文章目录
- 一、研究背景与目标
- 二、核心创新点
-
- [(一)3D 因果VAE](#(一)3D 因果VAE)
- [(二) 专家Transformer与自适应层归一化(Expert AdaLN)](#(二) 专家Transformer与自适应层归一化(Expert AdaLN))
-
- [1. 分块化(Patchify)与序列生成](#1. 分块化(Patchify)与序列生成)
- [2. 3D 旋转位置编码(3D-RoPE)](#2. 3D 旋转位置编码(3D-RoPE))
- [3. 专家自适应层归一化(Expert AdaLN)](#3. 专家自适应层归一化(Expert AdaLN))
- [4. 3D 全注意力机制](#4. 3D 全注意力机制)
- (三)训练策略优化
-
- [1. 多分辨率帧打包(Multi-Resolution Frame Pack)](#1. 多分辨率帧打包(Multi-Resolution Frame Pack))
- [2. 渐进式训练(Progressive Training)](#2. 渐进式训练(Progressive Training))
- [3. 显式均匀采样(Explicit Uniform Sampling)](#3. 显式均匀采样(Explicit Uniform Sampling))
- (四)数据处理流程
- 三、模型总体架构
论文:CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
一、研究背景与目标
CogVideoX是针对文本到视频生成任务的大规模扩散变换器模型,旨在解决现有视频生成模型在运动幅度有限、生成时长短、语义连贯性差等问题。其核心目标是生成高分辨率(768×1360像素)、长时长(10秒)、高帧率(16fps) 且与文本提示高度对齐的视频。
二、核心创新点
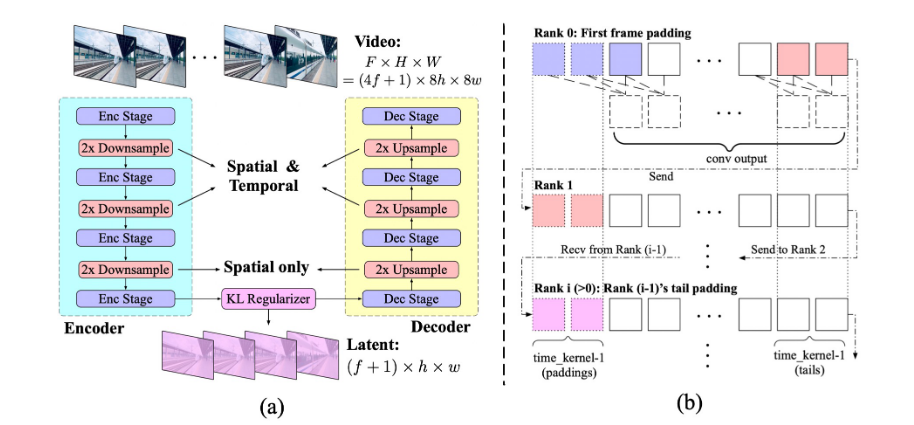
(一)3D 因果VAE
作用: 在空间和时间两个维度上对视频进行压缩,减少序列长度和计算成本,增强视频重建的连续性和减少闪烁。
核心方法: 结合3D Causal Convlution来在空间和时间上压缩视频(模型中所有的3D卷积都替换成3D因果卷积)
具体结构: 包含编码器、解码器和KL正则化器,支持时空因果卷积。
- 编码器和解码器:对称结构,通过交错堆叠的 3D 和 2D 卷积层实现时空下采样(编码)和上采样(解码)。
- 损失函数:结合 L1 重建损失、LPIPS 感知损失、KL 散度正则化,后期引入 3D 判别器的 GAN 损失增强细节。
- 时间因果卷积(下图b):只在时间维度前侧填充(而不是对称填充),确保当前帧仅依赖于过去信息,保证了未来的信息不会影响现在或过去的预测。
时间因果卷积的填充方式在上下文并行计算中得以实现:其中每个设备仅处理视频片段的一部分,并通过发送边界信息(长度 k−1)到相邻设备来维持因果性,通信开销较低。
(二) 专家Transformer与自适应层归一化(Expert AdaLN)
1. 分块化(Patchify)与序列生成
视觉潜在表示通过分块操作转换为序列化的视觉标记vision tokens:
- 分块参数:时间压缩因子 q q q(每 q q q帧压缩为一个时间token),空间压缩因子 p p p(每 p × p p\times p p×p像素区域压缩为一个空间token)
- 生成序列 z v i s i o n z_{vision} zvision的长度: L = T q × H p × W p L=\frac{T}{q}\times \frac{H}{p} \times \frac{W}{p} L=qT×pH×pW
- 首帧重复机制( q > 1 q \gt1 q>1时的处理):当时间压缩因子 q > 1 q \gt1 q>1 时(即时间维度被下采样),在序列起始端重复视频或图像的第一帧,从而统一图像与视频的输入格式,支持联合训练。此外,重复帧作为时间锚点能够提供稳定的初始状态,减少生成视频的起始闪烁现象。
2. 3D 旋转位置编码(3D-RoPE)
Rotary Position Embedding (RoPE) 是一种相对位置编码方法,最初为语言模型设计。其核心思想是通过旋转矩阵对查询(Query)和键(Key)向量进行变换,使注意力分数仅依赖于相对位置差,而非绝对位置。这种编码方式在长序列建模中表现出色,因为它:
- 保持平移不变性:模型能更好地泛化到不同长度的序列
- 增强远程依赖捕获:减少传统正弦编码在长序列下的性能衰减
视频数据本质上是三维的:空间维度(高度 x x x、宽度 y y y) 和时间维度(帧序号 t t t)。直接应用原始RoPE(仅处理1D序列)无法区分空间和时序关系。因此,CogVideoX提出3D-RoPE。
核心方法: 将潜在序列位置映射为三维坐标(高度、宽度、时间),分别对三个维度应用一维RoPE,并拼接结果
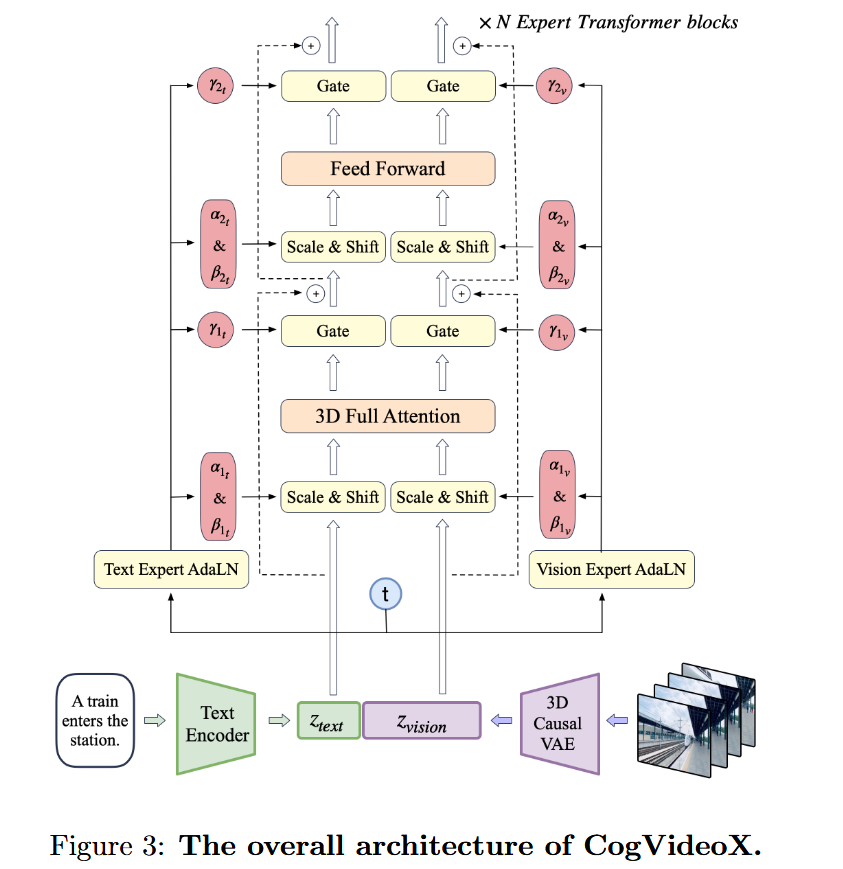
3. 专家自适应层归一化(Expert AdaLN)
- 动机:文本和视觉特征分布差异大,直接合并导致训练不稳定
- 机制:对文本和视觉模态分别应用独立的自适应层归一化,通过扩散时间步 t t t 调制特征尺度,促进模态对齐且不增加参数量。
4. 3D 全注意力机制
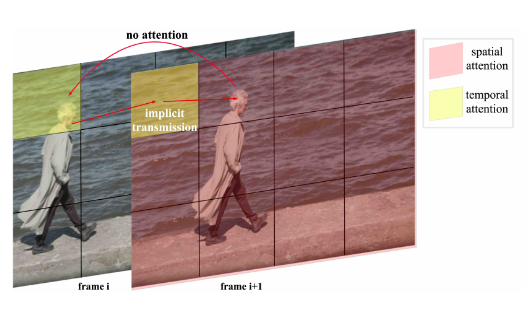
现有方案: 先前工作通常采用分离的时空注意力来生成视频。其中,空间注意力处理单帧内的视觉关系(类似图像生成),时间注意力处理帧与帧之间的时序关系。
缺陷:
- 隐式信息传递瓶颈:如下图所示,分离注意力要求视觉信息在空间和时间模块间进行大量隐式传输。例如,一个在帧间大幅运动的物体(如人物头部),其信息只能通过背景等间接路径传递,极易丢失或失真。
- 大运动一致性差:对于快速或大尺度运动,分离注意力难以维持物体 identity 和运动轨迹的连续性,导致视频闪烁或变形。
- 学习复杂度高:模型必须额外学习如何协调空间和时间两个独立模块,增加了训练难度。
基于大语言模型(LLMs)在长上下文训练中的成功和FlashAttention的高效性,CogVideoX提出了3D全注意力(3D Full Attention)机制,其核心思想是:
- 统一建模:将视频的空间维度(H, W) 和时间维度(T) 统一视为一个长的序列,直接应用全局注意力。
- 直接建模时空关系:每个 token(无论是哪个位置、哪一帧的)都可以直接关注到序列中任何其他位置的 token,彻底避免了隐式传递的需求。
