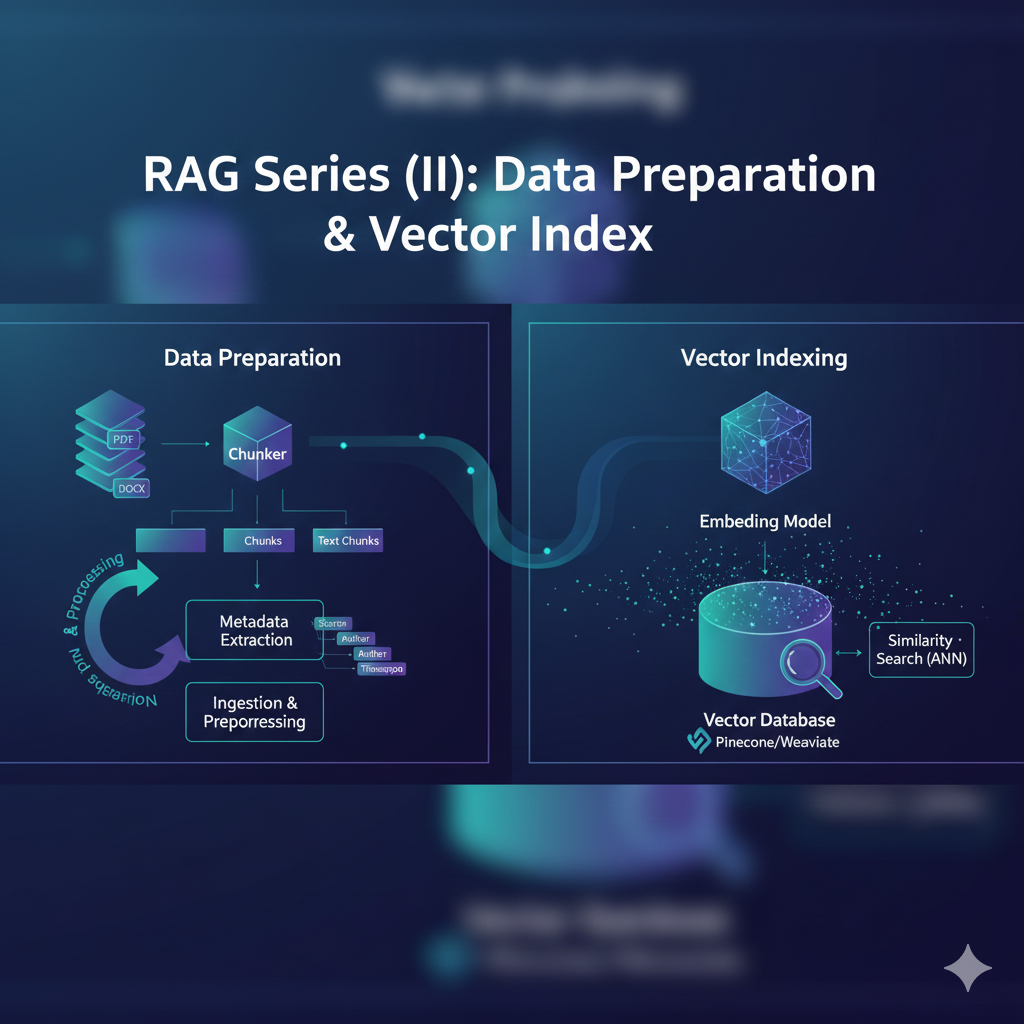
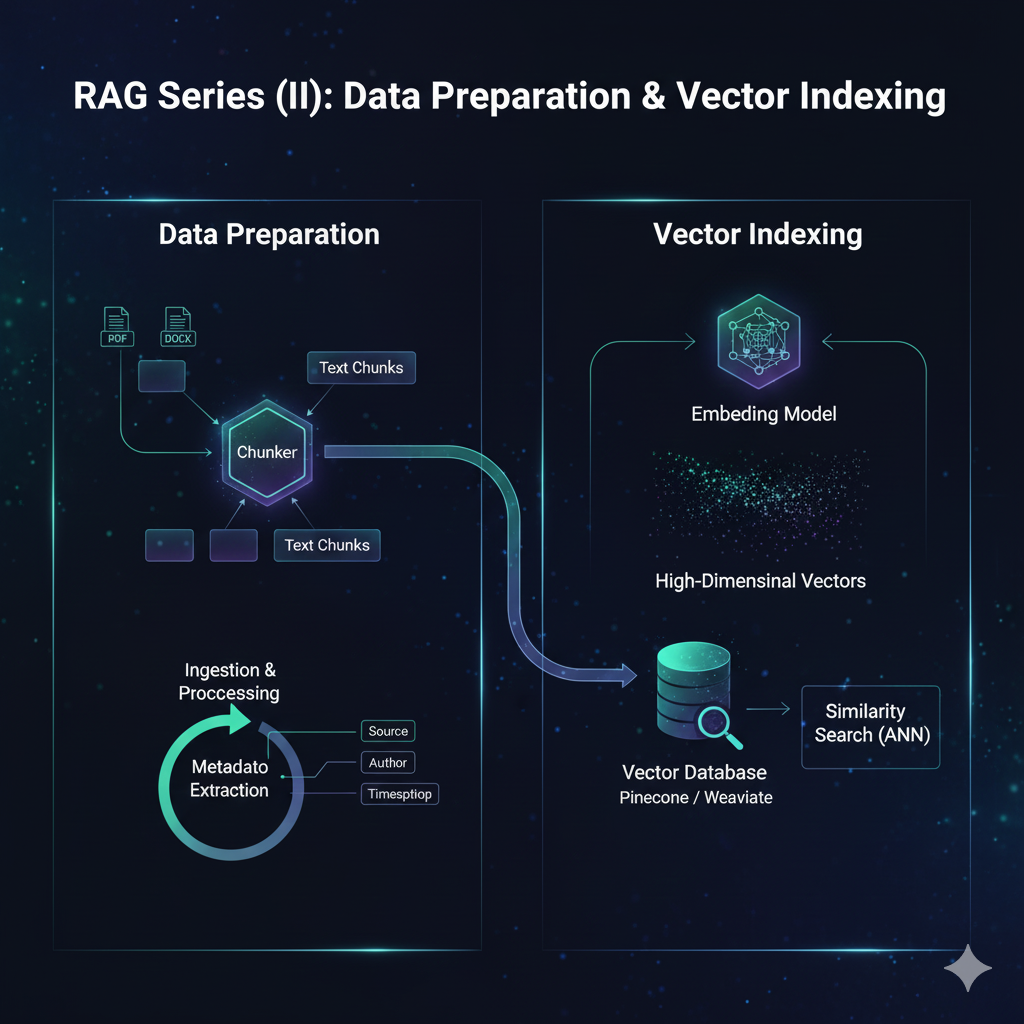
在 RAG(检索增强生成)系统中,数据准备是决定系统性能的最关键因素。即便拥有最先进的语言模型,如果检索到的上下文是含糊、破碎或无关的,模型也无法生成高质量的回答。本章将深入探讨如何通过精细的数据工程,将原始文档转化为高性能的向量索引。
一、 文档预处理与清洗
在进行分块和嵌入之前,必须遵循"垃圾进,垃圾出"的原则对原始数据进行清洗。未经过滤的噪声(如 HTML 标签、页眉页脚、样板文件)会稀释向量嵌入的语义精度。
1. 核心处理步骤
- 清理与规范化:移除无效字符、修复编码错误、去除冗余的空白符。
- 样板文件剔除:识别并删除对回答问题无贡献的导航菜单、免责声明或广告内容。
- PII 处理:在生产环境中,需对敏感信息(如个人身份信息)进行脱域或加密处理,以满足隐私合规要求。
- 元数据附加 :为每个文档段落添加结构化标签,如来源 URL、作者、发布日期、章节标题、访问权限级别。元数据在检索阶段极为重要,可用于精确的属性过滤。
二、 关键技术:文档分块 (Chunking Strategies)
分块是将长文档分割成语义连贯的短片段的过程。理想的块应包含完整的语义想法 ,同时能够适配 LLM 的上下文窗口。
常用分块策略对比
| 策略 | 机制 | 理想用途 | 优缺点 |
|---|---|---|---|
| 固定长度分块 | 按精确的字符或 Token 数分割 | FAQ、结构化代码 | 计算最快,但常在句子中间截断,损失连贯性 |
| 递归字符分割 | 优先尝试在段落、句子处分割 | 通用文档 (PDF, Markdown) | 保持自然结构,是大多数 RAG 系统的默认选择 |
| 语义分块 | 基于句子间的语义相似度寻找断点 | 法律或学术等复杂长文 | 检索精度最高,但计算开销大(需调用模型) |
