为独立的租户运行,处理业务计算。每个计算组内包含多个无状态 BE 节点,这些 BE 节点可以随时弹性伸缩。
-
存储层 :存储层可以使用 S3、HDFS、OSS、COS、OBS、Minio、Ceph 等共享存储方案来存储 Doris 的数据文件,包括 Segment 文件和倒排索引文件。
Apache
-
高可用性 :Apache Doris 的元数据和数据均采用多副本存储,并通过仲裁协议同步数据日志。当大多数副本完成写入后,数据写入即视为成功,确保即使少数节点故障,集群依然可用。Apache Doris 支持同城和跨地域容灾,实现双集群主从模式。当部分节点故障时,集群可以自动隔离故障节点,避免影响集群整体可用性。
-
高兼容性 :Apache Doris 高度兼容 MySQL 协议,支持标准 SQL 语法,涵盖大部分 MySQL 和 Hive 功能。这种高兼容性允许用户无缝迁移和集成现有应用程序和工具。Apache Doris 支持 MySQL 生态系统,用户可以通过 MySQL Client 工具连接 Doris,运维更加便捷。此外,它还支持 BI 报表工具和数据传输工具的 MySQL 协议兼容,确保数据分析和数据传输过程的高效和稳定。
-
实时数仓 :基于 Apache Doris 构建实时数仓服务。Apache Doris 提供秒级数据采集能力,可将上游在线事务型数据库的增量变更在秒级内捕获到 Doris 中。Doris 利用向量化引擎、MPP 架构和 Pipeline 执行引擎,提供亚秒级数据查询能力,从而构建高性能、低延迟的实时数仓平台。
-
统一 Lakehouse :Apache Doris 可以基于数据湖或关系型数据库等外部数据源构建统一 Lakehouse 架构。Doris 统一 Lakehouse 解决方案实现了数据湖与数据仓库之间的无缝集成和数据自由流动,帮助用户直接利用数据仓库的能力解决数据湖中的数据分析问题,同时充分利用数据湖的数据管理能力提升数据价值。
-
灵活的建模 :Apache Doris 提供多种建模方式,例如宽表模型、预聚合模型、星型/雪花模型等。在数据导入时,可以将数据扁平化为宽表,通过 Flink 或 Spark 等计算引擎写入 Doris,也可以将数据直接导入 Doris,通过视图、物化视图或实时多表连接等方式进行数据建模操作。
技术
Doris 提供高效的 SQL 接口,并完全兼容 MySQL 协议。其查询引擎基于 MPP(大规模并行处理)架构,能够高效执行复杂的分析型查询,实现低延迟的实时查询。通过列式存储技术进行数据编码和压缩,显著优化了查询性能和存储压缩率。
