学习目标
java
- 能够说出XML的作用
//存储数据(解析读取使用)
//配置文件(c3p0连接池,框架)==>存储一些数据
- 了解XML的组成元素(重点)
文档声明 <?xml version="1.0" encoding="UTF-8"?>
元素<beans>元素体</beans> <b><a>你好</a></b> <a/> <a></a>
属性<bean id='aa011' className="zhangsan" ></bean>
注释:解释说明xml文档,给程序员看的,不会被解析器解析(读取) <!-- -->
转义字符:xml文档中已经占用了一些字符(<,>,",',&),这些字符都有特殊的含义
而我们要使用这些字符,就可以使用转义字符代表这些字符
< <
> >
" "
' '
& &
CDATA区域:里边写的所有的内容,都作为普通的文本
<![CDATA[
...
]]>
- 能够说出有哪些XML约束技术(重点)
dtd约束
schema约束
会使用<根据提示写出元素和属性
- 能够说出解析XML文档DOM方式原理
使用SAXReader对象中的方法read,加载xml到内存中,生成Document对象(dom树)
使用Document对象获取根元素
使用根元素获取子元素,一层一层获取
使用元素Element的方法获取属性和文本
- 能够使用dom4j解析XML文档(重点)
见案例
- 能够使用xpath解析XML文档
使用前提:基于dom4j
先获取SAXReader对象
使用SAXReader对象中的方法read,加载xml到内存中,生成Document对象
Document对象中方法:xpath解析
List<Element> selectNodes("xpath表达式"),用来获取多个节点
Node selectSingleNode("xpath表达式"),用来获取一个节点一.XML
1.XML介绍
1.1什么是XML
-
XML 指可扩展标记语言(EXtensible Markup Language)
- 标记:也叫标签,有固定 的使用格式
<开始标签>标签体</结束标签>
- 可扩展:标签的名称自己定义,随意
<person>aaa</person><sdafdsafdsa>wwww</sdafdsafdsa>
- 标记:也叫标签,有固定 的使用格式
-
XML 是 W3C (万维网联盟)的推荐标准
W3C在1988年2月发布1.0版本,2004年2月又发布1.1版本,单因为1.1版本不能向下兼容1.0版本,所以1.1没有人用。同时,在2004年2月W3C又发布了1.0版本的第三版。我们要学习的还是1.0版本。
1.2 XML 与 HTML 的主要差异
- XML:
- 作用:存储数据,会获取出xml中存储的数据使用
- 可扩展的,标签的名称可以自定义
- HTML:
- 作用:展示数据,给别人看的(页面)
- 标签的名称都是固定的
2.XML的组成元素
XML文件中常见的组成元素有:文档声明、元素、属性、注释、转义字符、字符区。
Xml文件扩展名必须为.xml
3.XML语法(重点)
1).文档声明
xml
<?xml version="1.0" encoding="UTF-8" ?>- 使用IDE创建xml文件时就带有文档声明.
- 文档声明必须为<?xml开头,以?>结束
- 文档声明必须从文档的0行0列位置开始
- 文档声明中常见的两个属性:
- version:指定XML文档版本。必须属性,这里一般选择1.0;
- enconding:指定当前文档的编码,可选属性,默认值是utf-8;
2.元素element
注意:元素就是标签
xml
格式1:<Person>aaaa</Person>
格式2:<person/> 空元素 自闭和标签- 元素是XML文档中最重要的组成部分;
- 普通元素的结构由开始标签、元素体、结束标签组成。
- 元素体:元素体可以是元素,也可以是文本,例如:
<person><name>张三</name></person> - 空元素:空元素只有开始标签,而没有结束标签,但元素必须自己闭合,例如:
<sex/> - 元素命名
- 区分大小写
- 不能使用空格,不能使用冒号
- 不建议以XML、xml、Xml开头
- 不能以数字开头
- 格式化良好的XML文档,有且仅有一个根元素。
练习:
demo01.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<人>男人,女人,人妖</人>
<!--<动物></动物> 格式化良好的xml文件,只能有一个根元素(写在最外层的元素)-->demo02.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<人>
<男人>做男人真难</男人>
<女人>做女人更难</女人>
<人妖/>
</人>demo03.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean>
<property>张三</property>
<property>李四</property>
</bean>
<bean>
<property>王五</property>
<property>赵六</property>
</bean>
</beans>3).属性attribute
xml
<person></person>
<person name="aaa" id="110" age='18'></person>
<person id="110"></person>- 属性是元素的一部分,它必须出现在元素的开始标签中
- 属性的定义格式:属性名="属性值",其中属性值必须使用单引或双引号括起来
- 一个元素可以有0~N个属性,但一个元素中不能出现同名属性
- 属性名不能使用空格 , 不要使用冒号等特殊字符,且必须以字母开头
- 属性不区分先后顺序,写在前边和写在后边的作用是一样的
练习:
xml
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>
<bean>
