一.存储过程
1.什么是存储过程
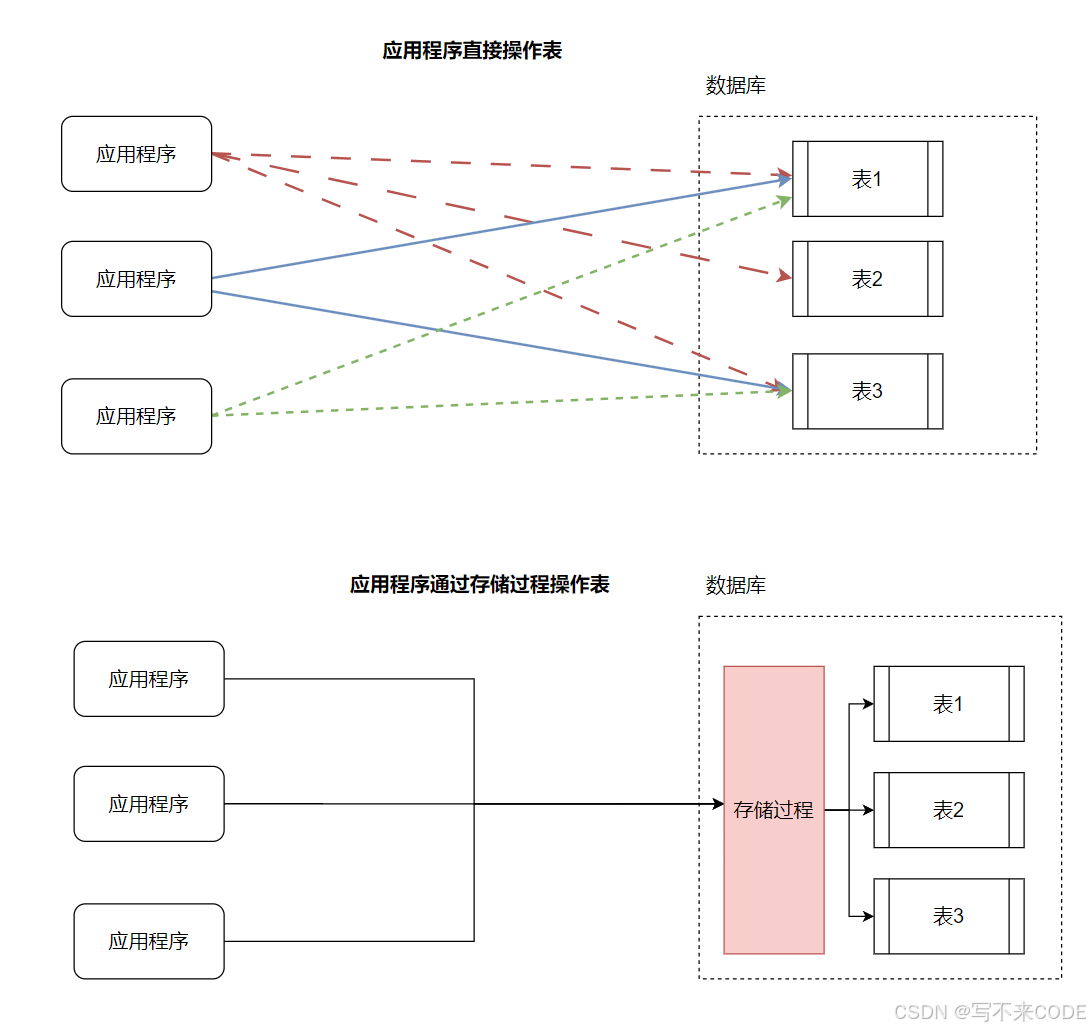
存储过程是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字和参数来执行,并获取相应的结果。
存储过程类比于C++中的函数。在项目中,当用户进行某种操作后,服务器端就要对用户的数据进行更新(比如游戏中的天梯分数,玩家赢了一局,此时我们就要调用对应的接口,对玩家的分数进行更新,并且写入到数据库中),这一业务逻辑是直接在应用层实现的。而存储过程则是将这一步移到了数据库中,即更新游戏天梯分数的这一步直接交由数据库层完成。
1.1.存储过程的特点
- 封装性:将业务逻辑封装在数据库内部,减少应用程序的复杂性;
- 可维护性:集中管理数据库操作,便于维护和更新,表结构更新了,不必修改应用层,做到一处修改,处处生效;
- 可重用性:像函数一样,编译好后可以被多次调用,提高代码的重用性。
1.2.存储过程的优缺点
优点:
性能优化:存储过程在创建好后编译并存储在数据库中,执行速度比单个SQL快;
代码重用:存储过程可以重复调用,减少重复代码,提高代码的可维护性;
安全性:可以限制应用层直接访问数据库,通过存储过程间接访问,从而保证数据库的安全性;
事务管理:可以在存储过程中实现复杂的事务逻辑;
降低耦合:当表结构发生变化时,只需要修改相应的存储过程,应用程序的改动小
缺点:可移植性差:存储过程不能跨数据库移植,更换数据库时需要重新编写;
调试困难:少数数据库支持存储过程的调试;
不适合高并发场景:在高并发场景下,同时有上万条SQL语句要数据库执行,如果此时再让数据库自己实现业务逻辑(存储过程)无异于雪上加霜。
2.创建存储过程的语法
sql
DELIMITER // -- 修改SQL语句的结束符
-- 创建存储过程
CREATE PROCEDURE name(参数列表)
BEIGN
... -- SQL语句
END//
DELIMITER ; -- 重设SQL语句的结束符
-- 调用存储过程
CALL name();
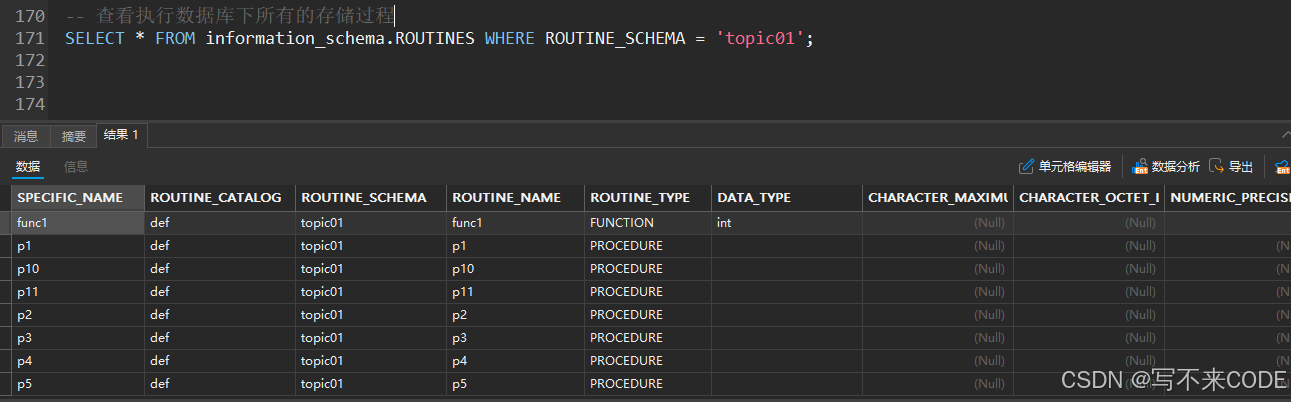
-- 查看指定数据库中的存储过程
SELECT * FROM information.schema.ROUTINES WHERE ROUTINE_SCHEMA = '数据库名';
-- 查看定义存储过程的具体细节
SHOW CREATE PROCEDURE 存储过程名;
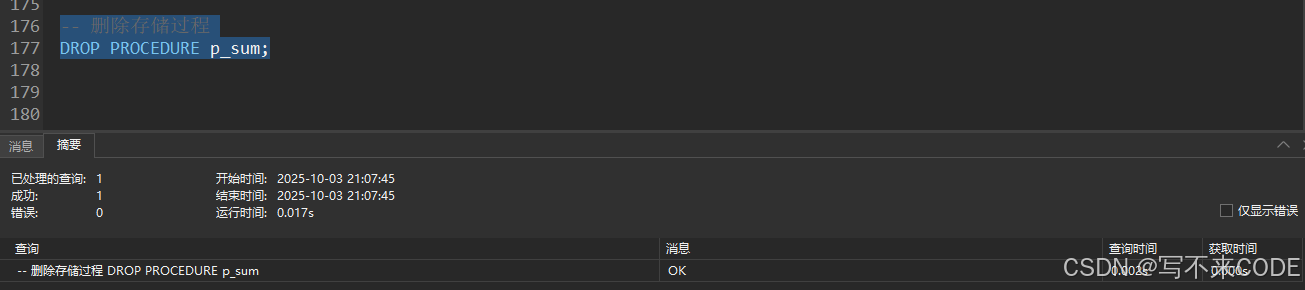
-- 删除存储过程
DROP PROCEDURE 存储过程名;DELIMITER // :
修改SQL语句的结束符,在图形化界面上写SQL时,会根据缩进来确认一个SQL的结束。但是在命令行,默认是以";"作为一个SQL的结束,如果在begin和end之间,SQL语句出现了";",就认为结束了。会导致我们的存储过程被解析失败。
