欢迎关注【人工智能通识】专栏
文献阅读是科研工作的基础能力和重要内容。科研新人在阅读专业文献时,由于面临领域认知断层和专业术语瓶颈的困难,常常望而生畏,学习效率很低。Deepseek智能辅助阅读能帮助科研人员在文献阅读中快速理解核心内容和知识关联,极大地降低了专业认知门槛,提高了阅读效率。
10.2.1 快速泛读
文献泛读的目的是通过快速浏览大量文献,了解研究领域的现状、趋势和研究热点。
使用DeepSeek辅助文献阅读,首先要输入文档内容。篇幅较短的文档可以直接复制到DeepSeek对话框中,篇幅较长的文档可以通过上传附件方式上传到DeepSeek。
快速提炼核心内容
文献泛读的核心是研究目的、方法和关键结论。
我们上传文档【Deep Residual Learning for Image Recognition】后,可以向Deepseek提问如下:【请总结上传文献的研究问题、研究方法、主要结论和创新点】。Deepseek阅读文档后,总结了论文研究问题、研究方法、主要结论和创新点,如图10-8所示依次分条列出。
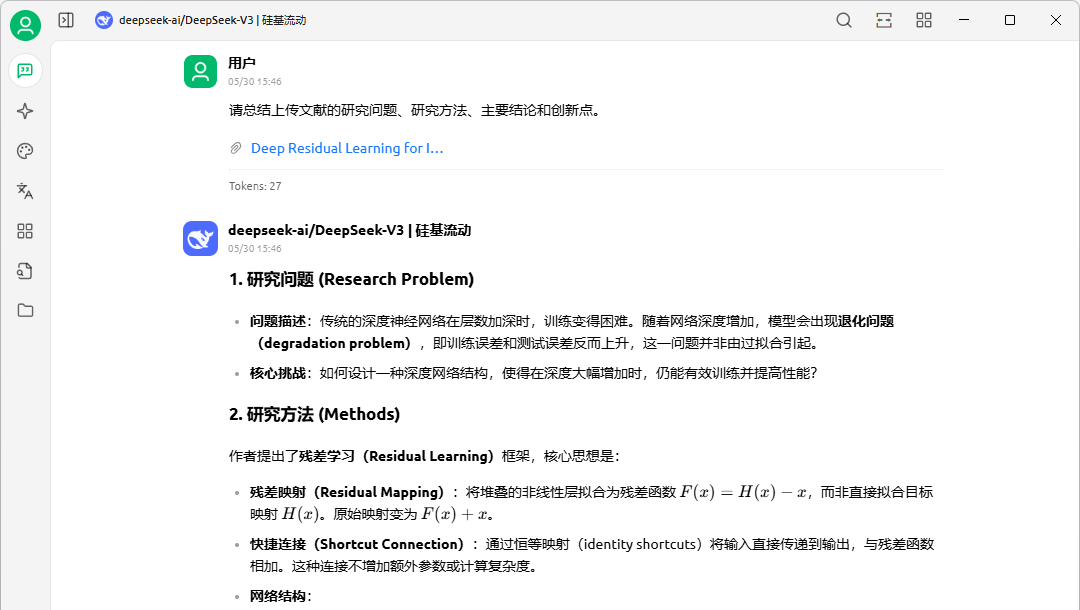
图10-8:基于Deepseek的智能文献阅读
结构化泛读
进一步地,可以让Deepseek设计结构化的泛读模板,以. csv格式输出,结果如下。读者根据自己的需要,可以对模板文件的内容进行简化或优化。
模块,字段,说明
元信息,论文标题,"<Deep Residual Learning for Image Recognition>"
元信息,作者,"<Kaiming He et al.>"
元信息,发表年份,"<2015>"
研究问题,核心挑战,"<深度网络退化问题: 层数增加导致训练误差上升>"
研究问题,现存方案,"<归一化初始化,中间层归一化>"
方法框架,关键创新,"<残差学习: H(x)=F(x)+x,恒等映射捷径连接>"
方法框架,结构设计,"<Bottleneck块(1x1-3x3-1x1卷积组合)>"
实验结果,数据集,"<ImageNet,CIFAR-10,COCO>"
实验结果,性能提升,"<ImageNet误差3.57%(152层),COCO检测mAP↑28%>"
创新点,理论突破,"<首次实现超100层可训练网络(最高1202层)>"
创新点,技术优势,"<无额外参数/计算,解决梯度消失问题>"
应用价值,实践意义,"<ILSVRC2015分类/检测/定位/分割全部冠军>"
