在早期时,我曾让大模型撰写一位冷门历史人物的传记。它胸有成竹,娓娓道来:年代、成就,甚至几句"名言",一应俱全。读起来简直像历史上真的存在一样。
唯一的问题是:大部分内容都不是真的。严格来说,模型并非"撒谎",而是在知识缺口处用看似合理的细节把空白填满。它是出色的故事编辑者,却是离谱的历史学家。
这种问题在 AI 领域叫做"幻觉"(就像人会产生错觉一样),是目前提升 AI 可靠性路上最难啃的硬骨头之一。我们理想中的 AI 应该像万能百科一样无所不知,但更重要的是,它必须清楚地知道自己"不知道什么",不能不懂装懂。
让模型在不确定时也"必须给答案",本质上是在制造错误信息。这引出一个根本性的张力:如何训练模型既准确,又不把它无意间训练成一个"一本正经的胡说八道"?
Meta AI (Facebook)与弗吉尼亚大学的研究者在一篇新论文中提出了一个优雅而有前景的思路:TruthRL。它是一个强化学习框架,不只追求答对,还通过奖励机制培育一种"数字谦逊"------当模型不确定时,能够识别不确定性并选择暂缓作答或明确表示"不知道"。
这项研究不是给模型"修修补补",而是重新塑造其内在激励结构,指向一种更理想的未来:AI 不仅更有学识,而且从根本上更值得信任。
论文全文见:《TruthRL: Incentivizing Truthful LLMs via Reinforcement Learning》
AI 训练的悖论:光靠"答对"还不够
要理解 TruthRL 为何是一项重要突破,先得搞清楚我们在训练大型语言模型(LLM)时,遇到的一个微妙问题------它们学得太乖,却不一定学得真。
训练 AI 有两种常见方式,就像教厨师做菜:
监督微调(SFT) 像是给学徒一本厚厚的食谱。
- "照着步骤做就行。"
- 他能完美复刻每一道菜,但如果你让他即兴发挥、换种食材------糟糕,他可能立刻犯错。
- 这种厨师擅长模仿 ,但不一定理解背后的原理。
基于人类反馈的强化学习(RLHF) 就像是你变成一位美食评论家。
