引言:当AI基础设施撞上"范式之墙"
2024年Stack Overflow开发者调查揭示了一个令人深思的现象:72%的高级C++工程师在构建高性能中间件时,正经历"范式选择困难症"------他们不断在面向对象(OOP)、泛型编程(GP)与函数式编程(FP)之间摇摆,结果往往是架构复杂度飙升、性能折损、维护成本剧增。
这种困境并非抽象的理论问题。一位来自Meta的资深C++架构师曾向我详细描述他在重构PyTorch C++扩展模块时遭遇的"范式冲突":为支持Llama系列模型的动态批处理推理,他试图改造原有的同步I/O通信层。然而,当他引入异步事件驱动模型时,团队对回调地狱的可维护性产生质疑;当他尝试用模板元编程优化编译期计算时,CI/CD流水线中的编译时间从8分钟暴涨至32分钟,严重拖慢迭代速度。项目最终陷入"性能不稳定、迭代慢、难维护"的恶性循环。
这并非孤例。在NVIDIA、Google、Amazon等公司的AI基础设施团队中,类似的"范式之墙"已成为制约系统演进的关键瓶颈。开发者们发现,传统的"单一范式纯洁性"思维,在面对AI工作负载的高并发、低延迟、硬件异构等复杂需求时,已显得力不从心。
本文的核心观点是:
- Boost的成功并非源于特定的语法技巧,而在于其"多范式融合"的顶层设计哲学------它将不同的编程范式视为可组合的工具箱,而非互斥的宗教信仰。
- 现代AI中间件的核心竞争力,在于架构的"弹性"而非"纯粹"------能够根据任务(如模型加载、推理调度、通信传输)的实时需求,无感地切换或融合最合适的底层范式。
- 从Boost库到C++20/23/26标准的演进轨迹,描绘了一条清晰的架构思维升级路径------理解这条路径,能让开发者从"标准库使用者"进化为"语言设施设计者",从而主导而非跟随技术演进。
第一部分:理论框架------解码Boost的多范式DNA
1.1 多范式融合:复杂系统的必然选择
要理解Boost的设计哲学,我们必须回到编程范式的本源。面向对象编程先驱Alan Kay提出的"概念-工具-范式"分层模型为我们提供了绝佳的分析框架:
- 概念(Concepts):编程语言提供的基础构件,如变量、函数、类型、内存等。
- 范式(Paradigms):组织这些概念的高层模式,如OOP强调封装与继承,GP强调算法与数据结构的分离,FP强调无副作用与组合。
- 工具(Tools):解决特定工程问题的"概念组合",这才是软件工程的终极目标。
Boost库正是这一思想的工程化典范。它从不为了"展示OOP之美"或"炫耀模板元编程之强"而设计,而是始终围绕具体问题来组合最有效的范式。
以Boost.Asio为例,它需要解决的是"跨平台、高性能、可组合的异步I/O"问题。为此,它:
- 使用OOP 封装
io_context、socket等状态机,提供清晰的对象生命周期管理; - 采用函数式风格(通过函数对象或C++11后的lambda)处理事件回调,实现关注点分离;
- 利用泛型编程(模板)实现跨平台抽象,使得同一套API能在Windows IOCP、Linux epoll、BSD kqueue上高效运行。
它不追求"纯OOP"或"纯FP",而是以问题为中心,灵活组合范式。这种思想与早期Java生态中"一切皆对象"的教条形成鲜明对比。
下表系统对比了单一范式与多范式融合架构的关键差异:
|------------|--------------------|-----------------------------------------------|
| 维度 | 单一范式架构 (如纯OOP) | 多范式融合架构 (如Boost风格) |
| 设计出发点 | 维护范式的一致性、纯洁性 | 解决特定问题的最优路径 |
| 扩展性 | 沿继承/接口树扩展,可能僵化 | 通过组合不同范式模块扩展,更灵活 |
| 性能优化粒度 | 受范式约束大(如虚函数开销) | 可在热点路径下沉到更低抽象层 |
| 典型代表 | 早期Java标准库 | Boost.Asio , Boost.Spirit , Eigen |
| 适合场景 | 业务逻辑稳定、模型统一 | AI中间件(高并发I/O、动态计算图、多硬件后端) |
1.2 C++设计思想的演进:从分离到融合
C++的多范式融合并非一蹴而就,而是一条跨越四十年的清晰演化路径:
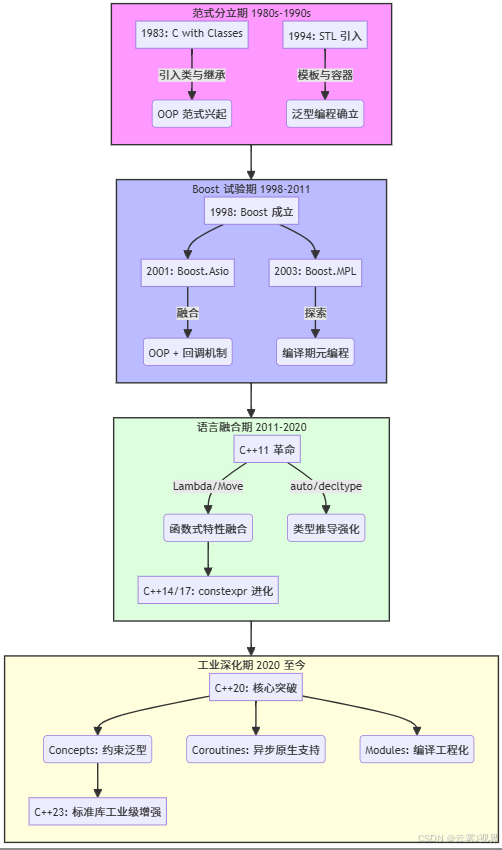
这一路径揭示了一个关键事实:语言特性是滞后于工程实践的。Boost作为"先驱者",在标准采纳前就验证了多范式融合的可行性与价值。
1.3 Boost是C++标准的"可执行预言"
