这是一篇关于个人学习 AI 的笔记与代码摘录。希望从前端的视角出发,快速了解大语言模型(LLM)、提示词工程、LangChain、RAG 等相关术语知识,最终能够搭建一个 "玩具智能体" 或者真正应用到生产中去。
目录 📑
- LLM 基础:深入 AI 的心脏
- 提示词工程:与 AI 对话的艺术
- LangChain.js 实战:搭建你的第一个 AI 应用
- RAG:让 AI 拥有你的专属知识库
- 多模态:让 AI 看见听见
- 其他术语
LLM 基础:深入 AI 的心脏 🤖
要理解 AI 应用,我们首先要抓住大语言模型(LLM)的核心。它的本质其实非常朴素:一次一个 token 地补全内容,或者说,不断地"预测下一个词"。
比如下面,会计算接下来字符的出现概率

通过不断预测下个词,最终生成一段话:

但这个预测过程并非总是选择概率最高的词,否则每次的回答都会一成不变。为了引入创造性,模型在采样时会加入一些随机性。这可以通过 temperature (温度) 这个参数来控制:
- 较低的
temperature(如 0.2): 回答更具确定性和稳定性,适合需要事实性回答的场景。 - 较高的
temperature(如 0.8): 回答更具发散性和创意。
那么,模型是如何理解我们输入的文字的呢?计算机会将文字(字符串)转换为数字(向量)。这个过程通常分为两步:第一步 One-Hot编码,第二步,将编码结果进行压缩。
如下图,文本中的每个 Token 都会对应一个向量。起初,这是一个包含大量 0 的稀疏向量。
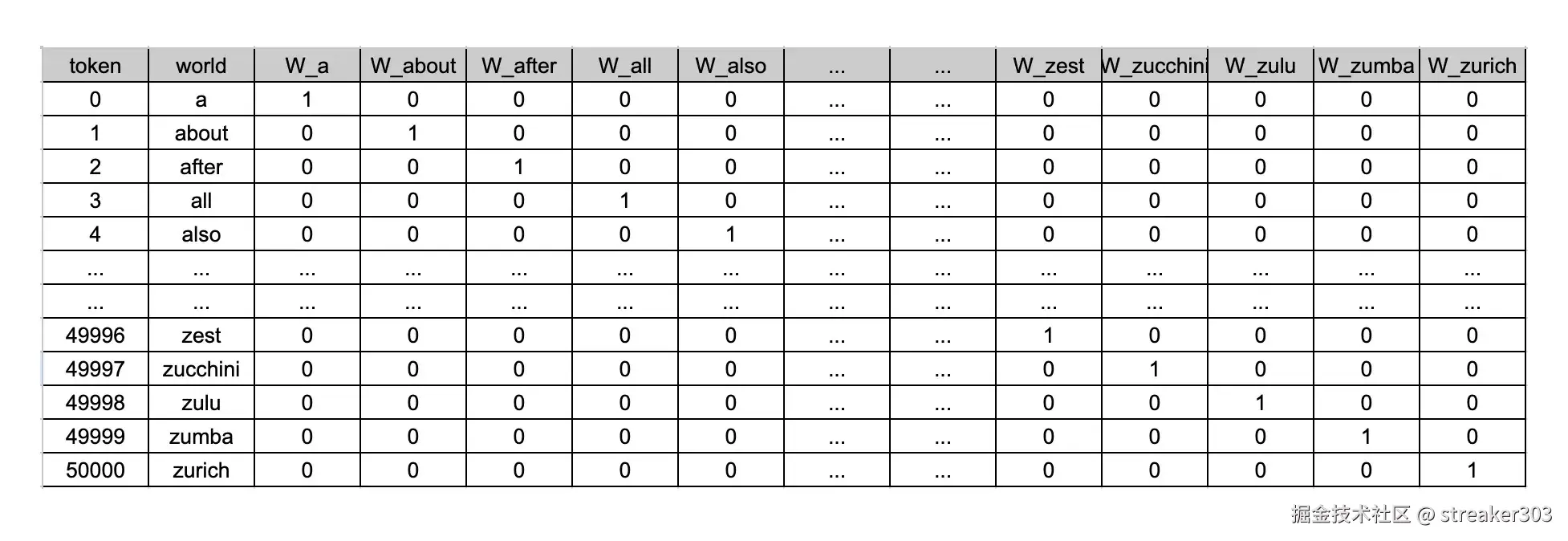
经过 Embedding 处理后,一个硕大的向量就会压缩成一个固定大小的向量。比如在 GPT3 中,每个 Token 由768个数字组成的向量表示。
在与大模型 API(以 OpenAI 为例)交互时,有一些常用参数可以帮助我们精确地控制模型的行为。这里我们对它们进行一个简单的记录和解释,便于理解和查询(不同的大模型 API 参数会有差异)。
核心参数
这些是每次调用时几乎都会用到的基础参数。
- model: (字符串) 指定要使用的模型 ID,例如 "gpt-4o-mini"。
- messages: (数组) 包含了整个对话历史的消息列表。每个消息都是一个对象,包含 role (角色,如 "system", "user", "assistant") 和 content (内容)。这是模型理解上下文的关键。
- temperature: (数字, 0-2) 控制输出的随机性。
- max_tokens: (整数) 设置在生成的回复中允许的最大 token 数量。这是一个控制回复长度和 API 成本的有效手段。
- stream: (布尔值) 如果设置为 true,API 会以数据流(Server-Sent Events)的形式分块返回结果,可以实现前端的"打字机"效果。如果为 false,则会等所有内容生成完毕后一次性返回。
工程参数
- user: (字符串) 最终用户的唯一标识符。
- n: (整数) 为每条输入消息生成的回复数量。
- response_format: (对象) 规定模型输出的格式,如 JSON。
工具类参数
用于扩展模型的能力,让它能与外部世界交互。
- tools: (数组) 模型可调用的外部工具(函数)列表。
- tool_choice: (字符串或对象) 控制模型如何选择和调用工具。
采样与行为参数
用于更精细地调整模型的生成策略。
- seed: (整数) 用于实现可复现、确定性输出的采样种子。
- stop: (字符串或数组) 模型生成时遇到即停止的文本序列。
- frequency_penalty: (数字, -2.0 到 2.0) 降低模型重复已生成文本的惩罚值。
- logit_bias: (对象) 手动调整特定 Token 的出现概率。
- top_p: (数字, 0-1) 一种替代
temperature的核采样方法,控制生成文本的多样性。
提示词工程:与 AI 对话的艺术 🧠
与大模型沟通的艺术,就是提示词工程(Prompt Engineering)。一个好的提示词能极大提升模型的表现。
从用户的角度来看,一个结构化的提示词可以遵循这样一个公式:
提示词 = 定义角色 + 背景信息 + 任务目标 + 输出要求
在实践中,有几种常见的提示词范式可以帮助我们更好地引导模型:
