
在分析型数据库的性能比拼中,"少做事" 往往比 "快做事" 更关键 ------ 数据读取过程中的磁盘 IO、网络传输(尤其存算分离场景)是资源消耗的核心,而数据裁剪正是通过 "跳过不需要处理的数据",从根源降低开销。
Apache Doris 作为面向实时分析的现代数据仓库,设计了多维度的数据裁剪与过滤机制,覆盖 "静态谓词过滤→动态场景优化(LIMIT/TopK/JOIN)" 全链路。本文将深入拆解这些机制的实现原理,带你理解 Doris 如何做到 "智能跳过无用数据"。
一、数据裁剪的价值
数据裁剪的核心逻辑是 "提前排除不符合条件的数据,减少后续计算的输入量"------ 对于 100TB 的原始数据,若能裁剪掉 99%,则后续计算只需处理 1TB,性能提升呈数量级增长。
行业内主流数据库已形成成熟的裁剪思路:
- 静态裁剪 :基于元数据或预计算信息过滤,如通过
zone map(存储列的 min/max 值)、SMA(小物化聚合)跳过不满足谓词的分区 / 文件; - 动态裁剪:查询执行中生成过滤条件,如 Join 时用 Build 侧数据生成谓词过滤 Probe 侧;
- 二级索引辅助:用 Bloom Filter、Cuckoo Filter等轻量级索引快速判断数据是否存在,避免全文件扫描。
Doris 的裁剪机制在吸收这些思路的基础上,结合自身 "MPP 架构 + 列存储 + 有序 Segment" 的特性,实现了更贴合实时分析场景的优化。
二、Doris 架构与数据存储:裁剪机制的基础
要理解裁剪逻辑,需先明确 Doris 的数据组织方式 ------ 裁剪机制本质是 "利用数据存储的结构化特征,精准定位有用数据"。
