节点信息请参考:
zookeeper: Apache Hadoop生态组件部署分享-zookeeper
hadoop:Apache Hadoop生态组件部署分享-Hadoop
hive: Apache Hadoop生态组件部署分享-Hive
hbase: Apache Hadoop生态组件部署分享-Hbase
一、IMPALA编译
1.1 下载impala-4.2.0
下载地址:https://impala.apache.org/downloads.html
1.2 解压并修改相关配置
bash
cd apache-impala-4.2.0修改./bin/impala-config.shexport USE_APACHE_HIVE=${USE_APACHE_HIVE-false} 为 export USE_APACHE_HIVE=${USE_APACHE_HIVE-true}修改此参数原因: 部署时候impala无法查询数据,因为默认引用的是cloudera产品的依赖,cdp hive中的元数据表字段与apache hive元数据表字段不一致,报错信息为: Operations not supported. Table xxx access type is: NONE
见https://issues.apache.org/jira/browse/IMPALA-10792
1.3 开始编译
编译之前在编译机器安装:
nginx
yum install boost boost-devel redhat-lsb python-devel cyrus-sasl-devel cyrus-sasl lzo-devel lzo gcc-c++ gcc cmake maven python pip python-devel开始编译
cs
[root@wqg apache-impala-4.2.0]# export IMPALA_HOME=`pwd`[root@wqg apache-impala-4.2.0]# bin/bootstrap_system.sh...[root@wqg apache-impala-4.2.0]# $IMPALA_HOME/buildall.sh -noclean -notests注:中间编译遇到了很多异常后面会统一贴出
说明: 本次编译并没有调整过多版本,大多采用默认版本号,因此兼容性不是最佳,目前还未发现问题
编译参考网址:
impala官方文档:https://cwiki.apache.org/confluence/display/IMPALA/Impala+Home
编译文档: https://cwiki.apache.org/confluence/display/IMPALA/Building+Impala
二、impala安装部署(单节点)
其实多节点也就是在其他节点部署impala daemon 步骤一样的
2.1 打包分发解压
将编译好的文件打包从192.168.242.130 分发至 192.168.242.230
解压后的目录: /opt/apache/apache-impala-4.2.0
bash
mkdir /opt/apache_v00/hadoop-3.3.5/hdfs-sockets#后面配置需要2.2 配置文件
hdfs-site.xml
在hdfs-site.xml配置文件中新增以下内容,配置完成后将其分发至其他节点以及hive的配置路径下
xml
<!--impala所需配置--><property> <name>dfs.client.read.shortcircuit</name> <value>true</value></property>
<property> <name>dfs.domain.socket.path</name> <value>/opt/apache_v00/hadoop-3.3.5/hdfs-sockets/dn</value></property>
<property> <name>dfs.client.file-block-storage-locations.timeout.millis</name> <value>10000</value></property> <property> <name>dfs.datanode.hdfs-blocks-metadata.enabled</name> <value>true</value> </property>hive-site.xml
在hive的conf下编译hive-site.xml新增以下内容然后分发到其他节点
xml
<!--impala所需--><property> <name>hive.metastore.dml.events</name> <value>true</value></property>重启hadoop、hive相关组件服务
2.3 state_store_flags配置
我的是在/opt/apache_v00/apache-impala-4.2.0/conf,配置文件路径位置可以任意
ini
-state_store_pending_task_count_max=0-max_log_files=10-state_store_port=24000-enable_webserver=true-webserver_port=25010-state_store_num_server_worker_threads=4-log_filename=statestored-minidump=9-hostname=apache230.hadoop.com2.4 catalogserver_flags配置
ini
-catalog_service_port=26000-max_log_files=10-hms_event_polling_interval_s=2-load_auth_to_local_rules=false-load_catalog_in_background=false-webserver_port=25020-server_name=apache230.hadoop.com-ranger_app_id=impala-authorization_provider=ranger-ranger_service_type=hive-catalog_topic_mode=minimal-log_filename=catalogd-state_store_subscriber_timeout_seconds=30-state_store_host=apache230.hadoop.com-state_store_port=240002.5 impalad_flags配置
ini
-server-name=apache230.hadoop.com-ranger_service_type=hive-ranger_app_id=impala-authorization_provider=ranger-state_store_host=apache230.hadoop.com-catalog_service_host=apache230.hadoop.com-catalog_service_port=26000-hostname=apache230.hadoop.com-beeswax_port=21000-fe_port=21000-be_port=22000-use_local_catalog=true2.6 启动impala相关服务
bash
export IMPALA_HOME=/opt/apache_v00/apache-impala-4.2.0export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:${IMPALA_HOME}/fe/target/impala-frontend-4.2.0-RELEASE.jar:$(echo ${IMPALA_HOME}/fe/target/dependency/*.jar | tr ' ' ':'):${HADOOP_HOME}/etc/hadoop/core-site.xml:${HADOOP_HOME}/etc/hadoop/hdfs-site.xmlexport CLASSPATH=\/root/libthrift-0.16.0.jar:\${HADOOP_HOME}/etc/hadoop:\"$IMPALA_HOME"/fe/src/test/resources:\"$IMPALA_HOME"/fe/target/dependency:\"$IMPALA_HOME"/fe/target/impala-frontend-4.2.0-RELEASE.jar:\"$IMPALA_HOME"/fe/target/impala-frontend-4.2.0-RELEASE-tests.jar:$CLASSPATH
cd /opt/apache/apache-impala-4.2.0/be/build/debug/servicenohup ./statestored start --flagfile=/etc/impala/conf/state_store_flags > statestored.log 2>&1 &nohup ./catalogd start --flagfile=/etc/impala/conf/catalogserver_flags > catalogd.log 2>&1 &./impalad start --flagfile=/opt/apache_v00/apache-impala-4.2.0/conf/impalad_flags2.7 连接测试
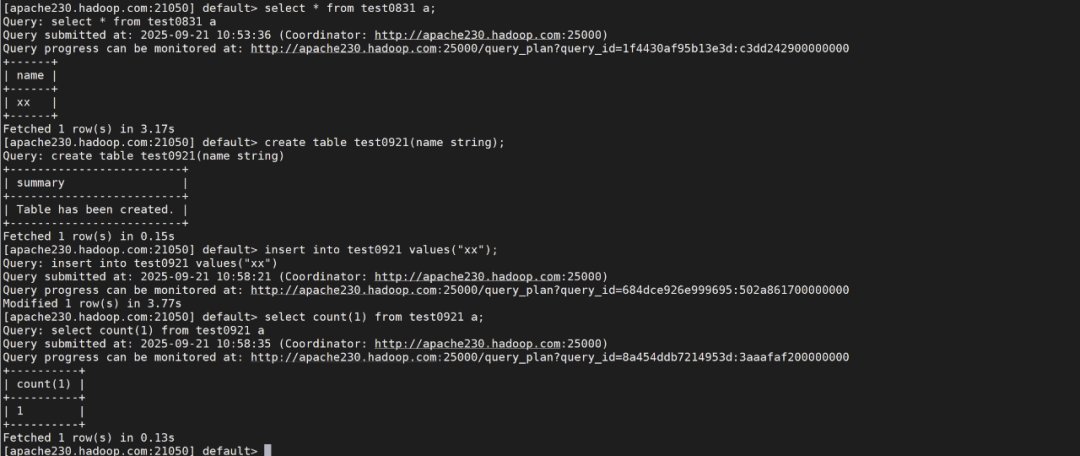
impala-shell -i apache230.hadoop.com:21000 -d default --protocol=beeswax
impala-shell -i apache230.hadoop.com:21050 -d default (默认走21050端口)