- 零样本(Zero-shot):直接向模型提出你的需求,适用于那些模型已经很熟悉的通用任务。
- 少样本(Few-shot):在提问前给模型一两个示例或参照,这在处理特定或复杂任务时尤其有效。
- 思维链(Chain-of-Thought, CoT):引导模型"慢下来",一步一步地思考,并把推理过程展示出来。这不仅能提高复杂问题的准确率,还能让我们了解它的"思考"轨迹。 下图左边是让大模型直接返回结果,右边是提示大模型慢思考。(比如 1.11 和 1.2 哪个大这种,符合这个场景)

- ReAct 框架 :即 R easoning(推理)+ Acting(行动)。它将大模型的推理能力和调用外部工具(如搜索引擎)的行动能力结合起来,让 AI 能够解决自身知识库之外的问题。
LangChain.js 实战:搭建你的第一个 AI 应用 🧩
LangChain 是一个强大的开源框架,它能帮助我们轻松地构建和组合各种大模型应用,我们称之为"链"(Chain)。
它的生态还包括:
- LangServe: 用于快速部署。
- LangSmith: 用于调试和监控。
- LangGraph: 用于构建复杂 Agent。
其核心是 LCEL(LangChain Expression Language),一种用管道符 | 将不同组件声明式地组装在一起的表达式语言,非常清晰且易于复用。
【【---下面代码摘自 python 学习资料,不需要完全理解具体实现,能知道有那么个 API 能够在各阶段进行相应的处理就行了。---】】
ChatModel:基础的对话调用
从最基础的开始:如何与一个聊天模型进行交互。下面的代码展示了如何发送系统和用户消息,并获得模型的回复。
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "你的 API Key"
os.environ["OPENAI_API_BASE"] = "你的 API Base"
messages = [
SystemMessage(content="Translate the following from English into Chinese:"),
HumanMessage(content="Welcome to LLM application development!"),
]
model = ChatOpenAI(model="gpt-4o-mini")
result = model.invoke(messages)
print(result)PromptTemplate:优雅管理提示词
为了让代码更清晰、更易于维护,我们通常不会把给开发者的指令和用户的输入混在一起。LangChain 提供了 PromptTemplate 来优雅地解决这个问题。
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "Translate the following from English into Chinese:"),
("user", "{text}")
]
)
model = ChatOpenAI(model="gpt-4o-mini")
chain = prompt_template | model
result = chain.invoke({"text":"Welcome to LLM application development!"})
print(result)OutputParser:获取结构化的输出
有时我们希望模型返回的是严格的 JSON 格式或其他结构化数据,而不是纯文本。OutputParser 可以帮助我们定义输出格式,并自动解析模型的返回结果。
python
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
class Work(BaseModel):
title: str = Field(description="Title of the work")
description: str = Field(description="Description of the work")
parser = JsonOutputParser(pydantic_object=Work)
prompt = PromptTemplate(
template="列举3部{author}的作品。\n{format_instructions}",