2.1 整体架构:FE 决策 + BE 执行 + 存储层支撑
Doris 集群由三大组件协同:

- FE(Frontend):负责元数据管理(分区、表结构)、SQL 解析优化、裁剪策略规划(如分区列谓词过滤);
- BE(Backend):执行数据扫描、计算,实现动态裁剪(如 LIMIT 停止读取、TopK 堆过滤);
- 存储组件:本地 / 云端存储,以 "分区→分桶→Segment→列文件" 的层级存储数据,为裁剪提供元数据支持。
2.2 数据存储层级:从分区到列文件
Doris 的表按 "三级结构" 组织数据,每一层都为裁剪提供切入点:
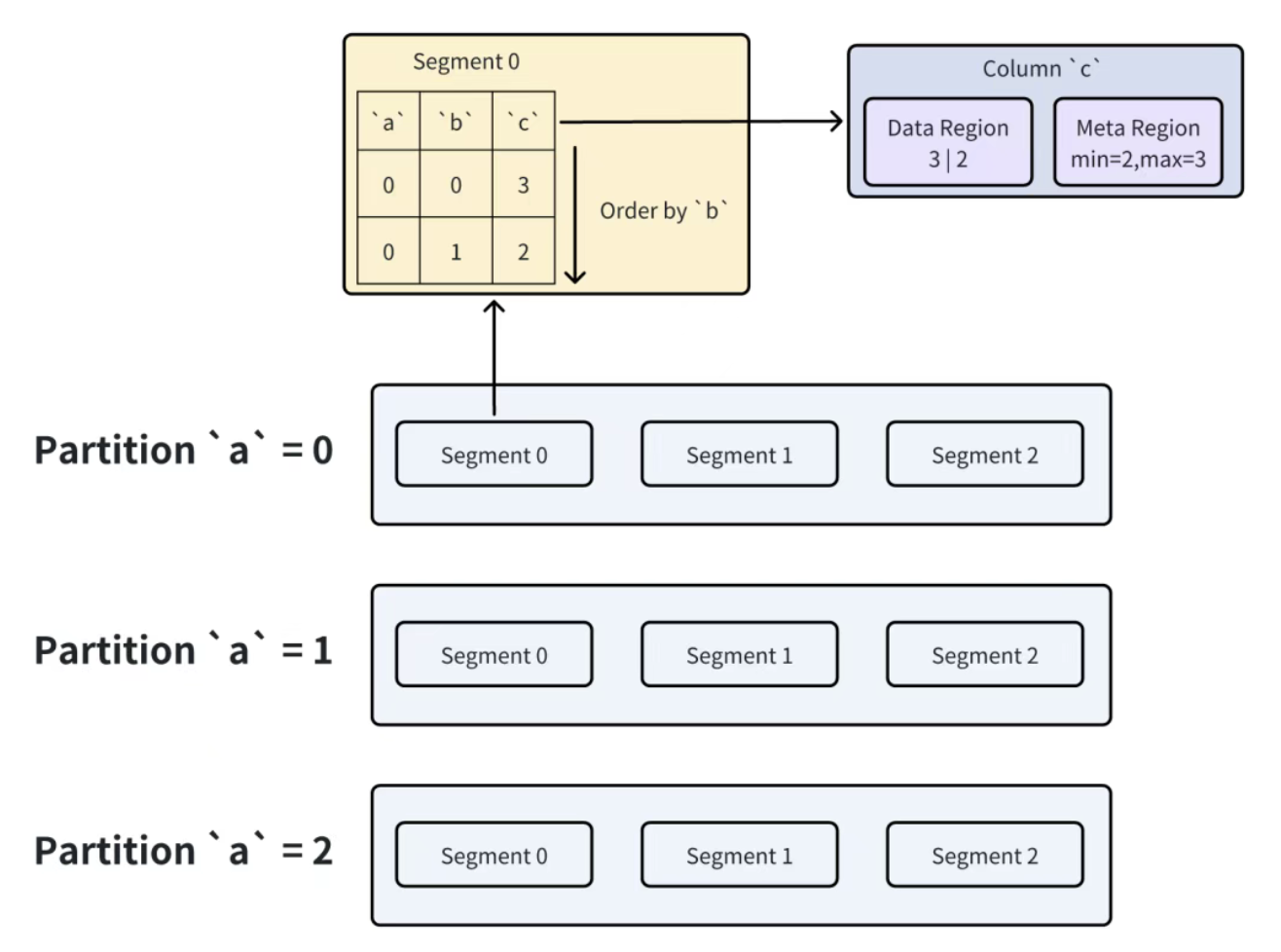
- 分区(Partition) :按分区键(如时间
a)拆分,元数据记录每个分区的范围(如partition1: a<1,partition2: 1≤a<2); - 分桶(Bucket) :每个分区按分桶键(如
b)Hash 拆分,确保数据均匀分布; - Segment :分桶的物理存储单位,每个 Segment 内数据按 Key 列(如
a,b)有序排列,且包含:
- 列文件:每列单独存储,文件头记录该列的 min/max、非空数等元数据;
- 短键索引:快速定位 Key 列的行范围,避免全文件扫描。
2.3 数据裁剪的分类:静态与动态
Doris 按 "裁剪发生的时间" 将机制分为两类:
- 静态裁剪 :SQL 解析优化阶段确定,无需执行时计算,如 "
a>0过滤p1分区"; - 动态裁剪:查询执行中根据实时数据生成过滤条件,如 LIMIT 到行数停止、TopK 用堆顶过滤数据。
