🚀 欢迎来到「数据中心网络与异构计算」专栏!
在这个算力定义未来的时代,我们正见证一场从底层网络到计算架构的深刻变革。本专栏将带您穿越技术迷雾,从当前困境出发,历经三次关键技术跃迁,最终抵达「数据中心即计算机」的终极愿景。
目录
[一、硬件组件类:IB 网络的 "实体器官"](#一、硬件组件类:IB 网络的 “实体器官”)
[1.1 基本概念](#1.1 基本概念)
[1.2 HCA:服务器的 "智能 IB 网卡",不止于 "收发数据"](#1.2 HCA:服务器的 “智能 IB 网卡”,不止于 “收发数据”)
[1.3 TCA:存储设备的 "IB 接入网关"](#1.3 TCA:存储设备的 “IB 接入网关”)
[1.4 IB 交换机:"无阻塞" 的流量调度中枢](#1.4 IB 交换机:“无阻塞” 的流量调度中枢)
[1.5 IB 路由器:连接不同子网的 "桥梁"](#1.5 IB 路由器:连接不同子网的 “桥梁”)
[二、网络结构类:IB 网络的 "组织框架"](#二、网络结构类:IB 网络的 “组织框架”)
[2.1 子网(Subnet):IB 网络的 "基本管理单元"](#2.1 子网(Subnet):IB 网络的 “基本管理单元”)
[2.2 GUID:IB 设备的 "身份证"](#2.2 GUID:IB 设备的 “身份证”)
[2.3 GID:跨子网通信的 "全球地址"](#2.3 GID:跨子网通信的 “全球地址”)
[三、通信端点类:IB 数据传输的 "接口与通知机制"](#三、通信端点类:IB 数据传输的 “接口与通知机制”)
[3.1 QP:IB 通信的 "专属通道端点"](#3.1 QP:IB 通信的 “专属通道端点”)
[3.2 CQ:IB 通信的 "完成通知器"](#3.2 CQ:IB 通信的 “完成通知器”)
[3.3 SRQ:海量连接场景的 "资源优化器"](#3.3 SRQ:海量连接场景的 “资源优化器”)
[四、寻址与路由类:IB 数据的 "导航系统"](#四、寻址与路由类:IB 数据的 “导航系统”)
[4.1 LID:子网内的 "本地导航地址"](#4.1 LID:子网内的 “本地导航地址”)
[4.2 Service Level:流量的 "优先级通行证"](#4.2 Service Level:流量的 “优先级通行证”)
[五、操作类:IB 通信的 "基本指令集"](#五、操作类:IB 通信的 “基本指令集”)
[六、总结与预告:IB "语言体系" 的基石与下一步](#六、总结与预告:IB “语言体系” 的基石与下一步)
上一篇文章中,我们将 InfiniBand 比作高性能计算的 "超级血管"------ 它承载着 AI 训练集群中千卡 GPU 的参数同步、超算中心里数万节点的计算协同,是数据中心 "血液"(数据)高效流动的关键。但要真正理解这 "超级血管" 如何运作,仅知道它 "快" 是不够的:就像医生需要先认清动脉、静脉、毛细血管的结构与功能,才能解释血液循环原理,我们也需要先掌握 InfiniBand 的核心术语与基础架构,才能看懂它的通信逻辑。这篇文章,正是为你准备的 IB "词汇表" 与 "架构地图",帮你打通进入 IB 世界的第一道语言关卡。
一、硬件组件类:IB 网络的 "实体器官"
InfiniBand 网络的物理构成,由一套专用硬件组件组成。这些组件不是普通以太网设备的 "升级版",而是为 "低延迟、高可靠" 量身设计的 "专用器官",每一个都承担着独特的功能。
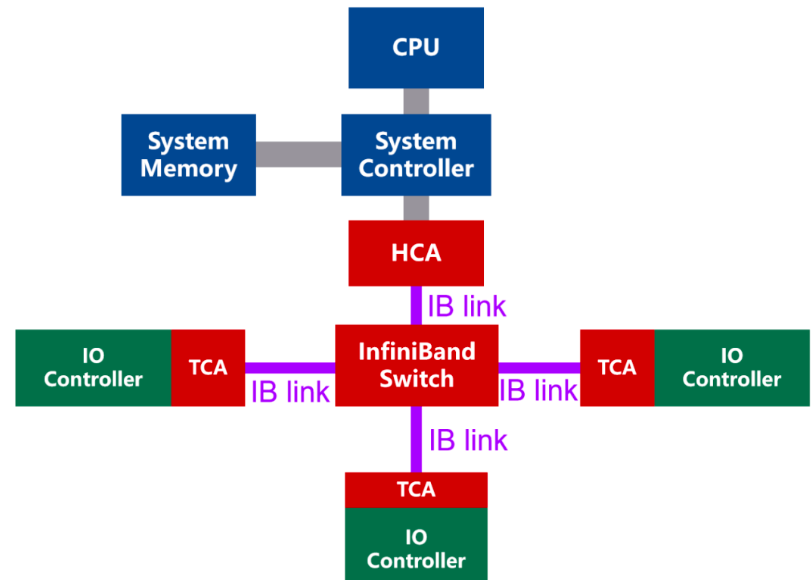
1.1 基本概念