input_variables=["author"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
model = ChatOpenAI(model="gpt-4o-mini")
chain = prompt | model | parser
result = chain.invoke({"author": "老舍"})
print(result)会话记忆:让机器人"记住"上下文
标准的 API 调用是无状态的,但聊天机器人需要记住之前的对话。LangChain 提供了多种方式来管理会话历史,让我们的应用能够进行连续的多轮对话。
python
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
chat_model = ChatOpenAI(model="gpt-4o-mini")
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
with_message_history = RunnableWithMessageHistory(chat_model, get_session_history)
config = {"configurable": {"session_id": "dreamhead"}}
while True:
user_input = input("You:> ")
if user_input.lower() == 'exit':
break
stream = with_message_history.stream(
[HumanMessage(content=user_input)],
config=config
)
for chunk in stream:
print(chunk.content, end='', flush=True)
print()RAG:让 AI 拥有你的专属知识库 🔍
大模型虽然知识渊博,但它的知识是静态的(截止到某个训练日期),而且不包含你的私有数据。
那么,如何让模型"知道更多"呢?答案就是 RAG(Retrieval-Augmented Generation),即检索增强生成。
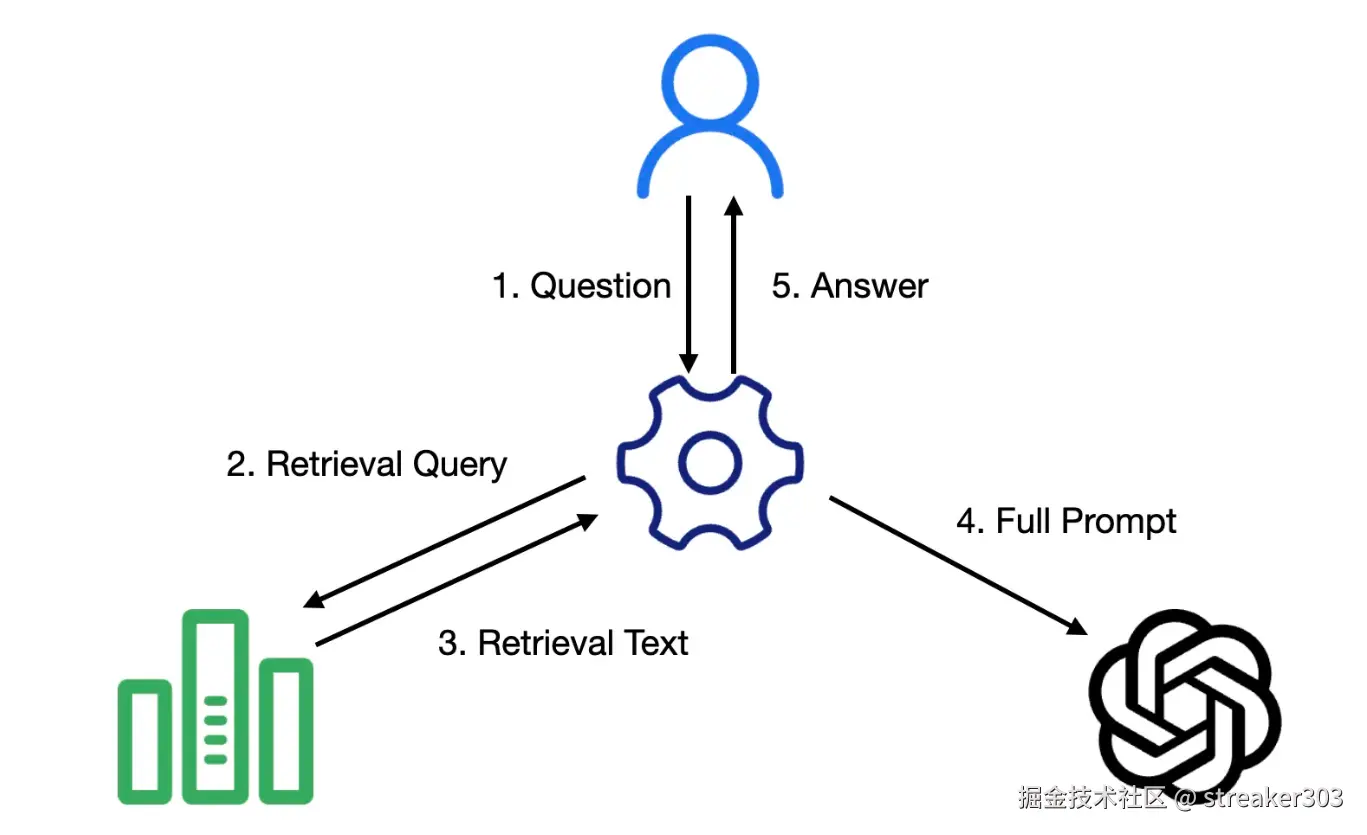
它的核心思想很简单,就是"先查后答"。具体流程如下:
-
接收问题: 用户提出问题。
-
检索: 不直接把问题丢给大模型,而是先用它去检索我们自己的知识库(比如公司的产品文档、个人笔记等)。
-
增强: 把检索到的相关内容和原始问题一起打包,作为更丰富的上下文(Context)交给大模型。
-
生成: 让大模型基于这些信息来生成最终答案。
用户问题
↓
文本转 Embedding → 检索知识库(向量匹配)
↓
找到相关内容
↓
大模型生成答案(融合外部信息)
关于向量数据库的见解
向量数据库的核心,是将文本等多模态数据转化为高维空间中的向量。每一个词、每一段话,都相应地成为 N 维空间中的一个点。
这种表示方式的强大之处在于,我们可以通过计算这些点之间的"距离"或"夹角"来量化它们的语义相似度。以二维空间为例,两个向量的点积可以揭示它们的关系:
- 锐角 (点积为正): 表示语义相似。
- 垂直 (点积为零): 表示语义无关。
- 钝角 (点积为负): 表示语义背离或相反。
这种从几何角度理解语义的算法,不仅是 RAG 的基石,也是许多推荐系统的核心原理,让机器能够在海量信息中找到"邻近"的内容。

数据入库:构建你的向量知识库
首先,我们需要将文档加载、切分、并转换为向量,存入专门的向量数据库中。
python
from langchain_community.document_loaders import TextLoader
loader = TextLoader("introduction.txt")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma(
collection_name="ai_learning",
embedding_function=OpenAIEmbeddings(),
persist_directory="vectordb"
)
vectorstore.add_documents(splits)检索与生成:完成 RAG 的闭环