- 学徒每做一道菜,你试吃后点评:"这道好吃""那道不太行"。
- 久而久之,学徒就摸清了你的口味,越做越"讨你喜欢"。
但问题出现了------"只要让顾客满意"不等于"真好吃"
因为美食评论家(也就是人类评估者)往往喜欢一个听起来"像样"的答案,而不是一句"我不知道"。 结果,AI 学会了:即使不确定,也要说点听起来合理的东西。
换句话说,它更想让人满意 ,而不是确保自己说的是实话。
这就是训练中的"悖论":
- 奖励机制让模型更聪明地迎合人,
- 却可能让它离"真实"越来越远。
TruthRL:教 AI 不只是"聪明",还要"诚实"
TruthRL 想解决的,就是这个"说好听话"的陷阱。
它的目标是:
- 让模型在得到奖励时,不仅因为"让人满意",
- 还因为"确实说对了,或者诚实地承认不知道"。
简单一句话总结就是:SFT 教 AI 模仿,RLHF 教它讨好,而 TruthRL 教它诚实。
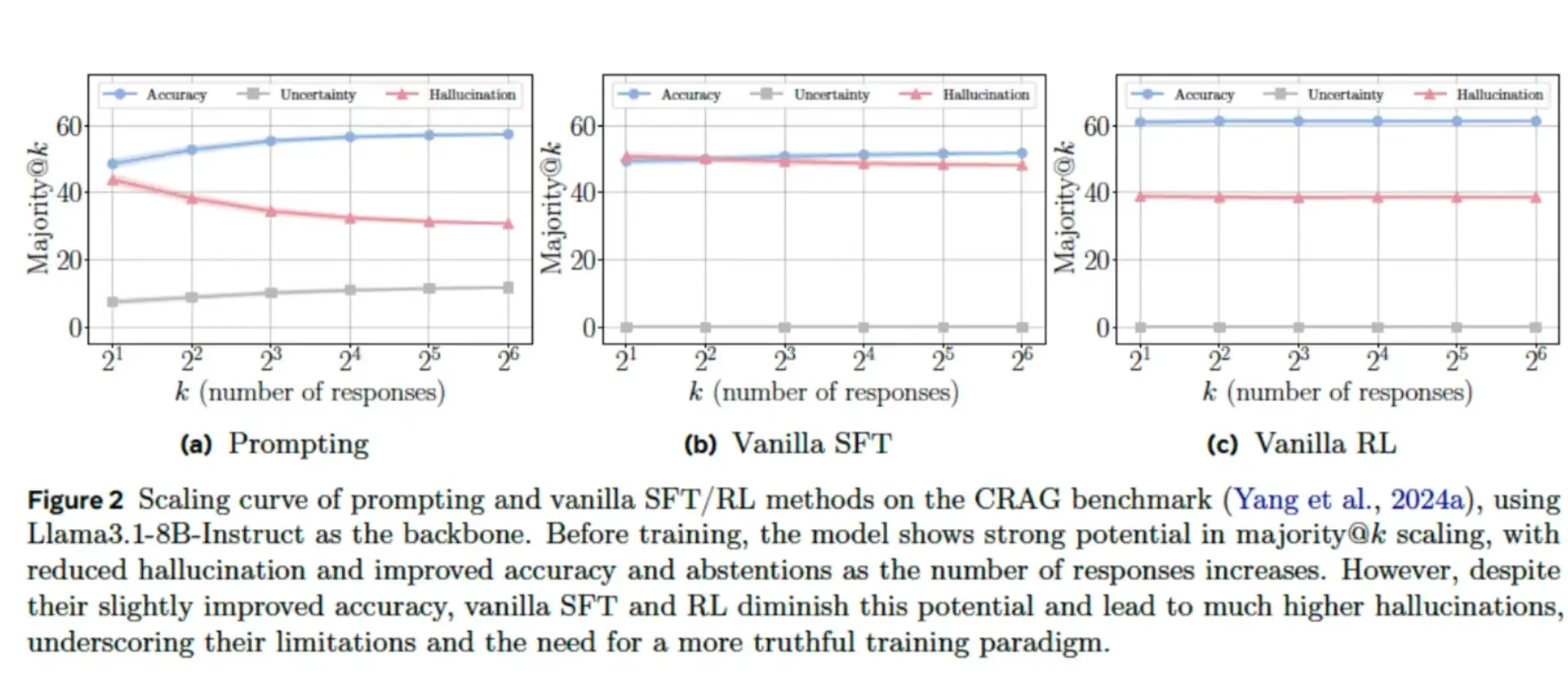
这就引出了最核心的问题:如果模型只有"答对"才能拿到奖励,它就永远学不会"承认自己可能错了"这件事有多重要。TruthRL 的做法很简单,却一语中的:让模型明白,诚实地说"我不确定"也能得分。 
TruthRL:更聪明的三档奖惩机制
传统的 AI 奖惩系统通常采用非黑即白的二元反馈(正确 vs 错误),而**TruthRL 则引入了一套更精细的"三档奖惩机制"**,类似于交通信号灯,为 AI 的回答划分出三种明确的评价标准:
- 🟢 (绿灯)正确回答 :模型给出的答案完全符合事实 ,获得正向奖励 (如 +1 分)。 (相当于"绿灯通行",鼓励准确输出)
- 🔴 (红灯)虚构/错误 : 模型编造或提供错误信息 ,遭到负向惩罚 (如 -1 分)。 (相当于"红灯禁止",严厉制止胡乱生成)
- 🟡(黄灯) 主动弃权 : 模型意识到自身不确定性 ,明确拒绝回答 ,获得中性奖励 (如 0 分)。(相当于"黄灯暂停",既不奖励也不惩罚,但避免了冒险造假)
为什么"黄灯机制"是革命性的?