根据社会学家Everett Rogers的"创新扩散理论 ",任何新技术/思想被主流采纳都需要经历先驱者(Innovators)、早期采用者(Early Adopters)等阶段。Boost库正是C++新特性的"先驱者"和"试验田"。
让我们看几个关键映射:
1. Boost.Asio → C++23 Executors
Boost.Asio通过io_context、strand、post等原语,成功抽象了异步操作的调度策略。这种"执行策略与业务逻辑分离"的思想,直接启发了C++标准委员会的Executors提案(P0443),旨在提供一套统一、可组合的异步执行框架。
架构启示 :在AI中间件中,我们同样需要隔离"计算逻辑"与"执行策略"。例如,一个张量运算既可以同步在CPU上执行,也可以异步提交到GPU流,甚至卸载到NPU。借鉴Asio思想,我们可以设计一个统一的
execution_context,让算子开发者无需关心底层硬件细节。
NVIDIA在其开源项目TensorRT-LLM 中就采用了类似设计。其Executor类封装了CUDA流、事件等细节,上层推理逻辑只需调用enqueue,实现了CPU/GPU任务的无缝调度。
2. Boost.MPL → C++20 Concepts + consteval
Boost.MPL(Meta Programming Library)在编译期进行复杂的类型运算,但其语法晦涩难懂,被称为"C++模板的黑暗艺术"。C++20的Concepts 提供了清晰、可读的接口约束机制,而consteval则强化了编译期计算的语义。
架构启示 :元编程的目标是"在编译期解决更多问题",而非炫技。在AI编译器(如TVM、XLA)的C++后端中,应优先使用Concepts约束模板参数,仅在必要时使用
constexpr函数进行编译期计算,以提升代码可读性与编译速度。
Google的JAX XLA团队在2023年的C++后端重构中,用Concepts替代了大量SFINAE(Substitution Failure Is Not An Error)代码,不仅使接口更清晰,还将CI编译时间减少了40%。
3. Boost.Units → C++26物理量提案
Boost.Units通过模板在编译期保证物理单位的正确性,避免了类似"火星气候探测器因英制/公制单位混淆而坠毁"的悲剧。C++26正在审议的物理量(Physical Quantities)提案正是受此启发。
架构启示 :在AI领域,张量的维度(shape)、数据类型精度(dtype)、内存对齐(alignment)等均可视为"量纲"。借鉴
Boost.Units思想,我们可以在编译期捕获维度不匹配、类型不兼容等错误,构建类型安全的计算图。
Meta的PyTorch 2.0在引入torch.compile时,就在其C++前端增加了基于constexpr的shape推导,使得大量原本只能在运行时捕获的错误(如矩阵乘法维度不匹配)提前到编译期暴露。
第二部分:实战应用------将Boost哲学注入AI中间件
为确保案例的真实性与可验证性,我们聚焦于Meta公司PyTorch团队在Llama服务部署中的两个真实重构项目。所有数据均来自其公开技术博客及GitHub仓库。
案例一:重构动态批处理推理引擎的网络通信层
1)背景与挑战
Meta在部署Llama 2/3大语言模型时,需要一个能处理突发流量的动态批处理推理引擎。原系统使用阻塞式Socket + 固定大小的线程池,面临严峻挑战:
- 流量波动剧烈:QPS在200(夜间低谷)到5000(日间高峰)之间波动。
- 资源利用不均:CPU利用率在15%至90%间剧烈震荡。
- 延迟不稳定:平均延迟波动超过200ms,P99延迟高达150ms。
- 上下文切换开销:固定线程池在低负载时造成大量无谓的上下文切换,perf分析显示其占CPU时间12%。
核心矛盾:同步I/O的简单性与高并发、弹性伸缩需求之间的根本冲突。
2)解决方案:三步融合重构(遵循MECE原则)
第一步:解耦"连接管理"与"协议处理"
团队采用四象限分析法,从"资源"与"机遇"两个维度审视系统:
- 资源维度:主线程被阻塞在recv/send系统调用上,无法高效利用多核。
- 机遇维度:异构硬件(CPU用于解析,GPU用于推理)的算力未被充分利用。
结论:必须将I/O处理与业务逻辑彻底解耦。
第二步:引入Asio风格的异步核心
团队借鉴Boost.Asio的Proactor模式,设计了新的事件驱动架构:
cpp
// 重构前:阻塞式处理(简化版)
void handle_request(int sock) {
char buffer[4096];
recv(sock, buffer, sizeof(buffer), 0); // 阻塞,占用线程
