SFT数据场景,为什么要构建sft?
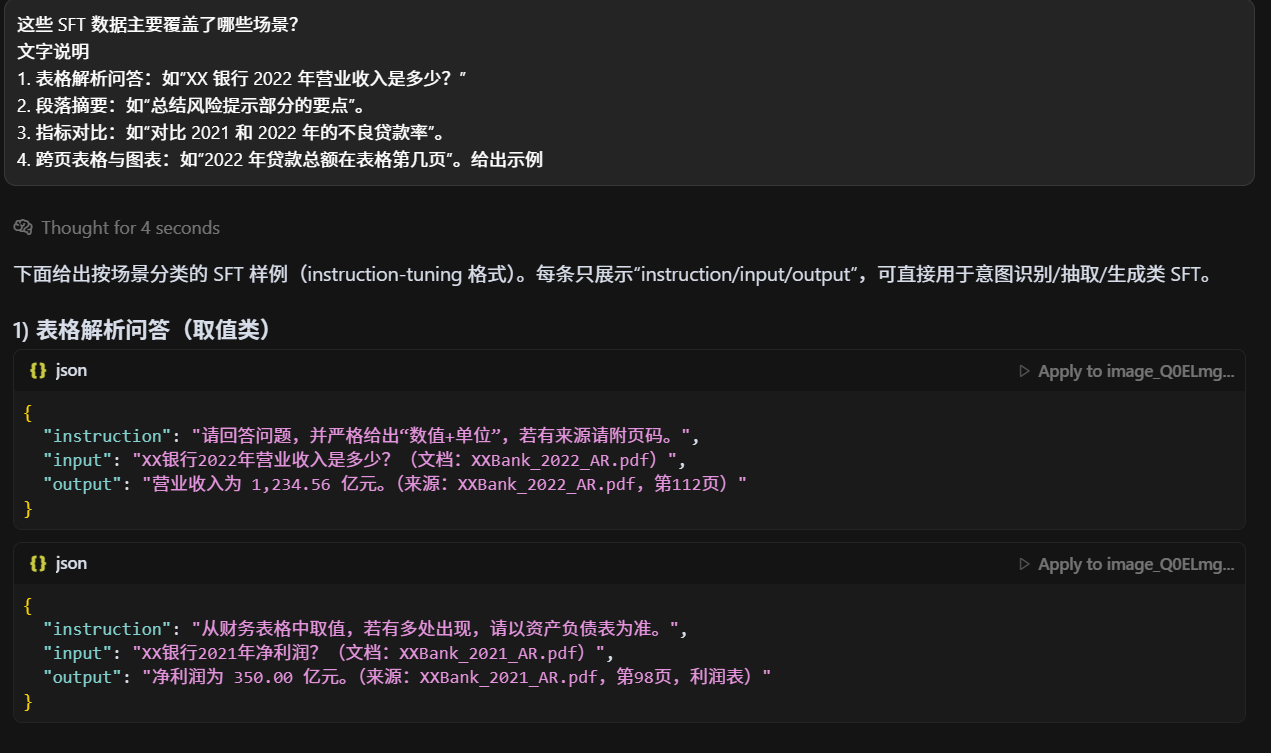
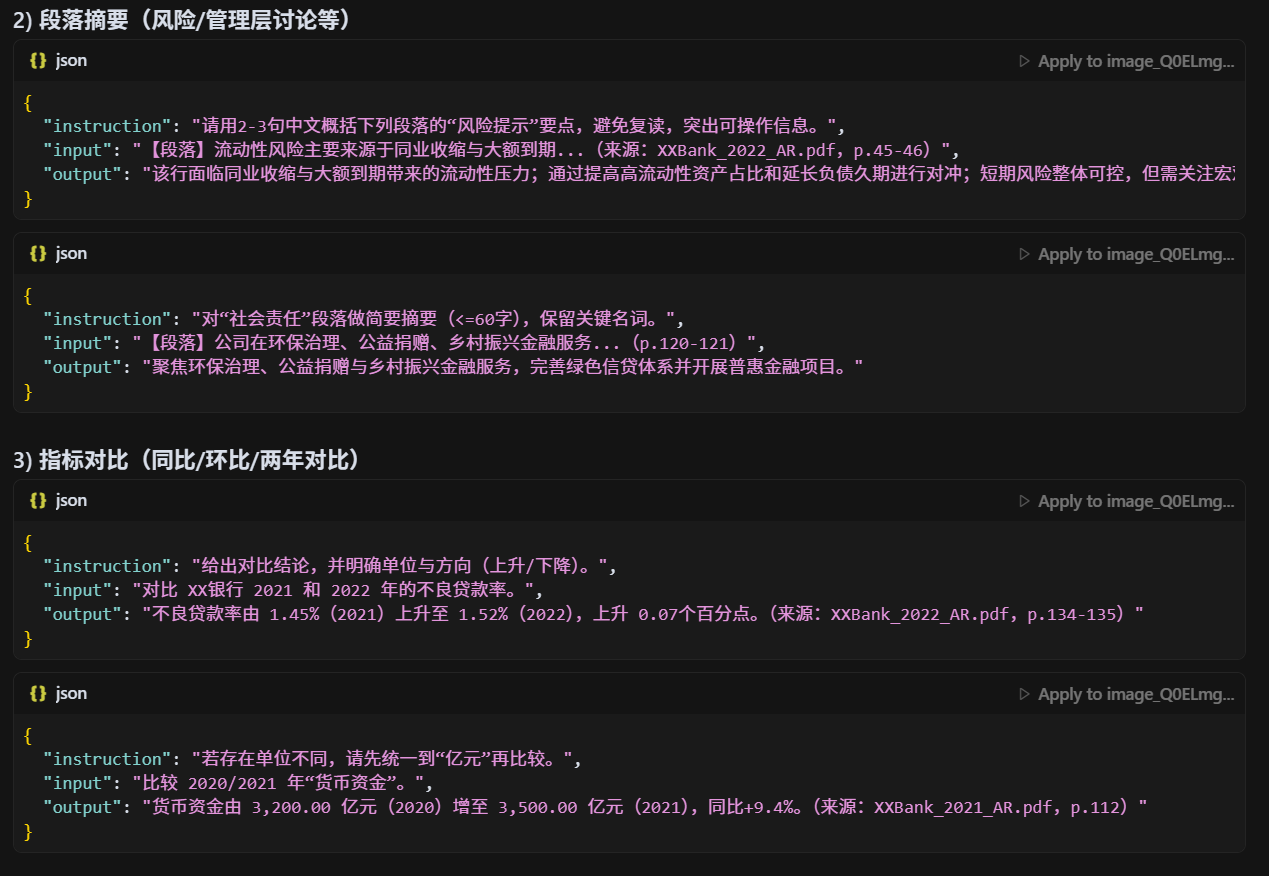
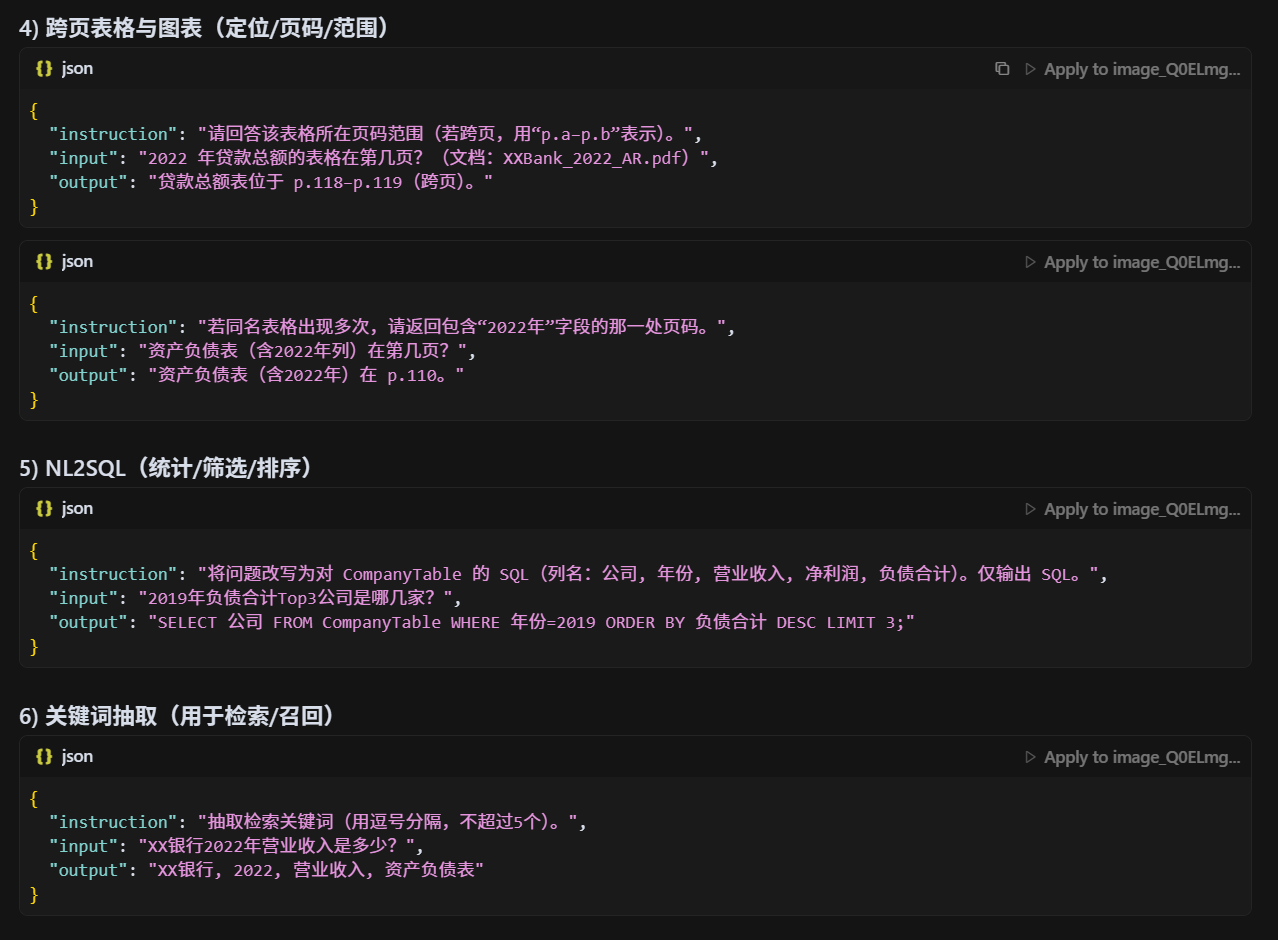
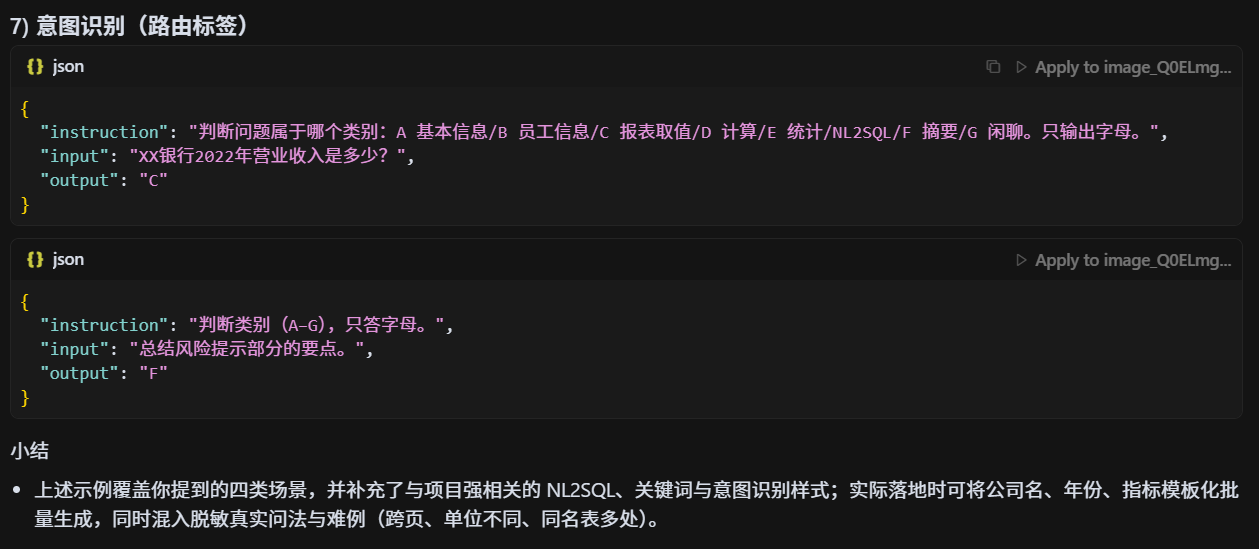
为什么你们要构造 6000 条高质量 SFT 数据?
-
补足不足:原始金融 PDF 解析语料稀缺,直接用开源语料训练无法覆盖金融报表问答需求。