延伸思考,核心启示,"<残差结构成为深度模型基础组件>"
延伸思考,批判反思,"<超深网络参数效率问题(1202层参数冗余)>"
我们可以要求Deepseek按照这个结构化模板阅读文献并输出泛读报告。例如,输入【请阅读论文Attention Is All You Need,并按照给定的泛读模板格式输出.csv文件。】,结果如图10-9所示。这种方法不仅可以快速实现文献阅读的标准化、结构化,而且可以批量处理文献、快速提取核心信息、自动抽取技术指标,为文献分析和文献综述做好准备。
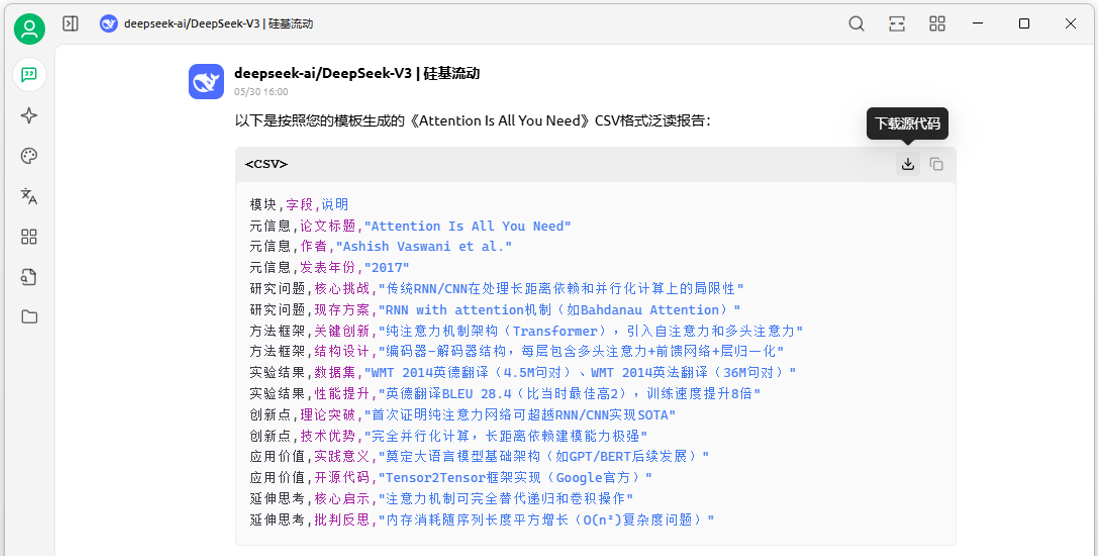
图10-9:基于Deepseek的智能文献阅读
全文翻译
传统翻译软件在处理专业文献时,常因缺失领域知识适配而导致术语歧义、语义脱节问题,翻译结果存在大量错误和晦涩。使用Deepseek翻译专业文献,可以结合专业领域和上下文,实现精准快速的翻译。
【请阅读并理解这篇文献,然后请你作为本领域的教授,将其翻译为中文,要求:逐字逐句精准翻译,不要改写缩写,内容通顺易懂,专业术语表达准确。】
10.2.2 文献精读
对重点文献的精读,要求全面理解论文的研究思路、方法和结论,并进行批判性的思考。通过Deepseek辅助,我们可以参考如下步骤进行文献精读。
深度阅读
首先要求Deepseek作为本专业的教授,对精读文献进行全文讲解,参考提问如下。
【请阅读并理解这篇文献,然后请你作为本领域的教授,详细讲解文献的研究对象、研究思路、实现方法和结论。】
重点难点讲解
其次,对于文献中的重点难点内容,例如创新原理、实现方法、实验设计、结果分析,都可以进行更深入的讲解,参考提问如下。
【请你作为本领域的教授,针对文献中的**部分,以通俗易懂的语言详细讲解和分析。】
【请你作为本领域的教授,针对文献中提到的**概念/方法,以通俗易懂的语言进行讲解。】
【请你作为本领域的教授,针对文献中的公式*,结合上下文解释符号含义,分步拆解推导,讲解公式的原理和作用。】
【请你作为本领域的教授,针对文献中的图/表*,讲解数据来源和符号标注的含义,分析图中曲线的含义,指出本图/表支撑了论文中哪句话的结论。】
交互式追问
如果对于Deepseek的讲解存在疑惑,我们可以聚焦疑难问题点进行交互式提问,例如要求Deepseek具体讲解问题点,或用简单的例子说明。举例如下。
【用户】论文Attention is all you need中,注意力机制的Q/K/V分别是什么?