- **IBA:**InfiniBand Architecture的缩写,它指的是 InfiniBand 技术从物理层到应用层的完整技术规范,本文中简单理解符合规范要求的设备即可。
- 处理器节点(processor Node):一组或多组处理器以及其内存,并通过主机通道适配器(HCA)与IBA光纤连接,每个HCA都有一个或多个端口;
- 端口(port):IBA设备与IBA链路连接的双向接口;
- 链路(link):用于两台IBA设备的两个端口间的双向高速连接。具体应用中以serdes实现,单条链路的传输速率可达2.5Gb/s,250MB/s的吞吐率(由于serdes中8b/10b的原因)。此外,还可以用4条或12条链路,达到1GB/s和3GB/s的吞吐率;
- 通道适配器Channel Adapter(CA):每个CA port在配置时就具有唯一地址,当一个CA必须发送信息或者读取信息时,首先需要发送一个请求报文,该报文带有destination port ID,通过交换机和路由器的帮助,CA最终抵达目标CA。
- IO单元与IO控制器(IOU and IOC):IOU的组成包括,连接到IBA的目标通道适配器;一个或多个IO控制器提供的IO接口,其实现形式会是一个大量的存储矩阵;
1.2 HCA:服务器的 "智能 IB 网卡",不止于 "收发数据"
HCA(Host Channel Adapter,主机通道适配器)是服务器接入 InfiniBand 网络的 "接口",看起来像一块网卡,但其功能远比普通以太网网卡复杂 ------ 它更像一台 "集成了协议处理能力的微型计算机",是 InfiniBand "CPU 卸载" 核心思想的载体。
普通以太网网卡仅负责 "数据包的物理层收发",TCP/IP 协议解析、数据拷贝等核心任务仍需 CPU 处理;而 HCA 内置了专用的协议处理引擎、内存控制器和队列管理单元,能独立完成 InfiniBand 协议栈的全流程处理:从链路层的帧封装、CRC 校验,到传输层的连接管理、流量控制,再到应用层的 RDMA 指令执行(如远程内存读写)。对服务器 CPU 而言,只需通过 "Verb API" 向 HCA 下发 "读取远程内存地址 X" 或 "写入数据到远程内存地址 Y" 的指令,后续所有通信流程都由 HCA 自主完成,CPU 无需再参与任何非计算任务。
此外,HCA 还支持 "多队列" 设计 ------ 一块 HCA 可同时创建数百个独立的通信队列(QP,后续会讲),分别对应不同的应用或任务,实现 "流量隔离",避免单一任务占用全部带宽。如今主流的 HCA(如 Mellanox ConnectX-7)已支持 400Gbps 单端口带宽,同时集成 TLS 加密、NVMe over Fabrics 卸载等功能,成为服务器连接 IB 网络的 "全能接口"。

1.3 TCA:存储设备的 "IB 接入网关"
TCA(Target Channel Adapter,目标通道适配器)是存储设备(如硬盘阵列、NVMe SSD)接入 InfiniBand 网络的专用组件,可理解为 "IB 存储网关" 或 "IB 硬盘阵列卡"。它的核心作用,是让存储设备能直接通过 IB 网络与服务器通信,无需经过传统的 SCSI 或 SAS 总线中转。
传统存储架构中,服务器要访问存储设备,需通过 "服务器→以太网交换机→存储控制器→SCSI 总线→硬盘" 的多段路径,每段路径都可能引入延迟;而配备 TCA 的存储设备,可直接通过 IB 网络与服务器的 HCA 建立连接,服务器通过 RDMA 指令直接读写存储设备的内存或磁盘 ------ 例如,服务器要读取某块 NVMe SSD 的数据,只需向 TCA 下发 "读取 SSD 某个扇区" 的 RDMA 指令,TCA 直接控制 SSD 读取数据并通过 IB 网络传输到服务器内存,全程无需存储控制器 CPU 参与,存储 IO 延迟从毫秒级降至微秒级。