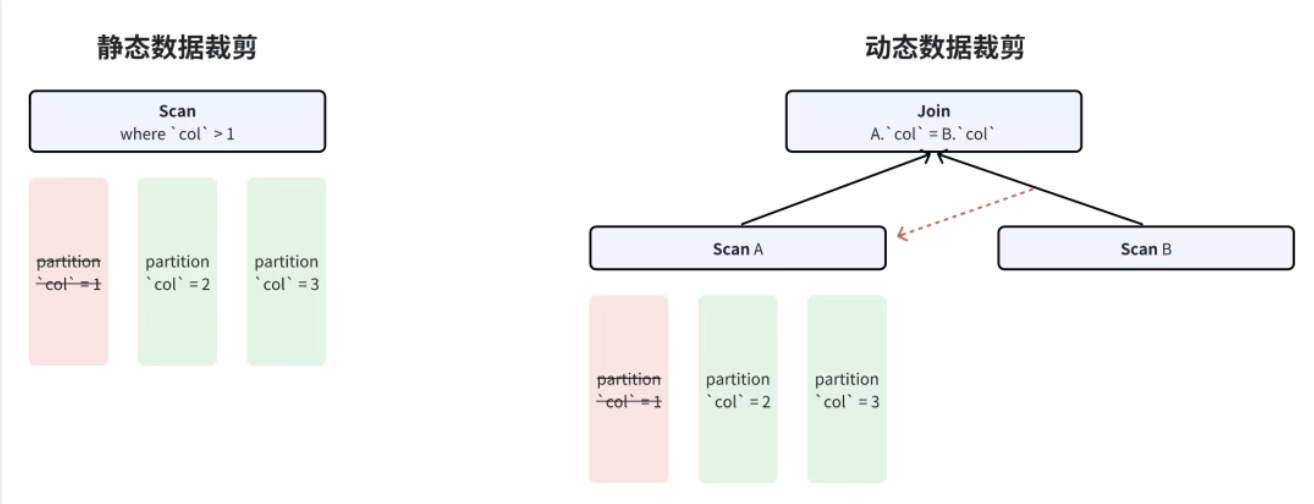
具体可细分为四种核心机制:谓词静态过滤、LIMIT 动态裁剪、TopK 裁剪、JOIN 裁剪,下文逐一拆解。
三、谓词静态过滤:基于元数据的 "提前排除"
谓词静态过滤是 Doris 最基础也最高效的裁剪方式,通过 "FE 解析 SQL 谓词 + 存储元数据比对",在数据读取前就排除无用分区 / 文件 / 行,分为三类场景。
3.1 分区列谓词过滤:FE 层的 "元数据筛选"
核心逻辑 :分区列的谓词(如a>0)由 FE 处理,通过查询分区元数据(每个分区的范围),直接跳过不满足条件的分区。
以 SQL SELECT * FROM tbl WHERE a>0为例:
- FE 读取分区元数据:
p1(a<1)、p2(1≤a<2)、p3(2≤a<3); - 比对谓词
a>0:p1包含a<1的部分数据(如a=-1)不满足,但p1整体范围与a>0有交集(如a=0.5),因此不跳过p1;p2、p3完全满足,全部保留; - FE 仅将
p1、p2、p3的读取任务下发给 BE,无需处理不存在的分区(如a≥3)。
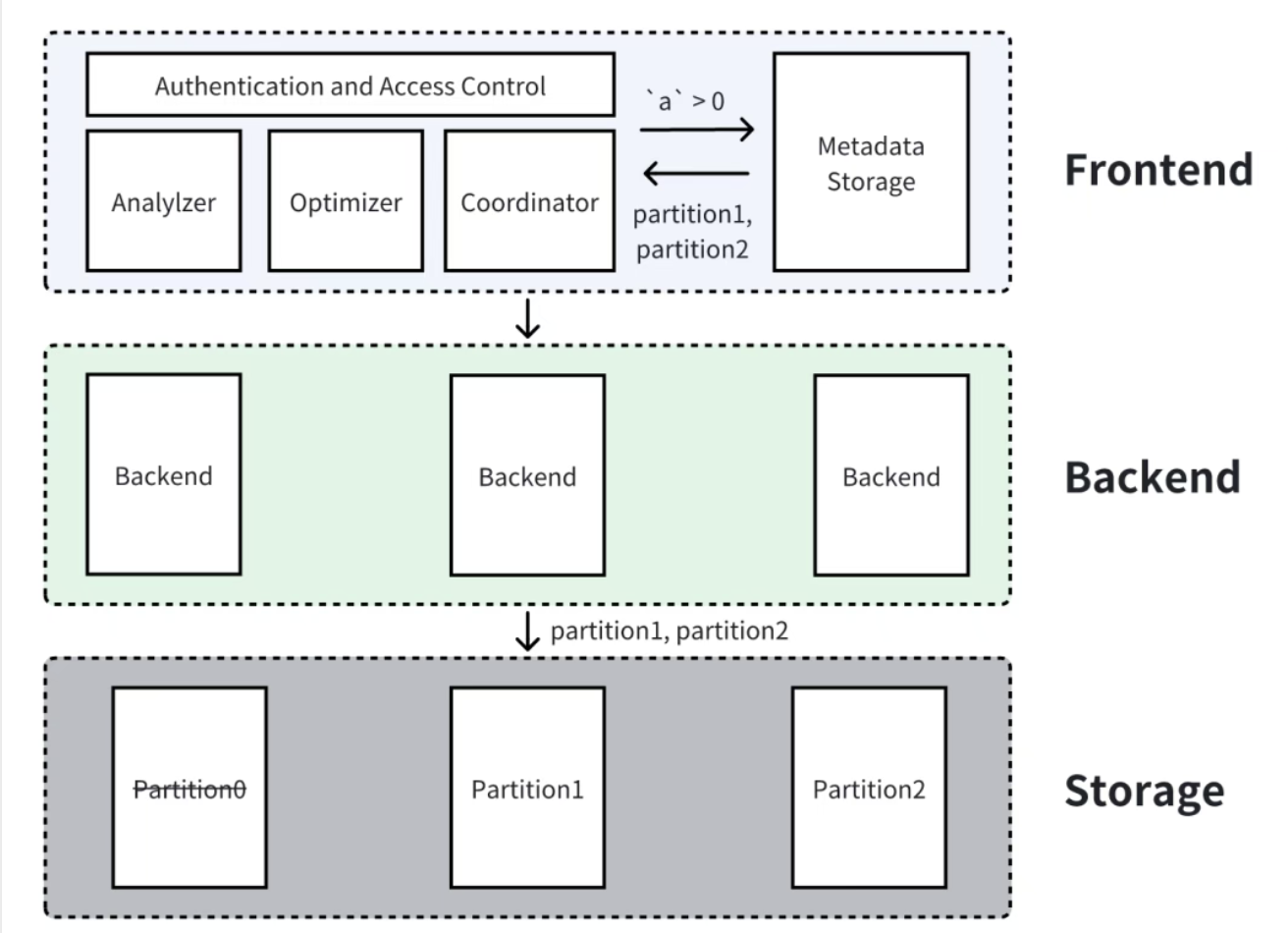
优势:完全在 FE 层完成,无需 BE 参与,是开销最小的裁剪方式。
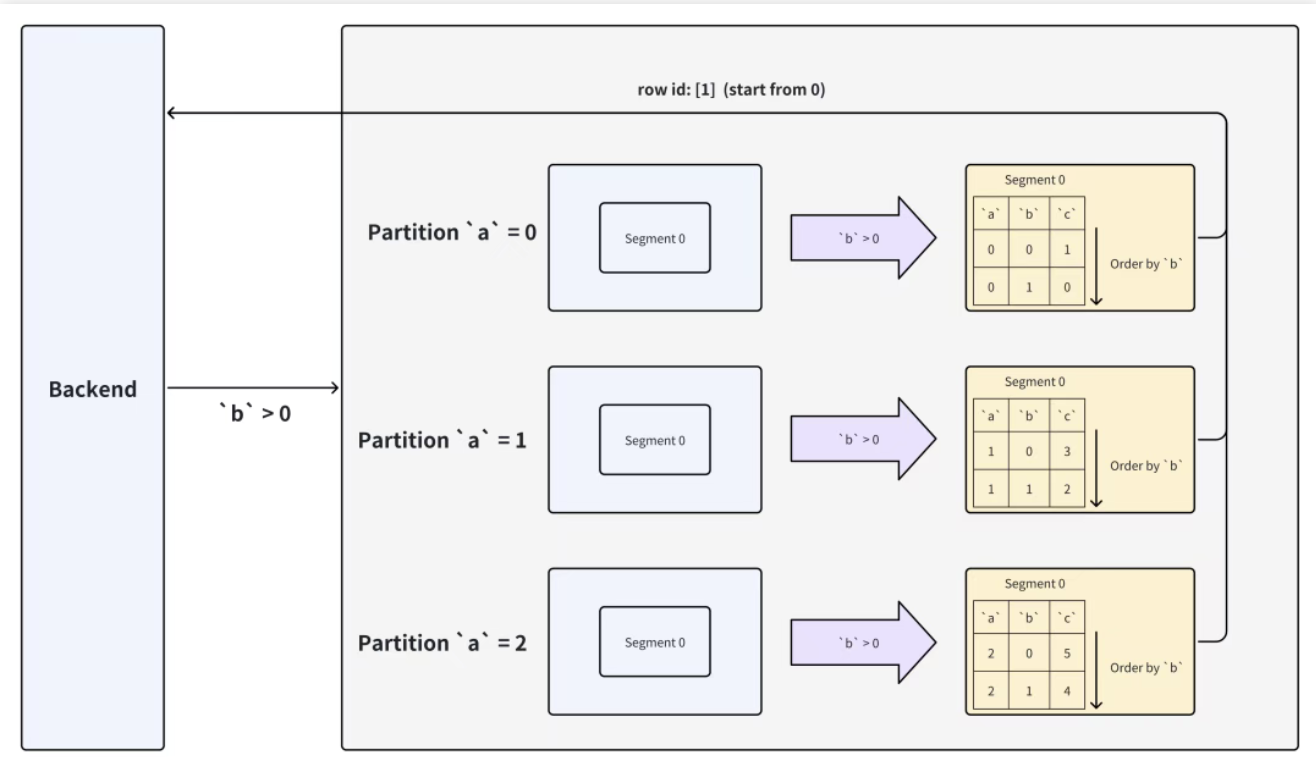
3.2 Key 列谓词过滤:Segment 内的 "范围定位"
核心逻辑 :Key 列(如b)在 Segment 内有序存储,通过谓词生成 Key 列的上下界,用二分查找确定需读取的行范围,跳过范围外的数据。
