摘要
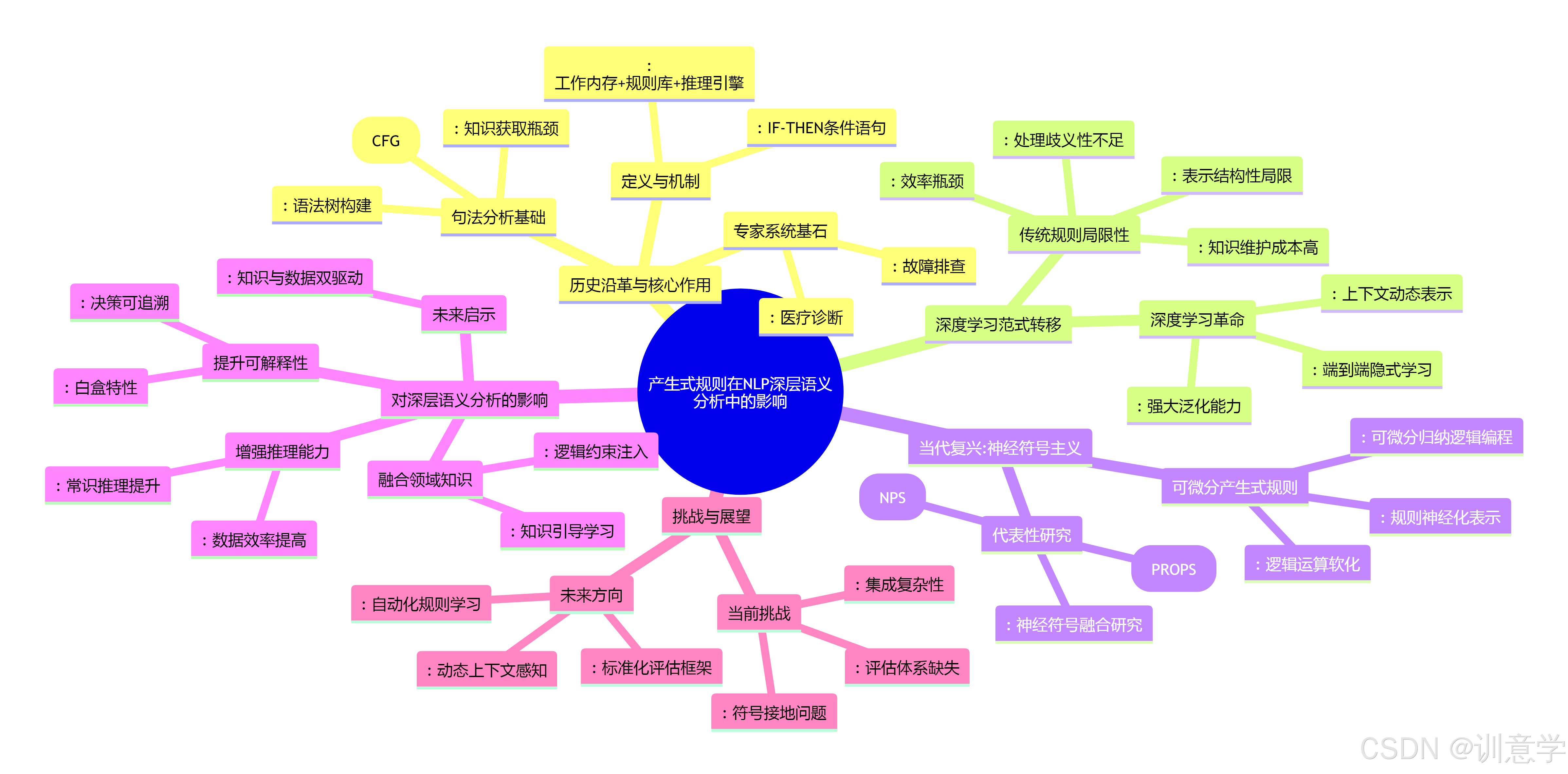
本报告旨在深入探讨产生式规则(Production Rule)在人工智能(AI)的自然语言处理(NLP)领域,特别是对深层语义分析所产生的历史影响、当代挑战与未来启示。研究表明,产生式规则作为早期AI知识表示与推理的核心,为NLP的句法分析奠定了基石。然而,随着深度学习模型的兴起,NLP的范式发生了根本性转变,传统的、基于硬编码规则的方法在处理语言的复杂性、歧义性和上下文动态性方面显示出巨大局限性 。尽管如此,产生式规则并未被完全摒弃。在2020年至2025年间,研究趋势清晰地指向一个将符号主义(以产生式规则为代表)与连接主义(以神经网络为代表)相结合的"神经符号"新范式。通过将规则转化为可微分的形式并集成到神经网络中,产生式规则正在以一种新的形态复兴,旨在解决当前深度学习模型在可解释性、常识推理和知识引导方面的核心挑战,从而为实现更深层次、更鲁棒的语义理解提供了关键启示。
第一章:产生式规则的历史沿革及其在早期NLP中的核心作用
1.1 产生式规则的定义与核心机制
产生式规则是人工智能领域中一种基础的知识表示方法,其核心结构为"如果...则..."(IF-THEN)形式的条件语句 。这一结构由两部分组成:前件(IF部分),即规则的前提或条件;以及后件(THEN部分),即规则的结论或要执行的动作 。一个完整的产生式规则系统通常包含三个核心组件:一个存储事实和数据的工作内存、一个存储所有规则的产生式内存(或规则库),以及一个负责匹配规则并执行的识别-执行循环(推理引擎)。这种机制使得系统能够根据当前状态(工作内存中的事实)自动触发相应规则,进行逻辑推理和问题求解 。
1.2 在早期AI与专家系统中的基石地位
在人工智能的黄金时代,产生式规则是构建专家系统的主要技术 。专家系统旨在模拟人类专家在特定领域的决策能力,而产生式规则恰好提供了一种直观且模块化的方式来编码专家的知识 。例如,在医疗诊断、故障排查等领域,专家们将诊断逻辑和经验知识编码为一系列产生式规则,系统通过这些规则进行推理,最终给出解决方案 。这种方法的成功证明了产生式规则在知识表示和自动化推理方面的巨大潜力 。
1.3 为NLP句法分析奠定基础
在自然语言处理的早期阶段,产生式规则的核心应用集中在句法分析(Syntactic Analysis)层面。其中,上下文无关文法(Context-Free Grammar, CFG)是其最典型的体现 。CFG使用一系列产生式规则来定义一种语言的语法结构,例如,"S -> NP VP"(一个句子由一个名词短语和一个动词短语构成)就是一条经典的产生式规则 。通过这些规则,分析器可以构建句子的语法树,从而理解其组成结构 。
虽然这一阶段的分析主要停留在结构层面,但它为后续的语义分析提供了不可或缺的基础。只有先厘清了句子的句法结构,才能进一步分析各个组成部分之间的语义关系 。因此,可以说,基于产生式规则的句法分析是通向深层语义理解的第一步,尽管它本身并未直接处理复杂的语义问题。然而,这一阶段也暴露了其局限性,即知识获取的瓶颈问题------如何系统性地创建和维护大规模、高质量的规则库,成为一个巨大的挑战 。