TCA 的出现,是 "存算分离" 架构的关键支撑 ------ 它让存储设备摆脱了对特定服务器的依赖,成为 IB 网络中可被所有服务器共享的 "独立资源",为 InfiniBand 早期 "统一计算织物" 的构想提供了存储侧的支持。
1.4 IB 交换机:"无阻塞" 的流量调度中枢
InfiniBand 交换机是 IB 网络的 "流量调度中枢",其设计目标是 "让数据在网络中无延迟、无丢失地流动",核心特点是 "低延迟、无阻塞、支持子网管理",与传统以太网交换机有本质区别。

首先是 "无阻塞架构":IB 交换机的每个端口都具备 "线速转发" 能力,且内部交换矩阵的带宽是所有端口带宽之和的 2 倍以上 ------ 例如,一台 36 端口 400Gbps IB 交换机,内部交换矩阵带宽可达 28.8Tbps,确保多个端口同时满负载传输时,不会出现内部拥塞。而传统以太网交换机虽也标榜 "无阻塞",但在多端口同时传输时,仍可能因缓存不足或交换矩阵带宽不够导致丢包。
其次是 "内置子网管理功能":每台 IB 交换机都集成了 "子网管理器代理(Subnet Manager Proxy)",可配合主子网管理器(SM)完成网络拓扑发现、设备配置、路径计算等任务 ------ 例如,SM 通过交换机的代理功能,能自动识别接入的 HCA、TCA 设备,绘制完整的网络拓扑图,并为每个设备分配唯一的本地标识符(LID),这是传统以太网交换机不具备的能力。
最后是 "基于信用的流量控制":IB 交换机的每个端口都能实时向发送端反馈 "空闲缓存数量(信用 值)",当端口缓存即将满时,会主动降低信用值,让发送端减少数据发送,从源头避免丢包。这种 "端到端的无损控制",是 IB 网络实现微秒级延迟的关键保障。
1.5 IB 路由器:连接不同子网的 "桥梁"
IB 路由器的作用是 "连接多个 InfiniBand 子网",实现跨子网的通信。在大型 IB 网络中(如超算中心、跨区域 AI 集群),由于单子网的设备数量有限(通常不超过 4096 个),需将网络划分为多个子网,再通过 IB 路由器连接,形成 "大网络"。
与以太网路由器不同,IB 路由器不仅负责 "数据包转发",还需处理 "子网间的地址转换"------ 例如,子网 A 中的 HCA 要与子网 B 中的 TCA 通信,IB 路由器需将 HCA 的本地标识符(LID,子网内唯一)转换为全局标识符(GID,跨子网唯一),再转发到子网 B 的路由器,由对方转换为子网 B 内的 LID。同时,IB 路由器还支持 "服务级别(Service Level)" 的跨子网传递,确保不同优先级的流量在跨子网传输时,仍能保持原有的 QoS 保障。
IB 路由器的出现,让 InfiniBand 网络突破了单子网的规模限制,为构建跨区域、超大规模的 IB 网络(如覆盖多个数据中心的 AI 训练集群)提供了可能。

二、网络结构类:IB 网络的 "组织框架"
如果说硬件组件是 IB 网络的 "实体器官",那么网络结构类术语就是这些器官的 "组织方式"------ 它们定义了 IB 网络的边界、设备身份和寻址规则,是网络有序运行的基础。
2.1 子网(Subnet):IB 网络的 "基本管理单元"
子网是 InfiniBand 网络中 "最小的独立管理单元",由一组 HCA、TCA、IB 交换机和 IB 路由器(子网间连接用)组成,受一个 "子网管理器(SM)" 统一管理。简单来说,一个子网就是 IB 网络中的 "一个局域网段",但比以太网的网段具备更强的管理属性。