(三)训练策略优化
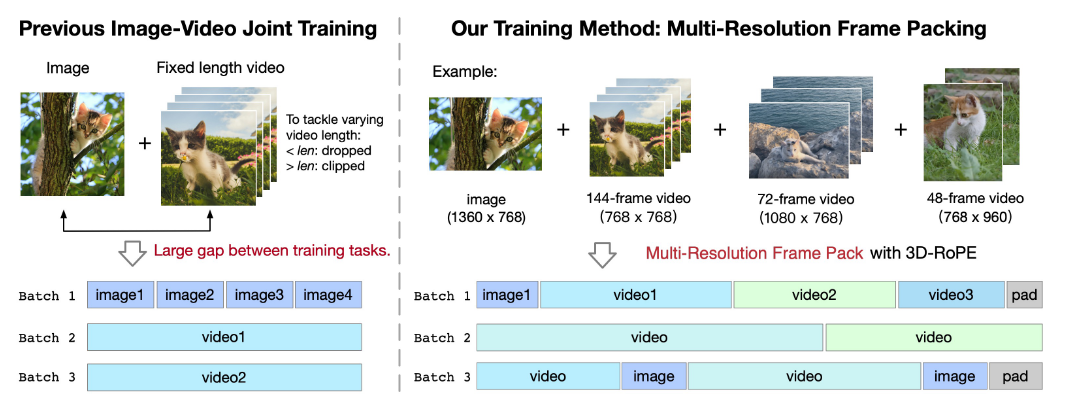
1. 多分辨率帧打包(Multi-Resolution Frame Pack)
问题: 固定帧数训练导致长视频截断、短视频丢弃,且图像(单帧)与视频(多帧)输入差异大。
解决方案: 将不同时长和分辨率的视频打包到同一批次(见上图),通过 3D-RoPE 自适应位置编码,提升数据利用率和泛化能力。
2. 渐进式训练(Progressive Training)
从低分辨率(256px)开始训练,逐步提升至512px、768px,学习高频细节
- 阶段1:256px 分辨率训练,学习语义和低频信息。
- 阶段2:逐步提升至 512px、768px,学习高频细节。
- 保持宽高比:仅调整短边,支持生成多种比例视频(如 768×1360)。
3. 显式均匀采样(Explicit Uniform Sampling)
CogVideoX采用的显式均匀采样(Explicit Uniform Sampling) 将区间划分并分配给不同计算节点,强制确保了每个训练步都能在全局上真正实现均匀采样。从而稳定不同扩散时间步的损失,避免因分辨率变化带来的训练波动。
(四)数据处理流程
问题:视频caption需要能够详细描述视频中的内容,之前开源的视频理解模型视频描述能力较差
数据来源:
- 视频数据:经过筛选后保留 约 3500 万 个单镜头视频片段; 平均时长 6 秒;
- 图像数据:引入来自 LAION-5B、COYO-700M 的 20 亿张高美学评分图像。
CogVideoX 提出密集视频字幕生成管线(Dense Video Caption Pipeline):
- Step 1 生成短标题:使用 Panda70M 模型为视频生成一个简短的初始描述;
- Step 2 提取帧并生成密集图像描述:从视频中抽帧(如每2秒一帧),使用 CogVLM(CogView3所用模型)为每一帧生成非常详细的结构化图像描述;
- Step 3 GPT-4 汇总:将所有帧的详细描述输入 GPT-4,让其总结生成一个最终的精炼、连贯、全面的视频文本描述;
- Step 4 模型蒸馏加速:为大规模处理数据,使用 GPT-4 生成的数据微调一个 LLaMA2 模型,替代 GPT-4 进行汇总,加速流程。
三、模型总体架构
CogVideoX 的整体架构核心包括:
- 3D Causal VAE:对视频进行压缩;
- Expert Transformer:实现文本与视觉模态的深度融合。
整体流程:
- 输入:视频和文本对;
- 视频经过 3D VAE 编码器 得到 latent 表示( z v i s i o n z_{vision} zvision),被 patchify 成一维序列;
- 文本通过 T5 编码器 得到嵌入向量( z t e x t z_{text} ztext);
- z v i s i o n z_{vision} zvision 与 z t e x t z_{text} ztext在序列维度上拼接;
- 拼接后的序列输入多层 Expert Transformer;
- 输出经过 unpatchify 和 3D VAE 解码器重建为视频。