第二章:深度学习浪潮下的范式转移:从显式规则到隐式学习
2.1 传统规则方法的局限性
随着语言数据规模的爆炸式增长和对语义理解深度的要求越来越高,传统基于产生式规则的方法逐渐暴露出其根本性的局限性:
- 处理歧义和复杂性的能力不足:自然语言充满了歧义、隐喻和上下文依赖。手工编写的规则很难覆盖所有语言现象,尤其是在面对新词汇、非标准用法和复杂的语境时,规则系统显得非常脆弱和僵化 。
- 知识获取与维护成本高昂:构建一个全面的规则库需要大量的语言学专家知识和人力投入。此外,随着语言的演变,规则库需要不断更新和维护,这使得系统的可扩展性和适应性受到严重制约 。将语言模式编码为形式化规则,本身就需要用户理解特定的形式化语言,这限制了其普适性 。
- 效率问题:随着规则数量的增加,推理引擎需要进行更多的匹配操作,导致系统响应速度下降,存在效率瓶颈 。
- 表示结构性知识的局限:产生式规则在表示程序性知识方面表现出色,但在表示显式的、结构化的语义知识方面存在不足,因为规则只能在特定条件下被触发和访问 。
2.2 深度学习的兴起与语义表示的革命
自2010年代以来,以深度学习为核心的技术革命彻底改变了NLP领域 。以Transformer架构为基础的大型语言模型(LLMs),如BERT和GPT系列,成为了处理NLP任务的主流范式 。
与基于规则的方法不同,深度学习模型采用一种截然不同的路径来理解语言:
- 端到端的隐式学习:这些模型不依赖任何明确的语法或语义规则,而是直接从海量的文本数据中通过端到端的方式学习语言的统计规律和模式 。词向量、注意力机制等技术使得模型能够捕捉单词之间复杂的语义关系和长距离依赖 。
- 上下文感知的动态表示:与规则的静态匹配不同,深度学习模型能够根据上下文动态地生成每个词的语义表示。例如,BERT模型通过其双向Transformer结构,能够深刻理解一个词在特定语境下的确切含义,从而有效解决词义消歧等问题 。
- 强大的泛化能力:通过在超大规模语料库上的预训练,这些模型获得了强大的语言知识和泛化能力,能够轻松适应各种下游任务,如机器翻译、情感分析、问答系统等,而无需为每个任务重新编写规则 。
这一范式转移导致在当代主流的深度语义分析应用中,几乎看不到传统产生式规则的身影 。深度学习模型以其卓越的性能和灵活性,在处理自然语言的细微差别和复杂性方面,远胜于基于规则的系统 。
第三章:产生式规则的当代复兴:神经符号主义与混合方法
尽管深度学习取得了巨大成功,但其"黑箱"特性、对海量数据的依赖以及在逻辑推理方面的脆弱性也日益凸显 。这为产生式规则的复兴提供了契机,但其形式不再是过去僵化的、手工编码的规则,而是与神经网络深度融合的、可学习的动态规则。这一前沿方向被称为"神经符号计算"(Neuro-Symbolic Computing)。
3.1 核心思想:可微分的产生式规则