Apache Doris 采用 MySQL 协议,支持标准 SQL,高度兼容 MySQL 语法。用户可以通过各种客户端工具访问 Apache Doris,并与 BI 工具无缝集成,包括但不限于 Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Superset 等。Apache Doris 可以作为任何支持 MySQL 协议的 BI 工具的数据源。
存储
Apache Doris 拥有列式存储引擎,按列对数据进行编码、压缩和读取,从而实现极高的数据压缩率,并大大减少不必要的数据扫描,从而更高效地利用 IO 和 CPU 资源。
Apache Doris 支持各种索引结构以最大限度地减少数据扫描:
-
有序复合键索引 :用户最多可以指定三列来组成一个复合排序键。这可以有效地修剪数据,以更好地支持高并发的报表场景。
-
最小/最大索引 :这使得在数字类型的等价和范围查询中能够进行有效的数据过滤。
-
BloomFilter Index :这对于高基数列的等价过滤和修剪非常有效。
-
倒排索引 :这可以快速搜索任何字段。
Apache Doris 支持多种数据模型,并针对不同场景进行了优化:
-
详细模型(重复键模型): 为满足事实表的详细存储需求而设计的详细数据模型。
-
主键模型(唯一键模型): 确保唯一键;具有相同键的数据将被覆盖,从而实现行级数据更新。
-
聚合模型(聚合键模型): 将具有相同键的值列合并,通过预聚合显著提高性能。
Apache Doris 还支持强一致的单表物化视图和异步刷新的多表物化视图。单表物化视图由系统自动刷新维护,无需用户手动干预。多表物化视图可以通过集群内调度或外部调度工具定期刷新,降低数据建模的复杂度。
查询
Apache Doris 拥有基于 MPP 的查询引擎,可在节点之间和节点内并行执行。它支持对大型表进行分布式 Shuffle Join,以更好地处理复杂查询。
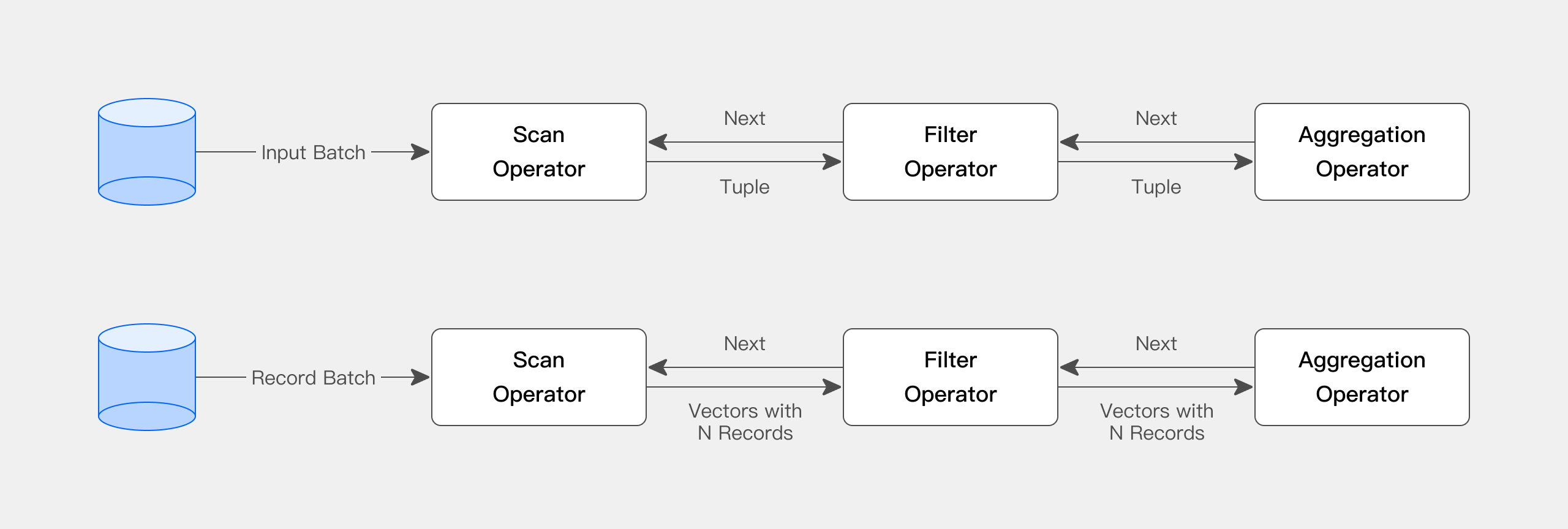
Apache Doris 的查询引擎完全矢量化,所有内存结构均以列式布局。这可以大幅减少虚函数调用,提升缓存命中率,并高效利用 SIMD 指令。在宽表聚合场景下,Apache Doris 的性能相比非矢量化引擎提升 5~10 倍。