以 SQL SELECT * FROM tbl WHERE b>0为例(b是 Key 列):
- BE 读取目标 Segment 的 Key 列(
a,b)有序数据,假设某 Segment 的b值为[-2, -1, 1, 2, 3]; - 谓词
b>0的下界是0,通过二分查找定位到第一个满足条件的行(b=1,行号 1); - BE 仅读取行号≥1 的数据,跳过前两行(
b=-2,-1),减少 50% 的行读取量。
3.3 普通列谓词过滤:列文件的 "元数据预筛"
核心逻辑 :普通列(如c)的列文件头记录该列的 min/max 值,BE 先比对 min/max 与谓词,跳过不满足的列文件;对满足的列文件,读取后计算谓词,得到符合条件的行号,再读取其他列的对应行。
以 SQL SELECT * FROM tbl WHERE c>2为例(c是普通列):
- BE 扫描目标 Segment 的
c列文件:
- 列文件 0 的 min=0、max=1,小于谓词下界
2,直接跳过该文件; - 列文件 1 的 min=1、max=5,与谓词有交集,读取该文件的
c值;
- 对列文件 1 的
c值(如[1,3,4,2,5])计算谓词,得到符合条件的行号(1,2,4); - BE 仅读取其他列(
a,b)的行号 1,2,4 的数据,避免读取全量行。
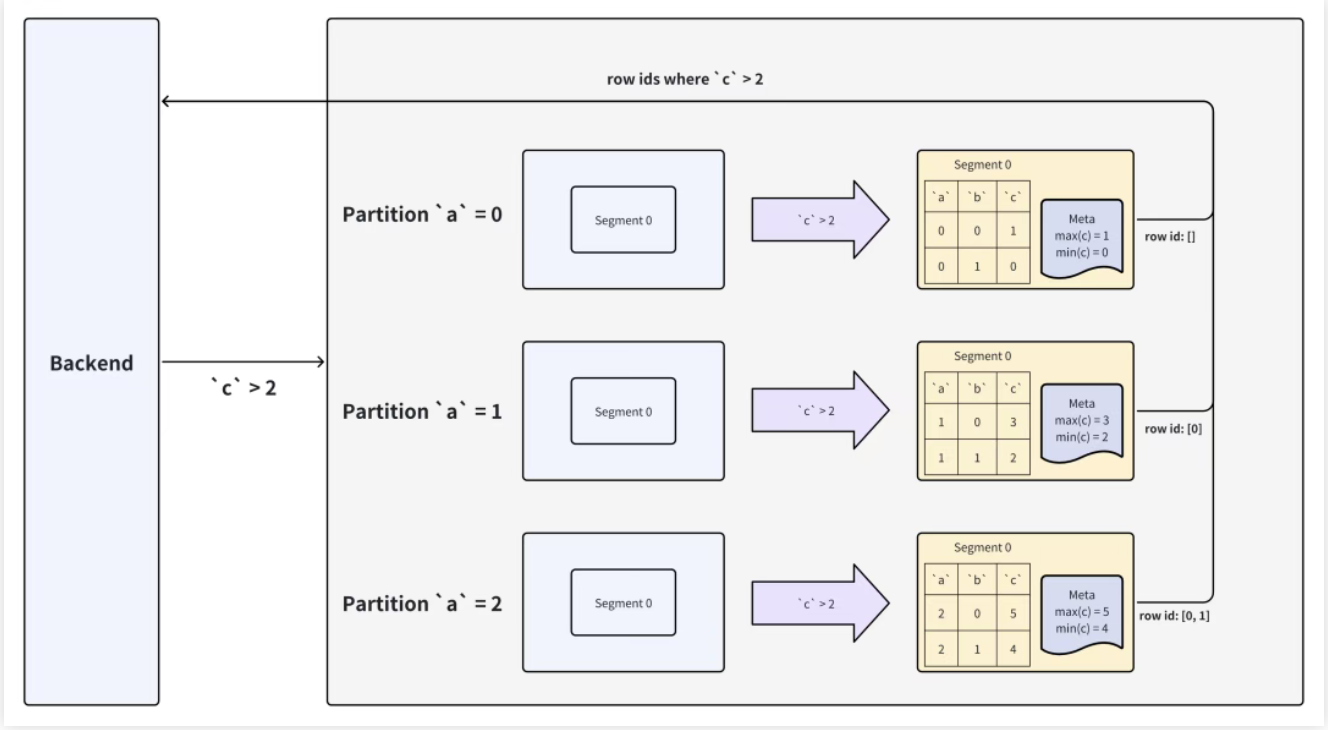
优势:通过列文件元数据提前排除无用文件,减少磁盘 IO;列存储特性确保仅读取需处理的列,进一步降低开销。
四、LIMIT 动态裁剪:"见好就收" 的读取策略
LIMIT 查询的核心需求是 "获取前 N 行数据",Doris 通过 "提前停止数据读取" 避免无用计算,分两种场景优化。