神经符号方法的核心思想是将离散的、符号化的产生式规则转化为连续的、可微分(differentiable)的形式,从而能够将其无缝嵌入到神经网络中,并通过梯度下降等优化算法进行端到端的训练 。
实现这一目标的技术路径主要包括:
- 逻辑运算的软化:将传统逻辑中的与、或、非等离散运算,替换为连续可微的数学运算(如使用t-norm等模糊逻辑算子),从而让逻辑推理过程可以被神经网络学习 。
- 规则的神经化表示:将每一条产生式规则表示为一个独立的神经网络模块(如一个多层感知机MLP)。这个模块的输入是当前的状态(类似于工作内存),输出是该规则被触发的置信度或结果 。注意力机制常被用来确定哪些规则在给定上下文中应该被激活 。
- **可微分归纳逻辑编程(Differentiable ILP)** :这类方法,如DFOL (Differentiable First-Order Rule Learner),旨在从数据中自动学习出显式的逻辑规则,并且整个学习过程是可微分的 。这使得系统不仅能做出预测,还能产出可供人类理解的规则。
3.2 代表性研究与模型
在2020年至2025年间,这一领域涌现了大量开创性的研究工作,这些研究探索了如何将规则与神经网络进行有效集成 。例如,"神经产生式系统"(Neural Production Systems, NPS)和受其启发的"提示产生式系统"(Prompt Production Systems, PROPS)等模型,尝试构建一种端到端的、通过可学习的产生式规则进行操作的系统 。
此外,大量的研究论文聚焦于神经符号方法的理论与应用,探讨如何融合深度学习的感知能力与符号方法的推理能力,以解决更复杂的语言和视觉任务 。这些研究共同构成了产生式规则在AI新时代下的演变图景:从静态的知识载体,转变为神经网络中动态的、可学习的计算组件。
第四章:对深层语义分析的影响与启示
产生式规则以新的"神经符号"形态回归,为解决当前深度学习在NLP深层语义分析中面临的瓶颈提供了重要的影响和启示。
4.1 影响一:提升模型的可解释性与可信度
深度学习模型常被诟病为"黑箱",其决策过程难以理解和追溯。而集成了可学习规则的神经符号系统,则有潜力在做出预测的同时,输出其决策所依据的显式规则 。这种"白盒"特性对于金融、法律、医疗等高风险领域的NLP应用至关重要,因为它不仅能告诉我们"是什么",还能解释"为什么",从而极大地增强了系统的可信度和透明度。
4.2 影响二:融合领域知识与逻辑约束
纯数据驱动的模型很难学习到特定领域中隐含的先验知识、常识或必须遵守的硬性逻辑约束。产生式规则为注入这些知识提供了一个自然的接口 。例如,在法律文本分析中,可以将法律条文编码为可微分规则,强制模型在进行语义理解时遵循这些法律逻辑。这种"知识引导"的学习方式,可以有效减少模型产生事实性错误或逻辑谬误的概率。NLP技术也被探索用于自动化生成IF-THEN规则,以辅助这一过程 。
4.3 影响三:增强模型的推理能力与数据效率