| 滑动窗口分块 | 在块与块之间设置重叠区域 (Overlap) | 引用密集的学术论文 | 防止重要信息在边界处丢失,但会增加索引体积 |
| 文档结构感知 | 识别 Markdown 标题或表格结构 | 技术文档、代码库 | 改善领域特异性精度达 40% 以上 |
专家建议 :对于大多数生产 RAG 系统,使用 400-800 个 Token 的递归分块 并设置 20% 的重叠度,能在检索精度和上下文完整性之间取得最佳平衡。
三、 嵌入与向量化 (Embedding)
嵌入模型将文本转换为高维数值向量,这些向量捕获了文本的语义本质。
- 模型选择 :通常选择针对"搜索"任务优化的模型,如 OpenAI 的
text-embedding-3-small或开源的BGE、E5系列。 - 微调必要性 :在医疗或法律等特定行业,通用嵌入模型可能无法识别缩写或术语。对嵌入模型进行领域适配微调可显著提升检索准确率。
四、 向量数据库与索引构建
向量数据库负责存储嵌入并执行近似最近邻 (ANN) 搜索。
主流向量数据库对比
- Pinecone:全托管 Serverless 架构,适合追求零运维、全球扩展的企业。
- Milvus:开源分布式,适合处理数十亿向量的超大规模场景,对数据工程能力要求高。
- Weaviate :支持原生混合搜索(向量+关键词)和模块化架构,灵活性极佳。
- Qdrant:Rust 编写,内存效率高,适合对延迟敏感和边缘部署。
- Chroma:轻量级,开发者友好,是原型设计和中小型应用的理想选择。
五、 代码实践:构建高级索引管道
以下示例展示了如何使用 LlamaIndex 框架实现句子窗口索引 (Sentence Window Indexing)。这种技术在检索时查找单个句子,但在生成时提供该句子前后的完整窗口,从而解决"块太小缺乏上下文"的问题。
python
import os
from llama_index.core import SimpleDirectoryReader, StorageContext, VectorStoreIndex, Settings