delimiter // 的作用就是将SQL语句的结束符修改为另一个不容易冲突的符号,这样在解析SQL语句时就会以//作为结束符,而不会遇到分号提前结束
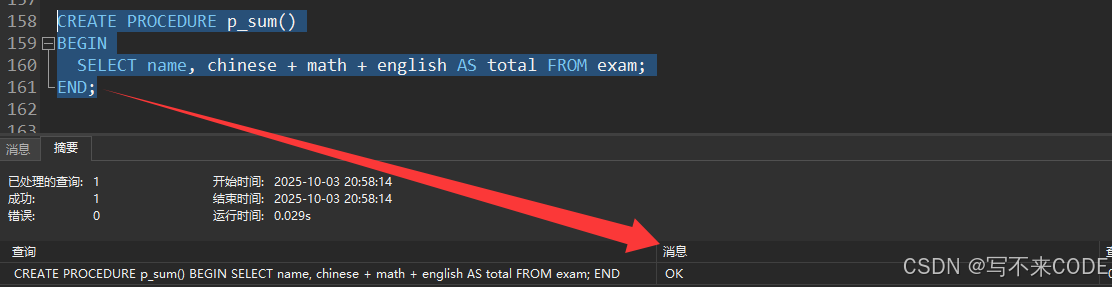

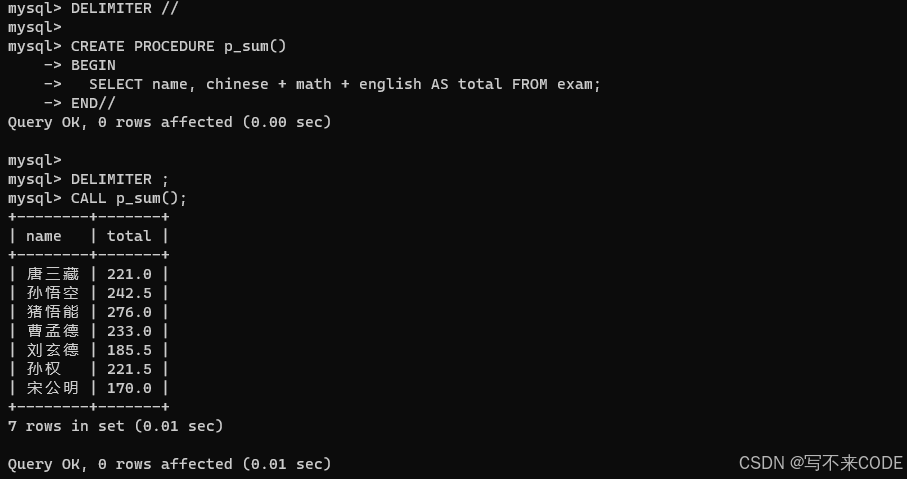
2.1利用存储过程,查看所有学生的姓名以及对应的总分
sql
DELIMITER //
CREATE PROCEDURE p_sum()
BEGIN
SELECT name, chinese + math + english AS total FROM exam;
END//
DELIMITER ;
CALL p_sum(); -- 调用存储过程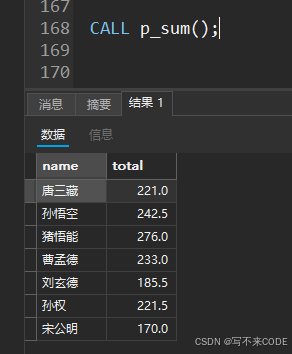

二.变量
MySQL中变量分为三类:系统变量,用户自定义变量,局部变量。
1.系统变量
系统变量是MySQL服务器的配置变量,控制着服务器的行为和性能。
分为全局系统变量和会话系统变量,全局系统变量由配置文件来,会话系统变量由全局来。
查看系统环境变量
sql-- 查看所有系统变量 show global variables; show session variables; -- 进行模糊匹配,%用作通配符 show global variables like 'auto%'; show session variables like 'auto%'; -- select @@global.具体系统变量名; @@表示系统变量 select @@session.autocommit;设置系统环境变量
sql-- 设置系统环境变量 set session autocommit = 0; set @@global.autocommit = 0;
- 如果没有指定session/global,默认修改和查询都是session系统变量;
- 不论是对会话还是全局的系统变量进行修改,都只是内存级的,MySQL重启后就会重置。想要永久修改系统变量,则需要修改配置文件。
2.用户自定义变量
- 用户自定义变量,用一个@表示
- 用户自定义变量在当前会话有效,通常用来定义一些查询的中间结果,或者表示一些条件,方面后面的查询使用
- 在定义用户自定义变量时,既可以使用 = ,也可以使用:=,但=又可以用来作为判断等于,所以为了避免歧义,推荐使用:=
sql
set @age = 18;
set @age := 99;
select @age := 100;
select count(*) into @stu_count from student;如果在select后面直接使用 = 则表示比较,不是赋值。
3.局部变量
局部变量,只在存储过程、函数、触发器中有效。使用时需要使用declare声明,作用域在begin end之间。
declare name type default 值 -- 声明局部变量