当用户提问时,我们从向量数据库中检索最相似的文档片段,并将其提供给模型。
python
vectorstore = Chroma(
collection_name="ai_learning",
embedding_function=OpenAIEmbeddings(),
persist_directory="vectordb"
)
retriever = vectorstore.as_retriever(search_type="similarity")
# Retriever 承担 RAG 中的 R:根据文本查询文档(Document)关键点:RAG 的成功与否,很大程度上取决于数据处理的质量。包括:
- 如何有效地提取数据源
- 选择合适的分块(Chunking)策略
- 优化向量化和检索算法等
多模态:让 AI 看见听见 🏞️🗣️
现代的 AI 应用早已超越了纯文本的范畴。
多模态意味着模型能够理解和处理多种类型的信息,如文本、图片、音频和视频。作为前端开发者,我们需要掌握如何在客户端处理这些复杂的输入和输出。
下面,我们将通过几个具体的场景,来看看前端是如何与多模态模型进行交互的。
场景一:文本与流式文本 (Text & Streaming)
这是最基础的交互。除了"一次性"返回所有结果,更优的用户体验是"流式"返回,即像打字机一样逐字显示内容。
在前端,这通常通过 fetch API 结合 ReadableStream 来实现。
-
关键代码 (
Chat.vue):typescript// ... if(stream.value) { const completion = await openai.chat.completions.create({ model: MODEL, stream: true, // 关键参数 messages: [ /* ... */ ] }); // 逐块读取流 for await (const chunk of completion as any) { const delta = chunk?.choices?.[0]?.delta?.content; if(delta) content.value += delta; } } else { const completion = await openai.chat.completions.create({ /* ... */ }); content.value = completion.choices?.[0]?.message?.content || '(无返回)'; } // ... -
解释 :当
stream: true时,返回的是一个数据流。我们通过for await...of循环来异步地迭代这个流,每次迭代得到一个数据块(chunk),然后将增量内容(delta)追加到界面上,实现了流畅的打字机效果。
场景二:文生图 (Text-to-Image)
调用文生图模型时,前端需要构造一个包含详细参数的请求,并将返回的图片 URL 展示出来。
-
关键代码 (
image.vue):typescript// ... const body = { model: 'qwen-image', input: { messages: [ { role: 'user', content: [ { text: prompt.value.trim() } ] } ] }, parameters: { negative_prompt: negativePrompt.value || '', size: size.value } }; const resp = await fetch('/api/.../multimodal-generation/generation', { method: 'POST', headers: { 'Content-Type': 'application/json', 'Authorization': `Bearer ${apiKey}` }, body: JSON.stringify(body) }); const json = await resp.json(); // 从复杂的 JSON 结构中解析出图片 URL const choices = json?.output?.choices || []; for (const c of choices) { const contents = c?.message?.content || []; if (Array.isArray(contents)) { for (const item of contents) { if (item?.image && typeof item.image === 'string') list.push(item.image); } } } // ... -
