本文介绍了 8 种常见的 UUID 替代方案,以及若干种不太常见的方案,介绍了这些方案的优缺点和使用场景,开发人员可以根据业务需求选择合适的方案。原文:UUID Alternatives for Cloud Apps

当 UUID 不是最佳解决方案时......
长期以来,UUID 一直是许多云和大数据应用首选的 ID 格式,被广泛应用于需要对数据记录、资源和实体进行唯一标识的众多应用中:数据库、资源标识符、会话和事务标识符、对象存储等。
对于非开发人员而言 :UUID 是由大量数字和字母组成、带有破折号的长字符串(格式:8-4-4-4-12),看上去就和一堆乱码一样,比如 1e7cacb7-af9f-4f07--88fd-45370c25ab62。
现在,开发人员 🛠️ 🚀 正尝试采用其他可能更符合需求的 ID 生成方案。
虽然 UUID(通用唯一识别码)曾经并且现在仍被广泛采用 (仍是使用最广泛的 ID 类型),但其庞大的尺寸 以及缺乏自然排序特性 ,可能会在大规模应用中导致性能、存储和索引方面的效率低下问题。
此外,那些依赖时间戳 或按字典顺序排序的 ID(如 KSUID 或 ULID)的系统日益受到欢迎,使得这些选项更具吸引力。
我们将探讨可能的替代方案 、它们的使用方法 以及优缺点。使用哪种方案取决于具体场景,即使对于简单的内部演示测试(POC),连续 ID 可能也就足够了(不过通常不建议这样做)。
作为参考,我们先从 UUIDv4 开始讲起 ,这是 UUID 标准的较新版本,是一个 128 位的值(16 个字节),其中 122 位随机生成,其余位则包含版本 和变体信息。
例:1e7cacb7-af9f-4f07--88fd-45370c25ab62
参考代码:www.npmjs.com/package/uui... (也可以用 node.js 的 crypto 模块)
Wikipedia:Universally unique identifier
UUIDv4 的优点:
- 由于其拥有 122 位的大型随机空间,因此具有极高的唯一性,发生冲突的可能性极小。
- 标准被广泛认可,使其在众多平台、数据库和编程语言中得到广泛支持。
- 无需系统之间的协调,这意味着 UUIDv4 可以在分布式系统中独立生成,而不会出现冲突风险。
- 非常适合在许多不同的机器或服务中独立生成 ID 的环境中使用。
- UUID 在 URL 或文件中非常容易传递,且不会出现编码问题。
- Python 的标准库或 node.js 的 crypto 库中也有它们的身影。
UUIDv4 的缺点:
- 其大小远超某些应用场景所需,从而导致存储和带宽使用量增加。
- UUIDv4 完全随机,且不具备任何内在的排序特性(如时间戳或序列号)。这对需要对记录进行索引的数据库来说可能效率低下,因为 UUIDv4 不支持自然排序。
- UUID 是很长且看起来随机的字符串,对于人类来说不易阅读或记忆。
- 尽管 UUIDv4 非常随机,但如果随机数生成器薄弱或可预测,其唯一性可能会受到威胁,从而可能导致冲突。
- 在更容易保证唯一性的系统中(例如单个数据库内),UUIDv4 可能过于复杂且效率低下,相比诸如自增整数之类更简单的 ID 而言不太合适。
以下将介绍 8 种 UUID 的替代方案以及它们的优缺点:
- 自增 ID(连续 ID)
- Snowflake ID(Twitter Snowflake)
- KSUID(K排序唯一标识符,K-Sortable Unique Identifier)
- ULID(通用唯一字典排序标识符,Universally Unique Lexicographically Sortable Identifier)
- NanoID
- 随机哈希 ID(SHA-256 或 MD5 哈希)
- ObjectID(MongoDB ObjectID)
- CUID(抗冲突唯一标识符,Collision-Resistant Unique Identifier)
- 其他(不太常见的)
1. 自增 ID(连续 ID)
自增 ID 是数值类型,每次添加新记录时都会加 1,这种类型通常用于关系型数据库中。
这种替代方案仅作为供许多人学习简单实现的参考存在......很可能并不能达到期望结果,通常而言,除非有特定使用场景,否则不要用这种方案。
下面的例子清楚说明了为什么重要的生产系统不会使用连续 ID。
示例:56482
优点:
- 易于实现且易于理解。
- 存储效率高(使用较小的数据类型)。
- 能够轻松进行索引,从而在数据库中实现更好的性能。
- 适用于小型系统或数据库,这些系统或数据库中顺序很重要且无需全局唯一标识符,例如关系型数据库中的主键。
缺点:
- 不适合用于分布式系统,因为可能会发生冲突。
- 具有可预测性,可能会带来安全风险(因为 ID 可预测)。
- 在分片系统中需要数据库协调以避免重复。
对于此类方法中的一些问题,请参阅以下文章链接:
2. Snowflake ID (Twitter Snowflake)
一种分布式 ID 生成算法,通过结合时间戳、机器 ID 和序列号生成 64 位唯一 ID。
示例:5643574219214851220
优点:
- 分布式且可扩展,适用于分布式系统。
- 时间戳 组件提供近似排序。
- 生成的 ID 在各系统间可保证唯一性。
- 可用于需要可扩展、按时间排序的唯一 ID 的系统,例如社交媒体或消息应用。
缺点:
- 实现起来比简单 ID 稍微复杂一些。
- 基于时间戳的 ID 可能会泄露时间信息。
- 需要仔细配置机器标识符以避免冲突。

Wikipedia: en.wikipedia.org/wiki/Snowfl...