set name = 值; -- 局部变量赋值
set name := 值; -- 赋值
select 列名 into name from 表名; -- 赋值,将查询结果赋值给局部变量
sql
delimiter //
-- 创建存储过程
create procedure p_count()
BEGIN
-- 实现方法,定义局部变量
DECLARE stu_count int default 0;
-- 给局部变量赋值
select count(*) into stu_count from student;
select stu_count;
END//
delimiter;
-- 调用存储过程
call p_count();4.注意事项
- 变量名不区分大小写;
- 在存储过程和函数中,局部变量必须在使用前声明;
- 用户自定义变量在会话结束时失效,而局部变量在存储过程/函数结束时失效;
三.SQL编程
结构化查询语⾔(Structured Query Language)简称SQL,是⼀种特殊的编程语⾔,是⼀ 种数据库查询和程序设计语⾔,⽤于存取数据以及查询、更新和管理关系数据库系统。
1.if语句
使用if语句,根据分数,判断等级:
sql
-- if语句
delimiter //
create procedure p1()
BEGIN
declare score int DEFAULT 86;
declare result varchar(10);
if score >= 90 THEN
set result := '优秀';
elseif score >= 80 and score < 90 THEN
set result := '良好';
elseif score >= 60 and score < 80 THEN
set result := '及格';
else
set result := '不及格';
end if;
select result;
END//
delimiter;
call p1();2.SQL参数
-- 参数分为 IN(输入) OUT(输出) INOUT(输入输出)
-- 对于输入型参数而言,只做为参数传递
-- 对于输出型参数而言,没有初始值,只用作接收结果
-- 对于输入输出型参数而言,既可以传递值,也可以接收值
sql
delimiter //
create procedure p2(in score int, out result varchar(10))
BEGIN
if score >= 90 THEN
set result := '优秀';
elseif score >= 75 and score < 90 THEN
set result := '良好';
elseif score >= 60 and score < 75 THEN
set result := '及格';
ELSE
set result := '不及格';