单个子网的设备数量有明确限制:由于本地标识符(LID)是 16 位或 32 位(根据 IB 规范版本),16 位 LID 最多支持 4096 个设备(去掉预留的 LID 后实际支持 4094 个),32 位 LID 最多支持 1600 万个设备。在实际部署中,为了简化管理和减少广播风暴,通常会将大型 IB 网络划分为多个子网,每个子网包含数百至数千个设备,再通过 IB 路由器连接。
子网的核心价值是 "管理隔离":不同子网的设备配置、路径计算、故障处理可独立进行,某个子网出现故障(如交换机宕机)不会影响其他子网的运行。例如,某超算中心将 IB 网络划分为 "计算子网"(连接计算节点 HCA)和 "存储子网"(连接存储设备 TCA),两个子网通过 IB 路由器通信,当存储子网的交换机故障时,计算子网仍能正常进行内部协同计算。
2.2 GUID:IB 设备的 "身份证"
GUID(Global Unique Identifier,全局唯一标识符)是每个 InfiniBand 设备(HCA、TCA、交换机、路由器)的 "全球唯一身份证",由 64 位二进制数组成,通常以 "XX:XX:XX:XX:XX:XX:XX:XX" 的十六进制格式表示(如 "00:02:c9:03:00:4a:7d:8b")。
GUID 由设备厂商在生产时烧录到硬件中,全球唯一,不会重复 ------ 这就像每个网络设备都有一个 "全球唯一的序列号",用于在整个 IB 网络中标识设备身份。在子网管理中,子网管理器(SM)首先通过 GUID 识别接入的设备类型(是 HCA 还是交换机),再为其分配本地标识符(LID);在跨子网通信中,GUID 也是生成全局标识符(GID)的基础。
与以太网的 MAC 地址相比,GUID 的长度更长(64 位 vs 48 位),可支持更多设备,且具备更强的唯一性(MAC 地址存在厂商重复分配的可能,而 GUID 由专门机构分配,确保全球唯一),是 IB 网络设备身份识别的核心依据。
2.3 GID:跨子网通信的 "全球地址"
GID(Global Identifier,全局标识符)是 InfiniBand 设备用于 "跨子网通信" 的全局地址,由 128 位二进制数组成,格式上分为 "子网前缀(64 位)" 和 "接口 ID(64 位)" 两部分 ------ 其中 "接口 ID" 通常由设备的 GUID 转换而来,"子网前缀" 则是每个子网的全局唯一标识(由管理员分配)。
简单来说,GID 就像 IB 设备的 "IP 地址",用于在跨子网的大网络中定位设备;而之前提到的 LID(本地标识符)则像 "局域网内的 IP 地址",仅在子网内有效。当子网 A 的 HCA 要与子网 B 的 TCA 通信时,发送端 HCA 会使用 TCA 的 GID 作为目标地址,IB 路由器根据 GID 中的 "子网前缀" 将数据包转发到子网 B,再由子网 B 的 SM 将 GID 转换为 TCA 的 LID,完成最终通信。
GID 的另一个重要作用,是支撑 RoCEv2 协议 ------RoCEv2 将 IB 的 RDMA 功能封装在 UDP/IP 数据包中,其中 UDP 的目标地址就是由 GID 转换而来的 IPv6 地址(128 位 GID 可直接映射为 128 位 IPv6 地址)。可以说,GID 是 InfiniBand 从 "封闭子网" 走向 "与 IP 网络融合" 的关键技术纽带。
三、通信端点类:IB 数据传输的 "接口与通知机制"