<property name="刘德华" >王五</property>
<property name="张学友">赵六</property>
</bean>
<bean name="张学友"/>
</beans>4).注释
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
xml文件中的注释:
注释给程序员看的,写一些注释,对xml文件进行解释说明
注释的内容不会被xml解析器解析
添加|删除注释的快捷键:
ctrl+shift+/
-->
<!--哈哈-->
<!--beans是一个根元素,根元素只能有一个-->
<beans>
<!--<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>-->
<bean>
<property name="刘德华" >王五</property>
<property name="张学友">赵六</property>
</bean>
<bean name="张学友"/>
</beans>5).转义字符
a.java中的转义字符(了解)
java
package com.itheima.demo01;
import java.io.File;
/*
java中的转义字符(了解): \
作用:
1.可以把部分普通的字符转义为有特殊含义的字符
2.可以把有特殊含义的字符转义为普通的字符
*/
public class Demo01 {
public static void main(String[] args) {
//定义一个字符
char c = 't';
System.out.println(c);//t
//1.可以把部分普通的字符转义为有特殊含义的字符
System.out.println("你好t我好t大家好");
//使用转义字符\,把普通的t转义为有特殊含义的制表符 tab
System.out.println("你好\t我好\t大家好");
System.out.println("你好\t我好\t大家好");
System.out.println("你好\t我好\t大家好");
//2.可以把有特殊含义的字符转义为普通的字符
//使用转义字符,把有特殊含义的',转义为普通的'
char c2 = '\'';
System.out.println(c2);//'
//把有特殊含义的\使用转义字符转义为普通的\使用
File file = new File("c:\\a.txt");
}
}b.xml文件中的转义字符
XML中的转义字符与HTML一样。因为很多符号已经被文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符(也叫实体字符),例如:">"、"<"、"'"、"""、"&"。
| 字符 | 预定义的转义字符 | 说明 |
|---|---|---|
| < | < |
小于 |
| > | > |
大于 |
| " | " |
双引号 |
| ' | ' |
单引号 |
| & | & |
和号 |
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
转义字符:
在xml文件中有一些特殊的字符,他们具有特殊的含义,我们不能直接使用这些字符
要使用这些字符,需要使用转义字符代替这些有特殊含义的字符
需求:
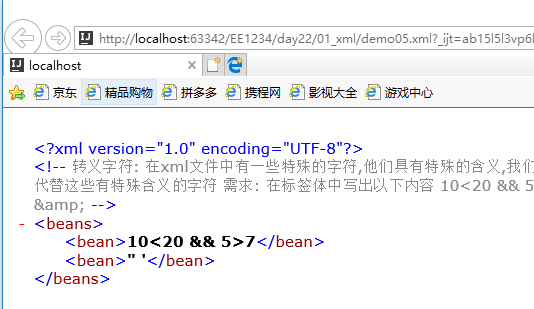
在标签体中写出以下内容
10<20 && 5>7
常用的转义字符
< <
> >
" "
' '
& &
-->
<beans>
<bean>10<20 && 5>7</bean>
<bean>" '</bean>
</beans>注意:xml文件可以使用浏览器打开
6).CDATA字符区(了解)
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
需求:把以下的内容以文本的形式展示出来,不是标签
<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>
解决:
可以使用转义字符,把有特殊含义的字符转义为普通的字符
大量的使用转义字符麻烦
使用CDATA区域来解决:
CDATA区域中写的任意的内容,都会以文本的形式解析
格式:
<![CDATA[
任意的内容,都是文本
]]>
什么时候使用CDATA区域:大量使用转义字符的使用
-->
<beans>
<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>
<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>
<![CDATA[
<bean className="com.itheima.demo01.Person">
<property name="jack" age='18'>张三</property>
<property age="18" name="rose" >李四</property>
</bean>
]]>
</beans>4.XML文件的约束
在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束。
常见的xml约束:DTD、Schema
学习约束文档的目的:根据约束文档写出xml文档
1).dtd约束文档
a.概述
DTD是文档类型定义(Document Type Definition)。
DTD约束的作用:约束xml文档中元素属性如何编写

b.基本使用(重点)
bean.dtd
dtd
<?xml version="1.0" encoding="UTF-8"?>
<!--
传智播客DTD教学实例文档。
模拟spring规范,如果开发人员需要在xml使用当前DTD约束,必须包括DOCTYPE。
格式如下:
<!DOCTYPE beans SYSTEM "bean.dtd">
-->
<!ELEMENT beans (bean*,import*) >