【Deepseek】在注意力机制中(论文第3.1节):
Query (Q):当前需要计算注意力的目标向量(如翻译任务中待生成的词)。
Key (K):输入序列的向量表示,用于与Query计算相关性(如原文中的每个词)。
Value (V):与Key对应的实际内容向量,最终加权求和得到输出。
【用户】为什么Q和K要做点积再除以Sqrt(dk)?
【Deepseek】
1.点积:衡量Q与K的相似度,值越大表示相关性越强(参考论文3.2.1节)。
2.缩放因子Sqrt(dk):Sqrt(dk)是向量维度,防止点积结果过大导致softmax梯度消失。
假设Q,K各维度独立且方差为1,则QKT的方差为dk,缩放后方差恢复为1。
【用户】请举例说明缩放前后注意力权重的变化?
【Deepseek】
以句子"The cat sat on the mat"为例,假设dk=64:
1.未缩放时:注意力权重极端集中(如"cat"对"sat"的权重接近1,其他词接近0),梯度几乎仅存在于最大值位置,训练不稳定。
2.缩放后:权重分布更平滑(如"cat"对"sat"权重0.6,"on"权重0.3),可以保留多词关联信息,梯度分布更均衡。
【用户】这种权重差异如何影响实际任务?例如翻译任务。
【Deepseek】以英译中的翻译任务为例:
1.未缩放时:模型可能过度聚焦某个词(如"bank"只关注"河岸"而忽略"银行"),导致歧义错误。
2.缩放后:模型能同时关注多个相关词(如"bank"对"money"和"river"均有适度权重),结合上下文消除歧义。
论文第5.1节的实验表明,缩放使翻译BLEU评分提升约1.5-2分。
批判性思考
批判性思考的本质是用问题解构结论。在Deepseek的帮助下,通过分析论文的合理性与局限性,可以发现前人研究中的漏洞,成为我们研究创新的切入点。举例如下。
【用户】论文An Interpretable System for Screening the Severity Level of Retinopathy in Premature Infants Using Deep Learning,本文通过串联三个独立模型(病变检测→全景拼接→加病分类)实现"可解释性",请分析这种设计是否存在缺陷?
【Deepseek】
架构级缺陷:
1.误差传播累积:病变检测误差(如漏检Stage III病变)会直接破坏全景拼接的病灶定位 → 导致分区(Zone)误判 → 最终影响严重性分级。
2.协同训练缺失:各模块独立训练(无多任务联合优化),无法通过反向传播校正上游错误(如全景拼接无法反馈信号优化病变检测)。
解释性技术缺陷:
1.黑盒规则执行:模型仅输出病灶坐标+类型,但ETROP规则以硬编码逻辑实现,而非神经网络学习。
2.缺乏因果建模:可视化仅展示相关性,未证明病变存在导致严重性的因果链。
【用户】若改用多任务UNet++,共享编码器同时输出病灶分割+分期+分区热图,能否通过梯度协同降低误差累积?
【Deepseek】以下是对该技术提案的深度可行性分析与改进建议。
可行性论证:多任务UNet++ vs 串联模型
...
改进型架构提案:ROP-MTLNet
...
预期性能验证路径
...
结论建议
1.多任务架构在技术可行,但需针对性改造:
必须引入病灶感知机制避免小目标失效。
解剖规则嵌入需保持可微性而非硬编码。
2.验证重点应转向:当病变检测mAP下降20%时,ROP-MTLNet的严重性分级AUC降幅是否控制在≤5%(原文串联模型:12%降幅)?