当前的LLMs在进行复杂的、多步骤的逻辑推理时仍显不足 。神经符号系统通过将符号推理机制显式地集成到网络结构中,有望提升模型在常识推理、因果推断等任务上的表现 。由于规则提供了强大的结构先验,模型不再需要从零开始学习所有的逻辑关系,因此可能在较少的数据上达到更好的性能,从而提高数据效率 。
4.4 未来启示:从"数据驱动"走向"知识与数据双驱动"
产生式规则的演变给我们的最大启示是,未来NLP深层语义分析的发展方向,并非是符号主义与连接主义的对立,而是二者的深度融合。一个真正智能的系统,既需要具备深度学习模型强大的模式识别和泛化能力,也需要具备符号系统严谨的逻辑推理和知识运用能力。产生式规则作为知识和推理的经典载体,其在神经网络框架下的新生,标志着NLP正在从纯粹的"数据驱动"范式,向着"知识与数据双驱动"的更高级范式迈进。
第五章:挑战、局限性与未来展望
尽管神经符号方法前景广阔,但其发展仍面临诸多挑战。
5.1 当前的挑战与局限性
- 集成复杂性与可扩展性:设计和训练一个高效的神经符号系统在技术上极具挑战性。如何平衡符号模块和神经模块的计算,以及如何保证系统在规则库规模扩大时的可扩展性,都是亟待解决的难题 。
- 评估体系的缺失:目前,学术界严重缺乏专门用于评估神经符号系统,特别是基于产生式规则的深层语义分析模型的标准性能基准和公开数据集。搜索结果显示,现有的NLP基准(如GLUE、MMLU)和评估指标(如准确率、召回率、BLEU、ROUGE)大多是为端到端模型设计的,无法有效衡量混合系统在推理正确性、知识运用准确性和可解释性等方面的表现 。这是一个重大的研究空白。
- **符号接地问题(Symbol Grounding Problem)** :如何确保模型学习到的符号规则真正与其在现实世界中的语义含义对应起来,即符号接地问题,依然是AI领域的根本性挑战之一 。
5.2 未来展望
展望未来,我们预测产生式规则将在NLP深层语义分析中扮演越来越重要的角色,其研究将聚焦于以下几个方向:
- 自动化规则学习与抽取:发展更强大的算法,能够直接从非结构化文本、知识图谱甚至多模态数据中自动学习和提炼出高质量、可解释的产生式规则。
- 动态与上下文感知的规则系统:研究如何让产生式规则本身变得更加动态和上下文感知,使其能够根据不同的语境自适应地调整其行为和优先级。
- 构建标准化的评估框架:学术界和工业界需要合作,共同开发针对神经符号NLP系统的评测基准和数据集,重点评估其在复杂推理、知识融合和可解释性方面的能力,以推动该领域的健康发展 。
结论
总而言之,产生式规则的历程是一部浓缩的AI发展史。它从早期NLP的奠基者,到深度学习时代被边缘化,再到如今以神经符号融合的形态迎来复兴,其角色和形式发生了深刻的演变。对于深层语义分析而言,产生式规则的价值已不再是作为一种孤立的、手工编码的分析工具,而是作为一种能够为深度学习模型注入知识、逻辑和可解释性的关键组件。这种"规则即网络,网络即规则"的融合范式,为我们突破当前纯数据驱动方法的瓶颈,迈向更强大、更可靠、更可信的通用人工智能,指明了充满希望的方向。