-
对齐任务目标:SFT(Supervised Fine-Tuning)数据使模型学会"如何回答",确保生成结果贴合问答场景。
-
质量优先:高质量人工构造的数据能显著提升模型在长尾问题上的表现,而不是盲目堆砌低质样本。
-
规模适配:6000 条数据在成本与效果之间平衡,足以支撑 7B 级模型的指令对齐。不懂

微调 Qwen2-7B 的目的是什么?
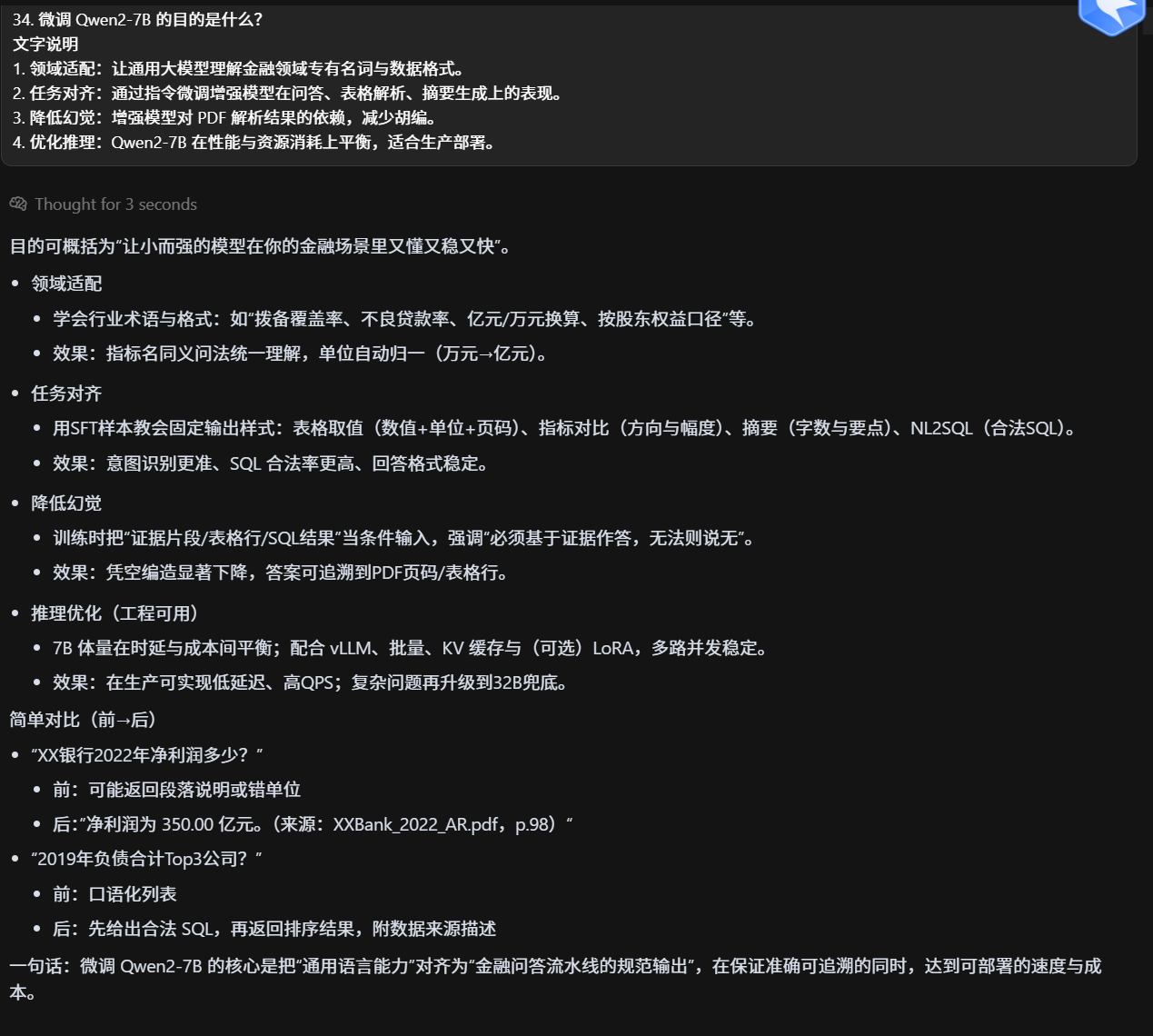
意图识别咋做的?作用?为撒?