<!ELEMENT bean (property*)>
<!ELEMENT property (#PCDATA)>
<!ELEMENT import (#PCDATA)>
<!ATTLIST bean id CDATA #REQUIRED
className CDATA #REQUIRED
>
<!ATTLIST property name CDATA #REQUIRED
value CDATA #REQUIRED
>
<!ATTLIST import resource CDATA #REQUIRED>复制dtd约束文档到模块中,一般都和xml文档放在同一个文件夹下
demo01-dtd.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
dtd约束文档的使用步骤:
1.目前在每个dtd约束文档中都有一个以<!DOCTYPE开头的代码,复制到xml文档中
<!DOCTYPE beans SYSTEM "bean.dtd">
a.<!DOCTYPE:是dtd约束文档的固定声明格式
b.beans:dtd约束文档,约束在xml文档中写的根元素的名称叫beans
c.SYSTEM:系统的意思,说明dtd约束文档来源于本地的操作系统中
D:\Work_idea\EE1234\day22\02_dtd\bean.dtd
d."bean.dtd":dtd约束文档的路径
一般都会把约束文档和xml文档放在同一个文件夹下
所以我们就可以写相对路径
2.根据约束文档的要求,写出根元素
3.在根元素中,根据提示写出其他的元素(写<就有提示我们可以写什么内容)
-->
<!DOCTYPE beans SYSTEM "bean.dtd">
<beans>
<bean id="111" className="222">
<property name="" value="">
<!--dtd约束的xml文档中,写<没有提示了,说明只能写文本了,不能写标签-->
只能写普通文本了
</property>
</bean>
<bean id="" className=""></bean>
<bean id="" className=""></bean>
<bean id="" className=""></bean>
<import resource="">
只能写普通文本了
</import>
<import resource=""></import>
<import resource=""></import>
<import resource=""></import>
</beans>c.dtd约束文档的语法(了解)
1.文档声明
作用:声明dtd约束文档如何编写 一共有3种书写dtd文档的方式
- 内部DTD,在XML文档内部嵌入DTD,只对当前XML有效。
xml
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE beans [
... //具体的语法
]>
<beans>
</beans>- 外部DTD---本地DTD,DTD文档在本地系统上,公司内部自己项目使用。
xml
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE beans SYSTEM "bean.dtd">
包含了4部分内容
a.!DOCTYPE:是dtd约束文档的固定格式
b.beans:约束xml文档中的根元素想要使用dtd约束就必须叫beans
c.SYSTEM:系统,当前使用的dtd约束文档来源于本地的操作系统
d."bean.dtd":dtd约束文档所在的位置,和xml在同一个文件夹下可以直接使用名字
<beans>
</beans>- 外部DTD---公共DTD,DTD文档在网络上,一般都由框架提供。
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN 2.0//EN"
"http://www.springframework.org/dtd/spring-beans-2.0.dtd">
一共包含了5部分内容:
a. !DOCTYPE:dtd约束文档声明的固定格式
b. Beans:根源元素的名称
c. PUBLIC:公共,dtd约束文档来源于互联网
d. "-//SPRING//DTD BEAN 2.0//EN":dtd约束文档的名称,一般由框架提供
e. "http://www.springframework.org/dtd/spring-beans-2.0.dtd">:dtd约束文档在互联网上的位置
<beans>
</beans>2.元素声明
作用:约束xml文档中的元素如何编写
xml
定义元素语法:<!ELEMENT 元素名 元素描述>
!ELEMENT:固定格式
元素名:自定义
元素描述包括:符号和数据类型
常见符号:
?:代表元素只能出现0次或者1次
+:代表元素至少出现1次 1次或者多次
*(?和+): 代表元素可以出现任意次 0次,1次,多次
():一组元素 (a,b)* aaabbbb (a|b)* abba
|:选择关系 在多个中选择一个 张三|李四
,:顺序关系 a,b,c 元素书写顺序只能先写a,在写b,最后写c
常见类型:#PCDATA 表示内容是文本,不能是子标签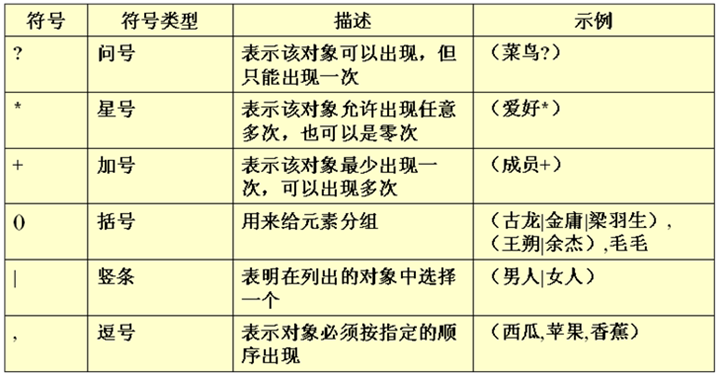
dtd
<!ELEMENT beans (bean*,import*) >
<!ELEMENT bean (property*)>
<!ELEMENT property (#PCDATA)>
<!ELEMENT import (#PCDATA)>
3.属性声明
作用:在约束文档中规定xml文档中的属性如何编写
xml
属性的语法:(attribute)
<!ATTLIST 元素名
属性名 属性类型 约束
属性名 属性类型 约束
...
>
!ATTLIST:属性声明的固定写法
元素名:属性必须是给元素添加,所有必须先确定元素名
属性名:自定义
属性类型:ID、CDATA...
