别再被引用坑了!JavaScript 深浅拷贝全攻略
一、为什么需要拷贝函数
在 JavaScript 中,数据类型分为两种:值类型 (基本类型)和 引用类型(对象类型),二者在存储方式与赋值行为上存在明显差异。
值类型包括 number 、string 、boolean 等,这些类型的变量会直接保存在栈内存 中,在复制的时候会创建一个该值的全新副本,新旧变量互不影响。 就像复印一份文档,原文档和复印件是完全独立的。
引用类型包括 object 、array 等,这些类型的变量会将数据保存在堆内存 中,同时会在栈内存中存储该变量数据在堆内存中的引用 (地址),在复制时也只会复制这些数据的引用,实际在堆内存中保存的数据仍然只有一份。 就像复印了一份文件的目录,原文件和复印件都指向同一个文件。
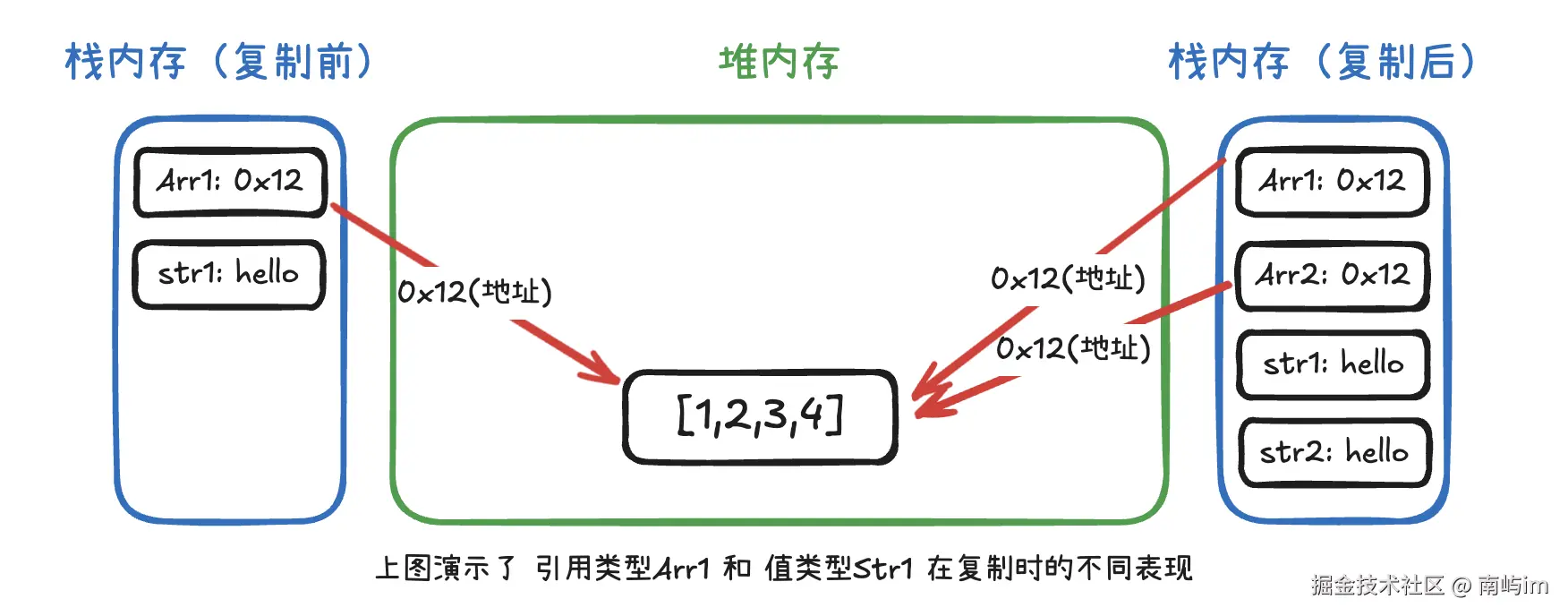
由于引用类型的存储方式机制,导致通过一个引用类型变量直接赋值给另一个引用类型变量时,当前一个变量的内容发生了修改时,被赋值的变量仍然会发生同样的改变。这种特性在实际开发中经常会导致一些意外的 bug,比如:
javascript
const user = { name: "John", preferences: { theme: "dark" } };
const admin = user;
admin.preferences.theme = "light";
console.log(user.preferences.theme); // 'light' - 意外修改了原始数据拷贝函数的核心目的就是为了解决数据独立的问题,尤其是在处理引用类型时,避免直接赋值后导致数据被意外修改的情况。在实际开发中,这种场景非常常见,比如:
- 处理表单数据时,需要保存原始数据的副本
- 实现撤销/重做功能时,需要保存数据的历史版本
- 在状态管理中,需要确保数据的不可变性
- 在组件间传递数据时,需要避免数据污染
二、浅拷贝与深拷贝的概念解析
拷贝函数根据其复制的深度分为浅拷贝 与深拷贝。这两种拷贝方式就像复印文件的不同方式:
-
浅克隆就像只复印了文件的第一页,如果文件中包含其他文件的引用,那么这些引用仍然指向原来的文件。浅克隆的核心思想是只复制对象的第一层属性,对于嵌套的对象或数组,只复制引用而不复制内容。
-
深克隆就像复印了整个文件,包括其中引用的所有文件。深克隆需要递归地复制对象的每一层,确保克隆后的对象与原对象完全独立。
让我们通过一个简单的例子来理解这两种拷贝方式的区别:
javascript
const original = {
name: "John",
address: {
city: "New York",
country: "USA",
},
};
// 浅拷贝
const shallowCopy = { ...original };
shallowCopy.address.city = "London";
console.log(original.address.city); // 'London' - 原始数据被修改
// 深拷贝
const deepCopy = JSON.parse(JSON.stringify(original));
deepCopy.address.city = "Paris";
console.log(original.address.city); // 'London' - 原始数据保持不变三、浅拷贝的多种实现方式
浅拷贝的核心原理是创建一个新对象,并将原对象的第一层属性值完整复制到新对象中。对于基本数据类型属性,会直接复制值本身;而对于引用类型属性,则仅复制其内存地址引用而非实际内容。这也就意味着如果我们修改任一元素的这些内容,另外一个元素会随之改变,仅当改变第一层的属性时,两元素之间相互独立。
实际上,JavaScript 的多个 API 包含了浅拷贝的逻辑,我们可以直接调用这些 API 实现对不同元素的浅拷贝操作。
1. Array.prototype.slice()
Array.prototype.slice() 方法用于从数组中提取指定范围的元素并返回一个新数组,生成的新数组相当于从原数组浅拷贝而来。其允许接受两个参数,第一个参数是提取起始位置的索引,第二个参数是提取结束位置的索引(不包括该索引对应的元素)。
javascript
const array1 = [1, 2, 3, ["a", "b"]];
const array2 = array1.slice();2. Array.prototype.map()
Array.prototype.map() 方法通过指定的回调函数处理数组的每个元素,并返回一个由回调函数返回值组成的新数组,它与 slice 方法类似,生成的新数组都是相当于从原数组浅拷贝而来。
javascript
const array1 = [1, 2, 3, ["a", "b"]];
