该数据集是Kaggle平台上的IMDb Top 950 Movies Dataset (2025) 数据集,虽未提供完整字段详情,但核心是收录了IMDb平台排名前950部电影的相关数据,可用于电影行业趋势分析、观众偏好挖掘、电影评分/票房预测等数据科学任务,为电影领域的机器学习、数据可视化项目提供基础数据支持,数据集创作者为vedikagupta0。
我分享了「IMDb 前950电影数据集(2025)」:https://pan.quark.cn/s/70d047516aa8
源地址:https://www.kaggle.com/datasets/vedikagupta0/imdb-top-950-movies-dataset-2025
2. 思维导图(mindmap)
3. 详细总结
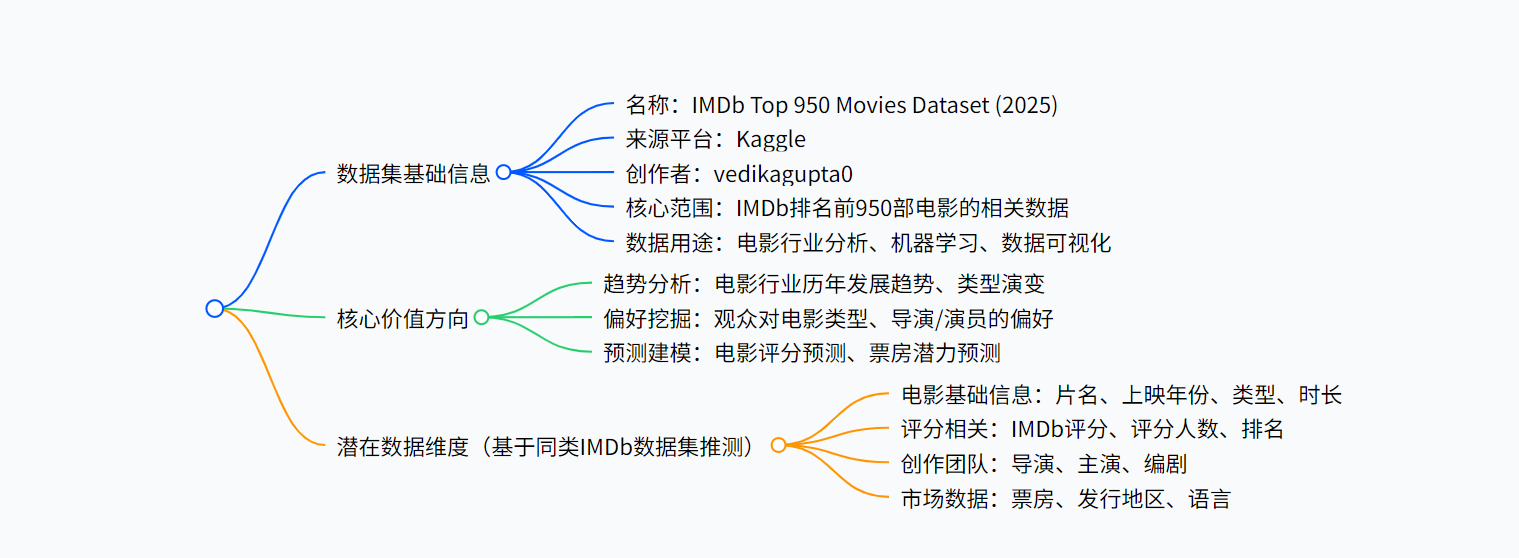
一、数据集核心基础信息
| 信息类别 | 具体内容 | 说明 |
|---|---|---|
| 数据集名称 | IMDb Top 950 Movies Dataset (2025) | 名称直接体现数据集核心范围:IMDb平台排名前950的电影,数据时间维度标注为2025年 |
| 发布平台 | Kaggle | 全球知名的数据科学与机器学习平台,数据集可被开发者、研究者自由获取用于项目开发 |
| 创作者 | vedikagupta0 | Kaggle用户ID,为数据集的归属主体,可通过该ID查看创作者的其他相关数据集 |
| 核心规模 | 涵盖950部电影 | 聚焦IMDb排名靠前的电影,筛选标准以IMDb平台的评分、热度等核心指标为依据,确保数据的代表性 |
| 数据用途 | 电影行业分析、机器学习建模、数据可视化 | 未明确标注具体字段,但结合"IMDb Top电影"的属性,可推断支持多类数据任务 |
二、数据集潜在数据维度(基于同类IMDb电影数据集推测)
由于网页未提供完整字段详情,参考IMDb同类电影数据集的常见维度,该数据集可能包含以下核心信息(需以实际下载数据为准):
| 数据类别 | 潜在字段 | 字段说明 | 示例 |
|---|---|---|---|
| 电影基础属性 | movie_title |
电影官方名称 | 《The Shawshank Redemption》《Inception》 |
release_year |
电影上映年份 | 1994、2010 | |
genre |
电影类型(可多分类) | Drama(剧情)、Sci-Fi(科幻)、Action(动作) | |
duration |
电影时长(单位:分钟) | 142、148 | |
| IMDb核心评分信息 | imdb_rating |
IMDb平台的用户评分(满分10分) | 9.3、8.8 |
votes |
参与评分的用户数量 | 270万+、180万+ | |
imdb_rank |
电影在IMDb的排名 | 1、10 | |
| 创作与制作信息 | director |
电影导演 | Frank Darabont、Christopher Nolan |
cast |
主要演员(主演列表) | Tim Robbins、Leonardo DiCaprio | |
writer |
编剧 | Stephen King、Jonathan Nolan | |
| 市场与发行信息 | box_office |
电影全球票房 | 2.83亿美元、8.25亿美元 |
country |
主要发行国家/地区 | USA(美国)、UK(英国) | |
language |
电影主要语言 | English(英语)、Spanish(西班牙语) |
三、数据集的核心应用场景
- 电影行业趋势分析
基于电影的上映年份、类型、票房等数据,分析近数十年电影行业的类型演变(如科幻片占比变化)、票房增长趋势、地区创作活跃度差异等,为行业报告提供数据支撑。 - 观众偏好挖掘
通过关联"电影类型-评分""导演/演员-票房"等数据,挖掘观众对特定类型、创作团队的偏好程度(如是否更青睐某导演的作品、某类型电影的平均评分是否更高)。 - 机器学习建模任务
可作为回归任务(如基于电影类型、时长、演员阵容预测IMDb评分)或分类任务(如根据电影属性分类"高票房/低票房"电影)的基础数据集,也可用于聚类分析(如将电影按"评分-票房"特征分组)。 - 数据可视化展示
通过柱状图、热力图、词云等可视化方式,直观呈现"Top 950电影的类型分布""历年评分变化趋势""高评分演员的作品数量"等信息,提升数据解读效率。