一句话
用小模型(Qwen2-7B/ChatGLM2-6B)做轻量分类头,经由 P-tuning/LoRA 微调,在统一模板里判定意图(A/B/C/D/开放问答等),并输出置信度用于分层路由。
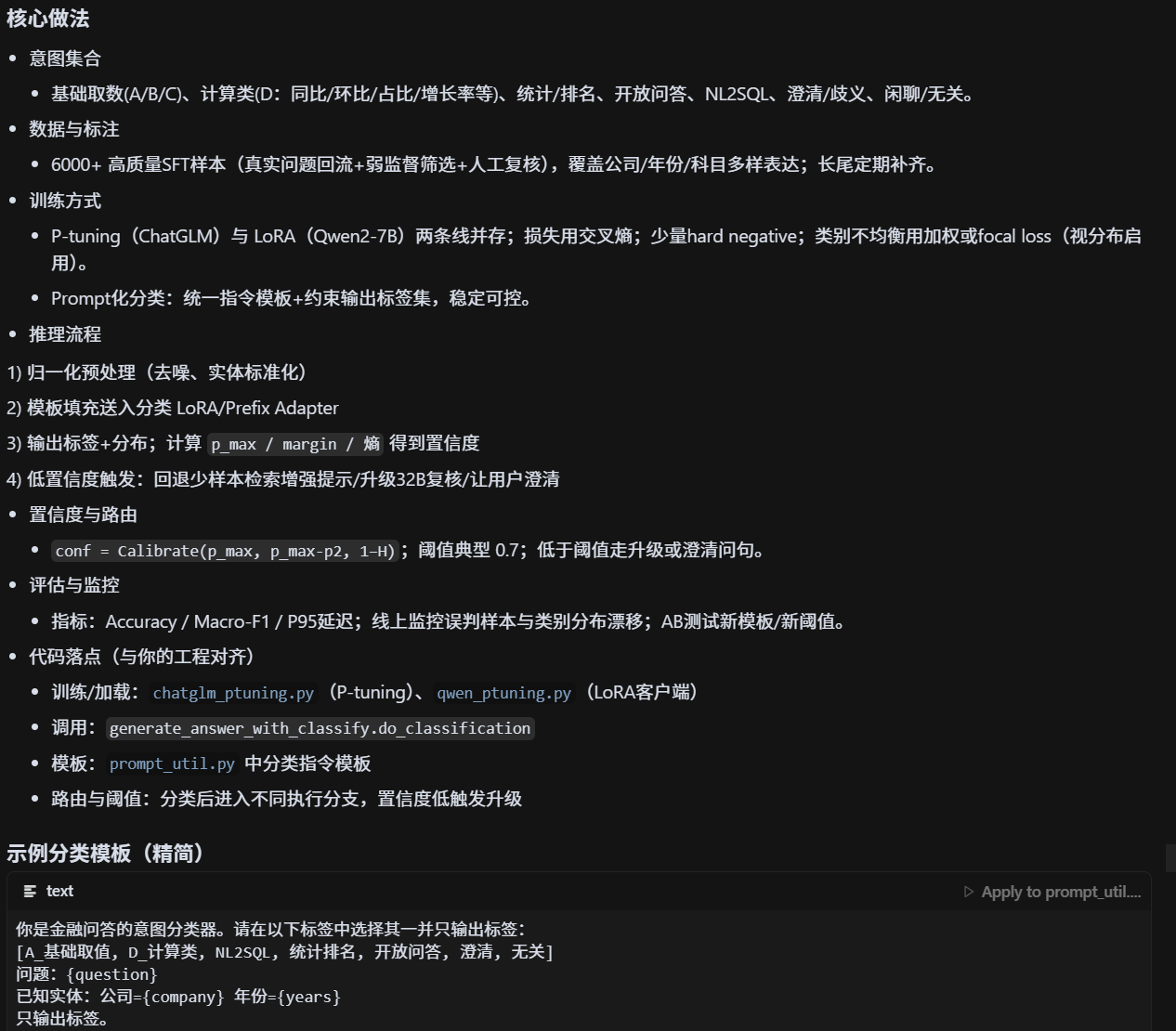

用户 query 的意图识别准确率为什么能达到 94%?

NL2SQL哪来的?为什么要做?