Apache Doris 使用自适应查询执行技术,根据运行时统计信息动态调整执行计划。例如,它可以生成运行时过滤器并将其推送到探针端。具体来说,它将过滤器推送到探针端最底层的扫描节点,这大大减少了需要处理的数据量并提高了连接性能。Apache Doris 的运行时过滤器支持 In/Min/Max/Bloom Filter。
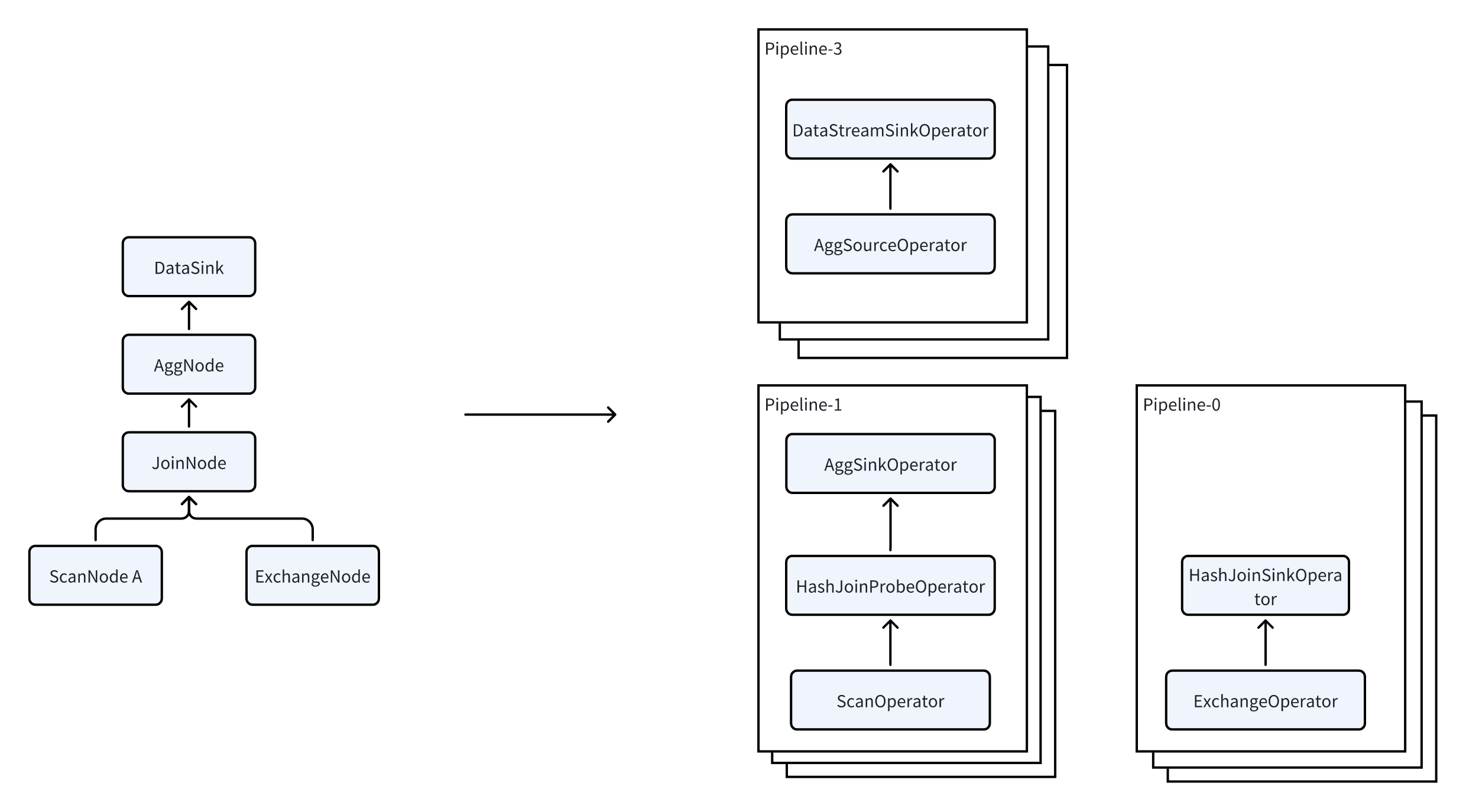
Apache Doris 采用 Pipeline 执行引擎,将查询分解为多个子任务并行执行,充分利用多核 CPU 能力。同时,通过限制查询线程数,有效解决了线程爆炸问题。Pipeline 执行引擎减少了数据复制和共享,优化了排序和聚合操作,从而显著提升查询效率和吞吐量。
在优化器方面,Apache Doris 采用了 CBO(基于成本的优化器)、RBO(基于规则的优化器)和 HBO(基于历史的优化器)的组合优化策略。RBO 支持常量折叠、子查询重写、谓词下推等优化;CBO 支持连接重排序等优化;HBO 则根据历史查询信息推荐最优执行计划。多重优化措施确保 Doris 能够针对各种类型的查询枚举出高性能的查询计划。
快速入门
警告:
以下快速部署方法仅适用于本地开发和测试,不应在生产环境中使用。原因如下:
-
数据漏洞:使用 Docker 部署时,数据很容易丢失,因为容器销毁时数据也会丢失。手动部署单副本实例缺乏数据冗余和备份功能,这意味着机器故障可能会导致数据丢失。
-
单副本配置:示例中的建表语句均为单副本,在生产环境中,为了保证数据的可靠性,应该使用多副本存储。
使用 Docker 进行快速
从Doris 2.1.8版本开始,可以使用Docker进行快速部署。
步骤 1:下载快速启动
下载脚本,运行以下命令赋予其相应的执行权限。
codeBlock_bY9V
chmod 755 start-doris.sh步骤2:启动
运行脚本启动集群,默认版本为2.1.9,可以通过 -v 参数指定启动版本,例如:
codeBlock_bY9V
bash start-doris.sh -v 3.0.4步骤3:使用MySQL客户端连接集群并检查集群
codeBlock_bY9V
## Check the FE status to ensure that both the Join and Alive columns are true.
mysql -uroot -P9030 -h127.0.0.1 -e 'SELECT `host`, `join`, `alive` FROM frontends()'