end if;
end//
delimiter;
call p2(90, @result);
select @result;
-- 输入输出型参数
delimiter //
create procedure p3(inout score int)
BEGIN
set score := score + 10;
end//
delimiter;
set @score := 999;
call p3(@score);
select @score;3.case语句
在SQL中,case语句有两种写法,第一种即C++中的switch case语句;第二种即是对if else的一种变形
每一个选项下的语句可以是一句也可以是多句但不允许为空。可以使用begin end。
sql
delimiter //
create procedure p4(IN code INT, OUT result VARCHAR(50))
BEGIN
CASE code
WHEN 0 THEN
set result := 'ok';
WHEN 1 THEN
set result := 'warning';
WHEN 2 THEN
set result := 'error';
WHEN 3 THEN
set result := 'fatal';
ELSE
set result := 'unknow';
END CASE;
END//
delimiter ;
call p4(-1, @result);
select @result;
delimiter //
create procedure p5(IN month int, OUT result VARCHAR(50))
BEGIN
case
when month >= 3 and month <= 5 THEN
set result := '春季';
when month >= 6 and month <= 8 THEN
set result := '夏季';
when month >= 9 and month <= 11 THEN
set result := '秋季';
when month = 12 or month = 1 or month = 2 THEN
set result := '冬季';
ELSE
set result := 'unknow';
end case;
END//
delimiter ;
call p5(97, @result);
select @result;4.while循环
类似于C++中的while循环,循环条件:是否继续的条件,满足则进入循环。
sql
delimiter //
CREATE PROCEDURE p6(IN n INT)
BEGIN
-- 定义结果和
DECLARE sum INT DEFAULT 0;
-- 循环
WHILE n > 0 DO
SET sum := sum + n;
SET n := n - 1;
END WHILE;