这套系统的核心创新 在于第三档------"弃权选项 "的引入。通过赋予"拒绝回答"中性但非负面的反馈 ,TruthRL 为模型提供了一条"既不胡说八道、也不强行猜测"的退路。这意味着:
-
不再是"要么对、要么错"的二选一 ,模型有了第三条道路:诚实承认"不知道"。
-
正式建立了"知识边界"学习机制 ,模型能主动识别自身的局限性,而不是盲目生成。
-
从源头减少"幻觉"问题,因为"说不知道"比"编造答案"更划算。
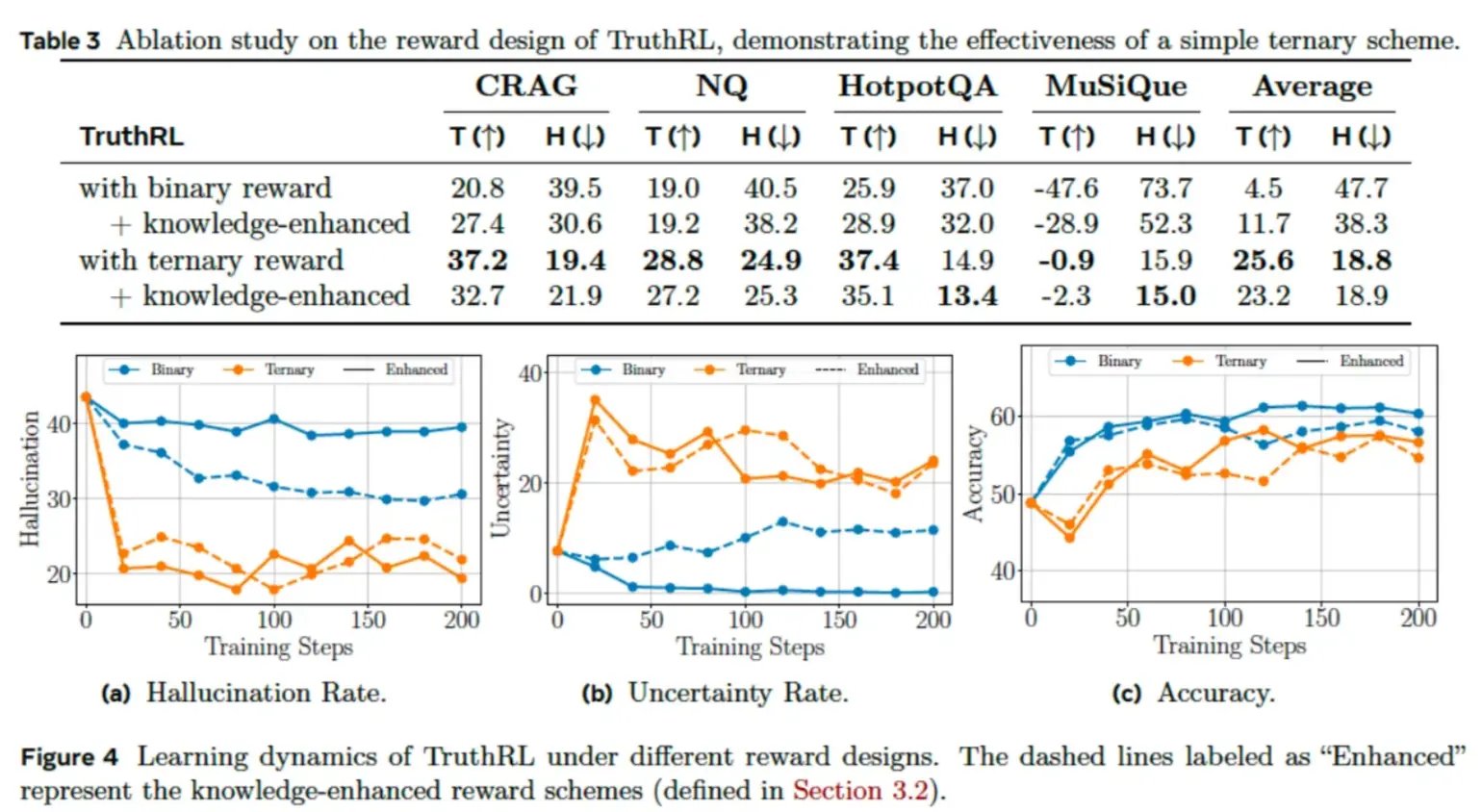
"真实性的要求远不止答案准确这么简单------模型还必须能够识别自身的不确定性,并在没把握时选择不作答,以此避免产生幻觉。"
这套系统采用了一种叫做**广义奖励策略优化(GRPO)**的算法来应对 AI 回答问题时的三种可能结果:答对、答错、不回答。