+-----------+------+-------+
| host | join | alive |
+-----------+------+-------+
| 127.0.0.1 | true | true |
+-----------+------+-------+
## Check the BE status to ensure that the Alive column is true.
mysql -uroot -P9030 -h127.0.0.1 -e 'SELECT `host`, `alive` FROM backends()'
+-----------+-------+
| host | alive |
+-----------+-------+
| 127.0.0.1 | 1 |
+-----------+-------+本地快速
环境建议:
-
操作系统:建议使用Ubuntu及以上等AMD/ARM主流Linux环境。
-
Java环境:建议使用Java 17运行环境。
-
用户权限:建议在Linux上创建一个新的Doris用户,避免使用root用户进行操作。
步骤 1:下载二进制
从 Apache Doris 网站(此处)下载相应的二进制安装包,并解压。
步骤2:修改环境
-
修改系统最大打开文件描述符限制
使用以下命令调整最大文件描述符限制。进行此更改后,您需要重新启动会话以应用配置:
codeBlock_bY9Vvi /etc/security/limits.conf * soft nofile 1000000 * hard nofile 1000000 -
修改虚拟内存区域
使用以下命令永久修改虚拟内存区域为至少 2000000,并立即应用更改:
codeBlock_bY9Vcat >> /etc/sysctl.conf << EOF vm.max_map_count = 2000000 EOF ## Take effect immediately sysctl -p
步骤 3:安装
-
配置 FE
修改FE配置文件中的以下内容
apache-doris/fe/conf/fe.conf:codeBlock_bY9V## Specify Java environment JAVA_HOME=/home/doris/jdk ## Specify the CIDR block for FE listening IP priority_networks=127.0.0.1/32 -
启动 FE
通过执行脚本来运行 FE 进程
start_fe.sh:codeBlock_bY9Vapache-doris/fe/bin/start_fe.sh --daemon -
检查 FE 状态
使用MySQL客户端连接集群并检查集群状态:
codeBlock_bY9V## Check FE Status to ensure that both the Join and Alive columns are true mysql -uroot -P9030 -h127.0.0.1 -e "show frontends;" +-----------------------------------------+-----------+-------------+----------+-----------+---------+----------+----------+-----------+------+-------+-------------------+---------------------+----------+--------+-------------------------+------------------+ | Name | Host | EditLogPort | HttpPort | QueryPort | RpcPort | Role | IsMaster | ClusterId | Join | Alive | ReplayedJournalId | LastHeartbeat | IsHelper | ErrMsg | Version | CurrentConnected | +-----------------------------------------+-----------+-------------+----------+-----------+---------+----------+----------+-----------+------+-------+-------------------+---------------------+----------+--------+-------------------------+------------------+ | fe_9d0169c5_b01f_478c_96ab_7c4e8602ec57 | 127.0.0.1 | 9010 | 8030 | 9030 | 9020 | FOLLOWER | true | 656872880 | true | true | 276 | 2024-07-28 18:07:39 | true | | doris-2.0.12-2971efd194 | Yes | +-----------------------------------------+-----------+-------------+----------+-----------+---------+----------+----------+-----------+------+-------+-------------------+---------------------+----------+--------+-------------------------+------------------+