ID : ID类型的属性用来标识元素的唯一性(不能重复,必须有,只能以字母开头)
CDATA:文本类型,字符串
约束:
#REQUIRED:说明属性是必须的;required
#IMPLIED:说明属性是可选的;implied
#FIXED:代表属性为固定值,实现方式:book_info CDATA #FIXED "固定值"
出版社 (清华|北大|传智播客) "传智播客"
dtd
<?xml version="1.0" encoding="UTF-8"?>
<!--
传智播客DTD教学实例文档。
模拟spring规范,如果开发人员需要在xml使用当前DTD约束,必须包括DOCTYPE。
格式如下:
<!DOCTYPE beans SYSTEM "bean.dtd">
-->
<!ELEMENT beans (bean*,import*)>
<!ELEMENT bean (property*)>
<!ELEMENT property (#PCDATA)>
<!ELEMENT import (#PCDATA)>
<!--ID : ID类型的属性用来标识元素的唯一性(不能重复,必须有,只能以字母开头)-->
<!ATTLIST bean id ID #REQUIRED
className CDATA #REQUIRED
>
<!--
#IMPLIED :可选属性
#FIXED: 包含固定值的属性
(男|女):多个值中选择一个值
-->
<!ATTLIST property name CDATA #REQUIRED
value CDATA #REQUIRED
age CDATA #IMPLIED
type CDATA #FIXED "abc"
sex(男|女)
>
<!ATTLIST import resource CDATA #REQUIRED>
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE beans SYSTEM "bean.dtd">
<beans>
<bean className="123123" id="aaa">
<property name="" value="">
只能写文本
</property>
<property name="" value="" age="11" type="abc" sex="女"></property>
</bean>
<bean id="b111" className=""></bean>
<bean id="b112" className=""></bean>
<bean id="b113" className=""></bean>
<import resource="">
只能写文本
</import>
</beans>2).schema约束
a.概述
Schema 语言也可作为 XSD(XML Schema Definition)。
Schema 比DTD强大,是DTD代替者。
Schema 本身也是XML文档,但是Schema文档扩展名为xsd,而不是xml。
Schema 功能更强大,数据类型约束更完善。
Schema 支持命名空间

b.基本使用(重点)
bean-schema.xsd
xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
传智播客Schema教学实例文档。
模拟spring规范,如果开发人员需要在xml使用当前Schema约束,必须包括指定命名空间。
格式如下:
<beans xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
-->
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn/bean"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:tns="http://www.itcast.cn/bean"
elementFormDefault="qualified">
<element name="beans">
<complexType>
<choice minOccurs="0" maxOccurs="3">
<element name="bean">
<complexType>
<sequence minOccurs="0" maxOccurs="unbounded">
<element name="property">
<complexType>
<attribute name="name" use="optional"></attribute>
<attribute name="value" use="required"></attribute>
</complexType>
</element>
</sequence>
<attribute name="id" use="required"></attribute>
<attribute name="className" use="required"></attribute>
</complexType>
</element>
<element name="import">
<complexType>
<attribute name="resource" use="required"></attribute>
</complexType>
</element>
</choice>
</complexType>
</element>
</schema>demo01-schema.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
schema约束文档的使用步骤:
1.在schema约束文档中有一个根元素的开始标签,赋值到xml文档中,添加结束标签
2.在根元素中,根据提示(写<出现提示要写的内容),写出其他的元素和属性
-->
<beans xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
<!--