若需进一步探讨具体实现代码或对比实验设计,我可提供更详细技术方案。
我们对Deepseek的每一次提问都应该按照"证据缺口 + 改进路径"的结构,在多轮交互中反复使用此框架,从质疑中获得撬动新知识的支点。
10.2.3 Zotero集成Deepseek
将文献上传后进行提问,不仅要耗费大量Tokens,而且缺乏系统性。在Zotero文献管理工具中集成 Deepseek,可以更高效地 进行AI辅助文献阅读。
Awesome GPT插件的安装与配置
Awesome GPT是开源Zotero插件,可以调用Deepseek模型的API进行对话式提问,实现文献摘要生成、关键词提取与知识图谱构建。
(1)从 Zotero中文社区插件商店(https://zotero-chinese.com/plugins/)下载Awesome GPT插件安装包zotero-gpt.xpi。
(2)打开 Zotero,点击顶部菜单栏的"工具--插件",在插件管理页面选择 "Install Add-on From File",选择zotero-gpt.xpi安装包进行安装。
(3)安装完成后重启Zotero以激活插件。
(4)点击顶部菜单栏的"工具--插件"进入插件管理页面,点击"Awesome GPT"插件后面的开关,以启用该插件。
(5)点击顶部菜单栏的"编辑--设置",进入如图10-10所示的Zotero设置页面,从左侧菜单选择"GPT"选项卡。
(6)点击"BaseAPI"所在行的API下拉框,展开下拉选项并选择硅基流动作为模型接入服务商"siliconflow",在API url 栏中会自动匹配为"https://api.siliconflow.cn"。
(7)在"API Key"输入从硅基流动官网获取的API 密钥"sk-******"。
(8)点击"Model"所在行的下拉框,展开下拉选项选择"deepseek-v3(siliconflow)",也可以根据需要选择其它模型。
(9)勾选"Using custom embeddings"选框,配置嵌入(Using custom embeddings)模型。