步骤 4:安装
-
配置 BE
修改BE配置文件中的以下内容
apache-doris/be/conf/be.conf:codeBlock_bY9V## Specify Java environment JAVA_HOME=/home/doris/jdk ## Specify the CIDR block for BE's listening IP priority_networks=127.0.0.1/32 -
开始 BE
使用以下命令启动BE进程:
codeBlock_bY9Vapache-doris/be/bin/start_be.sh --daemon -
在集群中注册 BE 节点
使用 MySQL 客户端连接到集群:
codeBlock_bY9Vmysql -uroot -P9030 -h127.0.0.1使用ADD BACKEND命令注册BE节点:
codeBlock_bY9VALTER SYSTEM ADD BACKEND "127.0.0.1:9050"; -
检查 BE 状态
使用MySQL客户端连接集群并检查集群状态:
codeBlock_bY9V## Check BE Status to ensure that the Alive column is true mysql -uroot -P9030 -h127.0.0.1 -e "show backends;" +-----------+-----------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------+------------------+--------------------+---------------+---------------+---------+----------------+--------------------+--------------------------+--------+-------------------------+-------------------------------------------------------------------------------------------------------------------------------+-------------------------+----------+ | BackendId | Host | HeartbeatPort | BePort | HttpPort | BrpcPort | LastStartTime | LastHeartbeat | Alive | SystemDecommissioned | TabletNum | DataUsedCapacity | TrashUsedCapcacity | AvailCapacity | TotalCapacity | UsedPct | MaxDiskUsedPct | RemoteUsedCapacity | Tag | ErrMsg | Version | Status | HeartbeatFailureCounter | NodeRole | +-----------+-----------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------+------------------+--------------------+---------------+---------------+---------+----------------+--------------------+--------------------------+--------+-------------------------+-------------------------------------------------------------------------------------------------------------------------------+-------------------------+----------+ | 10156 | 127.0.0.1 | 9050 | 9060 | 8040 | 8060 | 2024-07-28 17:59:14 | 2024-07-28 18:08:24 | true | false | 14 | 0.000 | 0.000 | 8.342 GB | 19.560 GB | 57.35 % | 57.35 % | 0.000 | {"location" : "default"} | | doris-2.0.12-2971efd194 | {"lastSuccessReportTabletsTime":"2024-07-28 18:08:14","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false} | 0 | mix | +-----------+-----------+---------------+--------+----------+----------+---------------------+---------------------+-------+----------------------+-----------+------------------+--------------------+---------------+---------------+---------+----------------+--------------------+--------------------------+--------+-------------------------+-------------------------------------------------------------------------------------------------------------------------------+-------------------------+----------+
运行
-
使用 MySQL 客户端连接到集群:
codeBlock_bY9Vmysql -uroot -P9030 -h127.0.0.1 -
创建数据库和测试表:
codeBlock_bY9Vcreate database demo; use demo; create table mytable ( k1 TINYINT, k2 DECIMAL(10, 2) DEFAULT "10.05", k3 CHAR(10) COMMENT "string column", k4 INT NOT NULL DEFAULT "1" COMMENT "int column" ) COMMENT "my first table" DISTRIBUTED BY HASH(k1) BUCKETS 1; -
导入测试数据:
使用 Insert Into 语句插入测试数据
codeBlock_bY9Vinsert into mytable values (1,0.14,'a1',20), (2,1.04,'b2',21), (3,3.14,'c3',22), (4,4.35,'d4',23); -
在 MySQL 客户端中执行以下 SQL 查询来查看导入的数据:
codeBlock_bY9VMySQL [demo]> select * from demo.mytable; +------+------+------+------+ | k1 | k2 | k3 | k4 | +------+------+------+------+ | 1 | 0.14 | a1 | 20 | | 2 | 1.04 | b2 | 21 | | 3 | 3.14 | c3 | 22 | | 4 | 4.35 | d4 | 23 | +------+------+------+------+ 4 rows in set (0.10 sec)
ClickHouse 的替代方案
Apache Doris 与 ClickHouse 都是全球领先的实时数据仓库,支持列式存储和快速查询。Doris 拥有更高的并发性、更高效的连接、更易于维护以及类似 MySQL 的 SQL 语法等优势,使其使用和部署更加简单。
特色迁移

腾讯音乐的数据平台已从 ClickHouse 迁移至 Apache Doris,提升了数据时效性并降低了维护成本。Doris 灵活的数据采集方式和强大的一致性协议确保了其高可用性和可靠性。
强调:
-
多表连接性能大幅提升。
-
易于扩展和维护。
-
高效的数据处理和实时更新。

"Apache Doris 在绝大多数场景下查询响应速度都比 ClickHouse 更快,特别是在复杂的 join 场景下,其性能明显优于 ClickHouse。"
强调: -
核心业务查询 2-3 倍。
-
复杂连接查询 2-10 倍。
-
可以运行所有 ClickHouse OOM 查询。

"通过用 Doris 替换 ClickHouse,Kwai 成功升级到 LakeHouse 架构,简化了数据管道,无需数据导入,因为 Doris 可以直接访问数据湖数据。"
强调: -
直接查询数据湖数据。
-
提高了查询性能。
-
通过物化视图进行灵活的数据治理。
Apache Doris 与
| 阿帕奇多丽丝 | ClickHouse | |
|---|---|---|
| 架构与 SQL | * 基于MPP架构 * 标准 SQL 支持,兼容 MySQL | * 使用分散-聚集架构 * 类似 SQL 的功能,但使用非标准 SQL |
| 查询 | * 分布式连接 * 基于成本的优化(CBO) * 查询重写和多表物化视图 * 更高的并发性能 | * 连接实施不佳 * 缺乏基于成本的优化器(CBO) * 仅支持单表物化视图 * 并发性能较低 |
| 实时更新 | * 具有强一致的主键存储模型,支持同步数据更新和删除 | * 仅支持异步更新,允许在更新后读取旧值。 |
| 数据 API | * 提供基于 Arrow-flight 的高吞吐量读取 API,促进与数据科学/AI 工具等其他引擎的集成 | * 仅通过 JDBC API 进行低效的数据读取 |
| 建造开放式湖畔别墅 | * 充当 Lakehouse SQL 引擎,支持 Hive、Hudi、Iceberg 和 Parquet 数据湖格式的查询 | * Lakehouse 集成能力有限 |
| 运营与维护 | * 支持自动缩减、扩展和副本平衡 | * 缩放操作期间需要手动重新平衡 |
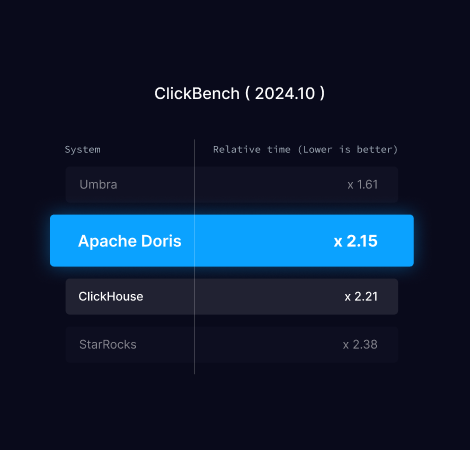