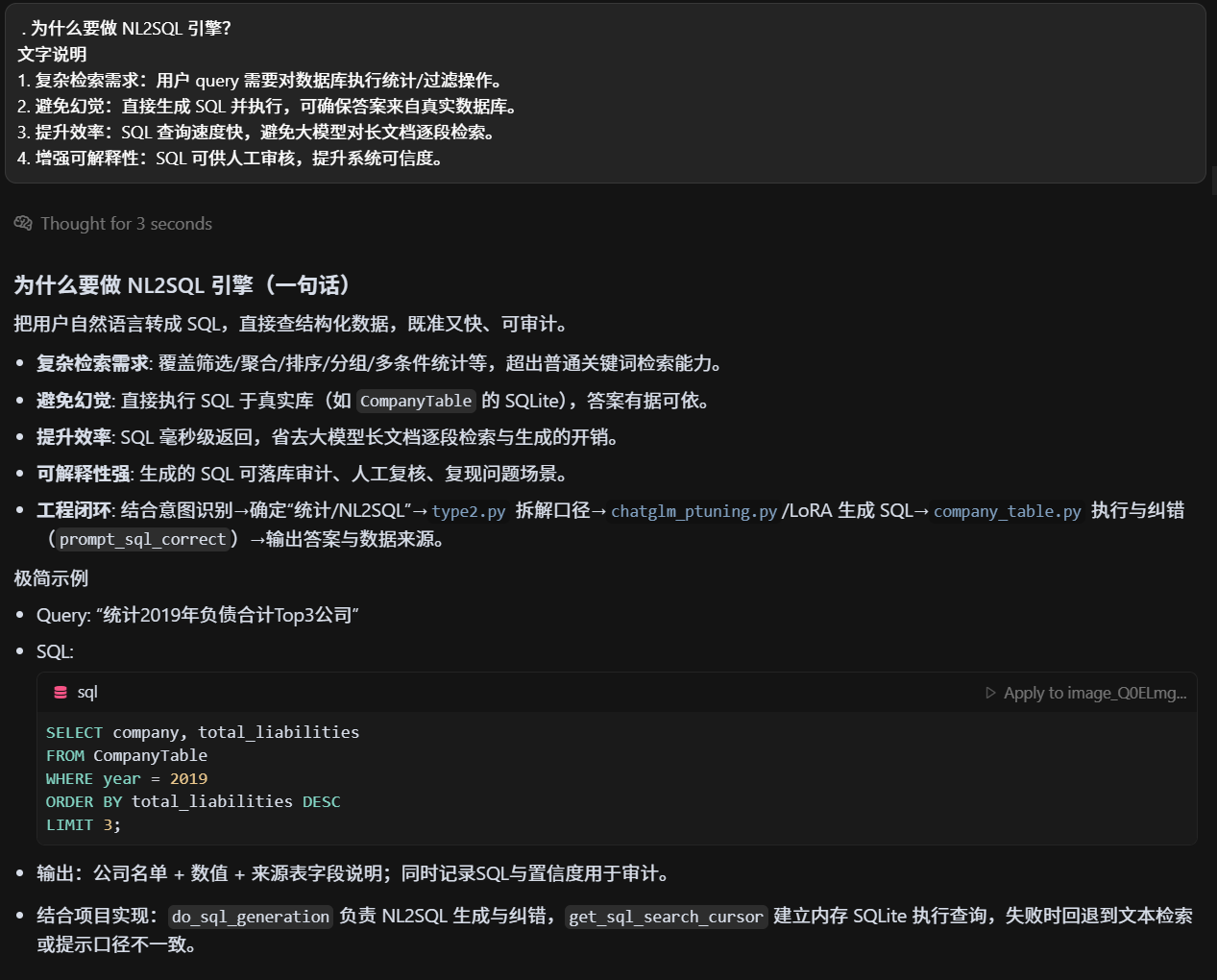
精准非精准目的
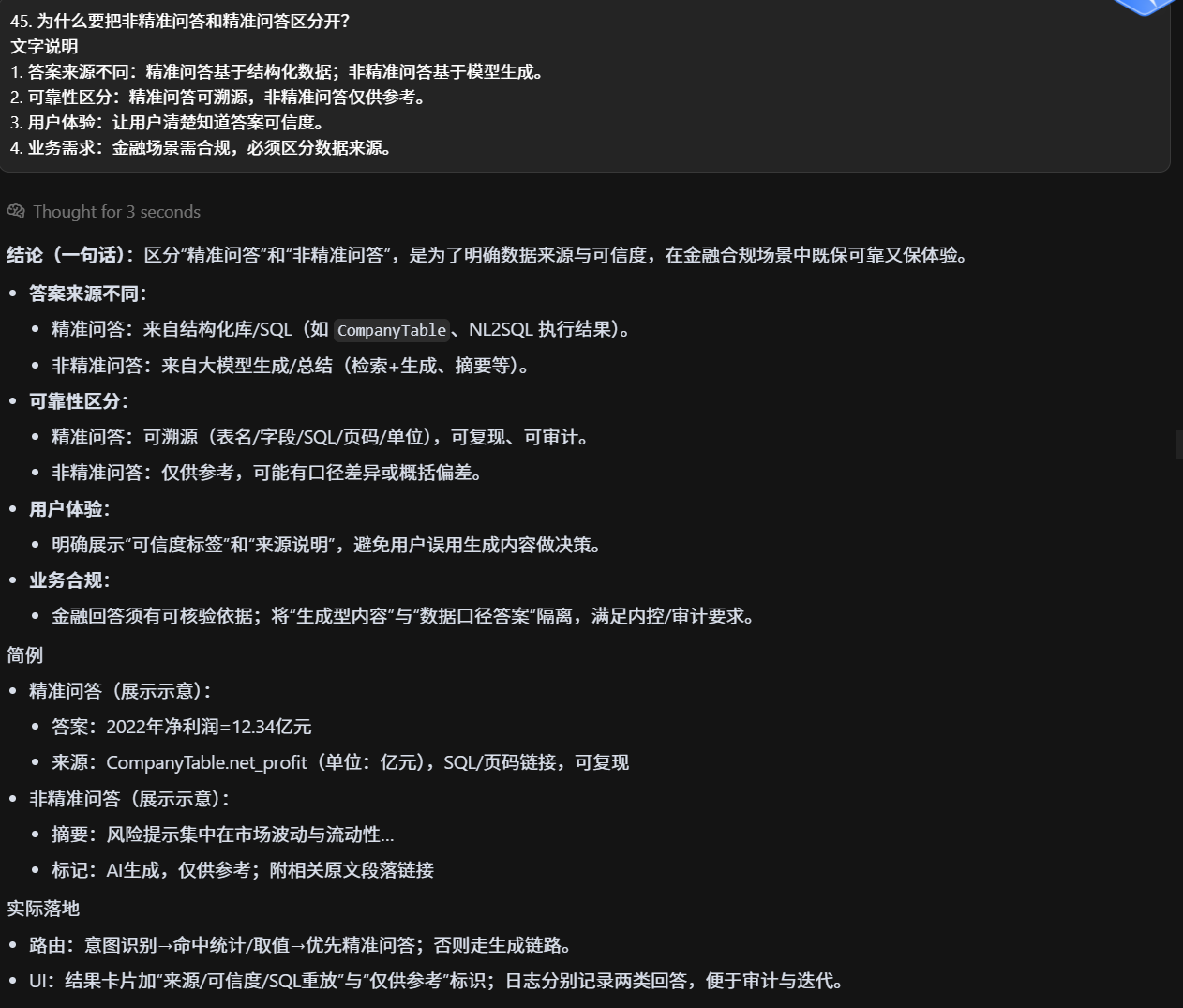
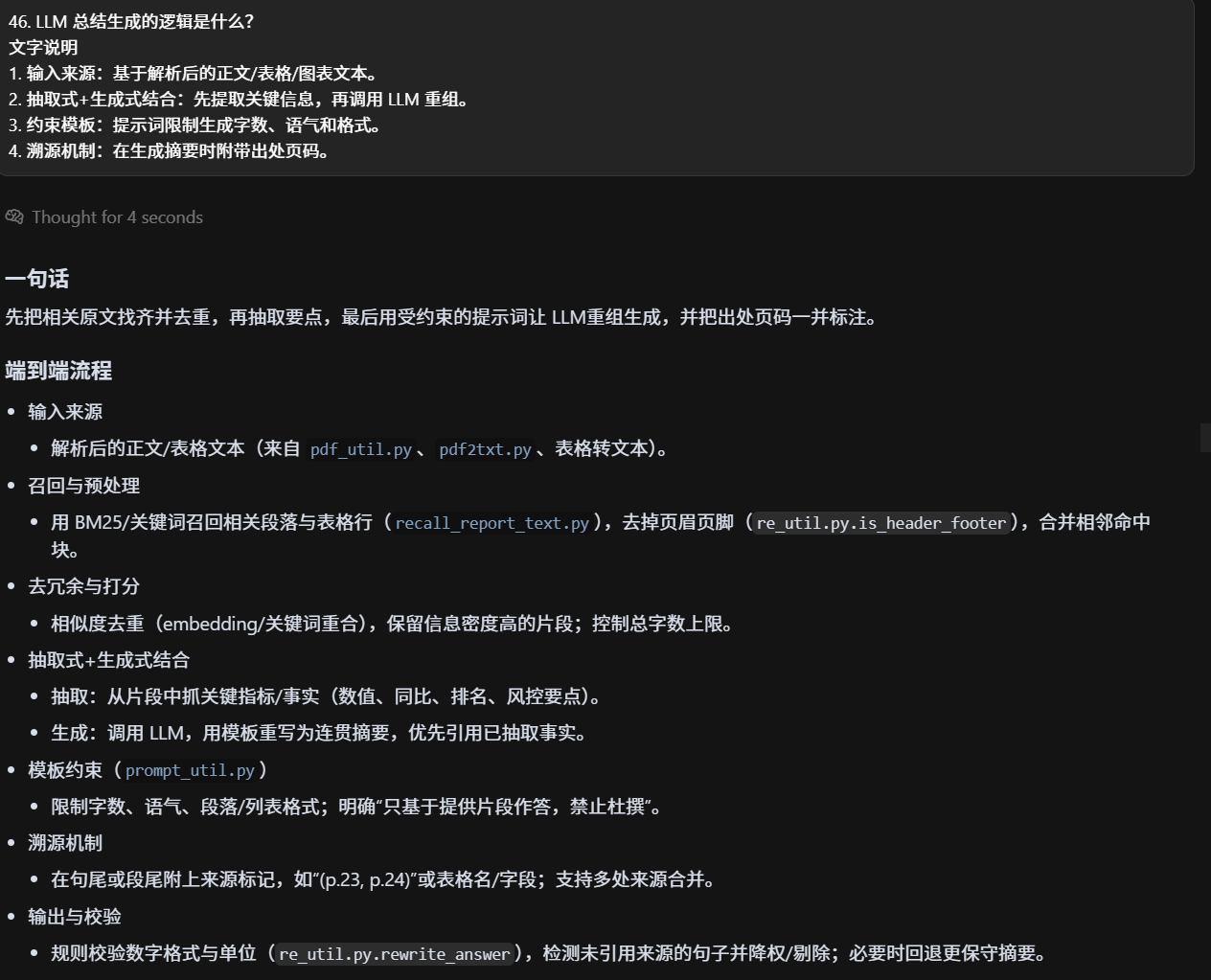
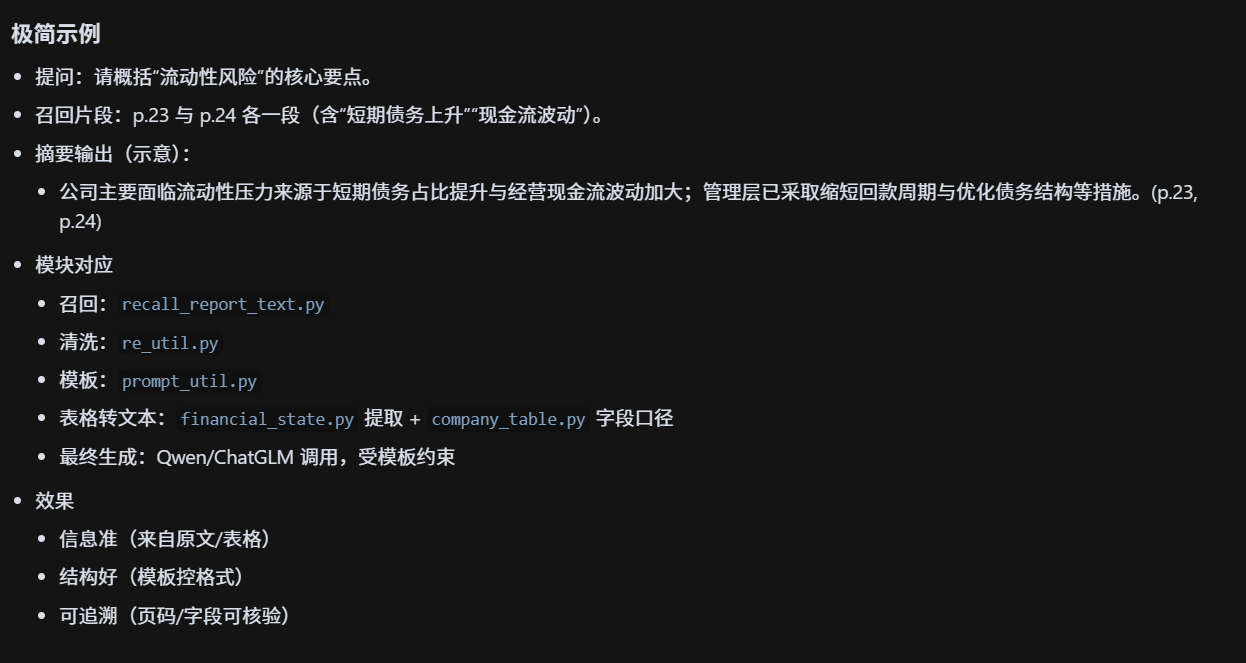
非精准llm总结逻辑
系统架构设计的时候考虑过哪些备选方案?