写元素的时候,元素的标签体,写任何的内容都会报错,说明这个元素是一个自闭和的标签
自闭和的标签不能有标签体的,写什么都报错
-->
<bean id="" className="">
<property value="" name=""/>
<property value=""/>
</bean>
<bean id="" className=""></bean>
<import resource=""/>
<import resource=""></import>
</beans> c.schema约束的练习
bookshelf.xsd
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
传智播客DTD教学实例文档.将注释中的以下内容复制到要编写的xml的声明下面
复制内容如下:
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn bookshelf.xsd"
>
-->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.itcast.cn"
elementFormDefault="qualified">
<xs:element name='书架' >
<xs:complexType>
<xs:sequence maxOccurs='unbounded' >
<xs:element name='书' >
<xs:complexType>
<xs:sequence>
<xs:element name='书名' type='xs:string' />
<xs:element name='作者' type='xs:string' />
<xs:element name='售价' type='xs:double' />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>demo02_schema.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn bookshelf.xsd"
>
<书>
<书名>三国演义</书名>
<作者>罗贯中</作者>
<售价>100</售价>
</书>
<书>
<书名>西游记</书名>
<作者>吴承恩</作者>
<售价>120</售价>
</书>
</书架> d.命名空间
1.概述
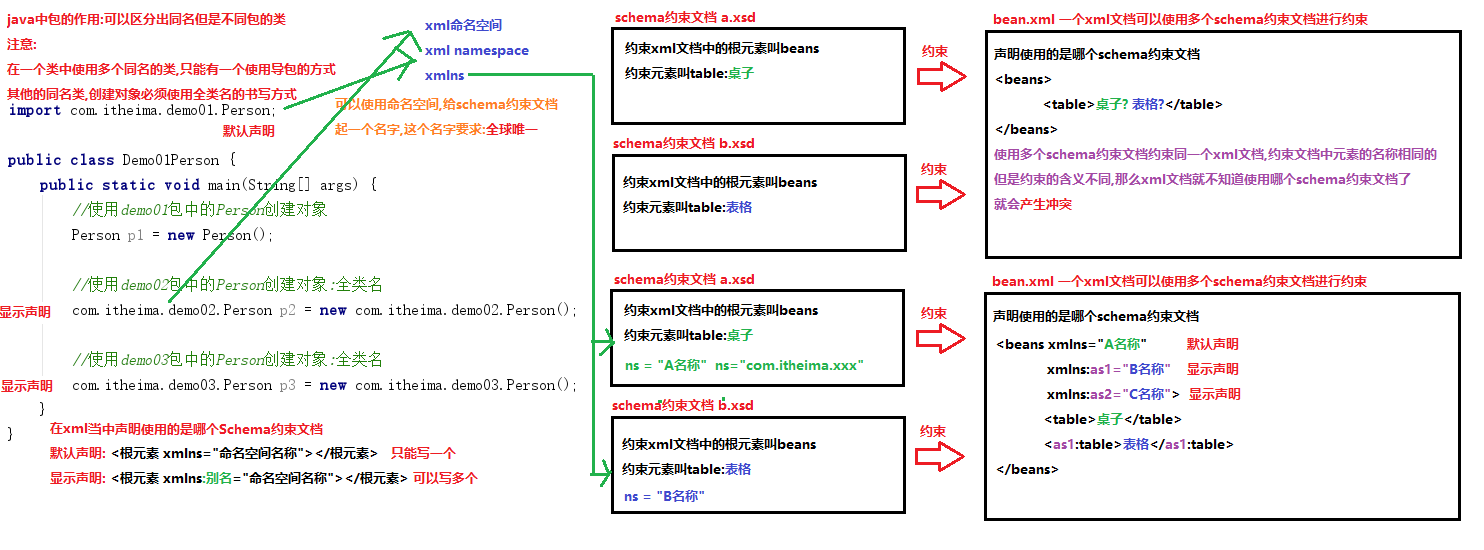
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Schema约束文档:
1.每个Schema约束文档,都必须有一个名字,这个名字就是命名空间
要求:全球唯一,一般使用公司的域名+项目名称+...
targetNamespace="http://www.itcast.cn/bean/demo01/...."
2.在xml文档中想要使用Scheme约束文档,必须声明使用的是哪个Schema约束文档
a.默认声明:只能有一个
xmlns="default namespace"
xmlns="http://www.itcast.cn/bean"
b.显示声明:可以有多个
xmlns:别名1="http://www.itcast.cn/bean"
xmlns:别名2="http://www.itcast.cn/bean"
3.想要使用Schema约束文档,必须确定约束文档的位置
a.先确定官方文档的位置
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
b.通过官方文档确定我们自己的Schema约束文档的位置
xsi:schemaLocation="{namespace} {location}"
命名空间 具体位置
4.使用
使用默认声明,直接写元素名称<bean></bean>
使用显示声明:格式
别名:元素名称
<别名1:bean></别名1:bean>
-->
<beans xmlns="http://www.itcast.cn/bean"
xmlns:as1="http://www.itcast.cn/bean"
xmlns:as2="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd
http://www.itcast.cn bookshelf.xsd">
<!--直接写元素名,使用默认命名空间-->
<bean id="" className=""></bean>
<!--别名:元素名称,使用显示命名空间-->
<as1:bean id="" className=""></as1:bean>
</beans>二.XML解析
1.解析概述
当将数据存储在XML后,我们就希望通过程序获取XML的内容。如果我们使用Java基础所学的IO知识是可以完成的,不过你学要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。人们为不同问题提供不同的解析方式,使用不同的解析器进行解析,方便开发人员操作XML。
2.解析方式和解析器
-
开发中比较常见的解析方式有三种,如下:
-
DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象
a)优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
b)缺点:XML文档过大,可能出现内存溢出
-
SAX:是一种速度更快,更有效的方法。她逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都触发对应的事件。(了解)
a)优点:处理速度快,可以处理大文件
b)缺点:只能读,逐行后将释放资源,解析操作繁琐。
-
PULL:Android内置的XML解析方式,类似SAX。(了解)
-
-
解析器,就是根据不同的解析方式提供具体实现。有的解析器操作过于繁琐,为了方便开发人员,又提供易于操作的解析开发包