const array2 = array1.map((item) => item);3. Object.assign()
Object.assign() 可以将一个或多个源对象的所有属性都复制到目标对象,其第一个参数为目标对象,其余的参数均为源对象。该方法常用于对象的浅拷贝操作。
javascript
const object1 = { name: "a", book: { title: "1984", author: "George Orwell" } };
const object2 = Object.assign({}, object1);4. 扩展运算符
在 ES6 语法中,提供了更加简便实现浅拷贝的方式 --- 拓展运算符 ,我们可以通过 [...array] 或 {...object} 轻松实现对数组或对象的浅拷贝操作。
javascript
const object1 = { name: "a", book: { title: "1984", author: "George Orwell" } };
const object2 = { ...object1 };通过这些 API,我们可以轻松实现一个简易的浅拷贝处理函数 --- 当传入值为值类型时,返回值类型本身;当传入值为引用类型时,对这些传入的内容进行浅拷贝操作:
javascript
const shallowCopy = (element) => {
// 类型守卫 ------ typeof null 也是 object,所以需要单独判断
if (typeof element !== "object" || element === null) {
return element;
}
// 数组场景
if (Array.isArray(element)) return element.slice(0, element.length);
// 对象场景
return Object.assign({}, element);
};四、深拷贝的实现与原型链处理
深拷贝的核心要求不仅是复制对象的第一层属性,要求拷贝后的每一层内容都与拷贝前的内容相互独立,形成一份全新的数据副本。在日常开发过程中,很多需要深拷贝的场景都可以使用现成的方案解决。
1. JSON 方法
最简单的方法就是对一个引用类型进行序列化再反序列化---JSON.parse(JSON.stringify(element)),但是这种方法有诸多弊端。由于 JSON 本身并不能表示 undefined 、function 等类型,并且在序列化的过程中并不能处理循环引用的场景,所以就导致这种处理方式在面对特殊数据类型及循环引用场景时就会出现问题。
注意: JSON 方法在处理以下情况时会出现问题:
Date对象会被转换为字符串RegExp对象会被转换为空对象Function会被完全忽略undefined会被忽略- 循环引用会抛出错误
2. Lodash 库
Lodash 库为我们提供了更加完善的方案,提供了 cloneDeep 方法我们可以直接使用。
3. 自定义深拷贝实现
这里我们实现一个简易版的深拷贝函数(不考虑循环引用及特殊对象类型)。
浅拷贝与深拷贝的本质区别在于处理深度:浅拷贝仅复制第一层属性,而深拷贝需要递归处理所有层级的引用类型数据。因此,我们的实现可以看作是在浅拷贝的基础上,对每个引用类型属性再进行一次"单层拷贝",如此递归下去,直到所有层级都被处理完毕。因此,我们每一层的拷贝其实与浅拷贝类似,遵循如下思路:
- 处理每一层元素时,使用 for...in 循环遍历对象的所有可枚举属性
- 对于基本数据类型(非引用类型),直接返回其值
- 对于引用类型,需要区分数组还是对象来创建新的元素,并递归调用"单层拷贝"处理该引用类型属性。
javascript
const deepCopy = (element) => {
// 类型守卫 ------ typeof null 也是 object,所以需要单独判断
if (typeof element !== "object" || element === null) {
return element;
}
// 数组或对象场景 ------ 根据类型创建空数组或对象
const result = Array.isArray(element) ? [] : {};
// 遍历 ------ 递归调用 deepCopy
for (const key in element) {
result[key] = deepCopy(element[key]);
}
return result;
};
const array = [1, [1, 2, 3]];
const object = { name: "a", book: { title: "Old Man and the Sea" } };
const array2 = deepCopy(array);
const object2 = deepCopy(object);