| 表现 | * 在宽表基准测试(ClickBench)中,Doris 在 2022 年 10 月和 2024 年 10 月均位列第一或第二,表现优于 ClickHouse * 在大型TPC-H和TPC-DS测试中,Doris取得了领先的性能 | * 在 ClickBench 性能方面,ClickHouse 和 Doris 一直轮流领先 * 在大型 TPC-H 和 TPC-DS 测试中遇到许多 OOM(内存不足)查询 |
性能
ClickBench
ClickBench 是由 ClickHouse 团队创建和维护的用于评估分析数据库性能的基准测试工具。
它专注于测试大型扁平表的性能,**而非复杂的多表连接。**它使用来自主流网络分析平台的真实数据,涵盖点击流分析和结构化日志等典型场景。
该基准测试由一组查询组成,用于测试聚合操作和单表性能,无需复杂的连接操作。这使得它对于评估针对实时分析和大规模数据处理进行优化的数据库特别有用。
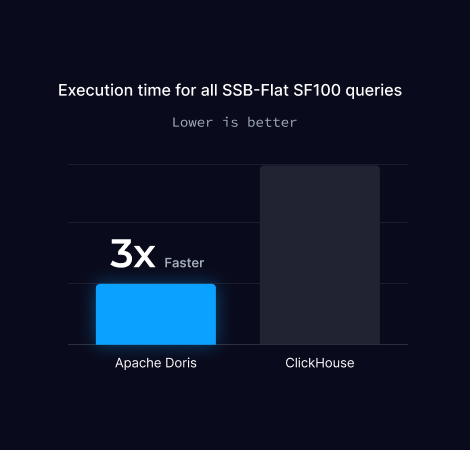
SSB-Flat SF100
SSB-Flat SF100 是一个基准测试,旨在测试分析数据库处理大型宽表的性能。
它源自星型模式基准 (SSB),但将星型模式扁平化为单个宽表,以关注单表查询的性能。
SF100表示数据规模为基数的100倍,是评估查询性能和系统可扩展性的重要测试。
TPC-H SF100
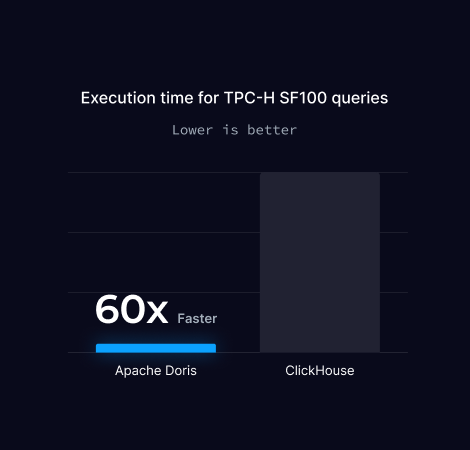
比例因子为 100 的 TPC-H 基准测试 (SF100) 是评估数据库性能的广泛使用的标准。它包含一组复杂的 SQL 查询,旨在模拟现实世界的商业智能工作负载。
SF100表示数据规模是基础规模的100倍,是衡量查询性能和系统可扩展性的大规模测试。
注意:由于 ClickHouse 有 7 个查询执行失败,因此总执行时间指的是 Doris 运行全部 22 个查询所用的时间,以及 ClickHouse 仅运行 15 个查询所用的时间。
TPC-DS 1TB
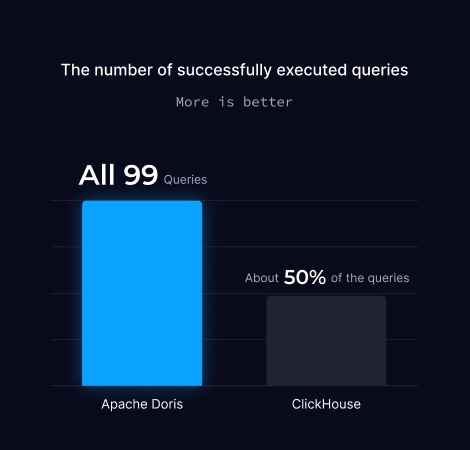
TPC-DS 1TB 是评估数据仓库和分析数据库性能的广泛认可的基准。它涉及大约 1TB 大小的数据集,包含分布在 24 个表中的约 63.5 亿条记录。
该基准测试包括 99 个复杂查询,旨在测试数据库性能的各个方面,例如连接、聚合和子查询。
TPC-DS 模式基于雪花模式,代表了 Web、目录和商店销售等真实场景。1TB 的规模对于数据仓库来说算是中等规模,但由于查询的复杂性和记录数量庞大,仍然具有挑战性。
注意:TPC-DS 大量使用了相关子查询,而 ClickHouse 在测试时(2024 年 9 月)尚不支持这些子查询。因此,大约 50% 的基准查询会失败并出现错误。
更多迁移
Elasticsearch 的替代方案
Elasticsearch 和 Apache Doris 在可观测性、网络安全和实时分析领域都很受欢迎。然而,Elasticsearch 的存储和写入资源成本较高。Apache Doris 通过高效的存储和高压缩率降低了这些成本,并提供全面的分析功能,例如 JOIN 和卓越的查询性能。
特色迁移

"通过用 VeloDB(由 Apache Doris 提供支持)替换 Elasticsearch,GuanceDB 在提高数据处理速度和降低成本方面取得了巨大进步。"
强调:
-
成本降低70%
-
全文搜索性能提高 2-3 倍
-
变体数据类型可以灵活地处理日志跟踪中的半结构化数据

"以前,我们使用多个组件进行复杂的安全分析......采用 Doris 作为统一解决方案,显著提高了数据写入、查询性能和存储效率。"
强调: -
写入速度提高 4 倍
-
查询性能提高 3 倍
-
节省 50% 的存储空间

与原有的OLAP数据库相比,查询性能提高了5-10倍,并发能力提高了一倍,90%的分析时间从10分钟缩短到1分钟以内,而所用资源仅为原有的三分之一。
强调: -
报告分析并发度提高 2 倍
-
减少 65% 的存储空间
-
使用标准 SQL 简化查询
Apache Doris 与
| 阿帕奇多丽丝 | Elasticsearch | |
|---|---|---|
| 开放源代码许可证 | * 根据 Apache License 2.0 许可 * 自 Apache 软件基金会管理以来的稳定许可证 | * 许可证从 Apache 许可证 2.0 更改为 Elastic 许可证,然后更改为 AGPL 许可证 * 自 Elastic NV 管理以来,许可证不断变更 |
| 建筑学 | 更高的灵活性和弹性: * 通过工作负载组进行严格的工作负载隔离,由 Linux CGroups 提供支持,非常适合多租户 * 计算-存储解耦和耦合模式 | 传统部署弹性有限: * 按线程组隔离软工作负载 * 不支持计算和存储分离 |
| 实时数据写入 | * 高吞吐量:仅在一个副本上建立索引 * 通过 Kafka CDC 进行基于拉取的摄取,更轻松、更简单 * 支持 Logstash 和 Beats 输出插件 | * 低吞吐量:为多个数据副本建立索引 * 需要 Logstash 和 Beats 等额外工具进行基于拉取的数据提取,不太方便 |
| 实时数据存储 | * 存储消耗低,压缩率高达 1:5 - 1:10 * 独特的模型支持写入和读取优化(MoW 和 MoR),当数据被关键复制时,仍保留 90% 的写入速度 * 聚合模型支持强一致性,允许聚合数据更新,与原始数据共存 * 灵活的架构变更以满足动态业务需求 | * 存储消耗大,压缩比为1:1.5 * 独特模型仅支持写入优化,写入性能损失高达3倍 * 聚合模型不允许聚合数据更新,且不与原始数据共存 * 对架构变更的支持有限 |