- 单体服务(Monolith):将解析、存储、检索、问答全部堆叠在一个进程里,开发上线成本最低,配置与调试最直观。缺点是模块耦合严重,任何一处改动都可能触发全量回归,且无法针对不同负载进行弹性扩缩,难以满足高并发和异构算力的调度需求。
- 粗粒度微服务:按"解析层 / 存储层 / 理解层 / 交互层"拆为 3--4 个服务,服务边界清晰、接口数量可控,利于独立扩容与版本治理。适合团队规模中等的场景,既避免了过细粒度的治理成本,又保持了良好的演进空间。
- 细粒度微服务/事件驱动:进一步把 OCR、表格解析、意图识别、NL2SQL、LLM 生成拆成独立服务,通过消息总线(Kafka)串联,具备极强的弹性与容错。代价是观测与排错复杂度提升,需要完备的链路追踪、重试与幂等设计。
- 无服务器/函数编排:解析与推理以 FaaS 形态按需触发,结合对象存储和工作流编排(如 Step Functions/Argo)。好处是按量计费、天然扩缩,局限在于冷启动、镜像体积与本地文件系统依赖(如 xpdf、tesseract)带来的性能波动与运维限制。

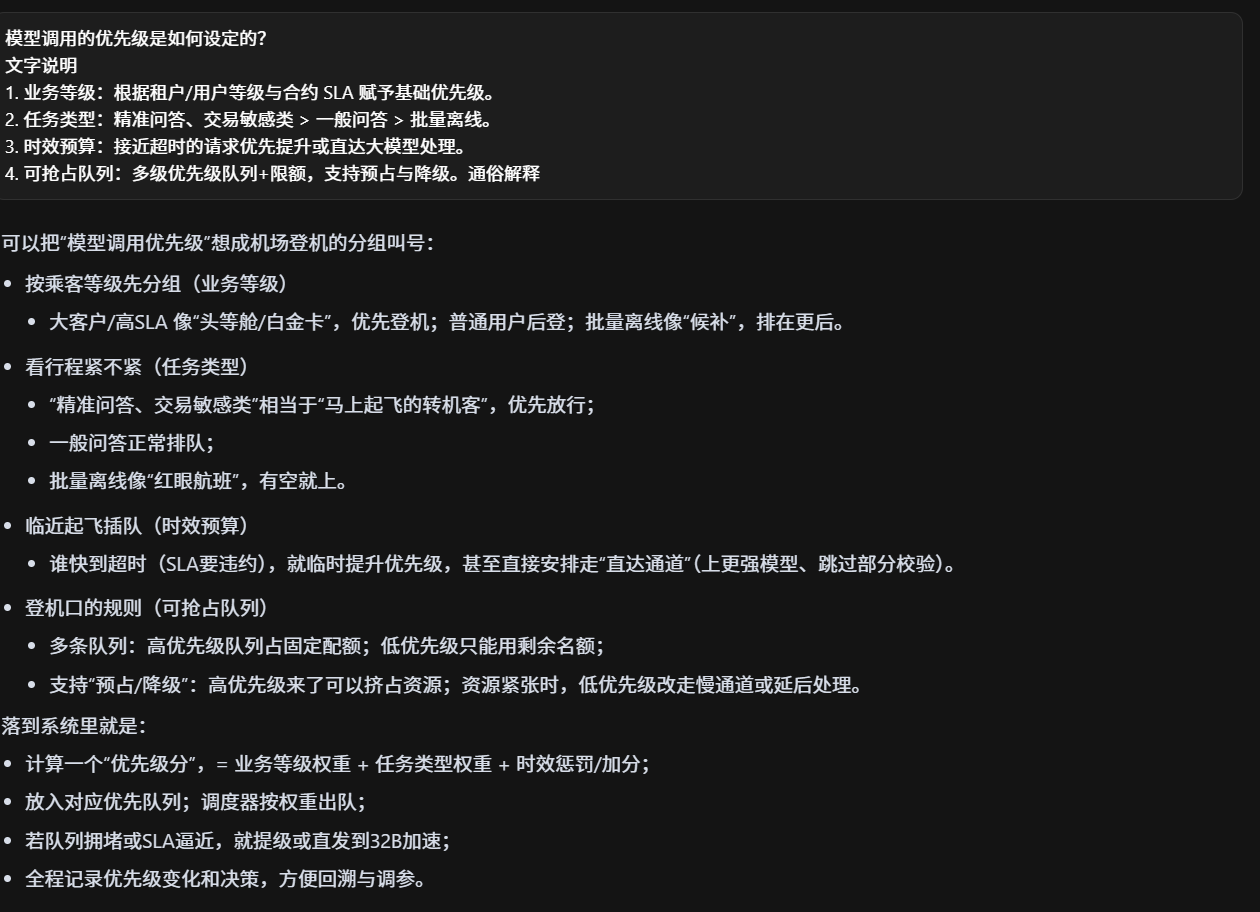
多模型协调咋做的?日志咋记录的?优先级问题?


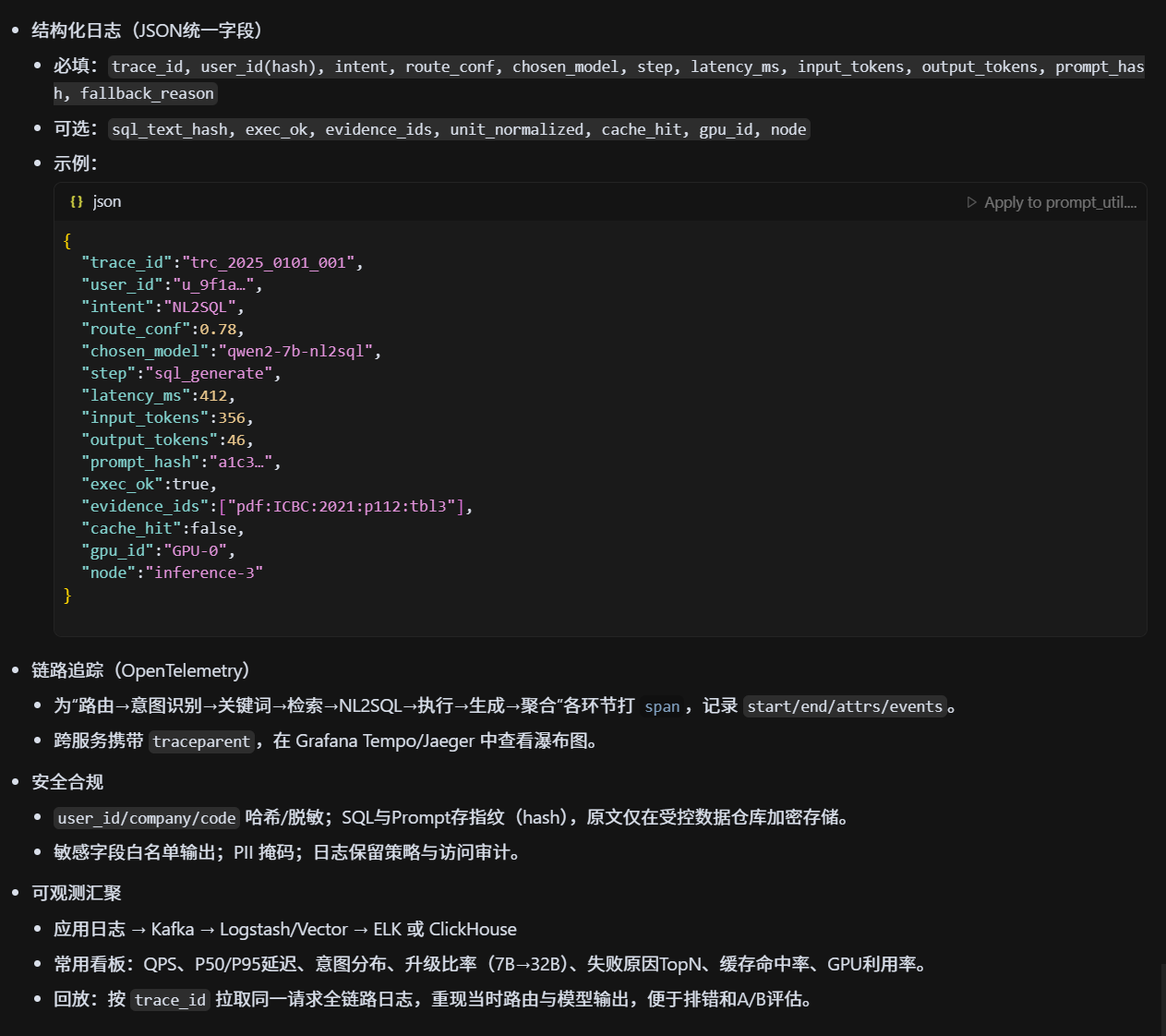
多模型协同时的日志是怎么记录的?
- 结构化日志:统一 JSON 字段:trace_id、user_id、intent、chosen_model、latency、tokens、prompt_hash、conf、fallback_reason。
- 链路追踪:OpenTelemetry 贯穿路由→模型→数据库,保留 span 与事件。
- 安全合规:敏感字段脱敏/哈希,Prompt/答案做指纹存储避免泄漏。
- 可观测汇聚:日志→Kafka→ELK/ClickHouse,支持检索、聚合与回放。
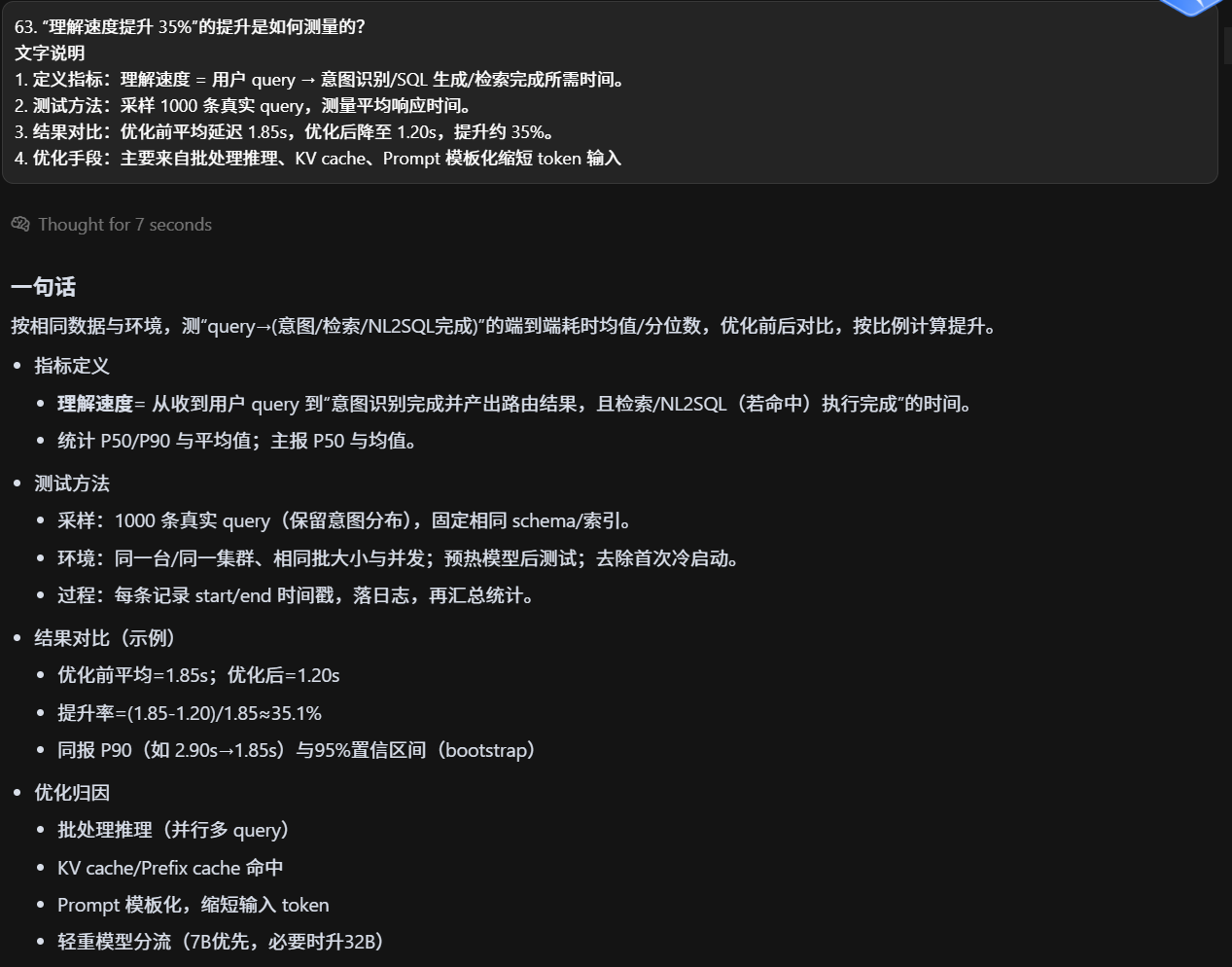
"理解速度提升 35%"的提升是如何测量的?