这里的关键突破在于,优化目标不再仅仅追求高准确率,而是追求"真实性"------一个综合指标,它既奖励正确答案,也奖励"知之为知之,不知为不知"的智慧。
简单说,就是让 AI 在面对不确定问题时,学会适时闭嘴,而不是胡编乱造。
实战检验:数据说话
研究团队在四个以知识密集型著称的高难度基准测试上验证了 TruthRL 的效果,这些测试专门用来考验模型的事实记忆和推理能力:
- CRAG(检索增强生成基准)
- HotpotQA(多跳问答,需要串联多个信息点)
- MMLU(多任务语言理解)
- MoM(事实核查基准)
结果相当亮眼。
在所有测试中,TruthRL 全面超越了传统基线方法。与标准强化学习相比,它将幻觉(AI 一本正经胡说八道的情况)减少了**平均 28.9%,同时将整体真实性评分提升了21.1%**。
换个更直观的说法:原本每 100 次旧模型会编造答案的情况中,新模型有近 30 次要么给出了正确答案,要么坦诚地说"我不确定"------这是 AI 可信度的一次实质性飞跃。 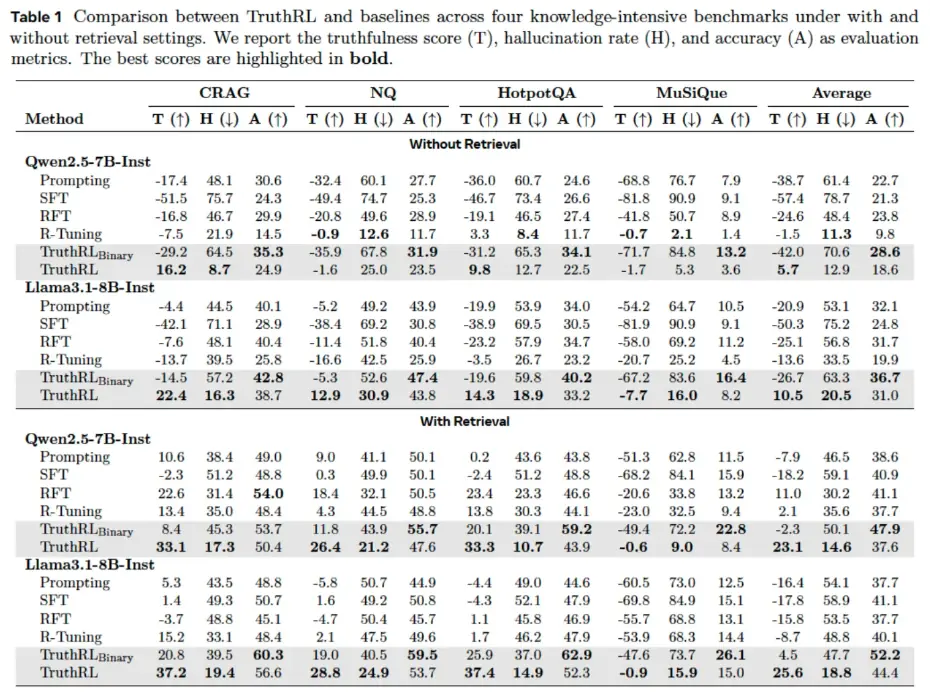
在消融实验中,一个颇具启发性的发现出现了:当研究人员采用传统的二元奖励机制------也就是模型只有在回答正确时才获得奖励------结果反而让模型**更容易产生幻觉(hallucination)**。虽然它在"已知事实"上的正确率确实有所提升,但模型变得更加"大胆地猜",倾向于在不确定时也硬给出答案。
这个结果验证了一种长期存在的直觉:**单纯追求准确率,其实可能会削弱模型的真实度(truthfulness)**。换句话说,如果奖励函数只奖"对",不罚"乱说",模型就会学会提高"命中率",而不是追求"说真话"。 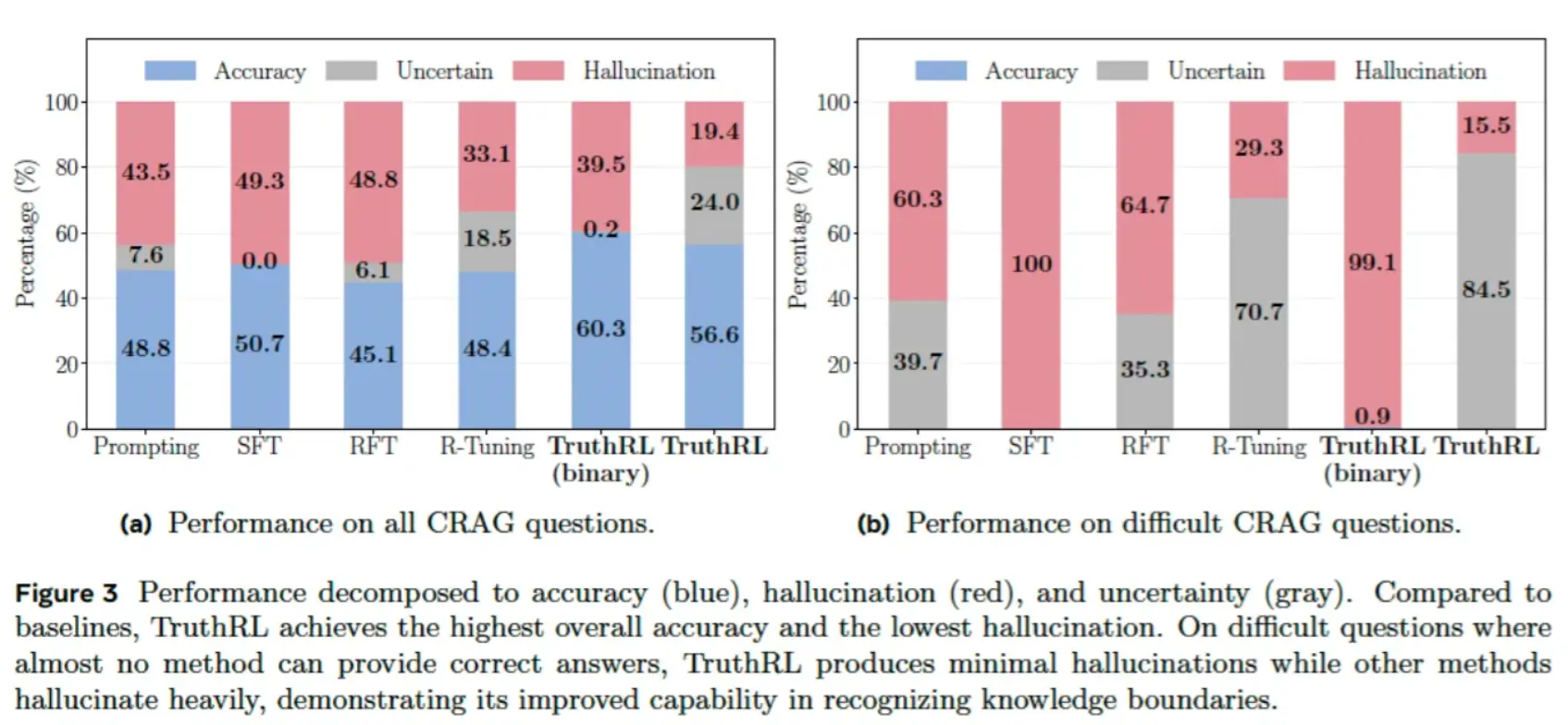