如果把 IB 网络的硬件和结构看作 "公路系统",那么通信端点类术语就是 "车辆的出发地、目的地和到达通知系统"------ 它们定义了数据从哪里发、到哪里收,以及如何告知 "数据已送达",是 IB 通信的核心交互单元。
3.1 QP:IB 通信的 "专属通道端点"
QP(Queue Pair,队列对)是 InfiniBand 通信的 "基本端点",由 "发送队列(Send Queue,SQ)" 和 "接收队列(Receive Queue,RQ)" 组成,每个 QP 对应一个 "专属的通信通道"。简单来说,要在两台 IB 设备(如服务器 HCA 和存储 TCA)之间传输数据,必须先在双方设备上创建一对匹配的 QP,数据从发送端的 SQ 发出,到接收端的 RQ 接收,全程通过这个专属通道传输。
QP 的核心特点是 "资源隔离":每个 QP 有独立的缓存、队列深度和优先级,不同 QP 的数据传输互不干扰。例如,一台服务器的 HCA 可同时创建 100 个 QP,分别对应 100 个不同的应用 ------ 应用 A 的数据库查询数据通过 QP1 传输,应用 B 的 AI 训练参数通过 QP2 传输,即使 QP1 满负载,也不会影响 QP2 的带宽和延迟。
QP 的工作流程可简单概括为:发送端应用将 "数据地址、目标 QP 编号、操作类型(如 RDMA Write)" 等信息放入 SQ;HCA 读取 SQ 中的指令,生成 IB 数据包并发送到网络;接收端 HCA 收到数据包后,根据目标 QP 编号找到对应的 RQ,将数据写入 RQ 关联的内存地址;最后,接收端 HCA 通过 "完成队列(CQ)" 通知应用 "数据已接收"。关于 QP 的详细工作机制,我们会在后续文章中专门讲解,这里只需记住:没有 QP,IB 设备就无法进行数据传输。
3.2 CQ:IB 通信的 "完成通知器"
CQ(Completion Queue,完成队列)是 InfiniBand 用于 "告知应用程序通信操作结果" 的组件 ------ 无论是发送端的 "数据已发出",还是接收端的 "数据已收到",抑或是通信过程中出现的 "错误(如数据包丢失)",都会通过 CQ 以 "完成事件(Completion Event)" 的形式通知应用。
CQ 的工作逻辑类似于 "邮件信箱":应用程序在创建 QP 时,会将 QP 与某个 CQ 绑定(一个 CQ 可绑定多个 QP);当 QP 的通信操作完成(或出错)时,HCA 会自动在对应的 CQ 中添加一个 "完成事件",事件中包含 "操作类型、QP 编号、结果(成功 / 失败)、数据长度" 等信息;应用程序通过 "轮询(Poll)" 或 "中断(Interrupt)" 的方式读取 CQ 中的事件,即可知道通信操作的状态,进而决定下一步动作(如继续发送数据、重传错误数据)。
与传统网络的 "回调函数" 相比,CQ 的优势是 "低开销":完成事件的生成和读取都在用户态完成,无需经过内核态上下文切换,通知延迟可低至数百纳秒。同时,一个 CQ 绑定多个 QP 的设计,也减少了应用程序管理的组件数量,降低了开发复杂度。
3.3 SRQ:海量连接场景的 "资源优化器"
SRQ(Shared Receive Queue,共享接收队列)是一种特殊的接收队列,可被多个 QP 共享 ------ 传统的 RQ 是 "一对一" 绑定 QP,每个 QP 需要独立的 RQ 缓存;而 SRQ 是 "一对多" 共享,多个 QP 可共用同一个 SRQ 的缓存和队列资源,主要用于 "海量连接场景"(如服务器同时与数千个客户端通信)。