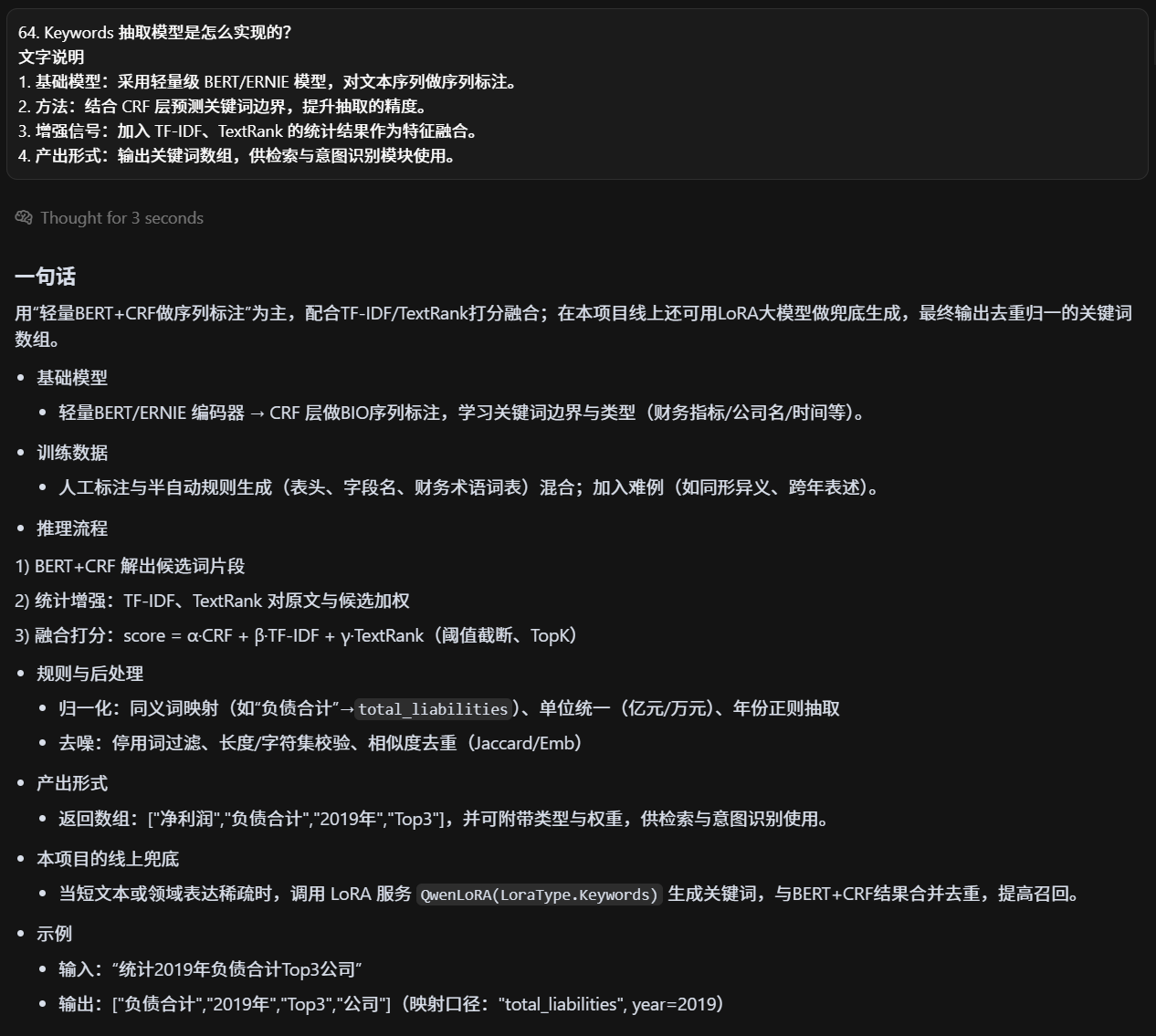
Keywords 抽取模型是怎么实现的?


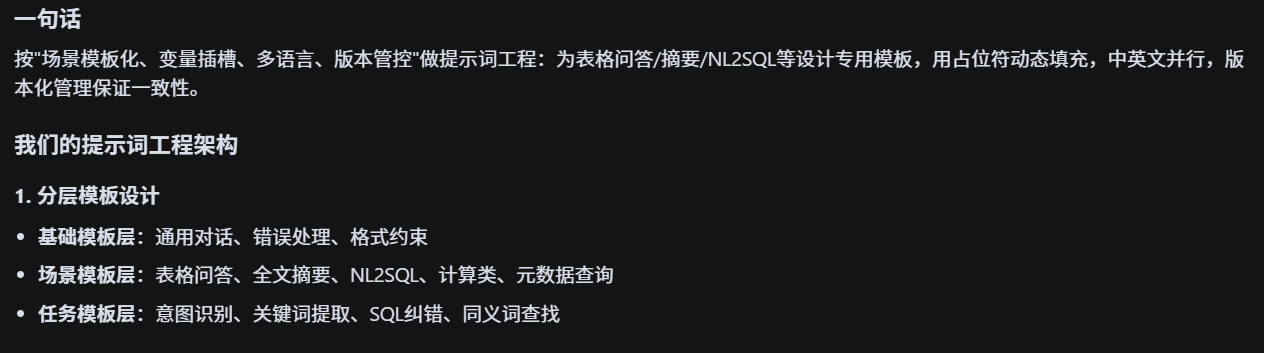
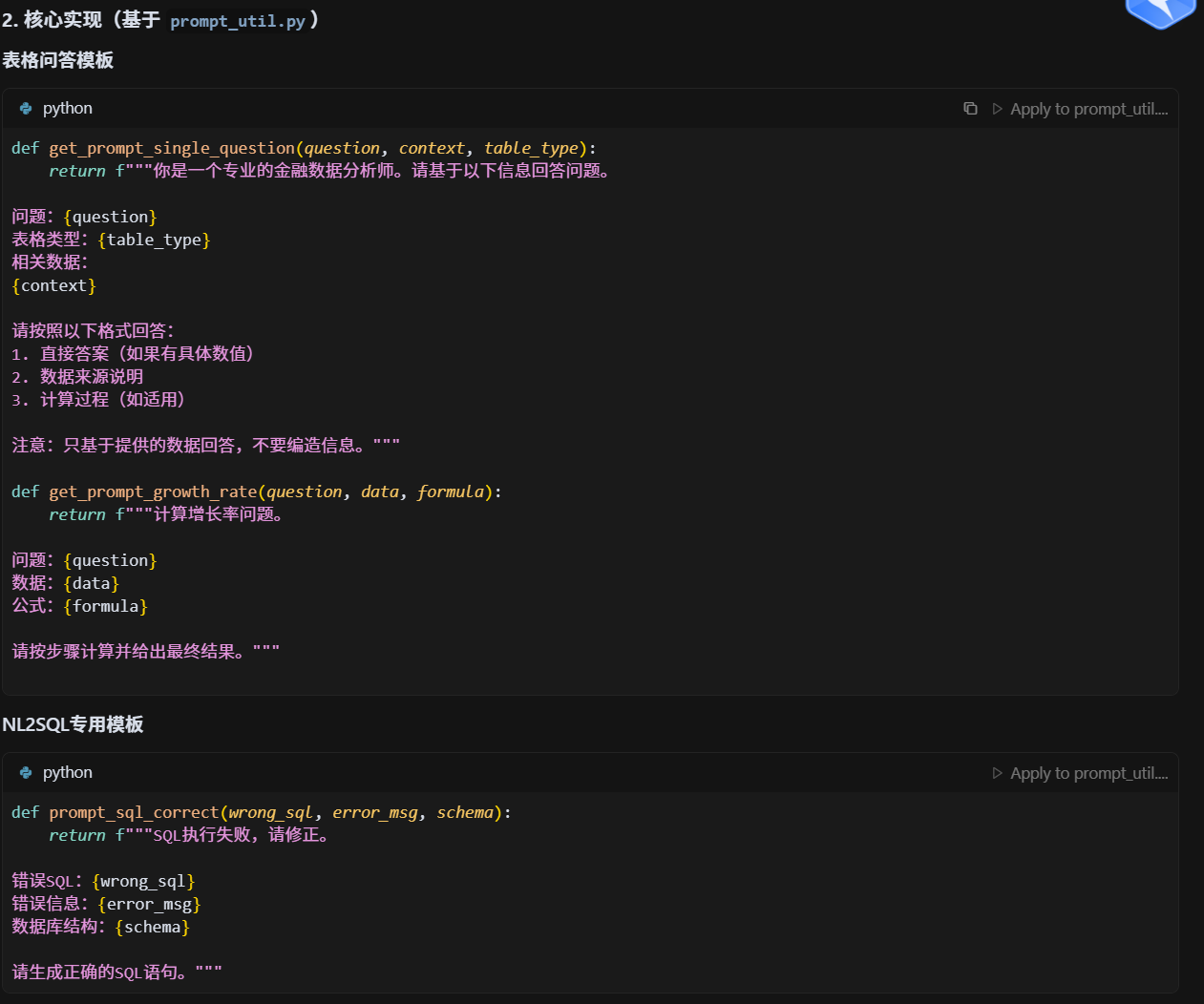
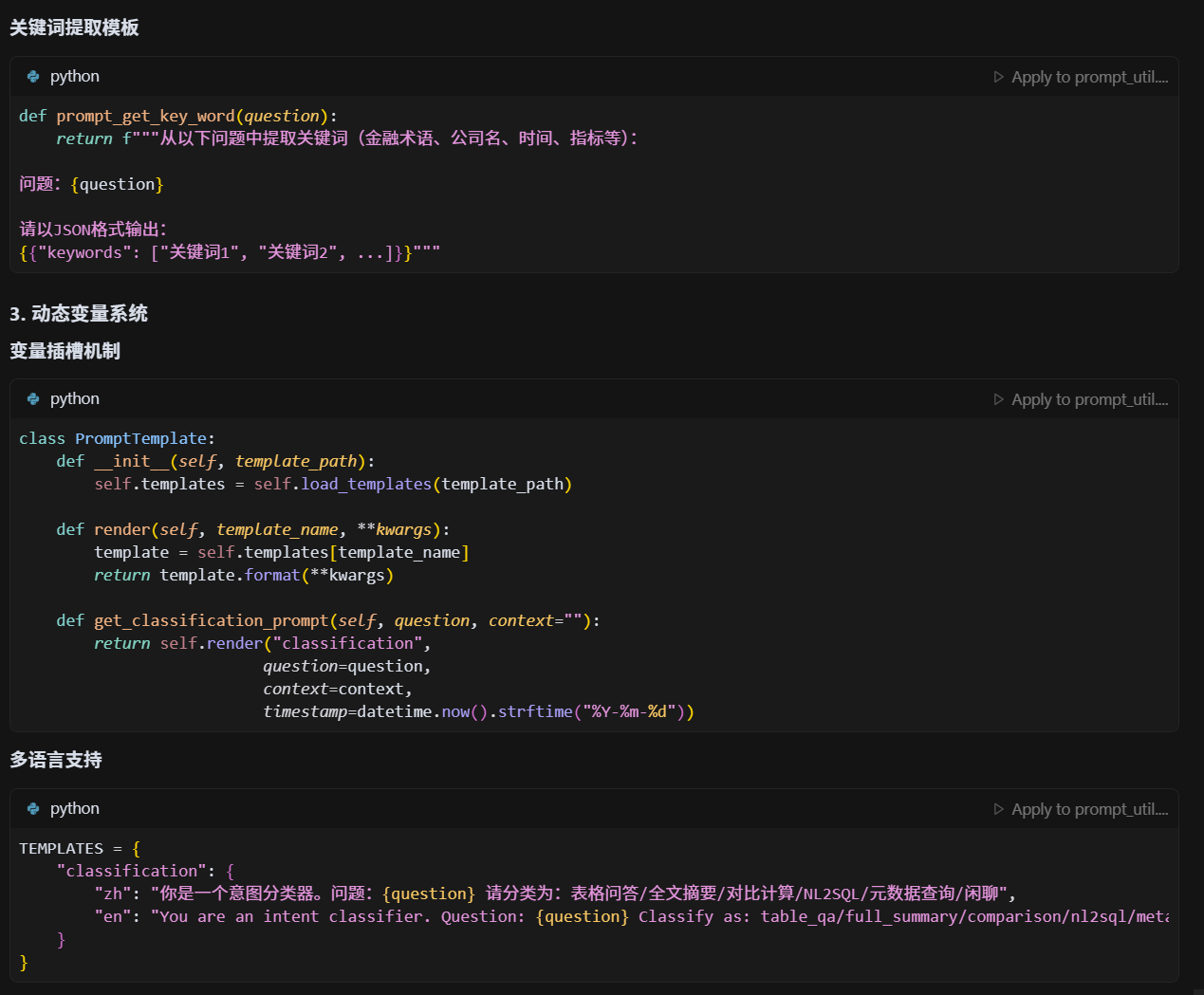