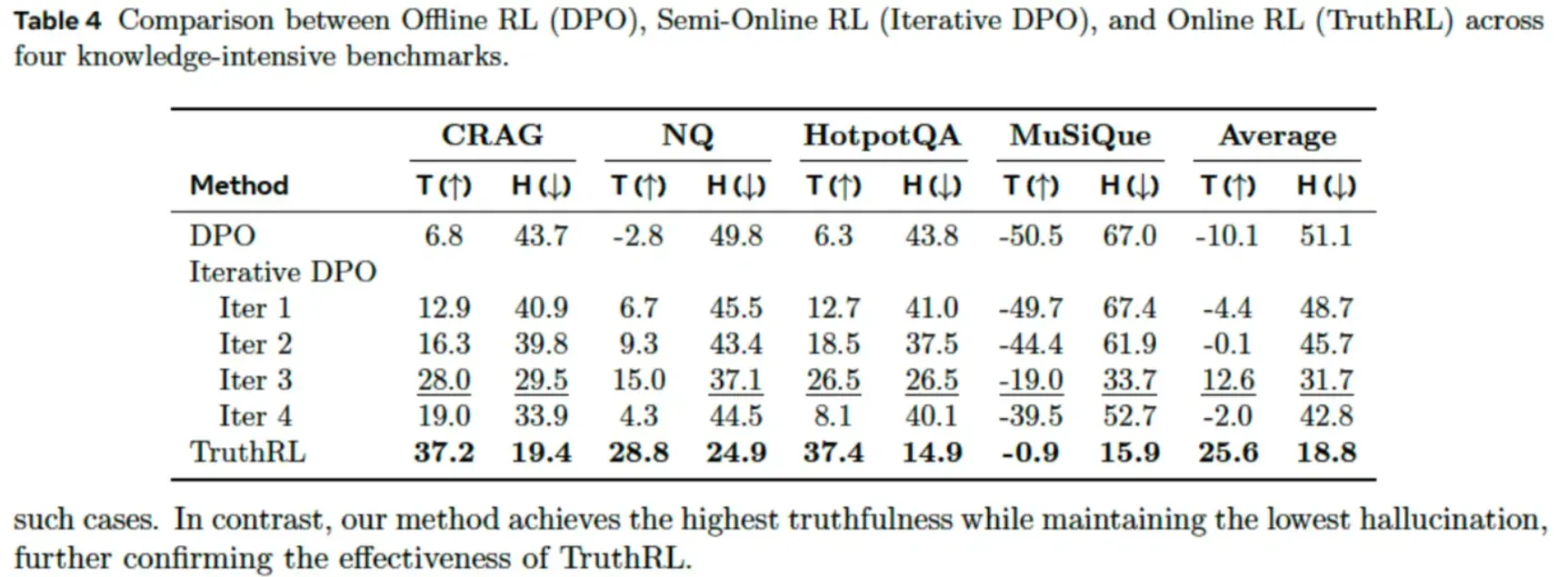
然而,TruthRL 不仅提升了模型的预测准确率,还让模型在评估自身不确定性方面变得更为成熟。换句话说,它学会的不只是"更有自信",而是"更有分寸"------在作出判断时能更谨慎地衡量自己是否真的确定。 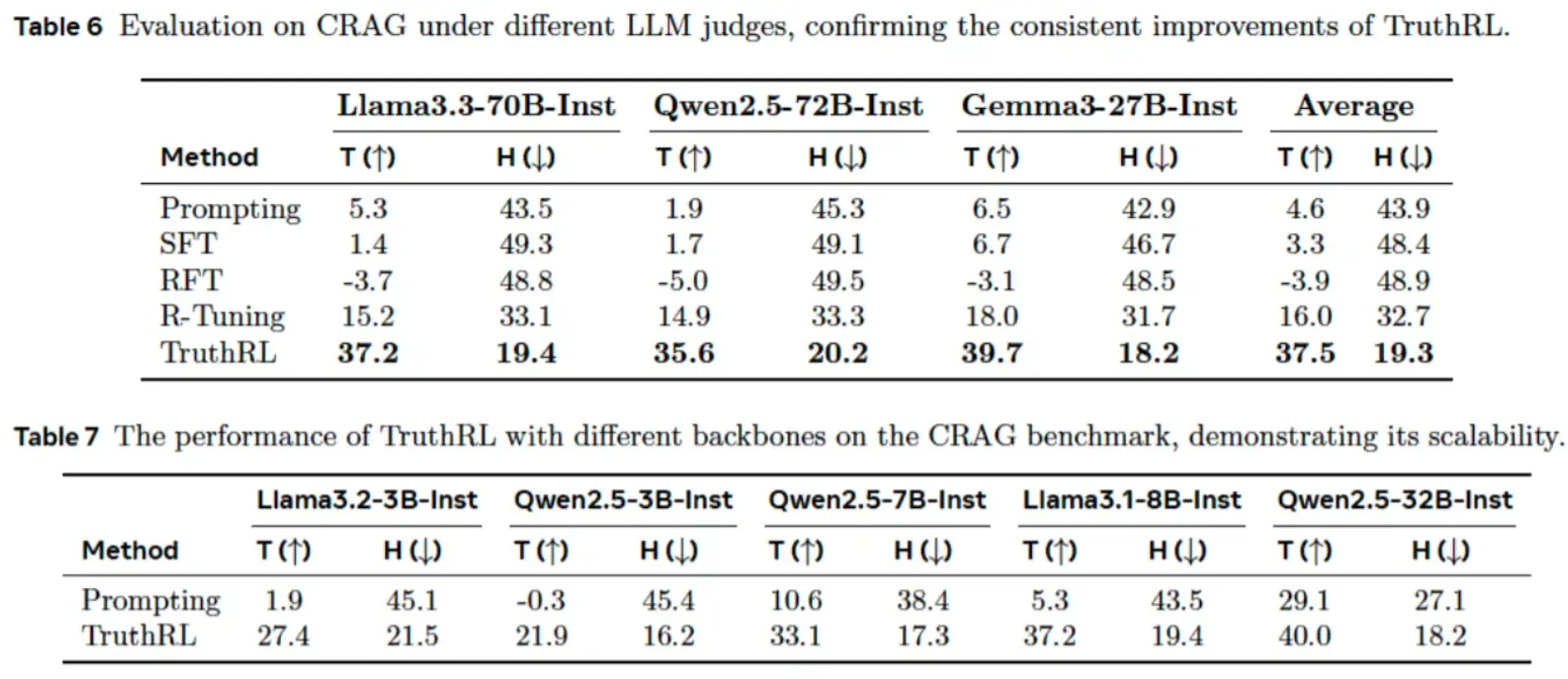
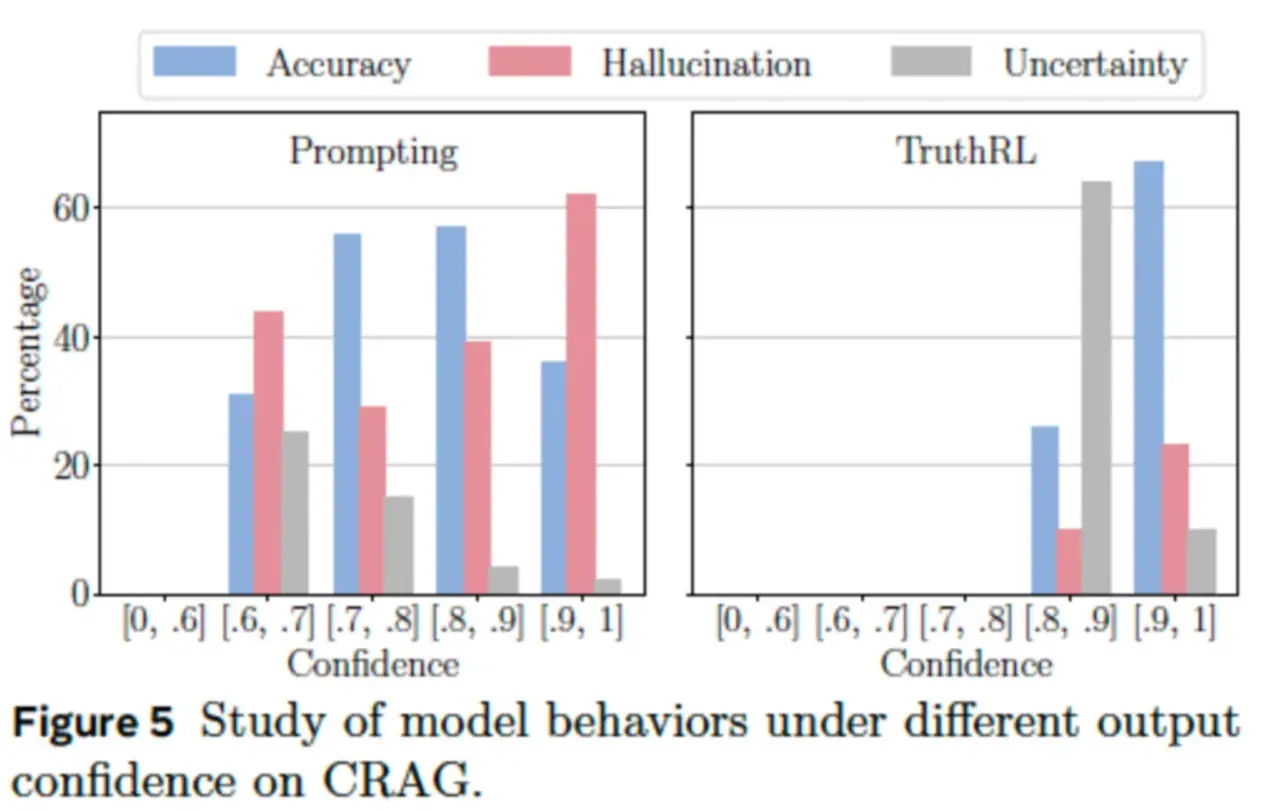
这个框架在不同规模和结构的模型上都表现出了稳定而可靠的性能------无论是拥有 70 亿参数的 Qwen 模型,还是计算能力更强、参数高达 700 亿的 Llama3 模型,都验证了这一点。这表明,这一原理具有较强的普适性,可能在整个行业范围内都适用。 