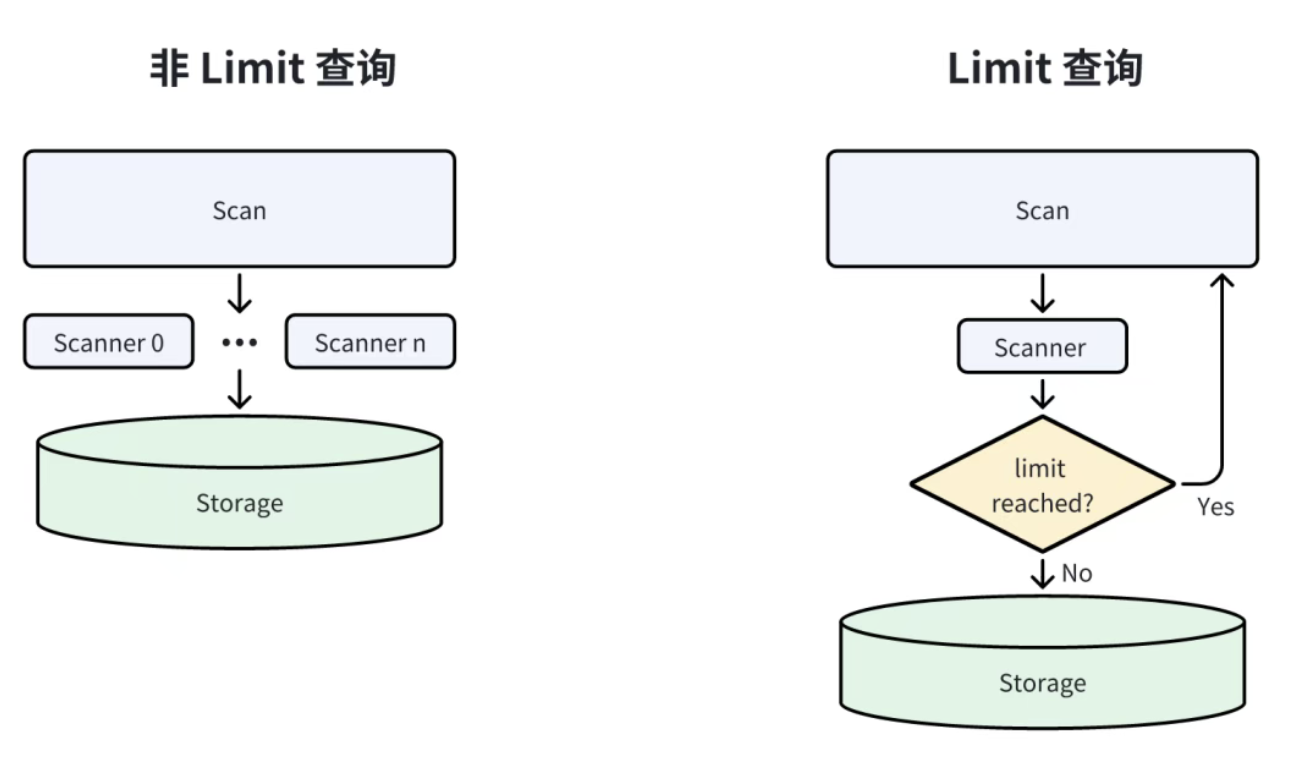
4.1 Scan 节点的 LIMIT 裁剪:单并发 + 即时停止
场景 :当 LIMIT 直接作用于 Scan 节点(如SELECT * FROM tbl LIMIT 100),Doris 会:
- 将 Scan 节点的并发度设为 1(默认并发为 BE 核心数);
- 当读取的数据行数达到 LIMIT 值(如 100 行),立即停止扫描,不再读取后续数据。
例:若表中有 10 万行数据,LIMIT 100 时,BE 读取 100 行后就停止,仅处理 0.1% 的数据。
4.2 非 Scan 节点的 LIMIT 裁剪:停止上游数据传输
场景 :当 LIMIT 作用于后续节点(如SELECT SUM(c) FROM tbl GROUP BY b LIMIT 100),Doris 会:
- 下游 LIMIT 节点实时统计接收的结果行数;
- 当行数达到 LIMIT 值,立即向上游节点(如 GROUP BY 节点)发送 "停止信号";
- 上游节点收到信号后,停止向 LIMIT 节点传输数据,同时停止自身的计算。
核心:从下游反向触发上游停止,避免 "上游计算完所有结果,下游只取前 N 行" 的资源浪费。
五、TopK 裁剪:BI 场景的 "精准筛选"
TopK 查询(如 "取 GMV 前 10 的商品")是 BI 分析的高频场景,传统做法是 "全量排序后取前 K",开销极大。Doris 通过 "局部裁剪 + 全局汇总" 的两阶段策略,大幅减少数据处理量。
5.1 标准堆排序的局限