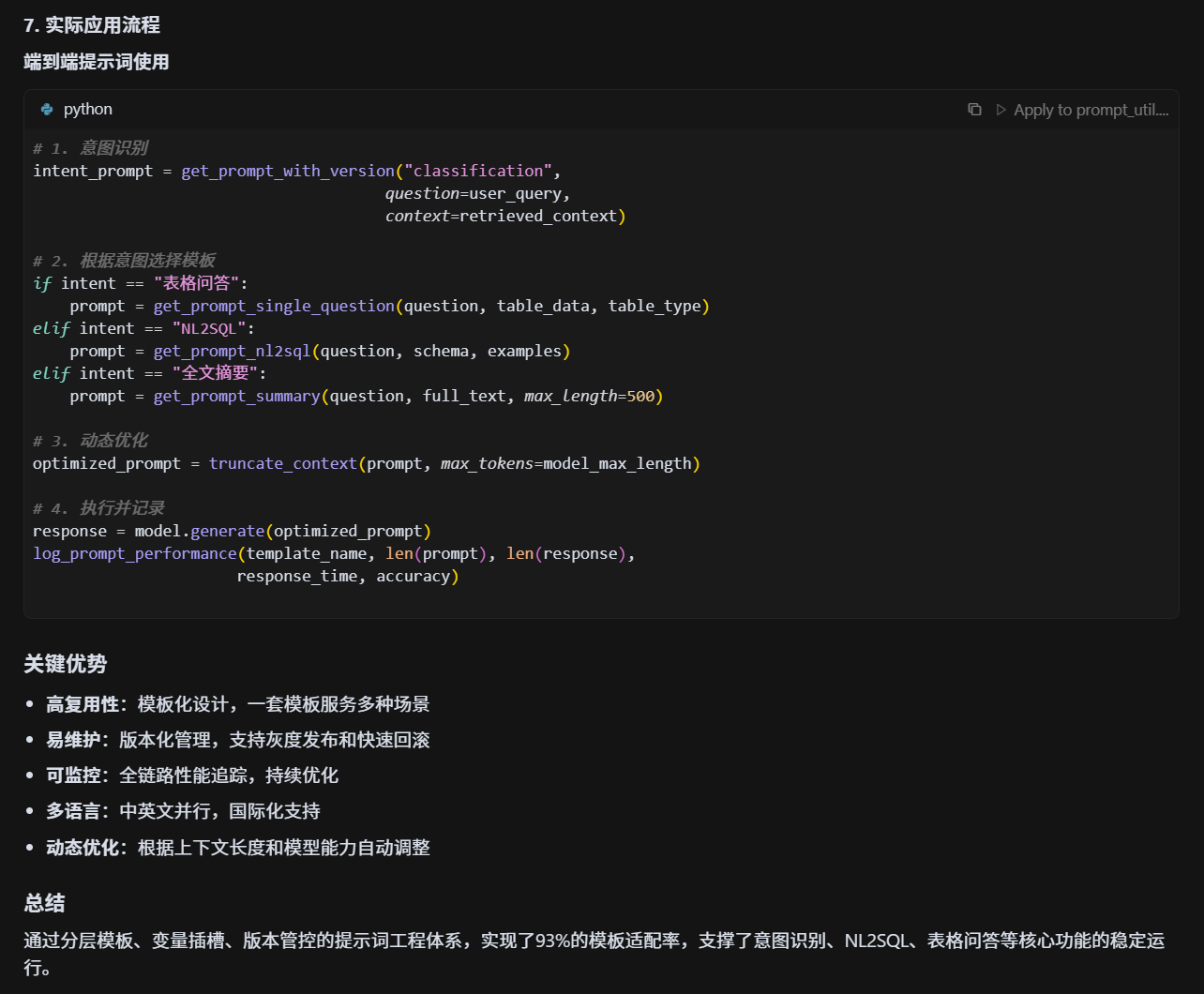
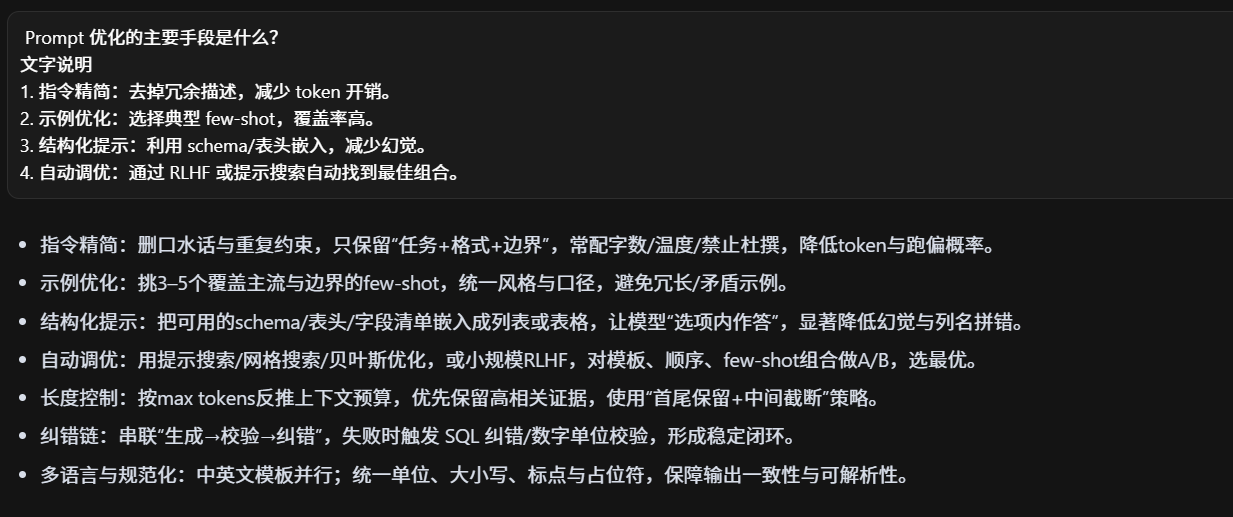
prompt咋做的?模板适配率?咋优化的

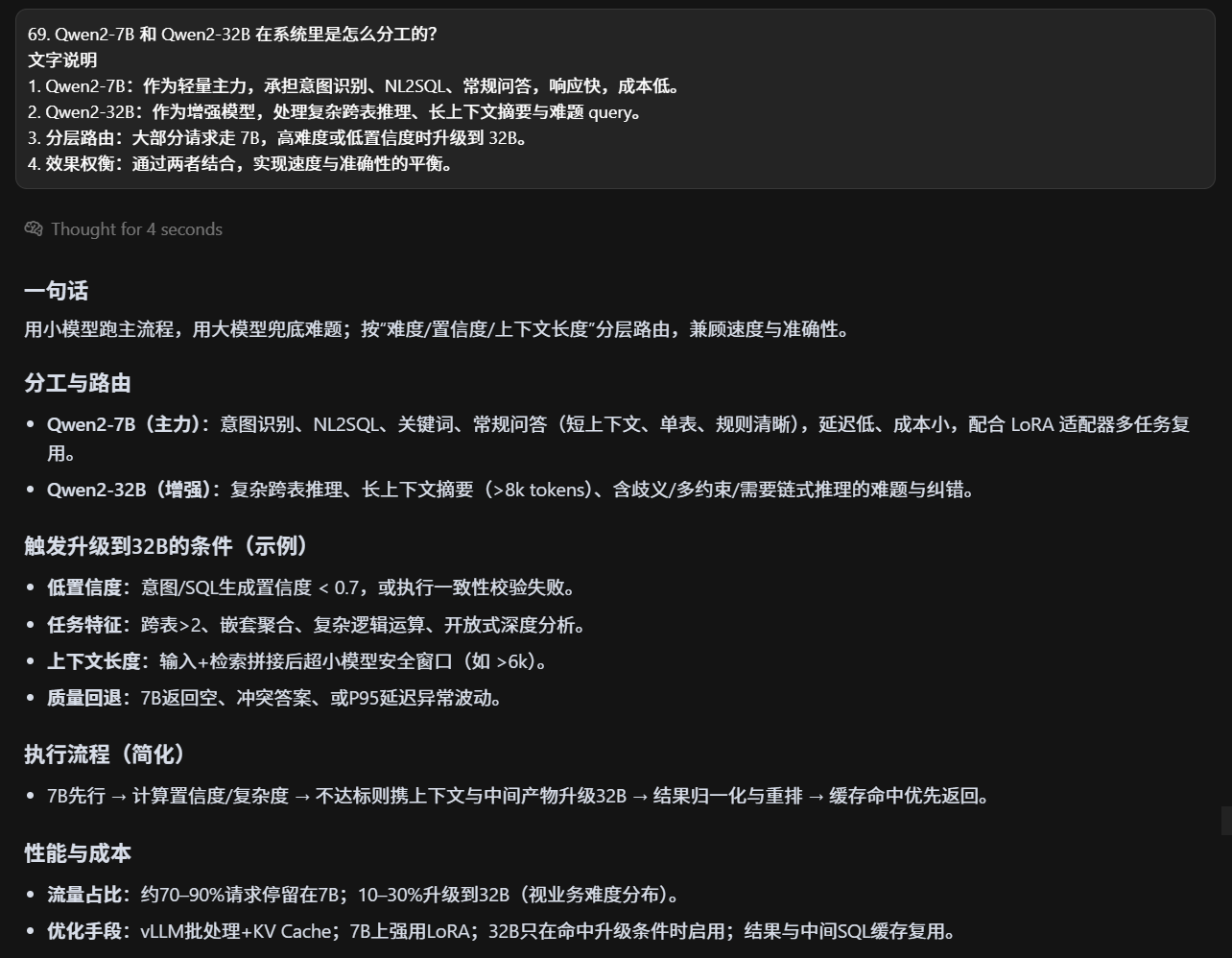
qianwen7和前文32什么情况
docker?兼容问题?

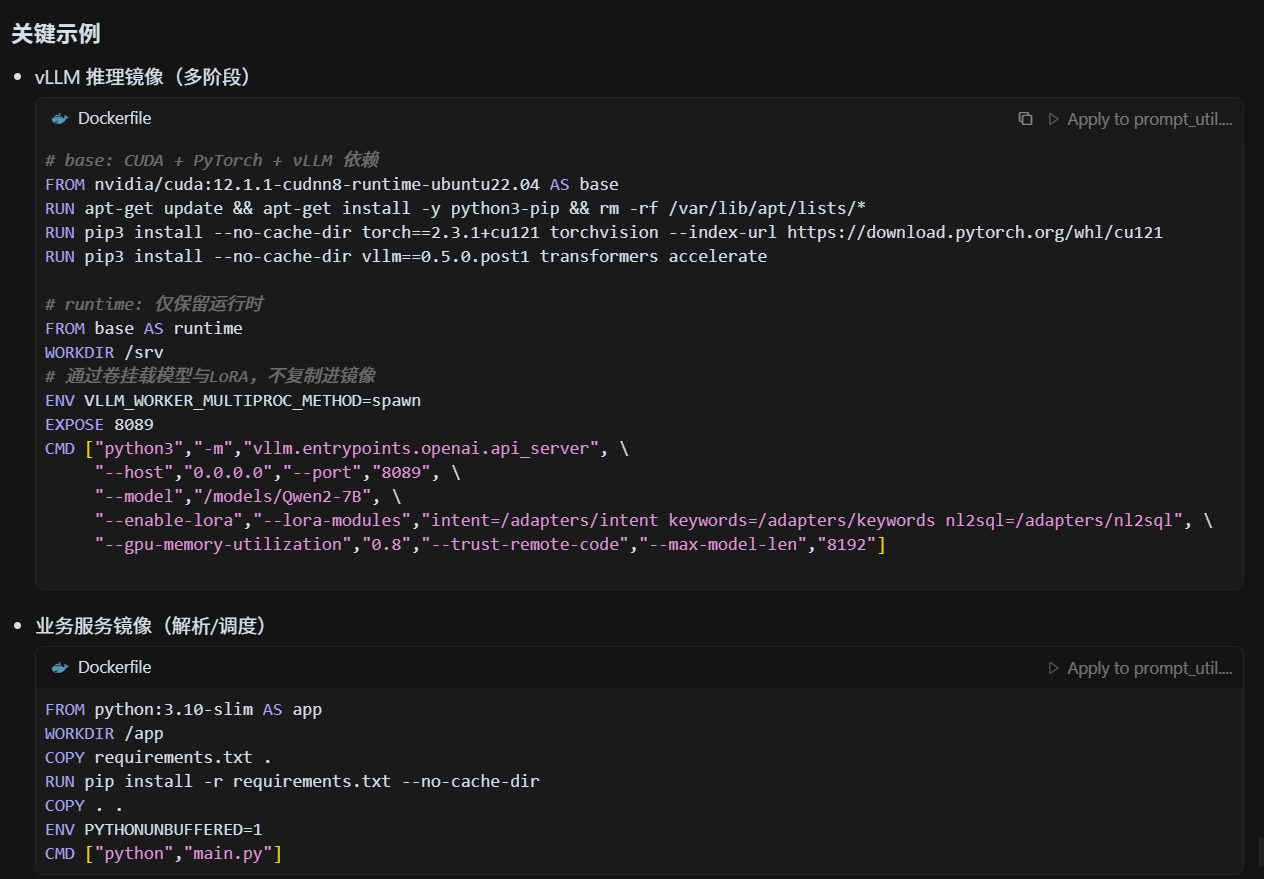

容器化过程中有没有遇到依赖冲突?
- Python 依赖冲突:OCR、PDF 解析和 NLP 库之间存在版本不兼容。
- CUDA 与驱动:宿主机驱动版本和容器内 CUDA 版本不匹配导致推理失败。
- 解决办法:采用多阶段构建,固定依赖版本号,并用 conda/venv 做隔离。
- 经验:建议使用官方 CUDA 镜像和 nvidia-docker 插件,降低兼容问题。