NPM: www.npmjs.com/package/sno...
PyPI: pypi.org/project/sno...
3. KSUID(K 排序唯一标识符)
KSUID 是 UUID 的一种变体,包含时间戳,因此可以根据创建时间进行排序。
一个由时间戳和随机生成的位组成的 27 字符的字符串,确保 k 排序性。
NPM:www.npmjs.com/package/ksu...
PyPI:pypi.org/project/svi... 或 pypi.org/project/ksu...
示例:1avvTqCSFGnD5LDc4hN6GFFCAXD
优点:
- K 排序(可按时间排序)且全局唯一**。
- 紧凑高效的表示形式。
- 可用于需要更好的时间排序性的唯一标识符以及唯一用户生成的内容标识符。
缺点:
- 比基础数字 ID 大。
- 比连续 ID 更难处理。
- 如果隐私是关注点,可能会暴露时间戳信息。
4. ULID(通用唯一字典序可排序标识符)
与 KSUID 类似,ULID 是一种结合了时间戳和随机数据以确保唯一性的字典序可排序 ID 格式。
基于时间戳和随机性的 26 位字母数字字符串,确保按字典顺序排列。
NPM:www.npmjs.com/package/uli...
示例:22H1UECHZX3FGGSZ7A9Y9BVC1
优点:
- 可按创建时间进行排序。
- 比 UUID 更易于理解。
- 适用于大规模分布式系统。
- 适用于需要进行字典排序且同时需要全局唯一标识符的情况,例如电子商务或文档管理系统。
缺点:
- 与 KSUID 类似,其时间戳也会被公开,可能不利于保护隐私。
- 生成方式比 UUID 更为复杂。
5. NanoID
NanoID 是一种小巧、快速且安全的 UUID 替代品,设计为便于在 URL 中使用,并且在大小方面具有可定制性。
简短、随机且便于记忆的网址字符串,其长度和字母表均可自定义设置。
NPM:www.npmjs.com/package/nan...
示例:E9SxJKL8_K5emHi2B-noZ
优点:
- 小巧的尺寸、可定制的长度。
- URL 安全且非顺序排列,提高了安全性。
- 生成速度快,比 UUID 所需存储空间更少。
- 非常适合前端,或者那些需要更短、便于在 URL 中使用且具有唯一性的标识符的情况,例如面向公众的 URL 或会话标识符。
缺点:
- 可自定义的大小可能会导致命名空间变小以及可能出现冲突。
- 与 UUID 相比,在企业系统中并未得到广泛采用。
6. 基于随机哈希的标识符(SHA-256 或 MD5 哈希)
基于诸如 SHA-256 或 MD5 这样的哈希函数生成随机字符串,以创建唯一的标识符。
通过对数据进行哈希处理而生成固定长度的 32 位或 64 位字符串(类似于时间戳与用户数据的组合)。
示例:
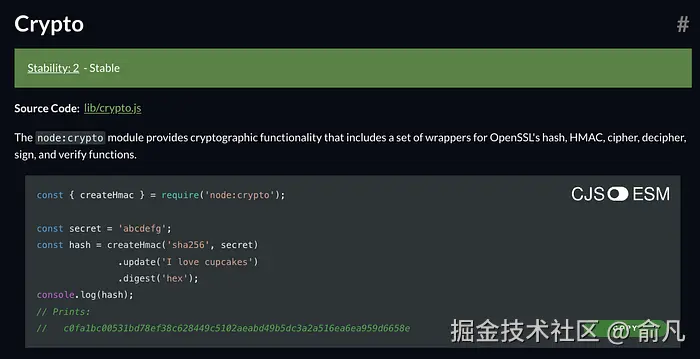
Node.js 内置:nodejs.org/api/crypto....