解释 :前端将用户的提示词、反向提示词和期望尺寸等参数打包成一个 JSON 对象发送给模型。请求成功后,需要根据 API 的约定,从层层嵌套的 JSON 响应中解析出最终的图片 URL 数组,并将其渲染到
<img>标签上。
场景三:流式文本转语音 (Streaming TTS)
为了实现低延迟的语音合成,前端可以接收实时的音频流并立即播放,而不是等待整个音频文件生成完毕。这通常使用 SSE (Server-Sent Events) 协议。
-
关键代码 (
TTS.vue):typescript// ... // 1. 发起 SSE 请求 const resp = await fetch('/api/.../multimodal-generation/generation', { method: 'POST', headers: { 'Authorization': `Bearer ${apiKey}`, 'X-DashScope-SSE': 'enable' // 启用 SSE }, body: JSON.stringify(body), }); // 2. 实时处理音频流 const reader = resp.body.getReader(); const decoder = new TextDecoder(); while(true) { const { done, value } = await reader.read(); if(done) break; // ... 解析 SSE 消息 ... const chunkB64 = out.audio_chunk; // 获取 Base64 编码的 PCM 音频块 if(!chunkB64) continue; const pcm = base64ToBytes(chunkB64); playPcmRealtime(pcm, sampleRate); // 实时播放 } // 3. 使用 Web Audio API 播放 PCM 数据 let audioCtx = new AudioContext(); let scheduledTime = 0; function playPcmRealtime(pcm, sr) { if(!audioCtx) return; const frameCount = pcm.length / 2; // 16-bit const abuf = audioCtx.createBuffer(1, frameCount, sr); // ... 将 PCM 数据写入 AudioBuffer ... const src = audioCtx.createBufferSource(); src.buffer = abuf; src.connect(audioCtx.destination); src.start(scheduledTime); // 精确调度播放时间,避免爆音 scheduledTime += abuf.duration; } // ... -
解释 :
- 请求头中加入
'X-DashScope-SSE': 'enable'来告诉服务端我们需要一个 SSE 连接。 - 使用
ReadableStream和TextDecoder来逐行读取和解析服务端推送的事件。 - 每个事件中包含一小段 Base64 编码的原始音频数据(PCM)。
- 我们使用
Web Audio API(AudioContext) 将这些 PCM 数据解码成AudioBuffer,并通过createBufferSource创建一个音频源进行无缝播放,实现了几乎无延迟的语音合成效果。
- 请求头中加入
场景四:图生视频 (Image-to-Video)
视频生成通常是耗时很长的异步任务。前端在提交请求后不会立刻得到结果,而是会收到一个任务 ID。之后,前端需要通过这个 ID 定期去轮询(Poll)任务状态,直到任务完成并获取视频 URL。
-
关键代码 (