SELECT sum;
END//
delimiter ;5.repeat循环
类似于do while循环,判断条件为true,退出循环,即repeat的判断条件是退出条件
sql
delimiter //
CREATE PROCEDURE p7(IN n INT)
BEGIN
-- 定义结果和
DECLARE sum INT DEFAULT 0;
-- repeat循环
REPEAT
SET sum := sum + n;
SET n := n - 1;
UNTIL n <= 0 END REPEAT;
SELECT sum;
END//
delimiter ;6.loop循环
本质上是一个死循环,需要通过循环体内部的if条件控制循环
leave 跳出循环,iterate 跳出本次循环
使用loop循环时,要对loop循环起一个名字,用来后序指定跳出循环
sql
-- 计算1 ~ n的和
delimiter //
CREATE PROCEDURE p8(IN n INT)
BEGIN
DECLARE sum INT DEFAULT 0;
sum_lable : LOOP
-- 循环退出条件
IF n <= 0 THEN
LEAVE sum_lable;
END IF;
SET sum := sum + n;
SET n := n - 1;
END LOOP sum_lable;
SELECT sum;
END//
delimiter ;
-- 使用loop循环,跳过某次循环:只计算1~n的偶数和
delimiter //
CREATE PROCEDURE p9(IN n INT)
BEGIN
DECLARE sum INT DEFAULT 0;
sum_lable : LOOP
IF n <= 0 THEN
LEAVE sum_lable;
END IF;
IF n % 2 = 1 THEN
SET n := n - 1;
ITERATE sum_lable;
END IF;
SET sum := sum + n;
SET n := n - 1;
END LOOP sum_lable;
SELECT sum;
END//
delimiter ;四.游标
游标是MySQL数据库中的一个数据库对象,用来在存储过程/函数中对查询到的结果集进行逐行检索。
游标四板斧:
- DECLARE 游标名 cursor for 查询语句; -- 声明游标
- open 游标名; -- 打开游标
- fetch 游标名 into 变量 -- 使用游标检索结果集 ,将检索到的结果写入到变量中,该变量必须提前声明
- close 游标名; -- 关闭游标
使用下述存储过程时,会遇到一个问题,我们通过游标遍历结果集时,怎么退出循环呢?当然时遍历到越界就结束,可是怎么判断是否越界呢?游标并没有规定。
如下代码,一致检索,当检索到结束位置时,此时继续检索,就会出错:表示没有数据
要解决这个问题,我们需要结合条件处理程序来解决!!!