传统 TopK 用 "最小堆"(降序排序):扫描所有数据,插入堆中(堆大小为 K),最终堆中数据即为 TopK。但问题是 "必须扫描全量数据",若数据量达 10 亿行,堆操作的开销依然巨大。
5.2 Doris 的两阶段 TopK 裁剪
Doris 利用 "Segment 内 Key 列有序" 和 "分布式计算" 特性,将 TopK 拆分为 "局部裁剪" 和 "全局裁剪":
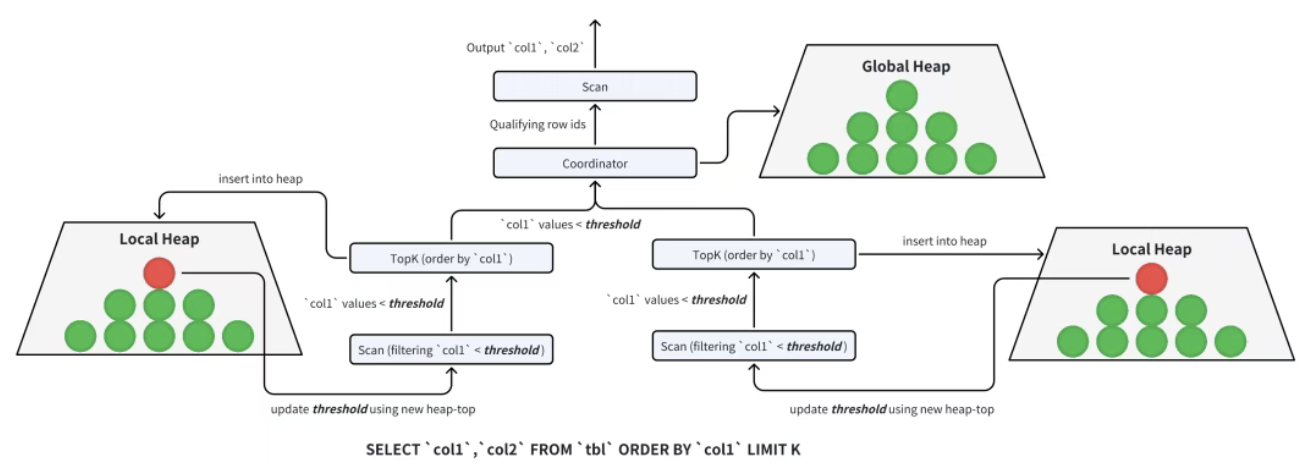
阶段 1:局部裁剪(每个 BE 扫描节点)
- 每个扫描节点维护一个大小为 K 的最小堆(如 K=10);
- 扫描数据时,将每行插入堆中:
- 若堆未满(不足 10 行),直接插入;
- 若堆满,比较当前行与堆顶(堆中最小的 TopK 元素):若当前行更大,替换堆顶并调整堆;若更小,直接丢弃;
- 扫描过程中,用 "堆顶元素" 作为动态过滤条件:后续数据若小于堆顶,直接跳过(无需插入堆),进一步减少堆操作。
阶段 2:全局裁剪(FE / 协调节点)
- 所有扫描节点将局部 TopK(最多 K 行 / 节点)发送给协调节点;
- 协调节点对所有局部 TopK 数据(共 N×K 行,N 为扫描节点数)构建新的最小堆,排序后取前 K 行,得到最终 TopK 结果;
- 若需返回 TopK 的完整列数据(如除排序列外的其他字段),协调节点将最终 TopK 的行号下发给 BE,BE 仅读取这些行号的完整数据。
例:10 个 BE 节点,K=10,局部裁剪后仅需传输 100 行数据到全局节点,全局排序 100 行即可,相比全量排序 10 亿行,开销可忽略不计。
六、JOIN 裁剪:Hash Join 的 "前置过滤"