Python 内置的 hashlib 库
示例(SHA-256):1d214892da28032151d0e36c2dc6291673603d1d61ab3dd32a11e2321d1542f2
优点:
- 能够生成非常庞大且独一无二的空间,几乎不存在冲突情况。
- 能够利用诸如用户详细信息之类的输入数据来确定性的生成独一无二的标识符。
- 使用加密哈希函数(SHA-256)时具有安全性。
- 适用于需要具有加密特性的唯一性,例如用于重复检测的文件哈希值,或者当标识符必须在不同系统中保持不变的情况时。
缺点:
- 与数字标识相比,存储空间占用较大。
- 由于计算复杂性,生成和验证速度较慢。
- 取决于哈希函数的不同,可能并非完全防冲突。
7. ObjectID(MongoDB ObjectID)
MongoDB 的 ObjectID(BSON 二进制 JSON 格式)是 12 个字节组成的唯一标识符,包括时间戳、机器标识符、进程标识符以及计数器。
NPM:www.npmjs.com/package/bso...
示例:102e1b71bcd16cd721434331
由 24 个字符组成的十六进制字符串,包含时间戳、机器标识符和进程标识符。
优点:
- 提供独特的分布式标识符,且无需大量协调。
- 包含时间戳,可用于按创建时间进行排序。
- 存储效率高(仅需 12 字节,小于 UUID)。
- 特别适用于像 MongoDB 这样的 NoSQL 数据库,尤其适用于需要带有时间戳的唯一标识符的文档存储系统。
缺点:
- 暴露了创建时间,可能不太适合保护隐私。
- 与 MongoDB 耦合;可能需要进行一些调整才能在其他系统中使用。
- 比基本数字 ID 稍微复杂一些。
8. CUID(抗碰撞唯一标识符)
CUID 的设计旨在降低分布式系统中出现冲突的可能性,提供了符合 URL 标准、易于人类理解且抗冲突的标识符。
NPM:www.npmjs.com/package/@pa...
示例:skbcvmzbk02217a1ad0m5qhc2
基于 36 进制编码的时间戳和随机数,确保了较低的冲突概率。
优点:
- 极高的抗冲突能力,即使在分布式系统中也是如此。
- 易于人类阅读且便于通过 URL 访问。
- 包含时间戳和随机数以确保唯一性。
- 可水平扩展:在多台机器上生成 ID 而无需协调。
- 兼容离线:无需网络连接即可生成标识符。
- 具有较低冲突风险的可靠唯一标识符,适用于分布式数据库或微服务。
缺点:
- 比诸如 NanoID 或 Snowflake 这类更简单 ID 格式要复杂。
- 会透露某些细节(例如时间戳和机器信息)。
- 与连续编号或数字标识相比,生成方式更为复杂。
9. 其他(较为少见)
我在研究中还发现了其他一些选项,但这些方案较为少见。如果你还没找到最适合使用场景的标识符,或许可以考虑一下:
Flake ID :包含时间戳、机器标识符和序列号。如果需要具有唯一性且按时间顺序排列的标识符,以便于排序和调试,可以试试。示例:304857642123456
基于时间的标识符 :通常由 Unix 时间戳与随机位或其他独特数据组合而成。适用于需要按时间顺序排列的情况下,例如日志记录或事件跟踪。示例:16972283871234567890(将时间戳 1697228387 与一个随机数后缀组合而成)
有序 GUID(SQL Server) :一种针对索引优化的 GUID,通常以时间排序段开头。在需要使用 GUID,同时又需要进行有序索引以提高数据库性能的情况下适用。示例:6E4F6A80-4F64-11EE-B4FA-0242AC120002
ShortID :简洁且独特的字母数字组合字符串,常用于网址中。用于短网址或在公开网址中提供用户友好的标识符。示例:2K5czP8
ZUID(零宽度唯一标识符) :包含零宽度字符(例如零宽度空格),这些字符不可见但可用于解析以确保唯一性。适用于需要跟踪或元数据的不可见标识符,且不干扰视觉布局的场景。示例:内部可能看起来像 \u200B\u200C\u200D。
到此结束!我们详细探讨了 UUID 的多种替代方案,希望这能让你对这个话题有更多了解,并能帮助你开发出更出色的应用。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!