array[1].push(4);
object.book.title = "Stronger";
console.log(array); // [1, [1, 2, 3, 4]]
console.log(array2); // [1, [1, 2, 3]]
console.log(object); // { name: 'a', book: { title: 'Stronger' } }
console.log(object2); // { name: 'a', book: { title: 'Old Man and the Sea' } }4. 原型链处理
其实写到这里,我们已经能够实现简单的深拷贝工作了。但是如果我们为对象的原型上添加属性或方法,可以发现这些方法也都会被拷贝下来,成为新对象自身的属性或方法,这是为什么呢?
javascript
function Animal(name) {
this.name = name;
}
// 为原型添加属性
Animal.prototype.action = ["eat", "sleep", "play"];
const dog = new Animal("dog");
const copyDog = deepCopy(dog);
console.log(dog); // Animal { name: 'dog' }
console.log(copyDog); // { name: 'dog', action: [ 'eat', 'sleep', 'play' ] }其实原因就出在我们使用了 for...in 循环,它会遍历对象的所有可枚举属性 (包括自身属性和原型链上的可枚举属性),这就意味着其原型上的可枚举的属性和方法也会被遍历出来,而我们直接把这些属性添加为新对象自身的属性和方法是会破坏掉原型链本身的共享机制,所有的共享属性和方法都会被单独复制出一份出来,同时也增加了拷贝的复杂度。
补充说明:
- prototype 原型可以把属性或方法定义在原型中让类实例化出来的所有对象共用一个属性或方法。
- JS 中的对象的继承是基于原型链 实现的,prototype 属性是这一机制的核心组成部分。
我们可以在每层循环中使用 hasOwnProperty 方法来判断该属性是否属于对象本身,同时在需要拷贝时处理原型的场景中使用 Object.create(Object.getPrototypeOf(obj)) 直接在创建新对象时继承原对象的原型:
javascript
const deepCopy = (element) => {
// 类型守卫 ------ typeof null 也是 object,所以需要单独判断
if (typeof element !== "object" || element === null) {
return element;
}
// 数组或对象场景 ------ 根据类型创建空数组或对象(继承原型的场景)
const result = Array.isArray(element)
? []
: Object.create(Object.getPrototypeOf(element));
// 遍历 ------ 递归调用 deepCopy
for (const key in element) {
if (element.hasOwnProperty(key)) {
result[key] = deepCopy(element[key]);
}
}
return result;
};
function Animal(name) {
this.name = name;
}
// 为原型添加属性
Animal.prototype.action = ["eat", "sleep", "play"];
const dog = new Animal("dog");
const copyDog = deepCopy(dog);
console.log(dog); // Animal { name: 'dog' }
console.log(copyDog); // Animal { name: 'dog' }
console.log(dog.action === copyDog.action); // true(引用类型指向同一个地址,共享同一个原型)总结
文章先解释为何需要拷贝(值类型与引用类型的差异及带来的数据污染问题),再清晰区分浅拷贝与深拷贝,并给出常用浅拷贝手段(slice、map、Object.assign、扩展运算符)与递归式深拷贝实现。
同时指出 JSON 序列化方案的局限(如 Date、RegExp、function、undefined、循环引用)与可用替代(Lodash cloneDeep),最后补充原型链处理要点(hasOwnProperty 与 Object.create)以避免破坏原型共享。 整体帮助读者从概念到实现形成完整心智模型,能在工程实践中安全地复制复杂数据结构。