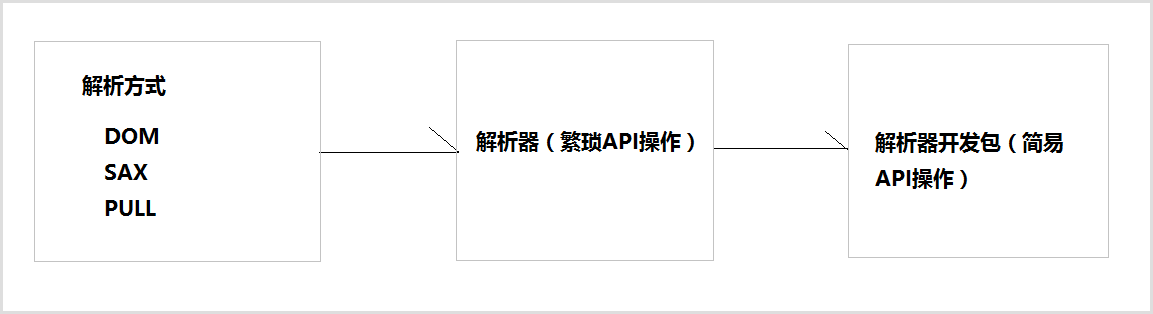
-
常见的解析开发包
- JAXP:sun公司提供支持DOM和SAX开发包
- Dom4j:比较简单的的解析开发包(常用)
- JDom:与Dom4j类似
- Jsoup:功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便(项目中讲解)
3.DOM解析原理及结构模型
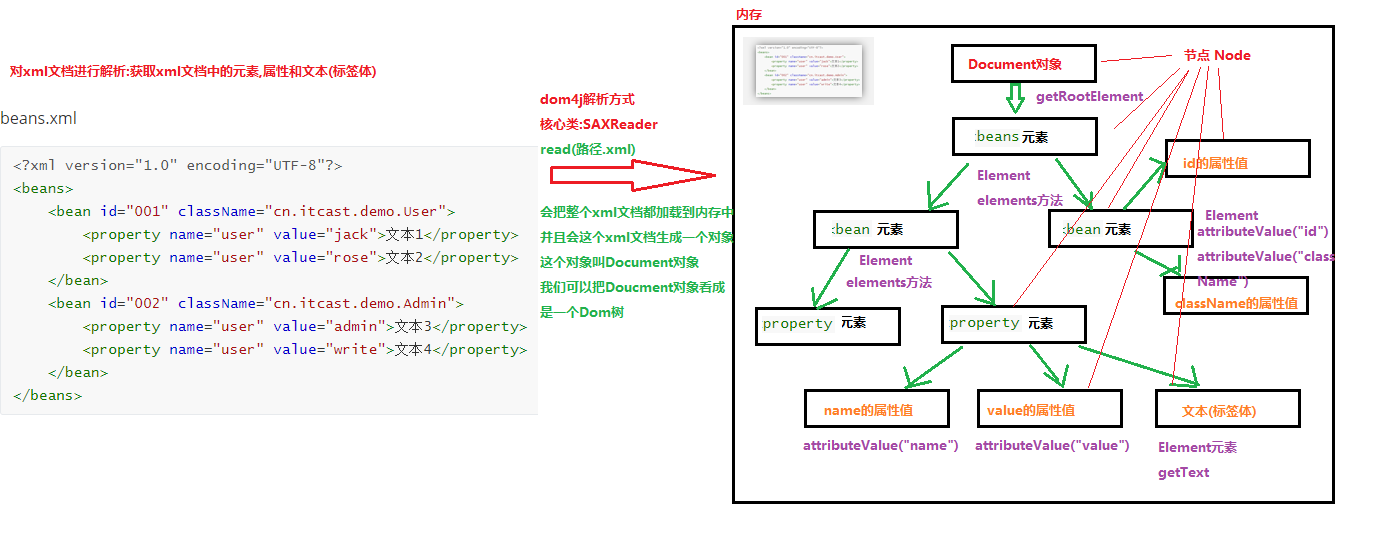
4.使用dom4j解析xml文件(重点)
beans.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="001" className="cn.itcast.demo.User">
<property name="user" value="jack">文本1</property>
<property name="user" value="rose">文本2</property>
</bean>
<bean id="002" className="cn.itcast.demo.Admin">
<property name="user" value="admin">文本3</property>
<property name="user" value="write">文本4</property>
</bean>
</beans>
java
package com.itheima.demo05parseXML;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
/*
使用dom4j解析xml文档
获取xml文档中的元素、属性和文本
解析步骤:
1.导入dom4j的jar包
2.创建dom4j核心类对象SAXReader
3.使用RAXReaderar对象中的方法read,读取xml文件到内存中,并生成Document对象
4.使用Doucment对象中的方法getRootElement,获取根元素beans
5.使用根元素Element对象中的方法elements获取根元素下边的子元素bean,多个bean元素存储到List集合中返回
6.遍历List集合,获取每一个bean元素
7.使用bean元素Element对象中的方法attributeValue,根据属性名,获取属性的值(id,className)
8.使用bean元素Element对象中的方法elements获取bean元素下边的子元素property,多个property存储到List集合中返回
9.遍历List集合,获取每一个property元素
10.使用property元素Element对象中的方法attributeValue,根据属性名,获取属性的值(name,value)
11.使用property元素Element对象中的方法getText,获取property元素上的文本(标签体)
*/
public class Demo01UseDom4jParseXML {
public static void main(String[] args) throws DocumentException {
//1.导入dom4j的jar包
//2.创建dom4j核心类对象SAXReader
SAXReader sax = new SAXReader();
//3.使用RAXReaderar对象中的方法read,读取xml文件到内存中,并生成Document对象
Document document = sax.read("day22\\beans.xml");
//4.使用Doucment对象中的方法getRootElement,获取根元素beans
Element rootElement = document.getRootElement();
System.out.println(rootElement.getName());
//5.使用根元素Element对象中的方法elements获取根元素下边的子元素bean,多个bean元素存储到List集合中返回
List<Element> beanElementList = rootElement.elements();
//6.遍历List集合,获取每一个bean元素
for (Element beanElement : beanElementList) {
System.out.println("\t"+beanElement.getName());
//7.使用bean元素Element对象中的方法attributeValue,根据属性名,获取属性的值(id,className)
String id = beanElement.attributeValue("id");
String className = beanElement.attributeValue("className");
System.out.println("\t\tbean元素的属性id:"+id);
System.out.println("\t\tbean元素的属性className:"+className);
//8.使用bean元素Element对象中的方法elements获取bean元素下边的子元素property,多个property存储到List集合中返回
List<Element> propertyElementList = beanElement.elements();
//9.遍历List集合,获取每一个property元素
for (Element propertyElement : propertyElementList) {
System.out.println("\t\t\t"+propertyElement.getName());
//10.使用property元素Element对象中的方法attributeValue,根据属性名,获取属性的值(name,value)