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# 1. 配置全局模型设置
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding()
# 2. 加载原始文档
documents = SimpleDirectoryReader("./data").load_data()
# 3. 配置高级分块器:句子窗口模式
# 设置 window_size=3 意味着检索到一个句子时,实际会返回其前后各3句
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text"
)
# 4. 提取节点并构建索引
nodes = node_parser.get_nodes_from_documents(documents)
index = VectorStoreIndex(nodes)
# 5. 配置检索后的"元数据替换"后处理器
# 这确保了发给 LLM 的是扩充后的窗口内容,而非孤立的句子
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
# 6. 创建查询引擎
query_engine = index.as_query_engine(
node_postprocessors=[postproc]
)
# 7. 执行查询
response = query_engine.query("文中提到的技术架构有哪些核心组件?")
print(response)生产环境优化清单:
- 元数据过滤 :在创建索引时添加
user_id等标签,检索时通过filters参数实现租户隔离。 - 量化技术:对大规模向量进行乘积量化 (PQ) 以减少内存开销。
- 层次化索引:为大型文档库构建二级索引------一级通过摘要检索文档,二级检索具体块。
通过精心设计的数据清洗和分块策略,您的 RAG 系统已经拥有了坚实的底层支撑,能够为后续的推理生成提供精准、可靠的知识依据。