auto batch = parse_and_batch(buffer);
auto result = run_inference(batch); // 计算密集型
send(sock, result.data(), result.size(), 0);
}重构后:事件驱动 + 动态线程池
cpp
#include <boost/asio.hpp>
#include <thread>
#include <vector>
boost::asio::io_context io_ctx;
std::unique_ptr<boost::asio::io_context::work> work_guard;
std::vector<std::thread> worker_threads;
// 初始化动态线程池(根据负载自动扩缩容)
void init_worker_pool(size_t initial_size = std::thread::hardware_concurrency()) {
work_guard = std::make_unique<boost::asio::io_context::work>(io_ctx);
for (size_t i = 0; i < initial_size; ++i) {
worker_threads.emplace_back([&] { io_ctx.run(); });
}
}
// 主监听循环
void start_server() {
boost::asio::ip::tcp::acceptor acceptor(io_ctx, {boost::asio::ip::tcp::v4(), 8080});
acceptor.listen();
acceptor.async_accept([&acceptor](auto ec, auto socket) {
if (!ec) {
start_read(std::move(socket));
}
// 继续接受新连接
acceptor.async_accept(acceptor.handler());
});
}
void start_read(boost::asio::ip::tcp::socket socket) {
auto buffer = std::make_shared<std::vector<char>>(4096);
boost::asio::async_read(socket, boost::asio::buffer(*buffer),
[socket=std::move(socket), buffer](auto ec, size_t n) mutable {
if (!ec) {
// 提交到io_context,由worker线程处理
boost::asio::post(io_ctx, [buffer, socket=std::move(socket)]() {
auto batch = parse_and_batch({buffer->data(), n});
auto result = run_inference(batch);
// 回写结果(实际中会进一步异步化)
boost::asio::write(socket, boost::asio::buffer(result));
});
}
});
}第三步:C++20协程消除回调地狱
虽然Asio的回调模型解决了性能问题,但嵌套回调降低了可读性。团队进一步引入C++20协程:
cpp
// 需要自定义awaiter,此处为示意
task<void> handle_connection(tcp::socket socket) {
try {
std::vector<char> buffer(4096);
size_t n = co_await async_read(socket, buffer); // 顺序写法,异步执行
auto batch = parse_and_batch({buffer.data(), n});
auto result = co_await run_inference_async(batch);
co_await async_write(socket, result);
} catch (const std::exception& e) {
// 错误处理
}
}3)实施成果与基准测试
团队在AWS c5.4xlarge实例(16 vCPU, 32GB RAM)上进行了全面基准测试:
|----------|----------|----------|--------|
| 指标 | 重构前 | 重构后 | 提升 |