Video.vue):typescript// 1. 提交异步任务 const resp = await fetch('/api/.../video-synthesis', { method: 'POST', headers: { 'Authorization': `Bearer ${apiKey}`, 'X-DashScope-Async': 'enable' // 启用异步模式 }, body: JSON.stringify(body) }); const json = await resp.json(); const returnedTaskId = json?.output?.task_id; if (returnedTaskId) { pollTask(returnedTaskId); // 开始轮询 } // 2. 轮询任务状态 const pollTask = async (id, interval = 5000) => { const endpoint = `/api/v1/tasks/${id}`; for (let attempt = 1; attempt <= maxAttempts; attempt++) { const r = await fetch(endpoint, { headers: { 'Authorization': `Bearer ${apiKey}` } }); const j = await r.json(); const s = j?.output?.task_status; const v = findVideoUrl(j); // 尝试从返回中寻找视频 URL if (v) { videoUrl.value = v; // 找到了!停止轮询 return; } if (s === 'SUCCEEDED') { /* 任务成功但可能 URL 在别处,继续解析 */ } await new Promise(res => setTimeout(res, interval)); // 等待 5 秒再查 } }; -
解释 :
- 请求头中加入
'X-DashScope-Async': 'enable'来启动一个异步任务。 - 从初始响应中获取
task_id。 - 启动一个
pollTask函数,该函数会每隔几秒钟(例如 5 秒)调用任务查询接口,检查任务状态。 - 当任务状态变为
SUCCEEDED或直接在响应中找到视频 URL 时,轮询结束,前端将视频展示给用户。
- 请求头中加入
场景五:图片文字识别 (OCR)
对于 OCR 这样的视觉语言模型,API 调用方式也发生了变化。我们需要在一个请求中同时包含图片和文本指令。
-
关键代码 (
Ocr.vue):typescript// ... const body = { model: 'qwen-vl-ocr', messages: [ { role: 'user', content: [ { type: 'image_url', image_url: imageUrl.value.trim() }, { type: 'text', text: buildPrompt() } // "请识别图片中全部文字..." ]} ] }; const resp = await fetch('.../chat/completions', { /* ... */ }); // ... -
解释 :在
messages数组中,content不再是一个简单的字符串,而是一个包含不同类型对象的数组。{ type: 'image_url', ... }用来指定图片地址。{ type: 'text', ... }用来给出具体的指令(比如要求返回纯文本还是 JSON)。 这种灵活的结构让我们可以轻松地实现复杂的图文混合输入。
其他术语 🛠️
在构建更复杂的 AI 应用时,我们会接触到一些关键的工具和协议:
- MCP(Model Context Protocol):Agent 与外部工具(Tool)之间沟通的协议,统一了上下文与调用规则。
- Function Calling:让模型能够调用外部函数或 API 的机制。
- History:在会话类应用中用于保存和管理上下文的机制。
- 向量数据库与索引:专门用于存储和高效检索向量数据的数据库,是 RAG 的核心。
- Schema:数据结构的规范,用于约束输入、输出或工具的格式。
写在最后 ✍️
AI 的世界这么大,后面会边学边补充,觉得有帮助不妨点个收藏夹~~