多表 Join 是数据库的耗时操作,Doris 通过 "在 Probe 侧读取前,用 Build 侧数据生成过滤谓词",减少 Probe 侧的数据量,核心是 "自适应谓词生成" 和 "谓词等待策略"。
6.1 Hash Join 的基础逻辑
Hash Join 分为 Build 侧(小表)和 Probe 侧(大表):
- Build 侧:读取小表数据,构建 Hash Table(Key 为 Join 列,Value 为其他列);
- Probe 侧:读取大表数据,用 Join 列查询 Hash Table,匹配则输出结果。
裁剪的关键是 "Probe 侧只读取可能匹配 Build 侧的数据"------ 即通过 Build 侧的 Join 列值,生成过滤谓词,提前排除 Probe 侧的不匹配行。
6.2 自适应谓词生成:In 谓词 vs Bloom Filter
Doris 根据 Build 侧数据量,动态选择谓词类型:
- 当 Build 侧去重后的数据量≤阈值(如 1000) :生成
In (v1, v2, ..., vn)谓词,Probe 侧用该谓词过滤,仅保留 Join 列在In列表中的行,过滤率 100%(无误判);
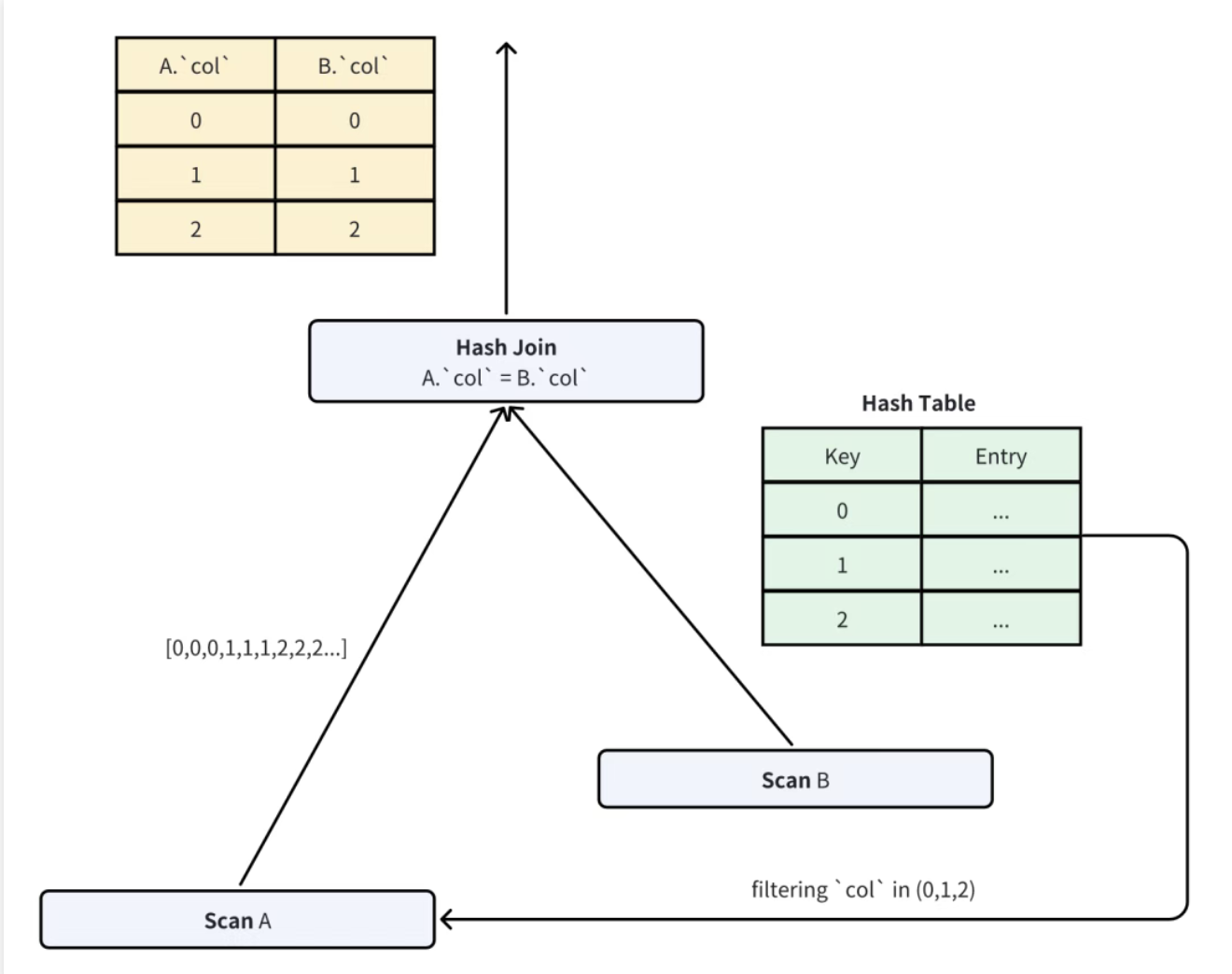
- 当 Build 侧数据量 > 阈值 :生成 Bloom Filter(布隆过滤器),Probe 侧用 Bloom Filter 判断 Join 列是否 "可能存在" 于 Build 侧:
- 若 Bloom Filter 判断 "不存在",直接跳过该行;