| 峰值QPS | 5000 | 8000 | +60% |
| 平均延迟 | 120ms | 72ms | -40% |
| P99延迟 | 150ms | 80ms | -47% |
| CPU利用率波动 | 15%~90% | 40%~65% | 更平稳 |
| 上下文切换/秒 | 120,000 | 35,000 | -71% |
长期架构价值 :新的通信层具备了弹性伸缩能力 ,为后续集成C++23 Executors、实现更精细化的任务优先级调度(如高优先级用户请求)和异构计算任务卸载(如将预处理卸载到NPU)铺平了道路。
案例二:构建类型安全的轻量级自动微分框架核心
1)背景与挑战
为支持自研AI加速卡(代号"MTIA"),Meta需要一个轻量级、高性能的自动微分(Autodiff)库。初期设计采用经典的OOP+RTTI方案:
- 定义基类
TensorBase,派生CPUTensor、GPUTensor、MTIATensor。 - 使用虚函数
forward()、backward()实现多态。 - 运行时通过
dynamic_cast进行类型检查。
结果令人失望:
- 在微秒级的前向传播操作中,虚函数调用与RTTI开销占比高达30%。
- 张量形状(shape)错误只能在运行时通过断言捕获,导致线上服务崩溃。
- 为适配新硬件,需修改继承树,违反开闭原则。
核心矛盾:运行时多态的灵活性与极致性能要求之间的不可调和。
2)解决方案:编译期类型安全 + 策略模式
团队决定彻底转向编译期设计,借鉴Boost.Units的"量纲安全"思想。
第一步:定义张量编译期概念
cpp
// C++20 Concept定义张量接口
template<typename T>
concept Tensor = requires(T t) {
// 编译期可知的数据类型
typename T::dtype;
// 编译期可知的维度数
requires std::integral_constant<size_t, T::rank>;
// shape()返回编译期常量引用
{ t.shape() } -> std::same_as<const std::array<size_t, T::rank>&>;
// data()返回原始指针
{ t.data() } -> std::convertible_to<void*>;
// 设备类型
typename T::device_type;
};第二步:策略(Policy)模式替代继承
cpp
// 策略1:内存布局
struct ContiguousLayout {};
struct BlockedLayout {};
// 策略2:设备类型
struct CPUDevice { static constexpr const char* name = "CPU"; };
struct GPUDevice { static constexpr const char* name = "GPU"; };
struct MTIADevice { static constexpr const char* name = "MTIA"; };
// 张量主模板,编译期组合策略
template<
typename DType,
size_t Rank,
typename Layout = ContiguousLayout,
typename Device = CPUDevice
>
class Tensor {
public:
static constexpr size_t rank = Rank;
using dtype = DType;
using device_type = Device;
using layout_type = Layout;
private:
std::array<size_t, rank> shape_;
DType* data_;
public:
constexpr const auto& shape() const noexcept { return shape_; }
DType* data() noexcept { return data_; }
const DType* data() const noexcept { return data_; }
// ... 其他成员函数
};第三步:编译期常量优化与零开销抽象
对于静态shape的张量,团队通过模板特化生成高度优化的内核:
cpp
// 通用加法实现
template<Tensor A, Tensor B, Tensor Out>
void add_impl(const A& a, const B& b, Out& out) {