String name = propertyElement.attributeValue("name");
String value = propertyElement.attributeValue("value");
System.out.println("\t\t\t\tproperty元素的属性name:"+name);
System.out.println("\t\t\t\tproperty元素的属性value:"+value);
//11.使用property元素Element对象中的方法getText,获取property元素上的文本(标签体)
String text = propertyElement.getText();
System.out.println("\t\t\t\tproperty元素的文本:"+text);
}
}
}
}程序执行的结果:
java
beans
bean
bean元素的属性id:001
bean元素的属性className:cn.itcast.demo.User
property
property元素的属性name:user
property元素的属性value:jack
property元素的文本:文本1
property
property元素的属性name:user
property元素的属性value:rose
property元素的文本:文本2
bean
bean元素的属性id:002
bean元素的属性className:cn.itcast.demo.Admin
property
property元素的属性name:user
property元素的属性value:admin
property元素的文本:文本3
property
property元素的属性name:user
property元素的属性value:write
property元素的文本:文本4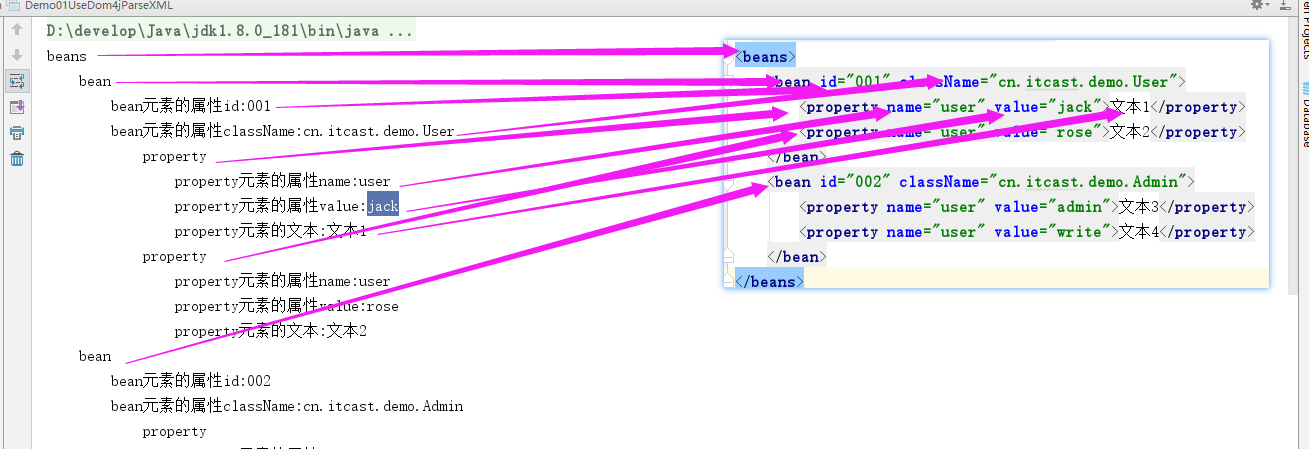
5.使用xpath和dom4j快读定位解析xml文件(重点)
xpath表达式常用查询形式
-
第一种查询形式
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB -
第二种查询形式
//BBB: 表示和这个名称相同,表示只要名称是BBB 都得到 -
第三种查询形式
/*: 所有元素 -
第四种查询形式
BBB[1]:表示第一个BBB元素 BBB[last()]:表示最后一个BBB元素 -
第五种查询形式
//BBB[@id]: 表示只要BBB元素上面有id属性 都得到 -
第六种查询形式
//BBB[@id='b1'] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
beans.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<beans>
<bean id="001" className="cn.itcast.demo.User">
<property name="user" value="jack">文本1</property>
<property name="user" value="rose">文本2</property>
<bean id="005" className="cn.itcast.demo.Animal">
<property name="user" value="小猫">文本9</property>
<property name="user" value="小狗">文本10</property>
</bean>
</bean>
<bean id="002" className="cn.itcast.demo.Admin">
<property name="user" value="admin">文本3</property>
<property name="user" value="write">文本4</property>
</bean>
<bean id="003" >
<property name="user" value="张三">文本5</property>
<property name="user" value="李四">文本6</property>
</bean>
<bean id="004" className="cn.itcast.demo.Student">
<property name="user" value="王五">文本7</property>
<property name="user" value="赵六">文本8</property>
</bean>
</beans>
java
package com.itheima.demo05parseXML;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.util.List;
/*
使用xpath和dom4j快读定位解析xml文件(重点)
使用的前提:
xpath是基于dom4j开发的,要使用xpath不仅仅的导入xpath的jar包,还需要使用dom4j的jar包
使用步骤:
1.导入dom4j和xpath的jar包
2.创建dom4j核心类对象SAXReader
3.使用SAXReader对象中的方法read,读取xml文件到内存中,生成Doucment对象
4.使用Document对象中的方法selectNodes|selectSigleNode解析xml文件
List<Element> selectNodes("xpath表达式") 获取符合表达式的元素集合
Element selectSingleNode("xpath表达式") 获取符合表达式的唯一元素
xpath表达式常用查询形式
- 第一种查询形式
//*: 所有元素
- 第二种查询形式
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB
/beans/bean/property
- 第三种查询形式
//BBB: 表示和这个名称相同,表示只要名称是BBB 都得到