在海量连接场景中,若使用传统 RQ,服务器的 HCA 需为每个客户端的 QP 创建独立的 RQ,数千个 QP 就需要数千个 RQ,会占用大量内存和队列资源;而使用 SRQ 时,所有客户端的 QP 可共享一个或几个 SRQ,HCA 只需维护少量 SRQ 即可,内存占用可降低 80% 以上,同时减少队列管理的开销。
例如,某云服务商的 IB 存储服务器,需要同时为 1000 个客户端提供 NVMe over Fabrics 服务 ------ 若用传统 RQ,需创建 1000 个 RQ,占用 2GB 内存;而用 SRQ,只需创建 10 个 SRQ,内存占用降至 200MB,同时通信延迟和 CPU 占用率也显著降低。SRQ 的出现,让 IB 设备能更高效地应对海量连接场景,拓展了 IB 网络的应用范围。
四、寻址与路由类:IB 数据的 "导航系统"
有了 "器官""框架" 和 "端点",还需要一套 "导航系统" 来指引数据找到正确的目的地 ------ 寻址与路由类术语就是 IB 网络的 "导航规则",定义了数据如何在子网内、子网间找到目标设备。
4.1 LID:子网内的 "本地导航地址"
LID(Local Identifier,本地标识符)是 IB 设备在 "子网内" 的 "本地地址",由 16 位或 32 位二进制数组成(通常用十六进制表示,如 "0x0001""0x0002"),在子网内唯一。LID 由子网管理器(SM)在设备接入网络时自动分配,类似于以太网中的 "私有 IP 地址",仅在子网内有效,跨子网通信时需转换为 GID。
LID 的核心作用是 "子网内路由":当数据在子网内传输时,IB 交换机通过数据包中的 "目标 LID" 确定转发路径。例如,子网内的 HCA(LID=0x0001)要向 TCA(LID=0x0005)发送数据,HCA 在数据包中填入目标 LID=0x0005,IB 交换机收到数据包后,查询本地的 "LID 路由表"(由 SM 生成),发现 LID=0x0005 对应的端口是 "端口 10",便将数据包转发到端口 10,最终送达 TCA。
与以太网的 IP 地址相比,LID 的长度更短(16 位 vs 32 位),交换机查询路由表的速度更快(可在硬件中实现纳秒级查找),这也是 IB 网络能实现低延迟转发的原因之一。同时,LID 的分配和管理由 SM 自动完成,无需人工配置,减少了运维复杂度。
4.2 Service Level:流量的 "优先级通行证"
Service Level(SL,服务级别)是 InfiniBand 用于 "区分流量优先级" 的机制,通过 3 位二进制数定义 8 个优先级级别(0-7),优先级 7 最高,0 最低。SL 的核心作用是 "为不同类型的流量提供差异化的 QoS 保障",确保关键业务(如 AI 训练参数同步)的流量不会被普通业务(如日志传输)挤占带宽。
SL 的工作机制贯穿整个 IB 网络:发送端应用在创建 QP 时,会为 QP 指定一个 SL 级别(如 AI 训练的 QP 用 SL=7,日志传输的 QP 用 SL=1);HCA 在发送数据包时,会将 SL 级别写入数据包头部;IB 交换机收到数据包后,根据 SL 级别将数据包放入对应的 "优先级队列",高 SL 级别的队列优先转发;接收端 HCA 也会根据 SL 级别,优先处理高优先级的数据包。
例如,在 AI 训练集群中,GPU 之间的参数同步流量(SL=7)和集群监控的日志流量(SL=1)同时传输时,IB 交换机会优先转发参数同步数据包,确保训练过程不被延迟;即使日志流量满负载,也不会影响参数同步的带宽和延迟。这种 "端到端的优先级保障",是 IB 网络能支撑多业务混合部署的关键。
五、操作类:IB 通信的 "基本指令集"