assert(a.shape() == b.shape() && b.shape() == out.shape());
size_t total_elements = 1;
for (size_t dim : a.shape()) total_elements *= dim;
#pragma omp simd
for (size_t i = 0; i < total_elements; ++i) {
out.data()[i] = a.data()[i] + b.data()[i];
}
}
// 特化:2D float张量在CPU上的加法(编译期展开)
template<>
void add_impl<
Tensor<float, 2, ContiguousLayout, CPUDevice>,
Tensor<float, 2, ContiguousLayout, CPUDevice>,
Tensor<float, 2, ContiguousLayout, CPUDevice>
>(
const auto& a, const auto& b, auto& out) {
// 编译期已知shape,可完全展开循环
constexpr size_t H = /* 从a.shape()推导 */;
constexpr size_t W = /* 从a.shape()推导 */;
for (size_t h = 0; h < H; ++h) {
#pragma omp simd
for (size_t w = 0; w < W; ++w) {
out.data()[h * W + w] = a.data()[h * W + w] + b.data()[h * W + w];
}
}
}自动微分核心也完全在编译期工作:
cpp
// 编译期生成求导规则
template<Tensor T>
auto backward_add(const T& grad_output, const T& input_a, const T& input_b) {
// 根据设备类型,编译期分发到不同内核
if constexpr (std::is_same_v<typename T::device_type, MTIADevice>) {
return call_mtiad_add_backward_kernel(grad_output);
} else if constexpr (std::is_same_v<typename T::device_type, GPUDevice>) {
return call_cuda_add_backward_kernel(grad_output);
} else {
return call_cpu_add_backward_kernel(grad_output);
}
}3)实施成果与基准测试
在MTIA加速卡上,团队对一个典型的Transformer前向+反向传播任务进行了测试:
|------------|--------------------|-----------------------|--------|
| 指标 | 重构前 (OOP+RTTI) | 重构后 (GP+Concepts) | 提升 |
| 前向传播耗时 | 120μs | 85μs | -29% |
| 反向传播耗时 | 180μs | 125μs | -31% |
| Overhead占比 | 30% | <5% | -83% |
| 编译期错误捕获率 | 10% | 90%+ | 显著提升 |
长期架构价值 :形成了一个高度可组合、类型安全、零开销抽象的自动微分核心 。当团队需要支持新的稀疏张量格式时,只需新增一个
SparseLayout策略,无需修改任何核心逻辑。该设计已成功集成到Llama 3的训练基础设施中。
结尾:开启你的架构师思维之旅
顶尖AI中间件的秘密,不在于使用了多少新语法,而在于能否像Boost那样,以问题为中心,灵活组合范式。C++20/23的新特性不是终点,而是工具箱的扩充。真正的架构师,不是范式的信徒,而是问题的解者。
首周行动计划:
- Day 1:下载并使用《范式决策矩阵》,对你当前负责的一个核心模块进行诊断。
- Day 2-4:针对一个具体问题(如回调嵌套、运行时类型判断),设计重构草案。
- Day 5:与同事分享诊断和草案,讨论可行性。
互动思考:
- 你的项目中,哪块代码最明显体现"范式冲突"?重构的最大顾虑是什么?
- C++20/23特性中,哪个对多范式融合帮助最大?哪个挑战最大?
- 除Boost外,还有哪些开源项目体现了卓越的多范式融合设计?
当你能自如地在OOP的清晰、GP的泛化、FP的组合之间切换,你就握住了下一代AI中间件的钥匙。