sql
delimiter //
CREATE PROCEDURE p10(IN class_id INT)
BEGIN
-- 新表字段,用来存储游标检索到的变量
DECLARE student_name VARCHAR(32);
DECLARE class_name VARCHAR(32);
-- 创建游标
DECLARE stu_cursor CURSOR FOR
SELECT s.name student_name, c.name class_name
FROM class c inner join student s on c.id = s.class_id where c.id = class_id;
-- 创建新表
DROP TABLE IF EXISTS t_student_class;
CREATE TABLE t_student_class(
id BIGINT PRIMARY KEY auto_increment,
student_name VARCHAR(32) NOT NULL,
class_name VARCHAR(32) NOT NULL
);
-- 打开游标
OPEN stu_cursor;
-- 使用游标检索结果集
WHILE TRUE DO
FETCH stu_cursor INTO student_name, class_name; -- TODO:如何结束循环,fetch最后肯定会遍历到空
-- 将检索结果插入到新表中
INSERT INTO t_student_class (student_name, class_name) values (student_name, class_name);
END WHILE;
-- 关闭游标
CLOSE stu_cursor;
END//
delimiter ;五.条件处理程序
条件处理程序就类似于C++中的异常机制,使用条件处理程序 保证存储过程/函数在遇到警告或者错误时能继续执行,可以增强程序处理问题的能力,避免程序异常停止运行。
- 定义条件,事先定义好可能出现的问题
- 处理程序,定义遇到问题所采取的处理方法
语法
sql-- 语法 -- 声明条件处理程序 DECLARE handler_action HANDLER FOR condition_value[多个] statement -- handler_action就是遇到问题后,应该怎么处理,是直接退出,还是继续向下运行 handler_action:{ CONTINUE | EXIT } -- condition_value 即可能遇到的问题所对应的错误码,有mysql级别的,也有sql级别的 condition_value { mysql_error_code -- MySQL错误码 SQLSTATE[value]sqlstate_value -- 状态码 SQLWARNING -- 所有01开头的SQLSTATE的状态码 NOT FOUND -- 所有02开头的SQLSTATE状态码 SQLEXCEPTION -- 其他状态码 }
使用条件处理程序,解决使用游标导致访问空行
sql
DROP PROCEDURE IF EXISTS p11;
delimiter //
CREATE PROCEDURE p11(IN class_id INT)
BEGIN
-- 定义变量
DECLARE student_name VARCHAR(32);
DECLARE class_name VARCHAR(32);
DECLARE is_done bool DEFAULT FALSE;
-- 声明游标
DECLARE stu_cursor CURSOR FOR
SELECT s.name student_name, c.name class_name
FROM class c inner join student s on c.id = s.class_id where c.id = class_id;
-- 声明条件处理程序
DECLARE CONTINUE HANDLER
FOR NOT FOUND
SET is_done := TRUE;
-- 创建新表
DROP TABLE IF EXISTS t_student_class;
CREATE TABLE t_student_class(
id BIGINT PRIMARY KEY auto_increment,
student_name VARCHAR(32) NOT NULL,
class_name VARCHAR(32) NOT NULL
);
-- 打开游标
OPEN stu_cursor;
-- 使用游标进行检索结果集
-- 如果使用while循环进行检索,当fetch遍历到空出错时,虽然is_done已经被设置为ture,但处理程序为继续向下运行
-- 此时会将游标重置为上一次使用的位置,并且继续执行之后的代码,导致重复插入最后一行
-- 所以,我们这里使用loop循环,手动控制循环退出条件
-- WHILE NOT is_done DO
-- FETCH stu_cursor INTO student_name, class_name;
--
-- INSERT INTO t_student_class (student_name, class_name) VALUES (student_name, class_name);
-- END WHILE;
stu_loop: LOOP
FETCH stu_cursor INTO student_name, class_name;
IF is_done THEN
LEAVE stu_loop;
END IF;
INSERT INTO t_student_class (student_name, class_name) VALUES (student_name, class_name);
END LOOP stu_loop;
-- 关闭游标
CLOSE stu_cursor;
END//
delimiter ;注意:
条件处理程序必须声明在游标之后,局部变量要声明在存储过程/函数的最前面。
六.存储函数
存储函数,带有返回值的存储过程,并且要求参数只能是IN类型,在指定参数时,不需要指定IN类型,否则会报错。
存储函数与存储过程唯一的区别就是,存储函数一定有返回值,存储过程可以有可以没有(通过输出型参数)。
1.语法
sql
-- 定义存储函数的语法
CREATE FUNCTION name(参数列表)
RETURNS type [characteristic...]