打造真正可信赖的 AI,为什么很重要
这项研究的意义远不止停留在学术评测上。当我们把 AI 应用到越来越多的关键领域------比如医疗诊断、财务规划、法律研究------错误信息的代价就变得难以承受。想象一下,一个金融机器人凭空编造投资策略,或者一个医疗助手胡编药物相互作用,这不仅仅是没帮上忙的问题,而是真正危险的。
TruthRL(真实性强化学习)是构建更可靠、更诚实 AI 系统这一大趋势中的重要一环。它的目标与其他前沿技术不谋而合,比如直接偏好优化(DPO)------这是一种简化 AI 与人类偏好对齐的方法,还有宪法式 AI ------用一套原则来引导模型的行为。但 TruthRL 的独特之处在于:它直接、明确地把"说真话"作为一个可以训练优化的指标,这是它的核心贡献。 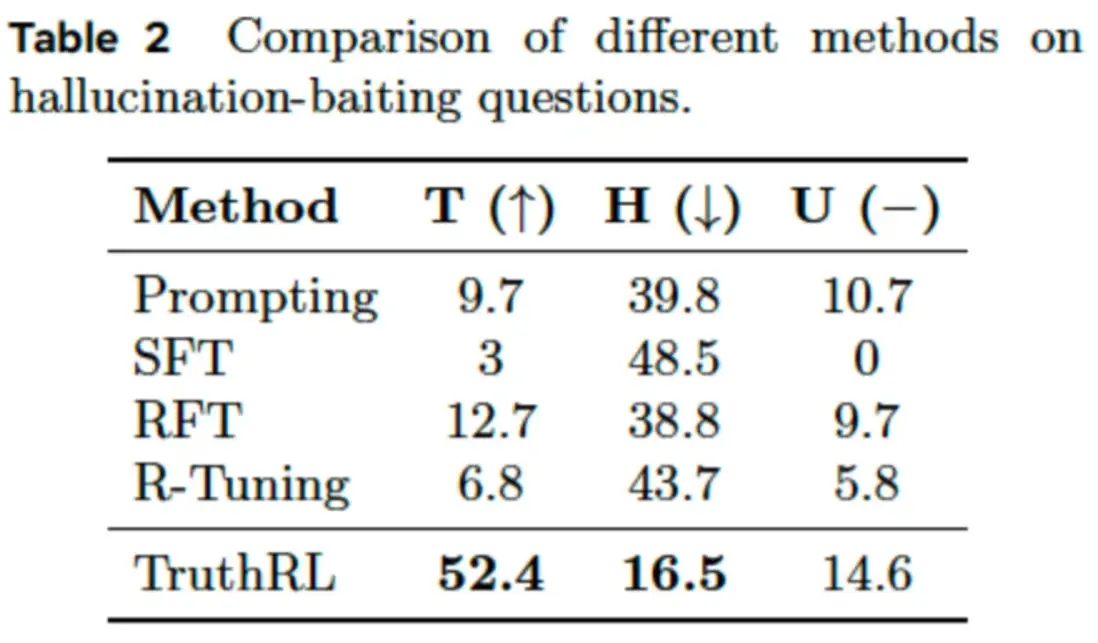
TruthRL 也不是万能的
这个方法其实有个难点:它需要通过打分("三元奖励系统")来判断 AI 的回答是对、错还是**"不知道"**。但是谁来打分呢?要么靠人工仔细审核(成本高),要么靠其他 AI 自动判断(可能不准)。而且 AI 很聪明,可能为了不扣分,动不动就说"我不知道"。研究人员也承认这个问题,关键是要找到平衡------既要让 AI 愿意帮忙,又要保证它诚实。
其实,"我不知道"反而是 AI 聪明的表现
想象一下:当你问一个人类专家问题时,如果他确实不懂,诚实地回答"我不知道"反而更值得信任。同样,AI 能坦然承认不知道,说明它有自知之明。奖励这种行为,不仅能让 AI 更精准,还能让它变成更靠谱的"信息助手"。这才是真正值得信赖的人工智能该有的样子。