| 实时数据查询 | * 在各种查询工作负载中速度极快 * 支持多表JOIN和复杂分析的优化 * 易于使用标准 SQL * 开放的 MySQL 生态系统 | * 擅长点查询,但不适合数据分析 * 不支持多表连接或复杂分析 * 由于自定义 DSL,给用户带来困难 * 专有 Elasticsearch 生态系统 |
性能
可观察性和网络
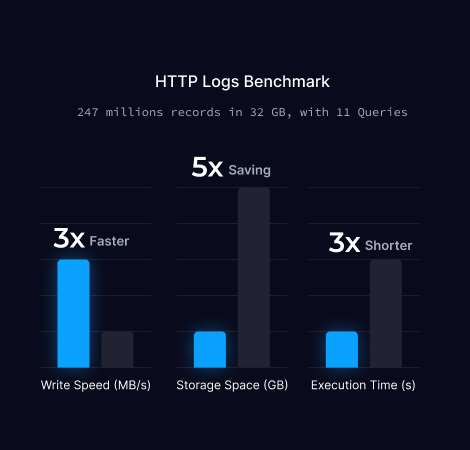
HTTP 日志基准测试是 Elasticsearch 官方针对日志存储和分析的性能测试。它使用真实的 HTTP 日志数据集来评估索引性能、存储效率和查询性能。
该基准测试涵盖了日志分析场景中常用的 11 个查询,包括关键字搜索、时间范围查询、聚合和排序等,非常适合用于评估可观测性和网络安全分析场景下的性能。
实时
ClickBench 是一款用于评估分析型数据库性能的基准测试工具。它专注于测试大型扁平表的性能,而非复杂的多表连接。它使用来自主流网络分析平台的真实数据,涵盖点击流分析和结构化日志等典型场景。
该基准测试由一组查询组成,用于测试聚合操作和单表性能,无需复杂的连接操作。这使得它对于评估针对实时分析和大规模数据处理进行优化的数据库特别有用。
注意:这些测试结果是 2024 年 12 月捕获的存档基准。当前的实时比较在ClickBench上维护。

更多迁移
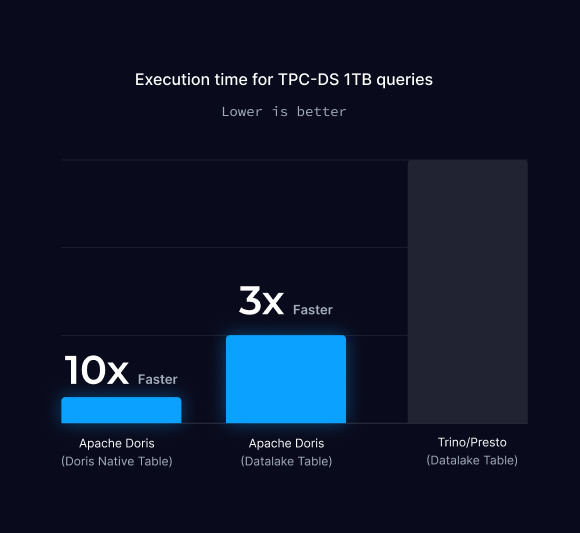
Apache Doris vs Trino / Presto
Apache Doris 和 Trino/Presto 都是流行的数据湖查询引擎,但 Doris 在性能方面优于 Trino/Presto。Trino/Presto 主要作为查询引擎,而 Doris 也可以作为独立的数据仓库运行。这使得企业能够通过 Doris 将数据仓库和 Lakehouse 查询引擎统一起来,从而简化数据架构。
-
统一:Doris 统一了数据仓库和 Lakehouse 查询引擎,简化了技术堆栈
-
10 倍查询性能:与 Presto/Trino 相比,Doris 原生表可将查询性能提高 10 倍
-
速度提升 2-3 倍:Doris 作为 Lakehouse 引擎,速度比 Presto/Trino 快 2-3 倍
特色迁移

作为全球知名的互联网巨头,我们早期的数据平台使用了 Trino、Pinot、Iceberg 和 Kyuubi,但面临复杂性、冗余性和性能不佳的问题。通过使用 Apache Doris 替换它们,我们统一了其数据湖库和查询引擎,从而提高了性能并将成本降低了 30%。

从 Presto 切换到 Doris 后,查询性能显著提升,**查询时间从 20-40 秒缩短到 1-2 秒。**通过基于常用数据维度设计 2-3 个物化视图,Doris 可以自动匹配查询的最优视图,进一步提升性能。
使用 Trino 和 SparkSQL,查询延迟在分钟级,性能也很低。切换到 Doris 后,性能提升了 2 倍。Doris还统一了技术栈,简化了实时和交互式分析工具的管理。
Apache Doris 与 Trino /
| 阿帕奇多丽丝 | 特里诺/普雷斯托 | |
|---|---|---|
| 建筑学 | * **统一架构:**结合数据仓库和 Lakehouse 查询引擎的功能 | * **联合查询:**擅长跨多个异构数据源进行查询,无需数据移动,但缺乏内置存储 |
| 执行引擎 | * 采用 C++ 实现的完全矢量化执行引擎,用于高性能数据处理 | * 主要用 Java 实现,矢量化目前正在作为 Hummingbird 项目的一部分进行开发 |
| 查询优化器 | * 高级查询优化器,针对连接、聚合和排序等复杂 SQL 操作进行基于成本的优化 | * 支持基于成本的优化,但统计信息收集和手动完整收集不太先进 |
| 缓存机制 | * **元数据缓存:**具有 TTL、自动刷新和增量同步的内存元数据缓存 * **数据缓存:**本地 SSD 上的热数据缓存,以减少网络 I/O * **查询缓存:**用于查询结果缓存的 SQL 缓存和分区缓存 | * **数据缓存:**依赖于 Alluxio 等外部缓存解决方案 |
| 物化视图 | * **增量刷新:**支持增量刷新,多种更新策略 * **透明加速:**查询优化器自动将查询路由到最合适的物化视图 | * **手动刷新:**仅限于手动、完全刷新,功能较少 |
| 用例 | * 高并发实时分析 * 交互式分析 | * 仅限交互式分析 |
性能
TPC-DS 1TB
TPC-DS 1TB 基准测试使用包含 24 个表、共 63.5 亿条记录的 1TB 数据集来评估数据仓库性能。它包含 99 个复杂查询,用于测试连接、聚合和子查询。它基于雪花模式,模拟真实的销售场景。由于查询复杂性,1TB 规模的测试具有挑战性。
测试环境包括:
- 1 个 FE/Coordinator 节点和 5 个 BE/Worker 节点。
- 每个节点有 64 个核心、1.5TB 内存和 SSD 存储。
- HDFS 位于这些节点上,并创建了 Hive 表。
本次测试,使用相同的数据集和同等的计算服务,结果显示:
- 当数据导入到Doris内部表,使用Doris进行查询时,实现了最短的执行时间。
- 当单独使用 Doris 和 Trino 直接从 Hive 表查询数据时,Doris 在数据湖中展现出了卓越的查询加速性能。