BEGIN
...
RETURN ...;
END;
-- 在MySQL8.0,默认开启了binlog,如果开了binlog,定义存储函数时,需要指定characteristic
-- 指定characteristic并不会对存储函数进行修改,是在MySQL底层起某种作用
characteristic:
[NOT] DETERMINISTIC -- 相同的输入,结果总是一致
NO SQL -- 不包含SQL语句
READS SQL -- 包含读取数据的SQL语句
MODIFIES SQL -- 包含写入数据的SQL语句2.使用存储函数,实现1~n的累加
sql
-- 定义存储函数,使用1~n的累加
delimiter //
CREATE FUNCTION func1(n INT)
RETURNS INT DETERMINISTIC
BEGIN
DECLARE sum INT default 0;
WHILE n > 0 DO
SET sum := sum + n;
SET n := n - 1;
END WHILE;
RETURN sum;
END//
delimiter;
-- 调用存储函数与调用MySQL的内置函数一致,使用select + 存储函数名()
SELECT func1(10);
七.触发器
- 触发器是一个与表关联的数据库对象,在对表进行insert、update、delete时,触发并执行定义触发器时的SQL语句。
- 触发器可以在对表的操作之前/之后执行,称为触发时间,before,after
- 触发器可以执行SQL语句或其他逻辑块,用于实现复杂的业务逻辑/数据验证
- MySQL支持3中触发器类型,insert、update、delete触发器。在触发器中使用new/old关键字访问操作后的数据
- 行级触发器,修改了多少行,就调用多少次
- 语句级触发器,调用了多少次修改语句,执行多少次触发器
- MySQL只支持行级触发器
sql
-- 定义触发器的语法
CREATE TRIGGER trg_name
trigger_time, trigger_event -- 触发器的触发时间,以及因为什么事件导致触发器触发
ON table_name, FOR EACH ROW -- 触发器关联表明,行级触发器
BEGIN
trigger_stmt;
END;
-- 查看当前表中所有的触发器
SHOW TRIGGERS;
-- 查看定义触发器时的细节
SHOW CREATE TRIGGER trg_name;
-- 删除触发器
DROP TRIGGER IF EXISTS trg_name;通过触发器记录学⽣表的变更⽇志,将变更⽇志写⼊⽇志表student_log中,包含增加,修改和删 除操作。
sql
-- insert 触发器
delimiter //
CREATE TRIGGER IF NOT EXISTS trg_student_insert
AFTER INSERT
ON student FOR EACH ROW
BEGIN
-- 插入一条新记录时,将该修改记录到student_log中
INSERT INTO student_log (
operation_type,
operation_time,
operation_id,
operation_data
)
VALUES (
'insert',
now(),
new.id,
CONCAT(new.id, '-', new.name, '-', new.sno, '-', new.age, '-', new.gender, '-', new.enroll_date, '-', new.class_id)
);
END//
delimiter ;