//property
//bean
- 第四种查询形式
//BBB[1]:表示第一个BBB元素
//BBB[2]:表示第二个BBB元素
...
//BBB[last()]:表示最后一个BBB元素
- 第五种查询形式
//BBB[@id]: 表示只要BBB元素上面有id属性 都得到
//BBB[@className]: 表示只要BBB元素上面有className属性 都得到
- 第六种查询形式
//BBB[@id='b1'] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
*/
public class Demo02UseXpathAndDom4jParseXML {
public static void main(String[] args) throws DocumentException {
//1.导入dom4j和xpath的jar包
//2.创建dom4j核心类对象SAXReader
SAXReader sax = new SAXReader();
//3.使用SAXReader对象中的方法read,读取xml文件到内存中,生成Doucment对象
Document document = sax.read("day22\\beans2.xml");
//4.使用Document对象中的方法selectNodes|selectSigleNode解析xml文件
//获取xml文档中所有的元素
List<Element> list01 = document.selectNodes("//*");
for (Element ele : list01) {
System.out.println(ele.getName());
}
System.out.println("-----------------------------");
//获取beans下边所有的bean(只有儿子,没有孙子)
List<Element> list02 = document.selectNodes("/beans/bean");
for (Element ele : list02) {
System.out.println(ele.getName()+"\t"+ele.attributeValue("id"));
}
System.out.println("-----------------------------");
//获取beans下边bean中的property
List<Element> list03 = document.selectNodes("/beans/bean/property");
for (Element ele : list03) {
System.out.println(ele.getName()+"\t"+ele.attributeValue("value"));
}
System.out.println("-----------------------------");
//获取文档中所有的bean(儿子,孙子都会获取)
List<Element> list04 = document.selectNodes("//bean");
for (Element ele : list04) {
System.out.println(ele.getName()+"\t"+ele.attributeValue("id"));
}
System.out.println("-----------------------------");
//获取所有bean元素中的第一个bean元素
Element oneBean = (Element)document.selectSingleNode("//bean[1]");
System.out.println(oneBean.getName()+"\t"+oneBean.attributeValue("id"));
//获取所有bean元素中的第二个bean元素
Element twoBean = (Element)document.selectSingleNode("//bean[2]");
System.out.println(twoBean.getName()+"\t"+twoBean.attributeValue("id"));
//获取所有bean元素中的最后一个bean元素
Element lastBean = (Element)document.selectSingleNode("//bean[last()]");
System.out.println(lastBean.getName()+"\t"+lastBean.attributeValue("id"));
System.out.println("-----------------------------");
//获取所有bean元素中含有className属性的
List<Element> list05 = document.selectNodes("//bean[@className]");
for (Element ele : list05) {
System.out.println(ele.getName()+"\t"+ele.attributeValue("id"));
}
System.out.println("-----------------------------");
//获取所有bean元素中含有className属性的,并且className的属性值是cn.itcast.demo.Student
Element stuEle = (Element) document.selectSingleNode("//bean[@className='cn.itcast.demo.Student']");
System.out.println(stuEle.getName()+"\t"+stuEle.attributeValue("id")+"\t"+stuEle.attributeValue("className"));
}
}