Verb(动词)是 InfiniBand 通信的 "基本操作指令",定义了应用程序通过 HCA 与远程设备交互的方式,类似于编程中的 "函数"。每个 Verb 对应一种特定的通信操作,应用程序通过调用 Verb API,触发 HCA 执行对应的硬件动作,完成数据传输或状态查询。
InfiniBand 的核心 Verb 包括以下几类:
数据传输类 Verb:如
ibv_post_send(发送数据)、ibv_post_recv(接收数据)、ibv_post_rdma_write(RDMA 写操作)、ibv_post_rdma_read(RDMA 读操作)------ 这些 Verb 是 IB 通信的核心,应用程序通过它们实现 "发送消息" 或 "远程内存访问"。例如,调用ibv_post_rdma_write时,应用程序需传入 "本地数据地址、远程内存地址、数据长度、目标 QP 编号" 等参数,HCA 会根据这些参数生成 RDMA 写请求,直接将本地数据写入远程内存。资源管理类 Verb:如
ibv_create_qp(创建 QP)、ibv_create_cq(创建 CQ)、ibv_reg_mr(注册内存区域 MR)------ 这些 Verb 用于创建和管理 IB 通信所需的资源,是数据传输类 Verb 的基础。例如,调用ibv_reg_mr可将应用程序的用户态内存注册为 "可被远程访问的内存区域",HCA 会为该内存区域分配 L_Key(本地密钥)和 R_Key(远程密钥),确保内存访问的安全性。状态查询类 Verb:如
ibv_poll_cq(查询 CQ 完成事件)、ibv_query_qp(查询 QP 状态)------ 这些 Verb 用于获取 IB 通信的状态信息,帮助应用程序判断操作是否完成或是否出现错误。例如,调用ibv_poll_cq可读取 CQ 中的完成事件,知道之前发送的 RDMA 写操作是否成功。
Verb 的本质是 "将硬件操作抽象为软件接口"------ 它屏蔽了 HCA 硬件的复杂细节,让应用程序无需了解 IB 协议栈的底层逻辑,只需调用简单的 API 就能实现高性能通信。同时,Verb API 是跨平台、跨厂商的(由 IBTA 协会制定标准),确保不同厂商的 HCA 都能兼容相同的应用程序,为 IB 生态的统一奠定了基础。
六、总结与预告:IB "语言体系" 的基石与下一步
通过本文的讲解,我们已经掌握了 InfiniBand 的核心术语体系:从硬件组件(HCA、TCA、交换机)到网络结构(子网、GUID、GID),从通信端点(QP、CQ、SRQ)到寻址路由(LID、SL),再到操作指令(Verb),这些术语共同构成了理解 IB 网络的 "语言基础"------ 就像学习英语需要先掌握 26 个字母和基础词汇,理解 IB 也需要先吃透这些 "黑话",才能看懂后续更复杂的通信机制和架构设计。
这些术语并非孤立存在:HCA 和 TCA 通过 QP 建立通信,数据根据 LID 在子网内路由,通过 SL 保障优先级,通信结果通过 CQ 通知应用,而这一切都依赖 Verb API 实现软件控制 ------ 它们相互关联、相互支撑,共同构成了 InfiniBand 网络的运行逻辑。
下一篇文章,我们将基于这些术语,深入探讨 IB 网络的 "组织与管理核心"------ 子网管理器(SM)。有了硬件组件和通信端点,IB 网络是如何被 SM 自动发现、配置和维护的?SM 如何为设备分配 LID、计算最优路由?当网络出现故障时,SM 又如何实现自愈?这些问题,将是我们下一篇文章的核心内容。让我们带着今天掌握的 "词汇表",继续深入 IB 世界的核心机制。