(10)点击"FullAPI"所在行的API下拉框,展开下拉选项并选择硅基流动 "siliconflow",在API url 栏中会自动匹配为"https://api.siliconflow.cn/v1/embeddings"。
(11)在"API Key"输入从硅基流动官网获取的API 密钥"sk-******"。
(12)点击"Model"所在行的下拉框,展开下拉选项选择"BAAI/bge-m3(siliconflow)"。
(13)配置完成后,点击下方的"test"按钮进行测试,输出"Normal"表明测试正常,配置成功。
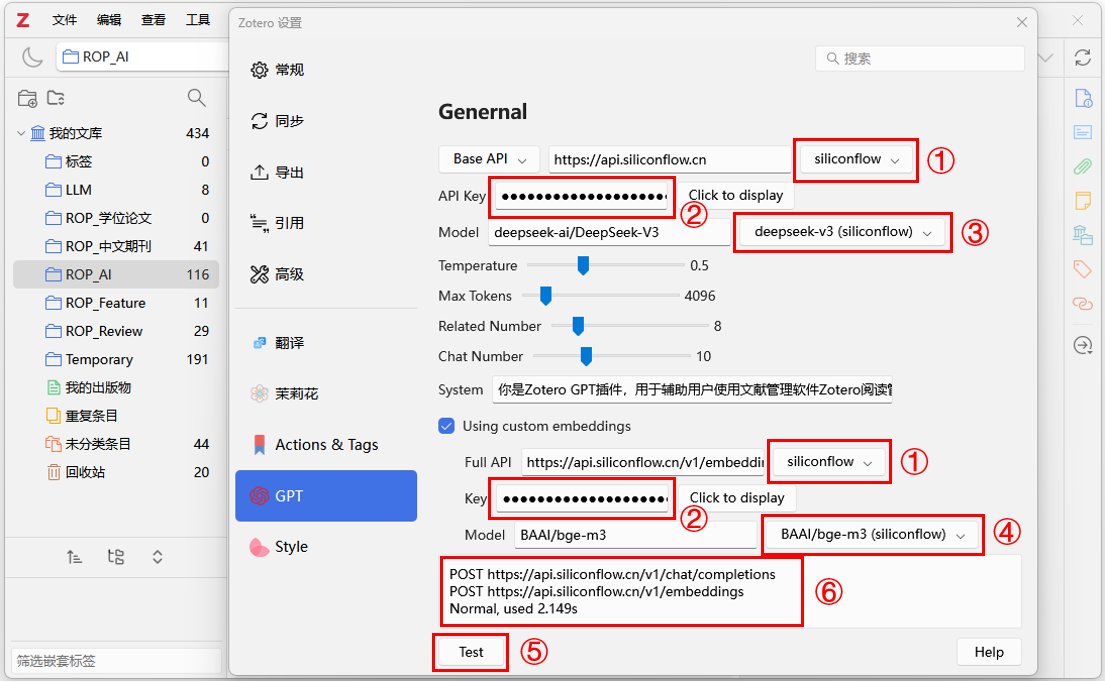
图10-10:安装和配置Zotero AwesomeGPT插件
启动和交互方法
在Zotero中打开文档,点击工具栏的GPT插件图标" ",就唤出AwesomeGPT对话窗口。窗口中提供了常用标签按键,如"AskPDF"、"Translate"、"Literature Review"等。按Esc键或再次点击GPT插件图标,则退出AwesomeGPT对话窗口。
",就唤出AwesomeGPT对话窗口。窗口中提供了常用标签按键,如"AskPDF"、"Translate"、"Literature Review"等。按Esc键或再次点击GPT插件图标,则退出AwesomeGPT对话窗口。
我们可以采用四种方式与 Deepseek 进行交互,实现对PDF文档的提问:
-
问题 + 回车:在输入框内输入问题后按下回车,就可以与Deepseek直接进行对话。
-
问题 + 标签按键,:在输入框内输入问题后点击"AskPDF"标签按键,Deepseek会阅读PDF文档后回复问题。
-
关键词触发命令标签:命令标签也可以通过关键词进行触发。
例如在输入框内输入"这篇论文写了什么"则自动选中命令标签AskPDF,直接按回车就可以实现问题+标签按键的快速提问。
- Ctrl + 回车:自动执行上一次的命令标签。
论文总结