- 若判断 "可能存在",继续后续 Hash 查询(Bloom Filter 的误判会被 Hash 查询修正,不影响结果正确性)。
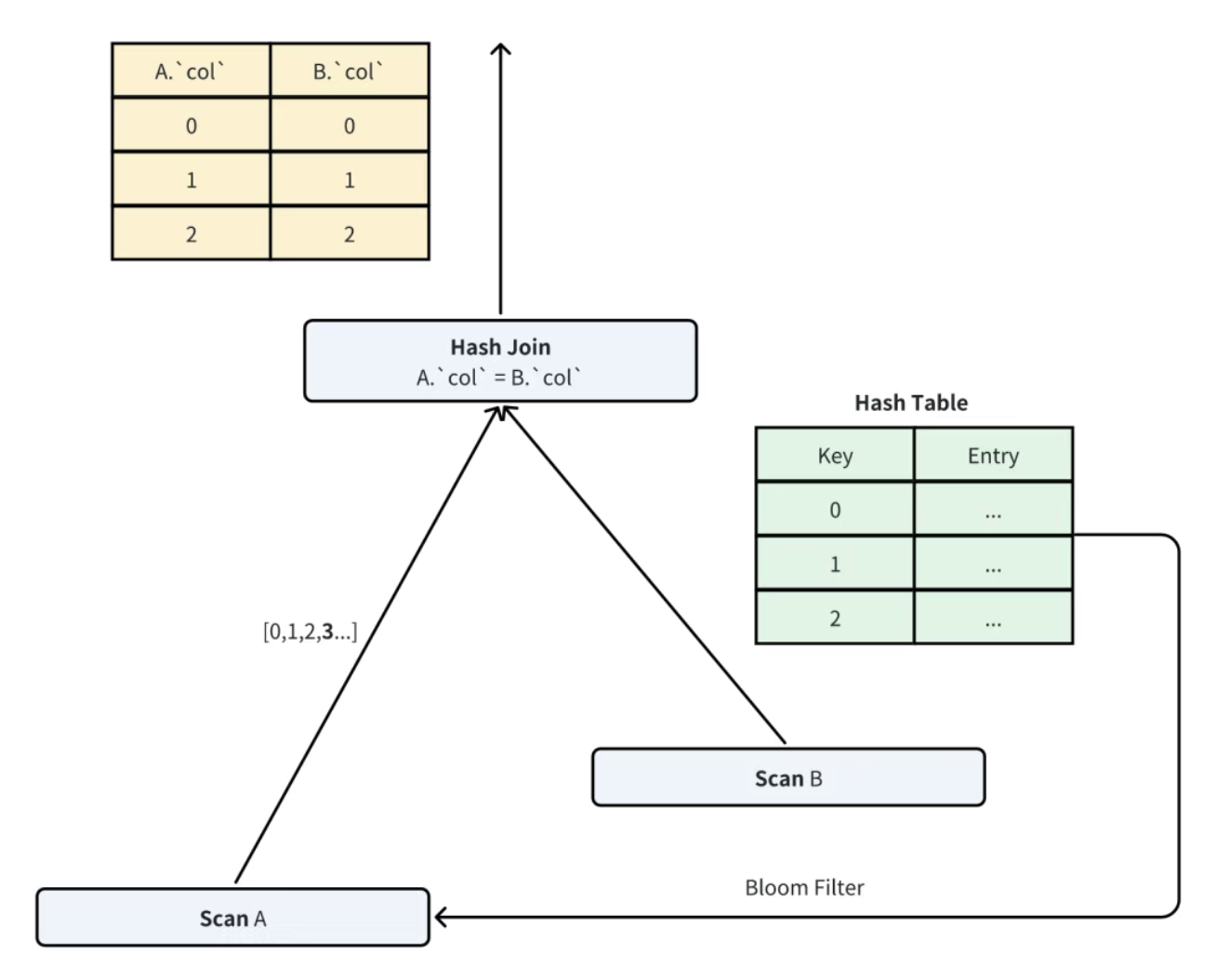
为什么用 Bloom Filter:当 Build 侧数据量极大(如 100 万行),生成 In 谓词的开销(存储、传输、解析)过高,而 Bloom Filter 体积小(如 100 万行仅需几 MB)、判断速度快,虽有误判但不影响正确性。
6.3 谓词等待策略:平衡延迟与效率
Bloom Filter/In 谓词的构建需要时间,若 Probe 侧一直等待,会增加查询延迟。Doris 采用 "1 秒等待策略":
- Probe 侧启动后,先等待 1 秒,若 Build 侧的谓词已生成,立即用谓词过滤;
- 若 1 秒内未收到谓词,Probe 侧直接开始读取数据(避免无限等待);
- 后续若谓词生成完成,Probe 侧立即启用谓词,过滤剩余数据。
例:Build 侧构建 Bloom Filter 需 2 秒,Probe 侧前 1 秒读取的数据未过滤,但 1 秒后启用 Bloom Filter,过滤后续 80% 的数据,整体仍能大幅减少 Join 开销。
七、总结
Doris 的四类数据裁剪机制,覆盖了从 "静态元数据筛选" 到 "动态执行优化" 的全链路,未来,Doris 社区将持续探索更通用的裁剪策略。
对于开发者而言,理解这些裁剪机制不仅能更好地编写高效 SQL(如优先用分区列 / Key 列做过滤),也能在排查性能问题时(如慢查询),快速定位 "是否因裁剪未生效导致全量扫描"------ 毕竟,在分析型数据库中,"不处理数据" 才是最快的处理方式。