点击AwesomeGPT对话窗口中的"AskPDF(Full test)"标签按键,就可以对当前论文进行系统性总结,并采用学术结构化表达,如图10-11所示。注意这是调用Deepseek模型自动生成的总结,而不是对论文摘要(Abstract)的翻译。
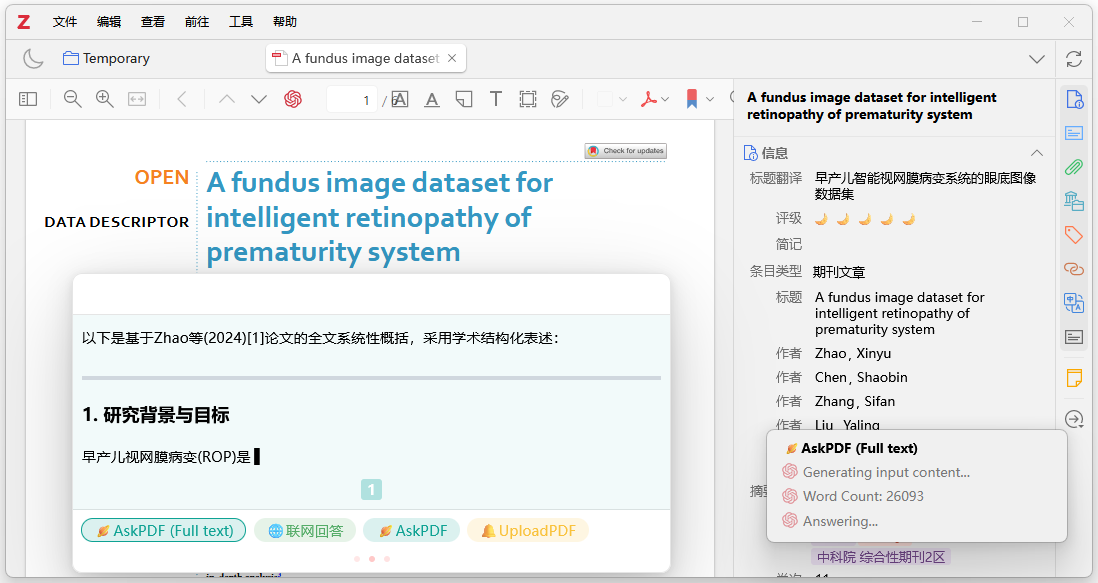
图10-11:Zotero+Deepseek生成论文总结
内容翻译
在文档中选择需要翻译的内容后,点击AwesomeGPT对话窗口中的"Translate"标签按键,就可以对选定的内容进行学术翻译。也可以在对话窗口的顶部输入类似"请翻译选择的内容"的要求,对选定的内容进行翻译。
论文分析和讲解
在AwesomeGPT窗口顶部的对话框输入问题,可以对论文进行分析。对于论文中的重点难点,也可以要求Deepseek进行讲解。
例如,在对话框输入"请分析本文的不足之处,提出改进的方案",结果如图10-12所示。在对话框输入"请对表2进行讲解",就可以调用Deepseek来讲解。这样的讲解和问答也可以进行多轮交互。
联网搜索
以当前论文为背景,进行联网搜索和分析。
例如,输入"请联网搜索,除本文外还有哪些ROP 数据集"后,点击"联网问答"标签按键,就可以调用Deepseek联网搜索后再回答提出的问题,结果如图10-13所示。
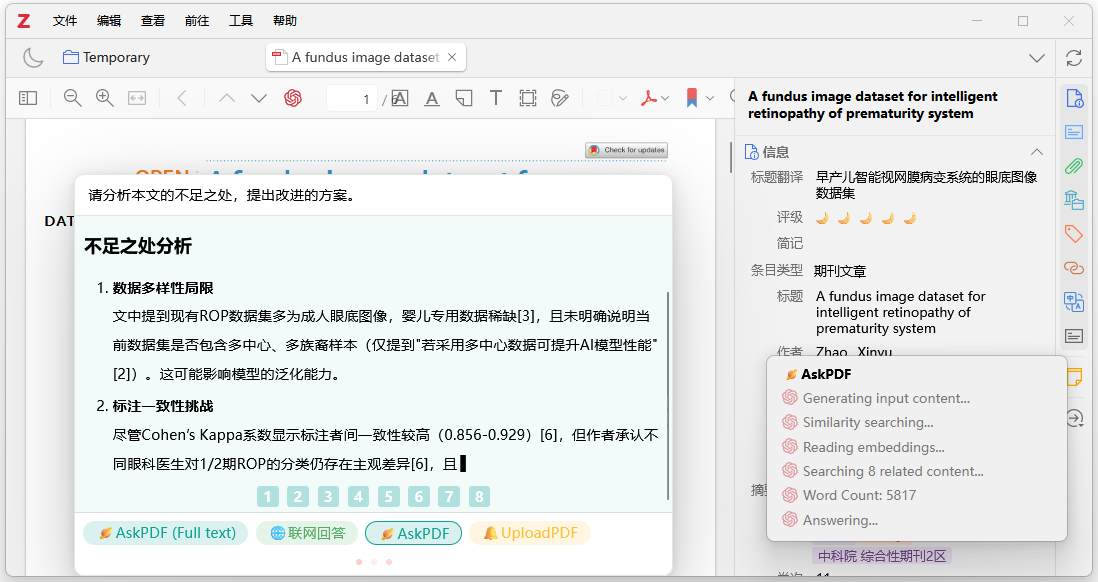
图10-12:Zotero+Deepseek论文分析与讲解
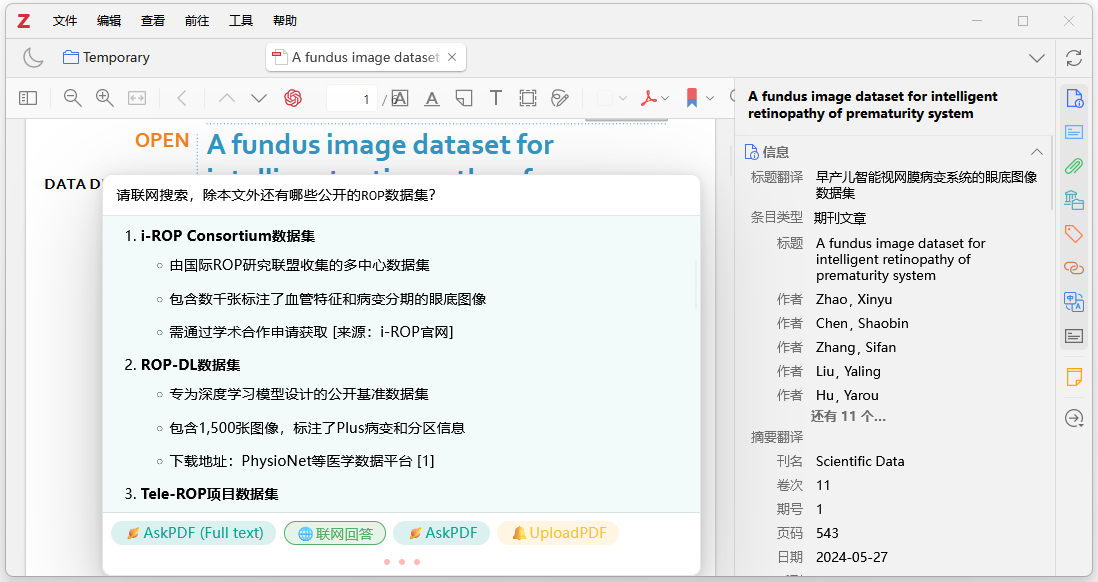
图10-13:Zotero+Deepseek联网搜索
往期回顾:
【人工智能通识专栏】第二十九讲:Deepseek助力文献检索
版权声明:
本文版权属于 AI小书房(aixiaoshufang@163.com),转载必须标注原文链接: https://mp.csdn.net/mp_blog/creation/editor/152273729
Copyright@AI小书房 2025